↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current any-to-any generation models often struggle with coherent multi-modal outputs and require substantial resources for training. These models usually combine modality-specific encoders and decoders, leading to limitations in integrating information across modalities. They often use simple averaging of embeddings for joint conditioning, which may not faithfully represent the input modalities. This can result in incoherent outputs and suboptimal performance.
OmniFlow addresses these issues with a novel modular architecture that extends the rectified flow framework to multi-modal settings. It uses a unified learning objective that integrates information from various modalities, including text, image, and audio, resulting in coherent multi-modal outputs. The modular design allows for efficient pre-training of individual components, reducing computational costs and facilitating flexible control over the generation process. OmniFlow outperforms existing models on a range of any-to-any tasks and contributes a new guidance mechanism that enables users to align outputs across various modalities.
Key Takeaways#
Why does it matter?#
This paper is important because it presents OmniFlow, a novel and unified generative model for any-to-any generation tasks, pushing the boundaries of multi-modal learning. Its modular design allows for efficient pre-training and flexible control over the generation process, paving the way for more advanced multi-modal applications. The work also provides valuable insights into optimizing performance across diverse modalities, advancing the field of generative models significantly.
Visual Insights#

🔼 Figure 1 showcases OmniFlow’s versatility in any-to-any multi-modal generation. It demonstrates the model’s ability to generate various output modalities (image, text, audio) from various input modalities (image, text, audio). Examples include generating an image from text, generating audio from text, and generating an image from both text and audio. This highlights OmniFlow’s capacity to seamlessly integrate and process information across different modalities, achieving coherent and diverse outputs.
read the caption
Figure 1: OmniFlow is capable of a diverse range of any-to-any generation tasks. OmniFlow supports generation of any output modalities given any input modality, such as text-to-image, text-to-audio, audio-to-image generations. It also supports tasks in multiple input modalities such as text+audio-to-image.
| Model | Param | FID↓ | CLIP↑ |
|---|---|---|---|
| UniDiffuser | 0.9B | 9.71 | 30.93 |
| CoDi | 4.3B | 11.26 | 30.69 |
| UIO-2XXL | 6.8B | 13.39 | - |
| SDv1.5 | 0.9B | 11.12 | 30.63 |
| SDXL* | 2.6B | 16.49 | 31.36 |
| SD3-Medium* | 2B | 20.94 | 30.65 |
| OmniFlow* | 3.4B | 13.40 | 31.54 |
🔼 This table presents a comparison of various models’ performance on the MSCOCO-30K benchmark for text-to-image generation. The models are evaluated using two metrics: FID (Fréchet Inception Distance), a measure of the generated images’ visual similarity to real images from the COCO dataset, and CLIP (Contrastive Language–Image Pre-training), assessing the alignment between the generated image and its corresponding text caption. Lower FID scores indicate better image quality, while higher CLIP scores reflect stronger alignment. The asterisk (*) next to some model names signifies that their pretraining data included high-quality images and captions not representative of the COCO dataset’s distribution. This deviation in training data can lead to lower FID scores, potentially misrepresenting the model’s true performance.
read the caption
Table 1: Text-to-Image Generation on MSCOCO-30K Benchmark. *Indicates models pretraining data consists of high quality images and captions that do not follow the distribution of COCO dataset, which can negatively affect FID scores.
In-depth insights#
Multimodal Flows#
Multimodal flows represent a significant advancement in generative modeling, enabling the seamless integration of diverse data modalities like text, images, and audio within a unified framework. Unlike traditional approaches that treat each modality separately, multimodal flows learn a joint distribution across modalities, thereby capturing intricate relationships and dependencies. This holistic approach allows for more coherent and contextually rich generation tasks, such as synthesizing an image based on both textual and audio descriptions. A key challenge is handling the varying dimensionality and structural differences across modalities, requiring sophisticated techniques to effectively encode and align information. Successful implementations often involve advancements in flow-based models, enabling efficient learning of complex transformations. The ability to control and guide the generation process across modalities is crucial, necessitating innovative methods for user-specified control or conditional generation. Future research directions include exploring more efficient architectures, expanding the range of supported modalities, and addressing potential limitations like biases and inaccuracies inherited from training data. The potential applications of multimodal flows are vast, ranging from improved AI assistants and creative content generation to advanced medical diagnosis and scientific discovery.
Rectified Flow Ext#
The heading ‘Rectified Flow Ext’ suggests an extension or enhancement of the rectified flow framework. This likely involves improving upon existing rectified flow models to address limitations or expand their capabilities. A key aspect might be the incorporation of additional modalities, such as audio or video, beyond the typical image and text data handled by standard rectified flows. This extension could leverage techniques like multi-modal transformers or attention mechanisms to effectively integrate and process information from various sources. The ‘Rectified Flow Ext’ might also involve refinements to the training process itself, perhaps incorporating novel loss functions or optimization strategies. This could lead to better performance, improved stability, or faster training times. Another potential area of improvement is enhanced controllability, allowing users to have more influence over the generated outputs using various guidance techniques. Ultimately, the goal of ‘Rectified Flow Ext’ is likely to create a more powerful and versatile generative model capable of handling a wider range of tasks and achieving superior performance in any-to-any generation, as suggested by the paper’s main focus.
OmniFlow Arch#
The OmniFlow architecture is a modular, multi-modal extension of Stable Diffusion’s MMDiT architecture. Its design prioritizes efficient training by allowing individual modality-specific components (text, image, audio) to be pretrained independently. These components then interact effectively through joint attention layers, facilitating coherent multi-modal generation. The architecture incorporates a novel multi-modal rectified flow formulation, enabling flexible control over the alignment between different modalities via a guidance mechanism. This modularity and the efficient training strategy represent key advantages of OmniFlow, offering a scalable solution for any-to-any generation tasks that avoids the computational burdens of training large, monolithic models from scratch. The design choices in OmniFlow, particularly concerning the rectified flow formulation and the guidance mechanism, provide valuable insights into optimizing multi-modal diffusion models. The effectiveness of this design is demonstrated through superior performance on a range of tasks and comparisons with previous any-to-any models.
