TL;DR#
Current conversational AI agents are limited by their reliance on text or voice interaction, lacking the natural expressiveness of human communication. This paper tackles the challenge of creating 3D autonomous characters capable of truly immersive and natural interactions, which requires overcoming the significant hurdle of a limited amount of multimodal interaction data. The scarcity of data makes it difficult to train models that understand and respond appropriately to both speech and body language.
To address these issues, the researchers developed SOLAMI, a novel framework for social vision-language-action modeling. SOLAMI uses a unified social VLA framework to generate multimodal responses based on user input, improving the naturalness and responsiveness of the interaction. The framework was trained on a new synthetic multimodal dataset they created (SynMSI), which addresses the lack of available data for social interaction. An immersive VR interface was also developed to make the interaction more realistic and engaging. Their experiments show improved character responses, demonstrating the efficacy of their approach in bridging the gap between current technology and truly natural human interaction.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in human-computer interaction, AI, and virtual reality. It introduces SOLAMI, a novel framework for creating more realistic and engaging interactions with 3D characters, addressing the scarcity of multimodal datasets and improving interaction latency. This opens new avenues for research in embodied AI, conversational agents, and immersive experiences.
Visual Insights#
🔼 This figure illustrates the SOLAMI system, which allows users to interact with 3D autonomous characters in an immersive virtual reality (VR) environment using both speech and body language. The system employs an end-to-end social vision-language-action (VLA) model. The user’s speech and body language are captured as input through multi-modal capture. This input is processed by the VLA model, which generates corresponding character motion and speech as output. The figure shows the various components of the system, including multi-modal capture, motion and speech tokenization, the social VLA modeling, character motion and speech generation, and interactive tasks. The model is trained using a synthesized multimodal dataset called SynMSI.
read the caption
Figure 1: SOLAMI enables the user to interact with 3D autonomous characters through speech and body language in an immersive VR environment via an end-to-end social vision-language-action model, which is trained on our synthesized multimodal dataset SynMSI.
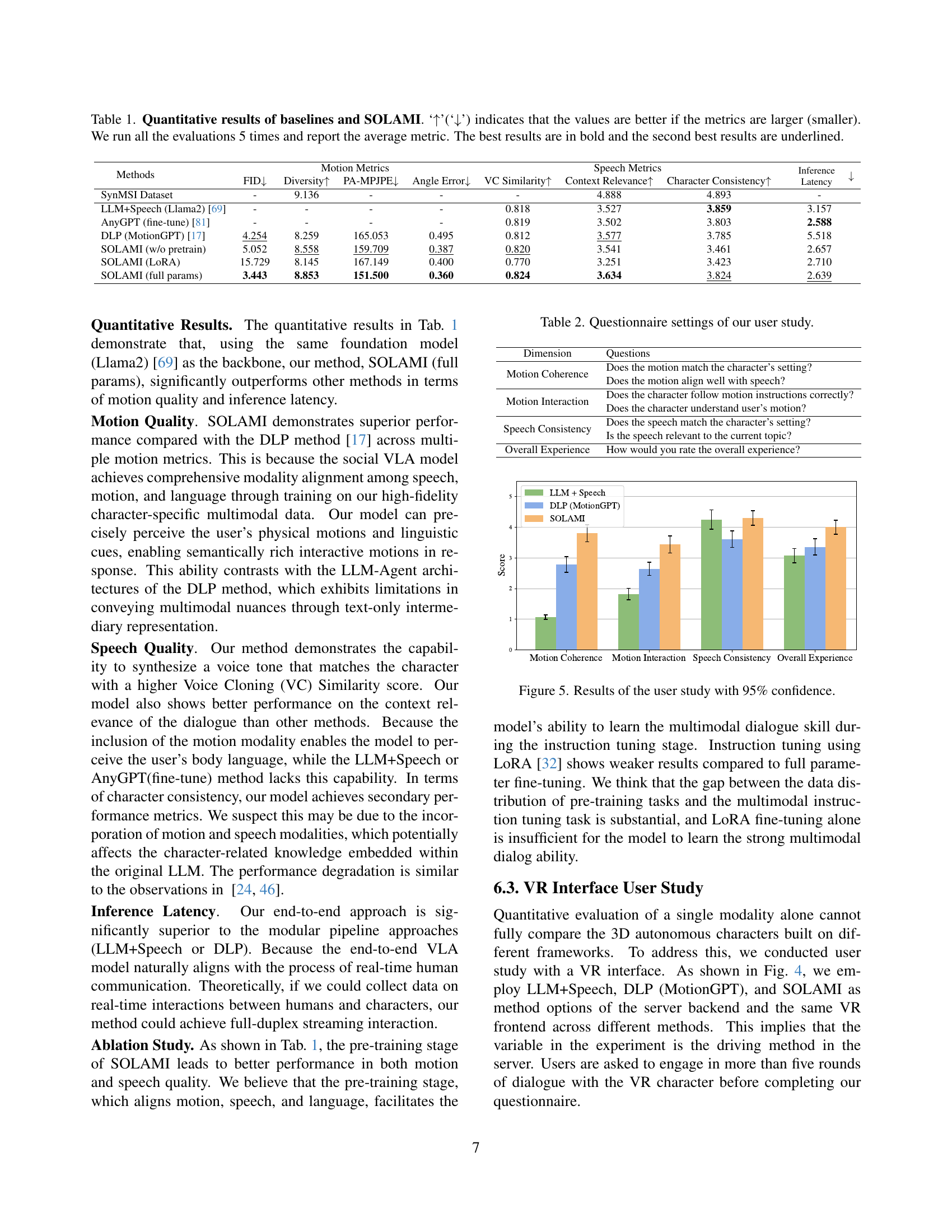
| Methods | FID ↓ | Diversity ↑ | PA-MPJPE ↓ | Angle Error ↓ | VC Similarity ↑ | Context Relevance ↑ | Character Consistency ↑ | Inference ↓ | Latency ↓ |
|---|---|---|---|---|---|---|---|---|---|
| SynMSI Dataset | - | 9.136 | - | - | - | 4.888 | 4.893 | - | - |
| LLM+Speech (Llama2) [69] | - | - | - | - | 0.818 | 3.527 | 3.859 | - | - |
| AnyGPT (fine-tune) [81] | - | - | - | - | 0.819 | 3.502 | 3.803 | - | - |
| DLP (MotionGPT) [17] | 4.254 | 8.259 | 165.053 | 0.495 | 0.812 | 3.577 | 3.785 | 5.518 | |
| SOLAMI (w/o pretrain) | 5.052 | 8.558 | 159.709 | 0.387 | 0.820 | 3.541 | 3.461 | 2.657 | |
| SOLAMI (LoRA) | 15.729 | 8.145 | 167.149 | 0.400 | 0.770 | 3.251 | 3.423 | 2.710 | |
| SOLAMI (full params) | 3.443 | 8.853 | 151.500 | 0.360 | 0.824 | 3.634 | 3.824 | 2.639 |
