↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) demonstrate impressive reasoning abilities but often produce errors due to flawed reasoning trajectories. These errors stem from individual tokens, dubbed ‘critical tokens’, that derail the logical flow, impacting final results. Current alignment methods struggle to effectively address these token-level issues, highlighting a gap in current research.
To tackle this, the paper introduces cDPO, a novel approach leveraging contrastive estimation. This method trains separate models on correct and incorrect reasoning trajectories, identifying critical tokens through likelihood comparison. These critical tokens are then incorporated into a token-level preference optimization framework, refining the LLM’s reasoning process. Experiments show cDPO significantly improves reasoning accuracy on standard benchmarks, demonstrating its effectiveness in addressing token-level errors.
Key Takeaways#
Why does it matter?#
This paper is crucial because it identifies a critical oversight in current LLM reasoning models and proposes a novel solution. It directly addresses the challenge of aligning LLMs with human preferences in complex reasoning tasks, opening new avenues for improving model accuracy and robustness. The findings are broadly relevant to the field, impacting the development and refinement of LLMs for various applications.
Visual Insights#

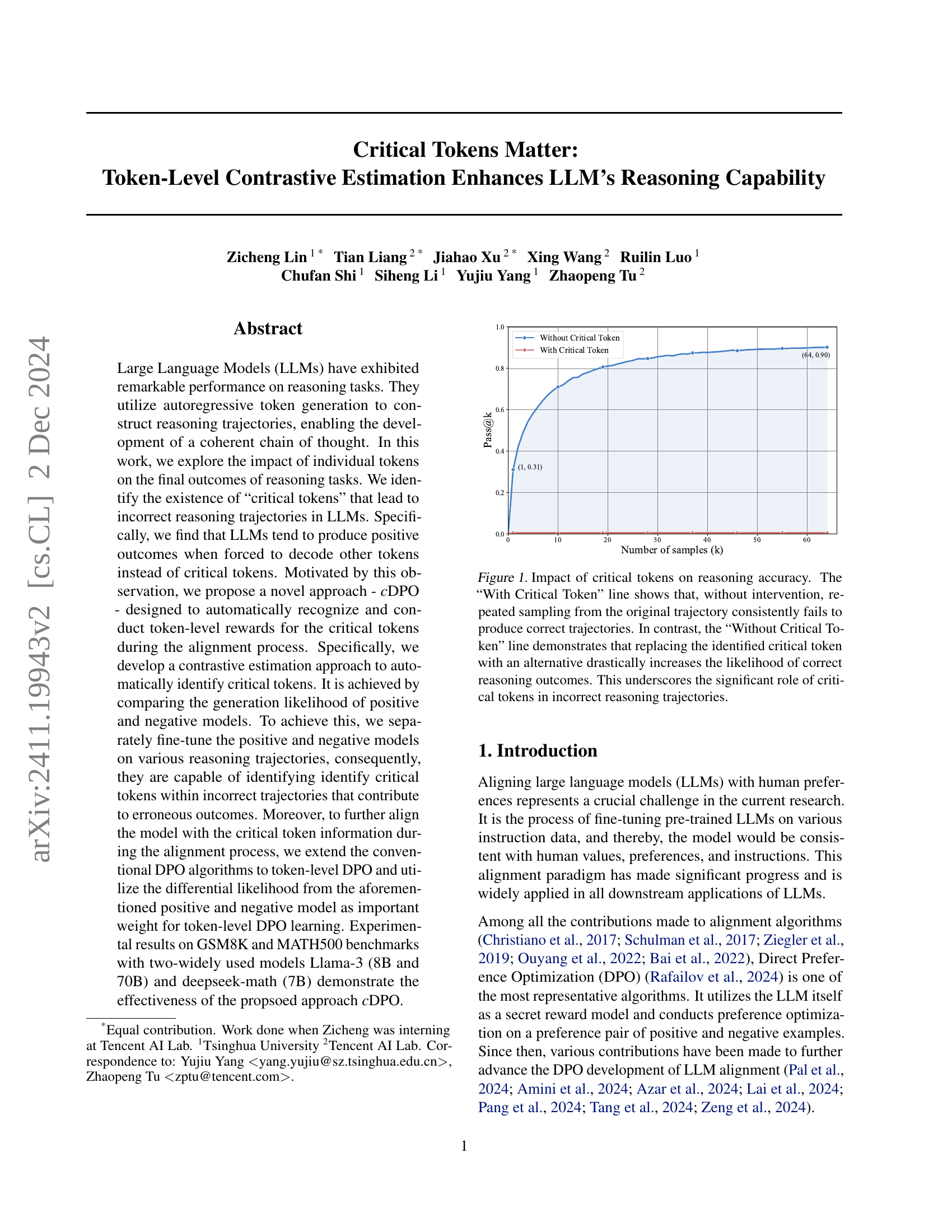
