TL;DR#
Current video-based large language models (LLMs) struggle to understand and reason about physical events depicted in gameplay videos. This is a significant limitation because gameplay videos often contain glitches that defy the laws of physics, offering a valuable testing ground for LLMs’ physical reasoning capabilities. The lack of a dedicated benchmark to assess this aspect hinders progress in developing more sophisticated LLMs.
To address this, the researchers introduce PhysGame, a novel benchmark containing 880 gameplay videos with physics glitches. They also introduce PhysInstruct and PhysDPO, two datasets designed to improve the training of video LLMs in understanding physics. Using these datasets, they train a new model, PhysVLM, showing significant improvement in recognizing and describing physical inconsistencies in videos. The model surpasses existing open-source and several proprietary models in benchmarks, indicating a significant step forward in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with video LLMs and physical reasoning. It introduces a novel benchmark, PhysGame, which addresses a critical gap in evaluating LLMs’ understanding of physical phenomena. The datasets and model, PhysVLM, significantly advance this under-explored area, shaping future research in video intelligence and bridging the performance gap between open-source and proprietary models. The findings will inspire the development of more robust and human-like video LLMs.
Visual Insights#

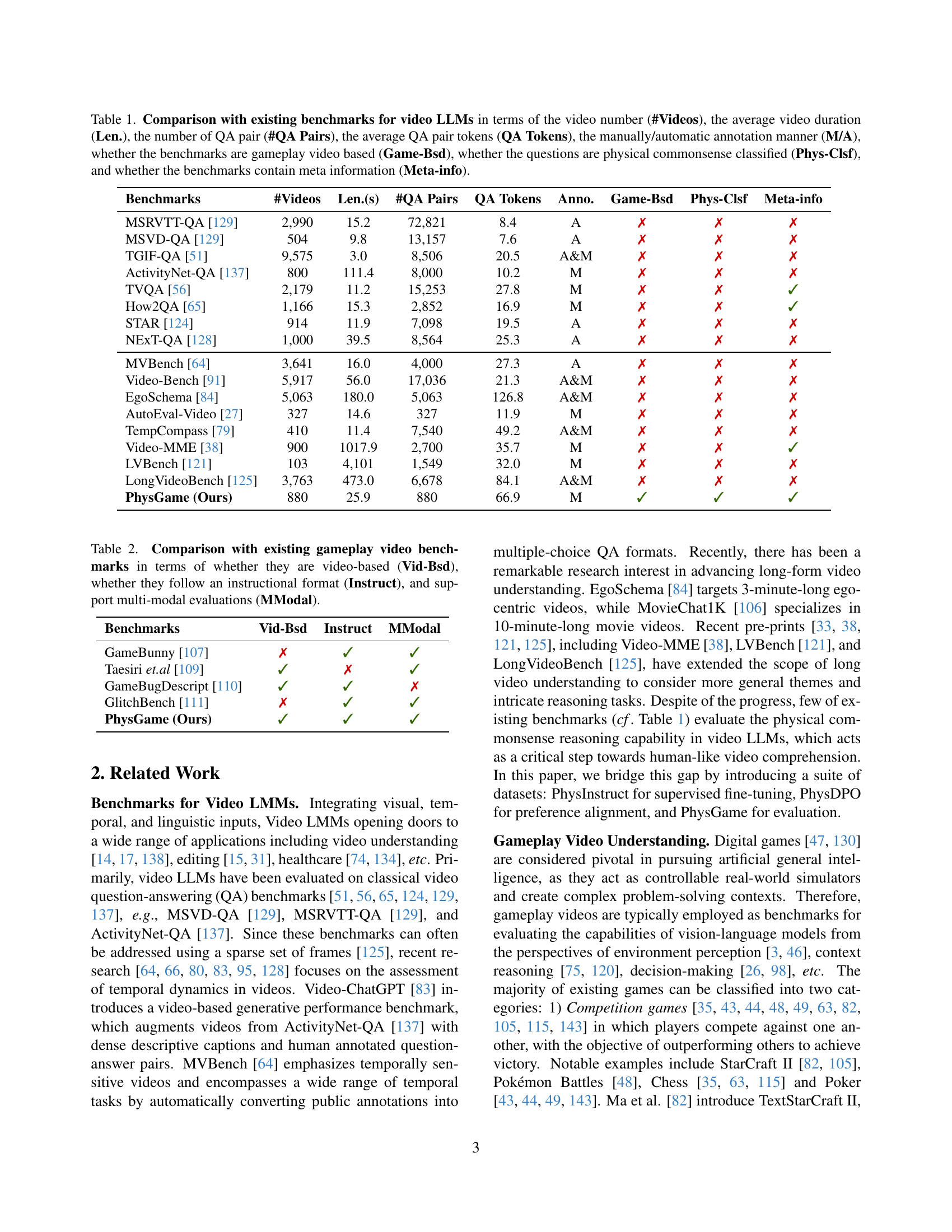
🔼 This figure shows a comparison of physical commonsense understanding between different video LLMs. On the left, a gameplay video is shown where a motorcycle collides with a car, causing it to flip unrealistically. PhysVLM correctly identifies this as a violation of physical commonsense. In contrast, GPT-4 and LLaVA-Next-Video fail to recognize this implausible event. The right side displays a taxonomy used in the PhysGame benchmark, illustrating its four primary categories (mechanics, kinematics, optics, and material properties) and the 12 associated fine-grained sub-categories, providing a detailed breakdown of the types of physical common sense violations included in the benchmark.
read the caption
Figure 1: Left: Comparisons of physical commonsense understanding capability. Our PhysVLM identifies that a motorcycle colliding and flipping a car is implausible while GPT-4o [92] and LLaVA-Next-Video [72] fail to accurately interpret the physical commonsense violations in the video; Right: The taxonomy of PhysGame benchmark including 4 primary categories and 12 fine-grained sub-categories.
