↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current AI inference frameworks struggle with the performance of Large Language Models (LLMs) on increasingly popular hybrid CPUs due to imbalanced hardware capabilities across different CPU cores. This paper tackles this issue.
The researchers propose a novel dynamic parallel method that optimizes workload distribution among CPU cores before parallel processing begins. This intelligent task scheduling considers each core’s performance characteristics, maximizing efficiency. They integrated this method into Neural Speed, resulting in a significant performance improvement, achieving more than 90% of memory bandwidth utilization on two Intel CPUs during 4-bit LLM inference. This shows a significant improvement over traditional methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel dynamic parallel method that significantly improves the performance of large language model (LLM) inference on hybrid CPUs. This addresses a critical limitation of current AI inference frameworks, which often overlook the imbalanced hardware capabilities of these increasingly common processors. The research opens avenues for optimizing LLM inference on diverse hardware platforms and contributes to the broader goal of making AI more efficient and accessible.
Visual Insights#

🔼 This figure illustrates the dynamic LLM inference process using a hybrid CPU. The process begins with the CPU runtime recording and managing CPU status, including execution times for each thread. A thread scheduler then uses this information to dynamically divide kernel tasks into subtasks based on each core’s performance. The performance of each core is constantly monitored and updated, allowing for optimal task assignment to maximize inference performance. The dynamic adjustment of workloads ensures efficient utilization of the hybrid CPU’s resources, overcoming limitations imposed by traditional static task allocation methods.
read the caption
Figure 1: The dynamic LLM inference process
In-depth insights#
Hybrid CPU Inference#
Hybrid CPU architectures, combining high-performance and energy-efficient cores, present both opportunities and challenges for AI inference. The inherent imbalance in core capabilities necessitates sophisticated optimization strategies to fully leverage the hardware. The paper highlights the limitations of traditional parallel methods, which often leave high-performance cores idle while waiting for slower cores to complete their tasks. A dynamic parallel method is proposed as a solution, intelligently distributing workloads based on real-time core performance and dynamically adjusting to changing conditions. This approach aims to maximize utilization of both core types, leading to significant performance gains. Key to this approach is accurate, real-time performance monitoring and a flexible task scheduler. The results demonstrate substantial improvements in latency and memory bandwidth utilization, showcasing the effectiveness of the dynamic approach in optimizing hybrid CPU inference for large language models. Future work should focus on extending this approach to other AI model types and integrating it with other accelerator units commonly found in modern systems for even greater efficiency.
Dynamic Parallelism#
Dynamic parallelism, as explored in this research, offers a compelling approach to optimize LLM inference on hybrid CPU architectures. The core idea revolves around adaptively balancing workloads across heterogeneous cores, unlike static partitioning methods. This dynamic adjustment is crucial because hybrid CPUs often exhibit significant performance variations between different core types and clock speeds. By continuously monitoring core performance and re-distributing tasks accordingly, the system effectively avoids performance bottlenecks caused by slower cores holding up faster ones. Real-time performance ratio tracking is essential; the algorithm dynamically updates these ratios, factoring in instruction set architecture (ISA) variations and noise to maintain accuracy. This adaptive scheduling, combined with intelligent kernel partitioning, promises significant improvements in overall LLM inference speed and memory bandwidth utilization. The results demonstrate substantial latency reductions in both prefill and decode phases, highlighting the effectiveness of this dynamic approach compared to traditional static parallel methods. The key to success lies in the continuous feedback loop that ensures tasks are efficiently distributed to maximize the potential of the hybrid CPU’s diverse computational resources. This strategy is particularly beneficial for complex LLMs where compute-intensive tasks can benefit greatly from flexible parallel processing.
