↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) show performance disparities across languages, hindering their deployment in many regions. This is largely due to a lack of high-quality evaluation resources in low-resource languages and the neglect of regional and cultural nuances in benchmark creation. Current benchmarks often translate from English, ignoring cultural contexts.
To address this, the researchers created INCLUDE, a multilingual benchmark comprising 197,243 question-answer pairs from diverse exams across 44 languages. INCLUDE tests LLMs’ knowledge and reasoning abilities in various regional settings, using questions from educational and professional exams, thus evaluating performance in their intended environments. The release of INCLUDE provides a crucial resource for researchers and developers in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical gap in multilingual LLM evaluation. Existing benchmarks often lack high-quality resources and ignore regional knowledge. This work provides a valuable, large-scale, multilingual benchmark (INCLUDE) to evaluate LLMs’ performance in real-world language environments, significantly advancing research in this area and fostering equitable AI development.
Visual Insights#

🔼 Figure 1(a) illustrates the importance of incorporating cultural and regional knowledge into multilingual benchmarks for evaluating large language models (LLMs). It highlights how the same question, when posed in different languages, can require different contextual understandings due to variations in regional laws, cultural norms, or historical contexts. This highlights the need for more representative and nuanced evaluation datasets. Figure 1(b) shows the structure of the INCLUDE benchmark, which addresses these issues by compiling questions from a wide range of academic exams, professional certification tests, and occupational licensing examinations. This diverse dataset covers 44 languages, ensuring that regional and cultural knowledge are accurately reflected in the evaluation of multilingual LLMs.
read the caption
Figure 1: Overview of Include. (a) Motivation: Multilingual benchmarks must reflect the cultural and regional knowledge of the language environments in which they would used. (b) Include is a multilingual benchmark compiled from academic, professional, and occupational license examinations reflecting regional and cultural knowledge in 44 languages.
| Model | Include-lite | Include-base | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| # | Langs | IL Prompt | Eng. Prompt | Reg. + IL Prompt | Reg. + Eng. Prompt | IL Prompt | Eng. Prompt | Reg. + IL Prompt | Reg. + Eng. Prompt | |
| — | — | — | — | — | — | — | — | — | — | — |
| GPT-4o | - | |||||||||
| - 5-shot | 77.1 | 76.2 | 76.3 | 76.3 | 77.3 | 76.3 | 76.2 | 76.2 | ||
| - Zero-shot CoT | 78.2 | 78.4 | 77.7 | 77.8 | 79.0 | 78.9 | 77.6 | 78.5 | ||
| Llama-3.1-70B-Inst. | - | |||||||||
| - 5-shot | 70.5 | 70.4 | 70.6 | 70.6 | 70.6 | 70.7 | 70.6 | 70.6 | ||
| - Zero-shot CoT | 60.6 | 55.3 | 60.2 | 55.4 | 60.6 | 56.0 | 60.6 | 55.6 | ||
| Aya-expanse-32B | 23 | |||||||||
| - 5-shot | 52.6 | 57.2 | 49.0 | 60.0 | 52.4 | 56.6 | 49.7 | 60.0 | ||
| - Zero-shot CoT | 50.6 | 57.1 | 52.5 | 58.0 | 51.4 | 57.7 | 52.9 | 57.8 | ||
| Qwen2.5-14B | 22 | |||||||||
| - 5-shot | 60.9 | 61.3 | 60.9 | 60.8 | 61.4 | 61.7 | 61.1 | 61.0 | ||
| - Zero-shot CoT | 46.8 | 50.7 | 46.5 | 51.4 | 47.3 | 51.0 | 47.1 | 51.6 | ||
| []cdashline1-10Aya-expanse-8B | 23 | 37.6 | 46.3 | 38.1 | 48.0 | 37.2 | 46.0 | 37.9 | 47.8 | |
| Mistral-7B (v0.3) | - | 44.0 | 45.0 | 44.0 | 45.2 | 43.3 | 44.9 | 43.8 | 45.0 | |
| Mistral-7B-Inst. (v0.3) | - | 43.5 | 44.6 | 44.2 | 44.7 | 43.6 | 44.5 | 44.2 | 44.7 | |
| Gemma-7B | - | 54.4 | 54.9 | 54.3 | 54.9 | 54.5 | 54.9 | 54.2 | 54.7 | |
| Gemma-7B-Inst. | - | 39.2 | 40.2 | 38.7 | 39.7 | 38.7 | 39.7 | 38.1 | 39.2 | |
| Qwen2.5-7B | 22 | 53.4 | 54.8 | 53.3 | 54.2 | 54.1 | 55.2 | 54.0 | 54.5 | |
| Qwen2.5-7B-Inst. | 22 | 53.4 | 54.2 | 52.8 | 53.7 | 53.8 | 54.6 | 53.2 | 53.9 | |
| Llama-3.1-8B | - | 50.9 | 52.3 | 50.9 | 51.9 | 51.0 | 51.8 | 51.0 | 51.6 | |
| Llama-3.1-8B-Inst. | - | 53.4 | 54.8 | 52.7 | 53.4 | 53.4 | 54.6 | 53.0 | 54.4 |
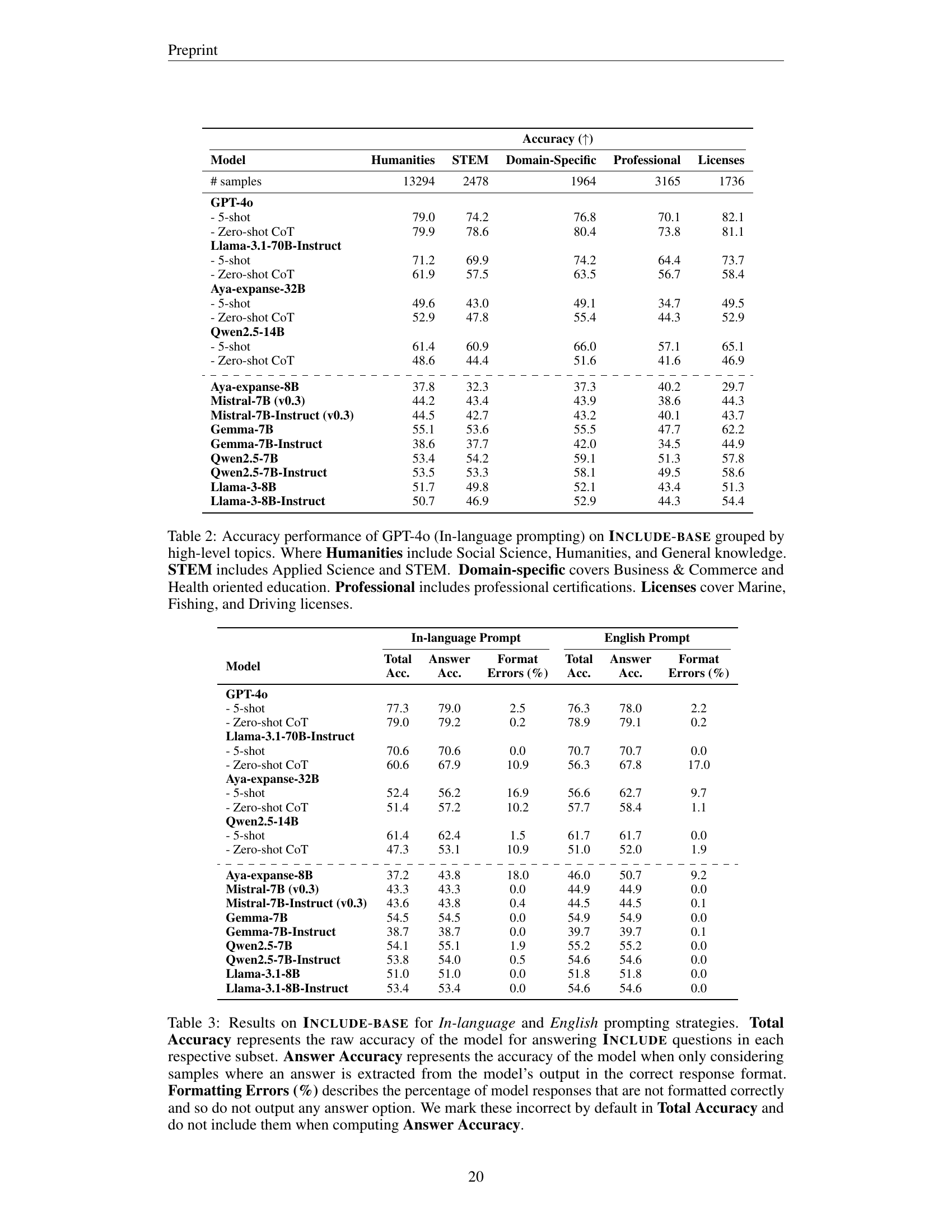
🔼 This table presents the results of evaluating various large language models (LLMs) on two subsets of the INCLUDE benchmark: INCLUDE-LITE and INCLUDE-BASE. The evaluation measures the models’ accuracy across 44 languages under four prompting conditions: in-language prompts (IL), English prompts (Eng.), in-language prompts with a regional prefix (Reg.+IL), and English prompts with a regional prefix (Reg.+Eng.). The table also indicates the number of languages each model explicitly reports having been pre-trained on.
read the caption
Table 1: Results on Include-lite and Include-base. In-language Prompt (IL) reports model accuracy when the prompt instructions are presented in the same language as the sample. English Prompt (Eng.) reports model accuracy when the prompt instructions are provided in English. In-language Regional Prompt (Reg. + IL) reports model accuracy when a regional prefix is added to the In-language Prompt. English Regional Prompt (Reg. + Eng.) reports model accuracy when a regional prefix is added to the English Prompt. # Langs reports the number of languages from Include publicly reported to be intentionally included in the pretraining data of each model.