Any-to-Any Gen#
The concept of ‘Any-to-Any Gen’ signifies a significant advancement in generative AI, moving beyond the limitations of single-modality models. It represents the ability of a model to seamlessly translate between diverse data types, such as text, image, and audio. This multi-modal capability is crucial for more natural and intuitive AI interactions, allowing for a more fluid exchange of information across different sensory modalities. The core challenge lies in effectively handling the complex relationships and dependencies between these various data formats. Successful ‘Any-to-Any Gen’ hinges on a robust architecture that can process, learn, and generate across modalities in a unified and coherent way. This includes overcoming hurdles such as modality-specific biases, data scarcity in certain modalities, and the computational complexity of managing heterogeneous data types. The potential applications are vast, ranging from realistic content creation to advanced AI assistants capable of versatile communication and problem-solving. However, achieving truly generalizable ‘Any-to-Any Gen’ requires addressing further challenges in scaling the models and handling rare or unseen modality combinations. The field is rapidly evolving, with ongoing research focusing on efficient architectures, robust training methods, and novel ways to evaluate the performance and generalizability of these impressive multi-modal models. The implications of successful ‘Any-to-Any Gen’ are far-reaching, promising a more integrated and immersive experience in human-computer interaction.
Future Work#
Future research directions stemming from this work on OmniFlow, a multi-modal generative model, are plentiful. Extending the model to encompass additional modalities beyond text, image, and audio (e.g., video, haptic feedback) would significantly broaden its capabilities and applications. Further research could explore optimizing the model’s architecture for specific any-to-any generation tasks to achieve even greater efficiency and performance. A deeper investigation into the guidance mechanism and its impact on the quality and controllability of generated outputs would improve user experience. Addressing the limitations in text generation, especially the reliance on large quantities of noisy text data, is vital for improving the model’s overall performance and capabilities. Finally, exploring the application of OmniFlow to more complex and creative tasks, investigating potential ethical implications, and developing robust evaluation metrics are crucial steps in advancing this impactful research.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architectural differences between OmniFlow and previous any-to-any generation models. Traditional approaches, exemplified by CoDi, use separate encoders and decoders for each modality (e.g., text, image, audio), combining their embeddings through simple averaging for joint conditioning. This method lacks nuanced interaction between modalities. In contrast, OmniFlow presents a unified, modular architecture. It directly interacts features across modalities using joint attention layers, allowing for more complex and coherent multi-modal generation. OmniFlow’s design is inspired by the modular text-to-image model Stable Diffusion 3.
read the caption
Figure 2: Pipeline of OmniFlow. Previous any-to-any models such as CoDi [46] (Top) concatenate multiple modality-specific encoders and decoders, and naively average the embedding of multiple modalities to achieve joint conditioning. By contrast, OmniFlow (Bottom) is a unified, modular multi-modal model, where features from different modalities directly interact with each other through joint attention layers. OmniFlow is inspired by the modular design of Stable Diffusion 3 [11] (Middle), a text-to-image model.

🔼 This figure shows a detailed breakdown of the OmniFlow model’s architecture. It illustrates the multi-modal nature of the model, demonstrating how multiple input modalities (text, image, audio) are processed through a series of encoding, joint attention, and decoding stages to generate outputs in any of those modalities or combinations thereof. The figure highlights the modular design of OmniFlow, where modality-specific blocks are used, allowing for independent pre-training and efficient integration. This unified approach contrasts with prior methods that concatenate separate modality-specific models.
read the caption
(a) Overall Pipeline of OmniFlow

🔼 The Omni-Transformer Block is a modular building block of the OmniFlow model. It takes as input the modality-specific latent representations (image, audio, text) and a unified timestep embedding. The modality-specific inputs are processed through separate projection layers to obtain queries (Q), keys (K), and values (V). These are concatenated across modalities before being fed into a joint attention mechanism, which allows for interaction between different modalities. The output of the joint attention is then passed through a feed-forward network (FFN) and skip connections are added to improve information flow. The unified timestep embedding modulates both the joint attention and FFN layers. The figure shows the architecture of this block in detail.
read the caption
(b) Design of Omni-Transformer Block

🔼 This figure details the architecture of the OmniFlow model, a multi-modal generative model. The left panel presents a high-level overview of the OmniFlow pipeline, illustrating how different modalities (image, text, and audio) are processed. It shows the input streams, the modality-specific Variational Autoencoders (VAEs) used for latent representation, the Omni-Transformer blocks where multi-modal interaction happens, and the final output streams. The right panel zooms in on the structure of a single Omni-Transformer block, which is a key component of the model. It displays the internal operations within a block, including the use of joint attention mechanisms to allow information flow and interaction between different modalities. This detailed view highlights the modular and multi-modal design of the OmniFlow model.
read the caption
Figure 3: Architecture of OmniFlow. Left: We highlight the architecture of OmniFlow. Right: We show the design of an individual Omni-Transformer Block.