| Benchmarks | #Videos | Len.(s) | #QA Pairs | QA Tokens | Anno. | Game-Bsd | Phys-Clsf | Meta-info |
|---|---|---|---|---|---|---|---|---|
| MSRVTT-QA [129] | 2,990 | 15.2 | 72,821 | 8.4 | A | ✗ | ✗ | ✗ |
| MSVD-QA [129] | 504 | 9.8 | 13,157 | 7.6 | A | ✗ | ✗ | ✗ |
| TGIF-QA [51] | 9,575 | 3.0 | 8,506 | 20.5 | A&M | ✗ | ✗ | ✗ |
| ActivityNet-QA [137] | 800 | 111.4 | 8,000 | 10.2 | M | ✗ | ✗ | ✗ |
| TVQA [56] | 2,179 | 11.2 | 15,253 | 27.8 | M | ✗ | ✗ | ✓ |
| How2QA [65] | 1,166 | 15.3 | 2,852 | 16.9 | M | ✗ | ✗ | ✓ |
| STAR [124] | 914 | 11.9 | 7,098 | 19.5 | A | ✗ | ✗ | ✗ |
| NExT-QA [128] | 1,000 | 39.5 | 8,564 | 25.3 | A | ✗ | ✗ | ✗ |
| MVBench [64] | 3,641 | 16.0 | 4,000 | 27.3 | A | ✗ | ✗ | ✗ |
| Video-Bench [91] | 5,917 | 56.0 | 17,036 | 21.3 | A&M | ✗ | ✗ | ✗ |
| EgoSchema [84] | 5,063 | 180.0 | 5,063 | 126.8 | A&M | ✗ | ✗ | ✗ |
| AutoEval-Video [27] | 327 | 14.6 | 327 | 11.9 | M | ✗ | ✗ | ✗ |
| TempCompass [79] | 410 | 11.4 | 7,540 | 49.2 | A&M | ✗ | ✗ | ✗ |
| Video-MME [38] | 900 | 1017.9 | 2,700 | 35.7 | M | ✗ | ✗ | ✓ |
| LVBench [121] | 103 | 4,101 | 1,549 | 32.0 | M | ✗ | ✗ | ✗ |
| LongVideoBench [125] | 3,763 | 473.0 | 6,678 | 84.1 | A&M | ✗ | ✗ | ✗ |
| PhysGame (Ours) | 880 | 25.9 | 880 | 66.9 | M | ✓ | ✓ | ✓ |
🔼 This table compares various video LLMs benchmarks across several key features. It details the number of videos, average video length, the number of question-answer pairs, the average token count per pair, whether the annotation was manual or automatic, if the benchmark uses gameplay videos, if the questions assess physical commonsense, and if metadata is included.
read the caption
Table 1: Comparison with existing benchmarks for video LLMs in terms of the video number (#Videos), the average video duration (Len.), the number of QA pair (#QA Pairs), the average QA pair tokens (QA Tokens), the manually/automatic annotation manner (M/A), whether the benchmarks are gameplay video based (Game-Bsd), whether the questions are physical commonsense classified (Phys-Clsf), and whether the benchmarks contain meta information (Meta-info).
In-depth insights#
PhysGame Benchmark#
The PhysGame benchmark is a novel contribution for evaluating physical commonsense understanding in video LLMs. Its core strength lies in leveraging gameplay videos, which frequently contain glitches violating physics, thus providing a rich source of data for testing this under-explored capability. The benchmark’s design is methodologically sound, categorizing glitches across four fundamental domains (mechanics, kinematics, optics, material properties) and twelve sub-categories. This granular approach allows for detailed analysis of model performance, highlighting specific areas of weakness or strength. PhysGame’s focus on intuitive understanding of physics, rather than complex mathematical formulas, makes it accessible and relevant to a broad range of video LLMs. The use of multi-choice questions ensures objective evaluation, minimizing subjectivity. Overall, PhysGame addresses a critical gap in video LLM evaluation, offering a unique and valuable resource for researchers to advance the field.
PhysVLM Model#
The PhysVLM model, a physical knowledge-enhanced video LLM, represents a significant advancement in video understanding. It leverages a two-stage training process: supervised fine-tuning using the PhysInstruct dataset and direct preference optimization using the PhysDPO dataset. This combined approach enables PhysVLM to outperform existing open-source models in identifying physical commonsense violations in gameplay videos, as demonstrated by its state-of-the-art performance on the PhysGame benchmark. PhysInstruct provides instruction-following pairs, guiding the model’s learning of physical principles. PhysDPO refines the model’s responses by including both preferred and misleadingly generated answers, addressing common training pitfalls. The model’s success highlights the importance of specialized datasets in improving video LLMs’ abilities to reason about physics, moving beyond simplistic object recognition towards a deeper, more nuanced understanding of dynamic scenes.
Dataset Creation#
The creation of a robust and representative dataset is crucial for evaluating video LLMs’ understanding of physical commonsense. A key aspect is the identification of glitches in gameplay videos, which serve as a rich source of physical violations. The process of acquiring videos, ideally from diverse sources and spanning various game genres, is critical for dataset diversity. Annotation is a significant challenge, requiring careful labeling and categorization of glitches, potentially involving multiple annotators for quality control and inter-annotator agreement. The choice of annotation format, such as multiple-choice questions or free-form descriptions, significantly impacts the evaluation process and the types of inferences LLMs can be assessed on. Furthermore, the design of evaluation metrics directly affects which aspects of physical understanding are prioritized and how well different LLMs are distinguished. Therefore, a well-designed dataset creation process requires careful consideration of data acquisition, annotation scheme, and evaluation metrics to ensure a fair and comprehensive assessment of the models.
