↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current 3D Vision-Language Models (3D-VLMs) struggle with accurately identifying task-relevant visual information within large, complex 3D scenes. Existing methods often segment all objects, leading to redundant information and computational inefficiencies. This paper addresses these challenges by focusing on the limitations of existing 3D-VLMs in handling large-scale scenes and the lack of a comprehensive benchmark for evaluating their capabilities in such environments.
To overcome these issues, the researchers propose LSceneLLM, a new framework that leverages the power of Large Language Models (LLMs) to identify task-relevant regions within 3D scenes. This is achieved through an adaptive scene modeling approach that uses LLMs to determine visual preferences and a scene magnifier module to capture fine-grained details in the focused areas. The effectiveness of LSceneLLM is demonstrated through a new benchmark, XR-Scene, which comprises large-scale scene understanding tasks. Experiments show that LSceneLLM significantly outperforms existing methods in various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D vision-language models due to its introduction of LSceneLLM, a novel framework that significantly improves large 3D scene understanding. The introduction of a new benchmark, XR-Scene, allows for more comprehensive evaluation of 3D-VLM’s, addressing a gap in current research. The findings offer valuable insights into adaptive visual attention mechanisms, opening up new avenues for developing more robust and efficient 3D scene understanding systems.
Visual Insights#
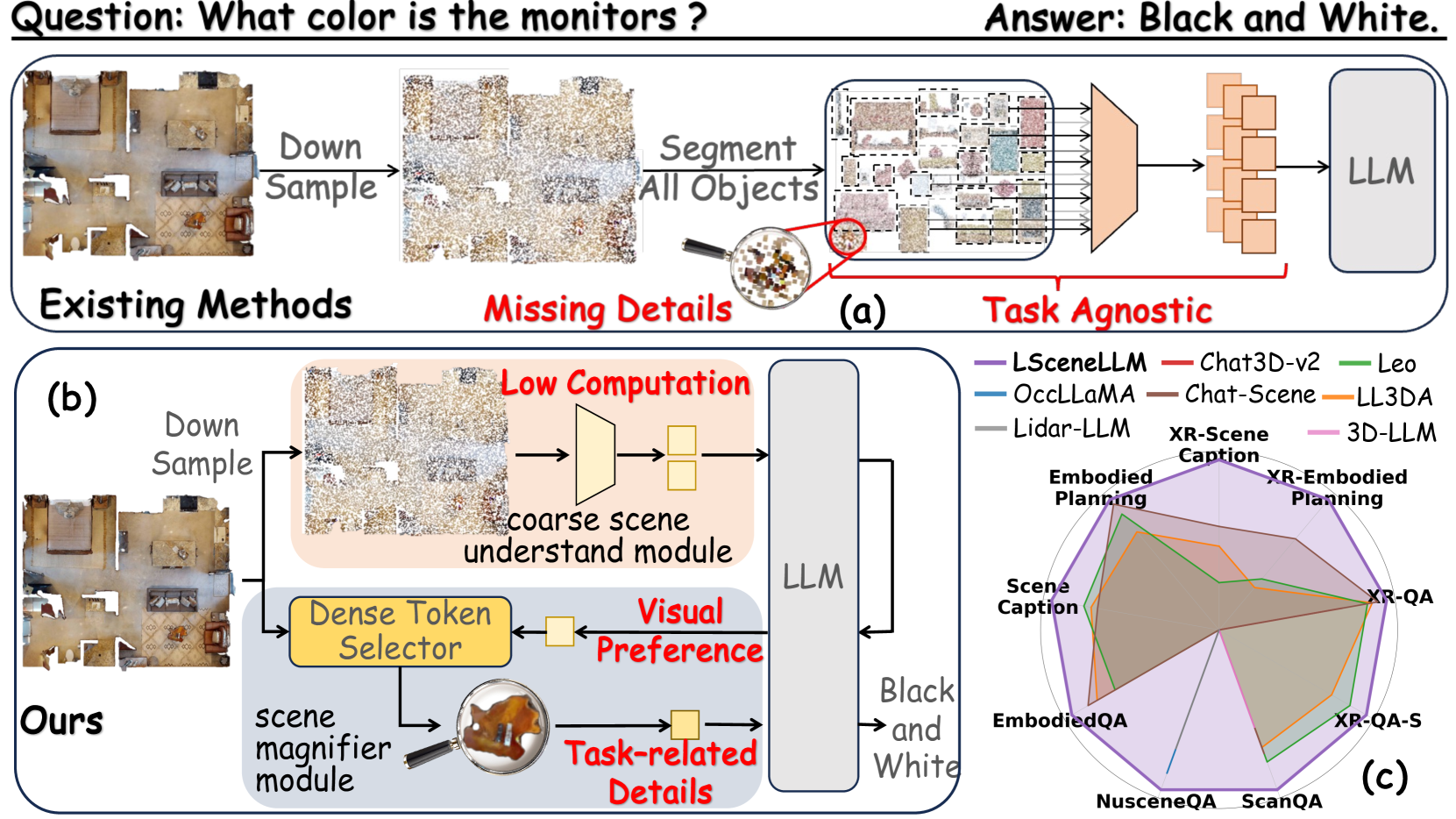
🔼 Figure 1 illustrates the LSceneLLM framework for enhanced large 3D scene understanding. Panel (a) shows the limitations of existing methods in identifying task-relevant visual details within large scenes due to their task-agnostic approach. Panel (b) highlights LSceneLLM’s adaptive approach: utilizing LLMs to prioritize task-relevant areas and a scene magnifier module to capture fine-grained details within those areas. Panel (c) presents a comparison demonstrating LSceneLLM’s superior performance across various benchmarks, showcasing its effectiveness in large 3D scene understanding.