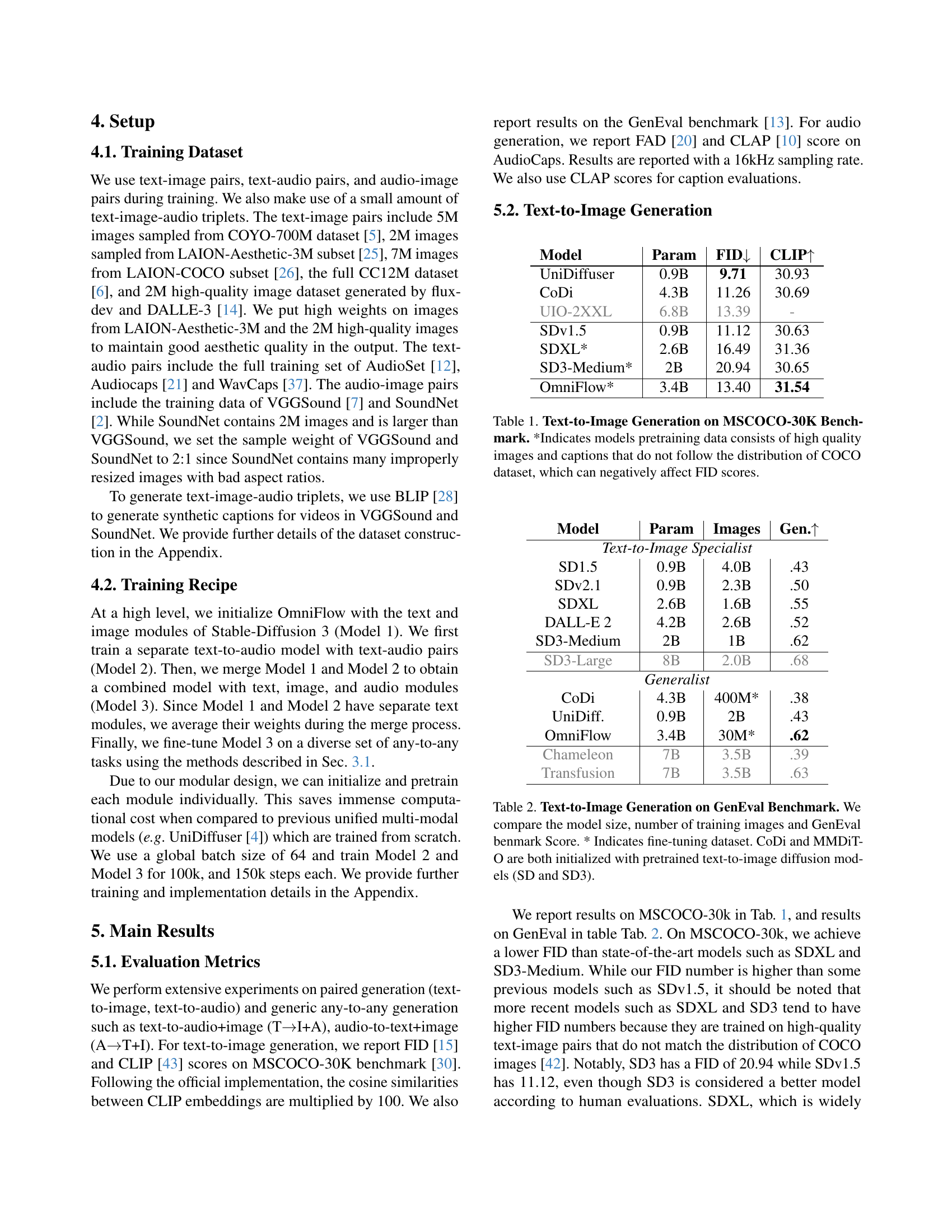
🔼 This figure shows the impact of classifier-free guidance (CFG) and timestep shift on the quality of text-to-audio generation. The x-axis represents the CFG scale, while the y-axis represents the FAD score (lower is better). Different lines represent different timestep shifts. The plot helps to determine the optimal settings for achieving the best audio generation quality.
read the caption
(a) Text-to-Audio Generation.

🔼 This figure shows the results of experiments on audio-to-text generation. The graph displays the relationship between classifier-free guidance (CFG) and the timestep shift for audio-to-text generation. Different lines on the graph represent experiments with different timestep shifts. This allows for an understanding of how changes in the CFG value and the timestep shift affect the performance of audio-to-text generation. The x-axis shows the CFG value, and the y-axis shows the CLAP score, which measures the quality of the generated text captions.
read the caption
(b) Audio-to-Text Generation.

🔼 This figure displays the impact of classifier-free guidance (CFG) and timestep shift on the quality of audio and text generation. Two subfigures are presented, one for text-to-audio generation and another for audio-to-text generation. Each subfigure shows curves plotting a performance metric (FAD for audio and CLIP for text) against the CFG scale for different values of timestep shift. The curves illustrate how adjusting these two parameters influences the quality of the generated audio and text, allowing for fine-tuned control over the generation process.
read the caption
Figure 4: Effect of CFG and Shift for audio and text generation. We evaluate the impact of guidance and timestep shift on text-to-audio and audio-to-text tasks.

