↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating realistic human motion remains challenging. Discrete methods prioritize faithfulness to input signals but often produce unnatural, noisy movements. Continuous methods generate smoother motions, but struggle with high dimensionality and limited training data, often lacking faithfulness. This creates a ‘discord’ between efficiency and realism.
DisCoRD resolves this by decoding discrete motion tokens into continuous motion via rectified flow. This iterative refinement in continuous space captures fine-grained dynamics, producing smoother, more natural motions while maintaining faithfulness to the input signals. Experiments across different tasks show DisCoRD’s effectiveness, significantly improving motion naturalness while preserving accuracy. A novel metric, sJPE, is introduced to better capture perceptual naturalness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel method for bridging the gap between the efficiency of discrete and the realism of continuous human motion generation. It introduces a new metric for evaluating motion naturalness and demonstrates state-of-the-art performance on multiple tasks. This opens avenues for creating more realistic and immersive virtual experiences. Researchers can adapt DisCoRD to various tasks and utilize the new evaluation metric (sJPE) to improve the realism of their generated human motions.
Visual Insights#

🔼 DisCoRD, unlike traditional methods, uses an iterative decoding process in continuous space to generate motion from discrete latent representations. This approach addresses the limitations of deterministic decoding by recovering the inherent continuity and dynamism of motion. The figure illustrates this process, highlighting how DisCoRD improves upon existing methods by balancing faithfulness and naturalness. It also introduces a new evaluation metric, Symmetric Jerk Percentage Error (sJPE), which is used in addition to FID to assess the naturalness of generated motion.
read the caption
Figure 1: Concept of DisCoRD. Discrete quantization methods encode multiple motions into a single quantized representation. While existing methods deterministically decode from this quantized representation, DisCoRD iteratively decodes the discrete latent in a continuous space to recover the inherent continuity and dynamism of motion. To assess the gap between reconstructed and real motion, prior work primarily used FID as the metric. Here, we additionally propose symmetric Jerk Percentage Error (sJPE) to evaluate the differences in naturalness between reconstructed and real motion.
| Methods | FID ↓ | MPJPE ↓ | sJPE ↓ |
|---|---|---|---|
| HumanML3D | |||
| MLD (cont.) | 0.017 | 14.7 | 0.404 |
| T2M-GPT | 0.089 ± .001 | 60.0 | 0.564 |
| +DisCoRD(Ours) | 0.031 ± .001 | 71.5 | 0.488 |
| MMM | 0.097 ± .001 | 46.9 | 0.517 |
| +DisCoRD(Ours) | 0.020 ± .001 | 56.8 | 0.429 |
| MoMask | 0.019 ± 001 | 29.5 | 0.512 |
| +DisCoRD(Ours) | 0.011 ± 000 | 33.3 | 0.385 |
| KIT-ML | |||
| T2M-GPT | 0.470 ± .010 | 46.4 | 0.526 |
| +DisCoRD(Ours) | 0.284 ± .009 | 58.7 | 0.395 |
| MoMask | 0.113 ± .001 | 37.5 | 0.384 |
| +DisCoRD(Ours) | 0.103 ± .002 | 33.0 | 0.359 |
🔼 Table 1 presents a quantitative comparison of different methods for motion reconstruction using the HumanML3D and KIT-ML datasets. The metrics used are Fréchet Inception Distance (FID), which measures the similarity between the generated and real motion feature distributions, and Mean Per Joint Position Error (MPJPE), which measures the average distance between corresponding joints in the generated and real motions. A novel metric, Symmetric Jerk Percentage Error (sJPE), is also included, assessing the naturalness of the generated motion by evaluating the smoothness of the motion trajectory. The table highlights that DisCoRD, when used as a decoder for discrete motion representations (as opposed to using a continuous method like MLD), achieves superior performance on both FID and sJPE, demonstrating its effectiveness at translating discrete tokens into natural, continuous motions.
read the caption
Table 1: Quantitative evaluation on the HumanML3D and KIT-ML test sets for reconstruction. DisCoRD serves as a discrete model’s decoder, outperforming MLD in both FID and sJPE, demonstrating its effectiveness in decoding discrete tokens in continuous space.
In-depth insights#
Motion Gen Models#
Motion generation models are broadly classified into those using continuous and discrete representations. Continuous models directly regress on continuous motion values, aiming for smooth and natural results. However, they struggle with high dimensionality and limited data, often compromising faithfulness to input signals. Discrete models, utilizing techniques like VQ-VAEs, quantize motions into discrete tokens, enhancing efficiency and faithfulness, but at the cost of reduced expressiveness and potential artifacts like frame-wise noise or under-reconstruction. DisCoRD innovatively bridges this gap by decoding discrete tokens into continuous motion via rectified flow, achieving a balance of faithfulness and naturalness that surpasses both approaches. The iterative refinement process in continuous space is key to capturing fine-grained dynamics, resulting in smoother, more realistic motion. This approach showcases the significant potential of combining the strengths of both continuous and discrete methods for superior human motion generation.
Rectified Flow Decode#
The concept of “Rectified Flow Decoding” presents a novel approach to enhance the naturalness of motion generation models while preserving faithfulness to input signals. It leverages the strengths of discrete tokenization for efficient representation and score-based models for generating continuous and dynamic motion. The core idea is an iterative refinement process in continuous space, where discrete motion tokens, representing compressed motion information, are decoded iteratively via a rectified flow. This method contrasts with traditional deterministic decoding, enabling the reconstruction of fine-grained dynamics and smoother, more realistic movements. Rectified flow’s iterative nature helps address under-reconstruction and frame-wise noise issues, often associated with discrete methods. The technique’s compatibility with existing discrete frameworks offers significant flexibility and broad applicability. The use of score-based models enhances the stochasticity of the decoding process, leading to greater variability and naturalness in the generated motion. Therefore, this approach successfully bridges the gap between the efficiency of discrete representations and the realism of continuous motion generation.
sJPE Evaluation#
The proposed sJPE (Symmetric Jerk Percentage Error) metric offers a nuanced approach to evaluating the naturalness of generated human motion, addressing shortcomings of traditional metrics like FID and MPJPE. sJPE directly assesses the smoothness of motion by analyzing jerk, the third derivative of position, thus capturing subtle irregularities missed by position-based metrics. By decomposing sJPE into Noise sJPE and Static sJPE, it differentiates between frame-wise noise and under-reconstruction, providing granular insights into specific aspects of motion quality. The strong correlation between sJPE scores and human perception validates its effectiveness in evaluating the realism of generated motion. This granular analysis is crucial because it allows for a more refined understanding of what constitutes natural motion, going beyond simple visual fidelity to capture human-perceptual nuances. The results from sJPE effectively distinguish the superior performance of the proposed method in terms of motion quality when compared to the baseline models.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of this research, it would involve selectively disabling parts of the DisCoRD model, such as the rectified flow decoder, the projection module, or the iterative refinement process, to understand their impact on the model’s performance. The results would help determine which components are essential for achieving high faithfulness and naturalness in motion generation. Key insights gained would include identifying critical model elements and understanding the trade-offs between different model components. For example, removing the iterative refinement step might increase computational efficiency but potentially sacrifice some motion detail or naturalness. The study helps to confirm the necessity of each element and assess the overall design choices. This analysis would ultimately improve the model’s efficiency and robustness by pinpointing areas for optimization and highlighting potentially redundant components, leading to a more streamlined and effective model architecture.
Future Works#
Future work for DisCoRD could involve several exciting directions. Extending DisCoRD to handle longer sequences is crucial for more complex motions. Current limitations on sequence length need to be addressed. Exploring alternative architectures for the rectified flow decoder could improve efficiency and potentially the quality of generated motion. Investigating different score-based models beyond rectified flow might yield further performance gains and explore a wider range of expressiveness. Incorporating more sophisticated conditioning techniques would increase the model’s ability to capture nuanced details from diverse signals. Finally, a focus on improving the evaluation metrics is important to better assess qualitative aspects such as fluidity and realism. A more comprehensive evaluation framework could further advance the field. The current success of DisCoRD paves the way for a multitude of improvements, promising significant advances in human motion generation.
More visual insights#
More on figures

🔼 DisCoRD’s training and inference stages are shown in this figure. During training, a pretrained quantizer processes motion data to create discrete motion tokens. These tokens are converted to continuous features (C), which are combined with noisy motion data (Xt) to train a vector field (v). In the inference phase, a token prediction model generates tokens from a control signal. These tokens are transformed into continuous features (Ĉ), combined with Gaussian noise (X0), and iteratively refined using the trained vector field (vθ) to produce continuous motion data (X̂1).
read the caption
Figure 2: An overview of DisCoRD. During the Training stage, we leverage a pretrained quantizer to first obtain discrete representations (tokens) of motion. These tokens are then projected into continuous features 𝐂𝐂\mathbf{C}bold_C, which are concatenated with noisy motion 𝐗tsubscript𝐗𝑡\mathbf{X}_{t}bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. This concatenated feature is used to train a vector field v𝑣vitalic_v. During the Inference stage, we use a pretrained token prediction model based on the pretrained quantizer to first generate tokens from the given control signal. These generated tokens are then projected into continuous features 𝐂^^𝐂\mathbf{\hat{C}}over^ start_ARG bold_C end_ARG, concatenated with Gaussian noise 𝐗0∼𝒩(0,I)similar-tosubscript𝐗0𝒩0𝐼\mathbf{X}_{0}\sim\mathcal{N}(0,I)bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∼ caligraphic_N ( 0 , italic_I ), and iteratively decoded through the learned vector field vθsubscript𝑣𝜃v_{\theta}italic_v start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT into motion 𝐗^1subscript^𝐗1\mathbf{\hat{X}}_{1}over^ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT.