Evaluation Metrics#
Choosing the right evaluation metrics for a research paper is crucial for accurately assessing the contribution and impact of the work. For a study on physical commonsense violations in gameplay videos, the selection of metrics should reflect the nuances of the task and the nature of the data. Accuracy is a fundamental metric, measuring the percentage of correctly identified glitches or violations. However, accuracy alone is insufficient. The evaluation should also account for different types of glitches, which may require specialized metrics. For example, metrics that assess the model’s capacity to distinguish between subtle and obvious glitches, or to handle variations in video quality or presentation, could prove valuable. Qualitative analysis, examining the specifics of the model’s reasoning and the reasons for errors, is also important. Finally, the choice of metrics should consider the feasibility of obtaining ground truth labels, especially given the subjective nature of determining what constitutes a physical commonsense violation. Ideally, the paper should justify its metric choices with reference to related work and demonstrate the metrics’ relevance to assessing video LLMs and their ability to understand physical phenomena.
Future Work#
Future research directions stemming from the PhysGame benchmark and PhysVLM model could involve expanding the dataset to encompass a wider variety of game genres and physical phenomena. Improving the robustness of PhysVLM to handle diverse video qualities and lighting conditions is crucial, as is further exploring the potential of preference optimization techniques for enhancing physical commonsense reasoning in video LLMs. A key area for future work is to investigate the transferability of the learned physical understanding to real-world scenarios. Finally, developing more sophisticated evaluation metrics that go beyond simple accuracy, and incorporating human evaluation, would help assess the model’s performance in a more nuanced and comprehensive way. This would allow for a better understanding of the model’s limitations and how it can be improved to better capture nuanced physical reasoning.
More visual insights#
More on figures

🔼 This figure shows an example of a multiple-choice question used in the PhysGame benchmark. The question asks to describe a glitch or anomaly observed in a gameplay video. Four options are provided, each describing a different potential anomaly. The correct answer is highlighted in green, illustrating how the PhysGame dataset is annotated for evaluating video LLMs’ understanding of physical common sense.
read the caption
Figure 2: The annotated multi-choice question in PhysGame. The correct option is annotated in green.

🔼 This figure illustrates the process of direct preference optimization (DPO) used to enhance the video LLM’s ability to identify physical commonsense violations. The preferred data consists of question-answer pairs generated using accurate video titles (meta-information) to guide the LLM. In contrast, the dispreferred data is created using misleading titles (meta-information hacking), reduced frame counts (temporal hacking), and lowered spatial resolutions (spatial hacking). This approach helps the model learn to distinguish between physically plausible and implausible video content.
read the caption
Figure 3: Overview of the direct preference optimization training, where the preferred data is generated with the guidance of associated meta-information (i.e., title) while dispreferred data is generated with misleading titles (i.e., meta-information hacking), fewer frames (i.e., temporal hacking) and lower resolutions (i.e., spatial hacking).

🔼 This figure showcases two example question-answer pairs from the PhysInstruct dataset. The dataset is used for instruction tuning of a video large language model (VLM) to improve its ability to understand physical commonsense in videos. The first example uses the video title as a hint (w/), guiding the model to correctly identify the physical glitch shown in the video. The second example omits the title (w/o), and in this case, the model does not correctly identify the glitch, demonstrating how meta information such as the video title can aid in physical commonsense understanding.
read the caption
Figure 4: Example cases in the PhysInstruct dataset with (w/) or without (w/o) meta-information hints.

🔼 This table presents the results of ablation studies conducted to evaluate the impact of different data augmentation techniques on the performance of the PhysVLM model. Specifically, it examines the effect of removing ’temporal hacking’, ‘spatial hacking’, and ‘meta-info hacking’ during the generation of the PhysDPO dataset. The results show the average accuracy of the model on the PhysGame benchmark with each of these augmentations removed, revealing the relative contribution of each technique to overall model performance.
read the caption
Table 7: Ablation studies of the temporal, spatial, and meta-info hacking in the PhysDPO dataset generation process.

🔼 The figure shows a qualitative comparison of three different video LLMs (PhysVLM, GPT-4, and LLaVA-Next-Video) in identifying visual glitches in gameplay videos. The left column shows a sequence of frames from a gameplay video, while the right column shows the captions generated by the respective models, describing the glitches or physical commonsense violations identified in the video. The specific example focuses on a scenario involving a motorcycle colliding with a car, which is followed by the car flying unrealistically into the air. The models vary significantly in their ability to detect and describe the physics-related issues.
read the caption
(a)

🔼 The figure shows qualitative examples of open-ended questions in the PhysGame benchmark. PhysGame uses both open-ended and multiple-choice questions to assess the understanding of physical common sense violations in gameplay videos. In this particular example (b), the questions ask about the physical commonsense violations shown in gameplay video clips. The answers from three video LLMs (PhysVLM, GPT-40, and LLaVA-Next-Video) are provided for comparison, highlighting differences in their abilities to detect and describe these violations.
read the caption
(b)

🔼 Figure 5 presents two examples showcasing open-ended questioning in the PhysGame benchmark. Each example displays a gameplay video clip with a physics glitch, followed by responses from three different video LLMs: PhysVLM, GPT-40, and LLaVA-Next-Video. The responses illustrate the varying capabilities of these models in identifying and describing the specific nature of the physical commonsense violations present in the video clips. This highlights the nuanced challenges in evaluating physical reasoning within video LLMs.
read the caption
Figure 5: Qualitative examples of open-ended questions.

