TL;DR#
Detecting abusive language in audio from multiple languages is a huge challenge, particularly when data is scarce. Existing methods often rely on text-based techniques which are inaccurate with audio since they can’t capture nuances like tone and volume. The paper explores this problem by using a technique called few-shot learning with pre-trained audio models to classify abusive audio from 10 different low-resource Indian languages. This allows the model to learn from a limited amount of labeled data for each language.
The researchers used two pre-trained models – Whisper and Wav2Vec – to extract features from audio, applying two different normalization techniques (L2-Norm and Temporal Mean) to improve performance. They then employed Model-Agnostic Meta-Learning (MAML) to quickly adapt to new languages with limited data. The results show that their method is highly effective, especially when using the Whisper model with L2-Norm normalization, reaching accuracy scores as high as 85% in some languages. They also conducted a feature visualization study to understand how the model works, finding that language similarity helps in improving cross-lingual detection.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the crucial and underexplored problem of cross-lingual audio abuse detection in low-resource settings. It introduces a novel few-shot learning method using pre-trained audio models, offering a practical solution for resource-constrained scenarios. The research opens new avenues for multilingual abuse detection and expands the possibilities of applying powerful pre-trained models in low resource contexts. The findings are highly relevant to ongoing work in cross-lingual transfer learning and few-shot learning in the NLP and speech processing community.
Visual Insights#

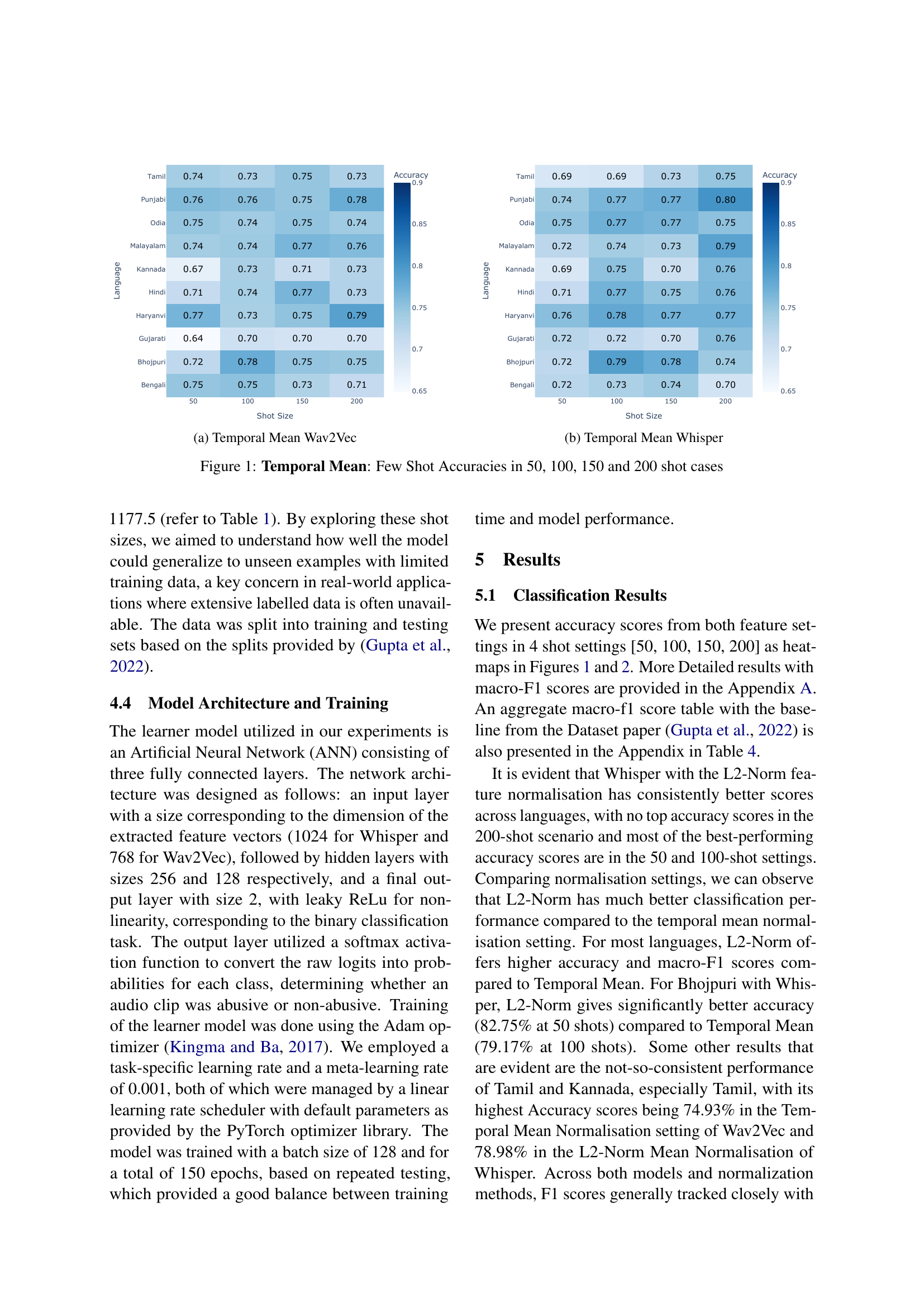
🔼 This figure shows the few-shot accuracies achieved using the Wav2Vec model with Temporal Mean feature normalization. The results are presented as a heatmap, showing the accuracy for each of the 10 languages across four different shot sizes (50, 100, 150, and 200). Each cell in the heatmap represents the accuracy for a specific language and shot size combination, enabling a visual comparison of performance under varying data constraints.