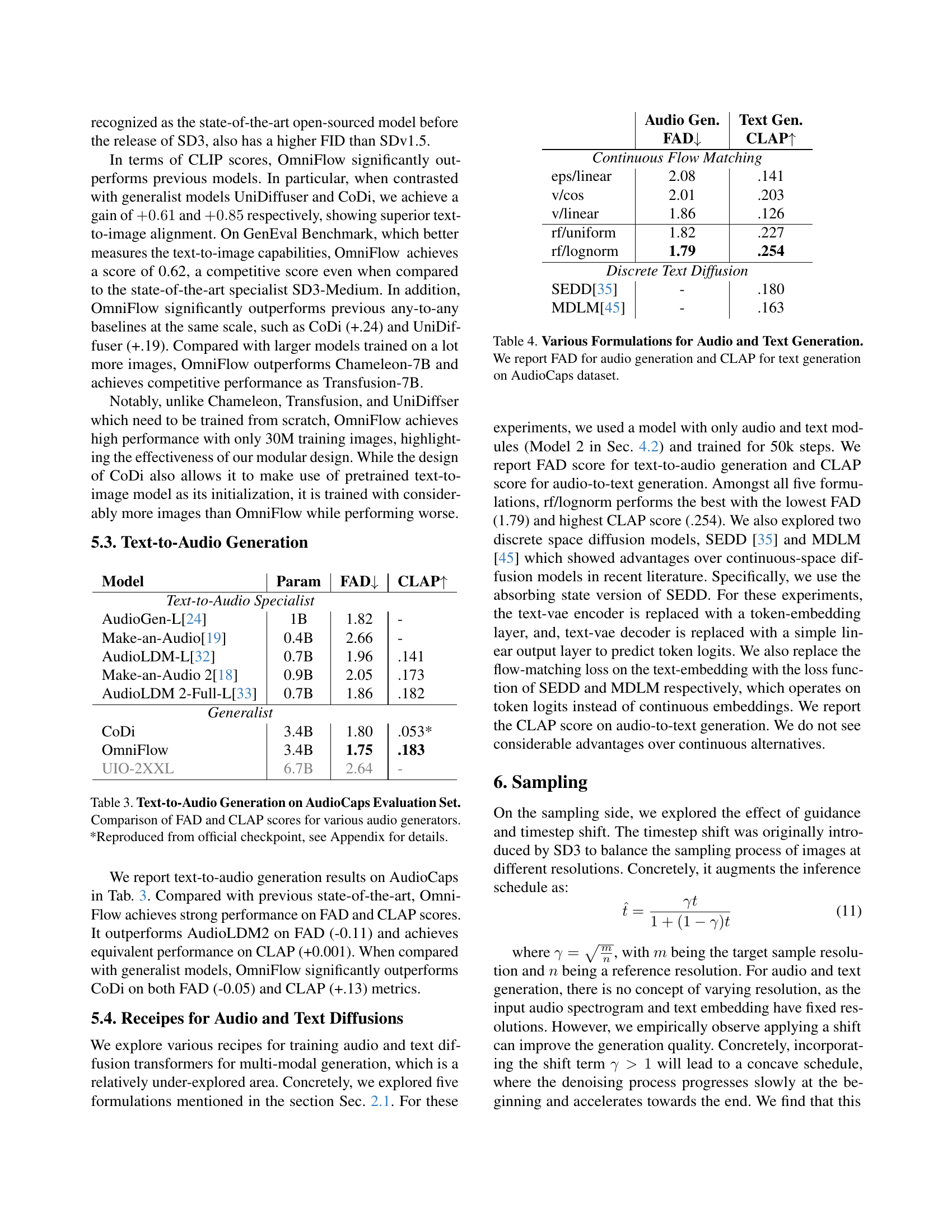
🔼 Figure 5 demonstrates the control OmniFlow offers over the alignment between generated text and the input modalities (image and audio). By adjusting two parameters, αim (alpha_im) and αau (alpha_au), users can independently influence whether the generated text prioritizes visual or auditory details. Increasing αim emphasizes aspects described in the input image (e.g., ’lined up’, ‘driving down’), while raising αau focuses the generated text on audio-related descriptors (e.g., ‘accelerating’, ‘revving’). This showcases the model’s ability to blend different input sources in flexible and nuanced ways.
read the caption
Figure 5: Effect of Multi-Modal Guidance. In this example, the user can flexibly control the alignment between output text and input image, audio independently by varying αausubscript𝛼au\alpha_{\text{au}}italic_α start_POSTSUBSCRIPT au end_POSTSUBSCRIPT and αimsubscript𝛼im\alpha_{\text{im}}italic_α start_POSTSUBSCRIPT im end_POSTSUBSCRIPT. Higher αimsubscript𝛼im\alpha_{\text{im}}italic_α start_POSTSUBSCRIPT im end_POSTSUBSCRIPT will make the output texts resemble image captions, with visual descriptions such as lined up, driving down. Higher αausubscript𝛼au\alpha_{\text{au}}italic_α start_POSTSUBSCRIPT au end_POSTSUBSCRIPT will make the output texts resemble audio captions, with descriptions such as accelerating, revving.