🔼 The figure shows a comparison of three different Video LLMs’ responses to a gameplay video glitch. The video depicts a motorcycle colliding with a car, causing the car to flip unrealistically. PhysVLM correctly identifies the physical commonsense violation, whereas GPT-4 and LLaVA-Next-Video fail to do so, highlighting the limitations of current video LLMs in understanding physics.
read the caption
(a)

🔼 The figure shows qualitative examples of open-ended questions for evaluating video LLMs’ understanding of physical commonsense. It presents two videos and their corresponding answers from three different video LLMs: PhysVLM, GPT-40, and LLaVA-Next-Video. The responses highlight how each model interprets and explains the physical glitches or inconsistencies present in the gameplay videos. In (b), the video involves a character’s transition from a dark area to a sunlit one, causing issues with shadow and lighting consistency. PhysVLM correctly points out the lighting inconsistencies, GPT-40 identifies a more generic game bug (the character is resetting to a previous position), and LLaVA-Next-Video highlights a jerky movement as the glitch.
read the caption
(b)
More on tables
| Benchmarks | Vid-Bsd | Instruct | MModal |
|---|---|---|---|
| GameBunny [107] | ✗ | ✓ | ✓ |
| Taesiri et.al [109] | ✓ | ✗ | ✓ |
| GameBugDescript [110] | ✓ | ✓ | ✗ |
| GlitchBench [111] | ✗ | ✓ | ✓ |
| PhysGame (Ours) | ✓ | ✓ | ✓ |
🔼 This table compares several existing benchmarks for evaluating video large language models (LLMs) specifically in the context of gameplay videos. It focuses on three key aspects: whether the benchmark uses video data (Vid-Bsd), if the evaluation tasks are presented in an instructional format (Instruct), and if the benchmark supports the evaluation of multi-modal models (MModal). This allows for a clearer understanding of how these benchmarks differ in their approach and capabilities and the types of LLMs they are designed to assess.
read the caption
Table 2: Comparison with existing gameplay video benchmarks in terms of whether they are video-based (Vid-Bsd), whether they follow an instructional format (Instruct), and support multi-modal evaluations (MModal).
| Opt. A | Opt. B | Opt. C | Opt. D | |
|---|---|---|---|---|
| Avg. tokens | 14.40 | 14.49 | 14.46 | 14.47 |
🔼 This table presents the average number of tokens (words or sub-words) across the four answer choices for each multiple-choice question in the PhysGame benchmark. It indicates the length of the distractor options relative to the correct option, helping to ensure the quality of the distractor options and mitigate any bias introduced by length differences.
read the caption
Table 3: The average tokens of four options in the annotations of PhysGame benchmark.
| Models | Citation | AVG | Mechanics | Kinematics | Optics | Material | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grav. | Elast. | Fric. | Velo. | Acc. | Refl. | Refr. | Abs. | Col. | Rig. | Sha. | Gest. | |||
| — | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| Proprietary Multi-modal LLMs | ||||||||||||||
| Claude3.5-Sonnet | [4] | 54.3 | 50.7 | 58.8 | 50.6 | 53.2 | 59.1 | 50.0 | 50.0 | 49.2 | 64.4 | 52.7 | 50.0 | 62.1 |
| Claude3.5-SonnetV2 | [4] | 47.6 | 46.5 | 52.5 | 46.6 | 37.2 | 53.4 | 47.8 | 50.0 | 33.9 | 55.6 | 54.1 | 43.8 | 51.7 |