read the caption
(a) Temporal Mean Wav2Vec
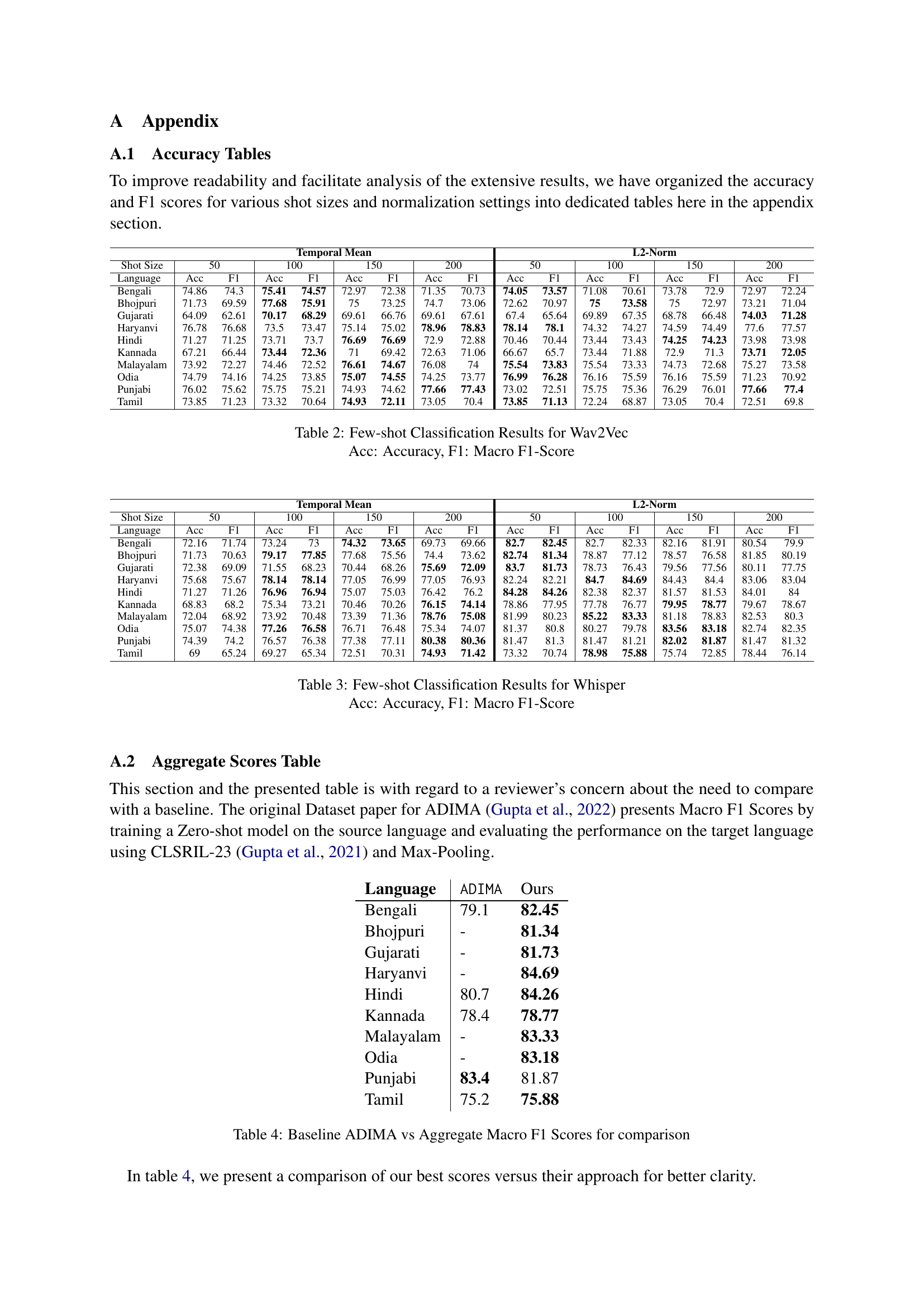
| Language | Abusive | Non-Abusive | Total | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | |||
| Bengali | 394 | 148 | 428 | 222 | 1192 | |
| Bhojpuri | 253 | 122 | 506 | 214 | 1095 | |
| Gujarati | 516 | 255 | 301 | 107 | 1179 | |
| Haryanvi | 419 | 193 | 399 | 173 | 1184 | |
| Hindi | 449 | 186 | 373 | 183 | 1191 | |
| Kannada | 530 | 243 | 289 | 126 | 1188 | |
| Malayalam | 582 | 257 | 237 | 115 | 1191 | |
| Odia | 491 | 209 | 323 | 156 | 1179 | |
| Punjabi | 405 | 176 | 413 | 191 | 1185 | |
| Tamil | 572 | 267 | 248 | 104 | 1191 | |
| Total | 4611 | 2056 | 3517 | 1591 | 11775 |
🔼 This table shows the distribution of data points in the ADIMA dataset across different Indian languages and the two classes (abusive and non-abusive). It breaks down the number of training and testing samples for each language in both classes. This provides insights into the class balance and the amount of data available for training and evaluation in each language, which is crucial for understanding the challenges and potential biases in the dataset, especially in the context of low-resource scenarios.
read the caption
Table 1: ADIMA Dataset distribution across languages and classes. Train and Test being the ones provided by authors.
In-depth insights#
Audio Abuse Detect#
Audio abuse detection in low-resource settings presents a significant challenge due to data scarcity and linguistic diversity. This research tackles this problem by leveraging pre-trained audio representations from models like Wav2Vec and Whisper, which are powerful and effective, even in cross-lingual scenarios. The study explores few-shot learning (FSL) via the Model-Agnostic Meta-Learning (MAML) framework, demonstrating promising results in adapting to multiple low-resource Indian languages with limited training