In-depth insights#
Multilingual LLM Gaps#
The concept of “Multilingual LLM Gaps” highlights the significant disparities in performance between large language models (LLMs) across different languages. These gaps aren’t merely technical limitations; they reflect deep-seated biases and inequalities in the data used to train these models. The overrepresentation of high-resource languages like English creates a feedback loop: models perform well on English, leading to further development focused on it, while low-resource languages are neglected. This disparity exacerbates existing digital divides, hindering access to beneficial AI technologies for speakers of low-resource languages. Furthermore, the methods used to create multilingual benchmarks often rely on translation from high-resource languages, failing to capture the nuances of regional and cultural contexts. Addressing these gaps requires a multifaceted approach. This includes actively developing high-quality evaluation resources in diverse languages, employing data collection techniques that are more inclusive and representative, and designing more culturally sensitive benchmarks that account for regional knowledge. Only with concerted effort to mitigate these biases can we ensure fair and equitable access to the benefits of advanced LLMs for all.
INCLUDE Benchmark#
The INCLUDE benchmark is a significant contribution to multilingual language understanding evaluation. Its strength lies in its comprehensive nature, encompassing a large number of multiple-choice questions across 44 languages, derived from diverse sources including academic exams and professional certifications. This broad scope allows for a nuanced understanding of model performance, going beyond simple translation tasks and assessing proficiency in real-world language use. Furthermore, INCLUDE’s focus on regional knowledge is crucial, as it directly addresses the limitations of existing benchmarks that often lack cultural and contextual awareness. By including questions that require regional understanding, INCLUDE offers a more equitable and comprehensive evaluation framework that better reflects the diversity and challenges of real-world applications of multilingual LLMs. The benchmark’s impact is magnified by its public release, which will facilitate further research and development in this critical area. However, the reliance on existing benchmarks for a portion of the data, while acknowledging and accounting for dataset contamination, may necessitate further analysis to ensure complete independence and unbiased evaluation.
Regional Knowledge#
The concept of “Regional Knowledge” in the context of multilingual large language models (LLMs) is crucial. The paper highlights how current LLMs often struggle with questions requiring regional knowledge, showcasing a significant performance gap across different languages. This gap stems from the fact that existing multilingual benchmarks often translate resources from high-resource languages like English, ignoring the unique cultural and regional nuances of other environments. This underscores the importance of using locally sourced, high-quality evaluation resources to accurately measure LLM performance. The authors stress that benchmarks must reflect actual language usage scenarios to address the limitations of translating existing resources, which can lead to biases and inaccuracies. Creating evaluations based on regional contexts is essential for equitable and effective LLM deployment, reducing the digital divide and fostering a more inclusive development of AI tools.
Prompting Strategies#
Prompting strategies in large language model (LLM) evaluation are crucial for uncovering valuable insights into model capabilities and limitations. Effective prompting techniques can significantly influence the performance of LLMs across diverse tasks and languages. The choice of prompting methods (e.g., zero-shot, few-shot, chain-of-thought) directly impacts the model’s ability to generate accurate and coherent responses. In-language prompting, where instructions are provided in the native language of the task, often yields better results compared to using a common language like English, especially for tasks requiring regional or cultural knowledge. However, the use of a common language might help in scenarios with limited resources for specific languages. Investigating the impact of various prompting strategies on LLMs will reveal important information on how to develop and refine them. Further analysis might even explore the impact of incorporating regional contexts into the prompts to improve the performance on questions requiring such knowledge.
Future Directions#
Future research should prioritize expanding INCLUDE’s language coverage to encompass more under-resourced languages and dialects, thereby reducing evaluation biases. Improving data collection methodology is vital to ensure accurate representation of regional knowledge, perhaps by refining the exam selection process and incorporating more rigorous quality control measures. Investigating the impact of various prompting strategies on model performance across languages and regions is crucial to optimize evaluation methodologies. A deeper investigation into why specific model architectures or training paradigms perform better on certain languages than others is warranted. This includes exploring factors like the size and diversity of training data, and the inherent linguistic properties of the languages themselves. Finally, understanding how to better incorporate cultural and regional context into the models’ training data is a key challenge that requires focused investigation, potentially through the development of innovative data augmentation techniques.
More visual insights#
More on figures

🔼 Figure 2 shows the number of samples collected for each of the 15 scripts used in the INCLUDE benchmark. For each script, the figure displays the languages using that script, the total number of samples for that script, and the percentage of those samples that are from original, unpublished sources. This illustrates the diversity of languages and scripts included in the benchmark, as well as the proportion of novel data that was collected.
read the caption
Figure 2: Overview of the collected data grouped by script. We depict the languages associated with each script, the total samples in each script, and the percentage of the samples that were collected from new sources that have not been published by the community yet.
![]()
🔼 This figure displays the performance of three large language models (LLMs) across different languages, categorized based on their relationship to the models’ training data. The x-axis represents the accuracy of each model on various languages, while the y-axis represents the languages. Languages are grouped into three categories: ‘Trained on Language’ (languages explicitly included in the training data), ‘Trained on Script’ (languages sharing the same script as languages in the training data), and ‘Neither’ (languages not linguistically similar to those in the training data). The colored dotted lines show the average performance for each language category within each model, while the black dotted lines indicate the average performance across all languages that share a script.
read the caption
Figure 3: Performance of models stratified by language using in-language prompting. Results are grouped by whether the language was explicitly included in the pretraining dataset of the model (Trained on Language), whether a similar language with the same script was in the pretraining corpus (Trained on Script), or whether there was no linguistically similar language in the pretraining corpus (Neither). Color dotted lines represent average performance for each category for a particular model. Black dotted lines represent average performance across all script-aligned languages.
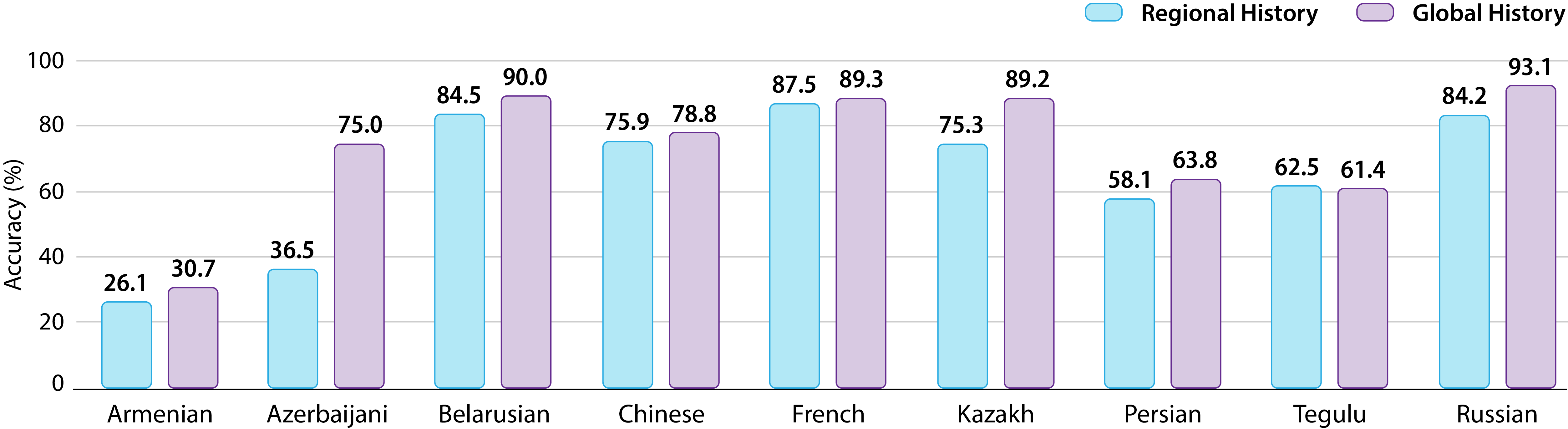
🔼 This figure displays the performance of the GPT-40 language model on history-related questions from the INCLUDE benchmark. The questions are categorized into two types: regional history (cultural knowledge specific to a region) and global history (general historical knowledge). The results show that GPT-40 performs better on global history questions than on regional history questions, across most languages. This suggests that the model may struggle with questions requiring nuanced cultural knowledge specific to particular regions. The dataset included a total of 11,148 questions in this analysis.
read the caption
Figure 4: GPT-4o performance (In-language Prompt) on regional history exams (cultural) and global history exams from that region (region-implicit) based on a total of 11,148 questions from Include. In each language (except Telugu), models perform better on the global history exam than the regional history exam.

