↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for 3D planar reconstruction from videos struggle with accuracy, consistency, and flexibility due to limitations in plane representation and reconstruction techniques. Existing methods rely on either 2D masks (inconsistent across views) or discrete 3D representations (lacking detail and precision).
This paper introduces AlphaTablets, a new representation defining 3D planes as rectangles with alpha channels. This allows for continuous surfaces and precise boundary delineation. A novel bottom-up pipeline is presented, starting with 2D superpixels, initializing 3D planes as AlphaTablets, and optimizing via differentiable rendering and merging. The results demonstrate state-of-the-art performance on the ScanNet dataset, highlighting AlphaTablets’ potential for various applications.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and generic 3D plane representation, AlphaTablets, significantly improving 3D planar reconstruction from monocular videos. AlphaTablets address limitations of existing methods by combining the advantages of 2D and 3D representations, achieving state-of-the-art performance. This opens new avenues for research in scene modeling, mixed reality, and robotics.
Visual Insights#

🔼 Figure 1 illustrates the properties of an AlphaTablet and its rendering process. An AlphaTablet represents a 3D plane as a rectangular primitive with associated properties: a normal vector and an up vector determine its 3D orientation, while a distance ratio maintains a consistent scale relationship between its 3D coordinates and its 2D projection in pixel space. This ensures accurate and consistent representation of the tablet across different viewpoints.
read the caption
Figure 1: Illustration of tablet properties and rendering. Normal and up vector determines the rotation of a tablet in 3D space, while every tablet maintains a distance ratio between the coordinates of the 3D field and 2D-pixel space.
| Method | Comp ↓ | Acc ↓ | Recall ↑ | Prec ↑ | F-Score ↑ |
|---|---|---|---|---|---|
| NeuralRecon [46] + Seq-RANSAC | 0.144 | 0.128 | 0.296 | 0.306 | 0.296 |
| Atlas [31] + Seq-RANSAC | 0.102 | 0.190 | 0.316 | 0.348 | 0.331 |
| ESTDepth [29] + PEAC [13] | 0.174 | 0.135 | 0.289 | 0.335 | 0.304 |
| PlanarRecon [50] | 0.154 | 0.105 | 0.355 | 0.398 | 0.372 |
| Metric3D [19] + Seq-RANSAC | 0.074 | 0.379 | 0.426 | 0.161 | 0.231 |
| SuGaR [18] + Seq-RANSAC | 0.121 | 0.324 | 0.385 | 0.296 | 0.327 |
| Ours | 0.108 | 0.161 | 0.481 | 0.447 | 0.456 |
🔼 This table presents a quantitative comparison of different methods for 3D geometry reconstruction on the ScanNet dataset. It shows the performance of various techniques in terms of completeness accuracy (Comp Acc), recall (Recall), precision (Prec), and F-score. Lower completeness accuracy indicates that the methods did not reconstruct all the surfaces. Higher recall, precision and F-score values represent better performance.
read the caption
Table 1: 3D geometry reconstruction results on ScanNet.
In-depth insights#
AlphaTablets: A Novel 3D Plane Representation#
The proposed AlphaTablets representation offers a novel approach to 3D plane modeling by combining the strengths of 2D and 3D methods. Representing planes as textured rectangles with alpha channels enables both precise boundary definition and the modeling of continuous surfaces. This addresses limitations of previous methods that either lacked precise boundaries (2D masks) or suffered from discontinuous geometry (3D point clouds, surfels). The use of alpha channels allows for the representation of complex, irregular shapes, and the incorporation of texture maps adds realism and detail. The authors’ claim of efficient and consistent modeling across multiple views due to the 3D representation is a significant advantage, potentially simplifying the reconstruction process from monocular videos. The integration of differentiable rasterization further enhances the representation’s utility by facilitating efficient optimization within a learning-based framework. Overall, AlphaTablets presents a promising representation capable of advancing 3D planar reconstruction techniques.
