↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current joint video highlight detection and moment retrieval models often struggle with cross-task dynamics and limited attention mechanisms, leading to suboptimal performance. Existing methods also underutilize the power of large vision-language models (LVLMs) for multimodal feature integration.
VideoLights addresses these issues through a novel framework incorporating (1) a Convolutional Projection and Feature Refinement module to improve video-text alignment; (2) a Bi-Directional Cross-Modal Fusion network for strongly coupled clip representations; and (3) a Uni-directional Joint-Task Feedback mechanism. Further enhancing performance, VideoLights introduces hard positive/negative losses and leverages LVLMs like BLIP-2 for intelligent pre-training. Extensive experiments demonstrate state-of-the-art performance on several benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents VideoLights, a novel framework that significantly improves the joint prediction of video highlight detection and moment retrieval. This is crucial for enhancing video understanding, which is a rapidly growing area of research with broad applications. The innovative techniques used—feature refinement, cross-modal and cross-task alignment—offer valuable insights for researchers working in related areas. The open-sourcing of the code further accelerates progress in this field.
Visual Insights#
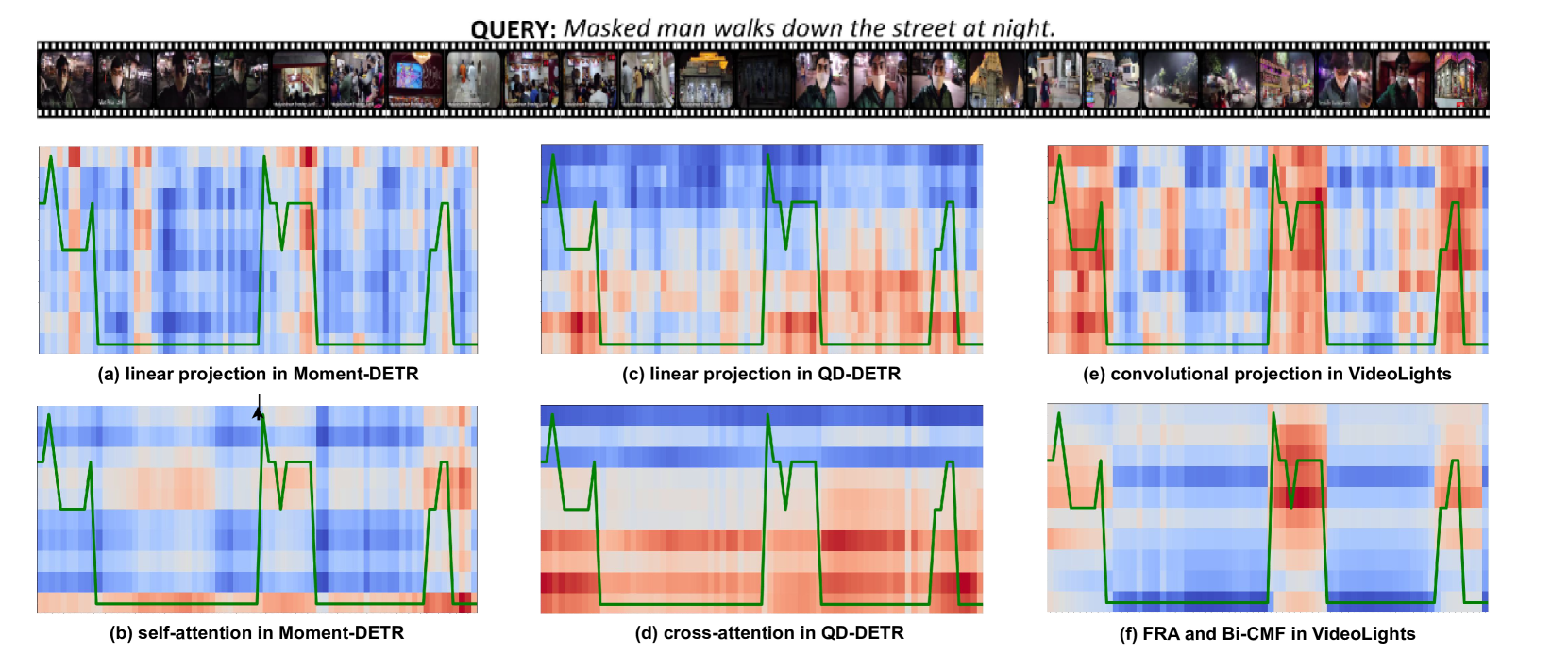
🔼 Figure 1 presents a comparative analysis of multimodal alignment in video understanding models, focusing on the relationship between text queries and video clips. Six heatmaps illustrate the alignment scores between query words and video clips for three different models: Moment-DETR, QD-DETR, and VideoLights. Color intensity ranging from blue (low relevance) to red (high relevance) represents the strength of the alignment. A green line indicates the ground truth saliency scores for each video clip. The heatmaps reveal that VideoLights progressively refines the alignment between query and video through distinct stages (projection, feature refinement, and bi-directional cross-attention) leading to improved query-clip relevance. Conversely, Moment-DETR and QD-DETR exhibit more limited multimodal interaction and less refined alignment.
read the caption
Figure 1: Relevance heat map illustrating multimodal alignment dynamics across video understanding models. Color intensity (blue to red) quantifies query-video clip correspondence, with the green line indicating ground truth clip-wise saliency. Comparative visualization reveals VideoLights’s progressive refinement of query-clip relevance through projection, feature refinement, and bi-directional cross-attention stages, in contrast to Moment-DETR [16] and QD-DETR [19]’s limited multimodal interaction.
| Dataset | Domain | Annotations | Videos | Task | Used in pt | Synthetic data |
|---|---|---|---|---|---|---|
| QVHighlights | Vlog / News | 10.3K | 12.5K | MR, HD | ✓ | 187682 |
| Charades-STA | Activity | 16.1K | 6.7K | MR | ✓ | 23193 |
| TVSum | Web | 50 | 50 | HD |
🔼 This table compares the characteristics of three datasets used in the paper: QVHighlights, Charades-STA, and TVSum. It lists the domain from which the videos originate, the type of annotations provided, the number of videos and annotations, the tasks (Moment Retrieval and Highlight Detection) each dataset is used for, whether the data was used for pre-training, and the size of any synthetic data generated for pre-training.
read the caption
TABLE I: Comparison of datasets used in this study.
In-depth insights#
Cross-Task Dynamics#
The concept of ‘Cross-Task Dynamics’ in the context of video highlight detection and moment retrieval highlights the interdependence and interplay between these two closely related tasks. While seemingly distinct, highlight detection (identifying salient video segments) and moment retrieval (locating specific moments matching textual queries) share underlying representations and processes. Effective models must account for this, avoiding isolated processing. A strong model should leverage information learned during one task to improve performance in the other, creating a synergistic relationship. For example, identifying highlights might inform which parts of the video are more likely to contain moments relevant to user queries. Conversely, successful moment retrieval could indicate the significance of certain video segments, reinforcing highlight detection accuracy. Ignoring cross-task dynamics leads to suboptimal performance, as crucial contextual information remains untapped. Therefore, a nuanced approach that recognizes and exploits this synergy is pivotal for achieving state-of-the-art results in both video highlight detection and moment retrieval.
