TL;DR#
Current video generation models struggle to create long videos (15+ seconds) that maintain coherence and rich content throughout the duration. Existing methods either extend short clips, leading to abrupt transitions and content repetition or directly generate longer videos resulting in error propagation and a lack of diversity. This paper introduces Presto, which directly tackles this challenge.
Presto uses a Segmented Cross-Attention (SCA) strategy, dividing hidden states into segments to focus attention on relevant parts of the caption. The model leverages the new LongTake-HD dataset, consisting of 261,000 content-rich videos annotated with detailed sub-captions for better training. Presto significantly outperforms existing methods, demonstrating improved content richness, long-range coherence and capturing intricate textual details in generated videos.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the challenge of generating long, coherent videos with rich content, a significant limitation of current video generation models. Its introduction of a novel segmented cross-attention mechanism and a new high-quality dataset, LongTake-HD, provides a strong foundation for future research in long-form video generation, opening up possibilities for creative applications and advancing AI research. The improved results achieved in benchmarks highlight its significance.
Visual Insights#
| Dimensions | Specific Dimensions | Specific Dimensions | Specific Dimensions | Specific Dimensions | Specific Dimensions | Specific Dimensions | Holistic Dimensions | Holistic Dimensions | Holistic Dimensions | |
|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Dynamic | Temporal | Human | Object | Color | Overall | Semantic | Quality | Overall | |
| Degree | Style | Action | Class | Consist. | Score | Score | Score | |||
| Gen-3 | 60.1 | 24.7 | 96.4 | 87.8 | 80.9 | 26.7 | 75.2 | 84.1 | 82.3 | |
| Allegro | 55.0 | 24.4 | 91.4 | 87.5 | 82.8 | 26.4 | 73.0 | 83.1 | 81.1 | |
| TALC | 98.6 | 18.0 | 89.0 | 45.3 | 57.3 | 19.5 | 44.4 | 62.5 | 58.9 | |
| Presto | 100.0 | 25.8 | 93.0 | 93.7 | 98.1 | 27.8 | 78.5 | 80.6 | 80.2 |
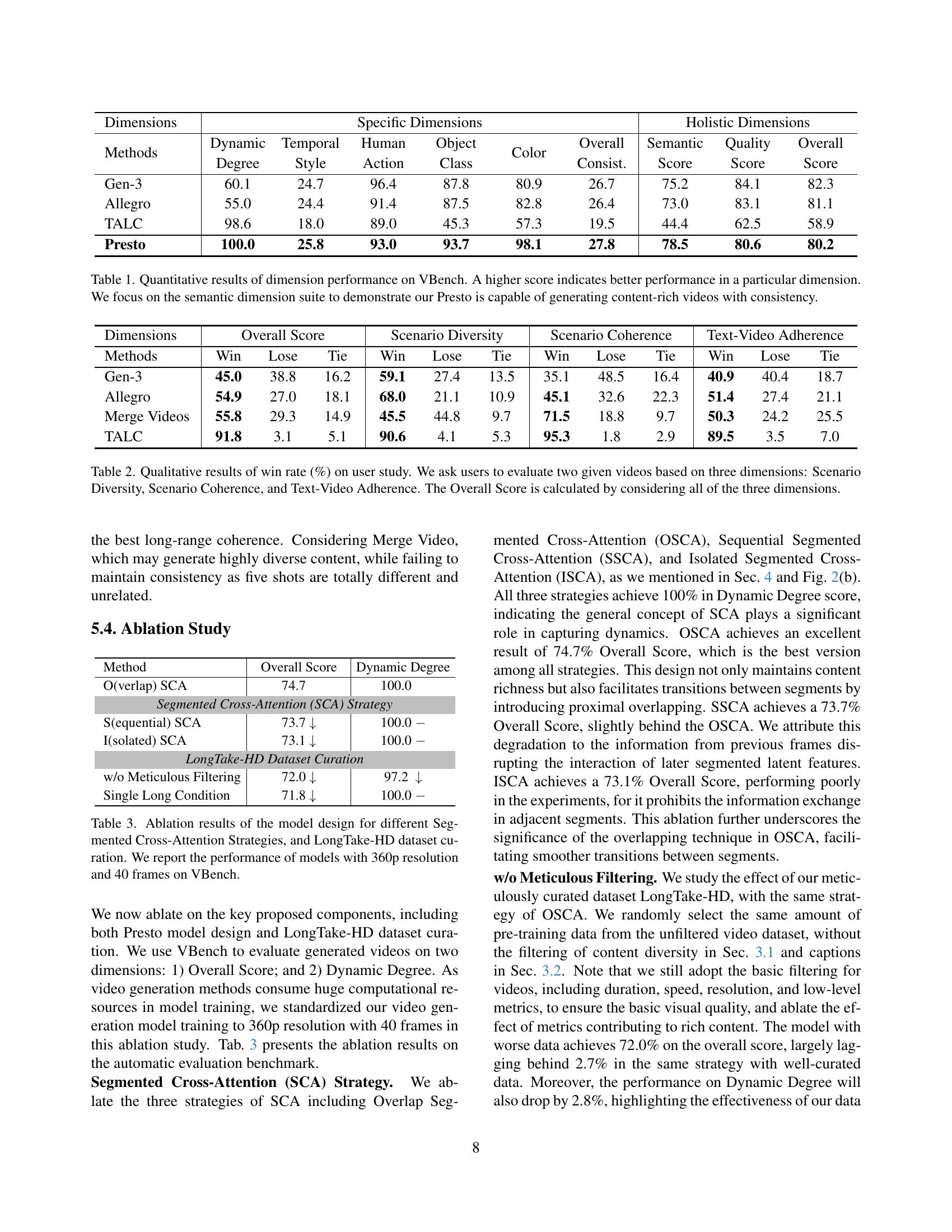
🔼 This table presents a quantitative evaluation of the Presto video generation model using the VBench benchmark. VBench assesses various aspects of video generation quality across multiple dimensions. The table shows Presto’s performance scores compared to other models (Gen-3, Allegro, and TALC) in different categories, including dynamic degree, temporal style, human action, object class, color consistency, and overall semantic and quality scores. Higher scores indicate better performance within each dimension. The focus on the semantic score highlights Presto’s ability to generate videos with rich and consistent content as indicated by the high score achieved by Presto.
read the caption
Table 1: Quantitative results of dimension performance on VBench. A higher score indicates better performance in a particular dimension. We focus on the semantic dimension suite to demonstrate our Presto is capable of generating content-rich videos with consistency.
In-depth insights#
Long Video Diffusion#
The concept of “Long Video Diffusion” introduces significant challenges to traditional video generation models. Generating videos longer than a few seconds requires overcoming limitations in maintaining long-range coherence and preserving content richness. Methods for extending short video clips often result in repetitive or disjointed content, failing to capture the nuances of a longer narrative. Addressing the temporal aspect is crucial; techniques like segmented cross-attention show promise in improving long-range dependencies by allowing each segment of the video to selectively attend to relevant parts of the textual description. Creating high-quality datasets with richly annotated content and longer-duration videos is also essential for training robust models. The development of such datasets, coupled with innovative diffusion models adapted for handling long sequences, is key to advancing the field of long-form video synthesis.