Differentiable Rendering#
Differentiable rendering is a crucial technique in modern computer graphics and machine learning, enabling the optimization of 3D scene parameters by backpropagating errors from rendered images. Its core idea lies in making the rendering process differentiable, allowing gradients to flow through the rendering pipeline and be used to adjust 3D models, camera parameters, lighting conditions, and other scene elements to better match a target image or achieve a specific visual effect. This is particularly relevant for applications like neural rendering and inverse rendering, where the goal is to reconstruct 3D scenes from images or videos. In the context of 3D planar reconstruction, differentiable rendering allows for efficient optimization of plane parameters such as position, orientation, and texture, leading to accurate and complete 3D plane models. Furthermore, the capability of differentiable rendering facilitates flexible modeling of planes with irregular shapes and semi-transparent surfaces by incorporating alpha channels into the rendering process. This offers a significant advantage over traditional methods that often rely on simpler representations and assumptions, leading to more realistic and detailed 3D reconstructions.
Bottom-Up Reconstruction#
A bottom-up reconstruction approach for 3D planar scene understanding is a powerful technique that leverages readily available 2D information (such as superpixels) and integrates it with higher-level geometric cues (e.g., depth, normals) from pre-trained models. This approach is particularly useful when dealing with monocular videos, where direct 3D information is scarce. The iterative optimization and refinement of these initial 3D plane estimations are key strengths of this approach. The differentiable rendering of the planes is particularly valuable, allowing for the efficient optimization of the planes within the image space. Merging neighboring planes into larger, more coherent structures is another important component of this process. This merging scheme improves the overall accuracy and completeness of the final reconstruction, ultimately helping to achieve accurate and detailed 3D planar surface representations. The process starts with small, possibly overlapping planes which grow and merge into larger ones, improving the reconstruction process by allowing for better handling of complex shapes and resolving ambiguities. The iterative refinement, differentiable rendering, and merging scheme make this an effective way to achieve a high-quality 3D reconstruction.
Ablation & Future Work#
The section on “Ablation and Future Work” would ideally delve into a systematic analysis of the proposed AlphaTablets method. Ablation studies should isolate the effects of individual components—the differentiable rasterization, the merging scheme, specific loss functions (photometric, alpha inverse, distortion, depth, and normal)—to demonstrate their relative contributions to the overall accuracy and robustness. This would involve systematically removing or modifying each component and quantifying the impact on key metrics (such as completeness, accuracy, and F-score). The results would justify design choices and highlight the most critical aspects of the AlphaTablets pipeline. Regarding future work, the authors should explore extensions to handle challenging scenarios like highly non-planar scenes where the planar assumption of AlphaTablets might not hold. Integrating view-dependent effects to address lighting variations and non-Lambertian surfaces is crucial for improving realism and generalizability. Furthermore, exploring hybrid representations by incorporating other primitives (such as Gaussians) alongside AlphaTablets could improve performance on complex scenes with a mixture of planar and non-planar structures. Finally, addressing potential privacy concerns related to the collection and use of 3D scene data through robust security measures would be a valuable contribution.
Limitations & Challenges#
The research on 3D planar reconstruction from monocular videos, while showing promise with AlphaTablets, faces several limitations and challenges. Accuracy is heavily dependent on the quality of initial depth and normal estimations, meaning that errors in these initial steps propagate through the pipeline. The assumption of planar surfaces is not always valid, especially in real-world scenarios with complex geometries. The approach struggles in highly textured or non-Lambertian surfaces, as photometric consistency is crucial for accurate results. The current method also lacks explicit handling of view-dependent effects, leading to potential inaccuracies in reconstruction, and the computational cost, particularly during the initialization and merging stages, is relatively high. Finally, generalizability across diverse scenes and viewpoints requires further investigation, as the current model’s performance is highly influenced by the specific characteristics of the training dataset. Future work should focus on improving robustness to noise and various scene conditions.