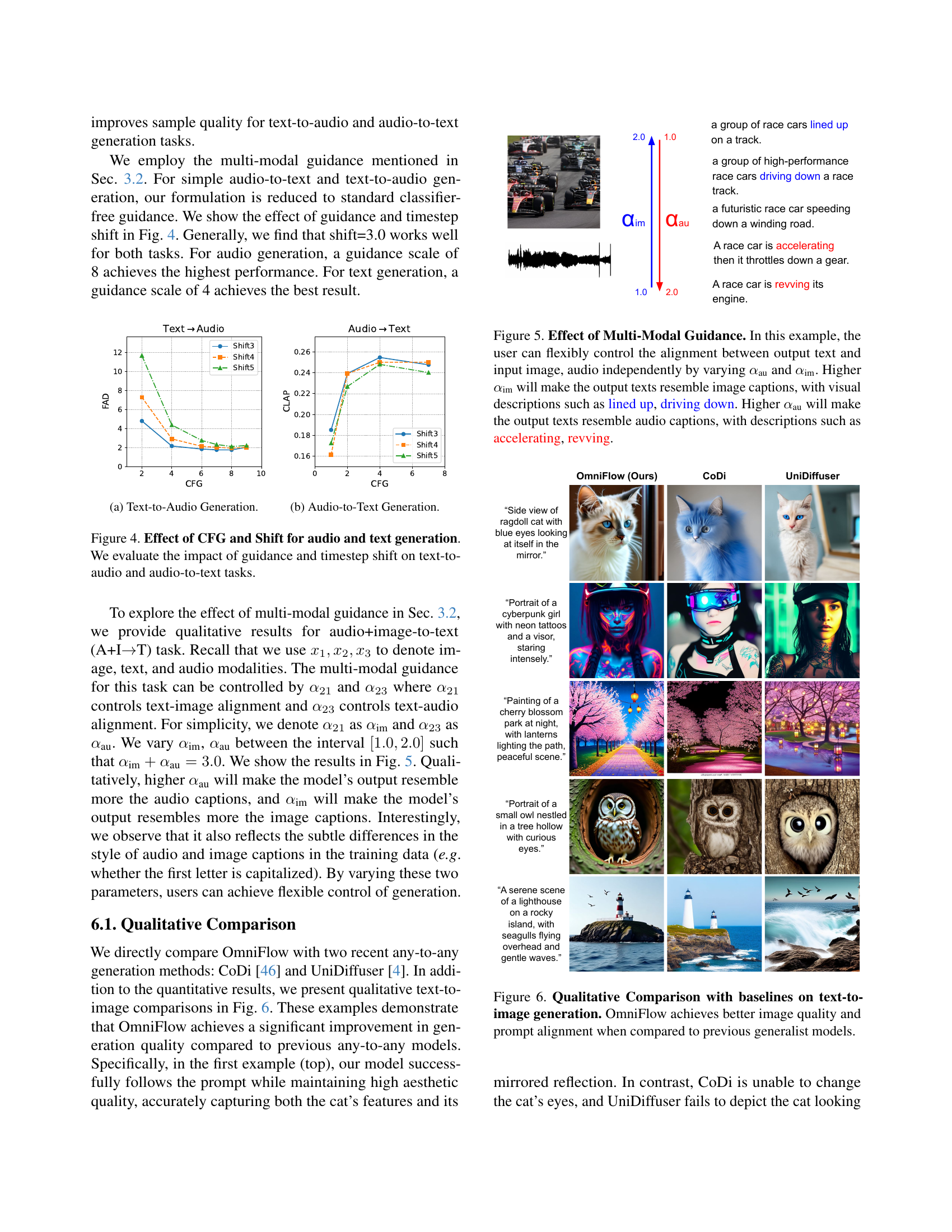
🔼 Figure 6 presents a qualitative comparison of image generation results between OmniFlow and two other any-to-any generation models (CoDi and UniDiffuser) using the same text prompts. The figure showcases how OmniFlow produces images with significantly better quality and a closer adherence to the details and style specified in the text prompts when compared to the baselines. This visual comparison highlights OmniFlow’s strengths in achieving superior alignment between the generated image and the input text description.
read the caption
Figure 6: Qualitative Comparison with baselines on text-to-image generation. OmniFlow achieves better image quality and prompt alignment when compared to previous generalist models.

🔼 This figure illustrates how different any-to-any generation tasks can be represented using a three-dimensional space defined by the ’noise levels’ of image (t1), text (t2), and audio (t3) modalities. Each point in this space corresponds to a different combination of noise levels for each modality. The origin (0, 0, 0) signifies clean data for all three modalities (a clean image, clean text, and clean audio). The point (1, 1, 1) represents pure Gaussian noise for all three modalities. Different generation tasks are represented by paths connecting various points within this space. For example, text-to-image generation would be a path from a point representing clean text and pure noise for image and audio to a point representing a combination of clean text and image with pure noise in audio. This visualization helps to understand how OmniFlow handles the joint distribution of multiple modalities in a unified framework.
read the caption
Figure 7: Paths encoding different any-to-any generation tasks. (t1,t2,t3)subscript𝑡1subscript𝑡2subscript𝑡3(t_{1},t_{2},t_{3})( italic_t start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_t start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , italic_t start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT ) represents the “noise level” of image, text and audio modalities. (0,0,0)000(0,0,0)( 0 , 0 , 0 ) represents clean (image, text, audio) triplets, and (1,1,1)111(1,1,1)( 1 , 1 , 1 ) represents pure Gaussian noise.
🔼 This figure illustrates the training pipeline used to develop the OmniFlow model. The process begins by initializing the model with the architecture and weights of Stable Diffusion 3 (referred to as Model 1). Next, Model 1 is trained on a dataset of text-audio pairs to create a specialized model capable of text-to-audio generation (Model 2). Model 1 and Model 2 are then merged, combining their respective components to generate Model 3. Finally, Model 3 is further fine-tuned on a more extensive dataset encompassing various any-to-any generation tasks (text-to-image, audio-to-image, etc.) to achieve the final OmniFlow model.
read the caption
Figure 8: Training Pipeline of OmniFlow. We initialize our model with SD3 (Model 1). We then train the model on text-audio pairs to obtain Model 2. We merge Model 1 and Model 2 to obtain Model 3. The final model is obtained by further training Model 3 on any-to-any generation tasks.

🔼 Figure 9 details the architecture of the text Variational Autoencoder (VAE) and text encoders used in the OmniFlow model. The top portion shows the architecture of Stable Diffusion 3 (SD3), which uses three text encoders: CLIP-L, CLIP-G, and the large T5-XXL model. The middle section illustrates how OmniFlow modifies this architecture. It replaces the large and computationally expensive T5-XXL model with a more efficient VAE encoder built upon the Flan-T5-L model. The CLIP encoders become optional in OmniFlow and are only used when clean text inputs are available; they are not necessary for tasks that don’t involve text input. Finally, the bottom section shows the VAE decoder, which is based on the TinyLlama-1.1B model. The embedding generated by the VAE is used as a prefix in the decoding process.
read the caption
Figure 9: Architecture of Text VAE and Text Encoders in OmniFlow. SD3 (Top) uses three text encoders: CLIP-L, CLIP-G, and T5-XXL. OmniFlow (Middile) replaces the 4.7B T5-XXL with a VAE encoder based on Flan-T5-L. CLIP encoders become optional and are not used for tasks without clean text inputs. The decoder of VAE (Bottom) is based on TinyLlama-1.1B. The VAE embedding is used as the prefix for decoding.