Segmented Attention#
Segmented attention, in the context of long video generation, offers a compelling approach to address the challenges of maintaining both rich content and long-range coherence. By dividing the video’s hidden states into temporal segments and associating each segment with a corresponding text caption (often a sub-caption from a progressive captioning strategy), the model can effectively capture more nuanced information. This strategy avoids information loss associated with processing very long, single text embeddings. The effectiveness of different segmented attention mechanisms, such as isolated, sequential, and overlapped approaches, requires careful consideration. Overlapping segmented attention, in particular, proves beneficial by allowing information exchange between adjacent segments, leading to improved temporal continuity and a more seamless narrative flow. This method allows for better integration of progressive sub-captions, enhancing the overall coherence and richness of the generated video. The absence of additional parameters in this approach is also significant, highlighting its ease of implementation and integration into existing diffusion transformer architectures. Presto’s success demonstrates the power of this approach for long video generation.
LongTake-HD Dataset#
The LongTake-HD dataset is a crucial contribution of this research, addressing the scarcity of high-quality, long-form video data for training video generation models. Its content-rich videos, averaging 15 seconds, are carefully curated from a massive dataset, ensuring long-range coherence and scenario diversity. The inclusion of multiple progressive sub-captions for each video further enhances the model’s ability to understand and generate long, coherent narratives. This meticulous data curation process, involving various filtering steps based on aesthetic quality, motion dynamics, and semantic consistency, significantly elevates the quality of the dataset. LongTake-HD’s focus on rich content, coherence, and progressive sub-captions makes it uniquely suitable for training models designed to generate high-quality, long videos. This carefully curated dataset directly addresses the limitations of existing datasets, enabling substantial progress in the field of long-form video generation.
Presto Model Ablation#
A Presto model ablation study systematically investigates the contribution of individual components to the overall model performance. By selectively removing or modifying parts of the model, such as different cross-attention strategies (ISCA, SSCA, OSCA), the impact of each component on key metrics like VBench semantic scores and dynamic degree can be precisely measured. The ablation study highlights the importance of the overlap segmented cross-attention (OSCA) strategy as it significantly outperforms other variants, showcasing its effectiveness in balancing content richness and long-range coherence. Similarly, ablating the meticulous data curation process reveals its crucial role in achieving high-quality results, underscoring the importance of high-quality training data for video generation models. Overall, the ablation study provides a granular understanding of Presto’s architecture, offering valuable insights for future model improvements and highlighting crucial design choices impacting long video generation capabilities.