🔼 This table presents a quantitative comparison of SOLAMI against several baseline methods across various metrics related to motion and speech quality. Lower values are better for FID and PA-MPJPE, while higher values are preferred for Diversity, Angle Error, VC Similarity, Context Relevance, and Character Consistency. Inference Latency is also compared. The evaluation was conducted five times for each method, and the table displays the average results. Bold values indicate the best performance, and underlined values represent the second-best performance.
read the caption
Table 1: Quantitative results of baselines and SOLAMI. ‘↑↑\uparrow↑’(‘↓↓\downarrow↓’) indicates that the values are better if the metrics are larger (smaller). We run all the evaluations 5 times and report the average metric. The best results are in bold and the second best results are underlined.
In-depth insights#
Social VLA Modeling#
The concept of “Social VLA Modeling” integrates vision, language, and action to create believable and engaging interactions with 3D autonomous characters. It’s a significant advancement over prior methods that relied on text-based interactions, enhancing the user experience with natural speech and realistic motion responses. The core innovation lies in a unified framework that processes multimodal input (speech and body language) to generate coordinated multimodal outputs (speech and motion), minimizing latency. This approach moves beyond the limitations of LLM-agent architectures that rely on text-based intermediary steps, leading to more natural and nuanced interactions. The model’s success depends heavily on the availability of high-quality training data; the use of a synthetic multimodal dataset, SynMSI, addresses data scarcity challenges. Immersive VR integration further elevates the realism and engagement, making it truly groundbreaking for immersive social interaction with 3D characters.
SynMSI Dataset#
The SynMSI dataset is a crucial contribution of this research, addressing the scarcity of multimodal social interaction data for training AI agents. Its synthetic nature is a clever solution to the high cost and effort of collecting real-world data, leveraging existing motion capture datasets and advanced LLMs (like GPT-4) to generate realistic multi-round interactions. The pipeline cleverly combines motion data with text-based role-playing models and speech synthesis to create a large-scale dataset (6.3K multi-turn multimodal conversations). This approach is not only cost-effective but also allows for control over the diversity of interaction scenarios and character characteristics. However, the synthetic nature presents both advantages and disadvantages. While it allows for the creation of a large dataset with specific characteristics, it also raises concerns about generalizability and whether the synthesized interactions truly reflect the nuances of natural human-computer interaction. Further research is needed to explore techniques to improve the realism and representativeness of synthetic data, potentially through incorporating real-world data where possible, or using more advanced models for data generation. The success of SynMSI hinges on the effectiveness of the data generation pipeline and the quality of the underlying motion datasets and LLMs. The paper should ideally include more detailed analyses of data quality, including metrics to evaluate the realism and diversity of the synthesized interactions.