| Gemini-1.5-pro | [114] | 55.2 | 50.7 | 70.0 | 48.9 | 51.1 | 59.1 | 50.0 | 42.9 | 52.5 | 71.1 | 56.8 | 53.1 | 58.6 |
| Gemini-1.5-pro-flash | [114] | 48.5 | 47.9 | 52.5 | 51.7 | 43.6 | 51.1 | 43.5 | 53.6 | 33.9 | 64.4 | 43.2 | 46.9 | 49.4 |
| GPT-4V | [1] | 45.9 | 40.8 | 60.0 | 48.3 | 34.0 | 48.9 | 43.5 | 46.4 | 42.4 | 53.3 | 45.9 | 37.5 | 44.8 |
| GPT-4o-0806 | [92] | 56.1 | 47.9 | 61.3 | 59.1 | 43.6 | 61.4 | 43.5 | 53.6 | 50.8 | 68.9 | 54.1 | 65.6 | 63.2 |
| GPT-4o-mini-0718 | [92] | 40.3 | 43.7 | 43.8 | 39.2 | 35.1 | 44.3 | 30.4 | 46.4 | 42.4 | 44.4 | 37.8 | 37.5 | 41.4 |
| Qwen-VL-max | [6] | 50.9 | 50.7 | 53.8 | 51.1 | 31.9 | 46.6 | 50.0 | 60.7 | 50.8 | 64.4 | 48.6 | 65.6 | 59.8 |
| Open-source Multi-modal LLMs | ||||||||||||||
| LLaVA-Next-Video | [72] | 32.2 | 43.7 | 33.8 | 27.3 | 34.0 | 22.7 | 21.7 | 35.7 | 23.7 | 35.6 | 41.9 | 34.4 | 37.9 |
| Video-LLaVA | [68] | 29.0 | 32.4 | 22.5 | 27.8 | 31.9 | 26.1 | 19.6 | 35.7 | 32.2 | 31.1 | 36.5 | 28.1 | 27.6 |
| LLaVA-OneVision | [58] | 47.7 | 50.7 | 50.0 | 46.0 | 39.4 | 45.5 | 43.5 | 71.4 | 40.7 | 55.6 | 44.6 | 56.2 | 52.9 |
| InternVL2 | [29] | 33.4 | 29.6 | 31.2 | 38.6 | 35.1 | 30.7 | 30.4 | 53.6 | 35.6 | 26.7 | 29.7 | 18.8 | 34.5 |
| VideoChat2 | [64] | 34.3 | 33.8 | 35.0 | 29.5 | 41.5 | 28.4 | 28.3 | 32.1 | 33.9 | 33.3 | 41.9 | 21.9 | 44.8 |
| ST-LLM | [77] | 32.8 | 32.4 | 26.2 | 26.7 | 37.2 | 28.4 | 37.0 | 25.0 | 28.8 | 33.3 | 40.5 | 37.5 | 46.0 |
| Chat-UniVi | [54] | 29.5 | 28.2 | 27.5 | 29.5 | 39.4 | 23.9 | 28.3 | 32.1 | 30.5 | 31.1 | 18.9 | 28.1 | 35.6 |
| PPLLaVA | [78] | 38.4 | 45.1 | 38.8 | 42.6 | 30.9 | 30.7 | 41.3 | 39.3 | 35.6 | 44.4 | 39.2 | 18.8 | 43.7 |
| PhysVLM-SFT | 56.7 | 54.9 | 62.5 | 60.2 | 51.1 | 63.6 | 45.7 | 57.1 | 28.8 | 64.4 | 51.4 | 50.0 | 72.4 | |
| PhysVLM-DPO | 59.5 | 64.8 | 66.3 | 60.2 | 59.6 | 60.2 | 39.1 | 67.9 | 35.6 | 57.8 | 62.2 | 37.5 | 78.2 |
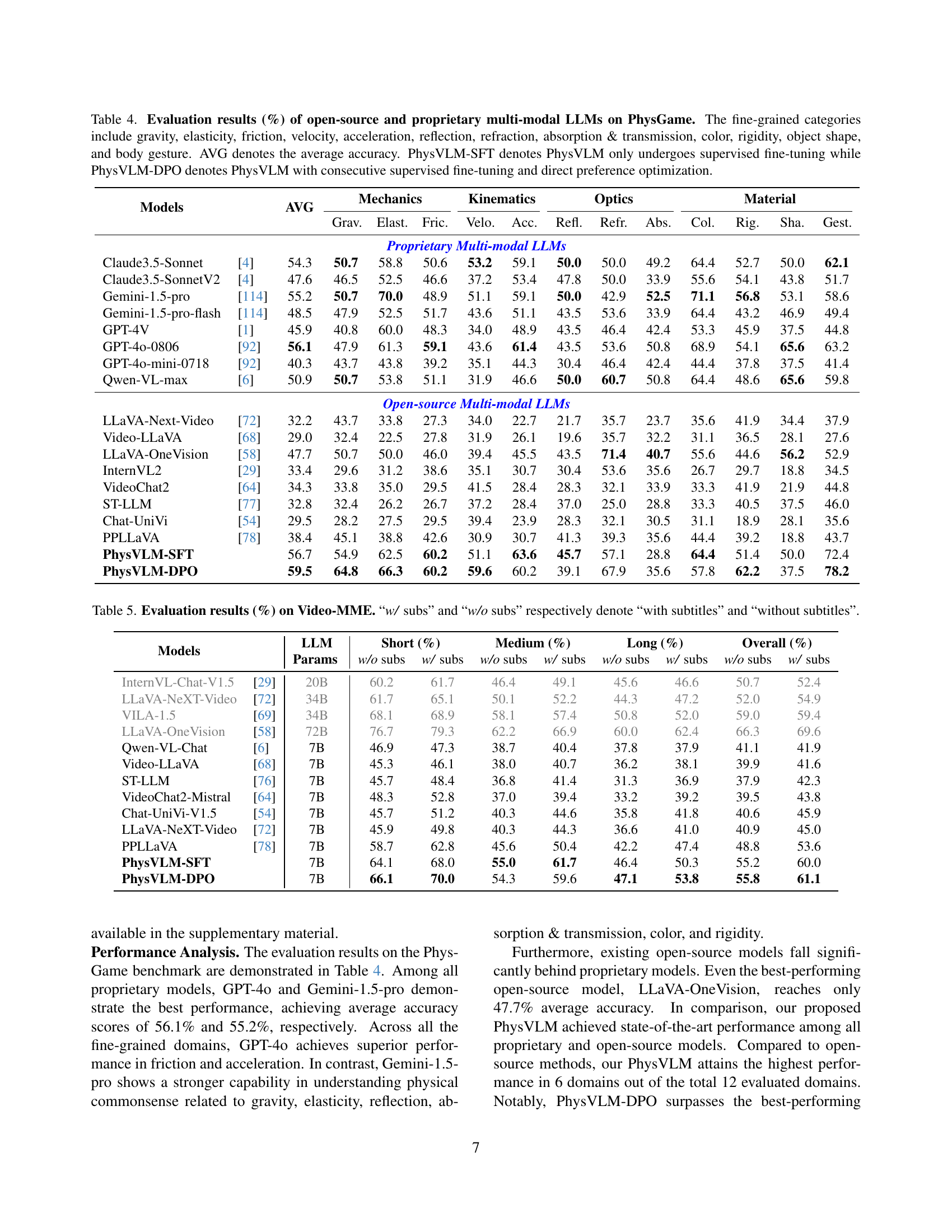
🔼 Table 4 presents a detailed comparison of the performance of various open-source and proprietary Large Language Models (LLMs) on the PhysGame benchmark. PhysGame assesses the ability of LLMs to identify and understand violations of physical common sense within gameplay videos. The table breaks down the results by several fine-grained subcategories of physics (gravity, elasticity, friction, velocity, acceleration, reflection, refraction, absorption & transmission, color, rigidity, object shape, and body gesture), providing a granular view of each model’s strengths and weaknesses. It also shows the overall average accuracy for each model and distinguishes between two versions of the PhysVLM model: one trained with supervised fine-tuning only (PhysVLM-SFT) and another trained with both supervised fine-tuning and direct preference optimization (PhysVLM-DPO). This allows for a direct comparison of the impact of the more advanced training technique on performance.
read the caption
Table 4: Evaluation results (%) of open-source and proprietary multi-modal LLMs on PhysGame. The fine-grained categories include gravity, elasticity, friction, velocity, acceleration, reflection, refraction, absorption & transmission, color, rigidity, object shape, and body gesture. AVG denotes the average accuracy. PhysVLM-SFT denotes PhysVLM only undergoes supervised fine-tuning while PhysVLM-DPO denotes PhysVLM with consecutive supervised fine-tuning and direct preference optimization.