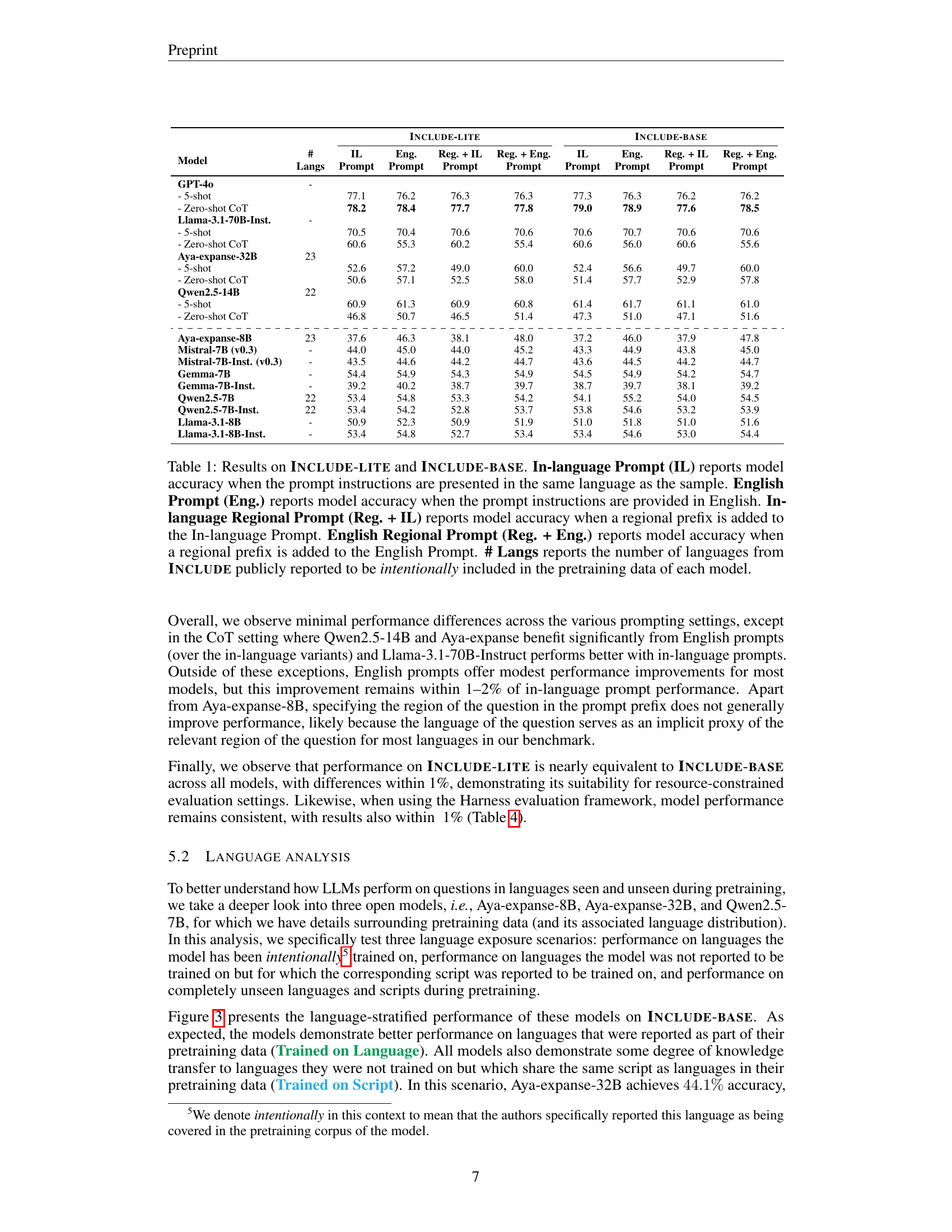
🔼 This figure displays GPT-40’s performance across various academic disciplines for six different languages: Korean, Persian, Armenian, Hindi, Greek, and Russian. Each bar graph represents a specific language and is further broken down by academic disciplines within that language. The height of each bar visually represents the model’s accuracy (percentage of correctly answered questions) for that specific discipline within that language. The number of questions used to calculate the accuracy for each discipline is also indicated on each bar.
read the caption
Figure 5: GPT-4o performance across academic disciplines for Korean, Persian, Armenian, Hindi, Greek, and Russian. Each bar is annotated with the number of questions with correct answers.

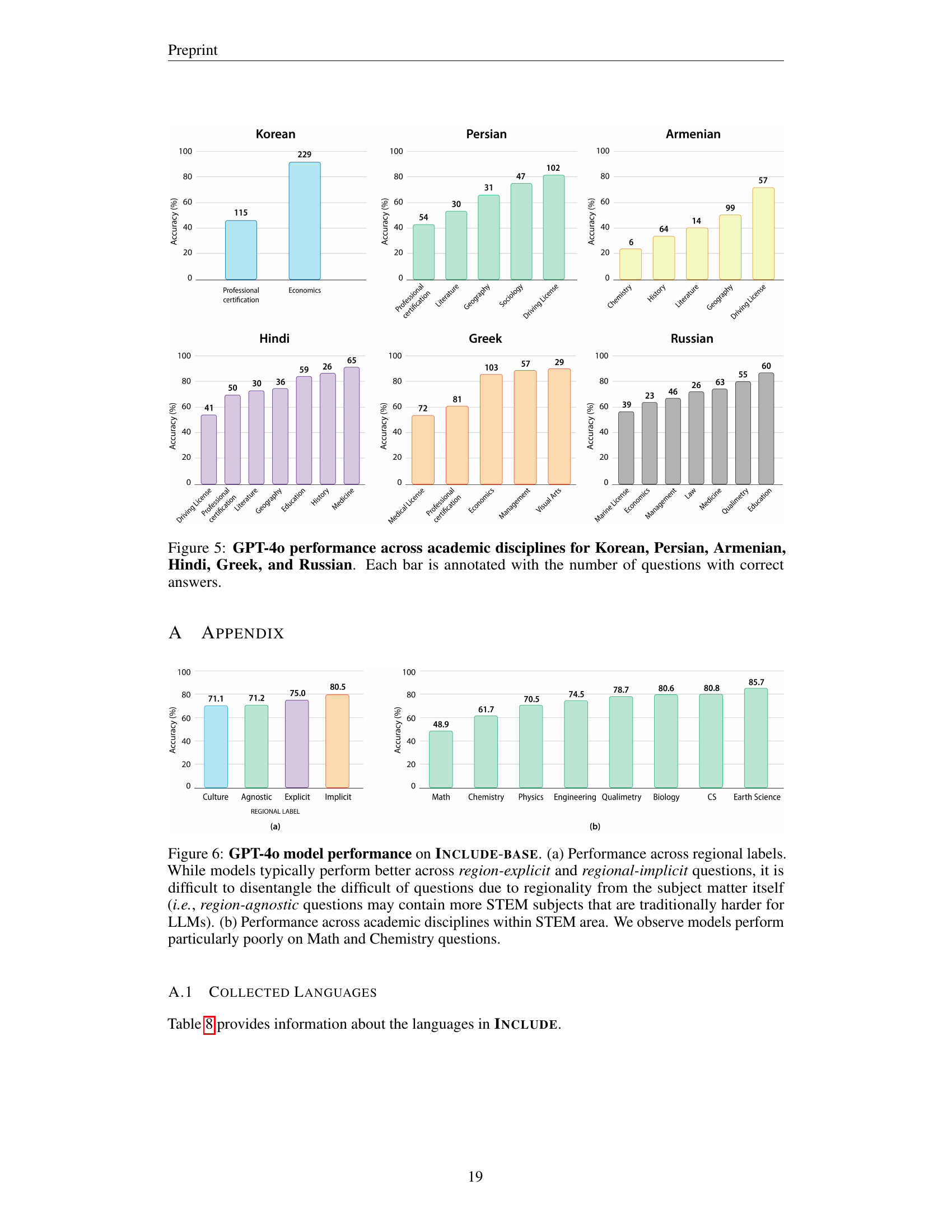
🔼 Figure 6 shows GPT-4’s performance on the INCLUDE-BASE benchmark. Panel (a) compares performance across three question categories based on their regional knowledge dependence: region-agnostic (no regional knowledge needed), region-explicit (requiring specific regional knowledge), and region-implicit (regional knowledge potentially relevant but not explicitly required). The figure reveals that while performance is generally higher on explicit and implicit regional questions, this may be confounded by the fact that region-agnostic questions often involve STEM topics, which are known to be more challenging for LLMs. Panel (b) focuses specifically on STEM subjects and shows that the model’s accuracy is particularly low for math and chemistry questions.
read the caption
Figure 6: GPT-4o model performance on Include-base. (a) Performance across regional labels. While models typically perform better across region-explicit and regional-implicit questions, it is difficult to disentangle the difficult of questions due to regionality from the subject matter itself (i.e., region-agnostic questions may contain more STEM subjects that are traditionally harder for LLMs). (b) Performance across academic disciplines within STEM area. We observe models perform particularly poorly on Math and Chemistry questions.

🔼 This figure provides a visual representation of the distribution of questions across different academic domains and fields within the INCLUDE benchmark. The figure uses a circular layout, with each academic area (e.g., Humanities, STEM, Social Sciences) represented as a section. Within each section, the different academic fields are further broken down and shown with the number of questions from that field. The size of each section and the visual representation of each field within it are scaled according to the number of questions in that area or field, offering a clear representation of the dataset’s composition across various disciplines.
read the caption
Figure 7: Academic domain and academic fields with the number of examples across all languages.

🔼 This figure shows the Google Form used to solicit exam questions from the academic community to create the INCLUDE benchmark. The form requests details such as the name and description of the exam, the language used, URLs to the exam source, and a description of how the answers are provided. It specifically targets three types of exams: educational (high school, university), professional (law, medical licenses), and practical tests (driver’s license). The form also collects additional metadata about the exam, such as the approximate number of questions and their format.
read the caption
Figure 8: Exam source collection form sent to the academic community.

🔼 This figure visualizes the performance of various large language models (LLMs) on a multilingual question-answering benchmark. It compares the models’ accuracy across different languages, offering insights into their cross-lingual capabilities. Panel (a) focuses on a single model’s accuracy across multiple languages, while panel (b) displays multiple models’ accuracy in a single language. This dual perspective helps analyze both the strengths and weaknesses of individual models and the overall challenges of multilingual language understanding.
read the caption
Figure 9: Accuracy of different models on languages where both existing benchmark data and newly collected data are available. Each point represents the accuracy score of a model for a specific language. (a) Points of the same color represent the accuracy scores of a single model across different languages. (b) Points of the same color represent the accuracy scores for a single language across different models.
