TL;DR#
Current embodied instance navigation tasks assume users provide complete descriptions before navigation starts. This is unrealistic; real-world instructions are often brief and ambiguous. This paper introduces Collaborative Instance Navigation (COIN), where agents interact dynamically with users during navigation to clarify ambiguities. This requires addressing when and how to interact effectively.
The paper proposes a novel method, AIUTA, which uses Vision-Language Models (VLMs) and Large Language Models (LLMs) for self-dialogue to refine object descriptions and reduce uncertainties. An Interaction Trigger module decides when to ask clarifying questions from the user, minimizing interaction. The authors introduce CoIN-Bench, a benchmark with real and simulated users, to evaluate AIUTA’s performance and demonstrate its efficiency in minimizing user input.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and realistic task, Collaborative Instance Navigation (COIN), that addresses limitations in existing embodied navigation methods. By minimizing user input through dynamic agent-human interaction, it paves the way for more natural and efficient human-robot collaboration. The proposed AIUTA method and the CoIN-Bench benchmark provide valuable resources for future research in human-centered AI, particularly in areas like robotics and human-computer interaction.
Visual Insights#

🔼 This figure illustrates the Collaborative Instance Navigation (COIN) task and the AIUTA method. A user requests to find a picture. The AIUTA-equipped agent navigates an unknown environment, interacting with the user only when necessary through open-ended dialogue. The agent uses two modules: a Self-Questioner (which uses an LLM and a VLM in a self-dialogue to refine object descriptions) and an Interaction Trigger (which decides whether to ask the user a question, continue navigation, or stop). The figure shows the agent’s path (1-5) with blue boxes showing the Self-Questioner and Interaction Trigger outputs at each step. The right side details the inner workings of the modules.
read the caption
Figure 1: A sketched episode of the proposed Collaborative Instance Navigation (CoIN) task. The human user (bottom left) provides a request (“Find the picture”) in natural language. The agent has to locate the object within a completely unknown environment, interacting with the user only when needed via template-free, open-ended natural-language dialogue. Our method, Agent-user Interaction with UncerTainty Awareness (AIUTA), addresses this challenging task, minimizing user interactions by equipping the agent with two modules: a Self-Questioner and an Interaction Trigger, whose output is shown in the blue boxes along the agent’s path (① to ⑤), and whose inner working is shown on the right. The Self-Questioner leverages a Large Language Model (LLM) and Vision Language Model (VLM) in a self-dialogue to initially describe the agent’s observation, and then extract additional relevant details, with a novel entropy-based technique to reduce hallucinations and inaccuracies, producing a refined detection description. The Interaction Trigger uses this refined description to decide whether to pose a question to the user (①,③,④), continue the navigation (②) or halt the exploration (⑤).
| Method | Model Condition Input | Model Condition Training-free | Val Seen SR ↑ | Val Seen SPL ↑ | Val Seen NQ ↓ | Val Seen Synonym SR ↑ | Val Seen Synonym SPL ↑ | Val Seen Synonym NQ ↓ | Val Unseen SR ↑ | Val Unseen SPL ↑ | Val Unseen NQ ↓ | Train SR ↑ | Train SPL ↑ | Train NQ ↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Monolithic [10] (CVPR-24) | d | ✗ | 4.88 | 2.93 | - | 8.33 | 1.54 | - | 0 | 0 | - | 6.58 | 4.08 | |
| PSL [35] (ECCV-24) | d | ✗ | 10.98 | 5.71 | - | 8.33 | 3.06 | - | 4.26 | 2.67 | - | 4.61 | 1.39 | |
| VFLM [44] (ICRA-24) | c | ✔ | 0 | 0 | - | 0 | 0 | - | 0 | 0 | - | 0.66 | 0.61 | |
| AIUTA | c | ✔ | 8.64 | 3.2 | 1.57 | 11.11 | 3.32 | 1.50 | 12.77 | 9 | 1.66 | 14.47 | 7.22 | 1.68 |
🔼 Table 1 presents a comparison of the proposed AIUTA model against existing state-of-the-art methods on the CoIN-Bench benchmark. The table evaluates performance across multiple metrics: Success Rate (SR, highlighted as the primary metric), Success Rate weighted by Path Length (SPL), and the average Number of Questions (NQ) asked during the navigation task. Crucially, the table also indicates whether each model is training-free and specifies the input type it uses: ‘c’ for models utilizing only the object category and ’d’ for models utilizing a detailed description of the object. This detailed breakdown allows for a comprehensive comparison of model performance, considering both accuracy and efficiency, as well as the level of user input required.