🔼 This figure illustrates the effect of critical tokens on the accuracy of reasoning in large language models (LLMs). The blue line (‘With Critical Token’) shows that repeatedly sampling from a reasoning trajectory containing a critical token results in consistently low accuracy, rarely producing correct answers. In contrast, the orange line (‘Without Critical Token’) shows that if the critical token is replaced with another, the accuracy increases dramatically. This demonstrates that these critical tokens are a significant factor leading to incorrect reasoning outcomes in LLMs.
read the caption
Figure 1: Impact of critical tokens on reasoning accuracy. The “With Critical Token” line shows that, without intervention, repeated sampling from the original trajectory consistently fails to produce correct trajectories. In contrast, the “Without Critical Token” line demonstrates that replacing the identified critical token with an alternative drastically increases the likelihood of correct reasoning outcomes. This underscores the significant role of critical tokens in incorrect reasoning trajectories.
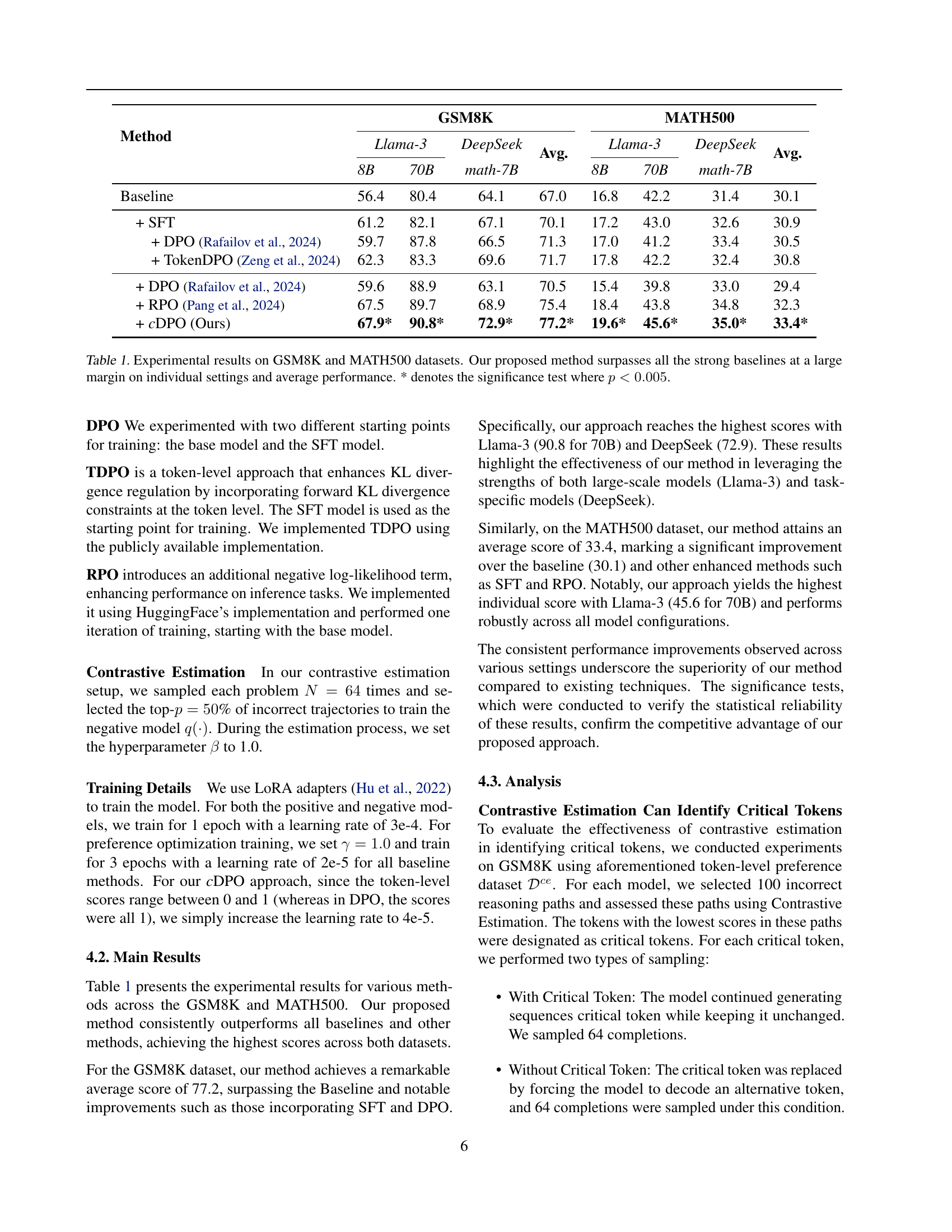
| Method | GSM8K Llama-3 8B | GSM8K Llama-3 70B | GSM8K DeepSeek math-7B | GSM8K Avg. | MATH500 Llama-3 8B | MATH500 Llama-3 70B | MATH500 DeepSeek math-7B | MATH500 Avg. |
|---|---|---|---|---|---|---|---|---|
| Baseline | 56.4 | 80.4 | 64.1 | 64.1 | 67.0 | 16.8 | 42.2 | 31.4 |