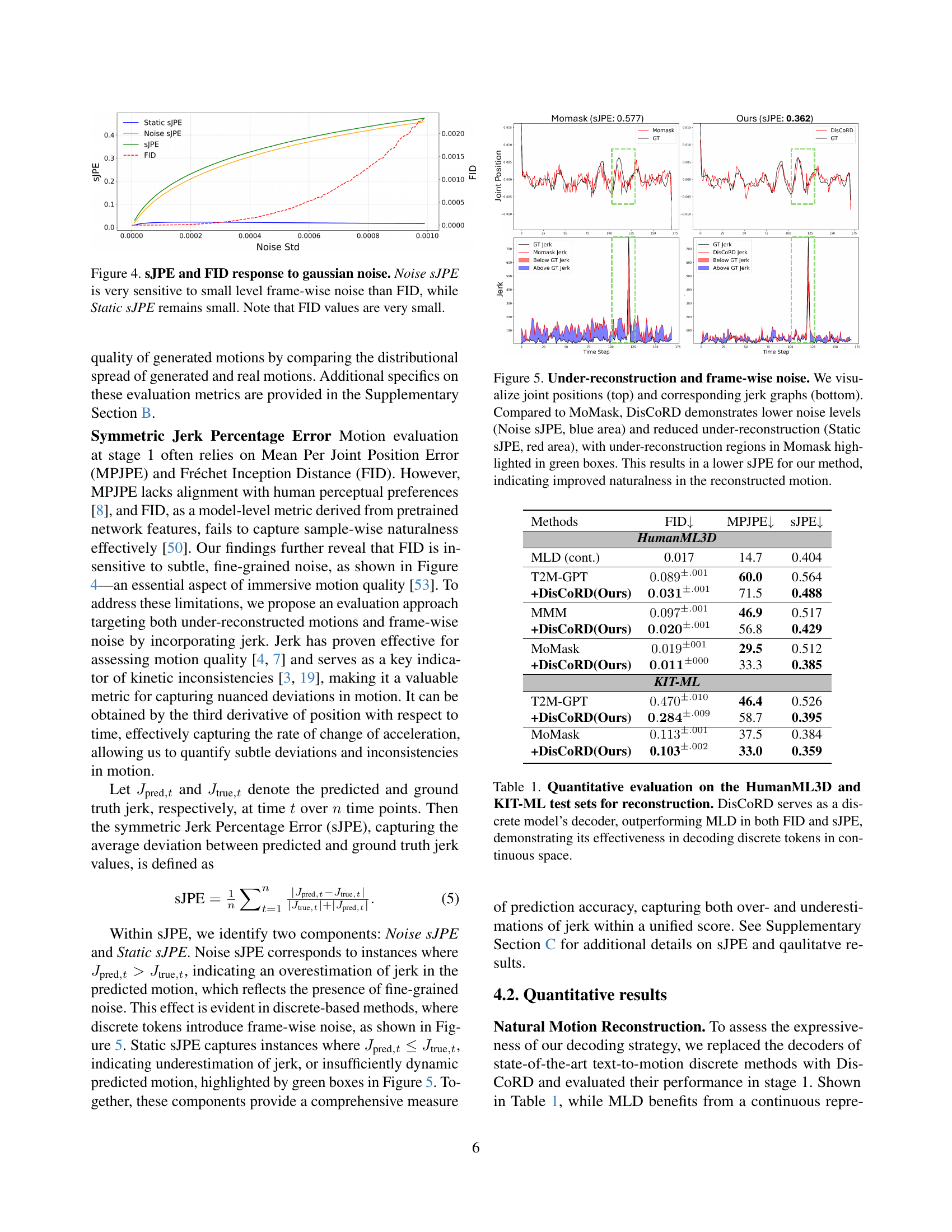
🔼 This figure demonstrates the sensitivity of the Symmetric Jerk Percentage Error (sJPE) and Fréchet Inception Distance (FID) metrics to Gaussian noise in generated motion data. The left graph shows that Noise sJPE is highly sensitive to small amounts of frame-wise noise, while Static sJPE remains relatively unaffected. This indicates that Noise sJPE is a more effective metric for capturing subtle noise artifacts. The right graph visually compares the generated motions, showcasing the effect of Gaussian noise. It further illustrates how Noise sJPE distinguishes between subtle variations in motion quality more effectively than FID, which is less sensitive to small differences, especially with already low FID scores.
read the caption
Figure 3: sJPE and FID response to gaussian noise. Noise sJPE is very sensitive to small level frame-wise noise than FID, while Static sJPE remains small. Note that FID values are very small.

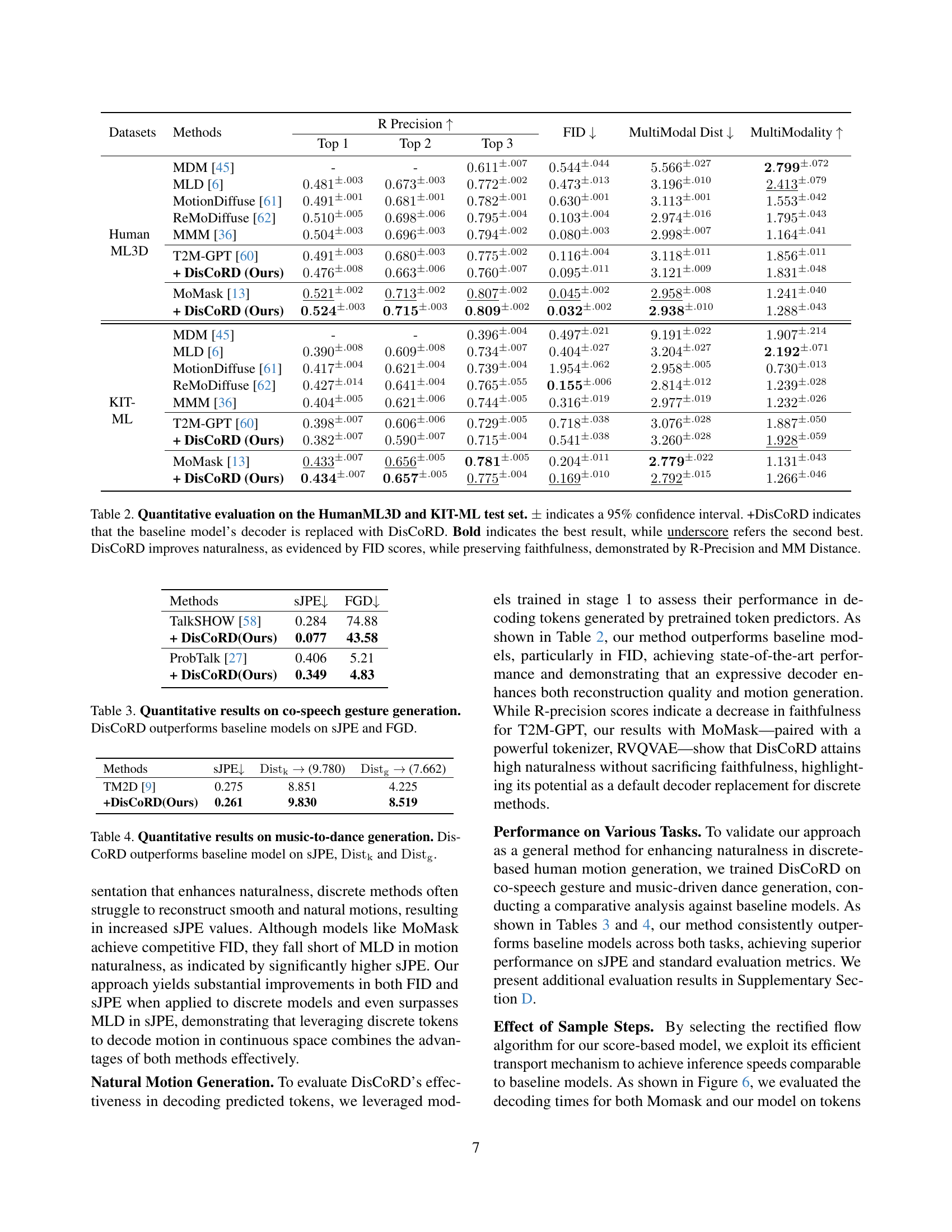
🔼 Figure 4 compares the motion reconstruction quality of DisCoRD and MoMask, focusing on under-reconstruction and frame-wise noise. The top row shows the joint positions of the reconstructed motions over time, while the bottom row displays the corresponding jerk values, which represent the rate of change in acceleration. The figure highlights that MoMask exhibits more pronounced frame-wise noise (blue shaded areas) and under-reconstruction (red shaded areas), indicated by the green boxes. Conversely, DisCoRD demonstrates significantly reduced frame-wise noise and under-reconstruction, resulting in a lower symmetric Jerk Percentage Error (sJPE) score. This indicates that DisCoRD generates more natural and smoother reconstructed motions compared to MoMask.
read the caption
Figure 4: Under-reconstruction and frame-wise noise. We visualize joint positions (top) and corresponding jerk graphs (bottom). Compared to MoMask, DisCoRD demonstrates lower noise levels (Noise sJPE, blue area) and reduced under-reconstruction (Static sJPE, red area), with under-reconstruction regions in Momask highlighted in green boxes. This results in a lower sJPE for our method, indicating improved naturalness in the reconstructed motion.

