↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
The ever-growing volume of online news necessitates efficient topic classification across various languages. However, creating robust multilingual classifiers is challenging due to the scarcity of manually-annotated training data, which is expensive and labor-intensive to produce. Existing datasets often suffer from inconsistencies or use outdated topic schemata. This paper tackles these issues by proposing a novel methodology.
This study introduces a teacher-student framework leveraging large language models (LLMs). A GPT model automatically annotates news articles in several languages, creating a substantial training dataset. Smaller, more computationally efficient BERT-like models are then fine-tuned on this data. The research thoroughly evaluates the framework’s performance, comparing the teacher LLM’s annotation quality to human annotators and demonstrating high performance even with relatively small training datasets. The best-performing multilingual classifier is made publicly available, along with the generated dataset, advancing the field significantly.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multilingual NLP and text classification. It presents a novel teacher-student framework that efficiently addresses the scarcity of annotated data, a major hurdle in many languages. The open-source release of the model and dataset greatly benefits the community, enabling further research and application in diverse news-related tasks.
Visual Insights#
| Micro-F1 | Macro-F1 | |
|---|---|---|
| Hr | 0.714 ± 0.002 | 0.721 ± 0.001 |
| Ca | 0.703 ± 0.002 | 0.702 ± 0.001 |
| Sl | 0.741 ± 0.000 | 0.748 ± 0.001 |
| El | 0.730 ± 0.009 | 0.738 ± 0.009 |
| Entire Test Set | 0.722 ± 0.002 | 0.731 ± 0.003 |
🔼 This table presents the performance of the GPT-40 model on a human-labeled test set, broken down by language. The evaluation metrics used are micro-F1 and macro-F1 scores. The results are averages across three prediction iterations, with standard deviations provided to show variability.
read the caption
TABLE I: GPT-4o performance on each language in the human-labeled test set in micro-F1 and macro-F1 scores, averaged across three prediction iterations, with standard deviation included.
In-depth insights#
LLM Teacher-Student#
The ‘LLM Teacher-Student’ framework presents a novel approach to multilingual text classification, particularly valuable where manually annotated data is scarce. A large language model (LLM) acts as the ’teacher,’ automatically annotating a substantial corpus of news articles. This bypasses the expensive and time-consuming manual annotation process. The automatically generated dataset then trains a smaller, computationally efficient ‘student’ model (e.g., XLM-RoBERTa). This two-stage process is effective because the teacher LLM leverages its zero-shot capabilities for high-quality annotation, while the student model addresses real-world scalability needs. The teacher’s performance is validated against human annotations, demonstrating comparable accuracy. The study examines the impact of varying training dataset sizes on the student model’s performance, revealing high accuracy even with a relatively small number of training instances. This demonstrates the practical utility of this method for various languages, showcasing strong zero-shot cross-lingual capabilities. The framework’s success hinges on the ability of the teacher LLM to reliably annotate data, thereby generating high-quality training data for the student model. The resulting multilingual classifier is publicly available, contributing significantly to the field.
Zero-Shot Annotation#
Zero-shot annotation, a technique leveraging large language models (LLMs) to label data without prior training, offers a promising approach to overcome data scarcity challenges in NLP. By directly applying pre-trained LLMs to new, unseen data, we can bypass the labor-intensive process of manual annotation. GPT models have shown remarkable potential in this area, achieving comparable performance to human annotators for specific tasks, as demonstrated in the research paper. However, it is crucial to acknowledge potential limitations such as bias inherent in the LLM, and the necessity for careful prompt engineering to guide the model toward desired outputs. The accuracy also depends heavily on the complexity of the task, where simpler, more clearly defined categories will likely yield more reliable results than highly ambiguous ones. Further research is needed to fully understand the reliability and generalizability of zero-shot annotation across diverse datasets and domains, and to explore how to mitigate biases and improve the overall quality and consistency of automatically generated annotations.
Multilingual Evaluation#
A robust multilingual evaluation is crucial for assessing the generalizability and effectiveness of a cross-lingual model. The selection of languages should consider linguistic diversity, encompassing languages from different families and varying levels of relatedness. Data balance across languages is essential to avoid bias and ensure fair comparison. Evaluation metrics beyond simple accuracy, such as F1-score, precision, recall, and macro/micro averages, should be employed to provide a comprehensive picture of performance across all languages and across different label types. Moreover, error analysis is needed to understand specific weaknesses in the model’s performance with certain languages, potentially highlighting areas for improvement in training or model architecture. Zero-shot capabilities, the ability to perform well on unseen languages, should be carefully examined, as this is a key indicator of a truly multilingual model’s ability to generalize beyond its training data. Finally, comparisons to existing state-of-the-art multilingual models provide valuable context for the model’s overall performance. A comprehensive multilingual evaluation should address these points to ensure the proposed model’s true capabilities are thoroughly assessed.