| + SFT | 61.2 | 82.1 | 67.1 | 67.1 | 70.1 | 17.2 | 43.0 | 32.6 |
| + DPO (Rafailov et al., 2024) | 59.7 | 87.8 | 66.5 | 66.5 | 71.3 | 17.0 | 41.2 | 33.4 |
| + TokenDPO (Zeng et al., 2024) | 62.3 | 83.3 | 69.6 | 69.6 | 71.7 | 17.8 | 42.2 | 32.4 |
| + DPO (Rafailov et al., 2024) | 59.6 | 88.9 | 63.1 | 63.1 | 70.5 | 15.4 | 39.8 | 33.0 |
| + RPO (Pang et al., 2024) | 67.5 | 89.7 | 68.9 | 68.9 | 75.4 | 18.4 | 43.8 | 34.8 |
| + cDPO (Ours) | 67.9* | 90.8* | 72.9* | 72.9* | 77.2* | 19.6* | 45.6* | 35.0* |
🔼 This table presents a comparison of the performance of various methods on two benchmark datasets for mathematical reasoning: GSM8K and MATH500. The methods include several baselines (SFT, DPO, TokenDPO, DPO+RPO) and the authors’ proposed method, cDPO. Results are shown for three different language models (Llama-3 8B, Llama-3 70B, and DeepSeek-math 7B). The table reports accuracy scores, demonstrating that the cDPO method significantly outperforms all other methods across all models and datasets. The asterisk (*) indicates that the performance difference between cDPO and other methods is statistically significant (p < 0.005).
read the caption
Table 1: Experimental results on GSM8K and MATH500 datasets. Our proposed method surpasses all the strong baselines at a large margin on individual settings and average performance. * denotes the significance test where p<0.005𝑝0.005p<0.005italic_p < 0.005.