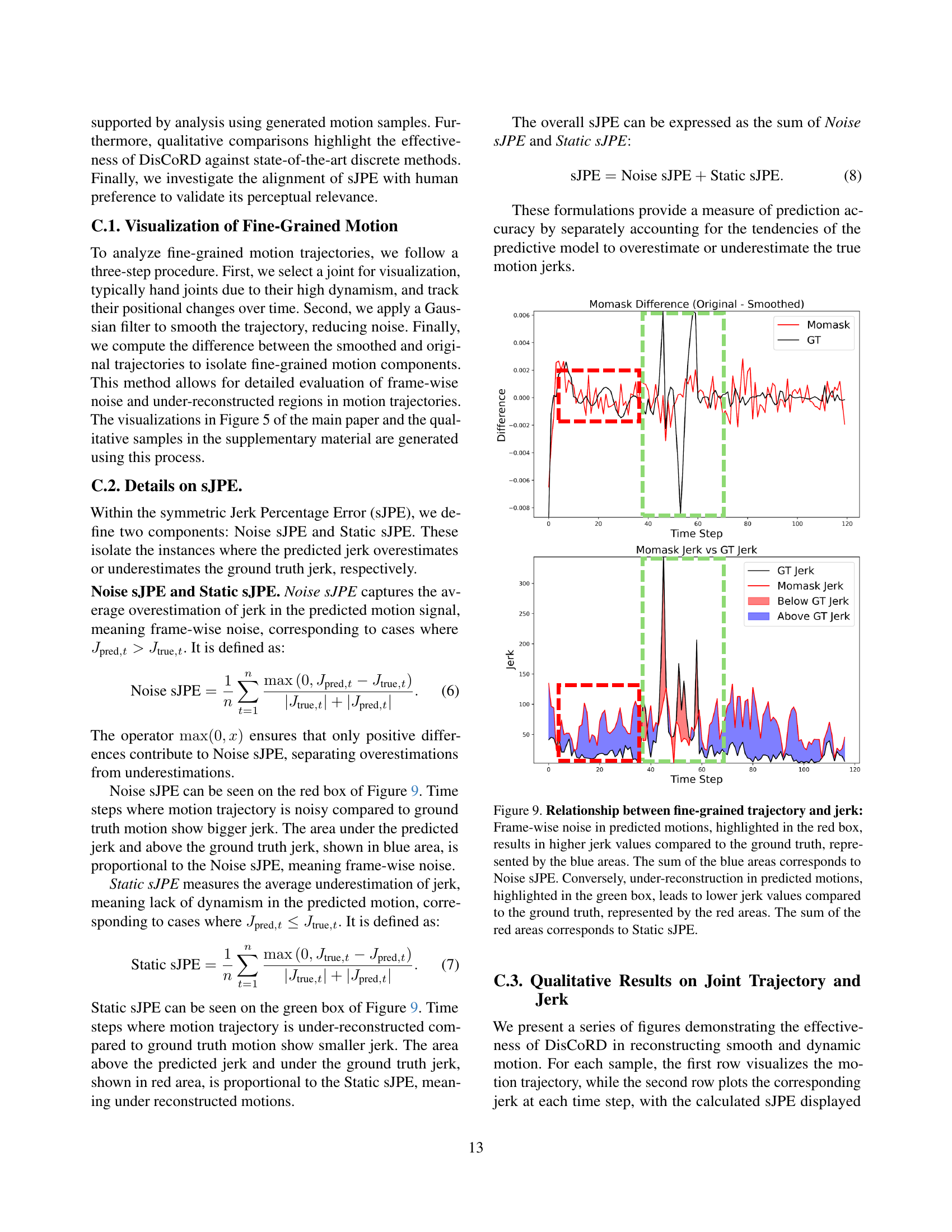
🔼 This figure shows the time taken to decode a batch of 32 motion token sequences using three different methods: MLD, MoMask, and DisCoRD (the authors’ method). The decoding was performed on the same hardware (NVIDIA RTX 4090Ti GPU) to ensure a fair comparison. The experiment was repeated 20 times for each method on the complete HumanML3D dataset. The graph displays the average decoding time for each method.
read the caption
Figure 5: Time spent decoding a batch of token sequences with a batch size of 32. All tests are conducted on the same NVIDIA RTX 4090Ti. Each experiment was repeated 20 times across the entire HumanML3D test set, and the average values were reported.

🔼 This figure showcases a qualitative comparison of human motion generation results on the HumanML3D dataset. It visually presents generated motions alongside corresponding text descriptions from various models, highlighting differences in both faithfulness (how accurately the motion matches the text description) and naturalness (how smooth and realistic the motion appears). The comparison enables a visual assessment of the models’ strengths and weaknesses in producing high-quality, natural human movement based on textual prompts.
read the caption
Figure 6: Qualitative comparisons on the test set of HumanML3D.

🔼 This figure displays the results of a user study comparing the performance of different models on the HumanML3D dataset. Each bar graph represents a head-to-head comparison between two models, showing the percentage of times each model was preferred by users for either faithfulness or naturalness of generated motion. Blue sections indicate the win rate for a particular model (i.e., the percentage of times that particular model was preferred over the other model in that comparison) while red shows the loss rate. The user study aimed to evaluate the subjective quality of generated motions in terms of their faithfulness to input text prompts and their naturalness.
read the caption
Figure 7: User study results on the HumanML3D dataset. Each bar represents a comparison between two models, with win rates depicted in blue and loss rates in red, evaluated based on naturalness and faithfulness.

🔼 Figure 8 visualizes the relationship between fine-grained motion trajectories and jerk, a measure of motion smoothness. The figure shows how frame-wise noise (in red boxes) leads to higher jerk values in the prediction compared to the ground truth. The cumulative area of this discrepancy is quantified as Noise sJPE. Conversely, under-reconstruction (in green boxes), where the model fails to capture fine details, results in lower jerk values than the ground truth. The cumulative difference here is represented by Static sJPE. Thus, the figure illustrates how these two components of the Symmetric Jerk Percentage Error (sJPE) capture different types of motion imperfections: noise and under-reconstruction.
read the caption
Figure 8: Relationship between fine-grained trajectory and jerk: Frame-wise noise in predicted motions, highlighted in the red box, results in higher jerk values compared to the ground truth, represented by the blue areas. The sum of the blue areas corresponds to Noise sJPE. Conversely, under-reconstruction in predicted motions, highlighted in the green box, leads to lower jerk values compared to the ground truth, represented by the red areas. The sum of the red areas corresponds to Static sJPE.

