↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models struggle with tasks requiring 3D spatial understanding, largely due to their training on predominantly 2D data. This limitation hinders effective application in areas like robotics and augmented reality, where understanding 3D environments is crucial. Existing attempts to improve these models by adding 3D information have faced limitations due to the considerable gap between the model’s learned representations and the inherent complexity of 3D scenes.
The proposed Video-3D LLM addresses this by representing 3D scenes as dynamic videos and incorporating 3D position encoding. This approach accurately aligns video representations with real-world spatial contexts. A maximum coverage sampling technique is also implemented to optimize the balance between computational costs and performance. Extensive experiments demonstrate that Video-3D LLM achieves state-of-the-art performance on several 3D scene understanding benchmarks, showcasing its effectiveness and generalizability.
Key Takeaways#
Why does it matter?#
This paper is important because it bridges the gap between 2D-focused large language models and the complexities of 3D scene understanding. It introduces a novel approach using video data and 3D position encoding, leading to state-of-the-art results across multiple benchmarks. This work opens new avenues for research in multimodal learning and 3D scene analysis, and its techniques are directly applicable to various applications such as robotics and augmented reality. The efficient frame sampling method also offers practical benefits for computational resource management.
Visual Insights#

🔼 Figure 1 illustrates the core difference between existing 3D large language models (LLMs) and the proposed Video-3D LLM. (a) shows the conventional approach: pre-trained LLMs, trained only on 2D image-text data, are fine-tuned with 3D point cloud or voxel representations derived from RGB-D videos. This indirect method struggles to capture the inherent complexity of 3D scenes. (b) highlights the Video-3D LLM approach: it directly leverages video frames and their corresponding 3D coordinates (obtained via coordinate transformation from depth data) as input. By integrating positional information directly into the video representation, Video-3D LLM effectively bridges the gap between 2D and 3D understanding, leading to improved performance in 3D scene understanding tasks.
read the caption
Figure 1: Comparison of previous work and our method: (a) Previous 3D LLMs are initialized on MLLMs trained solely on image-text pairs, and learn point cloud or voxel representations via fine-tuning on 3D scenes. The 3D point clouds are reconstructed from RGB-D videos. (b) Our method directly utilizes video frames and 3D coordinates as input, where the 3D coordinates are converted from depths through coordinate transformation. We then transfer the ability of video understanding to 3D scene understanding by injecting position information into video representations.
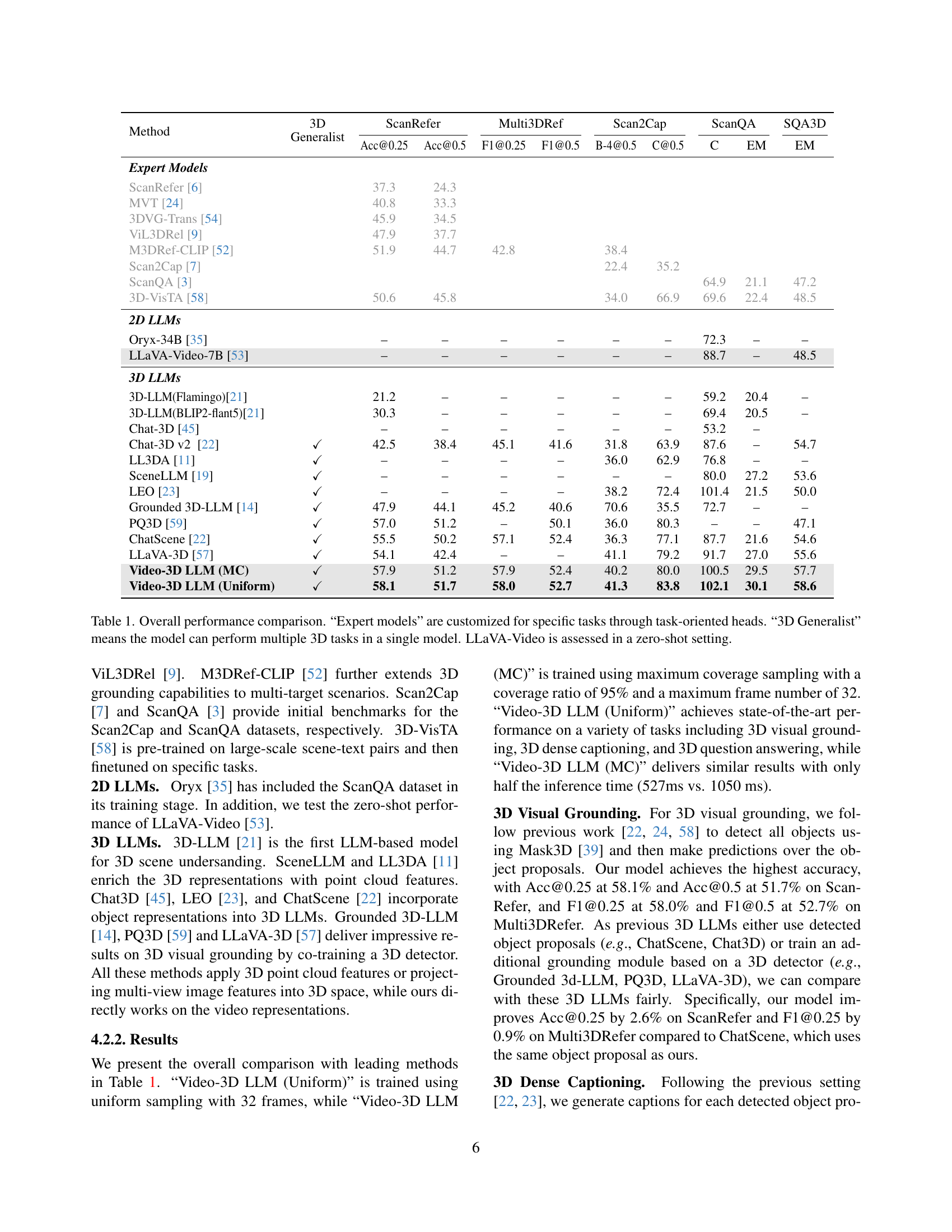
| Method | 3D Generalist | ScanRefer Acc@0.25 | ScanRefer Acc@0.5 | ScanRefer F1@0.25 | ScanRefer F1@0.5 | Multi3DRef B-4@0.5 | Multi3DRef C@0.5 | Scan2Cap C | Scan2Cap EM | ScanQA EM | SQA3D EM |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Expert Models | |||||||||||
| ScanRefer [6] | 37.3 | 24.3 | |||||||||
| MVT [24] | 40.8 | 33.3 | |||||||||
| 3DVG-Trans [54] | 45.9 | 34.5 | |||||||||
| ViL3DRel [9] | 47.9 | 37.7 | |||||||||
| M3DRef-CLIP [52] | 51.9 | 44.7 | 42.8 | 38.4 | |||||||
| Scan2Cap [7] | 22.4 | 35.2 | |||||||||
| ScanQA [3] | 64.9 | 21.1 | |||||||||
| 3D-VisTA [58] | 50.6 | 45.8 | 34.0 | 66.9 | 69.6 | 22.4 | |||||
| 2D LLMs | |||||||||||
| Oryx-34B [35] | – | – | – | – | – | – | – | 72.3 | – | – | |