data. The impact of different feature normalization techniques and the generalizability of pre-trained models across languages are key aspects of the research. Feature visualization enhances understanding of how pre-trained models capture linguistic similarities, improving cross-lingual performance. While the use of pre-trained models greatly reduces data requirements, further research is needed to address the challenges of other low-resource languages and dialects and explore alternative meta-learning methods to enhance the robustness of the system.
Few-Shot Learning#
The research paper explores cross-lingual audio abuse detection in low-resource settings, a challenging task due to limited data. Few-shot learning (FSL) is presented as a crucial methodology to address this data scarcity. By leveraging powerful pre-trained audio representations from models like Wav2Vec and Whisper, the authors demonstrate that FSL can effectively adapt to new languages with limited labeled data, achieving surprisingly high accuracy. The core of the FSL approach lies in its ability to quickly adapt the model to new tasks (languages in this case) using only a few training examples, showcasing adaptability and generalization capabilities. This is particularly relevant for multilingual contexts where obtaining large, labeled datasets for all languages is impractical. The effectiveness of different feature normalization techniques (L2-norm and temporal mean) is also investigated, with L2-norm generally demonstrating superior performance. A visual analysis of pre-trained features underscores the method’s ability to capture linguistic nuances and similarities, contributing to cross-lingual generalization. The success of FSL in this low-resource, cross-lingual setting highlights its potential as a valuable technique for real-world applications of audio content moderation.