🔼 Figure 9 visualizes the effectiveness of DisCoRD in reconstructing dynamic motion compared to other discrete methods. It presents a detailed analysis of joint trajectories and jerk (the rate of change of acceleration) over time. The figure highlights how DisCoRD minimizes under-reconstruction, a common issue in discrete methods where fine-grained details are lost, as represented by the reduction in the red area. This improvement directly correlates with a lower Symmetric Jerk Percentage Error (sJPE) value, indicating that DisCoRD produces smoother and more natural-looking motions.
read the caption
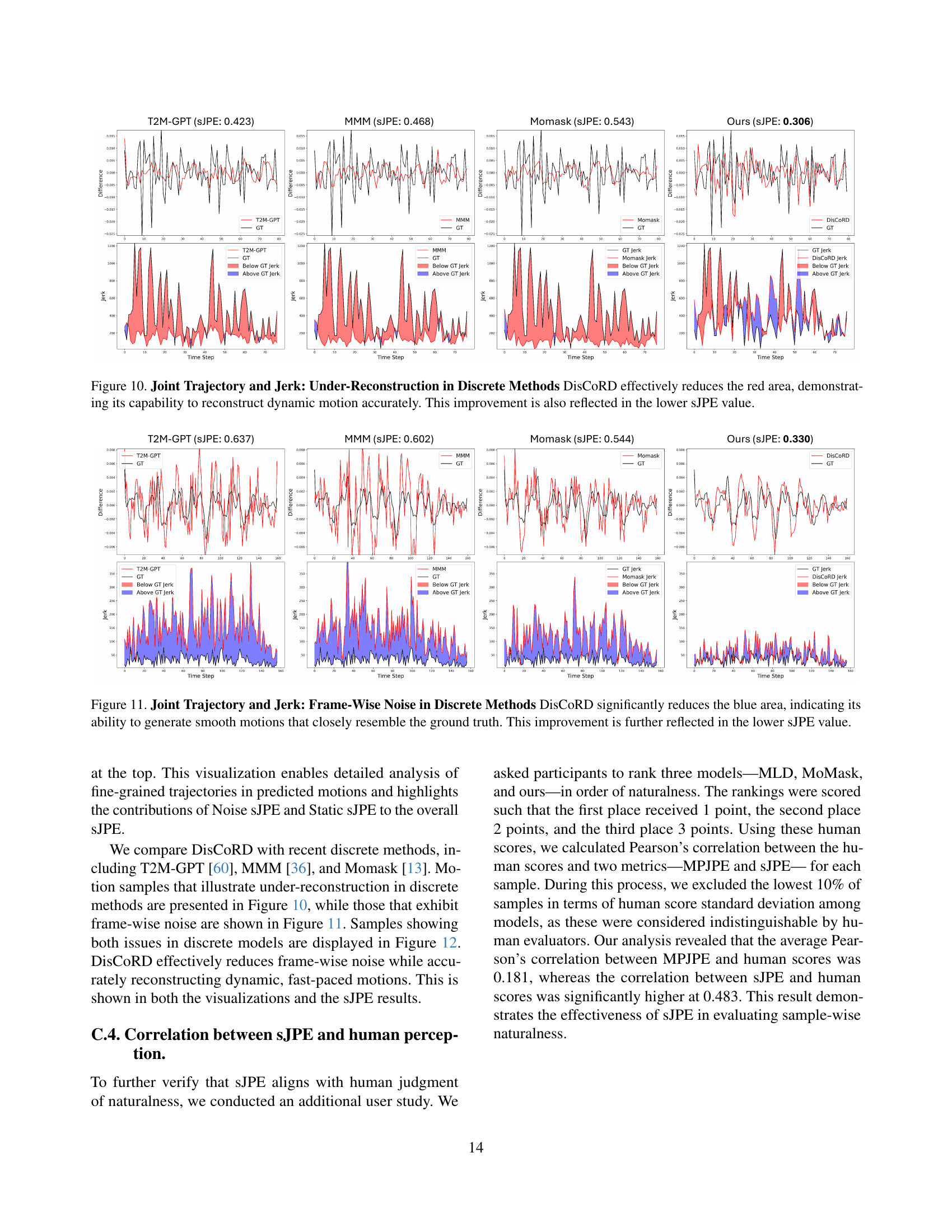
Figure 9: Joint Trajectory and Jerk: Under-Reconstruction in Discrete Methods DisCoRD effectively reduces the red area, demonstrating its capability to reconstruct dynamic motion accurately. This improvement is also reflected in the lower sJPE value.

🔼 Figure 10 visualizes the effectiveness of DisCoRD in reducing frame-wise noise during motion generation. It compares the joint trajectories and jerk (rate of change of acceleration) of motions generated by DisCoRD against those from other discrete methods. The blue areas in the plots represent instances where the predicted jerk exceeds the ground truth jerk, indicating noisy or unnatural motion. DisCoRD’s significantly smaller blue area demonstrates its superior ability to produce smooth, natural motions that closely match the ground truth. This improvement is quantitatively reflected in a lower Symmetric Jerk Percentage Error (sJPE) value.
read the caption
Figure 10: Joint Trajectory and Jerk: Frame-Wise Noise in Discrete Methods DisCoRD significantly reduces the blue area, indicating its ability to generate smooth motions that closely resemble the ground truth. This improvement is further reflected in the lower sJPE value.

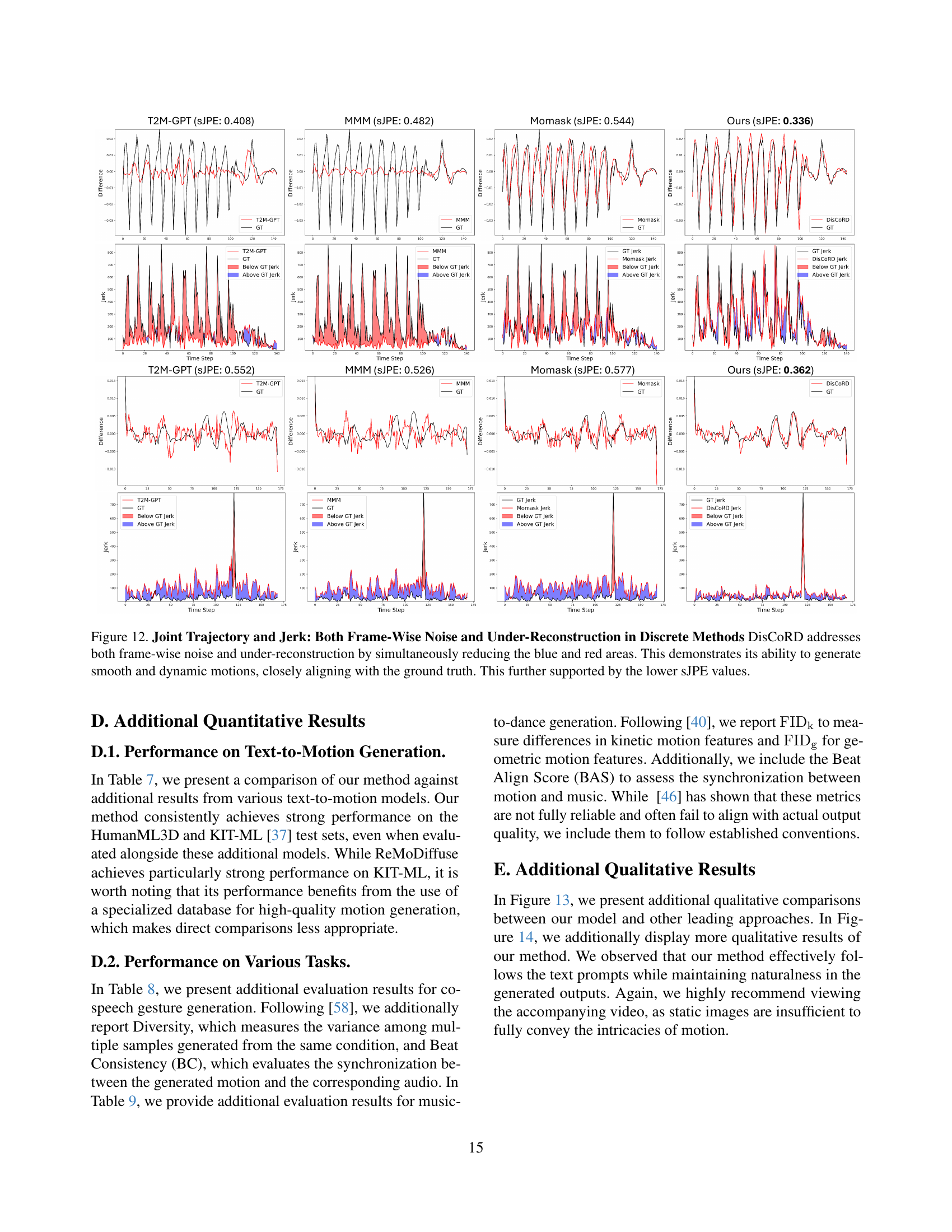
🔼 Figure 11 visualizes the effectiveness of DisCoRD in addressing both frame-wise noise and under-reconstruction, common issues in discrete methods. It presents joint trajectory and jerk plots for several methods, including DisCoRD, highlighting how DisCoRD significantly reduces both the blue area (representing noise) and the red area (representing under-reconstruction). This results in smoother, more dynamic, and accurate motions closely matching the ground truth, as confirmed by the lower Symmetric Jerk Percentage Error (sJPE) values.
read the caption
Figure 11: Joint Trajectory and Jerk: Both Frame-Wise Noise and Under-Reconstruction in Discrete Methods DisCoRD addresses both frame-wise noise and under-reconstruction by simultaneously reducing the blue and red areas. This demonstrates its ability to generate smooth and dynamic motions, closely aligning with the ground truth. This further supported by the lower sJPE values.