In-depth insights#
Critical Token ID#
The concept of “Critical Token ID” in the context of large language model (LLM) reasoning suggests a method to identify specific tokens within a generated text sequence that disproportionately influence the overall outcome. These critical tokens act as pivotal points of failure, potentially leading to incorrect conclusions even if the surrounding reasoning appears sound. Identifying these tokens is crucial for improving LLM reasoning capabilities. A promising approach involves contrastive estimation, comparing the likelihoods of token generation between models trained on correct and incorrect reasoning trajectories. Tokens with significantly different likelihoods between these models are flagged as critical, suggesting their importance in determining the correctness of the final answer. This approach provides a mechanism to directly address and mitigate the negative impact of specific tokens, leading to more reliable and accurate LLM reasoning.
Contrastive DPO#
Contrastive DPO represents a novel approach to aligning Large Language Models (LLMs) with human preferences, particularly for reasoning tasks. It leverages contrastive estimation to identify ‘critical tokens’—tokens within incorrect reasoning trajectories that significantly contribute to erroneous outcomes. By contrasting the likelihoods of these tokens between positive (correct) and negative (incorrect) model predictions, the method effectively pinpoints the source of errors. This information is then incorporated into a modified DPO (Direct Preference Optimization) algorithm, assigning token-level rewards that penalize the generation of critical tokens. This refinement moves beyond example-level or step-level DPO, resulting in finer-grained control over the model’s reasoning process and leading to substantial performance gains. The approach’s strength lies in its ability to automatically identify critical tokens, avoiding costly human annotation or reliance on external models, and its demonstration of superior performance on established reasoning benchmarks.
Token-Level Rewards#
The concept of ‘Token-Level Rewards’ in the context of aligning Large Language Models (LLMs) offers a granular approach to reinforcement learning. Instead of rewarding entire sequences or steps, individual tokens are assessed and rewarded based on their contribution to the overall quality of the generated response. This approach allows for more precise control over the model’s behavior and potentially improves its performance on complex reasoning tasks. The efficacy depends heavily on the ability to accurately identify ‘critical tokens’ – those that significantly impact the outcome, either positively or negatively. A robust method for identifying these critical tokens is therefore crucial to the success of a token-level reward system. Contrastive estimation, as described in the paper, presents a promising method for this task, utilizing the difference in likelihoods between models trained on correct and incorrect trajectories to highlight influential tokens. By focusing on the token level, the algorithm can effectively address the problem of uneven distribution of importance among tokens in a reasoning sequence. This nuanced approach holds the potential to surpass traditional reward mechanisms that often struggle with the complexities of mathematical and logical reasoning, leading to more reliable and accurate LLM outputs. However, the challenge remains in ensuring that the token-level rewards are designed and implemented in a way that doesn’t introduce new biases or overfit the model to specific patterns.
Reasoning Trajectories#
Reasoning trajectories in LLMs represent the step-by-step thought processes models undertake to solve reasoning tasks. Analyzing these trajectories reveals crucial insights into model capabilities and limitations. Critical tokens, specific words or symbols within a trajectory, disproportionately impact the final outcome, often leading to errors even when the overall reasoning approach seems sound. Identifying and addressing these critical tokens is key to improving LLM reasoning performance. The study of reasoning trajectories allows for a granular understanding of how LLMs build chains of thought, highlighting areas where models struggle with logical coherence, factual accuracy, or handling complex reasoning steps. By examining sequences of tokens, researchers can pinpoint precisely where models go astray, facilitating the development of more robust and reliable reasoning methods.
LLM Alignment#
LLM alignment is a critical challenge in the field of large language models (LLMs). The core goal is to ensure that LLMs behave in ways that align with human values and preferences. This involves overcoming several obstacles. Firstly, defining and quantifying these human preferences can be complex and subjective. Different individuals and cultures may have widely varying notions of what constitutes desirable or undesirable behavior in an LLM. Secondly, even with well-defined preferences, training LLMs to effectively meet those standards is difficult. Traditional supervised learning approaches often fall short, requiring sophisticated techniques like reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO). These methods, while showing promise, still suffer from issues such as reward model misspecification and sample inefficiency. Further research is needed to develop more robust and reliable alignment strategies. Addressing potential biases inherent in training data and ensuring the safety and ethical implications of aligned LLMs are also key challenges. Successfully aligning LLMs with human values is crucial for their responsible and beneficial deployment in society.