Immersive VR#
The concept of “Immersive VR” in this research paper focuses on creating a realistic and engaging virtual reality experience for users to interact with 3D autonomous characters. The goal is to move beyond traditional text or voice-based interactions, allowing for more natural and nuanced communication using speech and body language. The immersive VR environment is crucial for enhancing the sense of presence and social realism, enabling users to feel as if they are truly interacting with a virtual companion. This is achieved by enabling users to control their actions within the VR environment using natural human input methods like body motion and speech. This technology has profound implications, pushing the boundaries of human-computer interaction. The success of this approach hinges on the realism of both the characters and the virtual environment as well as the seamless integration of input and output modalities. The paper’s emphasis on developing a unified social vision-language-action (VLA) model underlines the complexity of this goal. Creating a truly immersive and natural social interaction in VR necessitates advancements in both the rendering of realistic characters with dynamic behavior and the processing of complex multimodal user inputs with low latency. The described VR interface itself, as a part of this system, is vital for the overall experience, providing the user with intuitive interactions and a believable virtual setting.
Ablation Study#
The ablation study systematically evaluates the contribution of different components within the SOLAMI framework. By removing or modifying key elements like the pre-training stage or the motion tokenizer, the researchers isolate their impact on the model’s performance. The results highlight the crucial role of the pre-training stage in achieving superior results in motion and speech quality, demonstrating the effectiveness of aligning the speech and motion modalities with language during this phase. Omitting this step led to a significant performance drop, emphasizing its contribution to robust multimodal understanding and response generation. Furthermore, the study compares different motion representation strategies, showing that using separate tokenizers for body and hand motions outperforms a unified approach, demonstrating the benefit of a more nuanced representation for improved motion quality. These findings provide valuable insights into the architecture and training processes, offering actionable guidance for future improvements and optimization of the SOLAMI framework.
Future Work#
The authors thoughtfully acknowledge the limitations of their current work and propose several promising avenues for future research. They highlight the need for expanding input modalities beyond speech and motion, suggesting the integration of video and 3D scene understanding for more immersive and realistic interactions. Data collection is identified as a crucial area for improvement, advocating for the creation of a larger, real-world dataset encompassing complex social scenarios. They also address the current limitations of the model’s ability to represent diverse characters effectively, proposing research into improved cross-embodiment techniques for enhanced realism. Addressing the computational challenges associated with long-term interactions is another key area, with suggestions for incorporating long-term memory and advanced learning methods to mitigate computational overhead and improve training efficiency. Finally, the authors acknowledge the long-tail distribution inherent in human motion data and suggest exploring alternative learning strategies to better handle this challenge, potentially including leveraging foundation models and incorporating human feedback into the training process. This demonstrates a forward-looking approach, strategically identifying key challenges and suggesting concrete solutions for enhancing the model’s capabilities.