read the caption
Figure 1: We propose LSceneLLM, a novel framework for adaptive large 3D scene understanding. (a) Existing methods struggle to locate task-relevant visual information when facing large scenes. (b) We are committed to precisely identifying fine-grain task-related visual features through adaptive scene modeling. (c) Our method outperforms existing approaches across various benchmarks.
| Methods | XR-QA | XR-SceneCaption | XR-EmbodiedPlanning | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CIDEr | METEOR | ROUGE | CIDEr | METEOR | ROUGE | CIDEr | METEOR | ROUGE | ||
| — | — | — | — | — | — | — | — | — | — | — |
| Zero-Shot | ||||||||||
| Chat-Scene# [16] | 69.55 | 26.63 | 10.06 | 0.01 | 5.94 | 1.52 | 32.64 | 20.71 | 10.26 | |
| Leo∗ [18] | 55.40 | 22.71 | 6.96 | 0.02 | 1.92 | 2.92 | 9.74 | 16.84 | 6.88 | |
| Ll3da [8] | 24.78 | 12.66 | 5.31 | 0.12 | 8.71 | 5.14 | 7.02 | 15.21 | 7.17 | |
| Finetuning | ||||||||||
| Chat-Scene# [16] | 114.10 | 35.93 | 14.32 | 3.58 | 17.49 | 11.59 | 46.18 | 22.34 | 36.71 | |
| Leo∗ [18] | 112.09 | 35.47 | 14.02 | 2.42 | 15.96 | 10.25 | 39.45 | 18.99 | 33.31 | |
| Ll3da [8] | 112.80 | 36.94 | 18.68 | 3.22 | 20.95 | 13.49 | 35.96 | 15.74 | 31.50 | |
| LSceneLLM(Ours) | 117.21 | 38.18 | 19.30 | 4.59 | 23.43 | 16.16 | 63.08 | 22.97 | 36.96 |
🔼 This table presents a comparison of different methods for 3D large scene understanding, specifically focusing on three sub-tasks: XR-QA (cross-room question answering), XR-SceneCaption (cross-room scene captioning), and XR-EmbodiedPlanning (cross-room embodied planning). The results are evaluated using metrics such as CIDER, METEOR, and ROUGE, which assess the quality of generated text. The table shows performance for both zero-shot and fine-tuned models, highlighting the improvements achieved by the proposed LSceneLLM framework. The use of Ll3da and XR-Scene datasets for training is also noted, along with clarification on whether methods required both image and point cloud input (#) or did not identify question-relevant objects (*).
read the caption
Table 1: 3D large scene understanding results. All use Ll3da and XR-Scene data for training. ∗ means do not identify the question-related objects for the model. # means requiring images and point clouds as input.
In-depth insights#
Adaptive 3D Vision#
Adaptive 3D vision systems represent a significant advancement in computer vision, moving beyond static scene interpretations. Adaptive capabilities are crucial for handling the dynamism inherent in 3D environments, such as variations in lighting, object motion, and viewpoint changes. Instead of relying on pre-defined models or parameters, these systems leverage techniques like attention mechanisms and reinforcement learning to dynamically adjust their focus and processing strategies. This adaptability leads to improved robustness and efficiency, especially in complex scenes with extensive visual information. Real-time processing and effective resource management are key challenges in adaptive 3D vision, demanding innovative algorithms and hardware acceleration. Integrating AI, especially deep learning models, is fundamental to achieving truly adaptive behaviors, enabling the system to learn from past experiences and optimize its performance over time. The potential applications are vast, impacting fields like autonomous navigation, robotics, augmented reality, and medical imaging, where the capacity to react intelligently to a constantly changing environment is paramount.