| LLaVA-Video-7B [53] | – | – | – | – | – | – | – | 88.7 | – | 48.5 | |
| 3D LLMs | |||||||||||
| 3D-LLM(Flamingo) [21] | 21.2 | – | – | – | – | – | – | 59.2 | 20.4 | – | |
| 3D-LLM(BLIP2-flant5) [21] | 30.3 | – | – | – | – | – | – | 69.4 | 20.5 | – | |
| Chat-3D [45] | – | – | – | – | – | – | – | 53.2 | – | ||
| Chat-3D v2 [22] | ✓ | 42.5 | 38.4 | 45.1 | 41.6 | 31.8 | 63.9 | 87.6 | 54.7 | ||
| LL3DA [11] | ✓ | – | – | – | – | 36.0 | 62.9 | 76.8 | – | ||
| SceneLLM [19] | ✓ | – | – | – | – | 80.0 | 27.2 | ||||
| LEO [23] | ✓ | – | – | – | – | 38.2 | 72.4 | 101.4 | 50.0 | ||
| Grounded 3D-LLM [14] | ✓ | 47.9 | 44.1 | 45.2 | 40.6 | 70.6 | 35.5 | 72.7 | |||
| PQ3D [59] | ✓ | 57.0 | 51.2 | 50.1 | 36.0 | 80.3 | 47.1 | ||||
| ChatScene [22] | ✓ | 55.5 | 50.2 | 57.1 | 52.4 | 36.3 | 77.1 | 87.7 | 21.6 | 54.6 | |
| LLaVA-3D [57] | ✓ | 54.1 | 42.4 | 41.1 | 79.2 | 91.7 | 27.0 | 55.6 | |||
| Video-3D LLM (MC) | ✓ | 57.9 | 51.2 | 57.9 | 52.4 | 40.2 | 80.0 | 100.5 | 29.5 | 57.7 | |
| Video-3D LLM (Uniform) | ✓ | 58.1 | 51.7 | 58.0 | 52.7 | 41.3 | 83.8 | 102.1 | 30.1 | 58.6 |
🔼 Table 1 presents a comprehensive comparison of the proposed Video-3D LLM model’s performance against various state-of-the-art methods across five distinct 3D scene understanding benchmarks. These benchmarks evaluate performance on different tasks, including 3D visual grounding (ScanRefer and Multi3DRefer), 3D dense captioning (Scan2Cap), and 3D question answering (ScanQA and SQA3D). The table highlights the distinction between ‘Expert Models,’ which are specifically designed and trained for individual tasks, and ‘3D Generalist’ models like Video-3D LLM, capable of handling multiple tasks within a single architecture. The results showcase Video-3D LLM’s superior performance compared to other generalist models and its competitive performance against expert models, even in zero-shot scenarios (as seen with LLaVA-Video).
read the caption
Table 1: Overall performance comparison. “Expert models” are customized for specific tasks through task-oriented heads. “3D Generalist” means the model can perform multiple 3D tasks in a single model. LLaVA-Video is assessed in a zero-shot setting.
In-depth insights#
3D Scene Encoding#
In a hypothetical research paper section on “3D Scene Encoding,” a key focus would likely be on how to effectively represent three-dimensional spatial information for downstream tasks. The core challenge lies in converting raw 3D data (point clouds, voxel grids, or meshes) into a format suitable for machine learning models, which typically operate on structured data. Efficient encoding methods are crucial to balancing model performance and computational cost. This might involve exploring techniques like point cloud feature extraction (using pointnet, etc.), volumetric representations (octrees, voxel grids), or graph-based methods. The choice of encoding method heavily depends on the characteristics of the 3D data, the specific application (e.g., object detection, scene understanding), and available computational resources. The section could delve into comparative analyses of different 3D encoding schemes, examining their performance on relevant benchmarks. Furthermore, attention should be given to the integration of encoded 3D information with other modalities, such as images or text, which are common in multimodal applications. Robustness to noise and variations in 3D data is also an important factor to address. The research could evaluate the efficacy of different encoding schemes by experimenting on various tasks and datasets. Ultimately, a good “3D Scene Encoding” section should offer a clear and insightful explanation of the chosen methods, justify the design choices, and provide a thorough analysis of their strengths and weaknesses.