More visual insights#
More on figures

🔼 This figure illustrates the pipeline for 3D planar reconstruction using AlphaTablets. Starting with a monocular video, the process begins by initializing AlphaTablets using pre-trained models for superpixel segmentation, depth estimation, and surface normal estimation. These initial AlphaTablets are then iteratively refined. First, an optimization step adjusts their geometry and texture using photometric guidance (comparing rendered images to actual video frames). Second, a merging scheme combines neighboring AlphaTablets to create larger, more coherent planar structures. This iterative optimization and merging process continues until accurate and complete 3D planar reconstructions are achieved.
read the caption
Figure 2: Pipeline of our proposed 3D planar reconstruction. Given a monocular video as input, we first initialize AlphaTablets using off-the-shelf superpixel, depth, and normal estimation models. The 3D AlphaTablets are then optimized through photometric guidance, followed by the merging scheme. This iterative process of optimization and merging refines the 3D AlphaTablets, resulting in accurate and complete 3D planar reconstruction.

🔼 This figure displays a qualitative comparison of 3D plane reconstruction results on the ScanNet dataset. Several methods are shown: Metric3D + Seq-RANSAC, SuGaR + Seq-RANSAC, PlanarRecon, and the proposed ‘Ours’ method. For each method, the reconstructed 3D planes are visualized alongside an error map to highlight discrepancies from the ground truth. The ‘high’ and ’low’ labels refer to the error level, indicating the accuracy of the reconstruction. The image is best viewed at a zoomed-in scale to better appreciate the details of the reconstruction and error maps.
read the caption
Figure 3: Qualitative results on ScanNet. Error maps are included. Better viewed when zoomed in.

🔼 This figure shows qualitative results comparing the proposed AlphaTablets method to other state-of-the-art methods on two benchmark datasets: TUM-RGBD and Replica. The visualizations showcase the reconstructed 3D planar surfaces. This allows for a visual comparison of accuracy and completeness of plane reconstruction in different scene types and complexities. The results demonstrate the generalization capability of AlphaTablets across various datasets.