More visual insights#
More on figures
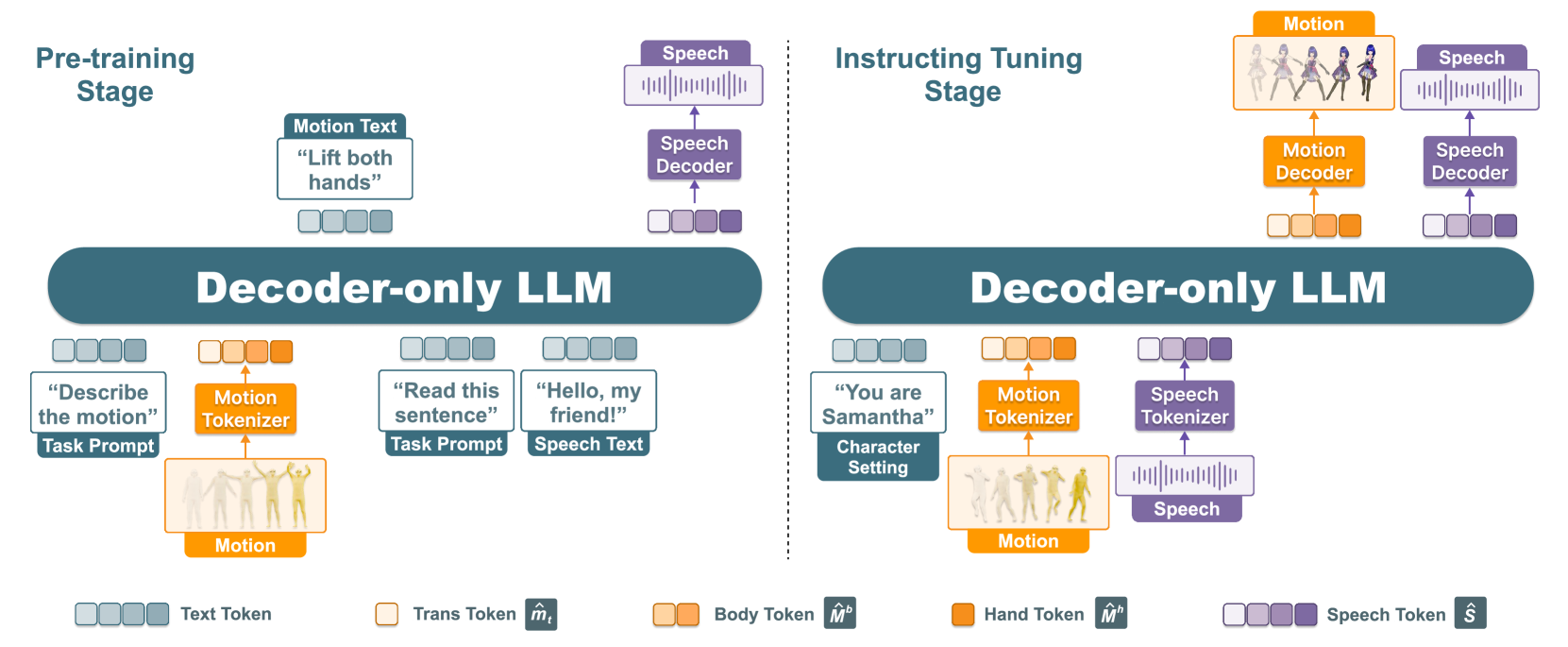
🔼 The figure illustrates the three-stage training pipeline for the SOLAMI model. The pre-training stage focuses on aligning speech and motion modalities with language using motion-text and speech-text paired data. This stage helps the model learn the relationships between different modalities. The instruction tuning stage utilizes social multimodal multi-round interaction data to train the model to generate appropriate multimodal responses based on the character’s setting and conversational context. This stage teaches the model to engage in natural, context-aware interactions. The figure visually depicts these stages, showing the data used and the model’s output.
read the caption
Figure 2: Training pipeline of SOLAMI. We train SOLAMI through a three-stage process. In the pre-training stage, we train the model with motion-text and speech-text related tasks to align the speech and motion modalities with language. During the instruction tuning stage, we train the model with social multimodal multi-round interaction data, enabling it to generate multimodal responses that align with the character settings and the context of the topic.
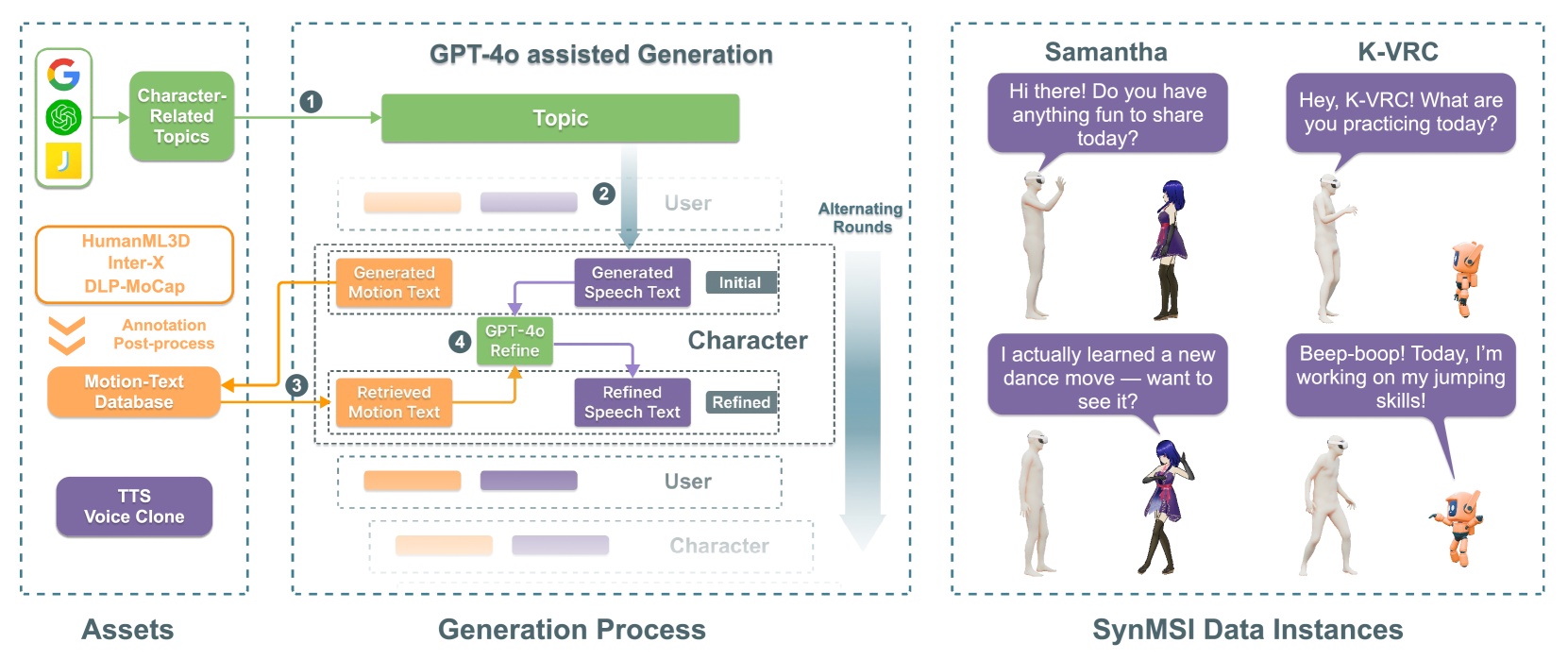
🔼 This figure illustrates the four-step synthesis pipeline used to create the SynMSI dataset. First, character-relevant topics are identified using LLMs to generate text scripts for multimodal dialogues. Second, a large-scale motion database is used to select the most suitable motions for the generated scripts, and the speech scripts are refined accordingly. Third, character-specific speech is generated using TTS or voice cloning technology. Finally, the combined data produces multimodal interaction data for various characters, leveraging only pre-existing motion datasets.
