TL;DR#
Current image generation models often struggle with in-context learning due to the complexity of handling images and text simultaneously. Diffusion models, while dominant, are less adaptable to this in-context learning setting. Autoregressive models offer a potential solution, but their ability to handle long context sequences is limited, hindering their effectiveness. Furthermore, existing methods often involve significant information loss during image compression, impacting the quality of generated images.
The paper introduces X-Prompt to address these challenges. X-Prompt is a novel autoregressive vision-language model designed for efficient in-context image generation. It incorporates a specialized mechanism to compress information from in-context examples, supporting longer sequences and improved generalization. A unified training task for text and image prediction enhances the model’s awareness of different tasks, leading to superior performance across various image generation tasks and the ability to generalize to unseen tasks. Extensive experiments demonstrate significant improvements over existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances in-context learning for image generation. It addresses limitations of existing methods by introducing a novel compression technique and unified training framework, enabling more efficient and effective multi-modal image generation across diverse tasks. This opens new avenues for research in autoregressive vision-language models and multi-modal in-context learning, paving the way for more versatile and powerful AI systems.
Visual Insights#

🔼 Figure 1 showcases X-Prompt’s ability to generate diverse image outputs based on multi-modal in-context learning. The figure presents several examples of image generation tasks, each with an in-context prompt including example image pairs. X-Prompt processes these examples and the input prompt to produce a new image that reflects the instructions, showing its capacity for complex multi-modal generation and in-context learning in a purely auto-regressive framework.
read the caption
Figure 1: X-Prompt can perform multi-modal generation based on in-content examples in a pure auto-regressive foundation model.
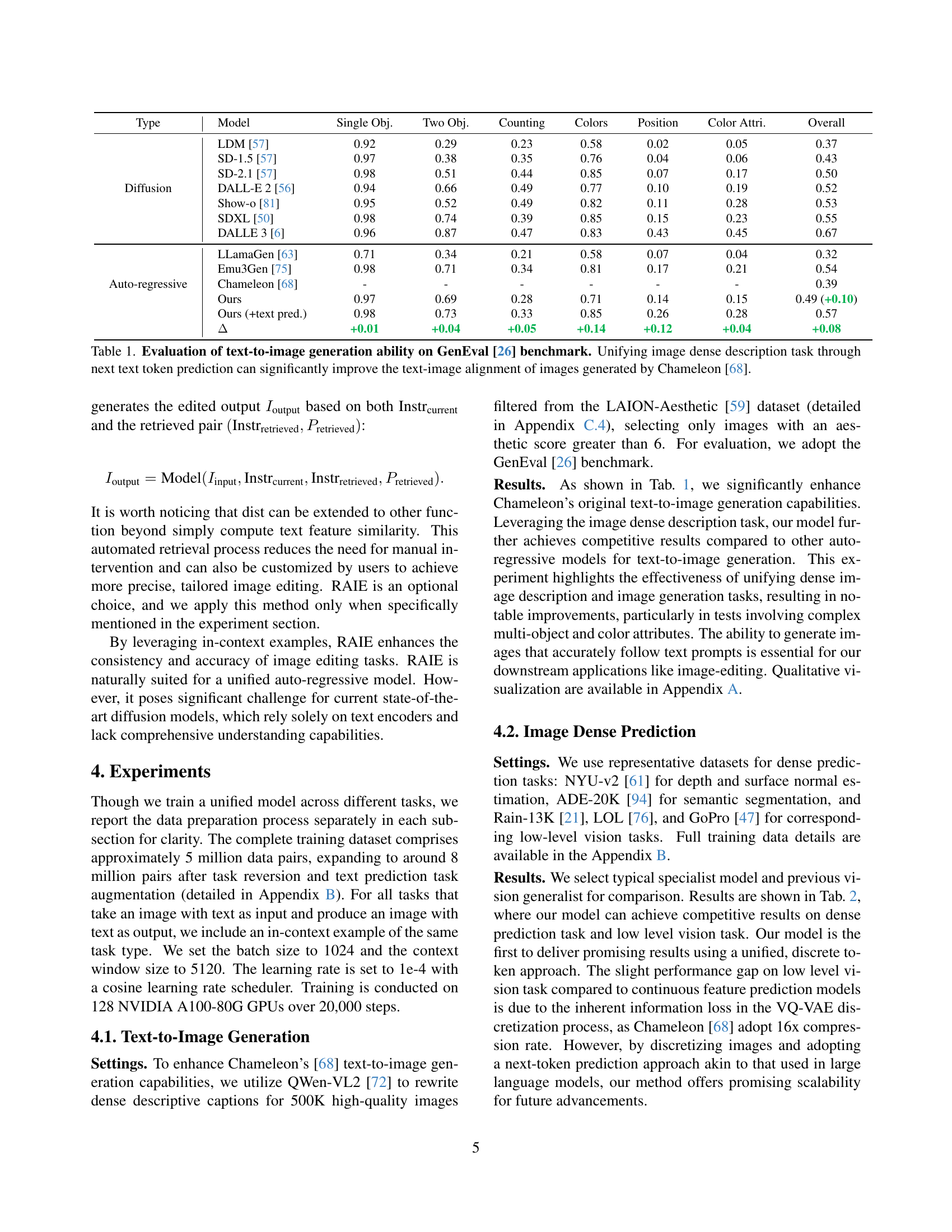
| Type | Model | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attri. | Overall |
|---|---|---|---|---|---|---|---|---|
| Diffusion | LDM [57] | 0.92 | 0.29 | 0.23 | 0.58 | 0.02 | 0.05 | 0.37 |
| SD-1.5 [57] | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 | 0.43 | |
| SD-2.1 [57] | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 | 0.50 | |
| DALL-E 2 [56] | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 | 0.52 | |