Data Size Impact#
The research explores the impact of training data size on the performance of a multilingual news topic classification model. The findings reveal a gradual performance improvement as the training data size increases, ultimately plateauing after 15,000 instances. Even with minimal data (1,000 instances), the model demonstrates substantial performance, indicating the effectiveness of the teacher-student framework and the quality of the automatically generated training data. This suggests that achieving high accuracy may not necessitate enormous datasets, offering practical implications for resource-constrained settings. The study highlights a balance between data size and performance, demonstrating that carefully curated, smaller datasets can yield excellent results, reducing computational costs and time demands. The plateau effect also implies a point of diminishing returns, suggesting optimization of resource allocation for training data is possible.
Future Directions#
Future research could explore expanding the methodology to encompass a wider array of languages, potentially leveraging the power of multilingual LLMs for even greater scalability and robustness. Investigating hierarchical topic classification using lower levels of the IPTC Media Topic schema would enhance the granularity and precision of the model, addressing current limitations in distinguishing between closely related topics. Addressing class imbalance is crucial, as some topics are significantly underrepresented in news datasets. This could involve techniques like data augmentation or cost-sensitive learning. Furthermore, comparing the teacher-student framework with alternative approaches, like purely zero-shot or fully supervised methods would provide valuable insights into its effectiveness. Finally, exploring the impact of different GPT models and prompts on annotation quality would refine the data generation process. This comprehensive approach would lead to more accurate and versatile news topic classification models for various applications.
More visual insights#
More on tables
| Annotators | Krippendorff’s alpha |
|---|---|
| 1st ann & 2nd ann | 0.728 |
| 1st ann & GPT-4o | 0.693 |
| 2nd ann & GPT-4o | 0.752 |
🔼 This table presents the pairwise Krippendorff’s alpha values, a measure of inter-rater reliability, for the agreement between different annotators on the news topic classification task. It compares the agreement between two human annotators, the agreement between the first human annotator and the GPT-40 model, and the agreement between the second human annotator and the GPT-40 model.
read the caption
TABLE II: Pair-wise inter-annotator agreement in terms of the nominal Krippendorff’s alpha.
| Annotator | Krippendorff’s alpha |