Cross-Lingual FSL#
Cross-lingual Few-Shot Learning (FSL) in audio abuse detection presents a significant challenge due to the scarcity of labeled data in many languages. This research area seeks to leverage powerful pre-trained audio representations, such as those from Wav2Vec and Whisper, to enable models to quickly adapt and generalize to new, low-resource languages with minimal training examples. The effectiveness hinges on the ability of these pre-trained models to capture cross-lingual features that generalize well across various languages. Model-Agnostic Meta-Learning (MAML) is often used as a suitable framework due to its ability to effectively learn from few-shot examples. A key aspect is the proper normalization of audio features (such as L2-Norm and temporal mean), which significantly impacts the model’s performance. Research suggests that the performance of cross-lingual FSL varies greatly by language, and that language families may exhibit closer performance groupings. Investigating pre-trained feature visualization can offer insights into the cross-lingual generalization ability and better inform feature engineering techniques. The overall goal is to develop more robust and effective abuse detection systems capable of handling multilingual content, especially in resource-constrained environments.
MAML Framework#
The Model-Agnostic Meta-Learning (MAML) framework is a powerful technique employed in few-shot learning scenarios, particularly relevant for low-resource settings. MAML’s strength lies in its ability to quickly adapt a model to a new task using only a limited number of examples. This is crucial in cross-lingual audio abuse detection, where data for each language may be scarce. By training on various languages simultaneously, MAML facilitates cross-lingual generalization. The core idea is to learn an initial set of model parameters that are easily adaptable to new tasks; this reduces the need for extensive retraining with new data for each language. Pre-trained audio representations, such as those from Whisper or Wav2Vec, are leveraged as feature extractors, providing powerful initial representations for MAML. These features are then further enhanced with normalization techniques to improve performance and the model is finally trained using a cross-lingual approach. The success of MAML in this context highlights its potential for other low-resource audio tasks, especially in multilingual settings. The resulting framework offers a valuable methodology for detecting abusive language across diverse languages with limited training data.
Future of Research#
Future research should prioritize expanding the dataset to encompass a wider range of Indian languages, addressing the current limitations. Including under-represented languages like Telugu and Marathi is crucial for broader applicability. Further investigation into different meta-learning algorithms beyond MAML, such as ProtoMAML and contrastive learning, could potentially enhance performance. Exploring alternative pre-trained audio models and feature normalization techniques beyond those used in this study is also warranted. A focus on improving the robustness of the models to noisy and incomplete audio data is important, as is investigating the impact of various accents and speaking styles. Finally, a detailed analysis of the specific features contributing to accurate abusive language detection is needed, to provide deeper insights for practical application.
More visual insights#
More on figures

🔼 This figure shows the few-shot accuracy results for audio abuse detection using the Whisper model with temporal mean feature normalization. The results are presented as a heatmap, where each cell represents the accuracy achieved for a specific language and a given shot size (number of training examples). Different colors in the heatmap represent different accuracy levels, ranging from low (darker shades) to high (lighter shades). The x-axis represents the shot size (50, 100, 150, 200), and the y-axis represents the ten different Indian languages used in the ADIMA dataset. This visualization helps to understand the model’s performance across different languages and training data sizes.
read the caption
(b) Temporal Mean Whisper

🔼 This figure displays the few-shot learning accuracy results for audio abuse detection using Temporal Mean feature normalization. It presents a heatmap for each language across four different shot sizes (50, 100, 150, and 200). The heatmaps visually compare the performance of two different pre-trained audio models (Wav2Vec and Whisper) across these different shot sizes and languages. Darker colors represent higher accuracy.
read the caption
Figure 1: Temporal Mean: Few Shot Accuracies in 50, 100, 150 and 200 shot cases

🔼 This figure displays the few-shot learning accuracy results for the Wav2Vec model using L2-norm feature normalization. It shows accuracy scores across four different shot sizes (50, 100, 150, and 200) for ten Indian languages. Each cell in the heatmap represents the accuracy achieved for a specific language and shot size, providing insights into the model’s performance under varying data constraints.
read the caption
(a) L2-Norm Wav2Vec

🔼 This figure shows the few-shot accuracies achieved using the L2-Norm feature normalization method with the Whisper model. The heatmap displays accuracy scores for four different shot sizes (50, 100, 150, and 200) across ten Indian languages. Each cell in the heatmap represents the accuracy for a specific language and shot size combination. The figure helps to visualize the performance of the model under different data scarcity conditions and across multiple languages.
read the caption
(b) L2-Norm Whisper
Full paper#