| Show-o [81] | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 | |
| SDXL [50] | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | 0.55 | |
| DALLE 3 [6] | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 | 0.67 | |
| Auto-regressive | LLamaGen [63] | 0.71 | 0.34 | 0.21 | 0.58 | 0.07 | 0.04 | 0.32 |
| Emu3Gen [75] | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 | |
| Chameleon [68] | - | - | - | - | - | - | 0.39 | |
| Ours | 0.97 | 0.69 | 0.28 | 0.71 | 0.14 | 0.15 | 0.49 (+0.10) | |
| Ours (+text pred.) | 0.98 | 0.73 | 0.33 | 0.85 | 0.26 | 0.28 | 0.57 | |
| Δ | +0.01 | +0.04 | +0.05 | +0.14 | +0.12 | +0.04 | +0.08 |
🔼 Table 1 presents a quantitative comparison of the text-to-image generation capabilities of various models on the GenEval benchmark [26]. The table assesses performance across different aspects of image generation, including the accuracy of object depiction, color representation, and text-image alignment. A key focus is on the impact of incorporating an image dense description task through next token prediction within an autoregressive model architecture. The results highlight the substantial performance gains achieved by this method, particularly in improving the text-image alignment of images generated by the Chameleon [68] model.
read the caption
Table 1: Evaluation of text-to-image generation ability on GenEval [26] benchmark. Unifying image dense description task through next text token prediction can significantly improve the text-image alignment of images generated by Chameleon [68].
In-depth insights#
X-Prompt: In-Context Image Generation#
The concept of ‘X-Prompt: In-Context Image Generation’ presents a novel approach to image generation using auto-regressive vision-language models. It leverages the power of in-context learning, allowing the model to generate images based on a few example prompts rather than extensive training data. This is achieved through a specialized design that efficiently compresses information from in-context examples, enabling the model to handle longer sequences and generalize better to unseen tasks. A key innovation is the unified training task for both text and image prediction, which enhances task awareness and overall performance. X-Prompt addresses the challenge of prohibitive context length in traditional methods by compressing context examples, allowing for more effective utilization of in-context information during inference. The approach shows promising results across diverse tasks, including image editing and style transfer, demonstrating the potential for universal image generation capabilities within a unified framework.