More on tables
| Model | Humanities | STEM | Domain-Specific | Professional | Licenses |
|---|---|---|---|---|---|
| # samples | 13294 | 2478 | 1964 | 3165 | 1736 |
| GPT-4o | |||||
| - 5-shot | 79.0 | 74.2 | 76.8 | 70.1 | 82.1 |
| - Zero-shot CoT | 79.9 | 78.6 | 80.4 | 73.8 | 81.1 |
| Llama-3.1-70B-Instruct | |||||
| - 5-shot | 71.2 | 69.9 | 74.2 | 64.4 | 73.7 |
| - Zero-shot CoT | 61.9 | 57.5 | 63.5 | 56.7 | 58.4 |
| Aya-expanse-32B | |||||
| - 5-shot | 49.6 | 43.0 | 49.1 | 34.7 | 49.5 |
| - Zero-shot CoT | 52.9 | 47.8 | 55.4 | 44.3 | 52.9 |
| Qwen2.5-14B | |||||
| - 5-shot | 61.4 | 60.9 | 66.0 | 57.1 | 65.1 |
| - Zero-shot CoT | 48.6 | 44.4 | 51.6 | 41.6 | 46.9 |
| Aya-expanse-8B | 37.8 | 32.3 | 37.3 | 40.2 | 29.7 |
| Mistral-7B (v0.3) | 44.2 | 43.4 | 43.9 | 38.6 | 44.3 |
| Mistral-7B-Instruct (v0.3) | 44.5 | 42.7 | 43.2 | 40.1 | 43.7 |
| Gemma-7B | 55.1 | 53.6 | 55.5 | 47.7 | 62.2 |
| Gemma-7B-Instruct | 38.6 | 37.7 | 42.0 | 34.5 | 44.9 |
| Qwen2.5-7B | 53.4 | 54.2 | 59.1 | 51.3 | 57.8 |
| Qwen2.5-7B-Instruct | 53.5 | 53.3 | 58.1 | 49.5 | 58.6 |
| Llama-3-8B | 51.7 | 49.8 | 52.1 | 43.4 | 51.3 |
| Llama-3-8B-Instruct | 50.7 | 46.9 | 52.9 | 44.3 | 54.4 |
🔼 This table presents the accuracy scores achieved by the GPT-40 language model across different categories of questions from the INCLUDE benchmark dataset. The questions are grouped into high-level topics: Humanities (encompassing Social Sciences, Humanities, and General Knowledge), STEM (including Applied Sciences and STEM fields), Domain-Specific (covering Business & Commerce and Health-oriented education), Professional (including professional certifications), and Licenses (including Marine, Fishing, and Driving licenses). The table shows the model’s performance in each topic area, offering insight into its strengths and weaknesses across various question types and knowledge domains. Note that the ‘In-language prompting’ condition is implied, as specified in the table’s caption.
read the caption
Table 2: Accuracy performance of GPT-4o (In-language prompting) on Include-base grouped by high-level topics. Where Humanities include Social Science, Humanities, and General knowledge. STEM includes Applied Science and STEM. Domain-specific covers Business & Commerce and Health oriented education. Professional includes professional certifications. Licenses cover Marine, Fishing, and Driving licenses.
| Model | In-language Prompt | English Prompt | ||||
|---|---|---|---|---|---|---|
| Total Acc. | Answer Acc. | Format Errors (%) | Total Acc. | Answer Acc. | Format Errors (%) | |
| — | — | — | — | — | — | — |
| GPT-4o | ||||||
| - 5-shot | 77.3 | 79.0 | 2.5 | 76.3 | 78.0 | 2.2 |
| - Zero-shot CoT | 79.0 | 79.2 | 0.2 | 78.9 | 79.1 | 0.2 |
| Llama-3.1-70B-Instruct | ||||||
| - 5-shot | 70.6 | 70.6 | 0.0 | 70.7 | 70.7 | 0.0 |
| - Zero-shot CoT | 60.6 | 67.9 | 10.9 | 56.3 | 67.8 | 17.0 |
| Aya-expanse-32B | ||||||
| - 5-shot | 52.4 | 56.2 | 16.9 | 56.6 | 62.7 | 9.7 |
| - Zero-shot CoT | 51.4 | 57.2 | 10.2 | 57.7 | 58.4 | 1.1 |
| Qwen2.5-14B | ||||||
| - 5-shot | 61.4 | 62.4 | 1.5 | 61.7 | 61.7 | 0.0 |
| - Zero-shot CoT | 47.3 | 53.1 | 10.9 | 51.0 | 52.0 | 1.9 |
| \cdashline1-7 Aya-expanse-8B | 37.2 | 43.8 | 18.0 | 46.0 | 50.7 | 9.2 |
| Mistral-7B (v0.3) | 43.3 | 43.3 | 0.0 | 44.9 | 44.9 | 0.0 |
| Mistral-7B-Instruct (v0.3) | 43.6 | 43.8 | 0.4 | 44.5 | 44.5 | 0.1 |
| Gemma-7B | 54.5 | 54.5 | 0.0 | 54.9 | 54.9 | 0.0 |
| Gemma-7B-Instruct | 38.7 | 38.7 | 0.0 | 39.7 | 39.7 | 0.1 |
| Qwen2.5-7B | 54.1 | 55.1 | 1.9 | 55.2 | 55.2 | 0.0 |
| Qwen2.5-7B-Instruct | 53.8 | 54.0 | 0.5 | 54.6 | 54.6 | 0.0 |
| Llama-3.1-8B | 51.0 | 51.0 | 0.0 | 51.8 | 51.8 | 0.0 |
| Llama-3.1-8B-Instruct | 53.4 | 53.4 | 0.0 | 54.6 | 54.6 | 0.0 |
🔼 This table presents a detailed performance analysis of various large language models (LLMs) on the INCLUDE benchmark. It breaks down the accuracy into three key metrics: Total Accuracy (overall accuracy, including formatting errors), Answer Accuracy (accuracy considering only correctly formatted answers), and Formatting Errors (percentage of incorrectly formatted responses). By separating correctly formatted answers from those with formatting issues, the table provides a nuanced view of model performance, distinguishing between true comprehension failures and problems with output formatting. The analysis is further broken down by whether prompts were given in the native language or in English, offering insights into the effect of prompting language on both the raw accuracy and the ability of the model to produce correctly formatted outputs.
read the caption
Table 3: Results on Include-base for In-language and English prompting strategies. Total Accuracy represents the raw accuracy of the model for answering Include questions in each respective subset. Answer Accuracy represents the accuracy of the model when only considering samples where an answer is extracted from the model’s output in the correct response format. Formatting Errors (%) describes the percentage of model responses that are not formatted correctly and so do not output any answer option. We mark these incorrect by default in Total Accuracy and do not include them when computing Answer Accuracy.
| Model | Include-lite | Include-base | ||
|---|---|---|---|---|
| In-Language Prompt | English Prompt | In-Language Prompt | English Prompt | |
| Llama3.1-70B-Instruct | 70.3 | 70.6 | 70.6 | 70.9 |
| Aya-expanse-32B | 58.9 | 59.5 | 47.2 | 47.8 |
| Qwen2.5-14B | 61.8 | 61.9 | 62.3 | 62.6 |
| Aya-expanse-8B | 47.3 | 48.0 | 47.2 | 47.8 |
| Mistral-7B | 44.5 | 44.7 | 44.1 | 44.6 |
| Mistral-7B-Instruct | 43.8 | 43.9 | 44.2 | 44.3 |
| Gemma-7B | 53.6 | 53.1 | 53.5 | 53.2 |
| Gemma-7B-Instruct | 39.1 | 39.7 | 38.6 | 39.3 |
| Qwen2.5-7B | 54.4 | 54.9 | 55.0 | 55.5 |
| Qwen2.5-7B-Instruct | 54.5 | 54.6 | 54.8 | 54.8 |
| Llama-3.1-8B | 51.2 | 52.1 | 51.2 | 51.9 |
| Llama-3.1-8B-Instruct | 53.5 | 54.4 | 53.5 | 54.4 |
🔼 This table presents the results of evaluating various large language models using the Harness-Eval framework on the INCLUDE-BASE benchmark. It shows the performance of each model, broken down by prompting type (in-language and English) for both INCLUDE-LITE and INCLUDE-BASE subsets. This allows for a comparison of model performance across different language settings and resource constraints.
read the caption
Table 4: Harness evaluation results on Include-base.
| Academic area | Academic field | Label |
|---|---|---|
| Humanities | Logic | Agnostic |
| Law | Region Explicit | |
| Language | Culture | |
| Visual Arts, History, Philosophy, Religious studies, Performing arts, Culturology, Literature | Region implicit/ Culture | |
| Social Science | Sociology, Political sciences, Anthropology | Region implicit/Culture |
| Economics | Region implicit/Agnostic/Region explicit | |
| Psychology | Region implicit/Region explicit | |
| Geography | Region implicit/Agnostic | |
| STEM | Math, Physics, CS, Biology, Earth science, Chemistry, Engineering | Agnostic |
| Qualimetry | Region explicit | |
| Health oriented education | Medicine | Agnostic/Region implicit/Region explicit |
| Health | Region implicit/Region explicit | |
| Business and Commerce | Accounting | Region explicit |
| Management, Marketing, Industrial and labor relations, International trade, Risk management and insurance, Business administration, Business ethics, Business, Finance | Region implicit/Region explicit/Agnostic | |
| Applied Science | Agriculture, Library and museum studies, Transportation | Region implicit/Agnostic |
| Military Sciences, Public Administration, Public Policy | Region implicit/Region explicit | |
| Architecture and Design, Family and consumer science, Environmental studies and forestry, Education | ||
| Journalism, media studies, and communication, Social Work, Human physical performance and recreation | Region implicit | |
| Other | Driving license, Marine license, Fishing license, Medical license, Public administration, Professional certification | Region explicit |
| General knowledge | Multiple exams | Region implicit/Culture |
🔼 This table details the annotation schema used to categorize the exams included in the INCLUDE benchmark. It maps high-level academic areas (like Humanities or STEM) to more specific academic fields (e.g., History, Biology). Critically, it also assigns a regionality label to each exam, indicating whether the knowledge required to answer the questions is region-agnostic (doesn’t require regional knowledge), culture-related (requires cultural understanding of a region), region-explicit (explicitly requires knowledge about laws or regulations specific to a region), or region-implicit (implicitly relies on regional context). While the table shows the most frequent regionality label for each exam, it’s important to note that each exam in the dataset was individually labeled with one of these four regionality categories.