Video-LLM Fusion#
The concept of “Video-LLM Fusion” represents a significant advancement in multimodal AI, merging the strengths of large language models (LLMs) with the rich temporal information inherent in video data. This fusion unlocks the ability to understand not only the visual content of videos but also their contextual meaning and narrative structure. LLMs provide the semantic understanding and reasoning capabilities, while video data offers a dynamic and contextualized representation of events and actions. This fusion can lead to breakthroughs in applications such as video question answering, video summarization, and video-based scene understanding, by enabling the extraction of intricate relationships between objects, actions, and narrative progression over time. However, challenges remain. Efficiently processing large video datasets presents a significant computational hurdle. Moreover, aligning the disparate data formats and ensuring effective communication between the LLM and the video processing components remains a critical design aspect. This necessitates sophisticated methods of feature extraction, dimensionality reduction, and model architecture design to mitigate resource constraints and ensure accuracy. Further research should focus on addressing these challenges, particularly in scaling the approach to handle ever-growing video corpora and complex visual scenarios. Finally, ethical considerations, including bias mitigation in training datasets and responsible deployment of the technology, must be addressed to ensure beneficial and equitable applications of Video-LLM fusion.
Max Coverage Sampling#
The concept of ‘Max Coverage Sampling’ in the context of processing video data for 3D scene understanding is crucial for efficiency and performance. The core challenge is managing the computational burden of processing large video sequences while ensuring the model captures the complete 3D scene. A naive approach of using all frames would be computationally expensive and inefficient. The greedy algorithm presented in the paper tackles this problem by iteratively selecting frames that maximize the coverage of the 3D scene. This approach cleverly balances computational cost and scene information. The selection is based on maximizing uncovered voxels, ensuring that the most informative frames are prioritised. The algorithm stops either when a predefined budget (number of frames) is met or a sufficient coverage threshold is reached. This dynamic strategy adapts to scenes of varying complexity, making it robust and generally applicable, and avoids redundancy inherent in processing every frame. Overall, Max Coverage Sampling provides a practical and efficient way to extract the most relevant information from video data while optimizing performance for 3D scene understanding tasks.
Position-Aware Video#
The concept of “Position-Aware Video” represents a significant advancement in video processing and understanding. It moves beyond traditional video analysis, which focuses primarily on temporal aspects, by explicitly incorporating spatial information. This integration is crucial for applications where understanding the spatial relationships between objects within the video frame is essential. The key is embedding 3D positional information, often derived from depth sensors or other spatial data sources, directly into the video’s representation. This allows for a more comprehensive understanding of 3D scenes captured as video. The benefits extend to tasks requiring spatial reasoning and contextual awareness, such as 3D scene understanding, object detection, and navigation in virtual environments. Challenges include efficient processing of the enriched data and the need for large, well-annotated datasets containing both visual and spatial information for training robust models. The approach’s effectiveness depends on the accuracy and precision of spatial data integration, making data quality and robust coordinate transformation key considerations.
3D-LLM Limitations#
Current 3D LLMs face limitations stemming from their training data and architectural constraints. Limited 3D training data significantly restricts their ability to generalize effectively to unseen 3D scenes. Unlike 2D LLMs which benefit from massive image datasets, 3D models often struggle with the scarcity of comprehensively labeled 3D data, resulting in poor generalization and limited understanding of complex 3D relationships. Furthermore, architectural designs often rely on converting 3D data into intermediate representations (point clouds, voxels), losing inherent spatial information during the process. This transformation introduces additional complexity and can negatively impact performance. Finally, the inherent disconnect between the primarily 2D-trained foundation models and the 3D task hinders effective knowledge transfer and requires extensive finetuning on 3D data, which further exacerbates the data scarcity issue. Addressing these limitations requires innovative approaches such as leveraging readily available video data, developing more robust 3D representations, and designing architectures better suited for direct 3D data processing.
More visual insights#
More on figures

🔼 Figure 2 illustrates the Video-3D LLM architecture. Part (a) shows how video sequences and their corresponding 3D global coordinates are integrated to create position-aware video representations. This is a key innovation, allowing the model to understand spatial context within 3D scenes. Parts (b) and (c) provide concrete examples of how this architecture is used for two specific 3D scene understanding tasks: 3D dense captioning (generating detailed descriptions of objects) and 3D visual grounding (locating objects based on textual descriptions). The figure highlights the model’s versatility, suggesting its applicability to a wide range of other 3D scene understanding tasks.
read the caption
Figure 2: The overview of the model architecture. (a) shows the integration of video sequence and global coordinates for creating position-aware video representations. (b) and (c) detail the examples of 3D dense captioning and 3D visual grounding, respectively. Our approach can generalize well to other 3D tasks.

🔼 This figure visualizes the results of the ScanRefer task, a 3D visual grounding benchmark. It showcases several examples where the model attempts to locate objects based on textual descriptions. Each example displays three boxes: a green box representing the model’s correct prediction, a red box showing an incorrect prediction, and a blue box indicating the ground truth object location. The visualization helps demonstrate the accuracy and limitations of the Video-3D LLM model in locating objects within 3D scenes.
read the caption
Figure 3: The visualization results on ScanRefer. The green/red/blue colors indicate the correct/incorrect/ground truth boxes.