More visual insights#
More on figures

🔼 Figure 2 shows examples of reasoning trajectories with different tokens. The top example uses the token ‘owed’ and leads to an incorrect answer (93.75 instead of 500). The model’s reasoning is flawed due to the use of this token. The subsequent examples show that replacing ‘owed’ with alternative tokens like ‘paid’ significantly improves the accuracy of the model’s answer, leading to the correct answer of 500. This highlights how a single token can drastically affect the outcome of a reasoning problem.
read the caption
Figure 2: Illustration of the impact of critical tokens on reasoning trajectories. The token “owed” leads to incorrect logical deductions, resulting in erroneous answers. In contrast, decoding alternative tokens like “paid” significantly improves reasoning accuracy, enabling the model to produce correct answers.

🔼 This figure shows how contrastive estimation is used to identify ‘critical tokens’ in incorrect reasoning trajectories. A positive model (trained on correct reasoning trajectories) and a negative model (trained on incorrect trajectories) are used to generate likelihoods for each token. By comparing the likelihoods produced by the two models, tokens that significantly contribute to the incorrectness of a trajectory (the critical tokens) are identified. The difference in likelihoods serves as an indicator of the token’s criticality. Tokens with a large difference in likelihood between the positive and negative models are highlighted as critical.
read the caption
Figure 3: Contrastive estimation identifies critical tokens. This figure illustrates how contrastive estimation identifies critical tokens in incorrect trajectories by comparing the likelihoods of tokens generated by positive model and negative model.

🔼 This figure illustrates the cDPO (Contrastive Direct Preference Optimization) process for aligning LLMs with critical tokens. The process is broken down into two steps. Step 1 involves training two separate models: a positive model trained on correct reasoning trajectories and a negative model trained on incorrect reasoning trajectories. This allows the models to learn distinct patterns associated with correct and incorrect reasoning. Step 2 applies contrastive estimation, comparing the likelihoods of token generation from both the positive and negative models. This comparison helps to automatically identify the ‘critical tokens’ within incorrect trajectories which are highly influential in producing erroneous results. The output of this contrastive estimation informs the cDPO algorithm which utilizes these insights for effective model optimization.
read the caption
Figure 4: Overview of aligning LLMs with critical tokens. The pipeline consists of two steps: (1) fine-tuning positive and negative models on correct and incorrect reasoning trajectories, and (2) applying contrastive estimation for cDPO.

🔼 Figure 5 presents a bar chart comparing the accuracy of three different LLMs (Llama-3 8B, Llama-3 70B, and DeepSeek math-7B) on the GSM8K benchmark. Three scenarios are compared: using the original model with critical tokens, a modified version where critical tokens are excluded, and the proposed cDPO method. The chart clearly demonstrates that removing critical tokens improves accuracy across all models, and that cDPO achieves the best performance. This highlights the effectiveness of contrastive estimation for identifying and mitigating the negative impact of critical tokens during LLM reasoning.
read the caption
Figure 5: The accuracy across models on GSM8K for critical tokens identified by contrastive estimation. The results highlight the effectiveness of contrastive estimation in identifying critical tokens and demonstrate that cDPO achieves the highest performance by leveraging token-level signal from Contrastive Estimation.