LLM Visual Priors#
LLM visual priors represent a crucial area of research in bridging the gap between language models and visual perception. Integrating visual information into LLMs enhances their ability to understand and reason about complex scenes. The core idea revolves around using pre-trained image or video models to extract visual features. These features, rich in spatial and semantic information, act as priors, guiding the LLM’s processing of textual input. This approach differs significantly from simply concatenating text and image embeddings; instead, visual priors shape the LLM’s attention mechanisms, directing its focus towards task-relevant visual details. Consequently, this leads to improved performance on various vision-language tasks, such as visual question answering, image captioning, and visual reasoning. Challenges remain, however, such as effectively handling varying levels of visual complexity, resolving ambiguities inherent in natural language, and managing computational costs associated with high-resolution visual data. Future research should explore more sophisticated methods for fusing visual priors with LLM’s internal representations, as well as developing more robust and efficient training techniques to enhance the overall performance.
XR-Scene Benchmark#
The XR-Scene benchmark is a significant contribution because it addresses the limitations of existing 3D scene understanding benchmarks by focusing on large-scale, multi-room environments. This is crucial for evaluating the capabilities of 3D Vision-Language Models (3D-VLMs) in more realistic and complex settings. Unlike previous benchmarks predominantly focused on single-room scenes, XR-Scene’s cross-room scenarios present greater challenges in terms of spatial reasoning, object diversity, and the identification of task-relevant information within a much larger visual field. The inclusion of diverse tasks such as XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption further enhances the benchmark’s comprehensiveness, allowing for a more nuanced evaluation of 3D-VLM capabilities. The larger scene size (average 132 m²) is a key differentiator, pushing the boundaries of current models and encouraging the development of more robust and efficient scene understanding techniques. The creation of this benchmark is particularly important for advancing research in embodied AI, where navigation and interaction within large and complex 3D scenes is paramount.
Scene Magnifier#
The concept of a “Scene Magnifier” in the context of 3D vision-language models (3D-VLMs) is quite innovative. It addresses a critical limitation of existing methods which struggle with large scenes due to the overwhelming amount of data. The magnifier doesn’t literally zoom in, but intelligently focuses processing on task-relevant regions. This is achieved by leveraging the attention mechanism of a Large Language Model (LLM) to identify areas of interest. The LLM acts as a guide, highlighting the parts of the scene most relevant to the given instruction. This adaptive focus dramatically reduces computational cost and improves accuracy by avoiding unnecessary processing of irrelevant information. Furthermore, the system cleverly enhances the selected region using a “plug-and-play” scene magnifier module, extracting finer-grained details. This two-stage process — coarse understanding followed by targeted magnification of critical areas — mimics human visual attention and search strategies, resulting in a more efficient and effective large-scene understanding capability. The integration of this module into existing 3D-VLMs is straightforward, showcasing its potential for widespread adoption and enhancement of current methodologies.
Future of 3D-VLMs#
The future of 3D Vision-Language Models (3D-VLMs) is bright, driven by the convergence of advancements in both 3D vision and large language models (LLMs). Improved scene understanding will likely involve more sophisticated methods for handling the complexities of large-scale and diverse 3D scenes. This could include better techniques for focusing on task-relevant visual information and reducing computational costs associated with processing large point clouds. Efficient feature extraction and representation, perhaps through the use of advanced neural architectures, will be crucial for scaling to larger, richer datasets. The integration of LLMs and other multi-modal models will also continue to play an important role, enabling more robust reasoning and contextual awareness. Furthermore, enhanced benchmarks are needed to rigorously evaluate the capabilities of 3D-VLMs in various tasks, especially in the areas of cross-room and outdoor scene understanding. Future research could also explore the development of 3D-VLMs that are more robust to noise, occlusion, and variations in viewpoint, thus leading to better generalization in real-world applications. Finally, ethical implications of increasingly sophisticated 3D-VLMs must be carefully considered. The development of 3D-VLMs must be guided by a commitment to fairness, transparency and safety. Ultimately, 3D-VLMs have a tremendous potential to power numerous applications in robotics, augmented reality, and other fields.
More visual insights#
More on figures

🔼 LSceneLLM processes 3D scenes in two stages. First, a coarse understanding is built using sparse vision tokens from a downsampled point cloud. Then, a dense token selector identifies task-relevant areas based on the LLM’s attention map, extracting detailed dense vision tokens from those specific regions. These dense tokens are integrated with the sparse tokens using an adaptive self-attention module, significantly improving the model’s ability to focus on critical details within large scenes. This two-stage approach enables the effective handling of various visual language tasks in complex 3D environments.
read the caption
Figure 2: An Overview of LSceneLLM. LSceneLLM first perceives the scene through sparse vision tokens at the coarse level and then enhances regions of interest using dense vision tokens. Our method can effectively handle various visual language tasks in large scenes.