🔼 Figure 12 presents a qualitative comparison of human motion generation results from three different methods: a continuous method (MLD), a discrete method (MoMask), and the proposed DisCoRD approach. Each row shows motion generated from the same text prompt. The continuous method (MLD) produces smooth motions but frequently lacks faithfulness to the textual description. The discrete method (MoMask) suffers from under-reconstruction, which leads to simplified or unnatural movements, especially noticeable in the hands and legs, and frame-wise noise, causing jerky or unnatural motion. The DisCoRD method, in contrast, aims to balance the strengths of both approaches, generating motion that remains faithful to the text description while maintaining smoothness and naturalness. The figure highlights how DisCoRD improves on the shortcomings of the other two methods.
read the caption
Figure 12: Additional qualitative comparisons on the HumanML3D test set. The continuous method, MLD, often fails to perfectly align with the text consistently, while the discrete method, MoMask, exhibits issues such as under-reconstruction, resulting in minimal hand movement, or unnatural leg jitter caused by frame-wise noise.

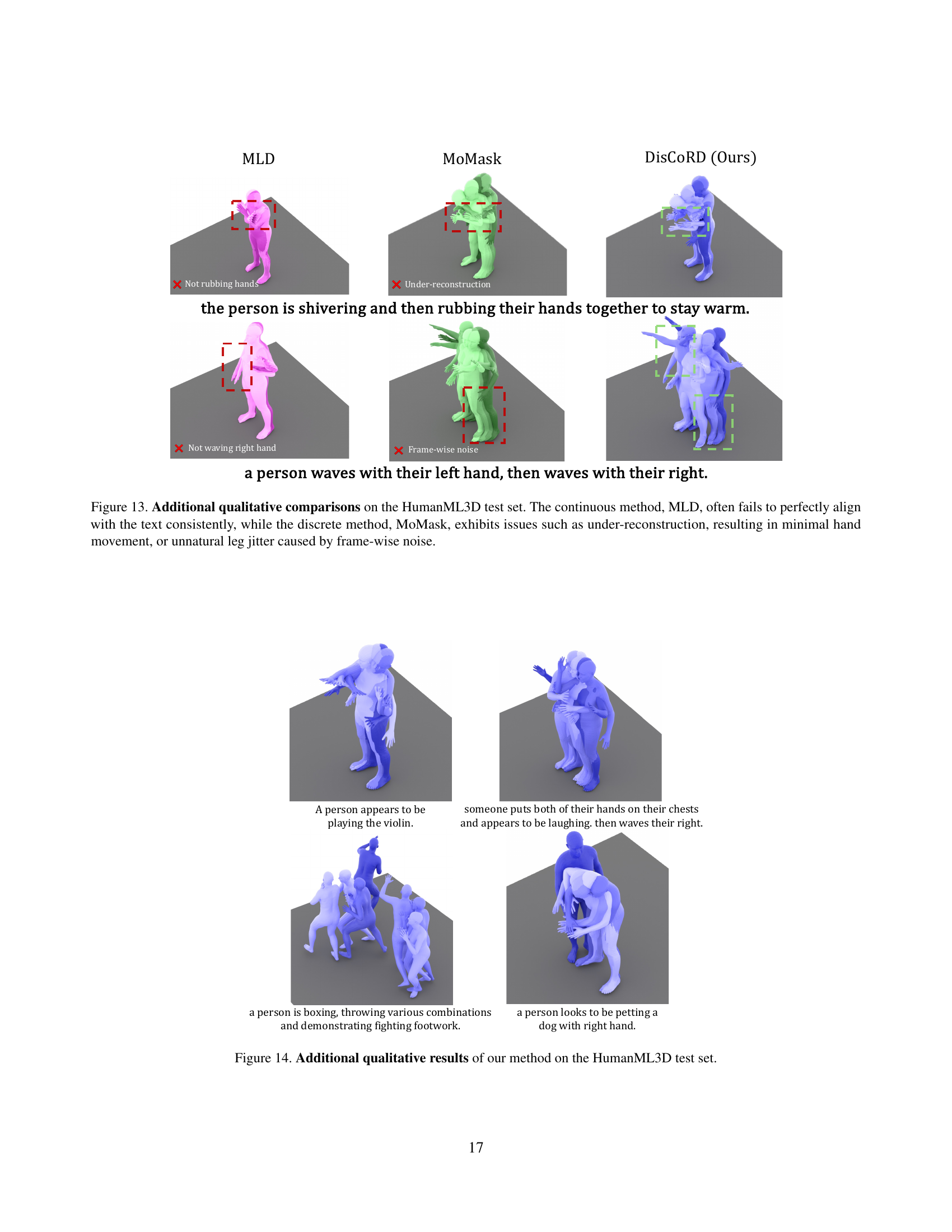
🔼 This figure showcases qualitative comparisons of human motion generation results between DisCoRD and two other methods (MLD and MoMask) on the HumanML3D dataset. It highlights DisCoRD’s ability to generate motions that are both faithful to the textual descriptions and visually natural. The examples demonstrate that MLD struggles with faithfulness to text descriptions, often resulting in incorrect actions, while MoMask, although more faithful, produces less natural motions with issues such as under-reconstruction and frame-wise noise. DisCoRD effectively addresses these limitations, generating smoother, more realistic movements that accurately reflect the input text.
read the caption
Figure 13: Additional qualitative results of our method on the HumanML3D test set.

🔼 This figure shows the guidelines used in the user study. Participants were asked to evaluate the generated motions based on two criteria: faithfulness (how well the motion reflects the given text description) and naturalness (how natural the motion appears, regardless of the text). Importantly, the instructions specifically excluded evaluating hand and facial movements, as these elements are not consistently present in the HumanML3D dataset used for training and evaluation.
read the caption
Figure 14: Guidelines for user study in the Main paper: participants were asked to evaluate Faithfulness and Naturalness, excluding hand and facial movements that are not included in HumanML3D.

🔼 This figure details the guidelines provided to participants in a user study conducted as part of supplementary materials for the research paper. The user study focused on evaluating the naturalness of generated human motions. Importantly, the guidelines explicitly instructed participants to disregard hand and facial movements when assessing naturalness, as these elements were not included in the HumanML3D dataset used for model training and evaluation. This exclusion is crucial because the models being assessed did not generate these features, and including them in the evaluation would introduce bias and unfair comparisons.
read the caption
Figure 15: Guidelines for User Study in the Supplementary: Participants were asked to evaluate Naturalness, excluding hand and facial movements that are not included in HumanML3D.

🔼 In this user study, participants were shown pairs of videos generated using different methods. For each pair, participants were asked to select which video better demonstrated two key qualities: faithfulness (how accurately the motion reflected the given text description) and naturalness (how smooth and realistic the motion appeared, irrespective of the text prompt). This figure shows the user interface used for this evaluation.
read the caption
Figure 16: User evaluation interface for the user study in the Main paper: participants were presented with two randomly selected videos and asked to choose the better sample in terms of faithfulness and naturalness.