🔼 This figure showcases example results from the Scan2Cap task. It presents several examples where the model generates captions for objects within a 3D scene. For each example, the ground truth (GT) caption and the model’s generated caption are shown alongside the visual input. The input includes bounding boxes around objects (in blue), illustrating the model’s understanding of spatial relations. Comparing the generated and ground truth captions highlights the model’s success (or challenges) in accurately describing objects and their contexts within the 3D scene.
read the caption
Figure 4: The visualization results on Scan2Cap. The input boxes are marked in blue.
More on tables
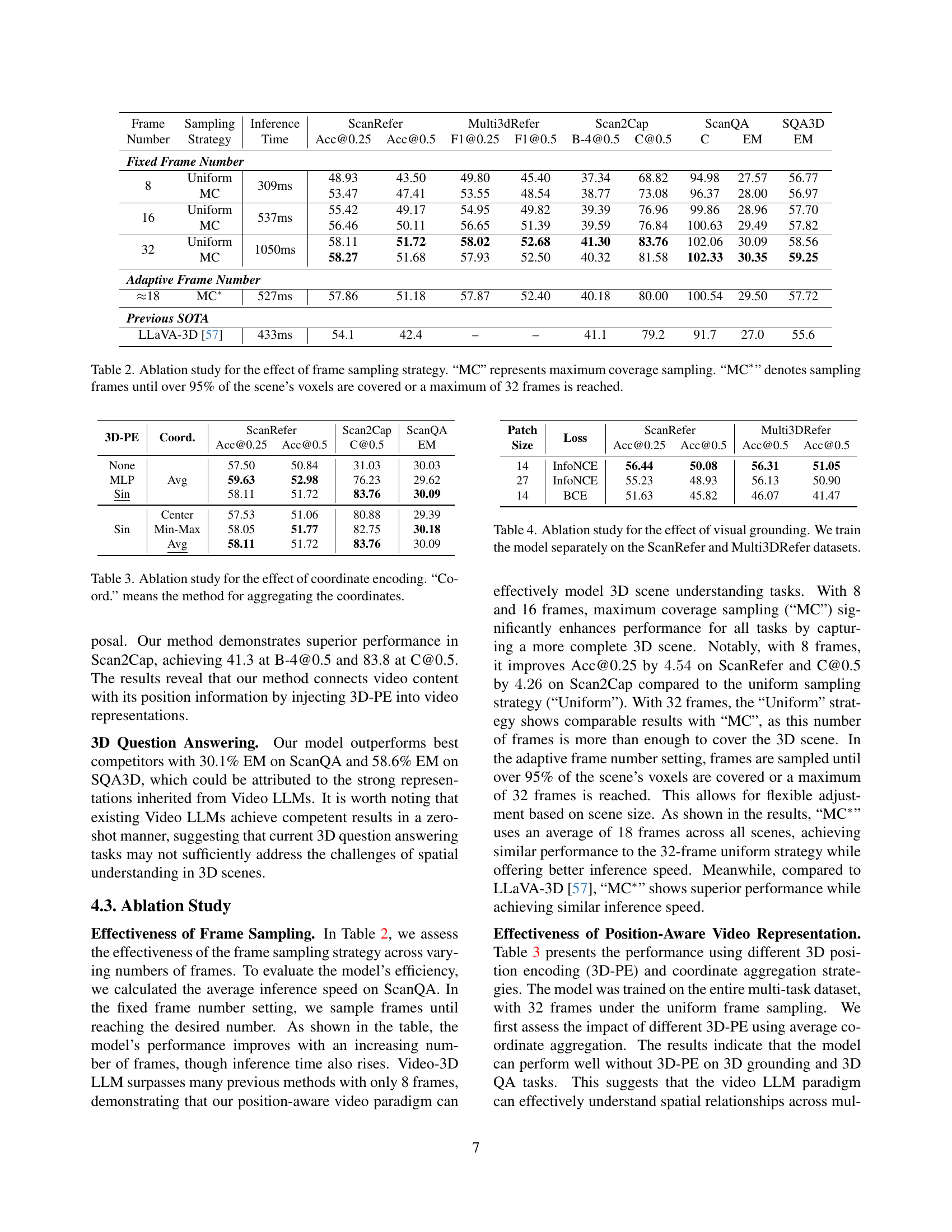
| Frame Number | Sampling Strategy | Inference Time | ScanRefer Acc@0.25 | ScanRefer Acc@0.5 | ScanRefer F1@0.25 | ScanRefer F1@0.5 | Multi3dRefer B-4@0.5 | Multi3dRefer C@0.5 | Scan2Cap C | Scan2Cap EM | ScanQA EM | SQA3D EM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fixed Frame Number | ||||||||||||
| 8 | Uniform | 309ms | 48.93 | 43.50 | 49.80 | 45.40 | 37.34 | 68.82 | 94.98 | 27.57 | 56.77 | |
| 8 | MC | 53.47 | 47.41 | 53.55 | 48.54 | 38.77 | 73.08 | 96.37 | 28.00 | 56.97 | ||
| 16 | Uniform | 537ms | 55.42 | 49.17 | 54.95 | 49.82 | 39.39 | 76.96 | 99.86 | 28.96 | 57.70 | |
| 16 | MC | 56.46 | 50.11 | 56.65 | 51.39 | 39.59 | 76.84 | 100.63 | 29.49 | 57.82 | ||
| 32 | Uniform | 1050ms | 58.11 | 51.72 | 58.02 | 52.68 | 41.30 | 83.76 | 102.06 | 30.09 | 58.56 | |
| 32 | MC | 58.27 | 51.68 | 57.93 | 52.50 | 40.32 | 81.58 | 102.33 | 30.35 | 59.25 | ||
| Adaptive Frame Number | ||||||||||||
| ≈18 | MC* | 527ms | 57.86 | 51.18 | 57.87 | 52.40 | 40.18 | 80.00 | 100.54 | 29.50 | 57.72 | |
| Previous SOTA | ||||||||||||
| LLaVA-3D [57] | 433ms | 54.1 | 42.4 | – | – | 41.1 | 79.2 | 91.7 | 27.0 | 55.6 |
🔼 This ablation study analyzes the impact of different frame sampling strategies on the performance of the Video-3D LLM model. It compares three approaches: using a fixed number of frames sampled uniformly, using a fixed number of frames selected via a maximum coverage strategy, and using an adaptive number of frames determined by the maximum coverage strategy, stopping when a coverage threshold is met. The results are evaluated across several 3D scene understanding benchmarks (ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D) using multiple metrics. The table shows the impact of each sampling strategy on both accuracy (across various metrics depending on the task) and inference time.