read the caption
Figure 3: SynMSI dataset generation. Our synthesizing pipeline consists of 4 steps. Based on numerous character-relevant topics and state-of-the-art LLMs [52], we generate text scripts for multimodal dialogues. Using a large-scale motion database [76, 29, 17], we retrieve the most appropriate motions and refine the speech scripts accordingly. Finally, we employ TTS/voice cloning [19] to generate character-specific speech. This approach enables us to create multimodal interaction data of various characters using only existing motion datasets.
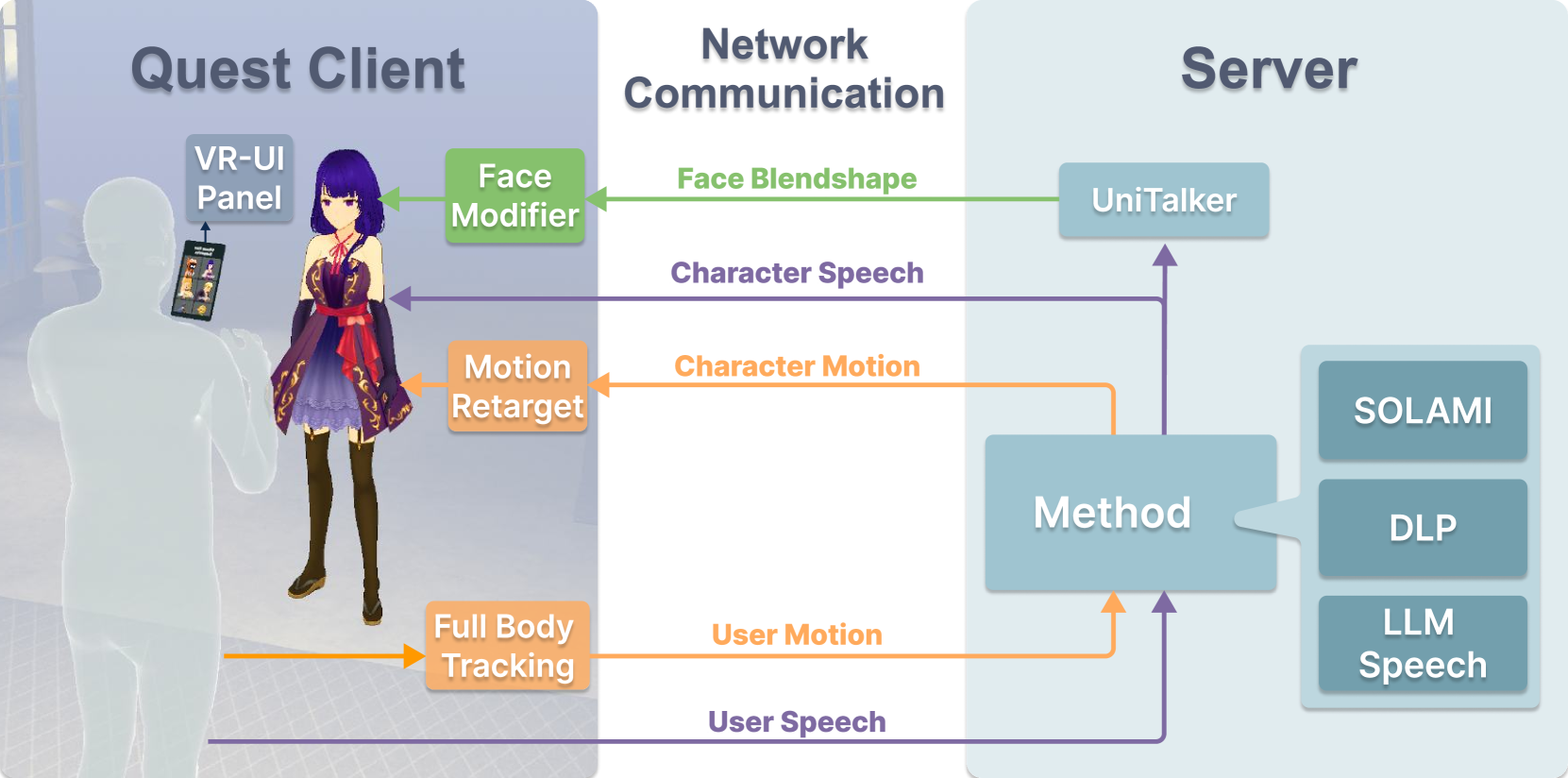
🔼 The VR system architecture comprises a Quest 3 client and a server. The Quest 3 client captures user speech and body motion data, transmitting it to the server. The server processes this data using chosen methods (e.g., SOLAMI) to generate a character’s response including speech, body motion, and facial expressions (blendshapes). This generated response is then sent back to the Quest 3 client for real-time animation of the 3D character.
read the caption
Figure 4: VR interface architecture. Our VR project consists of a Quest 3 client and a server. The Quest client captures and transmits user body motion and speech to the server. The server then generates character’s speech, body motion, and face blendshape parameters based on the selected methods. The response is then sent back to the Quest client to drive the character.