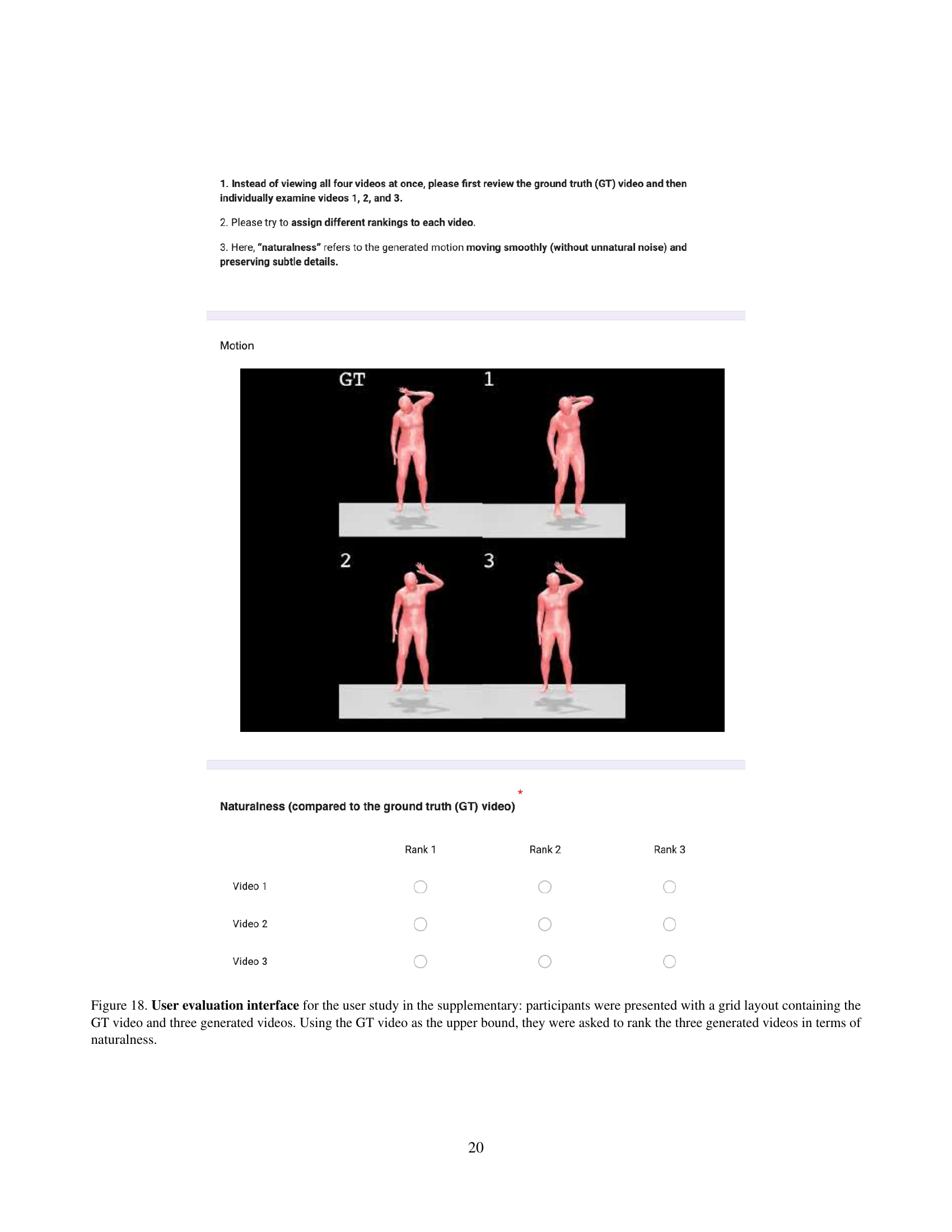
🔼 This figure shows the user interface employed in a supplementary user study. Participants viewed a grid containing the ground truth (GT) motion video alongside three motion videos generated by different models. Their task was to rank the three generated videos based on their naturalness, using the GT video as a benchmark for comparison. The ranking scale was ordinal, allowing participants to assign the same rank to multiple videos if the differences in naturalness were indistinguishable.
read the caption
Figure 17: User evaluation interface for the user study in the supplementary: participants were presented with a grid layout containing the GT video and three generated videos. Using the GT video as the upper bound, they were asked to rank the three generated videos in terms of naturalness.
More on tables
| Datasets | Methods | Top 1 | Top 2 | Top 3 | FID ↓ | MultiModal Dist ↓ | MultiModality ↑ |
|---|---|---|---|---|---|---|---|
| Human ML3D | MDM [45] | - | - | 0.611±.007 | 0.544±.044 | 5.566±.027 | 2.799±.072 |
| MLD [6] | 0.481±.003 | 0.673±.003 | 0.772±.002 | 0.473±.013 | 3.196±.010 | 2.413±.079 | |
| MotionDiffuse [61] | 0.491±.001 | 0.681±.001 | 0.782±.001 | 0.630±.001 | 3.113±.001 | 1.553±.042 | |
| ReMoDiffuse [62] | 0.510±.005 | 0.698±.006 | 0.795±.004 | 0.103±.004 | 2.974±.016 | 1.795±.043 | |
| MMM [36] | 0.504±.003 | 0.696±.003 | 0.794±.002 | 0.080±.003 | 2.998±.007 | 1.164±.041 | |
| T2M-GPT [60] | 0.491±.003 | 0.680±.003 | 0.775±.002 | 0.116±.004 | 3.118±.011 | 1.856±.011 | |
| + DisCoRD (Ours) | 0.476±.008 | 0.663±.006 | 0.760±.007 | 0.095±.011 | 3.121±.009 | 1.831±.048 | |
| KIT- ML | MDM [45] | - | - | 0.396±.004 | 0.497±.021 | 9.191±.022 | 1.907±.214 |
| MLD [6] | 0.390±.008 | 0.609±.008 | 0.734±.007 | 0.404±.027 | 3.204±.027 | 2.192±.071 | |
| MotionDiffuse [61] | 0.417±.004 | 0.621±.004 | 0.739±.004 | 1.954±.062 | 2.958±.005 | 0.730±.013 | |
| ReMoDiffuse [62] | 0.427±.014 | 0.641±.004 | 0.765±.055 | 0.155±.006 | 2.814±.012 | 1.239±.028 | |
| MMM [36] | 0.404±.005 | 0.621±.006 | 0.744±.005 | 0.316±.019 | 2.977±.019 | 1.232±.026 | |
| T2M-GPT [60] | 0.398±.007 | 0.606±.006 | 0.729±.005 | 0.718±.038 | 3.076±.028 | 1.887±.050 | |
| + DisCoRD (Ours) | 0.382±.007 | 0.590±.007 | 0.715±.004 | 0.541±.038 | 3.260±.028 | 1.928±.059 | |
| + DisCoRD (Ours) | 0.434±.007 | 0.657±.005 | 0.775±.004 | 0.169±.010 | 2.792±.015 | 1.266±.046 |
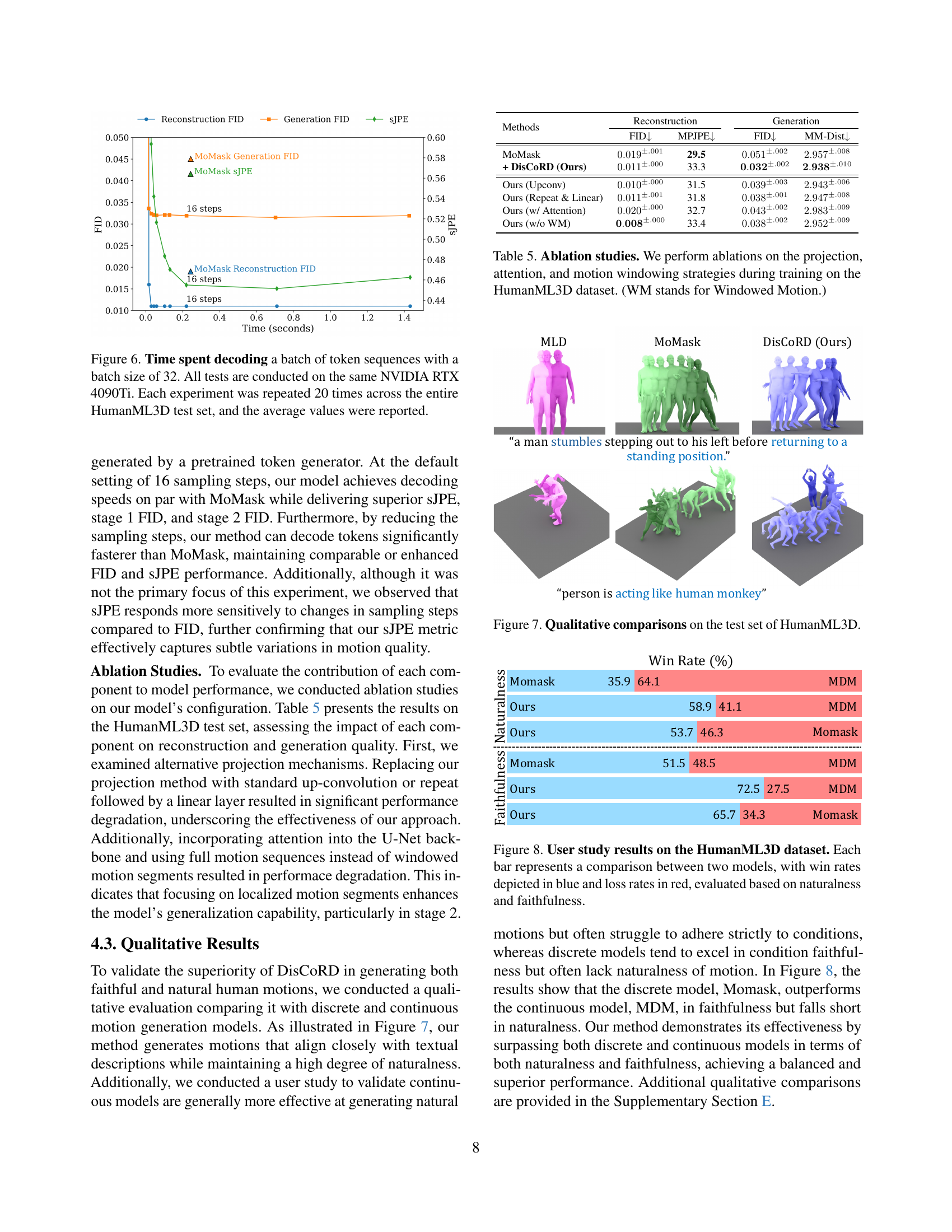
🔼 Table 2 presents a quantitative comparison of different methods for text-to-motion generation on the HumanML3D and KIT-ML datasets. The metrics used are Top-K Recall@1, FID (Fréchet Inception Distance), Multimodal Distance, and Multimodality. The plus-or-minus symbol (±) indicates the 95% confidence interval for each metric’s score. Rows with ‘+DisCoRD’ show the performance when the DisCoRD method replaces the original decoder of a baseline model. Bold typeface highlights the best performance for each metric, and underlined text indicates the second-best performance. The table demonstrates that DisCoRD improves the naturalness of generated motion (lower FID scores), while maintaining its faithfulness to the input text (higher R-Precision and lower Multimodal Distance).
read the caption
Table 2: Quantitative evaluation on the HumanML3D and KIT-ML test set. ±plus-or-minus\pm± indicates a 95% confidence interval. +DisCoRD indicates that the baseline model’s decoder is replaced with DisCoRD. Bold indicates the best result, while underscore refers the second best. DisCoRD improves naturalness, as evidenced by FID scores, while preserving faithfulness, demonstrated by R-Precision and MM Distance.
| Methods | sJPE↓ | FGD↓ |
|---|---|---|
| TalkSHOW [58] | 0.284 | 74.88 |
| + DisCoRD(Ours) | 0.077 | 43.58 |
| ProbTalk [27] | 0.406 | 5.21 |
| + DisCoRD(Ours) | 0.349 | 4.83 |
🔼 This table presents a quantitative comparison of different methods for co-speech gesture generation. The metrics used are Symmetric Jerk Percentage Error (sJPE), which measures the smoothness and naturalness of the generated motion, and Fréchet Gesture Distance (FGD), which assesses the overall similarity between the generated and ground truth gestures. The results show that DisCoRD significantly outperforms other methods in terms of both sJPE and FGD, indicating its superior ability to generate natural and faithful co-speech gestures.
read the caption
Table 3: Quantitative results on co-speech gesture generation. DisCoRD outperforms baseline models on sJPE and FGD.
| Methods | sJPE↓ | Distk→ | Distg→ |
|---|---|---|---|
| TM2D [9] | 0.275 | 8.851 | 4.225 |
| +DisCoRD(Ours) | 0.261 | 9.830 | 8.519 |