read the caption
Table 1: Results of the proposed AIUTA compared with baselines on the CoIN-Bench benchmark. We analyzed the SR (main metric, in gray), SPL, and the number of questions NQ. For each model, we indicate whether it operates in a training-free manner. Additionally, we specify the input type: c denotes models that utilize only the object category as input, while d models that use its associated description.
In-depth insights#
CoIN Task Intro#
The Collaborative Instance Navigation (CoIN) task introduces a novel, more realistic approach to embodied instance navigation by emphasizing dynamic human-agent interaction. Unlike traditional methods that assume complete initial descriptions, CoIN allows for minimal user input, such as simply specifying the object category. The agent actively engages in a template-free, open-ended dialogue with the user to clarify ambiguities and resolve uncertainties as needed during navigation. This requires the agent to not only perceive its surroundings but also to intelligently determine when and what to ask the user. This design better reflects real-world scenarios where detailed upfront instructions might be impractical. The CoIN task thus challenges existing methods to move beyond relying on exhaustive initial information and to adapt to the nuances of collaborative interaction in dynamic environments.
AIUTA Method#
The AIUTA method, presented in the context of Collaborative Instance Navigation (COIN), is a novel training-free approach that significantly reduces the need for explicit user input during embodied AI tasks. It leverages a synergistic interplay between a Vision Language Model (VLM) and a Large Language Model (LLM) to achieve this. The VLM provides initial visual perception, while the LLM refines this perception through a self-dialogue process, generating questions to clarify ambiguities and reduce hallucinations. This refined description is then used by an interaction trigger to determine if further user interaction is necessary, minimizing user input while maintaining high accuracy. The AIUTA method’s core strength lies in its capacity to handle uncertainty inherent in VLM outputs. A novel entropy-based technique quantifies this uncertainty, allowing the system to filter out unreliable details, resulting in a more robust and accurate representation of the scene. The combination of self-dialogue, uncertainty quantification, and a strategic interaction trigger forms the innovative core of the AIUTA method, making it a highly effective approach for collaborative instance navigation tasks.
CoIN-Bench Eval#
A hypothetical ‘CoIN-Bench Eval’ section would deeply analyze the proposed Collaborative Instance Navigation (CoIN) benchmark’s effectiveness. It would likely present results comparing the proposed AIUTA method against existing state-of-the-art object navigation techniques. Key metrics would include success rate, path efficiency, and crucially, the number of user interactions required. The evaluation would likely encompass both simulated and real human user studies, highlighting the strengths and limitations of each approach in handling varying levels of user input. Simulated users allow for scalable, repeatable experiments, while real users provide a more realistic measure of usability and robustness. A detailed breakdown of performance across different task difficulty levels (e.g., varying number of distractor objects) and user input types (e.g., minimal vs. detailed instructions) would be essential, demonstrating the true practical value and limitations of CoIN in real-world scenarios. The results would need to show AIUTA’s flexibility in minimizing user input while maintaining high performance. Finally, ablation studies would assess the impact of individual components of AIUTA, revealing which aspects are most crucial for success.