Multimodal Alignment#
Multimodal alignment in video analysis focuses on effectively integrating and harmonizing information from diverse sources, primarily video and text. The core challenge is to establish meaningful correspondences between visual and textual representations, enabling a system to understand how the words in a query relate to specific moments or highlights within a video. Successful multimodal alignment is crucial for tasks like video moment retrieval and highlight detection, where the goal is to locate and rank relevant video segments based on a natural language description. Effective techniques often involve generating aligned embeddings that capture semantic similarities across modalities and designing attention mechanisms that selectively focus on relevant parts of the video given a textual query. Advanced methods also incorporate refinements of these embeddings to filter out noise and irrelevant information, improving the accuracy and robustness of the alignment process. Ultimately, robust multimodal alignment empowers systems to interpret and interact with video data with a level of understanding typically only achieved with human intervention.
Feature Refinement#
Feature refinement in video analysis focuses on enhancing the quality of visual features used for tasks like highlight detection and moment retrieval. The core idea is to improve the alignment and relevance of video features to textual queries. This often involves techniques that filter out noise and irrelevant information from video frames, leading to more accurate and focused representations. Convolutional neural networks are frequently employed for this purpose, allowing for the extraction of more meaningful features based on both local (pixel level) and global (temporal or scene level) contexts. A crucial aspect of feature refinement is intermodal alignment, where visual and textual features are brought into closer correspondence, facilitating effective cross-modal fusion. This alignment can involve losses to penalize mismatches between video and text representations, driving the network to learn better-aligned features. Hard positive and hard negative mining is another related technique, ensuring the network pays attention to both easily and difficult cases, ultimately improving the model’s capacity for accurate video understanding.
Adaptive Losses#
The concept of ‘Adaptive Losses’ in the context of a video highlight detection and moment retrieval model is crucial for optimizing performance. Adaptive loss functions dynamically adjust their weighting or penalty based on the model’s performance on specific data points or tasks. This contrasts with traditional methods that apply a fixed loss across all samples. For hard negative samples (irrelevant video clips), an adaptive loss would focus on heavily penalizing incorrect predictions, thus forcing the model to learn to distinguish better between relevant and irrelevant content. Conversely, for hard positive samples (highly relevant clips), the adaptive loss may prioritize minimizing false negatives, ensuring that important moments aren’t missed. The adaptive nature of these losses is key; they aren’t static parameters but rather mechanisms that learn and evolve alongside the model, leading to a more robust and accurate system. The utilization of hard positive/negative mining further enhances this adaptive learning by selectively focusing the model’s attention on the most informative samples. This results in a more efficient use of training resources and improved generalization to unseen data. The implementation of adaptive losses is a significant advancement over traditional fixed loss functions, demonstrating a more sophisticated and intelligent approach to model training in the context of video analysis.
Future of HD/MR#
The future of Highlight Detection/Moment Retrieval (HD/MR) hinges on advancing multimodal understanding, particularly in handling noisy and ambiguous data. This means moving beyond simple feature concatenation towards sophisticated cross-modal fusion mechanisms, such as those employed in VideoLights, which leverage bidirectional attention to capture strong query-aware clip representations. More robust pre-training strategies are needed, potentially leveraging larger vision-language models (LVLMs) and synthetic data generation to improve generalizability and reduce reliance on extensive annotated datasets. Furthermore, research should explore more effective cross-task learning paradigms that truly capture the interdependence between HD and MR, enabling the models to inform and enhance each other’s performance. Finally, enhancing the efficiency and scalability of existing methods is crucial, focusing on reducing computational cost and memory requirements to enable real-time or near real-time processing of large video collections. The development of more sophisticated loss functions, like VideoLights’ adaptive hard positive/negative losses, will also improve model learning and robustness.
More visual insights#
More on figures
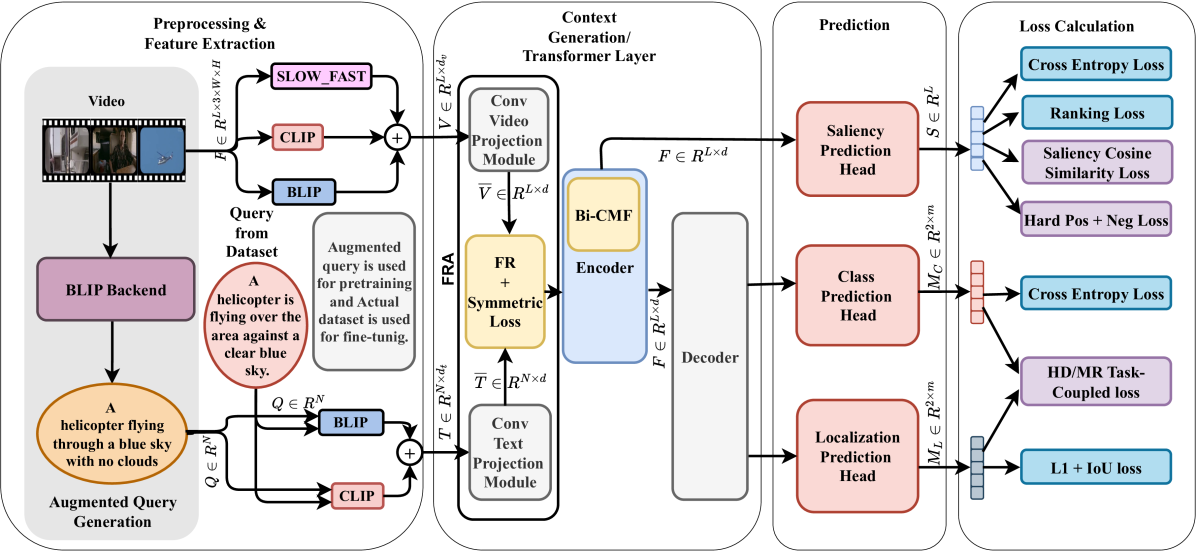
🔼 The VideoLights architecture uses a two-stage approach for joint video highlight detection and moment retrieval. First, the Feature Refinement and Alignment (FRA) module processes video and text features, aligning them and refining their representations. The output of FRA feeds into the Bi-directional Cross-Modal Fusion (Bi-CMF) network, which further integrates and refines the multimodal embeddings via transformer layers. The Bi-CMF output goes to prediction heads (Class, Localization, Saliency). These heads output the final highlight scores (saliency), video moment locations, and class predictions for each clip. A Unidirectional Joint-Task Feedback Mechanism (Uni-JFM) provides cross-task feedback using saliency cosine similarity and task-coupled loss functions to improve the learning process. The figure highlights the new proposed loss functions in purple.
read the caption
Figure 2: Overall VideoLights architecture. FRA models the video-text cross-modal correlations from projected embeddings and passes them to Bi-CMF in the encoder. A trainable saliency vector predicts output saliency levels. Class and moment prediction heads predict logits and video moments, while saliency cosine similarity and task-coupled HD/MR losses together provide cross-task feedback Uni-JFM. Proposed new losses are in purple.