LLM Performance#
The research paper analyzes Large Language Model (LLM) performance on hybrid CPUs, revealing significant performance limitations due to imbalanced hardware capabilities. Current AI inference frameworks fail to adequately address this imbalance, leading to suboptimal performance. The core issue stems from the uneven distribution of workloads across CPU cores with varying microarchitectures or clock speeds. The paper introduces a dynamic parallel method to mitigate these problems by dynamically balancing workloads before parallel processing begins, achieving over 90% memory bandwidth utilization. This is a substantial improvement over traditional parallel methods. Key performance metrics include latency (prefill and decode phases) and memory bandwidth, with the new method demonstrating improvements across both, especially in computationally intensive tasks. The dynamic approach enables real-time adaptation to fluctuating core performance and efficient utilization of hybrid CPU architectures. The results highlight the importance of considering heterogeneous hardware characteristics for optimal LLM inference performance on modern CPUs. Future work focuses on extending this dynamic optimization to other LLM kernels and integrating with other compute units (GPU, NPU) for further performance gains.
Workload Balancing#
Workload balancing in the context of hybrid CPU AI inference is crucial due to the inherent performance heterogeneity of different core types. The paper highlights the limitations of traditional parallel methods, where fixed workload partitions lead to inefficient utilization of high-performance cores while low-performance cores become bottlenecks. A dynamic approach is proposed, adjusting workload assignments based on the runtime performance of each core. This dynamic adaptation is key, ensuring that tasks are distributed to maximize overall efficiency. The core performance is monitored continuously and is used to dynamically adjust the workload distribution for each kernel. This approach surpasses static partitioning schemes by optimally utilizing the available