🔼 This figure illustrates the LSceneLLM framework’s core components: the Adaptive Self-attention Module and the Dense Vision Token Selector. The process begins by analyzing the Large Language Model’s (LLM) attention map to identify regions of interest within the scene. This attention map highlights areas that the LLM deems relevant to the given task. Next, the Dense Vision Token Selector uses this information to extract high-resolution point cloud features specifically from these key regions. These detailed features are then processed through sampling and grouping operations to create ‘dense vision tokens.’ Finally, the Adaptive Self-attention Module integrates these newly created dense vision tokens with the existing sparse visual information (from the rest of the scene), effectively enriching the LLM’s understanding of the scene with crucial context-specific details.
read the caption
Figure 3: Illustration of Adaptive Self-attention Module and Dense Vision Token Selector. We first obtain the focused regions by analyzing the attention map of LLM. Then we extract dense point cloud features from the region of interest and parse dense vision tokens through sampling and grouping operations.

🔼 XR-Scene is a new benchmark dataset designed to evaluate large-scale 3D scene understanding capabilities. It features three challenging tasks: XR-QA (cross-room question answering), XR-EmbodiedPlanning (cross-room embodied planning), and XR-SceneCaption (cross-room scene captioning). Each task requires the model to understand the spatial relationships between objects and rooms across multiple rooms, going beyond the single-room scope of existing benchmarks. The figure displays example scenes and questions from the XR-Scene dataset to illustrate the complexity and scale involved in the tasks.
read the caption
Figure 4: Examples of dataset XR-Scene. XR-Scene contains three cross-room scene benchmarks that comprehensively evaluate different understanding abilities.

🔼 This figure visualizes the attention maps generated by the LLM (Large Language Model) in LSceneLLM, a novel framework for large 3D scene understanding. The heatmaps show the model’s focus during different question-answering tasks. Red indicates high activation values (strong attention), while blue indicates low activation values (weak attention). The comparison across different models (LSceneLLM, Ll3da, and Leo) demonstrates how LSceneLLM effectively focuses on task-relevant objects, particularly small objects, which other methods often miss.
read the caption
Figure 5: Visualization of attention map of LLM. Red represents high activation values, while blue represents low activation values.

🔼 This figure illustrates the process of generating captions and embodied planning tasks within the XR-Scene benchmark dataset. It details how top-down views of scenes, along with per-room descriptions and object lists, are provided as input to GPT-4. GPT-4 then generates scene captions summarizing the overall scene and individual rooms, as well as a high-level task with decomposed steps for embodied planning. The process highlights how the multi-room nature of the scenes, combined with detailed room descriptions, allows for the creation of complex and comprehensive tasks that assess a model’s holistic understanding of the environment.
read the caption
Figure 6: Generation pipeline of XR-SceneCaption and XR-EmbodiedPlanning.

🔼 Figure 7 visualizes attention maps generated by LSceneLLM for various questions about a scene. Redder colors indicate higher attention weights, showing where the model focuses its attention while answering. The figure showcases the model’s ability to selectively attend to relevant objects and regions within the scene, successfully identifying details even in complex scenarios. It highlights LSceneLLM’s improved ability to locate and focus on task-relevant details when compared to other methods.
read the caption
Figure 7: More Attention Visualization of LSceneLLM.
More on tables
| Method | LLM | Training Data | ROUGE | METEOR | CIDEr |
|---|---|---|---|---|---|
| 3D-VLP [21] | - | - | 34.51 | 13.53 | 66.97 |
| ScanQA [2] | - | - | 33.33 | 13.14 | 64.86 |
| Chat3D [41] | Vicuna-7b | - | 28.5 | 11.9 | 53.2 |
| Chat3D-v2 [17] | Vicuna-7b | 204k | 40.1 | 16.1 | 77.1 |
| 3D-LLM [15] | BLIP2-flanT5 | 675k | 35.7 | 14.5 | 69.4 |
| SceneLLM [12] | Llama2-7b | 690k | 35.9 | 15.8 | 80.00 |
| Chat-Scene [16] | Vicuna-7b | 145k | 37.79 | 15.94 | 77.75 |
| Leo* [18] | Vicuna-7b | 1034k+145k | 40.24 | 16.68 | 80.20 |
| Ll3da [8] | Opt-1.3b | 145k | 37.02 | 15.37 | 75.67 |
| Ll3da [8] | Llama2-7b | 145k | 38.31 | 15.91 | 79.08 |
| LSceneLLM(Ours) | Llama2-7b | 145k | 40.82 | 17.95 | 88.24 |
🔼 This table presents the performance of various 3D Vision-Language Models (3D-VLMs) on the ScanQA [2] validation dataset, a benchmark for evaluating 3D question answering. The models are evaluated based on their ability to answer questions about a 3D scene using the ROUGE, METEOR, and CIDEr metrics. The asterisk (*) indicates methods that do not specifically identify objects relevant to the question before generating an answer. This highlights the difference in performance between methods that focus on task-relevant details versus those processing the entire scene.