|---|---|
| GPT-4o | 0.934 |
| Human annotator (1st ann) | 0.796 |
🔼 This table presents the intra-annotator agreement scores, calculated using Krippendorff’s alpha, for both a human annotator and the GPT-40 language model. Intra-annotator agreement measures the consistency of annotations provided by the same annotator on two separate occasions. The table shows the Krippendorff’s alpha coefficient for the human annotator’s two annotation rounds and the GPT-40 model’s two annotation rounds. A higher Krippendorff’s alpha indicates greater consistency in annotations.
read the caption
TABLE III: Intra-annotator agreement in terms of the nominal Krippendorff’s alpha for the human annotator (1st annotator) and the LLM teacher model.
| Hr Test | Ca Test | Sl Test | El Test | Entire Test Set | |
|---|---|---|---|---|---|
| Hr Model | 0.701 ± 0.017 | 0.672 ± 0.005 | 0.733 ± 0.014 | 0.739 ± 0.011 | 0.716 ± 0.009 |
| Ca Model | 0.706 ± 0.012 | 0.671 ± 0.008 | 0.728 ± 0.005 | 0.715 ± 0.014 | 0.710 ± 0.007 |
| Sl Model | 0.711 ± 0.007 | 0.660 ± 0.016 | 0.736 ± 0.014 | 0.721 ± 0.013 | 0.713 ± 0.005 |
| El Model | 0.674 ± 0.004 | 0.662 ± 0.012 | 0.716 ± 0.011 | 0.706 ± 0.013 | 0.695 ± 0.006 |
| Multilingual | 0.707 ± 0.011 | 0.656 ± 0.024 | 0.741 ± 0.007 | 0.729 ± 0.004 | 0.714 ± 0.009 |
| GPT-4o | 0.721 ± 0.001 | 0.702 ± 0.001 | 0.748 ± 0.001 | 0.738 ± 0.009 | 0.731 ± 0.003 |
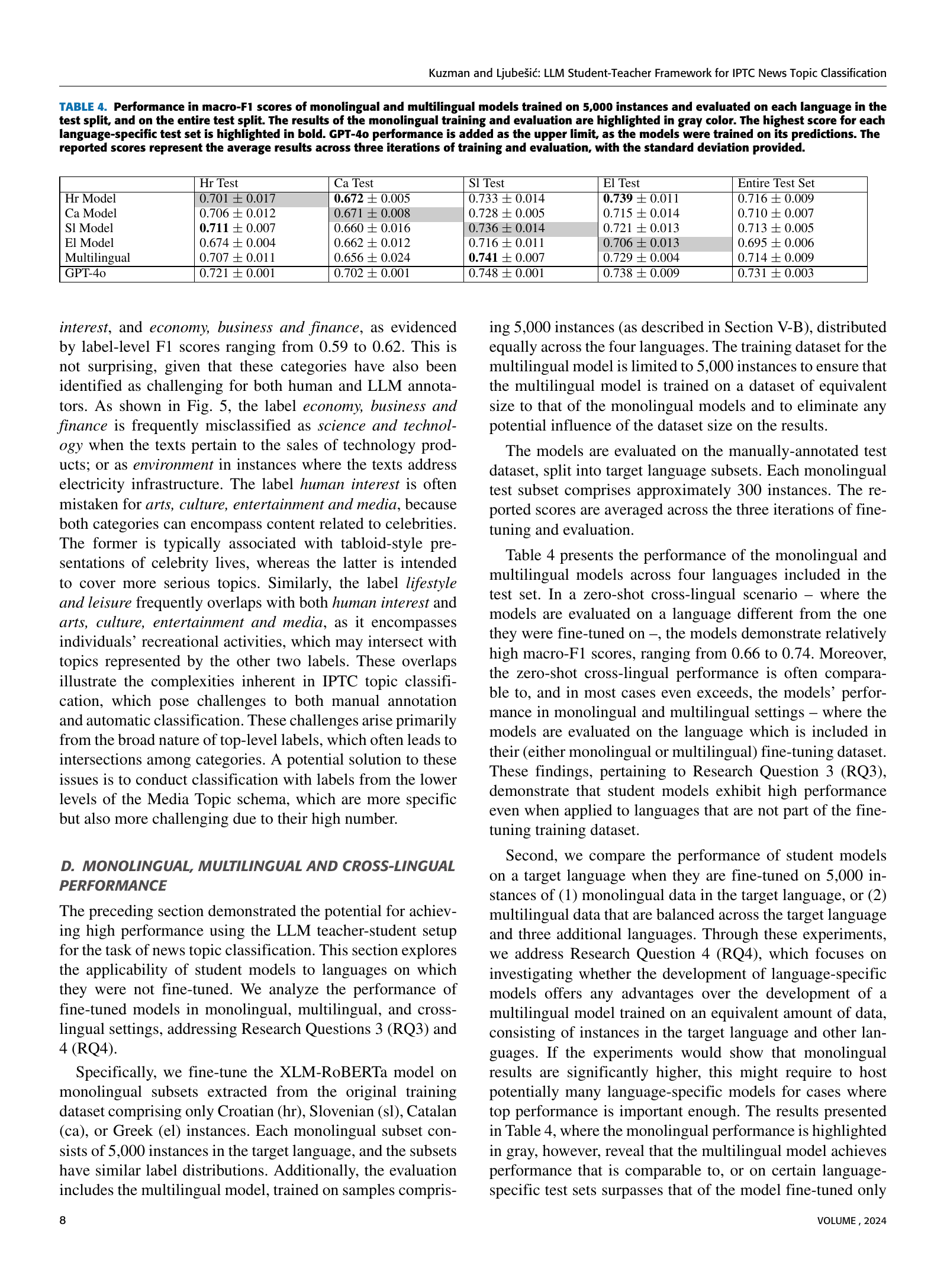
🔼 This table presents the macro-F1 scores achieved by monolingual and multilingual XLM-RoBERTa models trained on 5,000 instances of data. The models were evaluated on four different languages (Croatian, Catalan, Slovenian, Greek) individually and on the entire combined test set. Monolingual model results are shaded gray to distinguish them from the multilingual model. The highest score for each language is bolded. The zero-shot GPT-40 performance is also included as a baseline, representing the upper limit of achievable performance since the GPT-40 model’s predictions are used to create the training data. Standard deviations are provided to reflect the variability across three training/evaluation iterations.
read the caption
TABLE IV: Performance in macro-F1 scores of monolingual and multilingual models trained on 5,000 instances and evaluated on each language in the test split, and on the entire test split. The results of the monolingual training and evaluation are highlighted in gray color. The highest score for each language-specific test set is highlighted in bold. GPT-4o performance is added as the upper limit, as the models were trained on its predictions. The reported scores represent the average results across three iterations of training and evaluation, with the standard deviation provided.