read the caption
Figure 4: Qualitative results on TUM-RGBD and Replica datasets.

🔼 This figure shows examples of 3D scene editing using the AlphaTablets method. The original scene is shown, followed by the results of editing using AlphaTablets. The editing examples include changing textures, colors, and applying various visual effects. This demonstrates the flexibility and precision of the AlphaTablets method for manipulating 3D scenes.
read the caption
Figure 5: 3D scene editing examples of our method.
🔼 This figure shows a qualitative comparison of two different initialization methods for the SuGaR (Surface-Aligned Gaussian Splatting) algorithm used in 3D plane reconstruction. It visually compares the results obtained using COLMAP initialization versus Metric3D initialization. The comparison highlights the impact of the chosen initialization method on the final quality and accuracy of the 3D plane reconstruction generated by the SuGaR method.
read the caption
Figure 6: Qualitative Comparison of Initialization Methods for SuGaR.

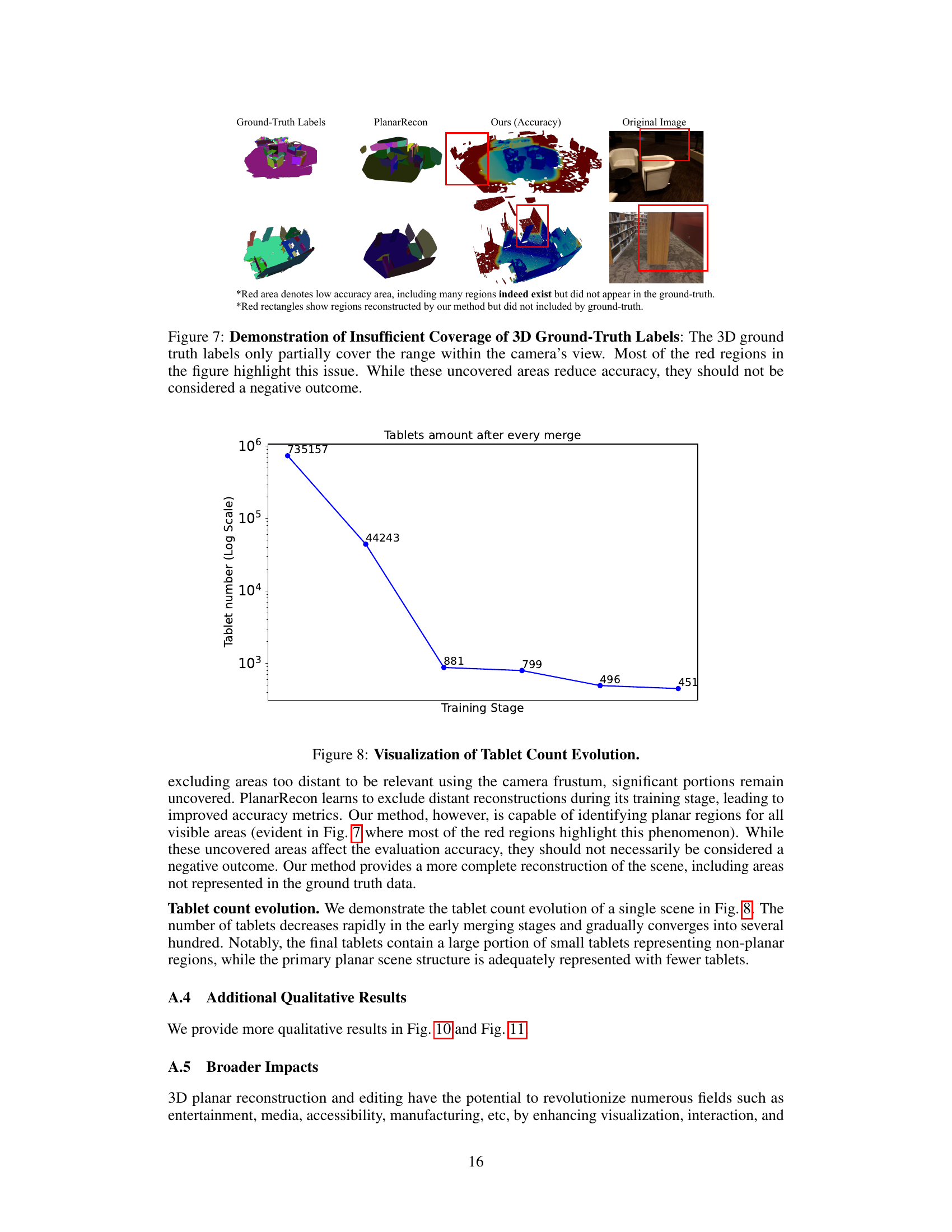
🔼 Figure 7 demonstrates a crucial limitation in the ScanNet dataset’s ground truth data for evaluating 3D planar reconstruction. The ground truth labels only cover a limited portion of the scene within the camera’s view, neglecting significant portions of the scene. The red regions in the figure highlight these areas not included in the ground truth data but present in the scene, showcasing the dataset’s insufficient coverage of 3D planes. These discrepancies reduce the accuracy of the quantitative evaluation metrics, but do not reflect a shortcoming of the 3D plane reconstruction itself, as the model is still accurately reconstructing areas outside the ground truth scope.
read the caption
Figure 7: Demonstration of Insufficient Coverage of 3D Ground-Truth Labels: The 3D ground truth labels only partially cover the range within the camera’s view. Most of the red regions in the figure highlight this issue. While these uncovered areas reduce accuracy, they should not be considered a negative outcome.