read the caption
Table 2: 3D question answering results on the ScanQA [2] validation dataset. ∗ means do not identify the question-related objects for the model.
| Method | Exist (H0) | Exist (H1) | Exist (All) | Count (H0) | Count (H1) | Count (All) | Object (H0) | Object (H1) | Object (All) | Status (H0) | Status (H1) | Status (All) | Comparison (H0) | Comparison (H1) | Comparison (All) | Acc |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NuscenesQA* [29] | 87.7 | 81.1 | 84.1 | 21.9 | 20.7 | 21.3 | 70.2 | 45.6 | 49.2 | 62.8 | 52.4 | 55.9 | 81.6 | 68.0 | 69.2 | 58.1 |
| LLaVA-Adaptaer-v2 [13] | 34.2 | 6.3 | 19.3 | 5.0 | 0.1 | 2.7 | 23.7 | 4.6 | 7.6 | 9.8 | 11.3 | 10.8 | 2.6 | 1.5 | 1.6 | 9.6 |
| LLaVA [25] | 38.9 | 51.9 | 45.8 | 7.7 | 7.6 | 7.7 | 10.5 | 7.4 | 7.8 | 7.0 | 9.9 | 9.0 | 64.5 | 50.8 | 52.1 | 26.2 |
| LidarLLM [45] | 79.1 | 70.6 | 74.5 | 15.3 | 14.7 | 15.0 | 59.6 | 34.1 | 37.8 | 53.4 | 42.0 | 45.9 | 67.0 | 57.0 | 57.8 | 48.6 |
| OccLLaMA [42] | 80.6 | 79.3 | 79.9 | 18.6 | 19.1 | 18.9 | 64.9 | 39.0 | 42.8 | 48.0 | 49.6 | 49.1 | 80.6 | 63.7 | 65.2 | 53.4 |
| LSceneLLM(Ours) | 86.4 | 81.3 | 83.6 | 19.4 | 19.8 | 19.6 | 64.4 | 41.3 | 44.8 | 58.8 | 51.2 | 53.8 | 81.0 | 67.5 | 68.7 | 56.4 |
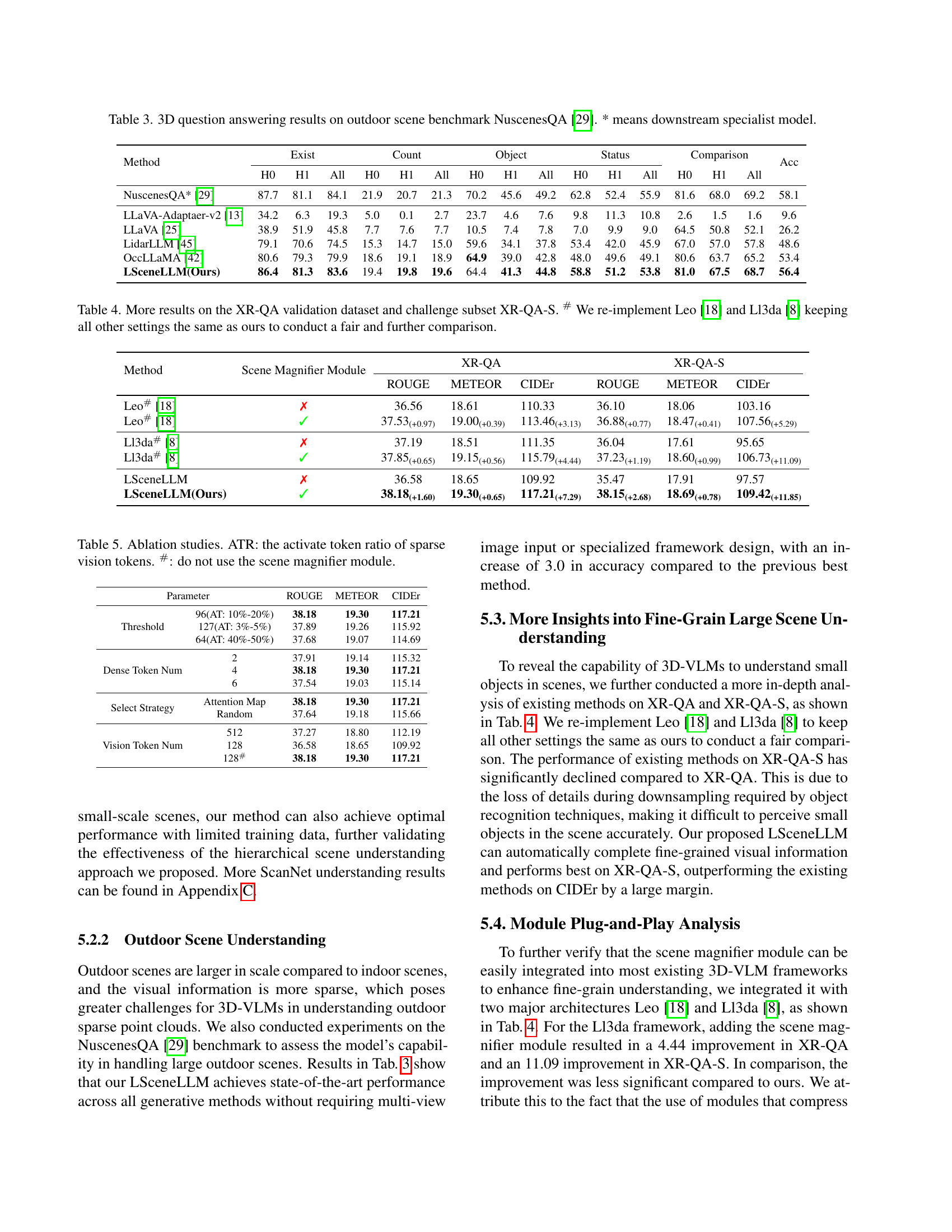
🔼 This table presents the performance of various models on the NuscenesQA benchmark, a dataset for evaluating 3D question answering in outdoor scenes. The results are categorized by different metrics, including those related to existence, count, status, object comparison, and overall accuracy. The asterisk (*) indicates models that utilize downstream specialist approaches. This allows for a comparison of general-purpose 3D question answering models against specialized models designed for specific tasks within the outdoor setting.
read the caption
Table 3: 3D question answering results on outdoor scene benchmark NuscenesQA [29]. * means downstream specialist model.
| Method | Scene Magnifier Module | XR-QA ROUGE | XR-QA METEOR | XR-QA CIDEr | XR-QA-S ROUGE | XR-QA-S METEOR | XR-QA-S CIDEr |
|---|---|---|---|---|---|---|---|
| Leo# [18] | ✗ | 36.56 | 18.61 | 110.33 | 36.10 | 18.06 | 103.16 |
| Leo# [18] | ✓ | 37.53(+0.97) | 19.00(+0.39) | 113.46(+3.13) | 36.88(+0.77) | 18.47(+0.41) | 107.56(+5.29) |
| Ll3da# [8] | ✗ | 37.19 | 18.51 | 111.35 | 36.04 | 17.61 | 95.65 |