| Label | Description |
|---|---|
| arts, culture, entertainment and media | News about cinema, dance, fashion, hairstyle, jewellery, festivals, literature, music, theatre, TV shows, painting, photography, woodworking, art exhibitions, libraries and museums, language, cultural heritage, news media, radio and television, social media, influencers, and disinformation. |
| conflict, war and peace | News about terrorism, wars, wars victims, cyber warfare, civil unrest (demonstrations, riots, rebellions), peace talks and other peace activities. |
| crime, law and justice | News about committed crime and illegal activities, the system of courts, law and law enforcement (e.g., judges, lawyers, trials, punishments of offenders). |
| disaster, accident and emergency incident | Man-made or natural events resulting in injuries, death or damage, e.g., explosions, transport accidents, famine, drowning, natural disasters, emergency planning and response. |
| economy, business and finance | News about companies, products and services, any kind of industries, national economy, international trading, banks, (crypto)currency, business and trade societies, economic trends and indicators (inflation, employment statistics, GDP, mortgages, …), international economic institutions, utilities (electricity, heating, waste management, water supply). |
| education | All aspects of furthering knowledge, formally or informally, including news about schools, curricula, grading, remote learning, teachers and students. |
| environment | News about climate change, energy saving, sustainability, pollution, population growth, natural resources, forests, mountains, bodies of water, ecosystem, animals, flowers and plants. |
| health | News about diseases, injuries, mental health problems, health treatments, diets, vaccines, drugs, government health care, hospitals, medical staff, health insurance. |
| human interest | News about life and behaviour of royalty and celebrities, news about obtaining awards, ceremonies (graduation, wedding, funeral, celebration of launching something), birthdays and anniversaries, and news about silly or stupid human errors. |
| labour | News about employment, employment legislation, employees and employers, commuting, parental leave, volunteering, wages, social security, labour market, retirement, unemployment, unions. |
| lifestyle and leisure | News about hobbies, clubs and societies, games, lottery, enthusiasm about food or drinks, car/motorcycle lovers, public holidays, leisure venues (amusement parks, cafes, bars, restaurants, etc.), exercise and fitness, outdoor recreational activities (e.g., fishing, hunting), travel and tourism, mental well-being, parties, maintaining and decorating house and garden. |
| politics | News about local, regional, national and international exercise of power, including news about election, fundamental rights, government, non-governmental organisations, political crises, non-violent international relations, public employees, government policies. |
| religion | News about religions, cults, religious conflicts, relations between religion and government, churches, religious holidays and festivals, religious leaders and rituals, and religious texts. |
| science and technology | News about natural sciences and social sciences, mathematics, technology and engineering, scientific institutions, scientific research, scientific publications and innovation. |
| society | News about social interactions (e.g., networking), demographic analyses, population census, discrimination, efforts for inclusion and equity, emigration and immigration, communities of people and minorities (LGBTQ, older people, children, indigenous people, etc.), homelessness, poverty, societal problems (addictions, bullying), ethical issues (suicide, euthanasia, sexual behaviour) and social services and charity, relationships (dating, divorce, marriage), family (family planning, adoption, abortion, contraception, pregnancy, parenting). |
| sport | News about sports that can be executed in competitions, e.g., basketball, football, swimming, athletics, chess, dog racing, diving, golf, gymnastics, martial arts, climbing, etc.; sport achievements, sport events, sport organisation, sport venues (stadiums, gymnasiums, …), referees, coaches, sport clubs, drug use in sport. |
| weather | News about weather forecasts, weather phenomena and weather warning. |
🔼 This table lists the 17 top-level IPTC Media Topic labels and their descriptions as defined and used by the authors in their study. Each label is provided with a detailed explanation to clarify its meaning and scope for accurate and consistent annotation. This is especially important as the study uses automatic annotation methods that rely on the preciseness of the definitions.
read the caption
TABLE V: IPTC Media Topic labels and their descriptions, which have been constructed by the authors of this paper.
| Training Data Size | Epoch Number |
|---|---|
| 20,000 | 3 |
| 15,000 | 5 |
| 10,000 | 9 |
| 5,000 | 10 |
| 2,500 | 22 |
| 1,000 | 24 |
🔼 This table shows the optimal number of training epochs for the XLM-RoBERTa model when fine-tuning it for news topic classification using different amounts of training data. The number of epochs is adjusted based on the size of the training dataset to achieve optimal performance. Smaller datasets require more epochs for convergence.
read the caption
TABLE VI: Number of epochs used for fine-tuning the XLM-RoBERTa model, depending on the size of the training data (number of instances).
Full paper#