VLM Uncertainty#
Vision-Language Models (VLMs) are powerful tools, but their susceptibility to hallucinations and inaccuracies poses a significant challenge in applications like instance navigation. The concept of “VLM Uncertainty” directly addresses this, focusing on quantifying and mitigating the unreliability of VLM outputs. This is crucial because blindly trusting VLM outputs can lead to significant errors in downstream tasks. The paper explores this issue in the context of collaborative instance navigation where the agent relies on the VLM’s perception of the environment. The authors propose a novel entropy-based technique to estimate VLM uncertainty, which helps identify and filter unreliable or hallucinated information. This uncertainty estimation is not just a simple yes/no answer but a nuanced probabilistic assessment, allowing the agent to make informed decisions about whether to trust the VLM’s perception or seek clarification from a human user. The method’s effectiveness is demonstrated through experiments, showcasing its importance in improving the robustness and reliability of VLM-powered systems. The approach is shown to greatly improve the accuracy of the overall system, while maintaining efficiency by reducing the number of interactions with the human user.
Future Works#
Future work in collaborative instance navigation should prioritize reducing reliance on large language models (LLMs) due to their computational cost and potential privacy issues. Research could focus on developing more efficient, lightweight models suitable for onboard processing in robots. Improving the robustness of vision-language models (VLMs) to reduce inaccuracies and hallucinations is crucial. This could involve developing novel uncertainty estimation techniques or exploring alternative architectures. Expanding the CoIN-Bench dataset with diverse environments and object categories would further enhance the generalizability and reliability of future collaborative navigation systems. Finally, exploring more sophisticated techniques for agent-user interaction, moving beyond simple question-answer pairs towards more nuanced and context-aware dialogues, would significantly improve the user experience and overall efficiency of the system.
More visual insights#
More on figures
🔼 Figure 2 illustrates the AIUTA method’s workflow. The left side shows the interaction between the AIUTA agent and a human user. The agent receives an initial instruction (1), such as ‘Find the picture.’ At each timestep (2), a zero-shot policy, incorporating an object detection module, selects an action. Upon detecting a potential target object (3), AIUTA is activated. The agent uses a VLM to get an initial scene description (4), which is then refined by a Self-Questioner module using an LLM to generate attribute-specific questions for the VLM (4). This process reduces uncertainty, leading to a refined description (Srefined). The Interaction Trigger module (5) then compares this refined description to known facts to decide whether to stop navigation (6), because the target object is found, or to ask the user a question (7) to obtain more information, updating the known facts (8). The right side of the figure provides a detailed breakdown of the AIUTA architecture and its components.
read the caption
Figure 2: Graphical depiction of AIUTA: left shows its interaction cycle with the user, and right provides an exploded view of our method. ① The agent receives an initial instruction I𝐼Iitalic_I: “Find a c=<𝑐c=>>”. ② At each timestep t𝑡titalic_t, a zero-shot policy π𝜋\piitalic_π [44], comprising a frozen object detection module [17], selects the optimal action atsubscript𝑎𝑡a_{t}italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. ③ Upon detection, the agent performs the proposed AIUTA. Specifically, ④ the agent first obtains an initial scene description of observation Otsubscript𝑂𝑡O_{t}italic_O start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT from a VLM. Then, a Self-Questioner module leverages an LLM to automatically generate attribute-specific questions to the VLM, acquiring more information and refining the scene description with reduced attribute-level uncertainty, producing Srefinedsubscript𝑆𝑟𝑒𝑓𝑖𝑛𝑒𝑑S_{refined}italic_S start_POSTSUBSCRIPT italic_r italic_e italic_f italic_i italic_n italic_e italic_d end_POSTSUBSCRIPT. ⑤ The Interaction Trigger module then evaluates Srefinedsubscript𝑆𝑟𝑒𝑓𝑖𝑛𝑒𝑑S_{refined}italic_S start_POSTSUBSCRIPT italic_r italic_e italic_f italic_i italic_n italic_e italic_d end_POSTSUBSCRIPT against the “facts” related to the target, to determine whether to terminate the navigation (if the agent believes it has located the target object ⑥), or to pose template-free, natural-language questions to a human ⑦, updating the “facts” based on the response ⑧.