| Ll3da# [8] | ✓ | 37.85(+0.65) | 19.15(+0.56) | 115.79(+4.44) | 37.23(+1.19) | 18.60(+0.99) | 106.73(+11.09) |
| LSceneLLM | ✗ | 36.58 | 18.65 | 109.92 | 35.47 | 17.91 | 97.57 |
| LSceneLLM(Ours) | ✓ | 38.18(+1.60) | 19.30(+0.65) | 117.21(+7.29) | 38.15(+2.68) | 18.69(+0.78) | 109.42(+11.85) |
🔼 This table presents a comparison of results for XR-QA and its challenging subset XR-QA-S across different models. The models compared include LSceneLLM (the authors’ proposed method), Leo [18], and Ll3da [8]. To ensure a fair comparison, Leo and Ll3da were re-implemented using the same settings as LSceneLLM. The evaluation metrics used are ROUGE, METEOR, and CIDEr, providing a comprehensive assessment of the models’ performance on both standard and challenging question-answering tasks in large 3D scenes.
read the caption
Table 4: More results on the XR-QA validation dataset and challenge subset XR-QA-S. # We re-implement Leo [18] and Ll3da [8] keeping all other settings the same as ours to conduct a fair and further comparison.
| Parameter | ROUGE | METEOR | CIDEr |
|---|---|---|---|
| Threshold 96(AT: 10%-20%) | 38.18 | 19.30 | 117.21 |
| Threshold 127(AT: 3%-5%) | 37.89 | 19.26 | 115.92 |
| Threshold 64(AT: 40%-50%) | 37.68 | 19.07 | 114.69 |
| Dense Token Num 2 | 37.91 | 19.14 | 115.32 |
| Dense Token Num 4 | 38.18 | 19.30 | 117.21 |
| Dense Token Num 6 | 37.54 | 19.03 | 115.14 |
| Select Strategy Attention Map | 38.18 | 19.30 | 117.21 |
| Select Strategy Random | 37.64 | 19.18 | 115.66 |
| Vision Token Num 512 | 37.27 | 18.80 | 112.19 |
| Vision Token Num 128 | 36.58 | 18.65 | 109.92 |
| Vision Token Num 128# | 38.18 | 19.30 | 117.21 |
🔼 This table presents the results of ablation studies conducted on the LSceneLLM model. It examines the impact of different components and hyperparameters on the model’s performance. Specifically, it investigates the effect of varying the activation token ratio (ATR) of sparse vision tokens, and the impact of removing the scene magnifier module. The results are presented in terms of ROUGE, METEOR, and CIDEr scores, which are standard metrics for evaluating text generation quality. Analyzing this table helps understand the contribution of individual components of the LSceneLLM framework and how they impact overall scene understanding ability.