read the caption
Table 2: Ablation study for the effect of frame sampling strategy. “MC” represents maximum coverage sampling. “MC∗” denotes sampling frames until over 95% of the scene’s voxels are covered or a maximum of 32 frames is reached.
| 3D-PE | Coord. | ScanRefer Acc@0.25 | ScanRefer Acc@0.5 | Scan2Cap C@0.5 | ScanQA EM |
|---|---|---|---|---|---|
| 3D-PE | Coord. | ||||
| None | Avg | 57.50 | 50.84 | 31.03 | 30.03 |
| MLP | 59.63 | 52.98 | 76.23 | 29.62 | |
| Sin | 58.11 | 51.72 | 83.76 | 30.09 | |
| Sin | Center | 57.53 | 51.06 | 80.88 | 29.39 |
| Min-Max | 58.05 | 51.77 | 82.75 | 30.18 | |
| Avg | 58.11 | 51.72 | 83.76 | 30.09 |
🔼 This table presents an ablation study analyzing the impact of different coordinate encoding methods on the model’s performance. It investigates various techniques for aggregating 3D coordinates, comparing their effects on key metrics across multiple 3D scene understanding tasks. The results help determine the optimal approach for incorporating spatial information into the model’s video representations.
read the caption
Table 3: Ablation study for the effect of coordinate encoding. “Coord.” means the method for aggregating the coordinates.
| Patch Size | Loss | ScanRefer Acc@0.25 | ScanRefer Acc@0.5 | Multi3DRefer Acc@0.5 | Multi3DRefer Acc@0.5 |
|---|---|---|---|---|---|
| 14 | InfoNCE | 56.44 | 50.08 | 56.31 | 51.05 |
| 27 | InfoNCE | 55.23 | 48.93 | 56.13 | 50.90 |
| 14 | BCE | 51.63 | 45.82 | 46.07 | 41.47 |
🔼 This table presents an ablation study focusing on the impact of different training strategies for 3D visual grounding. Instead of training a single model on both ScanRefer and Multi3DRefer datasets simultaneously, this experiment trains separate models for each dataset to isolate and analyze the effects of each training configuration on the final performance metrics. The results help determine the best approach for achieving high accuracy in 3D visual grounding tasks.
read the caption
Table 4: Ablation study for the effect of visual grounding. We train the model separately on the ScanRefer and Multi3DRefer datasets.
| Data | Data Count | Scan Count | Ques length | Answer Length |
|---|---|---|---|---|
| ScanRefer [6] | 36,665 | 562 | 24.9 | – |
| Multi3DRefer [52] | 43,838 | 562 | 34.8 | – |
| Scan2Cap [7] | 36,665 | 562 | 13.0 | 17.9 |
| ScanQA [3] | 26,515 | 562 | 13.7 | 2.4 |
| SQA3D [36] | 79,445 | 518 | 37.8 | 1.1 |
🔼 Table 5 presents a statistical overview of the training datasets used in the paper. It details the number of data points (scan, question, answer) for each dataset (ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D) and provides the average lengths of the questions and answers in each dataset. This information is crucial for understanding the scale and characteristics of the data used to train the proposed Video-3D LLM model.
read the caption
Table 5: Detailed statistics for training data. We report the average lengths for questions and answers, respectively.
| Dataset | Data Count | Scan Count | Ques length | Answer Length |
|---|---|---|---|---|
| ScanRefer 6 (Val) | 9,508 | 141 | 25.0 | – |
| Multi3DRefer 52 (Val) | 11,120 | 141 | 34.7 | – |
| Scan2Cap 7 (Val) | 2,068 | 141 | 13.0 | 18.7 |
| ScanQA 3 (Val) | 4,675 | 71 | 13.8 | 2.4 |
| SQA3D 36 (Test) | 3,519 | 67 | 36.3 | 1.1 |
🔼 This table presents a statistical overview of the testing data used in the experiments, specifically focusing on the lengths of questions and answers across different datasets. The datasets include ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D. For each dataset, the average length of questions and the average length of answers are provided, giving insights into the scale and complexity of the textual data involved in the 3D scene understanding benchmarks.