read the caption
Table 5: Annotation schema for high-level Academic area and fine-grained Academic field. The Label column lists the most likely regionality label for these exams in our dataset (e.g., region-{agnostic, implicit, explicit} or cultural), though all exams from which we collect data are individually labeled with a regionality category. The first label is the most frequent one.
| studi es | Professional | License | Avg (%) | |||
|---|---|---|---|---|---|---|
| Albanian | 95.0 | 88.0 | 83.5 | - | - | 89.50 |
| Arabic | 77.8 | 82.0 | 80.5 | - | 76.2 | 78.30 |
| Armenian | 52.7 | 32.0 | - | - | 72.2 | 53.60 |
| Azerbaijani | 71.3 | 73.6 | 71.4 | - | - | 71.90 |
| Basque | - | - | - | 64.8 | - | 64.80 |
| Belarusian | 51.8 | 42.0 | - | - | - | 50.90 |
| Bengali | 71.1 | 90.0 | - | 84.3 | - | 76.80 |
| Bulgarian | 93.8 | 60.0 | - | - | - | 90.70 |
| Chinese | 71.5 | 66.7 | 58.2 | 52.1 | 84.5 | 66.10 |
| Croatian | 89.0 | 82.0 | - | - | - | 88.40 |
| Dutch; Flemish | 86.6 | 87.5 | 80.0 | - | - | 86.40 |
| Estonian | 90.7 | 98.0 | 100.0 | - | - | 92.40 |
| Finnish | 67.0 | 87.0 | 77.8 | - | - | 69.90 |
| French | 83.8 | 50.0 | 81.2 | - | 68.1 | 80.70 |
| Georgian | 87.6 | - | - | - | - | 87.60 |
| German | 62.6 | 64.0 | - | - | 87.0 | 66.90 |
| Greek | 84.7 | 84.0 | 89.2 | 58.6 | - | 71.50 |
| Hebrew | 62.0 | - | - | - | 88.6 | 86.20 |
| Hindi | 77.7 | 71.9 | 91.5 | 71.8 | 57.7 | 75.10 |
| Hungarian | 66.3 | 80.6 | - | - | - | 75.80 |
| Indonesian | 84.0 | 69.1 | - | 84.8 | - | 79.50 |
| Italian | 87.7 | 87.2 | 91.7 | 95.5 | - | 90.00 |
| Japanese | - | - | - | 78.1 | 96.0 | 81.60 |
| Kazakh | 80.4 | - | - | - | - | 80.40 |
| Korean | 91.6 | - | - | 46.4 | - | 69.00 |
| Lithuanian | 92.0 | 97.1 | 82.5 | 81.2 | - | 90.60 |
| Malay | 84.5 | - | 80.3 | - | - | 83.00 |
| Malayalam | 69.6 | 66.0 | 55.0 | - | 80.9 | 70.80 |
| Nepali | - | - | - | 61.6 | 83.2 | 72.40 |
| Macedonian | 96.0 | 86.0 | 89.3 | - | - | 92.40 |
| Persian | 66.0 | 25.0 | - | 49.6 | 81.6 | 64.60 |
| Polish | 100.0 | 64.6 | - | 80.0 | - | 78.80 |
| Portuguese | 84.7 | 63.3 | 67.9 | - | - | 76.40 |
| Serbian | 92.2 | 86.0 | - | - | - | 91.60 |
| Spanish | 83.6 | 88.0 | 96.0 | - | - | 84.40 |
| Tagalog | 86.8 | - | - | - | 90.7 | 87.40 |
| Tamil | 70.6 | 54.0 | - | - | - | 69.10 |
| Telugu | 66.9 | 70.7 | - | - | - | 68.20 |
| Turkish | 62.0 | 52.0 | 75.9 | - | - | 65.30 |
| Ukrainian | 85.8 | 84.0 | - | - | - | 85.60 |
| Urdu | 61.7 | 65.3 | 100.0 | - | - | 62.50 |
| Uzbek | 63.6 | 84.0 | - | 73.3 | - | 69.70 |
| Vietnamese | 84.4 | 86.0 | - | - | - | 84.50 |
| Russian | 77.5 | 83.4 | 70.8 | - | 63.9 | 75.00 |
🔼 This table presents the performance of the GPT-40 language model on the INCLUDE benchmark dataset. For each of the 44 languages in the dataset, the accuracy of GPT-40 (using a 5-shot prompting technique) is shown across five categories of questions: Humanities (including Social Sciences and general knowledge), STEM (Science, Technology, Engineering, and Mathematics, including applied sciences), Domain-Specific (questions relating to Business & Commerce and health-oriented education), Professional (questions related to professional certifications), and Licenses (questions related to licenses such as Marine, Fishing and Driving). The percentages represent the accuracy achieved by the model for each language in each category.
read the caption
Table 6: Accuracy performance of GPT-4o (5-shot) on Include-base for each language. Humanities include Social Science, Humanities, and General knowledge. STEM includes Applied Science and STEM. Domain-specific covers Business & Commerce and Health oriented education. Professional includes professional certifications. Licenses cover Marine, Fishing, and Driving licenses.
| Model | Full Benchmark | Newly collected |
|---|---|---|
| Aya-expanse-8B | 0.02 | 0.01 |
| XGLM-7B | 0.17 | 0.14 |
| Qwen-2.5-7B | 0.13 | 0.11 |
| LLaMA-3.1-8B | 0.29 | 0.25 |
🔼 This table presents the percentage of questions in the INCLUDE-BASE benchmark that were identified as potentially originating from the training data of various large language models (LLMs). It shows the contamination rates, indicating the degree to which each model’s training data may overlap with the benchmark dataset. Lower percentages suggest less contamination, implying the benchmark is less likely to be biased by the models’ prior knowledge.
read the caption
Table 7: Data contamination rates per model on Include-base.
| Language | Script | Family | Branch | Availability | Count |
|---|---|---|---|---|---|
| Albanian | latin | Indo-European | Albanian | Mid | 2365 |
| Amharic | ge’ez | Afro-Asiatic | Semitic | Low | 131 |
| Arabic | perso-arabic | Afro-Asiatic | Semitic | High | 15137 |
| Armenian | armenian | Indo-European | Armenian | Low | 1669 |
| Assamese | bengali-assamese | Indo-European | Indo-Iranian | Low | 323 |
| Azerbaijani | latin | Turkic | Azerbaijani North | Mid | 6937 |
| Basque | latin | Isolate | Low | 719 | |
| Belarusian | cyrillic | Indo-European | Slavic East | Low | 687 |
| Bengali | bengali-assamese | Indo-European | Indo-Iranian | Mid | 15259 |
| Bulgarian | cyrillic | Indo-European | Slavic South Eastern | Mid | 2937 |
| Chinese | chinese | Sino-Tibetan | Chinese | High | 12977 |
| Croatian | latin | Indo-European | Slavic South Western | Mid | 2879 |
| Czech | latin | Indo-European | Slavic West | High | 50 |
| Danish | latin | Indo-European | Germanic | Mid | 732 |
| Dutch; Flemish | latin | Indo-European | Germanic | High | 2222 |
| Estonian | latin | Uralic | Finnic | Mid | 952 |
| Finnish | latin | Uralic | Finnic | Mid | 1574 |
| French | latin | Indo-European | Italic | High | 2457 |
| Georgian | mkherduli | Kartvelian | Georgian | Low | 599 |
| German | latin | Indo-European | Germanic | High | 1590 |
| Greek | greek | Indo-European | Greek | Mid | 6570 |
| Hebrew | hebrew | Afro-Asiatic | Semitic | Mid | 2457 |
| Hindi | devanagari | Indo-European | Indo-Iranian | Mid | 5167 |
| Hungarian | latin | Uralic | Hungarian | Mid | 2267 |
| Indonesian | latin | Austronesian | Malayo-Polynesian | High | 12013 |
| Italian | latin | Indo-European | Italic | High | 3038 |
| Japanese | kanji | Japonic | Japanese | High | 2699 |
| Kannada | kannada | Dravidian | Southern | Low | 335 |
| Kazakh | cyrillic | Turkic | Western | Low | 5736 |
| Korean | hangul | Koreanic | Korean | Mid | 1781 |
| Lithuanian | latin | Indo-European | Eastern Baltic | Mid | 1397 |
| Malay | latin | Austronesian | Malayo-Polynesian | Mid | 1021 |
| Malayalam | vatteluttu | Dravidian | Southern | Low | 275 |
| Marathi | devanagari | Indo-European | Indo-Iranian | Mid | 313 |
| Nepali | devanagari | Indo-European | Indo-Iranian | Mid | 1470 |
| Macedonian | cyrillic | Indo-European | Slavic South Eastern | Low | 2075 |
| Oriya | odia | Indo-European | Indo-Iranian | Low | 241 |
| Panjabi; Punjabi | gurmukhi | Indo-European | Indo-Iranian | Low | 453 |
| Persian | perso-arabic | Indo-European | Indo-Iranian | High | 23990 |
| Polish | latin | Indo-European | Slavic West | High | 2023 |
| Portuguese | latin | Indo-European | Italic | High | 1407 |
| Russian | cyrillic | Indo-European | Slavic East | High | 10169 |
| Serbian | cyrillic | Indo-European | Slavic South | Mid | 1636 |
| Sinhala; Sinhalese | sinhala | Indo-European | Indo-Iranian | Low | 325 |
| Slovak | latin | Indo-European | Slavic West | Mid | 131 |
| Spanish | latin | Indo-European | Italic | High | 2559 |
| Swedish | latin | Indo-European | Germanic | Mid | 5102 |
| Tagalog | latin | Austronesian | Malayo-Polynesian | Low | 530 |
| Tamil | tamil | Dravidian | Southern | Mid | 945 |
| Telugu | telugu | Dravidian | South-Central | Low | 11568 |
| Turkish | latin | Turkic | Southern | High | 2710 |
| Ukrainian | cyrillic | Indo-European | Slavic East | Mid | 1482 |
| Urdu | perso-arabic | Indo-European | Indo-Iranian | Low | 122 |
| Uzbek | latin | Turkic | Eastern | Low | 2878 |
| Vietnamese | latin | Austro-Asiatic | Mon-Khmer | High | 8901 |
🔼 This table lists all 44 languages included in the INCLUDE benchmark dataset. For each language, it provides metadata including the script used, the language family and branch it belongs to, and its resource availability level (High, Mid, or Low). Finally, it indicates the total number of samples available for each language within the dataset.