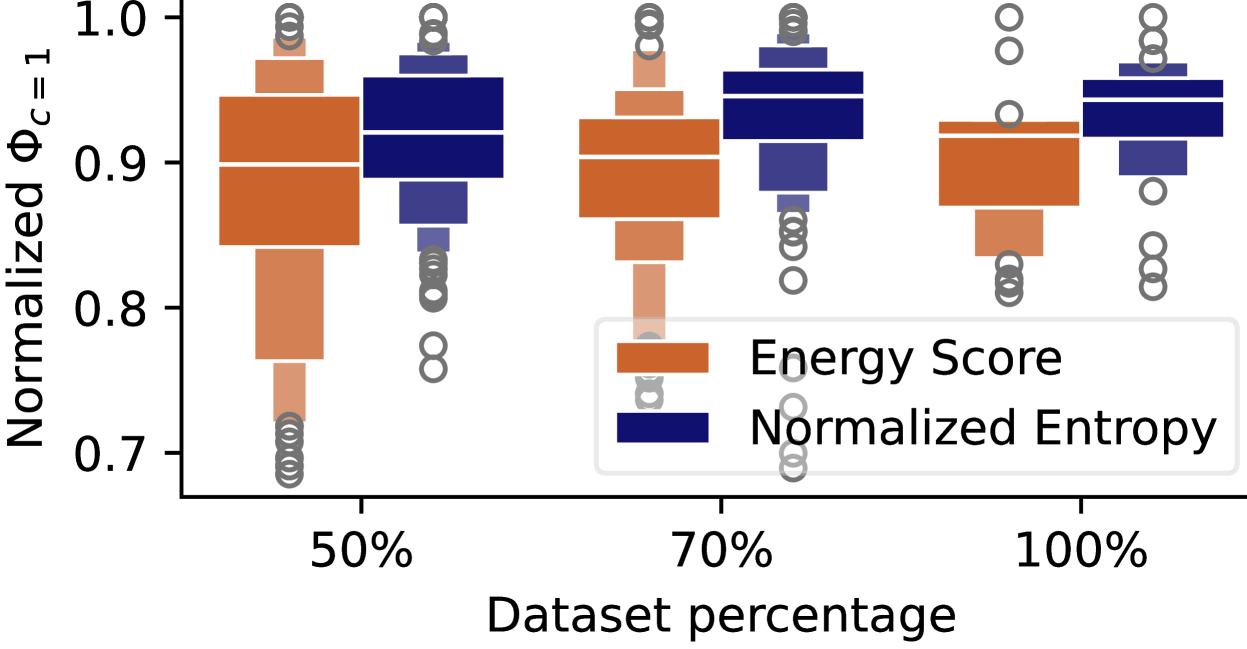
🔼 This figure shows the sensitivity analysis of the threshold τ (tau) used in the Normalized Entropy method for VLM uncertainty estimation. For each of three methods (Normalized Entropy, Energy Score, and LP), 30 different τ values were tested, symmetrically distributed around the optimal threshold (τ*). The x-axis represents the size of the IDKVQA dataset used (as a percentage of the original dataset size), and the y-axis shows the normalized Effective Reliability (ER Φc=1). The analysis reveals the robustness of the different methods to variations in the threshold τ, indicating how the performance changes as the dataset size and τ value are modified.
read the caption
Figure 3: τ𝜏\tauitalic_τ sensitivity results. For each method, 30303030 new τ𝜏\tauitalic_τ values are sampled symmetrically around the optimal threshold τ∗superscript𝜏\tau^{*}italic_τ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT. The x𝑥xitalic_x-axis shows the set size as a percentage of the original IDKVQA dataset size, while the y𝑦yitalic_y-axis displays the normalized ER Φc=1subscriptΦ𝑐1\Phi_{c=1}roman_Φ start_POSTSUBSCRIPT italic_c = 1 end_POSTSUBSCRIPT.

🔼 The figure shows four examples of scenes from the CoIN-Bench dataset. Each scene contains multiple instances of the same object category, making it challenging to identify the target object based solely on its category. The target instance in each scene is highlighted with a red border, whereas distractor objects are marked with a blue border. This visualization underscores the difficulty of the Collaborative Instance Navigation (CoIN) task when minimal user input is provided, emphasizing the need for the proposed AIUTA method.
read the caption
Figure 1: CoIN-Bench can be very challenging when only given the instance category to the agent. We highlight the target instance with red borders, while the distractor instances that exist in the same scene are marked with blue borders.