🔼 This figure illustrates a variant of the OmniFlow model architecture where discrete diffusion is used for text processing. Unlike the standard OmniFlow, which uses a text Variational Autoencoder (VAE), this variant directly inputs token embeddings into the Omni-Transformer blocks. The text is processed in a discrete token space, where tokens are progressively masked using ‘[m]’ tokens, representing a masked token. This modification simplifies the text processing pathway and removes the need for the VAE.
read the caption
Figure 10: Discrete Diffusion Variant of OmniFlow. In this setup, we remove the text VAE and directly pass token embedding to the Omni-Transformer layers. “[m]” indicates a mask token.

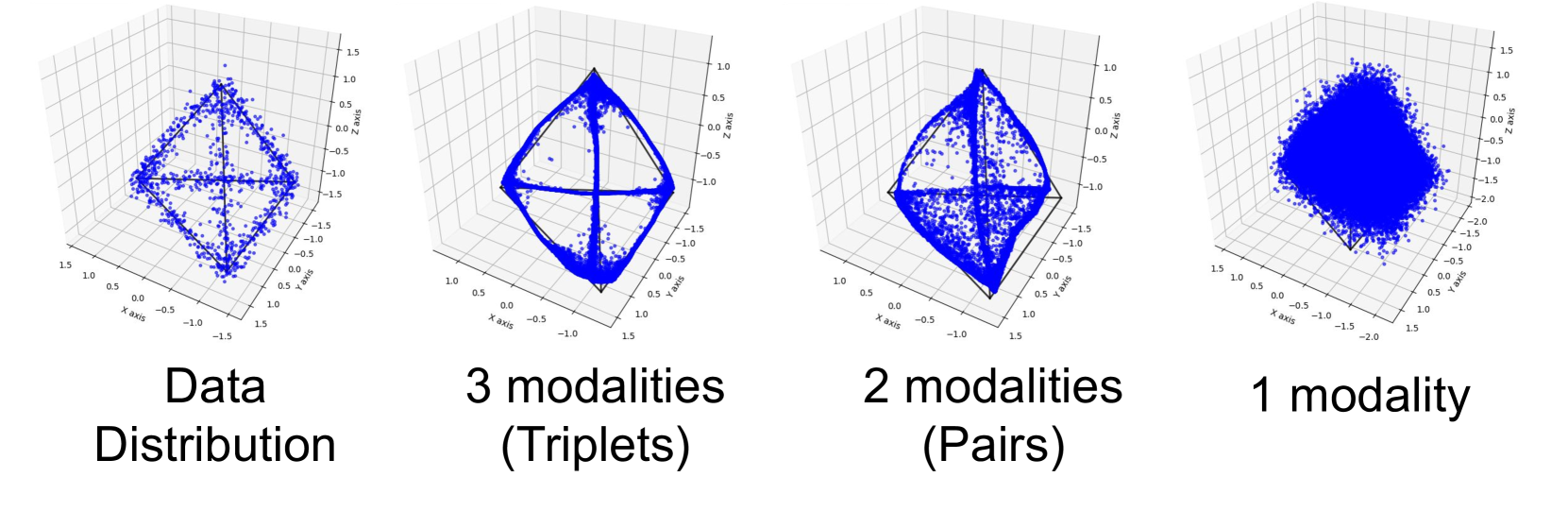
🔼 This figure displays synthetic experiments performed on three 1D modalities to evaluate the effectiveness of training data configurations on OmniFlow. Each modality (x1, x2, x3) is represented by a 1D vector, resulting in triplets represented as points in 3D space. A uniform distribution within the neighborhood of a tetrahedron is assumed as the joint distribution. The experiment compares the performance of OmniFlow trained on different data configurations: triplets (all three modalities together), pairs (combinations of two modalities), and individual modalities. The results show that models trained on triplets best capture the original distribution.
read the caption
Figure 11: Synthetic Experiments on three 1D-modalities. We consider the joint distribution of three toy modalities (x1,x2,x3subscript𝑥1subscript𝑥2subscript𝑥3x_{1},x_{2},x_{3}italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , italic_x start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT), each represented by a vector of dimension 1. Hence, a triplet consisting of three modalities be represented by a point in ℝ3superscriptℝ3\mathbb{R}^{3}blackboard_R start_POSTSUPERSCRIPT 3 end_POSTSUPERSCRIPT We assume the joint distribution is a uniform distribution in the neighborhood of tetrahedron (Left). We experiment with training OmniFlowusing triplets, pairs, and only individual modalities. Models trained with triplets of three modalities best represent the original distribution.
More on tables
| Model | Param | Images | Gen.↑ | |
|---|---|---|---|---|
| Text-to-Image Specialist | ||||
| SD1.5 | 0.9B | 4.0B | .43 | |
| SDv2.1 | 0.9B | 2.3B | .50 | |
| SDXL | 2.6B | 1.6B | .55 | |
| DALL-E 2 | 4.2B | 2.6B | .52 | |
| SD3-Medium | 2B | 1B | .62 | |
| SD3-Large | 8B | 2.0B | .68 | |
| Generalist | ||||
| CoDi | 4.3B | 400M* | .38 | |
| UniDiff. | 0.9B | 2B | .43 | |
| OmniFlow | 3.4B | 30M* | .62 | |
| Chameleon | 7B | 3.5B | .39 | |
| Transfusion | 7B | 3.5B | .63 |
🔼 Table 2 presents a comparison of various models’ performance on the GenEval benchmark, a more comprehensive evaluation of text-to-image generation capabilities than simple metrics like FID and CLIP. The table highlights key factors influencing model performance, including model size (number of parameters), the quantity of training images used, and the final GenEval score achieved. It specifically compares models categorized as either ‘Text-to-Image Specialists’ or ‘Generalists’, illustrating the trade-off between specialization and generalization. The asterisk (*) indicates models that underwent additional fine-tuning, highlighting that the results may not be solely representative of the base models. Noteworthy is the inclusion of CoDi and MMDIT-O, which were both initialized with pre-trained text-to-image diffusion models (Stable Diffusion and Stable Diffusion 3 respectively), showing how prior training can impact performance.