🔼 Table 4 presents a quantitative comparison of the proposed DisCoRD model against a baseline method for music-to-dance generation. The evaluation metrics used are Symmetric Jerk Percentage Error (sJPE), Distk (kinetic distance), and Distg (geometric distance). The results demonstrate that DisCoRD achieves superior performance across all three metrics, indicating its effectiveness in generating high-quality, natural dance movements from music.
read the caption
Table 4: Quantitative results on music-to-dance generation. DisCoRD outperforms baseline model on sJPE, DistksubscriptDistk\mathrm{Dist_{k}}roman_Dist start_POSTSUBSCRIPT roman_k end_POSTSUBSCRIPT and DistgsubscriptDistg\mathrm{Dist_{g}}roman_Dist start_POSTSUBSCRIPT roman_g end_POSTSUBSCRIPT.
| Methods | Reconstruction FID ↓ | Reconstruction MPJPE ↓ | Generation FID ↓ | Generation MM-Dist ↓ | |
|---|---|---|---|---|---|
| MoMask | 0.019 ± .001 | 29.5 | 0.051 ± .002 | 2.957 ± .008 | |
| + DisCoRD (Ours) | 0.011 ± .000 | 33.3 | 0.032 ± .002 | 2.938 ± .010 | |
| Ours (Upconv) | 0.010 ± .000 | 31.5 | 0.039 ± .003 | 2.943 ± .006 | |
| Ours (Repeat & Linear) | 0.011 ± .001 | 31.8 | 0.038 ± .001 | 2.947 ± .008 | |
| Ours (w/ Attention) | 0.020 ± .000 | 32.7 | 0.043 ± .002 | 2.983 ± .009 | |
| Ours (w/o WM) | 0.008 ± .000 | 33.4 | 0.038 ± .002 | 2.952 ± .009 |
🔼 This ablation study investigates the impact of different architectural choices within the DisCoRD model on its performance. Specifically, it examines the effect of three key components: the projection method used to transform discrete tokens into continuous features, the inclusion of an attention mechanism in the U-Net architecture, and the training strategy using windowed motion sequences (as opposed to full-length sequences). The results, evaluated on the HumanML3D dataset, quantify the contribution of each component to the model’s reconstruction and generation quality, as measured by FID and MPJPE.
read the caption
Table 5: Ablation studies. We perform ablations on the projection, attention, and motion windowing strategies during training on the HumanML3D dataset. (WM stands for Windowed Motion.)
| Training Details | ||
|---|---|---|
| Optimizer | AdamW (0.9,0.999) | |
| LR | 0.0005 | |
| LR Decay Ratio | 0 | |
| LR Scheduler | Cosine | |
| Warmup Epochs | 20 | |
| Gradient Clipping | 1.0 | |
| Weight EMA | 0.999 | |
| Flow Loss | MSE Loss | |
| Batch Size | 768 | |
| Window Size | 64 | |
| Steps | 481896 | |
| Epochs | 200 | |
| Model Details | ||
| — | — | — |
| Input Channels | 512 | |
| Output Channels | 263 | |
| Condition Channels | 256 | |
| Activation | SiLU | |
| Dropout | 0 | |
| Width | (512, 1024) | |
| # Resnet / Block | 2 | |
| # Params | 66.9M |
🔼 Table 6 details the hyperparameters and settings used to train the DisCoRD decoder. The DisCoRD decoder was trained using the pretrained Momask quantizer on the HumanML3D dataset. The table specifies the optimizer used (AdamW), learning rate, learning rate decay ratio, learning rate scheduler, gradient clipping, weight exponential moving average (EMA), flow loss function, batch size, window size, and the number of training steps and epochs. Architectural details like input and output channels, the activation function used (SiLU), dropout rate, and the number of parameters are also included.
read the caption
Table 6: Implementation details for training the DisCoRD decoder on the HumanML3D dataset using the pretrained Momask quantizer.
| Datasets | Methods | R Precision ↑ (Top 1) | R Precision ↑ (Top 2) | R Precision ↑ (Top 3) | FID ↓ | MultiModal Dist ↓ | MultiModality ↑ |
|---|---|---|---|---|---|---|---|
| Human ML3D | MDM [45] | - | - | 0.611 ± 0.007 | 0.544 ± 0.044 | 5.566 ± 0.027 | 2.799 ± 0.072 |
| MLD [6] | 0.481 ± 0.003 | 0.673 ± 0.003 | 0.772 ± 0.002 | 0.473 ± 0.013 | 3.196 ± 0.010 | 2.413 ± 0.079 | |
| MotionDiffuse [61] | 0.491 ± 0.001 | 0.681 ± 0.001 | 0.782 ± 0.001 | 0.630 ± 0.001 | 3.113 ± 0.001 | 1.553 ± 0.042 | |
| ReMoDiffuse [62] | 0.510 ± 0.005 | 0.698 ± 0.006 | 0.795 ± 0.004 | 0.103 ± 0.004 | 2.974 ± 0.016 | 1.795 ± 0.043 | |
| Fg-T2M [51] | 0.492 ± 0.002 | 0.683 ± 0.003 | 0.783 ± 0.024 | 0.243 ± 0.019 | 3.109 ± 0.007 | 1.614 ± 0.049 | |
| M2DM [18] | 0.497 ± 0.003 | 0.682 ± 0.002 | 0.763 ± 0.003 | 0.352 ± 0.005 | 3.134 ± 0.010 | 3.587 ± 0.072 | |
| M2D2M [7] | - | - | 0.799 ± 0.002 | 0.087 ± 0.004 | 3.018 ± 0.010 | 2.115 ± 0.079 | |
| MotionGPT [63] | 0.364 ± 0.005 | 0.533 ± 0.003 | 0.629 ± 0.004 | 0.805 ± 0.002 | 3.914 ± 0.013 | 2.473 ± 0.041 | |
| MotionLLM [54] | 0.482 ± 0.004 | 0.672 ± 0.003 | 0.770 ± 0.002 | 0.491 ± 0.019 | 3.138 ± 0.010 | - | |
| MotionGPT-2 [52] | 0.496 ± 0.002 | 0.691 ± 0.003 | 0.782 ± 0.004 | 0.191 ± 0.004 | 3.080 ± 0.013 | 2.137 ± 0.022 | |
| AttT2M [65] | 0.499 ± 0.003 | 0.690 ± 0.002 | 0.786 ± 0.002 | 0.112 ± 0.006 | 3.038 ± 0.007 | 2.452 ± 0.051 | |
| MMM [36] | 0.504 ± 0.003 | 0.696 ± 0.003 | 0.794 ± 0.002 | 0.080 ± 0.003 | 2.998 ± 0.007 | 1.164 ± 0.041 | |