| Models | LLM Params | Short (%) | Medium (%) | Long (%) | Overall (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| InternVL-Chat-V1.5 | [29] | 20B | 60.2 | 61.7 | 46.4 | 49.1 | 45.6 | 46.6 | 50.7 | 52.4 |
| LLaVA-NeXT-Video | [72] | 34B | 61.7 | 65.1 | 50.1 | 52.2 | 44.3 | 47.2 | 52.0 | 54.9 |
| VILA-1.5 | [69] | 34B | 68.1 | 68.9 | 58.1 | 57.4 | 50.8 | 52.0 | 59.0 | 59.4 |
| LLaVA-OneVision | [58] | 72B | 76.7 | 79.3 | 62.2 | 66.9 | 60.0 | 62.4 | 66.3 | 69.6 |
| Qwen-VL-Chat | [6] | 7B | 46.9 | 47.3 | 38.7 | 40.4 | 37.8 | 37.9 | 41.1 | 41.9 |
| Video-LLaVA | [68] | 7B | 45.3 | 46.1 | 38.0 | 40.7 | 36.2 | 38.1 | 39.9 | 41.6 |
| ST-LLM | [76] | 7B | 45.7 | 48.4 | 36.8 | 41.4 | 31.3 | 36.9 | 37.9 | 42.3 |
| VideoChat2-Mistral | [64] | 7B | 48.3 | 52.8 | 37.0 | 39.4 | 33.2 | 39.2 | 39.5 | 43.8 |
| Chat-UniVi-V1.5 | [54] | 7B | 45.7 | 51.2 | 40.3 | 44.6 | 35.8 | 41.8 | 40.6 | 45.9 |
| LLaVA-NeXT-Video | [72] | 7B | 45.9 | 49.8 | 40.3 | 44.3 | 36.6 | 41.0 | 40.9 | 45.0 |
| PPLLaVA | [78] | 7B | 58.7 | 62.8 | 45.6 | 50.4 | 42.2 | 47.4 | 48.8 | 53.6 |
| PhysVLM-SFT | 7B | 64.1 | 68.0 | 55.0 | 61.7 | 46.4 | 50.3 | 55.2 | 60.0 | |
| PhysVLM-DPO | 7B | 66.1 | 70.0 | 54.3 | 59.6 | 47.1 | 53.8 | 55.8 | 61.1 |
🔼 This table presents the performance comparison of various Large Language Models (LLMs) on the Video Multimodal Entailment (Video-MME) benchmark. The benchmark assesses the ability of LLMs to understand and reason about video content. The table shows the performance scores (in percentages) for each LLM, categorized by video length (short, medium, long), and whether subtitles were used. Higher percentages indicate better performance. The results are broken down into ‘with subtitles’ and ‘without subtitles’ to show the impact of textual information on the models’ video comprehension abilities.
read the caption
Table 5: Evaluation results (%) on Video-MME. “w/ subs” and “w/o subs” respectively denote “with subtitles” and “without subtitles”.
| Methods | CI | DO | CU | TU | CO | AVG |
|---|---|---|---|---|---|---|
| VideoChat | 2.23 | 2.50 | 2.53 | 1.94 | 2.24 | 2.29 |
| Video-ChatGPT | 2.50 | 2.57 | 2.69 | 2.16 | 2.20 | 2.42 |
| BT-Adapter | 2.68 | 2.69 | 3.27 | 2.34 | 2.46 | 2.69 |
| Chat-UniVi | 2.89 | 2.91 | 3.46 | 2.89 | 2.81 | 2.99 |
| VideoChat2 | 3.02 | 2.88 | 3.51 | 2.66 | 2.81 | 2.98 |
| LLaMA-VID | 2.96 | 3.00 | 3.53 | 2.46 | 2.51 | 2.89 |
| ST-LLM | 3.23 | 3.05 | 3.74 | 2.93 | 2.81 | 3.15 |
| PLLaVA | 3.21 | 2.86 | 3.62 | 2.33 | 2.93 | 2.99 |
| LLaVA-Next-Video | 3.39 | 3.29 | 3.92 | 2.60 | 3.12 | 3.26 |
| PPLLaVA | 3.32 | 3.20 | 3.88 | 3.00 | 3.20 | 3.32 |
| PhysVLM-SFT | 3.59 | 3.07 | 3.89 | 2.74 | 3.44 | 3.35 |
| LLaVA-Next-Video* | 3.64 | 3.45 | 4.17 | 2.95 | 4.08 | 3.66 |
| PPLLaVA* | 3.85 | 3.56 | 4.21 | 3.21 | 3.81 | 3.73 |
| PhysVLM-DPO* | 3.89 | 3.69 | 4.26 | 3.11 | 4.19 | 3.83 |
🔼 Table 6 presents a comprehensive evaluation of various video LLMs on the VCG benchmark [83], focusing on several key aspects of video understanding. The benchmark assesses the models’ capabilities across five dimensions: Correctness of Information (CI), Detail Orientation (DO), Contextual Understanding (CU), Temporal Understanding (TU), and Consistency (CO). The table shows the individual scores for each model and metric, along with an overall average (AVG) score. The models marked with an asterisk (*) utilize either Direct Preference Optimization (DPO) or Proximal Policy Optimization (PPO) [104], which are advanced training techniques aimed at improving model performance. This allows for comparison of models trained using traditional methods versus those employing more advanced techniques.
read the caption
Table 6: Evaluation results on VCG benchmark [83]. Methods marked by ∗ use DPO or PPO [104]. CI, DO, CU, TU, and CO respectively denote correctness of information, detail orientation, contextual understanding, temporal understanding, and consistency. AVG is the average result.