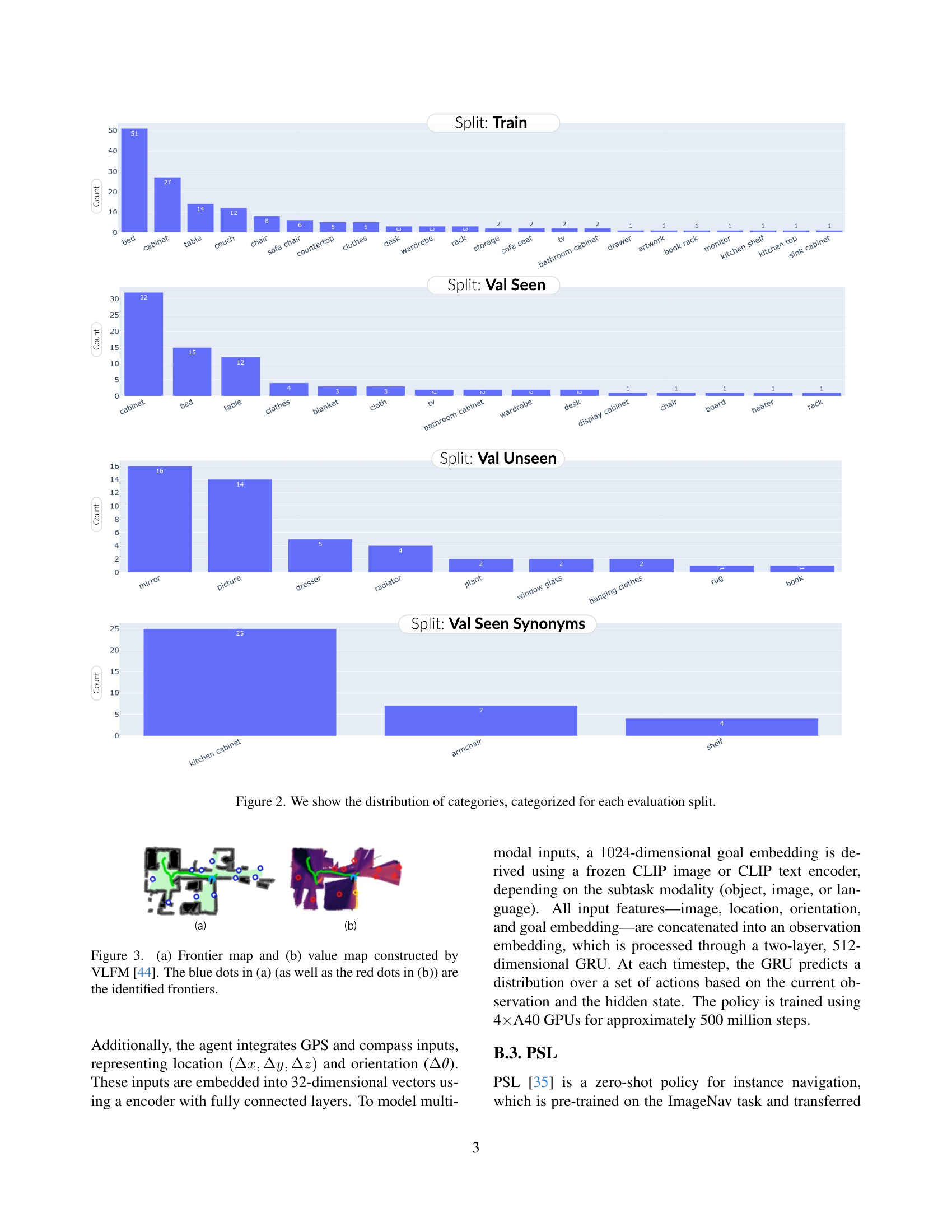
🔼 This figure presents bar charts illustrating the distribution of object categories across four different evaluation splits within the CoIN-Bench dataset: Train, Val Seen, Val Unseen, and Val Seen Synonyms. Each bar chart represents a specific object category and its frequency in the respective split. The charts visually demonstrate how the number and types of object categories vary across these splits, offering insights into the dataset’s composition and the diversity of objects encountered during different stages of evaluation.
read the caption
Figure 2: We show the distribution of categories, categorized for each evaluation split.