| T2M-GPT [60] | 0.491 ± 0.003 | 0.680 ± 0.003 | 0.775 ± 0.002 | 0.116 ± 0.004 | 3.118 ± 0.011 | 1.856 ± 0.011 | |
| + DisCoRD (Ours) | 0.476 ± 0.008 | 0.663 ± 0.006 | 0.760 ± 0.007 | 0.095 ± 0.011 | 3.121 ± 0.009 | 1.831 ± 0.048 | |
| KIT- ML | MDM [45] | - | - | 0.396 ± 0.004 | 0.497 ± 0.021 | 9.191 ± 0.022 | 1.907 ± 0.214 |
| MLD [6] | 0.390 ± 0.008 | 0.609 ± 0.008 | 0.734 ± 0.007 | 0.404 ± 0.027 | 3.204 ± 0.027 | 2.192 ± 0.071 | |
| MotionDiffuse [61] | 0.417 ± 0.004 | 0.621 ± 0.004 | 0.739 ± 0.004 | 1.954 ± 0.062 | 2.958 ± 0.005 | 0.730 ± 0.013 | |
| ReMoDiffuse [62] | 0.427 ± 0.014 | 0.641 ± 0.004 | 0.765 ± 0.055 | 0.155 ± 0.006 | 2.814 ± 0.012 | 1.239 ± 0.028 | |
| Fg-T2M [51] | 0.418 ± 0.005 | 0.626 ± 0.004 | 0.745 ± 0.004 | 0.571 ± 0.047 | 3.114 ± 0.015 | 1.019 ± 0.029 | |
| M2DM [18] | 0.416 ± 0.004 | 0.628 ± 0.004 | 0.743 ± 0.004 | 0.515 ± 0.029 | 3.015 ± 0.017 | 3.325 ± 0.037 | |
| M2D2M [7] | - | - | 0.753 ± 0.006 | 0.378 ± 0.023 | 3.012 ± 0.021 | 2.061 ± 0.067 | |
| MotionGPT [63] | 0.340 ± 0.002 | 0.570 ± 0.003 | 0.660 ± 0.004 | 0.868 ± 0.032 | 3.721 ± 0.018 | 2.296 ± 0.022 | |
| MotionLLM [54] | 0.409 ± 0.006 | 0.624 ± 0.007 | 0.750 ± 0.005 | 0.781 ± 0.026 | 2.982 ± 0.022 | - | |
| MotionGPT-2 [52] | 0.427 ± 0.003 | 0.627 ± 0.002 | 0.764 ± 0.003 | 0.614 ± 0.005 | 3.164 ± 0.013 | 2.357 ± 0.022 | |
| + DisCoRD (Ours) | 0.434 ± 0.007 | 0.657 ± 0.005 | 0.781 ± 0.005 | 0.204 ± 0.011 | 2.779 ± 0.022 | 1.928 ± 0.059 |
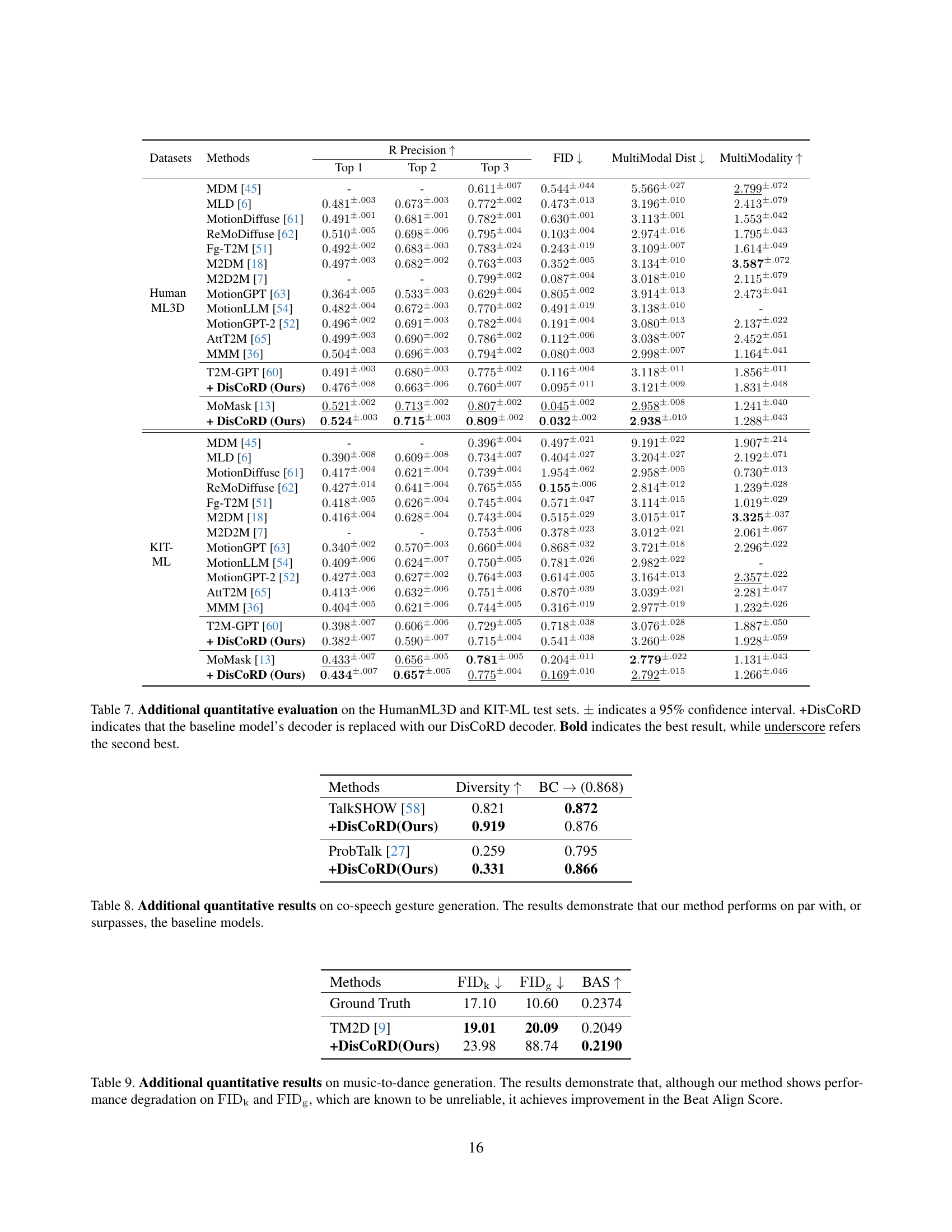
🔼 Table 7 presents a detailed quantitative comparison of different methods for text-to-motion generation on the HumanML3D and KIT-ML datasets. The metrics used include Fréchet Inception Distance (FID), which measures the realism of generated motions; R-Precision (Top 1, Top 2, Top 3), which evaluates the accuracy of retrieving the correct motion given a text description; MultiModal Distance (MM-Dist), which assesses how well the generated motions align with their textual descriptions; and MultiModality, which measures the diversity of generated motions. The table includes results for several baseline methods and then shows the improved performance achieved when replacing the baseline decoder with the DisCoRD decoder. The plus-or-minus values (±) indicate the 95% confidence interval around the reported metrics, reflecting the uncertainty in the measurements. Bold font highlights the best performance for each metric, while underlined font indicates the second-best performance.
read the caption
Table 7: Additional quantitative evaluation on the HumanML3D and KIT-ML test sets. ±plus-or-minus\pm± indicates a 95% confidence interval. +DisCoRD indicates that the baseline model’s decoder is replaced with our DisCoRD decoder. Bold indicates the best result, while underscore refers the second best.
| Methods | Diversity ↑ | BC → |
|---|---|---|
| TalkSHOW [58] | 0.821 | 0.872 |
| +DisCoRD(Ours) | 0.919 | 0.876 |
| ProbTalk [27] | 0.259 | 0.795 |
| +DisCoRD(Ours) | 0.331 | 0.866 |
🔼 Table 8 presents a quantitative comparison of DisCoRD against several state-of-the-art methods for co-speech gesture generation. The metrics used assess both the accuracy of the generated gestures in reflecting the accompanying speech (faithfulness) and the naturalness of the generated movements. The results show that DisCoRD either matches or exceeds the performance of existing methods across multiple evaluation metrics, indicating its effectiveness and robustness in this specific application.
read the caption
Table 8: Additional quantitative results on co-speech gesture generation. The results demonstrate that our method performs on par with, or surpasses, the baseline models.
| Methods | FIDk↓ | FIDg↓ | BAS ↑ |
|---|---|---|---|
| Ground Truth | 17.10 | 10.60 | 0.2374 |
| TM2D [9] | 19.01 | 20.09 | 0.2049 |
| +DisCoRD(Ours) | 23.98 | 88.74 | 0.2190 |
🔼 Table 9 presents a quantitative evaluation of music-to-dance generation performance. It compares the proposed DisCoRD method against a baseline. The metrics used are FIDk (kinetic features), FIDg (geometric features), and Beat Align Score (BAS). While FIDk and FIDg are known to be unreliable, DisCoRD shows an improvement in the BAS, indicating better synchronization between the generated dance and the music. This suggests that although some aspects of visual fidelity may not show significant improvement, the method still improves the overall alignment of the motion to the music.
read the caption
Table 9: Additional quantitative results on music-to-dance generation. The results demonstrate that, although our method shows performance degradation on FIDksubscriptFIDk\mathrm{FID_{k}}roman_FID start_POSTSUBSCRIPT roman_k end_POSTSUBSCRIPT and FIDgsubscriptFIDg\mathrm{FID_{g}}roman_FID start_POSTSUBSCRIPT roman_g end_POSTSUBSCRIPT, which are known to be unreliable, it achieves improvement in the Beat Align Score.
Full paper#