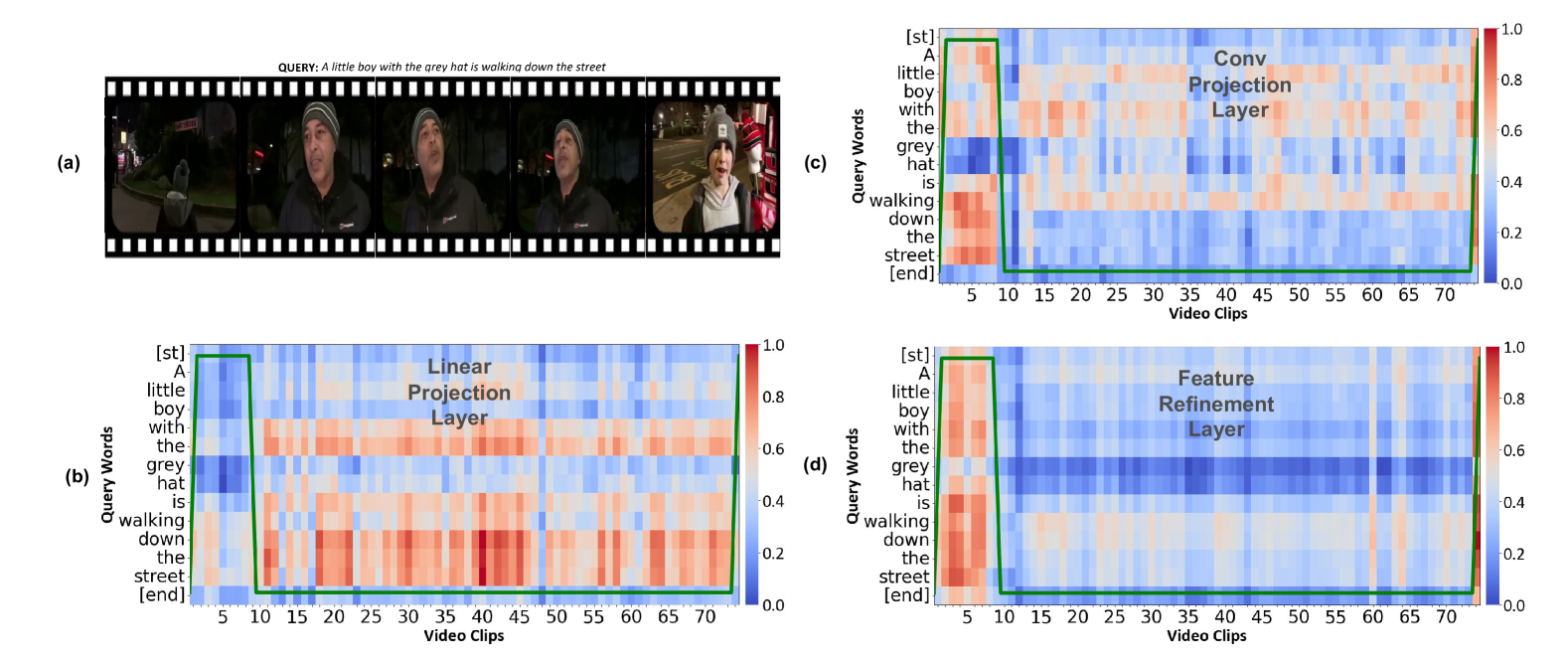
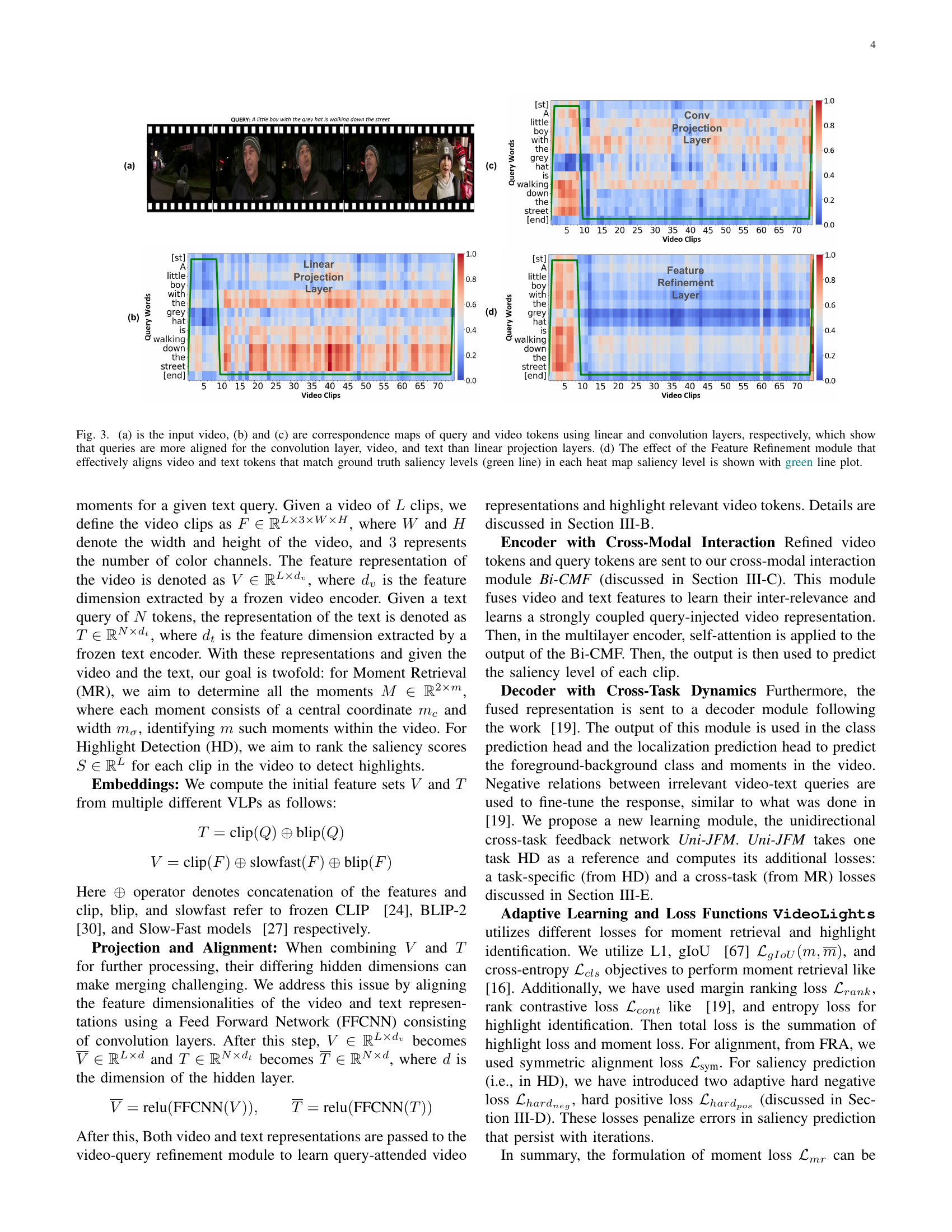
🔼 This figure visualizes the impact of different projection methods (linear vs. convolutional) and the Feature Refinement module on aligning video and text tokens. Subfigure (a) shows the input video. Subfigures (b) and (c) present correspondence maps illustrating the alignment between query and video tokens using linear and convolutional projection layers, respectively. The convolutional layer demonstrates better alignment of query and video tokens with the text. Subfigure (d) shows how the Feature Refinement module further improves this alignment, particularly for video and text tokens corresponding to ground truth saliency levels (indicated by the green line).
read the caption
Figure 3: (a) is the input video, (b) and (c) are correspondence maps of query and video tokens using linear and convolution layers, respectively, which show that queries are more aligned for the convolution layer, video, and text than linear projection layers. (d) The effect of the Feature Refinement module that effectively aligns video and text tokens that match ground truth saliency levels (green line) in each heat map saliency level is shown with green line plot.