read the caption
Table 5: Ablation studies. ATR: the activate token ratio of sparse vision tokens. #: do not use the scene magnifier module.
| Threshold | Activate Token Ratio | ROUGE | METEOR | CIDEr |
|---|---|---|---|---|
| 64 | 40% - 50% | 37.68 | 19.07 | 114.69 |
| 96 | 10% - 20% | 38.18 | 19.30 | 117.21 |
| 127 | 3% - 5% | 37.89 | 19.26 | 115.92 |
🔼 This table presents the results of ablation studies conducted to determine the optimal threshold for selecting relevant visual tokens. The experiment varied the selection threshold, impacting the proportion of visual tokens considered by the model. The table shows the effects of these different thresholds on the model’s performance, as measured by ROUGE, METEOR, and CIDEr scores.
read the caption
Table 6: Ablation studies of selection threshold
| Vision Token Num | Scene Magnifier Module | ROUGE | METEOR | CIDEr |
|---|---|---|---|---|
| 512 | ✗ | 37.27 | 18.80 | 112.89 |
| 128 | ✗ | 36.58 | 18.65 | 109.92 |
| 128 | ✓ | 38.18 | 19.30 | 117.21 |
🔼 This table presents the results of ablation studies conducted to determine the optimal number of vision tokens used in the LSceneLLM model. It shows how different numbers of vision tokens (512, 128, 128) impact the model’s performance, specifically the ROUGE, METEOR, and CIDEr scores on the XR-QA task. The table compares the performance when the scene magnifier module is included versus when it is not included (X). This analysis helps determine the optimal balance between computational cost and model performance.
read the caption
Table 7: Ablation studies of the number of vision tokens
| Dense Token Num | ROUGE | METEOR | CIDEr |
|---|---|---|---|
| 2 | 37.91 | 19.14 | 115.32 |
| 4 | 38.18 | 19.30 | 117.21 |
| 6 | 37.54 | 19.03 | 115.14 |
🔼 This table presents the ablation study results focusing on the impact of varying the number of dense vision tokens used in the LSceneLLM model. It shows how the model’s performance on the XR-QA benchmark (a cross-room scene question answering task) changes as the count of dense vision tokens is altered. The results illustrate the effect of different numbers of dense tokens on the model’s ability to accurately identify and utilize relevant visual details within large scenes for effective question answering.
read the caption
Table 8: Ablation studies of dense token
| Select Strategy | ROUGE | METEOR | CIDEr |
|---|---|---|---|
| Attention Map | 38.18 | 19.30 | 117.21 |
| Random | 37.64 | 19.18 | 115.66 |
🔼 This table presents the results of ablation studies conducted to evaluate the effectiveness of different strategies for selecting dense vision tokens. The study compares the performance of using an attention map-based selection method against a random selection method, both in terms of ROUGE, METEOR, and CIDEr scores. The goal is to determine whether using the attention map of the large language model to guide the selection of dense visual tokens improves the overall performance of the scene understanding model.