read the caption
Table 6: Detailed statistics for testing data. We report the average lengths for questions and answers, respectively.
| Method | What | Is | How | Can | Which | Others | Avg. |
|---|---|---|---|---|---|---|---|
| SQA3D [36] | 31.6 | 63.8 | 46.0 | 69.5 | 43.9 | 45.3 | 46.6 |
| 3D-VisTA [58] | 34.8 | 63.3 | 45.4 | 69.8 | 47.2 | 48.1 | 48.5 |
| LLaVA-Video [53] | 42.7 | 56.3 | 47.5 | 55.3 | 50.1 | 47.2 | 48.5 |
| Scene-LLM [19] | 40.9 | 69.1 | 45.0 | 70.8 | 47.2 | 52.3 | 54.2 |
| LEO [23] | – | – | – | – | – | – | 50.0 |
| ChatScene [22] | 45.4 | 67.0 | 52.0 | 69.5 | 49.9 | 55.0 | 54.6 |
| LLaVA-3D [57] | – | – | – | – | – | – | 55.6 |
| Video-3D LLM (Uniform) | 51.1 | 72.4 | 55.5 | 69.8 | 51.3 | 56.0 | 58.6 |
| Video-3D LLM (MC) | 50.0 | 70.7 | 57.9 | 69.8 | 50.1 | 55.8 | 57.7 |
🔼 This table presents a detailed comparison of different models’ performance on the SQA3D benchmark’s test set. It shows the average exact match accuracy (EM) across different question types (What Is, How Can, Which, Others), providing a comprehensive evaluation of each model’s ability to answer questions related to 3D scenes. The models compared include various state-of-the-art and baseline models in 3D scene understanding.
read the caption
Table 7: Performance comparison on the test set of SQA3D [36].
| Method | C | B-4 | M | R |
|---|---|---|---|---|
| Scan2Cap [7] | 39.08 | 23.32 | 21.97 | 44.48 |
| 3DJCG [4] | 49.48 | 31.03 | 24.22 | 50.80 |
| D3Net [8] | 62.64 | 35.68 | 25.72 | 53.90 |
| 3D-VisTA [58] | 66.9 | 34.0 | 27.1 | 54.3 |
| LL3DA [11] | 65.19 | 36.79 | 25.97 | 55.06 |
| LEO [23] | 68.4 | 36.9 | 27.7 | 57.8 |
| ChatScene [22] | 77.19 | 36.34 | 28.01 | 58.12 |
| LLaVA-3D [57] | 79.21 | 41.12 | 30.21 | 63.41 |
| Video-3D LLM (Uniform) | 83.77 | 42.43 | 28.87 | 62.34 |
| Video-3D LLM (MC) | 80.00 | 40.18 | 28.49 | 61.68 |
🔼 This table presents a detailed comparison of different models’ performance on the Scan2Cap benchmark, a task focused on generating detailed captions for objects within 3D scenes. It compares several state-of-the-art models, highlighting their performance using four common evaluation metrics: CIDEr, BLEU-4, Meteor, and Rouge-L. These metrics provide a comprehensive evaluation of caption quality by assessing various aspects like coherence, fluency, and semantic similarity to reference captions.
read the caption