Future Work#
Future research directions stemming from this work on long video generation could explore several promising avenues. Improving the model’s ability to handle complex scenes and intricate actions is crucial, as current limitations suggest difficulties in managing dynamic, multi-object scenarios. Further investigation into the balance between long-range coherence and content diversity is needed, as this is a key challenge in generating compelling long videos. This could involve refining the segmented cross-attention mechanism or exploring alternative architectural designs. Exploring different text encoding strategies beyond the current approach is another avenue worth investigating. It would be interesting to examine methods that better capture the nuances and temporal dependencies of long descriptive texts. Finally, extending the dataset with even more diverse content is essential. A larger dataset could significantly enhance the model’s ability to generate a wider range of high-quality, coherent long videos. The exploration of diverse data sources beyond publicly available resources might unlock enhanced capabilities.
More visual insights#
More on tables
| Dimensions | Overall Score | Scenario Diversity | Scenario Coherence | Text-Video Adherence | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Win | Lose | Tie | Win | Lose | Tie | Win | Lose | Tie | Win | Lose | Tie |
| Gen-3 | 45.0 | 38.8 | 16.2 | 59.1 | 27.4 | 13.5 | 35.1 | 48.5 | 16.4 | 40.9 | 40.4 | 18.7 |
| Allegro | 54.9 | 27.0 | 18.1 | 68.0 | 21.1 | 10.9 | 45.1 | 32.6 | 22.3 | 51.4 | 27.4 | 21.1 |
| Merge Videos | 55.8 | 29.3 | 14.9 | 45.5 | 44.8 | 9.7 | 71.5 | 18.8 | 9.7 | 50.3 | 24.2 | 25.5 |
| TALC | 91.8 | 3.1 | 5.1 | 90.6 | 4.1 | 5.3 | 95.3 | 1.8 | 2.9 | 89.5 | 3.5 | 7.0 |
🔼 This table presents the results of a user study comparing different video generation models. Users were asked to compare pairs of videos generated by different methods and rate them across three dimensions: Scenario Diversity (how varied the scenes were), Scenario Coherence (how well the scenes flowed together), and Text-Video Adherence (how well the video matched the text prompt). The ‘Win Rate’ represents the percentage of times a particular model’s video was preferred over another model’s video for each dimension. The ‘Overall Score’ is a combined score taking into account all three dimensions.
read the caption
Table 2: Qualitative results of win rate (%) on user study. We ask users to evaluate two given videos based on three dimensions: Scenario Diversity, Scenario Coherence, and Text-Video Adherence. The Overall Score is calculated by considering all of the three dimensions.
| Method | Overall Score | Dynamic Degree |
|---|---|---|
| O(verlap) SCA | 74.7 | 100.0 |
| Segmented Cross-Attention (SCA) Strategy | ||
| S(equential) SCA | 73.7 ↓ | 100.0 - |
| I(solated) SCA | 73.1 ↓ | 100.0 - |
| LongTake-HD Dataset Curation | ||
| w/o Meticulous Filtering | 72.0 ↓ | 97.2 ↓ |
| Single Long Condition | 71.8 ↓ | 100.0 - |
🔼 This table presents the ablation study results for the Presto model. It shows the impact of different design choices on the model’s performance, as measured by the VBench benchmark. Specifically, it evaluates three variations of the Segmented Cross-Attention (SCA) strategy (Isolated, Sequential, and Overlap), and the effect of using the meticulously curated LongTake-HD dataset versus a less refined version. All experiments used a 360p resolution and 40 frames for consistency.
read the caption
Table 3: Ablation results of the model design for different Segmented Cross-Attention Strategies, and LongTake-HD dataset curation. We report the performance of models with 360p resolution and 40 frames on VBench.