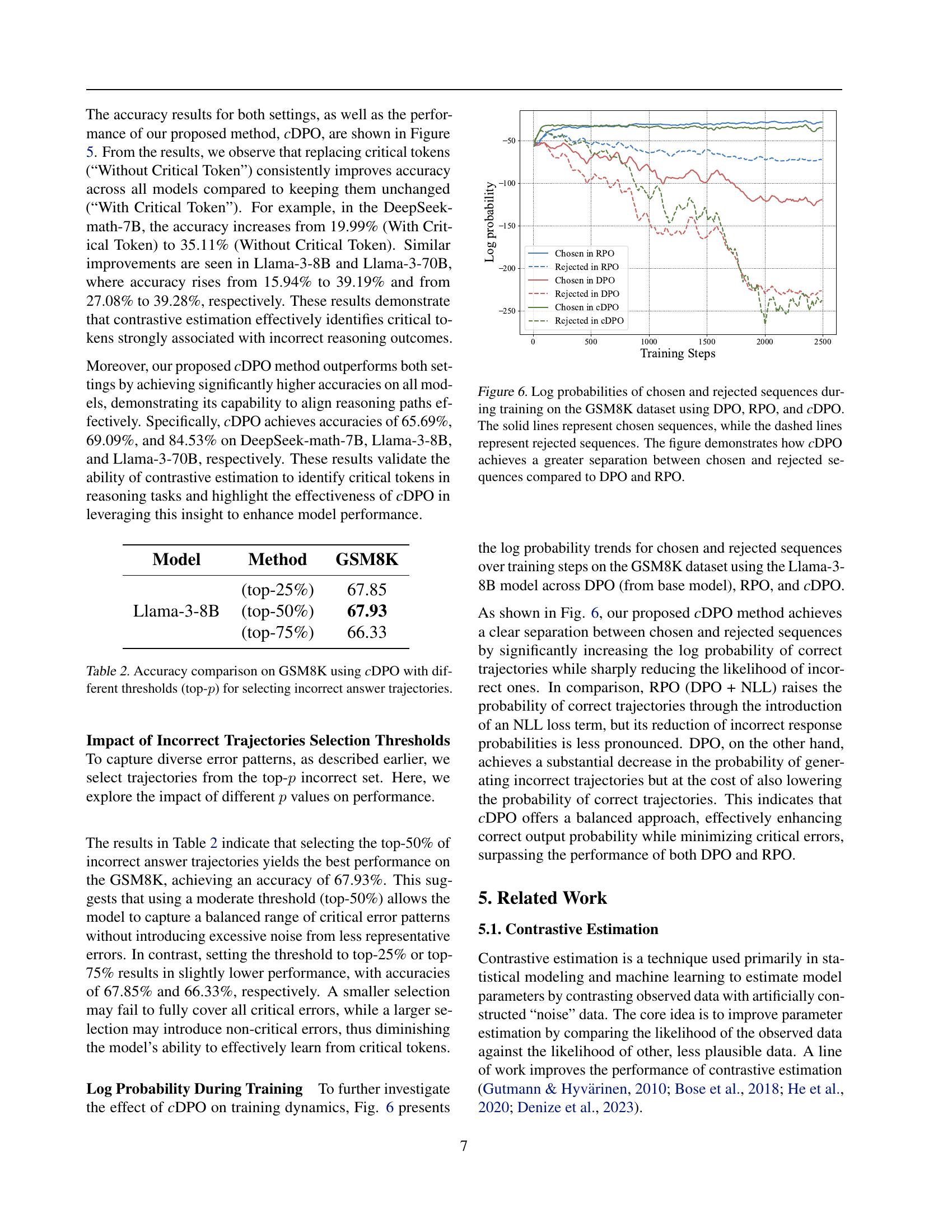
🔼 Figure 6 illustrates the training dynamics of three different preference optimization methods: DPO, RPO, and cDPO, on the GSM8K dataset. The graph plots the log probabilities of sequences chosen and rejected during training for each method. Solid lines represent the log probabilities of chosen sequences, while dashed lines represent the log probabilities of rejected sequences. The key observation is that cDPO achieves a significantly larger gap between the log probabilities of chosen and rejected sequences, compared to DPO and RPO. This demonstrates cDPO’s superior ability to distinguish between high-quality and low-quality sequences during training, resulting in more effective preference optimization.
read the caption
Figure 6: Log probabilities of chosen and rejected sequences during training on the GSM8K dataset using DPO, RPO, and cDPO. The solid lines represent chosen sequences, while the dashed lines represent rejected sequences. The figure demonstrates how cDPO achieves a greater separation between chosen and rejected sequences compared to DPO and RPO.
Full paper#