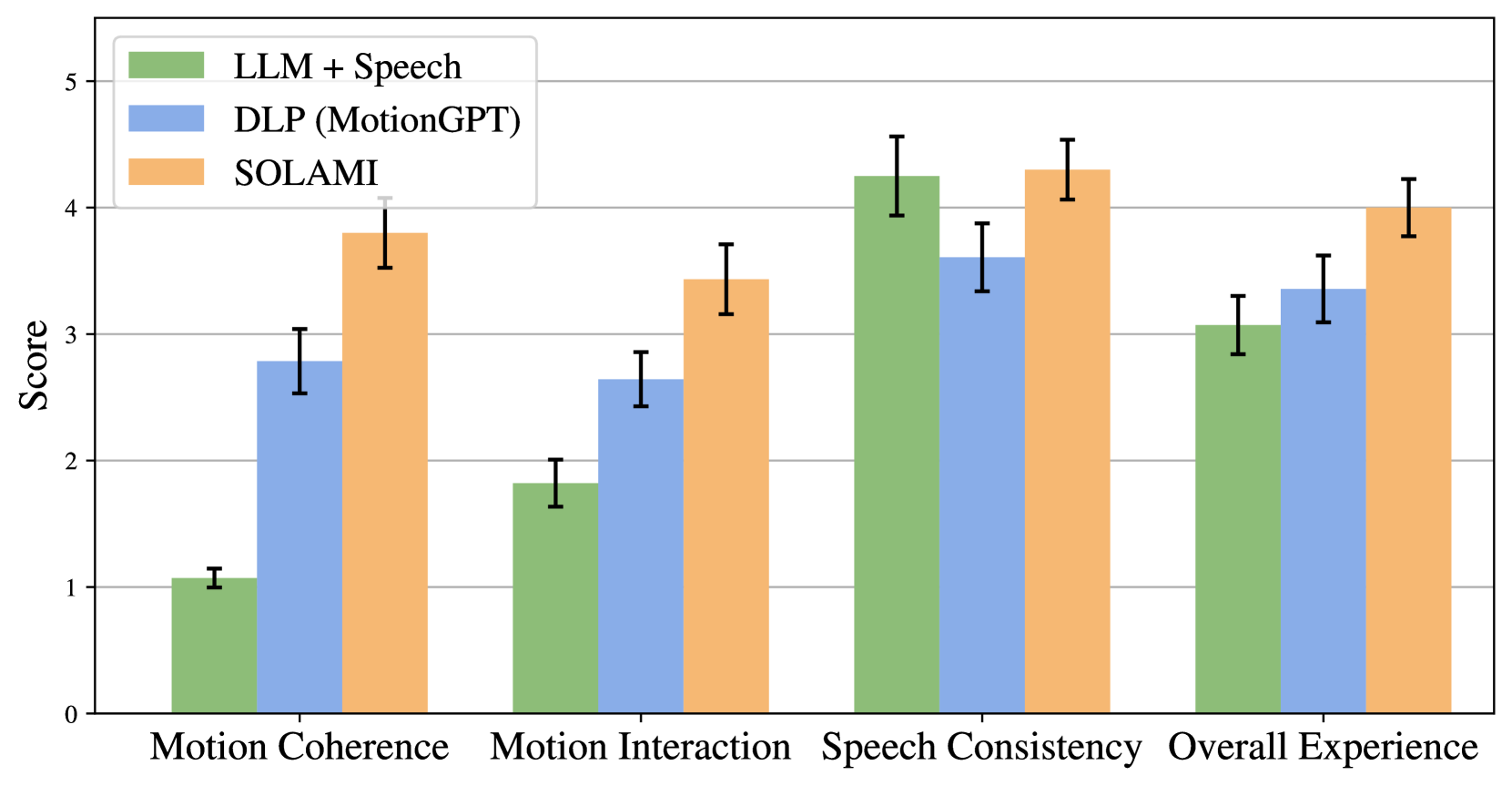
🔼 This figure displays the results of a user study evaluating the performance of SOLAMI and baseline models. The study used a 5-point Likert scale to assess four dimensions of user experience: Motion Coherence (how well the character’s motion matched the setting and dialogue), Motion Interaction (how well the character responded to user motion input), Speech Consistency (how well character speech matched the setting and topic), and Overall Experience (the overall user satisfaction). Error bars show 95% confidence intervals. The results visually demonstrate SOLAMI’s superior performance compared to LLM+Speech and DLP (MotionGPT) across all four dimensions, indicating a more natural and engaging interactive experience for users.
read the caption
Figure 5: Results of the user study with 95% confidence.
🔼 Figure 6 presents a qualitative comparison of SOLAMI against two baselines (LLM+Speech and DLP) in terms of their ability to handle three key aspects of social interaction: understanding body language, executing motion commands, and engaging in interactive tasks. The figure shows example user inputs and the corresponding responses from each method, visually demonstrating SOLAMI’s superior performance in generating natural and coherent responses that accurately reflect the semantic meaning of the user’s speech and motion. The workflow diagram illustrates the process: User input (speech and motion) is captured in the VR environment, processed by the chosen model, and the model’s response (speech and motion) drives the 3D character’s behavior, providing a visual representation of the overall system.
read the caption
Figure 6: Qualitative results of SOLAMI and baselines, and the user workflow for VR experience. Our social VLA model, trained in an end-to-end strategy on SynMSI dataset, can accurately perceive the semantic information embedded within users’ speech and motion input, and subsequently generate natural and coherent responses.

🔼 Figure 7 shows a word cloud visualization of keywords from the topics collected for different characters in the SynMSI dataset. The topics are categorized into four groups: character-related topics, news-related topics, daily life topics, and topics that people are generally curious about. These topics serve to provide a foundation for generating diverse and engaging multi-round dialogues in a natural conversational style for the characters within the virtual environment. The word clouds visually represent the frequency of keywords associated with each character, offering insight into the specific thematic areas of conversation covered in the SynMSI dataset.
read the caption
(a) Samantha
🔼 Figure 7(b) shows a word cloud visualization of keywords related to the character K-VRC from the SynMSI dataset. The word cloud highlights the topics and themes of conversations generated for this specific character, showcasing the variety of interactions encompassed within the dataset. The words’ sizes reflect their frequency in the dataset, providing insights into the common themes discussed with K-VRC during the multi-modal interactions.