read the caption
Table 8: Languages in Include with their associated metadata and the total count of the samples per language.
| Language | Academic Area | Accuracy | Count |
|---|---|---|---|
| Albanian | Humanities | 95.1 | 223 |
| Business & Commerce | 85.7 | 223 | |
| Social Science | 94.5 | 55 | |
| Arabic | Humanities | 79.0 | 105 |
| Business & Commerce | 79.3 | 82 | |
| General Knowledge | 86.7 | 105 | |
| Other | 76.2 | 105 | |
| STEM | 82.0 | 50 | |
| Social Science | 67.6 | 105 | |
| Armenian | Humanities | 34.7 | 225 |
| Other | 72.2 | 79 | |
| STEM | 28.0 | 50 | |
| Social Science | 50.5 | 196 | |
| Azerbaijani | Applied Science | 75.9 | 108 |
| Humanities | 74.1 | 108 | |
| Business & Commerce | 62.5 | 96 | |
| Health-Oriented Education | 80.2 | 96 | |
| Social Science | 67.6 | 108 | |
| Basque | Other | 64.8 | 500 |
| Belarusian | Humanities | 50.8 | 490 |
| STEM | 42.0 | 50 | |
| Bengali | Humanities | 62.0 | 166 |
| General Knowledge | 80.1 | 166 | |
| Other | 84.3 | 166 | |
| STEM | 88.0 | 50 | |
| Bulgarian | Humanities | 96.4 | 250 |
| STEM | 60.0 | 50 | |
| Social Science | 91.2 | 250 | |
| Chinese | Applied Science | 73.2 | 71 |
| Humanities | 67.8 | 87 | |
| Business & Commerce | 53.5 | 71 | |
| Health-Oriented Education | 60.9 | 87 | |
| Other | 68.3 | 142 | |
| Social Science | 76.1 | 71 | |
| Croatian | Humanities | 86.8 | 250 |
| STEM | 82.0 | 50 | |
| Social Science | 90.8 | 250 | |
| Dutch; Flemish | Humanities | 86.0 | 243 |
| Social Science | 86.8 | 243 | |
| Estonian | Humanities | 90.1 | 161 |
| STEM | 97.2 | 36 | |
| Finnish | Humanities | 69.5 | 226 |
| Health-Oriented Education | 75.6 | 45 | |
| Social Science | 64.6 | 226 | |
| French | Humanities | 86.5 | 266 |
| Other | 68.1 | 47 | |
| Social Science | 74.3 | 74 | |
| Georgian | Humanities | 87.6 | 500 |
| German | Social Science | 62.6 | 91 |
| Greek | Humanities | 83.8 | 37 |
| Business & Commerce | 89.1 | 64 | |
| Other | 57.5 | 266 | |
| Social Science | 84.2 | 133 | |
| Hebrew | Humanities | 60.0 | 50 |
| Other | 88.6 | 500 | |
| Hindi | Applied Science | 83.1 | 71 |
| Humanities | 72.9 | 96 | |
| General Knowledge | 83.1 | 71 | |
| Health-Oriented Education | 91.5 | 71 | |
| Other | 64.1 | 142 | |
| Social Science | 74.6 | 71 | |
| Hungarian | Applied Science | 79.8 | 341 |
| Social Science | 66.3 | 184 | |
| Indonesian | Applied Science | 71.2 | 125 |
| Humanities | 82.4 | 125 | |
| Other | 83.2 | 125 | |
| STEM | 60.0 | 50 | |
| Social Science | 84.8 | 125 | |
| Italian | Applied Science | 85.7 | 35 |
| Humanities | 85.0 | 167 | |
| Other | 95.5 | 155 | |
| Social Science | 89.8 | 167 |
🔼 This table presents the performance of the GPT-4o language model on the INCLUDE benchmark dataset. Specifically, it shows the accuracy of GPT-4o (using a 5-shot, in-language prompting method) across 44 languages, broken down by academic area (Humanities, STEM, Domain-Specific, Professional, Licenses). The table only includes results for academic areas with at least 30 examples per language to ensure statistical reliability. The accuracy scores represent the percentage of correctly answered multiple choice questions in each category. This allows for an analysis of GPT-4o’s performance across various languages and knowledge domains.
read the caption
Table 9: GPT-4o (5-shot, In-language prompting) performance on Include-base per language and academic area. Areas with less than 30 examples were excluded from the analysis.
| Language | Academic Area | Accuracy | Count |
|---|---|---|---|
| Japanese | Other | 80.2 | 501 |
| Kazakh | Humanities | 80.4 | 500 |
| Korean | Other | 46.0 | 250 |
| Korean | Social Science | 91.6 | 250 |
| Lithuanian | Humanities | 91.6 | 335 |
| Lithuanian | Business & Commerce | 77.5 | 40 |
| Lithuanian | Other | 81.2 | 48 |
| Lithuanian | STEM | 97.1 | 34 |
| Lithuanian | Social Science | 93.5 | 77 |
| Malay | Humanities | 84.3 | 178 |
| Malay | Business & Commerce | 79.8 | 178 |
| Malay | Social Science | 84.8 | 145 |
| Malayalam | Humanities | 64.3 | 56 |
| Malayalam | General Knowledge | 73.1 | 78 |
| Malayalam | Health-Oriented Education | 55.0 | 100 |
| Malayalam | Other | 80.9 | 194 |
| Malayalam | STEM | 66.0 | 47 |
| Nepali | Other | 72.4 | 500 |
| Macedonian | Humanities | 96.9 | 224 |
| Macedonian | Business & Commerce | 89.3 | 224 |
| Macedonian | STEM | 86.0 | 50 |
| Macedonian | Social Science | 92.5 | 53 |
| Persian | Humanities | 55.3 | 141 |
| Persian | Other | 62.4 | 250 |
| Persian | Social Science | 74.5 | 141 |
| Polish | Other | 80.0 | 496 |
| Polish | STEM | 62.5 | 48 |
| Portuguese | Applied Science | 58.3 | 84 |
| Portuguese | Humanities | 81.8 | 154 |
| Portuguese | Business & Commerce | 56.9 | 84 |
| Portuguese | Health-Oriented Education | 67.1 | 67 |
| Portuguese | Other | 67.6 | 169 |
| Russian | Applied Science | 87.0 | 69 |
| Russian | Humanities | 76.8 | 69 |
| Russian | Business & Commerce | 66.7 | 69 |
| Russian | Health oriented education | 74.1 | 85 |
| Russian | Other | 63.9 | 97 |
| Russian | STEM | 80.9 | 94 |
| Russian | Social Science | 76.8 | 69 |
| Serbian | Humanities | 90.4 | 313 |
| Serbian | STEM | 84.0 | 50 |
| Serbian | Social Science | 95.2 | 187 |
| Spanish | Humanities | 77.2 | 250 |
| Spanish | Health oriented education | 96.0 | 25 |
| Spanish | STEM | 88.0 | 25 |
| Spanish | Social Science | 89.6 | 250 |
| Tagalog | Humanities | 86.8 | 425 |
| Tagalog | Other | 90.7 | 75 |
| Tamil | General knowledge | 70.6 | 500 |
| Tamil | STEM | 54.0 | 50 |
| Telugu | Applied Science | 73.5 | 166 |
| Telugu | Humanities | 66.0 | 191 |
| Telugu | Social Science | 66.9 | 166 |
| Turkish | Humanities | 62.0 | 166 |
| Turkish | Business & Commerce | 75.9 | 166 |
| Turkish | STEM | 52.0 | 50 |
| Turkish | Social Science | 62.0 | 166 |
| Ukrainian | Humanities | 92.4 | 250 |
| Ukrainian | STEM | 84.0 | 50 |
| Ukrainian | Social Science | 79.2 | 250 |
| Urdu | Humanities | 61.7 | 300 |
| Urdu | STEM | 63.3 | 49 |
| Uzbek | Humanities | 62.9 | 240 |
| Uzbek | Other | 73.3 | 240 |
| Uzbek | STEM | 84.0 | 50 |
| Uzbek | Social Science | 71.4 | 21 |
| Vietnamese | Humanities | 88.0 | 250 |
| Vietnamese | STEM | 86.0 | 50 |
| Vietnamese | Social Science | 80.8 | 250 |
🔼 This table presents the performance of GPT-4, a large language model, on the INCLUDE benchmark. The benchmark evaluates multilingual language understanding, focusing on regional knowledge. The table is broken down by language, academic field (e.g., History, Economics, STEM subjects), and the type of regional knowledge required to answer the question (agnostic, culture-related, explicit, implicit). The accuracy of GPT-4’s responses is shown for each combination of language, field, and regional knowledge type, providing a detailed view of its performance across diverse contexts and language groups. Fields with fewer than 30 examples were excluded from the analysis to ensure statistical reliability.