Table 8: Performance comparison on the validation set of Scan2Cap [7]. C, B-4, M, R represent CIDEr, BLEU-4, Meteor, Rouge-L, respectively.
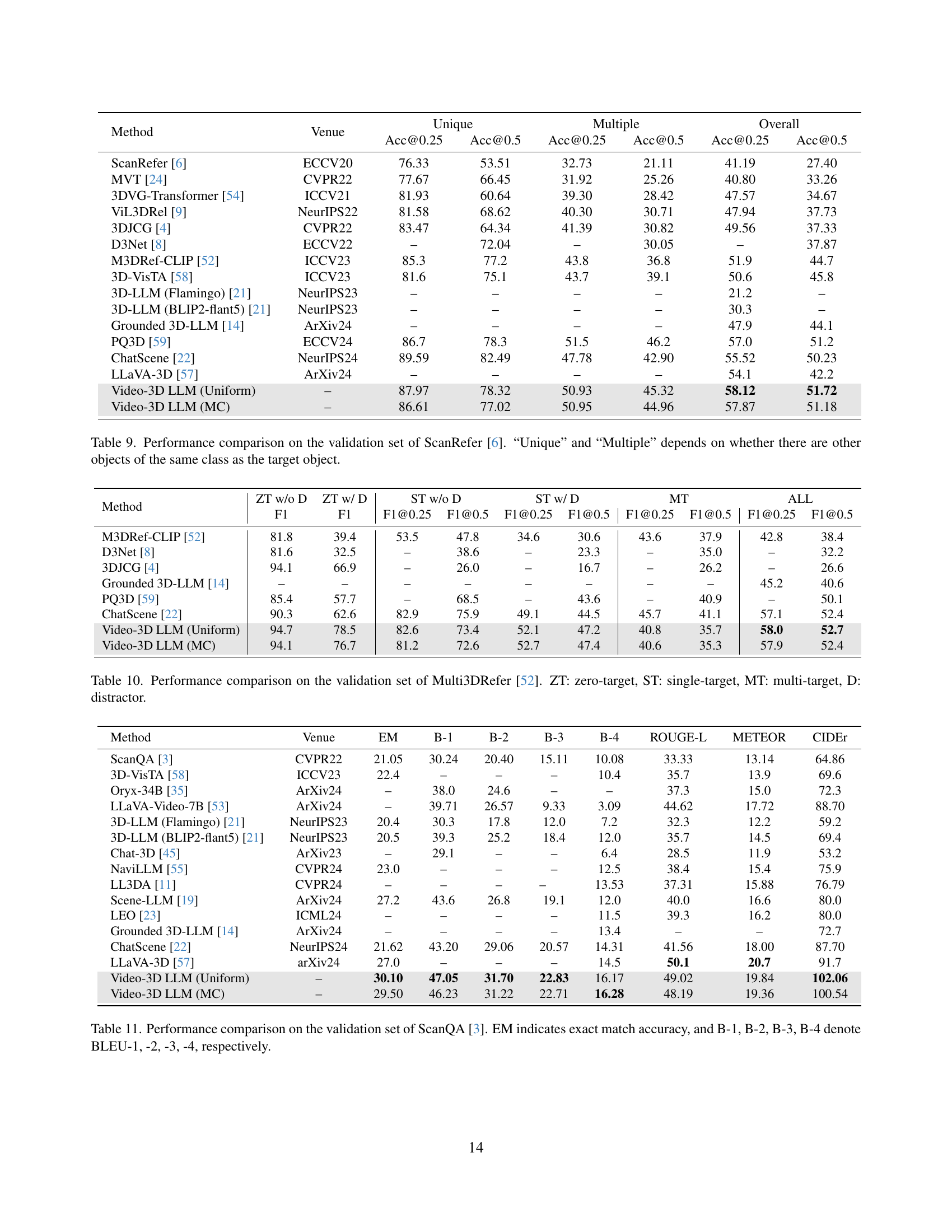
| Method | Venue | Unique Acc@0.25 | Unique Acc@0.5 | Multiple Acc@0.25 | Multiple Acc@0.5 | Overall Acc@0.25 | Overall Acc@0.5 |
|---|---|---|---|---|---|---|---|
| ScanRefer [6] | ECCV20 | 76.33 | 53.51 | 32.73 | 21.11 | 41.19 | 27.40 |
| MVT [24] | CVPR22 | 77.67 | 66.45 | 31.92 | 25.26 | 40.80 | 33.26 |
| 3DVG-Transformer [54] | ICCV21 | 81.93 | 60.64 | 39.30 | 28.42 | 47.57 | 34.67 |
| ViL3DRel [9] | NeurIPS22 | 81.58 | 68.62 | 40.30 | 30.71 | 47.94 | 37.73 |
| 3DJCG [4] | CVPR22 | 83.47 | 64.34 | 41.39 | 30.82 | 49.56 | 37.33 |
| D3Net [8] | ECCV22 | – | 72.04 | – | 30.05 | – | 37.87 |
| M3DRef-CLIP [52] | ICCV23 | 85.3 | 77.2 | 43.8 | 36.8 | 51.9 | 44.7 |
| 3D-VisTA [58] | ICCV23 | 81.6 | 75.1 | 43.7 | 39.1 | 50.6 | 45.8 |
| 3D-LLM (Flamingo) [21] | NeurIPS23 | – | – | – | – | 21.2 | – |
| 3D-LLM (BLIP2-flant5) [21] | NeurIPS23 | – | – | – | – | 30.3 | – |
| Grounded 3D-LLM [14] | ArXiv24 | – | – | – | – | 47.9 | 44.1 |
| PQ3D [59] | ECCV24 | 86.7 | 78.3 | 51.5 | 46.2 | 57.0 | 51.2 |
| ChatScene [22] | NeurIPS24 | 89.59 | 82.49 | 47.78 | 42.90 | 55.52 | 50.23 |
| LLaVA-3D [57] | ArXiv24 | – | – | – | – | 54.1 | 42.2 |
| Video-3D LLM (Uniform) | – | 87.97 | 78.32 | 50.93 | 45.32 | 58.12 | 51.72 |
| Video-3D LLM (MC) | – | 86.61 | 77.02 | 50.95 | 44.96 | 57.87 | 51.18 |
🔼 This table presents a quantitative comparison of various models on the ScanRefer benchmark for 3D visual grounding. It shows the performance of different models, categorized as expert models (designed specifically for ScanRefer), 2D LLMs, and 3D LLMs, along with the proposed Video-3D LLM. Performance is measured using accuracy at two Intersection over Union (IoU) thresholds (Acc@0.25 and Acc@0.5). The results are further broken down into ‘Unique’ and ‘Multiple’ scenarios: Unique denotes scenes with only one object of the target class, while Multiple denotes scenes with multiple objects of the target class. This breakdown helps to analyze how well each model generalizes to different levels of visual complexity and object density within 3D scenes.
read the caption
Table 9: Performance comparison on the validation set of ScanRefer [6]. “Unique” and “Multiple” depends on whether there are other objects of the same class as the target object.