read the caption
Table 2: Text-to-Image Generation on GenEval Benchmark. We compare the model size, number of training images and GenEval benmark Score. * Indicates fine-tuning dataset. CoDi and MMDiT-O are both initialized with pretrained text-to-image diffusion models (SD and SD3).
| Model | Param | FAD↓ | CLAP↑ |
|---|---|---|---|
| Text-to-Audio Specialist | |||
| AudioGen-L [24] | 1B | 1.82 | - |
| Make-an-Audio [19] | 0.4B | 2.66 | - |
| AudioLDM-L [32] | 0.7B | 1.96 | .141 |
| Make-an-Audio 2 [18] | 0.9B | 2.05 | .173 |
| AudioLDM 2-Full-L [33] | 0.7B | 1.86 | .182 |
| Generalist | |||
| CoDi | 3.4B | 1.80 | .053* |
| OmniFlow | 3.4B | 1.75 | .183 |
| UIO-2XXL | 6.7B | 2.64 | - |
🔼 This table presents a quantitative comparison of different text-to-audio generation models on the AudioCaps evaluation set. The comparison is based on two metrics: FAD (Fréchet Audio Distance), which measures the similarity between the generated audio and the ground truth audio, and CLAP (Contrastive Language–Audio Pre-training), which evaluates how well the generated audio aligns with the text prompt. Lower FAD scores indicate better audio quality and higher CLAP scores reflect a stronger alignment between audio and text. The table includes both specialized text-to-audio models and general-purpose models that can perform a wider range of tasks. One model’s result is marked with an asterisk (*) indicating the data was obtained from an official checkpoint rather than the authors’ own training, with details found in the appendix.
read the caption
Table 3: Text-to-Audio Generation on AudioCaps Evaluation Set. Comparison of FAD and CLAP scores for various audio generators. *Reproduced from official checkpoint, see Appendix for details.
| Audio Gen. | Text Gen. | |
|---|---|---|
| FAD↓ | CLAP↑ | |
| Continuous Flow Matching | ||
| eps/linear | 2.08 | .141 |
| v/cos | 2.01 | .203 |
| v/linear | 1.86 | .126 |
| rf/uniform | 1.82 | .227 |
| rf/lognorm | 1.79 | .254 |
| Discrete Text Diffusion | ||
| SEDD[35] | - | .180 |
| MDLM[45] | - | .163 |
🔼 This table presents a comparison of different mathematical formulations used for training audio and text diffusion models. The performance of each formulation is evaluated using two metrics: FAD (Frequency-Aware Distance) for audio generation quality and CLAP (Contrastive Language–Audio Pre-training) for text generation quality. The results are obtained from experiments conducted on the AudioCaps dataset, a dataset of audio clips paired with their corresponding text descriptions. The table aids in understanding the impact of different mathematical formulations on the quality of generated audio and text.
read the caption
Table 4: Various Formulations for Audio and Text Generation. We report FAD for audio generation and CLAP for text generation on AudioCaps dataset.
| Dataset | Size | Modality |
|---|---|---|
| LAION-Aesthetics-3M | 2M* | T,I |
| CC12M | 12M | T,I |
| COYO-700M(Subset) | 5M | T,I |
| LAION-COCO | 7M | T,I |
| SoundNet | 2M | T,A,I† |
| VGGSound | 0.2M | T,A,I† |
| T2I-2M | 2M | T,I |
| AudioSet | 2M | T,A |
| AudioCaps | 46K | T,A |
| WavCaps | 0.4M | T,A |
🔼 This table lists the datasets used to train the OmniFlow model. It details the name of each dataset, the approximate number of samples (images, audio, or text), and the modalities (text, image, and/or audio) present in each dataset. Note that some image URLs from certain datasets may no longer be accessible, and synthetic captions were generated for some datasets using the BLIP model.
read the caption
Table 5: List of all datasets used in training. *Some image URLs are no longer accessible. ††{\dagger}† We generate synthetic captions using BLIP.
| Images | Parms. | CLAP↑ | CIDEr↑ | CLIP↑ | CIDEr↑ | |
|---|---|---|---|---|---|---|
| AudioCaps | CLAP↑ | CIDEr↑ | CLIP↑ | CIDEr↑ | ||
| COCO-Karpathy | ||||||
| Specialist | ||||||
| BLIP-2[29] | 129M | 2.7B | - | - | - | 145.8 ‡ |
| SLAM-AAC[8] | - | 7B | - | 84.1 ‡ | - | - |
| Generalist | ||||||
| OmniFlow | 30M | 3.4B | 0.254 | 48.0 | 26.8 | 47.3 |
| CoDi † | 400M | 4.3B | 0.206 | 7.9 | 25.9 | 17.2 |
| Unidiffuser † | 2B | 0.9B | - | - | 29.3 | 20.5 |
| UIO2-XXL | 1B* | 6.8B | - | 48.9 | - | 125.4* |
| Transfusion | 3.5B | 7B | - | - | - | 35.2 |
🔼 This table compares the performance of different models on two tasks: generating captions for audio clips (AudioCaps) and generating captions for images (COCO-Karpathy). The models are categorized as either specialized (trained only on one dataset) or generalist (trained on multiple datasets). Performance is measured using three metrics: CLAP (a metric assessing the alignment of generated text with audio features), CIDEr (a metric evaluating the quality and relevance of image captions), and CLIP (a metric assessing the consistency between image features and the generated text). Note that UIO2 used COCO data in its training, and it was further fine-tuned with additional image understanding data. Some models’ results were obtained using officially released checkpoints, while other models were fine-tuned on specific datasets to ensure a fair comparison.