🔼 This figure illustrates the architecture of the Bi-Directional Cross-Modal Fusion (Bi-CMF) Network. The Bi-CMF network is a three-layer multi-head attention mechanism designed to generate a query-aware video representation by integrating text and video information. The first layer uses video features as queries and text features as keys and values to identify video tokens that are relevant to the text query (text2video attention). The second layer reverses this process, using text features as queries and video features as keys and values, identifying text tokens relevant to the video (video2text attention). The final layer refines the process using the outputs from the previous layers, strengthening the alignment between text and video tokens (text2video attention). Dropout and layer normalization are applied between each attention layer for robustness, with an activation layer at the output. This multi-stage attention mechanism helps to strongly couple video and text modalities.
read the caption
Figure 4: Bi-CMF learns query-oriented video via text2video, video2text, then text2video attentions. In this process, dropout and normalization are applied after each step, and activation is applied at the last stage.
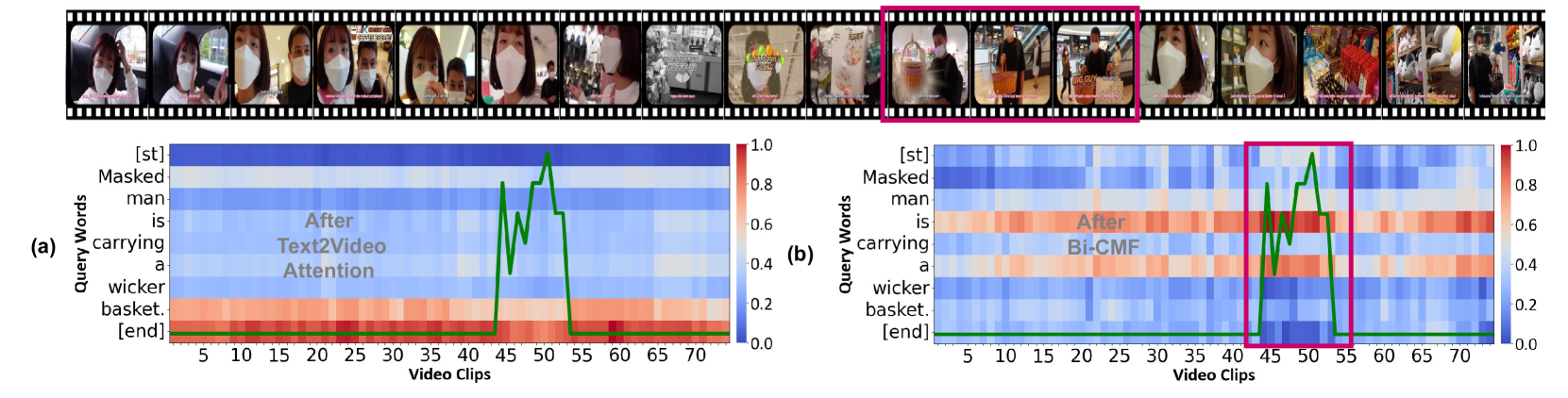
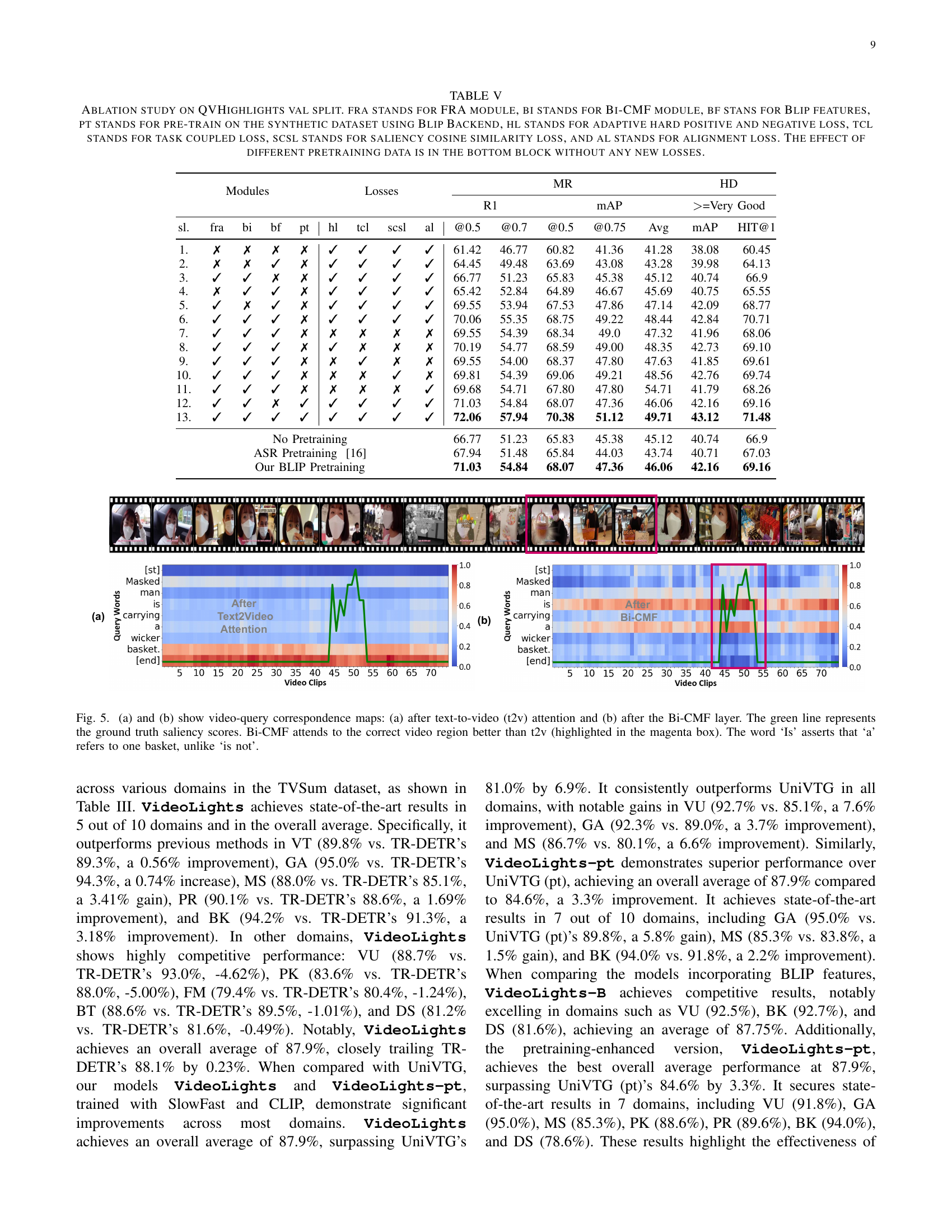
🔼 This figure visualizes the effectiveness of the Bi-Directional Cross-Modal Fusion (Bi-CMF) network in VideoLights. It presents two heatmaps showing the alignment between video clips and query words: (a) after the text-to-video attention mechanism and (b) after the Bi-CMF module. The green line indicates the ground truth saliency scores. The magenta box highlights the region where the Bi-CMF significantly improves the focus on the relevant video clips compared to the plain text-to-video attention. The caption also points out how the word ‘is’ in the query helps disambiguate the reference of ‘a’ to a single basket in the video, contrasting with a hypothetical ‘is not’ which would have a different meaning.