Autoregressive VLM Design#
Autoregressive Vision Language Models (VLMs) represent a significant advancement in multimodal AI. Their autoregressive nature allows for sequential generation of both text and image tokens, enabling a unified framework for diverse tasks like image generation, editing, and captioning. Unlike diffusion models, which often require separate text encoders and diffusion networks, autoregressive VLMs offer simpler architectures that facilitate in-context learning. This design allows the model to learn from a few input examples and generalize to unseen tasks without extensive retraining. The unified text and image token prediction is crucial, as it allows the model to better understand the relationship between textual descriptions and visual features, leading to improved generation quality and better alignment between text and image content. A key challenge, however, lies in efficiently handling long sequences, as images require many tokens for representation. This necessitates the development of sophisticated methods to compress visual information and optimize model design for efficient in-context learning. Further research into improving compression techniques and exploring alternative model architectures will continue to drive progress in autoregressive VLM technology.
Unified Training Tasks#
The concept of “Unified Training Tasks” in the context of a vision-language model is crucial for improving performance and generalization. A unified approach means training the model on a diverse set of tasks (e.g., image generation, captioning, image editing) simultaneously, rather than training separate models for each. This strategy leverages the inherent relationships between these tasks, allowing the model to learn shared representations and transfer knowledge effectively. The benefits are multifold: Firstly, it reduces the need for large, task-specific datasets, resulting in increased efficiency and reduced computational cost. Secondly, a unified framework promotes better generalization, as the model learns to handle unseen tasks more effectively by leveraging its knowledge acquired from related tasks during training. This is particularly relevant to in-context learning, where the model should generalize to new inputs based on limited examples. A key design challenge lies in defining the optimal unified training objective. Finding the right balance between different tasks during training is critical. Too much emphasis on one task might hurt the overall performance on other tasks. The choice of loss function, weighting scheme, and data augmentation strategies play significant roles in effectively balancing the different tasks. Therefore, careful consideration of the task relationships, dataset characteristics, and model architecture is needed to achieve optimal results. Ultimately, a well-designed unified training pipeline is essential for creating robust and versatile vision-language models that excel in diverse in-context generation scenarios.
In-Context Compression#
The concept of ‘In-Context Compression’ in the context of large vision-language models addresses a critical challenge: the excessive length of contextual information needed during training for high-quality image generation. Standard approaches often struggle to handle this length, limiting the number of examples used and hindering generalization. In-context compression tackles this by efficiently distilling essential features from in-context examples into a compact representation, such as compressed tokens. This enables the model to leverage longer sequences of examples without exceeding memory constraints, thereby significantly enhancing its ability to generalize to unseen tasks and interpret complex multi-modal prompts. A unified training strategy further boosts performance, by integrating image generation and description tasks, fostering enhanced task awareness. This approach is particularly valuable when dealing with diverse image generation tasks (editing, composition, etc.), where a compact but rich representation of past examples is crucial for success.
Generalization Limits#
The inherent limitations in a model’s ability to generalize beyond its training data are crucial. In-context learning, while offering impressive few-shot capabilities, often struggles with truly unseen tasks. The length of the context window plays a significant role; longer sequences improve generalization but introduce computational and memory constraints. The diversity and quality of examples within the context window significantly influence performance. Poorly chosen examples or an insufficient number can hinder generalization. Furthermore, the model’s underlying architecture and training methodology heavily impact generalization capabilities. The ability of a model to abstract underlying patterns and transfer knowledge effectively is key, but this remains a significant challenge for many current models. Finally, the inherent complexity of the task itself can be a limiting factor. Tasks requiring high-level reasoning or fine-grained visual understanding may prove especially difficult for models to generalize to.