| Filtering | Pre-training | Fine-tuning |
|---|---|---|
| Content-Diverse Video Clips | ||
| Width | ≥ 1280 | ≥ 1280 |
| Height | ≥ 720 | ≥ 720 |
| FPS | [24,60] | [24,60] |
| Duration | ≥ 15 | ≥ 15 |
| Grayscale | [20,180] | [20,180] |
| LAION Aesthetics | ≥ 4.8 | ≥ 5.0 |
| Tolerance Artifacts | ≤ 5% | ≤ 5% |
| Unimatch Flow | ≥ 40 | ≥ 50 |
| Coherent Video Captions | ||
| PSNR | [4,20] | [4,20] |
| SSIM | [0,0.7] | [0,0.7] |
| LPIPS | ≥ 0.4 | [0.5,0.8] |
| Text Similarity | ≤ 0.75 | [0,0.75] |
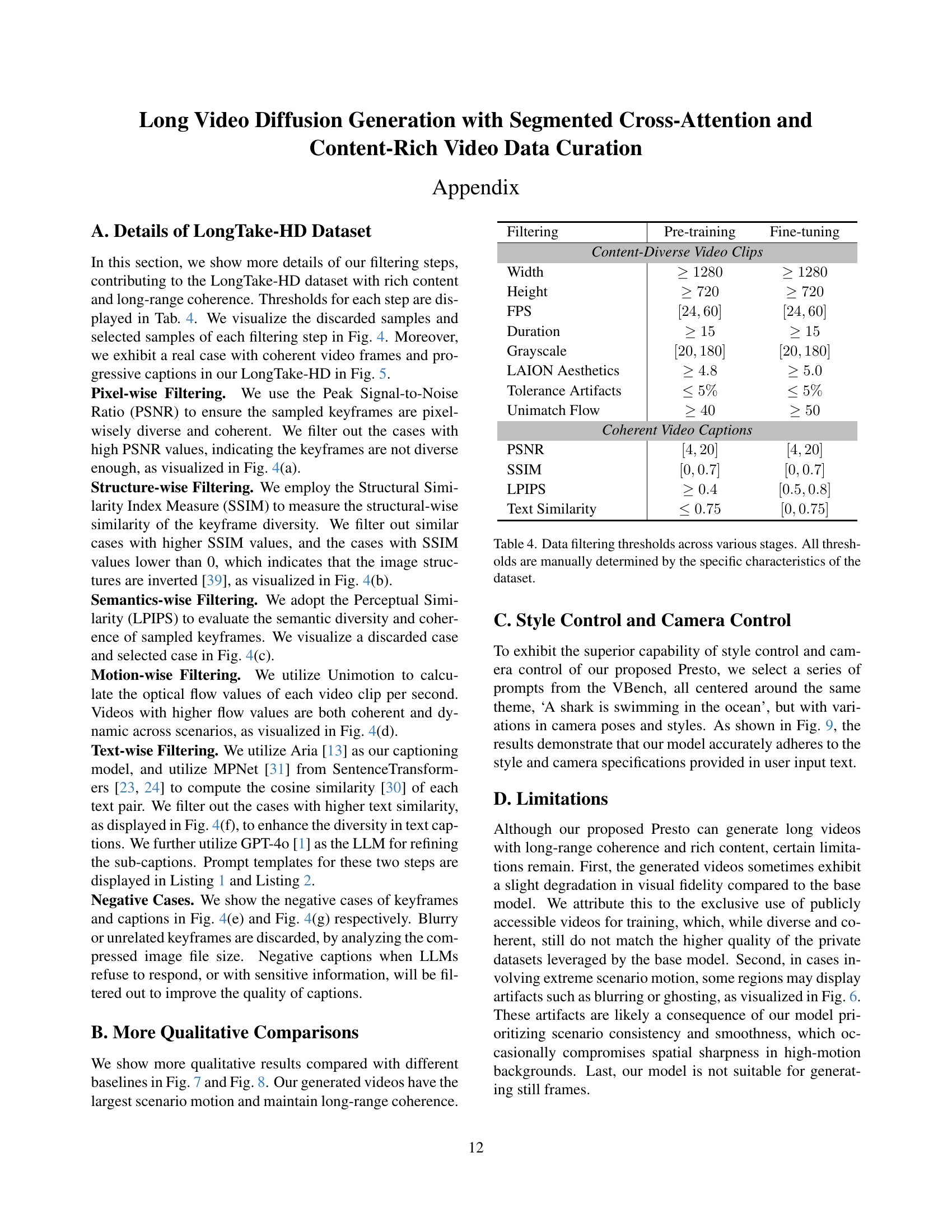
🔼 This table details the thresholds used at each stage of the LongTake-HD dataset filtering pipeline. It shows the criteria applied to the raw videos (resolution, duration, etc.), and the filtering steps performed to refine the dataset for both pre-training and fine-tuning. The filtering steps use metrics like PSNR, SSIM, LPIPS, and optical flow to ensure diversity and coherence in visual content and motion. The table includes the specific ranges and values used for the various filters. These manually determined thresholds are essential for creating a high-quality, curated dataset suitable for training video generation models.
read the caption
Table 4: Data filtering thresholds across various stages. All thresholds are manually determined by the specific characteristics of the dataset.
Full paper#