read the caption
Table 10: GPT-4o (5-shot, In-language prompting) performance on Include-base per language, academic field, and regional label. Fields with less than 30 examples were excluded from the analysis (Part 1)
| Language | Academic Field | Regional Feature | Accuracy | Count |
|---|---|---|---|---|
| Albanian | History | Implicit | 93.1 | 58 |
| Philosophy | Implicit | 97.6 | 82 | |
| Visual Arts | Implicit | 94.0 | 83 | |
| Business | Implicit | 85.7 | 223 | |
| Sociology | Implicit | 94.5 | 55 | |
| Arabic | History | Implicit | 73.3 | 30 |
| Language | Culture | 80.0 | 40 | |
| Accounting | Explicit | 89.5 | 57 | |
| Multiple exams | Implicit | 86.7 | 105 | |
| Driving License | Explicit | 76.2 | 105 | |
| Geography | Implicit | 65.3 | 49 | |
| Sociology | Implicit | 66.7 | 33 | |
| Armenian | History | Culture | 26.3 | 95 |
| History | Implicit | 41.1 | 95 | |
| Literature | Culture | 40.0 | 35 | |
| Driving License | Explicit | 72.2 | 79 | |
| Chemistry | Agnostic | 20.0 | 30 | |
| Geography | Implicit | 50.5 | 196 | |
| Azerbaijani | Agriculture | Implicit | 85.3 | 34 |
| Law | Explicit | 76.2 | 42 | |
| Management | Implicit | 66.7 | 36 | |
| Health | Implicit | 80.2 | 96 | |
| Economics | Implicit | 70.7 | 58 | |
| Basque | Professional certification | Explicit | 64.8 | 500 |
| Belarusian | Language | Culture | 47.9 | 426 |
| Literature | Culture | 67.4 | 43 | |
| Math | Agnostic | 40.8 | 49 | |
| Bengali | Language | Culture | 62.5 | 40 |
| Literature | Culture | 61.9 | 126 | |
| Multiple exams | Implicit | 80.1 | 166 | |
| Professional certification | Explicit | 84.3 | 166 | |
| Biology | Agnostic | 89.5 | 38 | |
| Bulgarian | History | Implicit | 93.9 | 115 |
| Philosophy | Implicit | 98.5 | 135 | |
| Geography | Implicit | 91.2 | 250 | |
| Chinese | Medicine | Explicit | 57.1 | 35 |
| Driving License | Explicit | 84.5 | 71 | |
| Professional certification | Explicit | 52.1 | 71 | |
| Political sciences | Implicit | 84.8 | 33 | |
| Croatian | History | Implicit | 88.2 | 119 |
| Philosophy | Implicit | 83.5 | 79 | |
| Religious Studies | Implicit | 90.2 | 51 | |
| Psychology | Implicit | 95.7 | 93 | |
| Sociology | Implicit | 94.8 | 135 | |
| Dutch; Flemish | History | Culture | 89.4 | 141 |
| Literature | Culture | 81.4 | 102 | |
| Economics | Implicit | 81.7 | 109 | |
| Geography | Implicit | 93.9 | 33 | |
| Sociology | Implicit | 90.1 | 101 | |
| Estonian | Language | Culture | 89.1 | 147 |
| Finnish | Law | Explicit | 69.3 | 215 |
| Economics | Implicit | 73.7 | 95 | |
| Political Sciences | Implicit | 61.5 | 96 | |
| Sociology | Implicit | 48.6 | 35 | |
| French | Culturology | Culture | 94.8 | 77 |
| Language | Culture | 79.0 | 124 | |
| Driving License | Explicit | 68.1 | 47 | |
| Geography | Implicit | 68.1 | 47 | |
| Georgian | History | Implicit | 93.8 | 161 |
| Language | Culture | 85.7 | 168 | |
| Law | Explicit | 83.6 | 171 | |
| German | Geography | Implicit | 50.0 | 54 |
| Greek | Visual Arts | Implicit | 90.6 | 32 |
| Management | Implicit | 89.1 | 64 | |
| Medical License | Explicit | 54.1 | 133 | |
| Professional Certification | Explicit | 60.9 | 133 | |
| Economics | Implicit | 85.8 | 120 | |
| Hebrew | Logic | Agnostic | 60.0 | 50 |
| Driving License | Explicit | 88.6 | 500 | |
| Hindi | Education | Implicit | 84.3 | 70 |
| History | Implicit | 86.7 | 30 | |
| Literature | Culture | 73.2 | 41 | |
| Multiple Exams | Implicit | 83.1 | 71 | |
| Medicine | Explicit | 91.5 | 71 | |
| Driving License | Explicit | 57.7 | 71 | |
| Professional Certification | Explicit | 70.4 | 71 | |
| Geography | Implicit | 75.0 | 48 |
🔼 This table presents the performance of the GPT-4o language model on the INCLUDE-BASE benchmark. It breaks down the model’s accuracy per language, academic field (e.g., History, Economics, Physics), and type of regional knowledge required to answer the questions (e.g., region-agnostic, culture-related, region-explicit, region-implicit). Only fields with at least 30 examples are included in this part of the analysis. The table helps to illustrate how well the model performs across different languages, topics, and the types of knowledge needed to correctly answer the questions, showing potential regional biases in the model’s performance.
read the caption
Table 11: GPT-4o (5-shot, In-language prompting) performance on Include-base per language, academic field, and regional label. Fields with less than 30 examples were excluded from the analysis (Part 2)
| Language | Academic Field | Regional Feature | Accuracy | Count |
|---|---|---|---|---|
| Hungarian | Agriculture | Implicit | 82.4 | 170 |
| Architecture and Design | Explicit | 85.7 | 42 | |
| Environmental Studies and Forestry | Implicit | 74.4 | 129 | |
| Economics | Implicit | 80.8 | 78 | |
| Geography | Implicit | 48.1 | 81 | |
| Indonesian | Human Physical Performance and Recreation | Implicit | 71.2 | 125 |
| Language | Culture | 79.5 | 78 | |
| Professional Certification | Region explicit | 83.2 | 125 | |
| Economics | Region explicit | 77.8 | 36 | |
| Geography | Implicit | 87.5 | 32 | |
| Sociology | Implicit | 87.7 | 57 | |
| Italian | Agriculture | Implicit | 85.7 | 35 |
| History | Implicit | 90.4 | 94 | |
| Professional Certification | Region explicit | 95.5 | 155 | |
| Psychology | Implicit | 95.0 | 60 | |
| Sociology | Implicit | 87.7 | 65 | |
| Japanese | Driving License | Region explicit | 96.0 | 99 |
| Medical License | Region explicit | 86.1 | 201 | |
| Professional Certification | Region explicit | 66.7 | 201 | |
| Kazakh | History | Culture | 78.4 | 241 |
| History | Implicit | 94.9 | 79 | |
| Literature | Culture | 76.7 | 180 | |
| Korean | Professional Certification | Region explicit | 46.0 | 250 |
| Economics | Implicit | 91.6 | 250 | |
| Lithuanian | History | Implicit | 91.6 | 335 |
| Finance | Implicit | 77.5 | 40 | |
| Professional Certification | Region explicit | 81.2 | 48 | |
| Earth Science | Agnostic | 97.1 | 34 | |
| Economics | Implicit | 93.5 | 77 | |
| Malay | History | Implicit | 84.3 | 178 |
| Accounting | Region explicit | 79.8 | 178 | |
| Geography | Implicit | 85.3 | 129 | |
| Malayalam | History | Implicit | 61.5 | 52 |
| Multiple Exams | Culture | 72.7 | 77 | |
| Health | Implicit | 55.0 | 100 | |
| Marine License | Explicit | 80.9 | 194 | |
| Nepali | Driving License | Explicit | 83.2 | 250 |
| Professional Certification | Explicit | 61.6 | 250 | |
| North Macedonian | History | Implicit | 95.8 | 48 |
| Philosophy | Implicit | 97.3 | 74 | |
| Visual Arts | Implicit | 97.1 | 102 | |
| Business | Implicit | 89.3 | 224 | |
| Sociology | Implicit | 92.5 | 53 | |
| Persian | Literature | Culture | 51.6 | 31 |
| Driving License | Explicit | 81.6 | 125 | |
| Professional Certification | Explicit | 43.2 | 125 | |
| Geography | Implicit | 66.0 | 47 | |
| Sociology | Implicit | 74.6 | 63 | |
| Polish | Professional Certification | Explicit | 80.0 | 496 |
| Math | Agnostic | 61.7 | 47 | |
| Portuguese | Agriculture | Implicit | 70.0 | 40 |
| Philosophy | Implicit | 83.3 | 84 | |
| Management | Implicit | 57.9 | 57 | |
| Health | Implicit | 70.3 | 37 | |
| Economics | Implicit | 89.7 | 126 | |
| Russian | Education | Implicit | 87.0 | 69 |
| Law | Explicit | 72.2 | 36 | |
| Management | Implicit | 66.2 | 65 | |
| Medicine | Explicit | 73.3 | 60 | |
| Marine License | Explicit | 56.5 | 69 | |
| Qualimetry | Explicit | 79.7 | 69 | |
| Economics | Implicit | 63.9 | 36 | |
| Serbian | History | Implicit | 91.5 | 235 |
| Philosophy | Implicit | 87.5 | 56 | |
| Psychology | Implicit | 99.2 | 125 | |
| Sociology | Implicit | 91.1 | 45 | |
| Spanish | Language | Culture | 69.6 | 46 |
| Law | Explicit | 67.0 | 109 | |
| Literature | Implicit | 93.8 | 64 | |
| Philosophy | Implicit | 90.3 | 31 | |
| Economics | Explicit | 95.6 | 91 | |
| Geography | Implicit | 86.2 | 159 | |
| Tagalog | Culturology | Culture | 91.6 | 203 |
| History | Culture | 85.3 | 116 | |
| Language | Culture | 79.2 | 106 | |
| Driving License | Explicit | 90.7 | 75 | |
| Tamil | Multiple Exams | Implicit | 70.6 | 500 |
| Telugu | Education | Implicit | 73.0 | 100 |
| History | Culture | 64.7 | 119 | |
| History | Implicit | 63.9 | 36 | |
| Economics | Explicit | 60.0 | 45 | |
| Geography | Implicit | 73.2 | 82 | |
| Political Sciences | Implicit | 63.3 | 30 | |
| Turkish | History | Implicit | 71.2 | 73 |
| Philosophy | Implicit | 74.6 | 63 | |
| Business | Implicit | 75.9 | 166 | |
| Geography | Implicit | 53.8 | 130 | |
| Sociology | Implicit | 91.7 | 36 | |
| Ukrainian | Law | Explicit | 92.4 | 250 |
| Physics | Agnostic | 84.0 | 50 | |
| Psychology | Implicit | 79.2 | 250 | |
| Urdu | Culturology | Culture | 61.7 | 300 |
| Uzbek | History | Implicit | 66.1 | 124 |
| Law | Explicit | 60.6 | 109 | |
| Medical License | Explicit | 73.3 | 240 | |
| Vietnamese | History | Implicit | 88.3 | 239 |
| Geography | Implicit | 80.8 | 250 |
🔼 This table presents the performance of the GPT-40 model on the INCLUDE-BASE benchmark for different output generation lengths (k). For each language, it shows the accuracy achieved at different values of k (50, 100, 200, and 512 tokens). The ‘Total gain’ column indicates the improvement in accuracy observed when increasing the generation length from k=50 to k=512. This allows for analyzing the impact of increasing the response length on the model’s performance and identifying which languages benefit most from longer generations.