| Method | ZT w/o D F1 | ZT w/ D F1 | ST w/o D F1@0.25 | ST w/o D F1@0.5 | ST w/ D F1@0.25 | ST w/ D F1@0.5 | MT F1@0.25 | MT F1@0.5 | ALL F1@0.25 | ALL F1@0.5 |
|---|---|---|---|---|---|---|---|---|---|---|
| M3DRef-CLIP [52] | 81.8 | 39.4 | 53.5 | 47.8 | 34.6 | 30.6 | 43.6 | 37.9 | 42.8 | 38.4 |
| D3Net [8] | 81.6 | 32.5 | – | 38.6 | – | 23.3 | – | 35.0 | – | 32.2 |
| 3DJCG [4] | 94.1 | 66.9 | – | 26.0 | – | 16.7 | – | 26.2 | – | 26.6 |
| Grounded 3D-LLM [14] | – | – | – | – | – | – | – | – | 45.2 | 40.6 |
| PQ3D [59] | 85.4 | 57.7 | – | 68.5 | – | 43.6 | – | 40.9 | – | 50.1 |
| ChatScene [22] | 90.3 | 62.6 | 82.9 | 75.9 | 49.1 | 44.5 | 45.7 | 41.1 | 57.1 | 52.4 |
| Video-3D LLM (Uniform) | 94.7 | 78.5 | 82.6 | 73.4 | 52.1 | 47.2 | 40.8 | 35.7 | 58.0 | 52.7 |
| Video-3D LLM (MC) | 94.1 | 76.7 | 81.2 | 72.6 | 52.7 | 47.4 | 40.6 | 35.3 | 57.9 | 52.4 |
🔼 This table presents a detailed comparison of different models’ performance on the Multi3DRefer dataset. Multi3DRefer is a benchmark for 3D visual grounding, focusing on the task of locating multiple objects in a 3D scene based on textual descriptions. The table breaks down the results based on several key factors: * Zero-target (ZT): Indicates scenarios where the description doesn’t specify the number of target objects to locate. * Single-target (ST): Indicates scenarios with descriptions explicitly specifying one target object. * Multi-target (MT): Indicates scenarios with descriptions specifying multiple target objects. * With Distractors (w/D): Indicates scenes that contain additional objects that are not the target objects, adding difficulty to the task. * Without Distractors (w/o D): Indicates scenes without these additional distracting objects. The evaluation metric used is the F1-score, which is calculated at an IoU threshold of 0.25 and 0.5. A higher F1-score indicates better performance. By separating the results in this manner, the table allows for a granular analysis of how different models perform under varying complexities of the 3D visual grounding task.
read the caption
Table 10: Performance comparison on the validation set of Multi3DRefer [52]. ZT: zero-target, ST: single-target, MT: multi-target, D: distractor.
| Method | Venue | EM | B-1 | B-2 | B-3 | B-4 | ROUGE-L | METEOR | CIDEr |
|---|---|---|---|---|---|---|---|---|---|
| ScanQA [3] | CVPR22 | 21.05 | 30.24 | 20.40 | 15.11 | 10.08 | 33.33 | 13.14 | 64.86 |
| 3D-VisTA [58] | ICCV23 | 22.4 | – | – | – | 10.4 | 35.7 | 13.9 | 69.6 |
| Oryx-34B [35] | ArXiv24 | – | 38.0 | 24.6 | – | – | 37.3 | 15.0 | 72.3 |
| LLaVA-Video-7B [53] | ArXiv24 | – | 39.71 | 26.57 | 9.33 | 3.09 | 44.62 | 17.72 | 88.70 |
| 3D-LLM (Flamingo) [21] | NeurIPS23 | 20.4 | 30.3 | 17.8 | 12.0 | 7.2 | 32.3 | 12.2 | 59.2 |
| 3D-LLM (BLIP2-flant5) [21] | NeurIPS23 | 20.5 | 39.3 | 25.2 | 18.4 | 12.0 | 35.7 | 14.5 | 69.4 |
| Chat-3D [45] | ArXiv23 | – | 29.1 | – | – | 6.4 | 28.5 | 11.9 | 53.2 |
| NaviLLM [55] | CVPR24 | 23.0 | – | – | – | 12.5 | 38.4 | 15.4 | 75.9 |
| LL3DA [11] | CVPR24 | – | – | – | – | 13.53 | 37.31 | 15.88 | 76.79 |
| Scene-LLM [19] | ArXiv24 | 27.2 | 43.6 | 26.8 | 19.1 | 12.0 | 40.0 | 16.6 | 80.0 |
| LEO [23] | ICML24 | – | – | – | – | 11.5 | 39.3 | 16.2 | 80.0 |
| Grounded 3D-LLM [14] | ArXiv24 | – | – | – | – | 13.4 | – | – | 72.7 |
| ChatScene [22] | NeurIPS24 | 21.62 | 43.20 | 29.06 | 20.57 | 14.31 | 41.56 | 18.00 | 87.70 |
| LLaVA-3D [57] | arXiv24 | 27.0 | – | – | – | 14.5 | 50.1 | 20.7 | 91.7 |
| Video-3D LLM (Uniform) | – | 30.10 | 47.05 | 31.70 | 22.83 | 16.17 | 49.02 | 19.84 | 102.06 |
| Video-3D LLM (MC) | – | 29.50 | 46.23 | 31.22 | 22.71 | 16.28 | 48.19 | 19.36 | 100.54 |
🔼 Table 11 presents a detailed comparison of the performance of various models on the ScanQA benchmark’s validation set. The benchmark assesses a model’s ability to answer questions about 3D scenes. The table lists multiple models, including the proposed Video-3D LLM and several state-of-the-art baselines. For each model, it shows the exact match accuracy (EM) and BLEU scores (B-1, B-2, B-3, B-4), which are common metrics for evaluating the quality of generated text. This allows for a direct comparison of the model’s ability to generate accurate and fluent answers to the 3D scene questions. The inclusion of multiple metrics provides a comprehensive evaluation of the model’s performance.
read the caption
Table 11: Performance comparison on the validation set of ScanQA [3]. EM indicates exact match accuracy, and B-1, B-2, B-3, B-4 denote BLEU-1, -2, -3, -4, respectively.
Full paper#