read the caption
Figure 5: (a) and (b) show video-query correspondence maps: (a) after text-to-video (t2v) attention and (b) after the Bi-CMF layer. The green line represents the ground truth saliency scores. Bi-CMF attends to the correct video region better than t2v (highlighted in the magenta box). The word ‘Is’ asserts that ‘a’ refers to one basket, unlike ‘is not’.
🔼 This figure shows the visualization of multimodal alignment dynamics across video understanding models. It compares the query-video clip correspondence heatmaps of three models: Moment-DETR, QD-DETR, and VideoLights. Color intensity (blue to red) represents the query-video clip correspondence strength, with green lines indicating ground truth clip-wise saliency. The visualization demonstrates how VideoLights progressively refines query-clip relevance through its different modules (projection, feature refinement, and bi-directional cross-attention), achieving stronger alignment with ground truth compared to the other two models. This highlights the improved multimodal interaction and alignment capabilities of VideoLights.
read the caption
(a)
🔼 This figure shows a heatmap visualization of the query-aware clip representation generated by VideoLights after applying the Bi-Directional Cross-Modal Fusion (Bi-CMF) network. The heatmap illustrates the alignment between the query words and the video clips, where higher color intensity (red) indicates stronger relevance. This visualization highlights how Bi-CMF effectively captures cross-modal interactions and enhances the alignment between text and video, improving the accuracy of moment retrieval and highlight detection compared to methods with only unidirectional attention mechanisms. The green line indicates the ground truth saliency scores for comparison.
read the caption
(b)
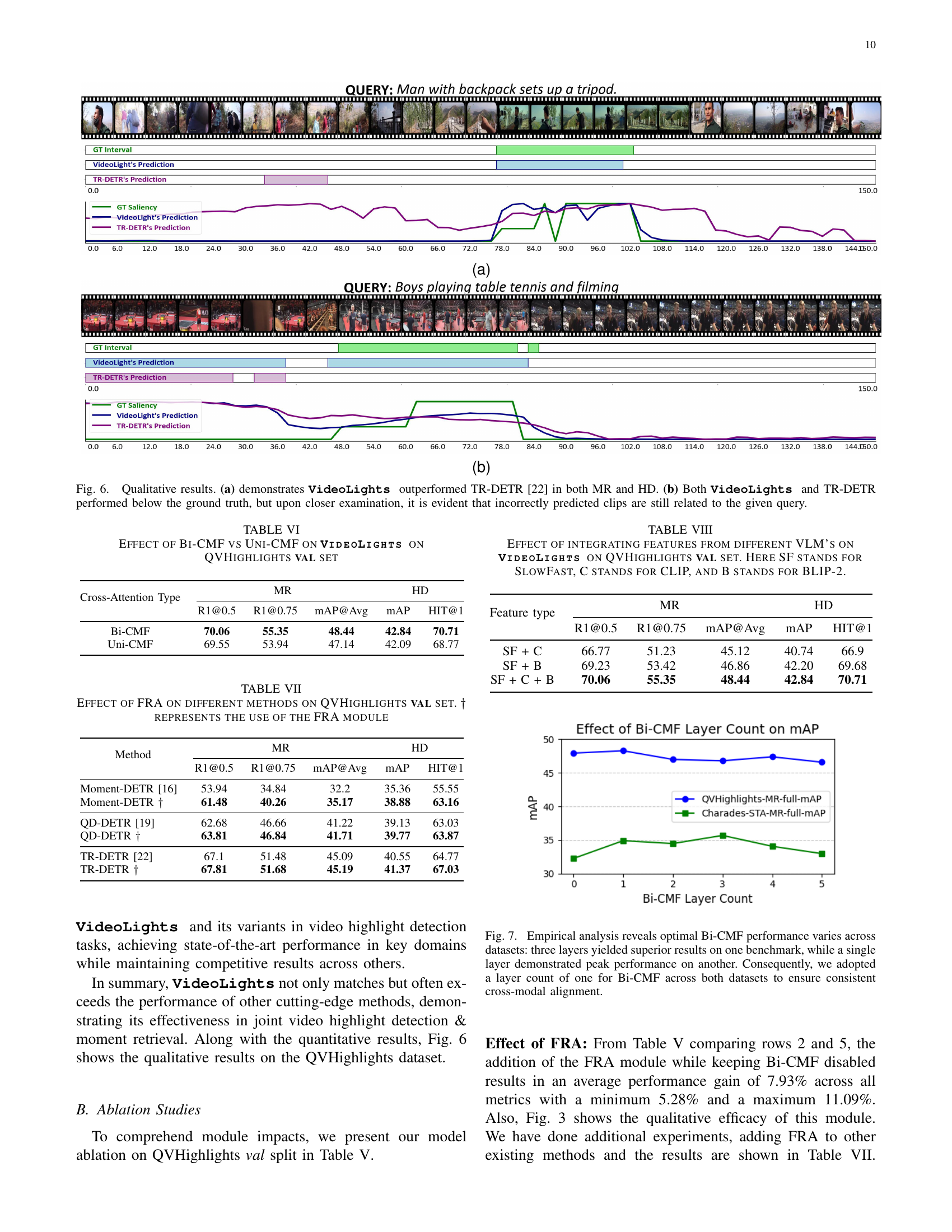
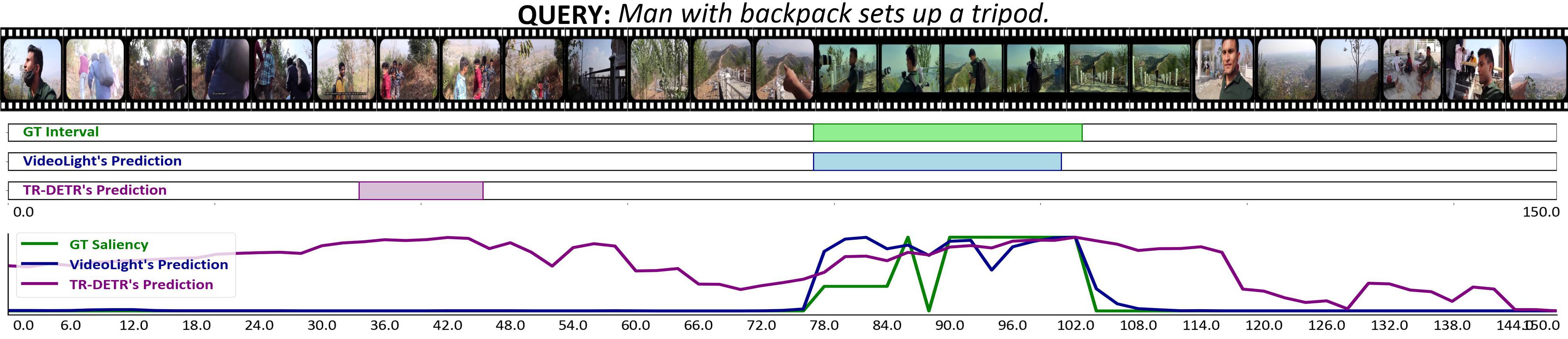
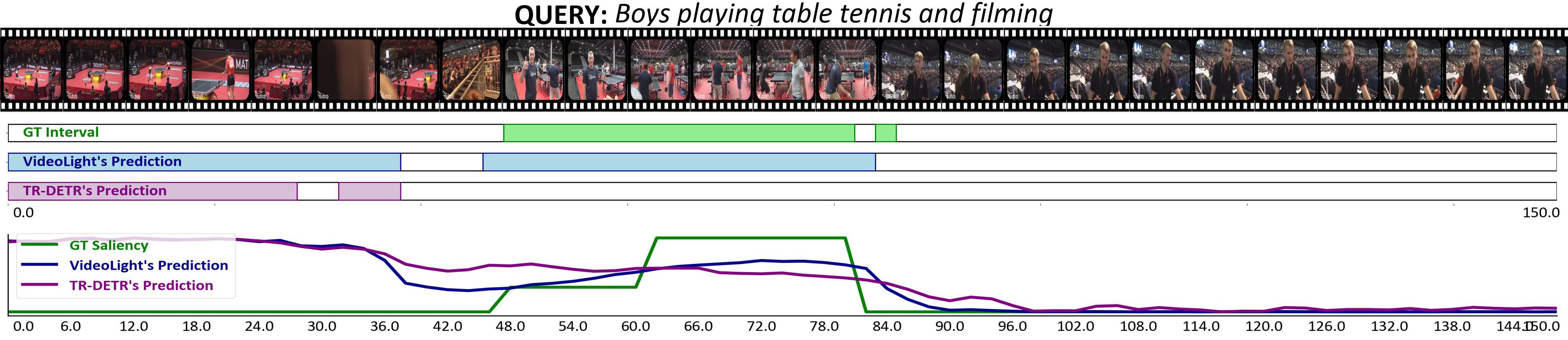