read the caption
Table 9: Ablation studies of selection strategies
| Method | Scene Caption ROUGE | Scene Caption CIDEr | Scene Caption METEOR | Embodied Planning ROUGE | Embodied Planning CIDEr | Embodied Planning METEOR | Embodied QA ROUGE | Embodied QA CIDEr | Embodied QA METEOR |
|---|---|---|---|---|---|---|---|---|---|
| Leo* [18] | 1.80 | 20.84 | 13.29 | 46.40 | 204.78 | 19.86 | 30.89 | 86.14 | 18.81 |
| Chat-Scene [16] | 3.67 | 21.05 | 12.60 | 40.03 | 210.86 | 20.71 | 34.23 | 99.01 | 18.48 |
| Ll3da [8] | 1.44 | 24.62 | 12.93 | 45.34 | 186.13 | 19.60 | 33.75 | 95.53 | 19.81 |
| LSceneLLM(Ours) | 3.07 | 21.88 | 14.79 | 47.05 | 214.63 | 21.05 | 36.00 | 104.98 | 21.26 |
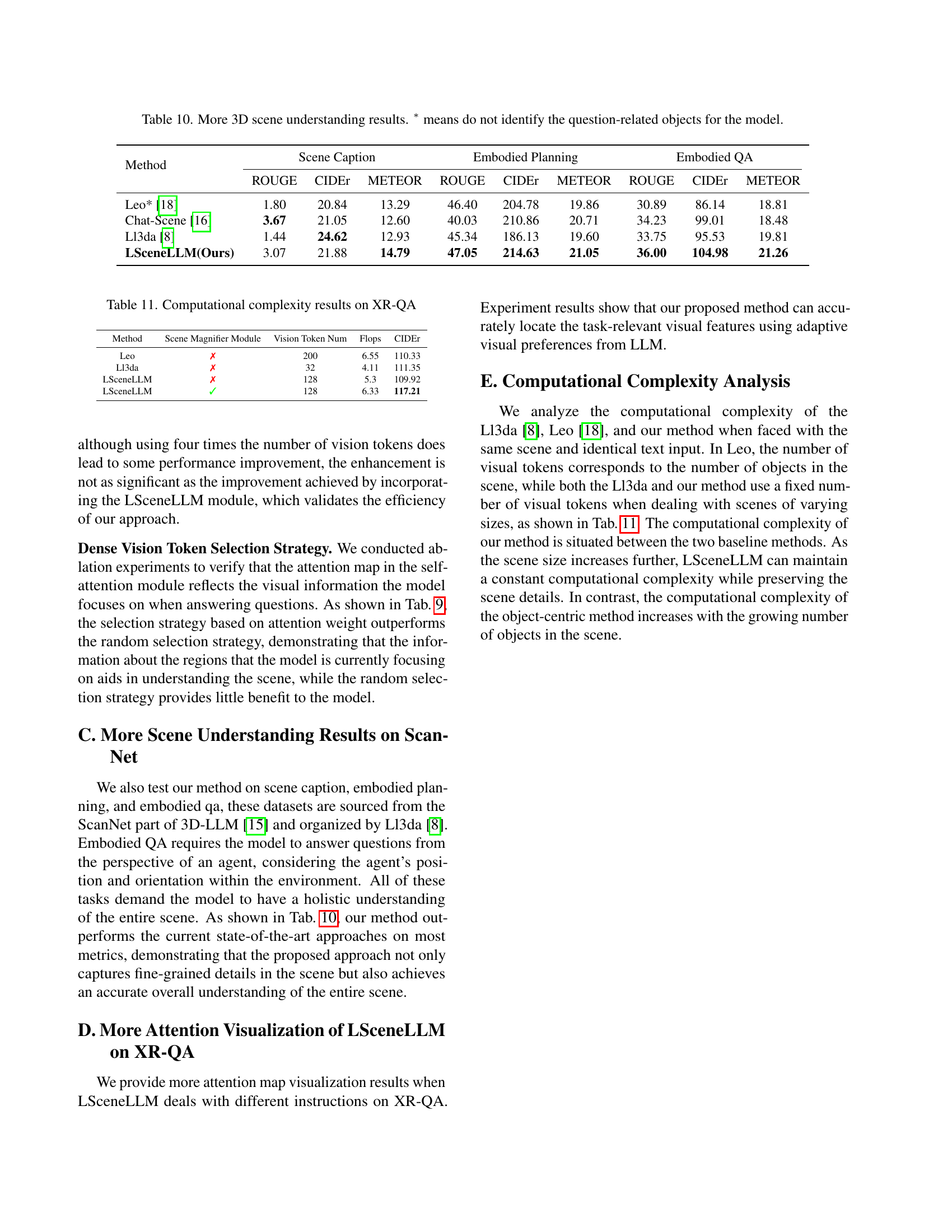
🔼 This table presents additional results for three 3D scene understanding tasks: scene captioning, embodied planning, and embodied question answering. The results compare the performance of the proposed LSceneLLM model against existing state-of-the-art methods (Leo and Chat-Scene) and another baseline (Ll3da). The metrics used for evaluation are ROUGE, CIDEr, and METEOR, reflecting different aspects of text generation quality. The asterisk (*) indicates methods that don’t specifically identify question-related objects when processing the scene.
read the caption
Table 10: More 3D scene understanding results. ∗ means do not identify the question-related objects for the model.
| Method | Scene Magnifier Module | Vision Token Num | Flops | CIDEr |
|---|---|---|---|---|
| Leo | ✗ | 200 | 6.55 | 110.33 |
| Ll3da | ✗ | 32 | 4.11 | 111.35 |
| LSceneLLM | ✗ | 128 | 5.3 | 109.92 |
| LSceneLLM | ✓ | 128 | 6.33 | 117.21 |
🔼 This table presents the computational complexities (measured in FLOPs) and CIDEr scores of three different 3D vision-language models on the XR-QA benchmark. It compares the performance of Leo, Ll3da, and the authors’ proposed LSceneLLM model, varying the number of vision tokens used. The results demonstrate the relative efficiency of each model in handling large-scale scene understanding tasks.
read the caption
Table 11: Computational complexity results on XR-QA
Full paper#