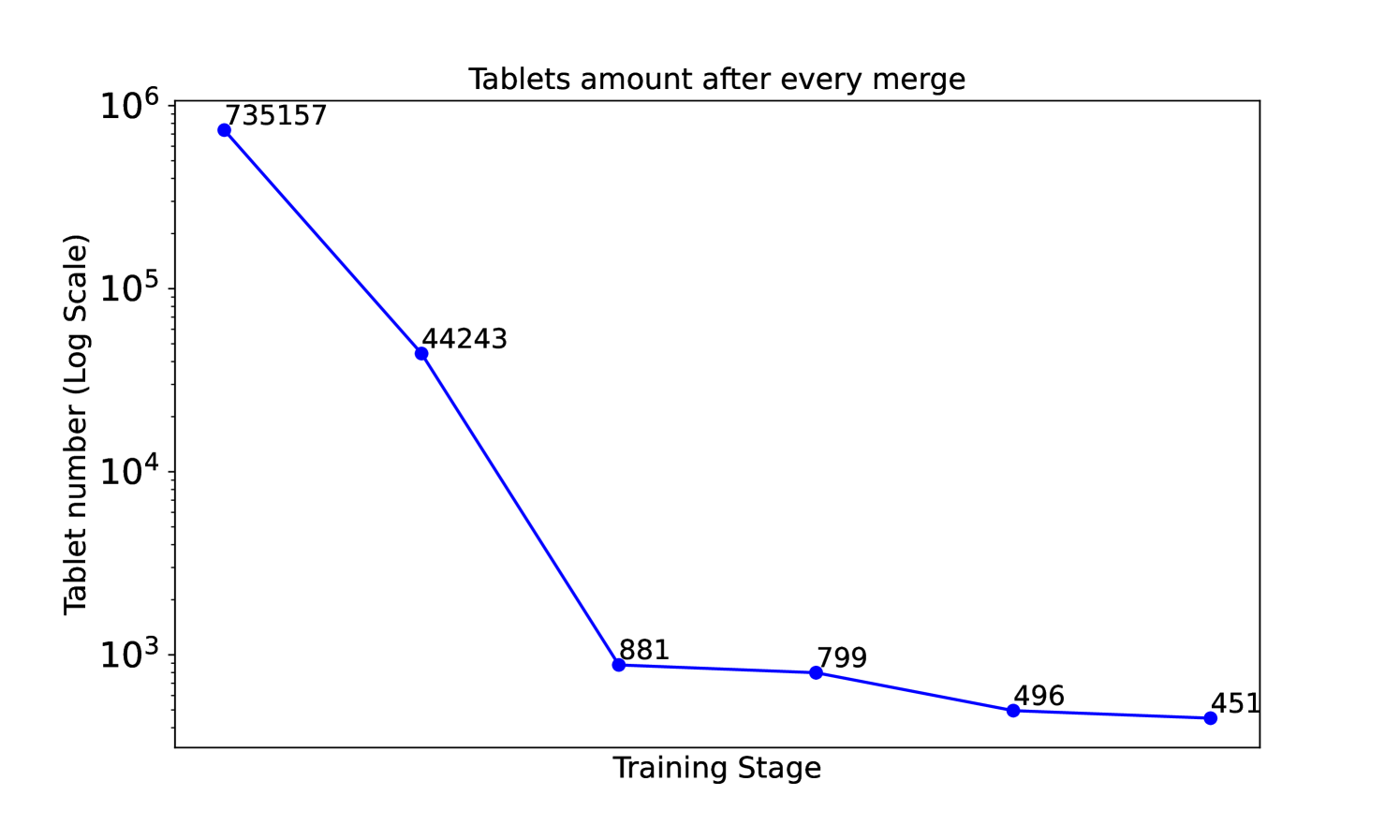
🔼 This figure shows a graph illustrating the evolution of the number of AlphaTablets during the training process. It starts with a large number of tablets in the initialization stage, which gradually decreases as the tablets merge during optimization. The x-axis represents the training stage, and the y-axis represents the number of tablets on a logarithmic scale. The graph shows how the number of tablets decreases over several training stages, finally converging to a smaller number of larger, more coherent tablets representing the final 3D planar reconstruction.
read the caption
Figure 8: Visualization of Tablet Count Evolution.