computational resources. This runtime monitoring and feedback loop are the strengths of the proposed dynamic parallel method, ultimately leading to significant performance improvements in LLM inference. The integration of this dynamic method with existing frameworks such as Neural Speed showcases its practical applicability and effectiveness in real-world scenarios.
Future AIPC Optimizations#
Future AIPC (AI PC) optimizations should prioritize seamless integration of diverse compute units (CPU, GPU, NPU). This necessitates advanced scheduling algorithms that dynamically allocate tasks based on real-time performance profiles of each unit, overcoming the inherent imbalances in capabilities among these heterogeneous components. Efficient data movement and memory management are critical; minimizing data transfer overhead between CPU, GPU, and NPU is paramount for optimal performance. Research into novel quantization techniques and their impact on different hardware architectures is also vital. Model-level optimizations should focus on algorithmic adaptations and partitioning to further improve parallelism and reduce latency. Exploring hardware-software co-design approaches, where architectural choices are informed by the capabilities of the inference algorithms, will be crucial for pushing the boundaries of AIPC performance. Finally, robust benchmarking and standardized metrics are essential to objectively evaluate the effectiveness of these optimizations across diverse hardware platforms and AI model workloads.
More visual insights#
More on figures

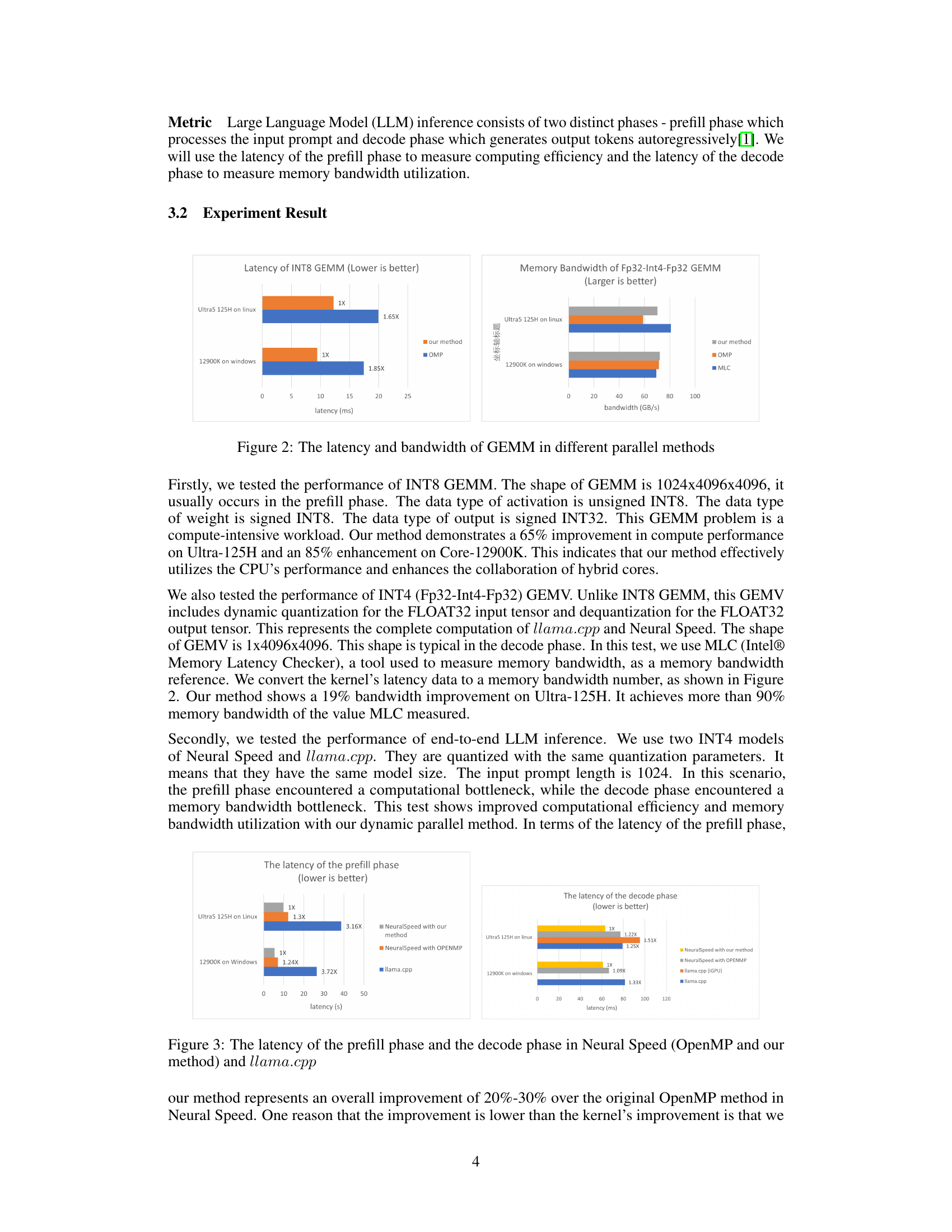
🔼 This figure compares the latency and memory bandwidth of INT8 GEMM (General Matrix Multiply) and INT4 GEMV (General Matrix-Vector Multiply) operations across three different parallel methods: the authors’ dynamic parallel method, OpenMP, and MLC (Intel Memory Latency Checker). The comparison is performed on two different Intel hybrid CPUs: Core i9-12900K and Intel Ultra-125H. The results highlight the performance improvements achieved by the authors’ dynamic parallel method in terms of reduced latency and increased memory bandwidth utilization.