🔼 Figure 3 shows the frontier map (a) and value map (b) generated by the VLFM model. The frontier map highlights the boundaries between explored and unexplored areas in the environment, with blue dots representing the frontiers. The value map assigns a value to each location in the explored area, indicating its relevance to locating the target object. Red dots on the value map highlight the high-value frontiers. These maps work together to guide the agent’s navigation towards the target.
read the caption
Figure 3: (a) Frontier map and (b) value map constructed by VLFM [44]. The blue dots in (a) (as well as the red dots in (b)) are the identified frontiers.
More on tables
| User type | Input | CoIN-Bench subset | |||
|---|---|---|---|---|---|
| SR ↑ | SPL ↑ | NQ ↓ | |||
| VLM | c | 68.75 | 32.35 | 1.25 | |
| Real Human | c | 87.50 | 43.96 | 1.38 | |
| VLM | I* | 77.08 | 40.52 | 0.12 | |
| Real Human | I* | 81.25 | 41.84 | 0.06 |
🔼 This table presents a comparison of the performance of the AIUTA model on a subset of the CoIN-Bench dataset, using two different types of user input: category label only and natural language instruction with detailed description. The success rate (SR), success rate weighted by path length (SPL), and average number of questions asked (NQ) are reported for both real human users and VLM-simulated users. This allows evaluating the impact of different levels of user input detail on the navigation performance, comparing human users with the simulated ones.
read the caption
Table 2: Results on a subset of CoIN-Bench between real human vs our simulated VLM, using as input either category c𝑐citalic_c or instruction I∗superscript𝐼I^{*}italic_I start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT containing arbitrary details regarding the target instance.
| Self-Questioner | Skip-Question | SR ↑ | SPL ↑ | NQ ↓ | ||
|---|---|---|---|---|---|---|
| ✗ | ✗ | 9.21 | 5.86 | 3.57 | ||
| ✗ | ✔ | 8.55 | 4.84 | 2.69 | ||
| ✔ | ✗ | 9.87 | 6.5 | 4.6 | ||
| ✔ | ✔ | 14.47 | 7.22 | 1.68 |
🔼 This table presents an ablation study analyzing the impact of different components within the AIUTA framework. It specifically focuses on the ‘Train’ split of the CoIN-Bench dataset. The results show the success rate (SR), success rate weighted by path length (SPL), and the average number of questions asked (NQ) for various configurations of the AIUTA model, demonstrating the contributions of the Self-Questioner and Interaction Trigger modules. The table helps to understand which parts of AIUTA are most important for achieving optimal performance.
read the caption
Table 3: Ablation of components in AIUTA on the Train split.
| VLM Model | Selection Function | |
|---|---|---|
| LLaVA llava-v1.6-mistral-7b-hf | MaxProb | 15.94 |
| LP | 14.01 | |
| Energy Score | 20.45 | |
| Normalized Entropy (ours) | 21.12 |
🔼 This table presents a comparison of different methods for estimating the uncertainty of vision-language models (VLMs) on the IDKVQA dataset. The Effective Reliability rate (Φc=1) is used as the evaluation metric, measuring the trade-off between correct answers and avoiding incorrect answers. The methods compared include: MaxProb (selecting the highest probability answer), LP (a logistic regression model trained on an answerability task), Energy Score (an energy-based out-of-distribution detection method), and the proposed Normalized Entropy method. The results show the performance of each method in terms of Φc=1, indicating their ability to balance accuracy and reliability in VLM uncertainty estimation.
read the caption
Table 4: Results of different selection functions and their corresponding Effective Reliability rate Φc=1subscriptΦ𝑐1\Phi_{c=1}roman_Φ start_POSTSUBSCRIPT italic_c = 1 end_POSTSUBSCRIPT on the IDKVQA dataset.
Full paper#