read the caption
Table 12: GPT-4o performance for different values of k𝑘kitalic_k for in-language prompting (the output generation length) per language on Include-base and total performance gain from k𝑘kitalic_k = 50 to 512.
| Language | Acc (k:50) | Acc (k:100) | Acc (k:200) | Acc (k:512) | Total gain |
|---|---|---|---|---|---|
| Uzbek | 51.4 | 60.6 | 66.6 | 68.6 | 17.2 |
| Armenian | 28.0 | 30.7 | 36.0 | 41.1 | 13.1 |
| Malayalam | 57.0 | 57.4 | 61.0 | 69.9 | 12.9 |
| Urdu | 53.7 | 56.8 | 58.8 | 62.2 | 8.5 |
| Greek | 58.0 | 58.2 | 63.8 | 66.4 | 8.4 |
| Korean | 60.4 | 61.0 | 62.4 | 68.8 | 8.4 |
| Chinese | 57.2 | 61.8 | 63.5 | 65.5 | 8.3 |
| Finnish | 63.3 | 64.4 | 67.0 | 69.1 | 5.8 |
| Basque | 60.0 | 60.8 | 63.8 | 64.8 | 4.8 |
| Polish | 74.1 | 75.2 | 75.4 | 78.1 | 4.0 |
| Azerbaijani | 67.7 | 69.2 | 70.4 | 71.5 | 3.8 |
| Dutch; Flemish | 81.9 | 82.9 | 83.8 | 85.3 | 3.4 |
| Telugu | 63.9 | 63.9 | 64.8 | 66.6 | 2.7 |
| Hindi | 72.0 | 72.4 | 73.7 | 74.4 | 2.4 |
| German | 64.0 | 65.5 | 65.5 | 66.2 | 2.2 |
| Malay | 80.6 | 81.8 | 82.4 | 82.8 | 2.2 |
| Tamil | 67.3 | 67.3 | 67.8 | 69.5 | 2.2 |
| Arabic | 76.3 | 76.8 | 77.9 | 78.4 | 2.1 |
| russian | 72.6 | 73.6 | 74.1 | 74.6 | 2.0 |
| Italian | 88.0 | 88.5 | 89.2 | 89.6 | 1.6 |
| Spanish | 82.4 | 83.1 | 83.3 | 84.0 | 1.6 |
| Japanese | 78.6 | 78.6 | 79.4 | 80.0 | 1.4 |
| Georgian | 86.2 | 86.4 | 87.0 | 87.6 | 1.4 |
| Vietnamese | 82.4 | 82.5 | 84.9 | 83.8 | 1.4 |
| Turkish | 63.5 | 64.1 | 64.4 | 64.8 | 1.3 |
| Kazakh | 79.2 | 79.6 | 80.4 | 80.4 | 1.2 |
| Portuguese | 72.8 | 73.5 | 73.5 | 74.0 | 1.2 |
| Bengali | 75.2 | 75.4 | 76.1 | 76.3 | 1.1 |
| Persian | 60.9 | 61.1 | 61.3 | 61.9 | 1.0 |
| Belarusian | 49.5 | 50.0 | 50.0 | 50.2 | 0.7 |
| French | 80.0 | 80.2 | 80.4 | 80.7 | 0.7 |
| Indonesian | 77.8 | 78.2 | 78.4 | 78.5 | 0.7 |
| Albanian | 88.9 | 89.3 | 89.3 | 89.5 | 0.6 |
| Lithuanian | 89.7 | 89.7 | 90.1 | 90.3 | 0.6 |
| Estonian | 92.0 | 92.0 | 92.4 | 92.4 | 0.4 |
| Croatian | 87.8 | 88.0 | 88.2 | 88.0 | 0.2 |
| Hungarian | 75.3 | 75.3 | 75.5 | 75.5 | 0.2 |
| Nepali | 71.8 | 72.0 | 71.6 | 72.0 | 0.2 |
| Bulgarian | 90.7 | 90.7 | 90.7 | 90.7 | 0.0 |
| Hebrew | 86.0 | 86.0 | 86.0 | 86.0 | 0.0 |
| Macedonian | 92.4 | 92.4 | 92.4 | 92.4 | 0.0 |
| Serbian | 91.5 | 91.5 | 91.5 | 91.5 | 0.0 |
| Tagalog | 87.4 | 87.4 | 87.4 | 87.4 | 0.0 |
| Ukrainian | 85.5 | 85.5 | 85.5 | 85.5 | 0.0 |
🔼 This table compares the performance of various multilingual and monolingual large language models (LLMs) on the INCLUDE-BASE benchmark. It shows the accuracy of each model on specific target languages, highlighting the differences in performance between multilingual and monolingual approaches for various languages. The benchmark focuses on evaluating models’ ability to understand and reason within the actual linguistic environments where they are meant to be used.
read the caption
Table 13: Accuracy of the multilingual and monolingual models for answering Include-base questions for specific target languages.
| Major training language | SoTA Monolingual | Monolingual Acc | GPT-4o | Qwen2.5-14B | Qwen2.5-7B |
|---|---|---|---|---|---|
| Chinese | Baichuan-7B | 38.7 | 68.1 | 82.2 | 78.3 |
| Arabic | SILMA-9B-Instruct | 56.9 | 78.1 | 70.5 | 61.6 |
| Japanese | calm2-7b-chat | 25.0 | 75.0 | 69.2 | 64.7 |
| Korean | Korean-Mistral-Nemo-sft-dpo-12B | 35.3 | 75.0 | 83.2 | 76.8 |
| Russian | ruGPT-3.5-13B | 53.8 | 69.0 | 68.2 | 59.6 |
| German | SauerkrautLM-v2-14b-DPO | 56.8 | 66.2 | 58.3 | 56.1 |
🔼 This table presents the R-squared (R²) values, a statistical measure indicating the goodness of fit of a model, comparing the performance of different language models on newly collected data against existing benchmarks. The R² values are calculated separately for each language and for each model, illustrating the correlation between the model’s performance on the new dataset and its performance on established benchmarks. This allows for an assessment of how well a model’s performance on known datasets predicts its performance on this new multilingual dataset.
read the caption
Table 14: R2superscript𝑅2R^{2}italic_R start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT scores between the performance different models for newly-collected data and existing benchmarks stratified by language and model.
| Language | R2 | Model | R2 |
|---|---|---|---|
| Albanian | 0.646 | GPT-4o | 0.077 |
| Chinese | 0.985 | Qwen2.5-14B | 0.546 |
| French | 0.770 | Aya-expanse-32B | 0.290 |
| German | 0.495 | Aya-expanse-8B | 0.333 |
| Italian | 0.953 | Qwen2.5-7B | 0.412 |
| Lithuanian | 0.945 | Mistral-7B | 0.231 |
| Persian | 0.833 | Gemma-7B | 0.001 |
| Polish | 0.831 | Llama 3.1-70B | 0.020 |
| Portuguese | 0.930 | Llama 3.1-8B | 0.001 |
🔼 This table provides a comparison of INCLUDE with existing multilingual benchmarks. It details the languages covered by each benchmark, the types of knowledge assessed (e.g., academic, region-specific, or general knowledge), and the percentage of questions in each benchmark focusing on region-agnostic vs. region-related topics. This allows for a clear understanding of how INCLUDE differs from and builds upon previous efforts in evaluating multilingual language models.
read the caption
Table 15: Existing published benchmarks descriptives and the comparison with Include-base.
| Benchmark | Language | Knowledge Coverage | Region agnostic (%) | Region related (%) |
|---|---|---|---|---|
| ArabicMMLU | Arabic | Academic knowledge (elementary school, high school, university), Driving License | 24.8% | 75.2% |
| CMMLU | Chinese | Academic knowledge (elementary school, high school, university) | 25.6% | 74.4% |
| PersianMMLU | Persian | Academic knowledge (elementary school, high school, university) | 63.1% | 36.9% |
| TurkishMMLU | Turkish | Academic knowledge (elementary school, high school, university) | 34.8% | 65.2% |
| VNHSGE | Vietnamese | High school examinations | 40.4% | 59.6% |
| EXAMS | 16 languages | High school examinations | 43.7% | 56.3% |
| Include (ours) | 44 languages | Academic knowledge (elementary school, high school, university), Professional examinations (Medical exam, Bar exam, Teaching exam), Occupational Licenses (Driving license, Marine license and more) | 7.8% | 92.2% |
🔼 This table breaks down the types of errors made by the model during the evaluation, categorizing them into four main types: computational errors, factual knowledge errors, regional knowledge errors, and model hallucinations. It provides the percentage of total errors that fall into each category, offering insights into the specific areas where the model struggles.
read the caption
Table 16: Breakdown of error types.
Full paper#