| Methods | AVG |
|---|---|
| PhysVLM-DPO | 59.5 |
| w/o temporal hacking | 57.6 |
| w/o spatial hacking | 57.3 |
| w/o meta-info hacking | 57.4 |
🔼 This table presents the results of ablation studies on the training data used for the PhysVLM model. It shows the impact of different training datasets on the model’s performance, measured by average accuracy on the PhysGame benchmark. Specifically, it compares the performance when using only LLaVA-Hound data, LLaVA-Hound and LLaVA-Image data, and the full dataset including PhysInstruct. The impact of using only LLaVA-Hound-DPO and the full dataset including PhysDPO is also analyzed in the DPO stage. This table helps to understand the contribution of each dataset to the overall model performance.
read the caption
Table 8: Ablations of training data in SFT and DPO stages. AVG denotes the average accuracy on the PhysGame benchmark.
| Stage | Training Data | AVG |
|---|---|---|
| SFT | LLava-Hound | 40.7 |
| SFT | LLava-Hound [142], LLaVA-Image [73] | 46.0 |
| SFT | LLava-Hound, LLaVA-Image, PhysInstruct | 56.7 |
| DPO | LLava-Hound-DPO [142] | 52.9 |
| DPO | LLava-Hound-DPO, PhysDPO | 59.5 |
🔼 This table presents the results of ablation studies conducted to analyze the impact of hyperparameters used in generating the PhysDPO dataset. Specifically, it examines how variations in the number of sampled frames (N) during temporal hacking and the frame resolution scale factor (γ) during spatial hacking affect the overall performance. The table helps determine the optimal settings for these hyperparameters to ensure the effectiveness of the PhysDPO dataset in improving the model’s understanding of physical commonsense.
read the caption
Table 9: Hyper-parameter ablations of (a) the sampled frame number N𝑁Nitalic_N in temporal hacking and (b) the frame resolution scale factor γ𝛾\gammaitalic_γ in spatial hacking for PhysDPO construction.
| N | 1 | 2 | 4 |
|---|---|---|---|
| AVG | 59.5 | 58.1 | 57.8 |
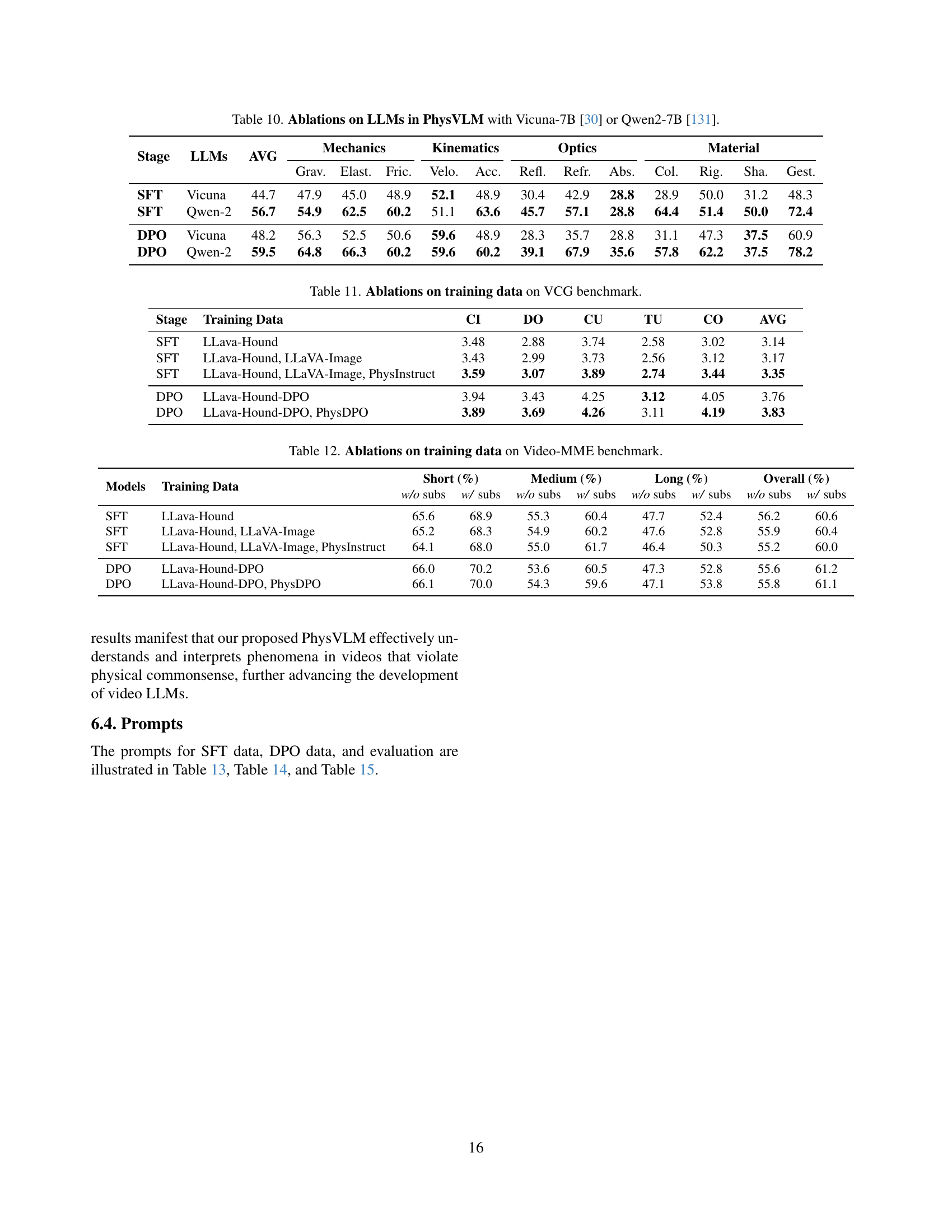
🔼 This table presents the ablation study results comparing the performance of PhysVLM when using either Vicuna-7B or Qwen-2-7B as the underlying large language model. It shows the average accuracy and the performance across different fine-grained categories within four main physical domains (Mechanics, Kinematics, Optics, and Material) for both supervised fine-tuning (SFT) and direct preference optimization (DPO) stages. This allows for a detailed assessment of the impact of the LLM choice on the model’s ability to understand physical common sense.