More on tables
| Method | VOI ↓ | RI ↑ | SC ↑ |
|---|---|---|---|
| NeuralRecon [46] + Seq-RANSAC | 8.087 | 0.828 | 0.066 |
| Atlas [31] + Seq-RANSAC | 8.485 | 0.838 | 0.057 |
| ESTDepth [29] + PEAC [13] | 4.470 | 0.877 | 0.163 |
| PlanarRecon [50] | 3.622 | 0.897 | 0.248 |
| Metric3D [19] + Seq-RANSAC | 4.648 | 0.862 | 0.209 |
| SuGaR [18] + Seq-RANSAC | 5.558 | 0.775 | 0.082 |
| Ours | 3.468 | 0.928 | 0.273 |
🔼 This table presents a quantitative comparison of different methods for 3D plane segmentation on the ScanNet dataset. It shows the performance of various approaches in terms of three metrics: Variation of Information (VOI), Rand Index (RI), and Segmentation Covering (SC). Lower VOI indicates better segmentation quality, while higher RI and SC values represent better agreement with the ground truth. The table allows for a direct comparison of the proposed method’s performance against several baselines.
read the caption
Table 2: 3D plane segmentation results on ScanNet.
| TUM Dataset | TUM Dataset | Replica Dataset | Replica Dataset |
|---|---|---|---|
 |  |  |  |
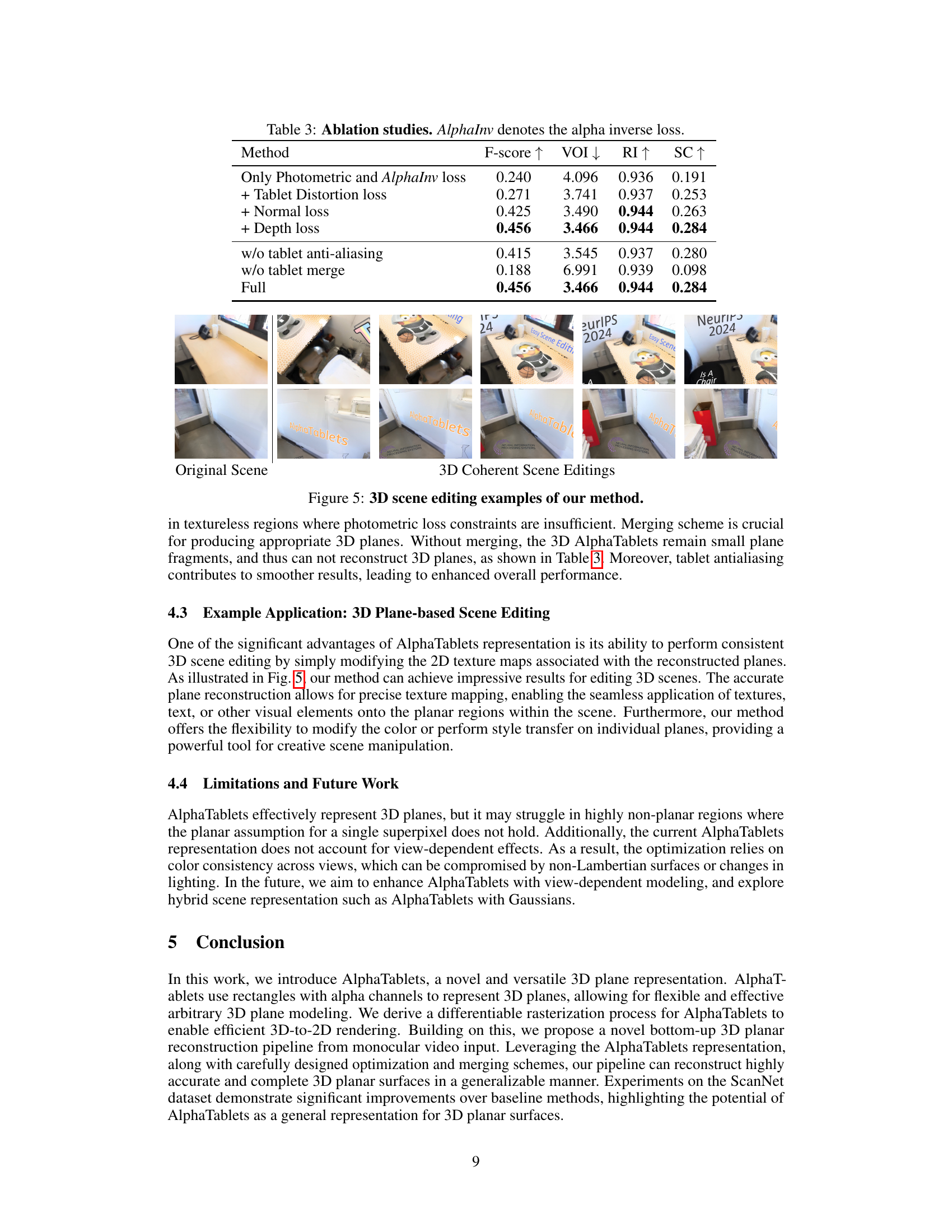
🔼 This table presents the results of ablation studies conducted to evaluate the impact of different components on the overall performance of the proposed 3D planar reconstruction method. The ablation studies systematically remove or modify individual components, such as loss functions (photometric loss, alpha inverse loss, tablet distortion loss, normal loss, and depth loss) and processing steps (anti-aliasing and tablet merging), to assess their individual contributions to the final accuracy of plane detection and reconstruction. The metrics used to evaluate performance are F-score, Variation of Information (VOI), Rand Index (RI), and Segmentation Covering (SC). AlphaInv in the caption refers to alpha inverse loss.
read the caption
Table 3: Ablation studies. AlphaInv denotes the alpha inverse loss.
| Method | F-score ↑ | VOI ↓ | RI ↑ | SC ↑ |
|---|---|---|---|---|
| Only Photometric and AlphaInv loss | 0.240 | 4.096 | 0.936 | 0.191 |
| + Tablet Distortion loss | 0.271 | 3.741 | 0.937 | 0.253 |
| + Normal loss | 0.425 | 3.490 | 0.944 | 0.263 |
| + Depth loss | 0.456 | 3.466 | 0.944 | 0.284 |