🔼 Figure 6 presents a qualitative comparison of VideoLights and TR-DETR on two video clips. Subfigure (a) showcases a clear advantage for VideoLights, demonstrating superior performance in both Moment Retrieval (MR) and Highlight Detection (HD) tasks compared to TR-DETR. Subfigure (b) shows instances where both models underperform compared to the ground truth. However, a closer inspection reveals that while the predictions aren’t perfect, the clips identified by both methods are still semantically relevant to the given query, indicating some level of success in capturing relevant video segments despite inaccuracies in precise localization or ranking.
read the caption
Figure 6: Qualitative results. (a) demonstrates VideoLights outperformed TR-DETR [22] in both MR and HD. (b) Both VideoLights and TR-DETR performed below the ground truth, but upon closer examination, it is evident that incorrectly predicted clips are still related to the given query.
More on tables
| Method | MR R1 @0.5 | MR R1 @0.7 | MR mAP @0.5 | MR mAP @0.75 | MR mAP Avg | HD mAP | HD HIT@1 |
|---|---|---|---|---|---|---|---|
| Moment-DETR [16] | 52.89 | 33.02 | 54.82 | 29.4 | 30.73 | 35.69 | 55.6 |
| UMT [17] † | 56.23 | 41.18 | 53.83 | 37.01 | 36.12 | 38.18 | 59.99 |
| MH-DETR [72] | 60.05 | 42.48 | 60.75 | 38.13 | 38.38 | 38.22 | 60.51 |
| EaTR [21] | 61.36 | 45.79 | 61.86 | 41.91 | 41.74 | 37.15 | 58.65 |
| QD-DETR [19] | 62.40 | 44.98 | 63.17 | 42.05 | 41.44 | 39.13 | 63.1 |
| UVCOM [62] | 63.55 | 47.47 | 63.37 | 42.67 | 43.18 | 39.74 | 64.20 |
| TR-DETR [22] | 64.66 | 48.96 | 63.98 | 43.73 | 42.62 | 39.91 | 63.42 |
| UniVTG [20] | 58.86 | 40.86 | 57.60 | 35.59 | 35.47 | 38.20 | 60.96 |
| VideoLights | 63.36 | 48.70 | 63.81 | 42.87 | 43.38 | 40.57 | 65.30 |
| Moment-DETR(pt) [16] | 59.78 | 40.33 | 60.51 | 35.36 | 36.14 | 37.43 | 60.17 |
| UMT(pt) [17] | 60.83 | 43.26 | 57.33 | 39.12 | 38.08 | 39.12 | 62.39 |