read the caption
Table 10: Ablations on LLMs in PhysVLM with Vicuna-7B [30] or Qwen2-7B [131].
| 1/8 | 1/16 | 1/32 | |
|---|---|---|---|
| γ | 57.1 | 59.5 | 58.6 |
🔼 This table presents ablation study results on the VCG benchmark, evaluating the impact of different training data combinations on the model’s performance. It shows the average scores and individual scores across five sub-categories (correctness of information, detail orientation, contextual understanding, temporal understanding, and consistency) for various training data setups. The setups include training with only LLaVA-Hound data, adding LLaVA-Image data, further adding the PhysInstruct dataset (for supervised fine-tuning), adding LLaVA-Hound-DPO data (for direct preference optimization), and finally adding both the PhysInstruct and PhysDPO datasets.
read the caption
Table 11: Ablations on training data on VCG benchmark.
| Stage | LLMs | AVG | Mechanics | Mechanics | Mechanics | Kinematics | Kinematics | Optics | Optics | Optics | Material | Material | Material | Material |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grav. | Elast. | Fric. | Velo. | Acc. | Refl. | Refr. | Abs. | Col. | Rig. | Sha. | Gest. | |||
| SFT | Vicuna | 44.7 | 47.9 | 45.0 | 48.9 | 52.1 | 48.9 | 30.4 | 42.9 | 28.8 | 28.9 | 50.0 | 31.2 | 48.3 |
| SFT | Qwen-2 | 56.7 | 54.9 | 62.5 | 60.2 | 51.1 | 63.6 | 45.7 | 57.1 | 28.8 | 64.4 | 51.4 | 50.0 | 72.4 |
| DPO | Vicuna | 48.2 | 56.3 | 52.5 | 50.6 | 59.6 | 48.9 | 28.3 | 35.7 | 28.8 | 31.1 | 47.3 | 37.5 | 60.9 |
| DPO | Qwen-2 | 59.5 | 64.8 | 66.3 | 60.2 | 59.6 | 60.2 | 39.1 | 67.9 | 35.6 | 57.8 | 62.2 | 37.5 | 78.2 |
🔼 This table presents the ablation study results on the Video-MME benchmark, showing the impact of different training data combinations on the model’s performance. It breaks down the results by video length (short, medium, long) and indicates whether subtitles were used. The table helps to understand the contribution of each dataset to the overall performance of the model on Video-MME.
read the caption
Table 12: Ablations on training data on Video-MME benchmark.
| Stage | Training Data | CI | DO | CU | TU | CO | AVG |
|---|---|---|---|---|---|---|---|
| SFT | LLava-Hound | 3.48 | 2.88 | 3.74 | 2.58 | 3.02 | 3.14 |
| SFT | LLava-Hound, LLaVA-Image | 3.43 | 2.99 | 3.73 | 2.56 | 3.12 | 3.17 |
| SFT | LLava-Hound, LLaVA-Image, PhysInstruct | 3.59 | 3.07 | 3.89 | 2.74 | 3.44 | 3.35 |
| DPO | LLava-Hound-DPO | 3.94 | 3.43 | 4.25 | 3.12 | 4.05 | 3.76 |
| DPO | LLava-Hound-DPO, PhysDPO | 3.89 | 3.69 | 4.26 | 3.11 | 4.19 | 3.83 |
🔼 This table details the prompt template used to generate the instruction-tuning dataset, PhysInstruct. The prompt instructs an AI to act as a visual assistant, analyzing a video and its title (which may or may not be accurate). The AI should identify and describe any violations of physics in the video, creating a conversational exchange between the AI and a user. The AI is explicitly told to base its analysis on its own observations and understanding of the video, not relying on the accuracy of the provided title. All descriptions must be at the video level, not referencing individual images or frames.
read the caption
Table 13: Prompt for instruction-tuning data generation in PhysInstruct.
| Models | Training Data | Short (%) w/o subs | Short (%) w/ subs | Medium (%) w/o subs | Medium (%) w/ subs | Long (%) w/o subs | Long (%) w/ subs | Overall (%) w/o subs | Overall (%) w/ subs |
|---|---|---|---|---|---|---|---|---|---|
| SFT | LLava-Hound | 65.6 | 68.9 | 55.3 | 60.4 | 47.7 | 52.4 | 56.2 | 60.6 |
| SFT | LLava-Hound, LLaVA-Image | 65.2 | 68.3 | 54.9 | 60.2 | 47.6 | 52.8 | 55.9 | 60.4 |
| SFT | LLava-Hound, LLaVA-Image, PhysInstruct | 64.1 | 68.0 | 55.0 | 61.7 | 46.4 | 50.3 | 55.2 | 60.0 |
| DPO | LLava-Hound-DPO | 66.0 | 70.2 | 53.6 | 60.5 | 47.3 | 52.8 | 55.6 | 61.2 |
| DPO | LLava-Hound-DPO, PhysDPO | 66.1 | 70.0 | 54.3 | 59.6 | 47.1 | 53.8 | 55.8 | 61.1 |
🔼 This table presents the prompt used for generating responses in the PhysDPO dataset. PhysDPO uses a technique called ‘direct preference optimization’ where it needs both preferred and dispreferred responses for training. To create the dispreferred responses, misleading information is given. Specifically, a false title is randomly selected from other videos in the dataset, and then this misleading title is combined with the question from the PhysInstruct dataset. This table shows exactly the structure of the prompt given to the model in this process, to create the less desirable answers.
read the caption
Table 14: Prompt for response generation in PhysDPO. The false_title is randomly selected from the other videos and the question is instantiated by the same instruction in PhysInstruct.
Full paper#