read the caption
Figure 2: The latency and bandwidth of GEMM in different parallel methods

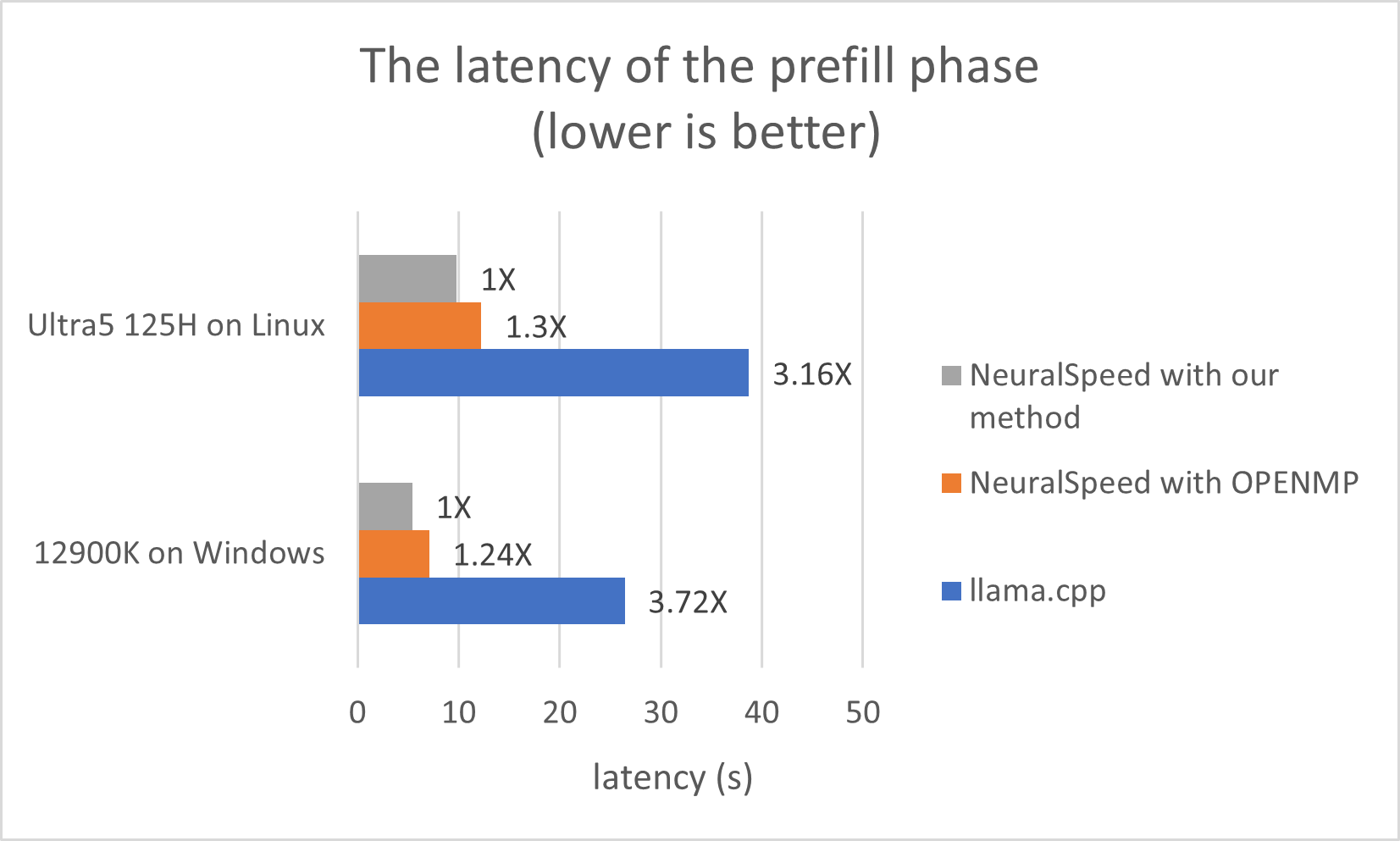
🔼 Figure 3 presents a comparison of the latency (time taken) for the prefill and decode phases of Large Language Model (LLM) inference across three different methods: Neural Speed using OpenMP (a standard parallel programming model), Neural Speed enhanced with the authors’ new dynamic parallel method, and llama.cpp. The prefill phase processes the input prompt, while the decode phase generates the output tokens. The figure shows that the dynamic parallel method significantly reduces latency in both phases compared to the other two methods, particularly in the prefill phase where it exhibits a much more substantial improvement. This highlights the efficiency gains achieved by the proposed dynamic workload balancing technique.
read the caption
Figure 3: The latency of the prefill phase and the decode phase in Neural Speed (OpenMP and our method) and llama.cppformulae-sequence𝑙𝑙𝑎𝑚𝑎𝑐𝑝𝑝llama.cppitalic_l italic_l italic_a italic_m italic_a . italic_c italic_p italic_p
🔼 This figure illustrates the dynamic changes in the performance ratio of a single P-core (performance core) within a hybrid CPU during the two main phases of LLM inference: the prefill phase and the decode phase. The performance ratio reflects the relative speed at which this specific core can complete its tasks. The graph shows that the ratio fluctuates, especially during the transition between phases, indicating a change in computational bottlenecks. The initial high ratio settles to a more stable range, and then a second change occurs at the boundary between the prefill and decode phases due to different computational demands of each phase. These variations highlight the need for dynamic workload balancing in hybrid CPUs and suggest the effectiveness of the proposed dynamic parallel approach in adapting to fluctuating performance.
read the caption
Figure 4: The performance ratio of one P-core in the prefill phase and the decode phase
Full paper#