| QD-DETR (pt) [19] | 64.10 | 46.10 | 64.30 | 40.50 | 40.62 | 38.52 | 62.27 |
| UVCOM(pt) [62] | 64.53 | 48.31 | 64.78 | 43.65 | 43.80 | 39.98 | 65.58 |
| UniVTG(pt) [20] | 65.43 | 50.06 | 64.06 | 45.02 | 43.63 | 40.54 | 66.28 |
| VideoLights-pt | 68.48 | 52.53 | 67.31 | 46.76 | 45.01 | 41.48 | 65.89 |
| VideoLights-B | 68.29 | 52.79 | 67.58 | 47.30 | 46.53 | 42.43 | 68.94 |
| VideoLights-B-pt | 70.36 | 55.25 | 69.53 | 49.17 | 47.94 | 42.84 | 70.56 |
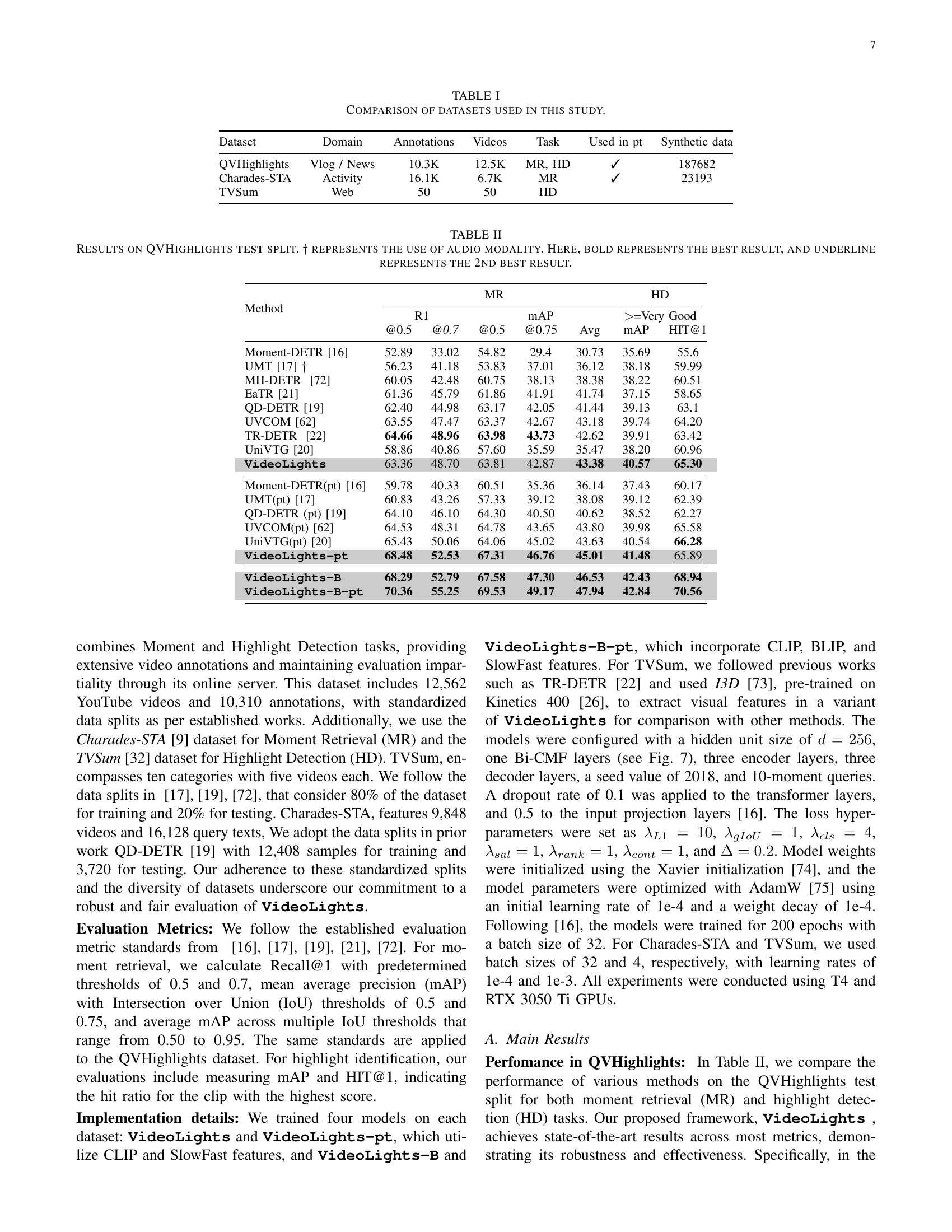
🔼 Table II presents a comprehensive comparison of different video highlight detection and moment retrieval methods on the QVHighlights test dataset. The table includes various evaluation metrics such as Recall@0.5, Recall@0.7, MAP@0.5, MAP@0.75, Average MAP, and HIT@1. Results are shown for both Moment Retrieval (MR) and Highlight Detection (HD) tasks. The table also indicates whether methods utilized audio modalities. The best performing method for each metric is highlighted in bold, and the second-best is underlined. This allows readers to easily compare the performance of various approaches and identify top-performing models for both tasks.
read the caption
TABLE II: Results on QVHighlights test split. ††{\dagger}† represents the use of audio modality. Here, bold represents the best result, and underline represents the 2nd best result.
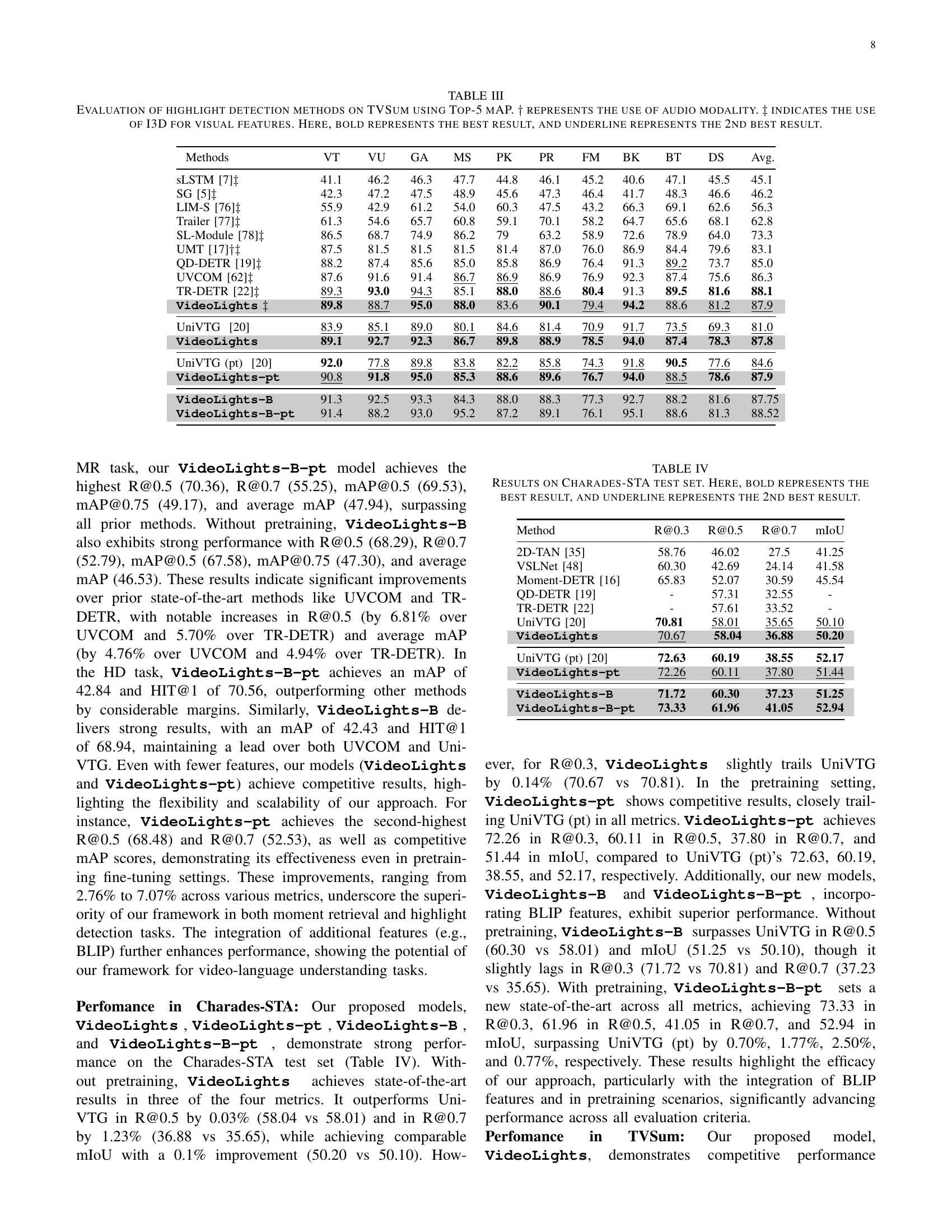
🔼 Table III presents a comparison of various highlight detection methods on the TVSum dataset. The evaluation metric used is Top-5 mean Average Precision (mAP). The table includes results for several methods, indicating whether they utilized audio modality (†) and/or I3D visual features (‡). The best performing method for each metric is highlighted in bold, with the second-best result underlined. This allows for a comprehensive comparison of the performance of different approaches to video highlight detection on this specific dataset.