| w/o tablet anti-aliasing | 0.415 | 3.545 | 0.937 | 0.280 |
| w/o tablet merge | 0.188 | 6.991 | 0.939 | 0.098 |
| Full | 0.456 | 3.466 | 0.944 | 0.284 |
🔼 This table presents the ablation study results on the impact of different initial merge strategies on the overall performance of the 3D planar reconstruction pipeline. It compares the F-score, Variation of Information (VOI), Rand Index (RI), and Segmentation Covering (SC) metrics across four different scenarios: 1) without any initial merging, 2) with only in-training merging, 3) with only initial merging, and 4) using all merging schemes. The results show the effect of the initial merging step on the accuracy and efficiency of 3D plane reconstruction.
read the caption
Table 4: Ablation studies on initial merge.
🔼 This table presents the ablation study results comparing the performance of the SuGaR method using different initialization strategies. Specifically, it shows the impact of using COLMAP initialization versus Metric3D initialization on the final F-score, Variation of Information (VOI), Rand Index (RI), and Segmentation Covering (SC) metrics. This helps to understand how the choice of initialization method influences the overall accuracy and quality of the 3D plane reconstruction.
read the caption
Table 5: Ablation studies on different initialization of SuGaR.
| Method | F-score ↑ | VOI ↓ | RI ↑ | SC ↑ |
|---|---|---|---|---|
| w/o in-training merge and init merge | 0.188 | 6.991 | 0.939 | 0.098 |
| w/o in-training merge | 0.438 | 5.171 | 0.941 | 0.138 |
| w/o init merge | 0.454 | 3.754 | 0.944 | 0.273 |
| w/ all merge schemes | 0.456 | 3.466 | 0.944 | 0.284 |
🔼 This table details the time taken for each stage of the 3D planar reconstruction pipeline processing a single scene. It breaks down the time spent on initialization (setting up texture and geometry), rendering (creating pseudo-meshes, rasterizing, compositing), loss calculation (computing various loss values), training (backpropagation), and merging (combining AlphaTablets). This provides insight into the computational cost of each step in the pipeline.
read the caption
Table 6: Breakdown of the time budget of a single scene.
Full paper#