read the caption
Table 6: X-to-Text Performance comparison on AudioCaps and COCO Captions. * UIO2’s training data includes COCO. The fine-tuning dataset also includes 53M image understanding data, including 14 image captioning datasets. ††{\dagger}† evaluated with official checkpoints. ‡‡\ddagger‡ fine-tuned on respective datasets (COCO and Audiocaps).
| ID | CoDi | OmniFlow | GT |
|---|---|---|---|
| yVjivgsU2aA | Four car driver trying forcoming for a speeding car. | A race car engine revs and tires squeal. | An engine running followed by the engine revving and tires screeching. |
| 8F-ndyrEWJ8 | Fire police cars stop and red traffic on different highway. | A fire siren goes off loudly as a man shouts and a low hum of an engine is running throughout the whole time. | A distant police siren, then racing car engine noise, and a man calling in police code over his radio. |
| 350OCezayrk | Four motor car driving for completing an automobile service. | A vehicle engine is revving and idling. | A motor vehicle engine starter grinds, and a mid-size engine starts up and idles smoothly. |
| LCwSUVuTyvg | Door, a blue hat and winter jacket. | A door is being slammed. | Glass doors slamming and sliding shut. |
| 7XUt6sQS7nM | The sheep of the woman are the sheep of the sheep. | Multiple sheep bleat nearby. | A sheep is bleating and a crowd is murmuring. |
| PVvi2SDOjVc | Car going for a car coming home. Three cars coming for a blue car coming down a road after the highway. | A car horn beeps. | A car engine idles and then the horn blows. |
| Z_smJ66Tb3c | Men in the bird while the man in the boat. | Two men talk over blowing wind and bird chirps. | A man is speaking with bird sounds in the background followed by a whistling sound. |
| CMNlIW6Lkwc | Two men in the fire and two men are coming towards the other man in the game. | A man speaks, followed by a loud bang and people laughing. | A man talking as a camera muffles followed by a loud explosion then a group of people laughing and talking. |
| JQz40TkjymY | Writing computers for people in writing. | Typing on a computer keyboard. | Typing on a computer keyboard. |
| U90e2P9jy30 | A man shouts the word to the person on the sidewalk to walk to get him to the door the hand to fall down on the sidewalk in. | Basketballs being dribbled and people talking. | Several basketballs bouncing and shoes squeaking on a hardwood surface as a man yells in the distance. |
| 5I8lmN8rwDM | Stationary fire drill technician drilling down a hose pipe while wearing safety gear. Railroad safety drill for motorcycle with hose or oil checking equipment. | A drill runs continuously. | Drilling noise loud and continues. |
| NlKlRKz8OKI | Birds on blue birds. | A woman talks and then an animal chewing. | A woman speaks with flapping wings and chirping birds. |
🔼 This table presents a qualitative comparison of the performance of two any-to-any generation models, CoDi and OmniFlow, on the AudioCaps audio captioning task. Randomly selected audio clips from the AudioCaps dataset were used for evaluation. AudioCaps provides five ground truth captions per audio clip, but only one ground truth caption is shown in the table for better readability and presentation. The table allows for a direct comparison of the generated captions for each audio clip between the two models, highlighting differences in accuracy and detail. This comparison provides insight into the relative strengths and weaknesses of CoDi and OmniFlow in terms of their ability to generate accurate and descriptive captions for unseen audio data.
read the caption
Table 7: Qualitative comparisons of CoDi and OmniFlow on Audiocaps audio captioning task. Audios are randomly sampled. Audiocaps provide five ground truth captions per audio. For better presentation, we only list one in this table.
| Reconstruction | GT |
|---|---|
| Crispy chicken tenders alongside a portion of a bbq sauce. | Crispy chicken tenders alongside a portion of bbq sauce. |
| A well-furnished living room with a patterned curtain rod, a small white side table holding a vase of flowers, and a tufted gray sofa. | A well-decorated living room with a patterned curtain panel hanging from the window, a small white side table holding a vase of flowers, and a tufted gray sofa. |
| A young man wearing a black shirt and holding an American flag. | A young man wearing a black shirt and holding an American flag. |
| An artistic painting of a futuristic city by the water. | An artistic painting of a futuristic city by the water. |
| Cozy and well-designed living room with a green velvet sofa, glass coffee table displaying potted plants, and a large skylight overhead. | Cozy and stylish living room with a green velvet sofa, glass coffee table displaying potted plants, and a large skylight overhead. |
| A silver Audi Rs4 sedan driving on the passenger side near a mountainous coastline. | A silver Acura RLX sedan driving on the passenger side near a mountainous coastline. |
🔼 This table presents a qualitative evaluation of the Text Variational Autoencoder (VAE) used in the OmniFlow model. For several input captions, it shows the text generated by the VAE after reconstruction (left column) and compares it to the original, ground truth caption (right column). The purpose is to demonstrate that while there may be minor word choices differences between the reconstructed text and the original, the overall semantic meaning is preserved.
read the caption
Table 8: Text VAE reconstruction results. We show reconstruction results (Left) and the ground truth text (Right).The reconstruction mostly adheres to the semantics of the ground truth, with minor differences.
Full paper#