read the caption
TABLE III: Evaluation of highlight detection methods on TVSum using Top-5 mAP. ††{\dagger}† represents the use of audio modality. ‡‡{\ddagger}‡ indicates the use of I3D for visual features. Here, bold represents the best result, and underline represents the 2nd best result.
| Method | R@0.3 | R@0.5 | R@0.7 | mIoU |
|---|---|---|---|---|
| 2D-TAN [35] | 58.76 | 46.02 | 27.5 | 41.25 |
| VSLNet [48] | 60.30 | 42.69 | 24.14 | 41.58 |
| Moment-DETR [16] | 65.83 | 52.07 | 30.59 | 45.54 |
| QD-DETR [19] | - | 57.31 | 32.55 | - |
| TR-DETR [22] | - | 57.61 | 33.52 | - |
| UniVTG [20] | 70.81 | 58.01 | 35.65 | 50.10 |
| VideoLights | 70.67 | 58.04 | 36.88 | 50.20 |
| UniVTG (pt) [20] | 72.63 | 60.19 | 38.55 | 52.17 |
| VideoLights-pt | 72.26 | 60.11 | 37.80 | 51.44 |
| VideoLights-B | 71.72 | 60.30 | 37.23 | 51.25 |
| VideoLights-B-pt | 73.33 | 61.96 | 41.05 | 52.94 |
🔼 Table IV presents the performance comparison of various methods on the Charades-STA test dataset for moment retrieval and highlight detection tasks. The metrics used are Recall@0.3, Recall@0.5, Recall@0.7, and mean Intersection over Union (mIoU). The best performing method for each metric is highlighted in bold, while the second-best is underlined. This allows for a clear view of the relative strengths and weaknesses of each approach on this specific dataset.
read the caption
TABLE IV: Results on Charades-STA test set. Here, bold represents the best result, and underline represents the 2nd best result.
| Modules | Losses | MR @0.5 | MR @0.7 | MR @0.5 | MR @0.75 | MR mAP | HD HIT@1 | |
|---|---|---|---|---|---|---|---|---|
| sl. | fra | bi | bf | pt | hl | tcl | scsl | al |
| 1. | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ |
| 2. | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| 3. | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ |
| 4. | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| 5. | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| 6. | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| 7. | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| 8. | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| 9. | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ |
| 10. | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| 11. | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ |
| 12. | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 13. | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| No Pretraining | ||||||||
| ASR Pretraining [16] | ||||||||
| Our BLIP Pretraining |
🔼 This ablation study analyzes the impact of individual components of the VideoLights model on the QVHighlights validation set. It examines the contributions of the Feature Refinement and Alignment (FRA) module, the Bi-directional Cross-Modal Fusion (Bi-CMF) network, the inclusion of BLIP features, synthetic data pretraining using a BLIP backend, adaptive hard positive/negative losses, task-coupled loss, saliency cosine similarity loss, and alignment loss. The bottom section of the table isolates the effects of different pretraining data sources without introducing any of the additional loss functions.
read the caption
TABLE V: Ablation study on QVHighlights val split. fra stands for FRA module, bi stands for Bi-CMF module, bf stans for Blip features, pt stands for pre-train on the synthetic dataset using Blip Backend, hl stands for adaptive hard positive and negative loss, tcl stands for task coupled loss, scsl stands for saliency cosine similarity loss, and al stands for alignment loss. The effect of different pretraining data is in the bottom block without any new losses.
| Cross-Attention Type | MR R1@0.5 | MR R1@0.75 | MR mAP@Avg | HD mAP | HD HIT@1 |
|---|---|---|---|---|---|
| Bi-CMF | 70.06 | 55.35 | 48.44 | 42.84 | 70.71 |
| Uni-CMF | 69.55 | 53.94 | 47.14 | 42.09 | 68.77 |
🔼 This table presents an ablation study comparing the performance of VideoLights with a bidirectional cross-modal fusion network (Bi-CMF) against a unidirectional version (Uni-CMF). It shows the impact of the Bi-CMF module on the overall performance of the VideoLights model, as measured by various metrics including Recall@0.5, Recall@0.75, mean Average Precision (mAP), and HIT@1, on the QVHighlights validation set. This helps quantify the benefit of bidirectional attention for the joint video highlight detection and moment retrieval task.
read the caption
TABLE VI: Effect of Bi-CMF vs Uni-CMF on VideoLights on QVHighlights val set
| Method | MR R1@0.5 | MR R1@0.75 | MR mAP@Avg | HD mAP | HD HIT@1 |
|---|---|---|---|---|---|
| Moment-DETR [16] | 53.94 | 34.84 | 32.2 | 35.36 | 55.55 |
| Moment-DETR † | 61.48 | 40.26 | 35.17 | 38.88 | 63.16 |
| QD-DETR [19] | 62.68 | 46.66 | 41.22 | 39.13 | 63.03 |
| QD-DETR † | 63.81 | 46.84 | 41.71 | 39.77 | 63.87 |
| TR-DETR [22] | 67.1 | 51.48 | 45.09 | 40.55 | 64.77 |
| TR-DETR † | 67.81 | 51.68 | 45.19 | 41.37 | 67.03 |
🔼 This table presents an ablation study evaluating the impact of the Feature Refinement and Alignment (FRA) module on the performance of several video highlight detection and moment retrieval models. It shows the results for four different models (Moment-DETR, QD-DETR, and TR-DETR) with and without the FRA module included. The results are presented in terms of Recall@0.5, Recall@0.75, mean average precision (mAP), average mAP across various IoU thresholds, and HIT@1. This allows for a direct comparison of the performance gains achieved by adding the FRA module to each model. The study highlights how FRA enhances model performance across different metrics.
read the caption
TABLE VII: Effect of FRA on different methods on QVHighlights val set. ††{\dagger}† represents the use of the FRA module
| Feature type | MR R1@0.5 | MR R1@0.75 | MR mAP@Avg | HD mAP | HD HIT@1 |
|---|---|---|---|---|---|
| SF + C | 66.77 | 51.23 | 45.12 | 40.74 | 66.9 |
| SF + B | 69.23 | 53.42 | 46.86 | 42.20 | 69.68 |
| SF + C + B | 70.06 | 55.35 | 48.44 | 42.84 | 70.71 |
🔼 This table presents an ablation study evaluating the impact of using different combinations of visual features extracted by various Vision-Language Models (VLMs) on the performance of the VideoLights model. Specifically, it shows how using SlowFast (SF), CLIP (C), and BLIP-2 (B) features, either individually or in combination, affects the model’s performance on the QVHighlights validation set. The metrics used to assess performance are Recall@0.5, Recall@0.75, Mean Average Precision (mAP) averaged across various IoU thresholds, and average mAP. The results demonstrate the effectiveness of combining features from multiple VLMs for improved accuracy.
read the caption
TABLE VIII: Effect of integrating features from different VLM’s on VideoLights on QVHighlights val set. Here SF stands for SlowFast, C stands for CLIP, and B stands for BLIP-2.
Full paper#