read the caption
(b) K-VRC
🔼 The figure shows a word cloud visualization of keywords related to Batman, a character used in the SynMSI dataset. The word cloud highlights terms associated with Batman’s persona, settings (Gotham, Batcave), and actions (criminals, attack, Batmobile), showcasing the diverse semantic information captured within the dataset.
read the caption
(c) Batman
More on tables
| Dimension | Questions |
|---|---|
| Motion Coherence | Does the motion match the character’s setting? |
| Does the motion align well with speech? | |
| Motion Interaction | Does the character follow motion instructions correctly? |
| Does the character understand user’s motion? | |
| Speech Consistency | Does the speech match the character’s setting? |
| Is the speech relevant to the current topic? | |
| Overall Experience | How would you rate the overall experience? |
🔼 This table details the questionnaire used in the user study to evaluate the immersive VR experience. It outlines the questions asked to assess different aspects of the user’s experience, categorized into dimensions such as motion coherence (how well the character’s motion aligned with the scene and dialogue), speech consistency (how well the speech matched the character and conversation), and overall experience. This provides a structured way to gather feedback on various aspects of the system’s performance.
read the caption
Table 2: Questionnaire settings of our user study.
| ID | Body & Hand | Repre | Backbone | Token Interleaved | FID ↓ | Diversity ↑ | PA-MPJPE ↓ | Pred Valid ↑ |
|---|---|---|---|---|---|---|---|---|
| 1 | bind | joints | GPT-2 | - | 1.48 | 9.03 | 148.00 | 0.836 |
| 2 | bind | rotation | GPT-2 | - | 3.44 | 12.94 | 143.70 | 0.813 |
| 3 | separate | rotation | GPT-2 | Yes | 3.00 | 11.64 | 117.26 | 0.676 |
| 4 | separate | rotation | GPT-2 | No | 2.72 | 14.05 | 112.53 | 0.638 |
| 5 | separate | rotation | Llama2 | No | 1.82 | 10.40 | 110.23 | 0.999 |
🔼 This table presents a quantitative comparison of different pre-training methods for a text-to-motion task. The methods are evaluated using several metrics: FID (Frechet Inception Distance), Diversity, PA-MPJPE (Percentage of Average MPJPE), and Pred Valid. Lower FID scores indicate better reconstruction quality, while higher Diversity, Pred Valid, and lower PA-MPJPE scores represent improved performance. The table shows results for different configurations: whether the body and hand motions are treated as separate sequences or combined, the type of backbone network used (GPT-2 or Llama2), and whether or not interleaved tokens were used. This allows for an analysis of the effectiveness of various design choices in generating high-quality motion from textual descriptions.
read the caption
Table 3: Quantitative results of pre-training on text-to-motion task. ‘↑↑\uparrow↑’(‘↓↓\downarrow↓’) indicates that the values are better if the metrics are larger (smaller). The best results are in bold and the second best results are underlined.
| ID | Body & Hand | Repre | Motion Metrics | PA-MPJPE ↓ | FID ↓ |
|---|---|---|---|---|---|
| 1 | separate | joints | 87 | 1.0 | |
| 2 | bind | joints | 80 | 1.3 | |
| 3 | separate | rotation | 88 | 1.88 | |
| 4 | bind | rotation | 113 | 2.34 |
🔼 This table presents a quantitative comparison of different motion vector quantization variational autoencoder (VQ-VAE) configurations. It evaluates the performance of four variations based on two factors: whether the body and hand motions are represented separately or jointly (‘bind’ vs. ‘separate’) and whether a joints representation or rotation representation was used. The evaluation metrics include FID (Fréchet Inception Distance), which measures the quality of reconstructed motion, and PA-MPJPE (Pose-Aligned Mean Per-Joint Position Error), which assesses the accuracy of the representation. Lower FID and PA-MPJPE scores indicate better performance. The table also shows the reconstruction success rate.
read the caption
Table 4: Quantitative results of Motion VQVAE. ‘↑↑\uparrow↑’(‘↓↓\downarrow↓’) indicates that the values are better if the metrics are larger (smaller). The best results are in bold.
🔼 This table compares three different methods for collecting multimodal interaction data, which is crucial for training models like SOLAMI. It outlines the input data used (e.g., MoCap data from internet videos, motion captioning from internet videos, real data collected via VR platforms) and shows the corresponding output format generated. The table highlights the challenges and complexities associated with each method, demonstrating the various ways researchers have attempted to gather this data for social VLA modeling.
read the caption
Table 5: Methods of collecting multimodal interaction data.
Full paper#