More visual insights#
More on figures
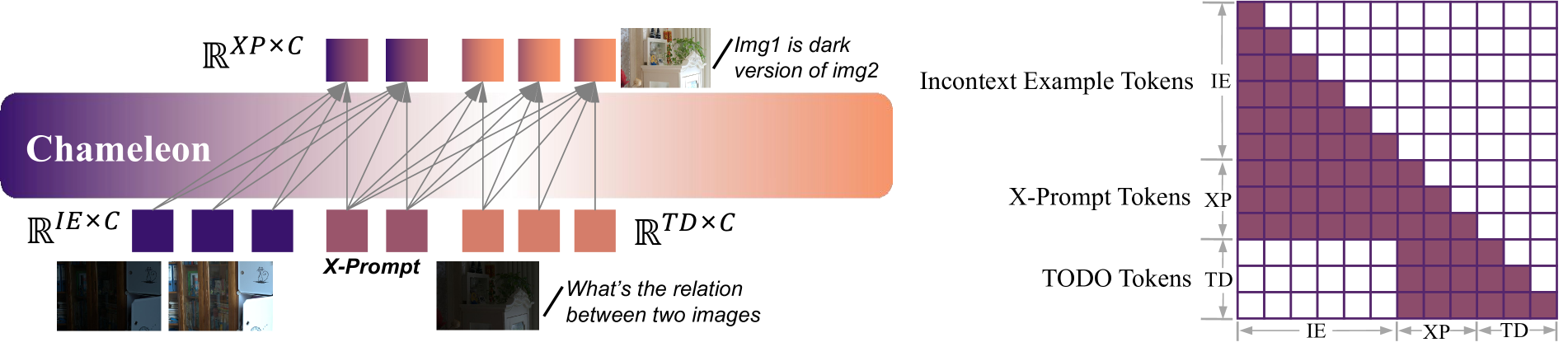
🔼 This figure illustrates the attention mechanism employed in X-Prompt. It shows how the model compresses contextual information from in-context examples into a fixed-length sequence of tokens (X-Prompt Tokens). The masking prevents direct interaction between the in-context examples (In-context Example Tokens) and the prediction target (TODO Tokens), forcing the model to rely on the compressed tokens for contextual information. This setup facilitates the unified training of text and image prediction, as well as the handling of longer in-context sequences, ultimately improving generalization to unseen tasks.
read the caption
Figure 2: Attention masking of X-Prompt for context feature compression and unified text and image next token prediction training.

🔼 This figure illustrates the data augmentation strategies and the task pipeline used in the training process. The left side shows how training data pairs are augmented by introducing reverse tasks and difference description tasks. A reverse task reverses the input and output images of a task, while a difference description task requires the model to describe the changes between input and output images using text. This augmentation is aimed at improving model performance and generalization. The right side of the figure details the prototype tasks and subtasks employed, which comprise image editing, controlled image generation, image composition, and low-level vision tasks. These varied tasks are integrated to allow the model to learn a broader range of image manipulation techniques.
read the caption
Figure 3: Training data pair augmentation and list of training prototype tasks and subtasks. We introduce reverse task and difference description task through next text token prediction to improve the performance and generalizibility.

🔼 Figure 4 presents a qualitative comparison of image editing results obtained using the X-Prompt model with and without in-context examples, evaluated on the MagicBrush [89] dataset. It visually demonstrates the model’s improved performance when provided with in-context examples, showcasing its ability to better understand and execute complex image editing tasks. The figure includes several image editing examples, each displaying the input image, the output generated by X-Prompt with context, the output of X-Prompt without context, and the ground truth. This allows for a direct visual comparison of the model’s performance under different conditions.
read the caption
Figure 4: Qualitative Results on MagicBrush [89] testset comparing with MagicBrush results w/ and w/o context examples.

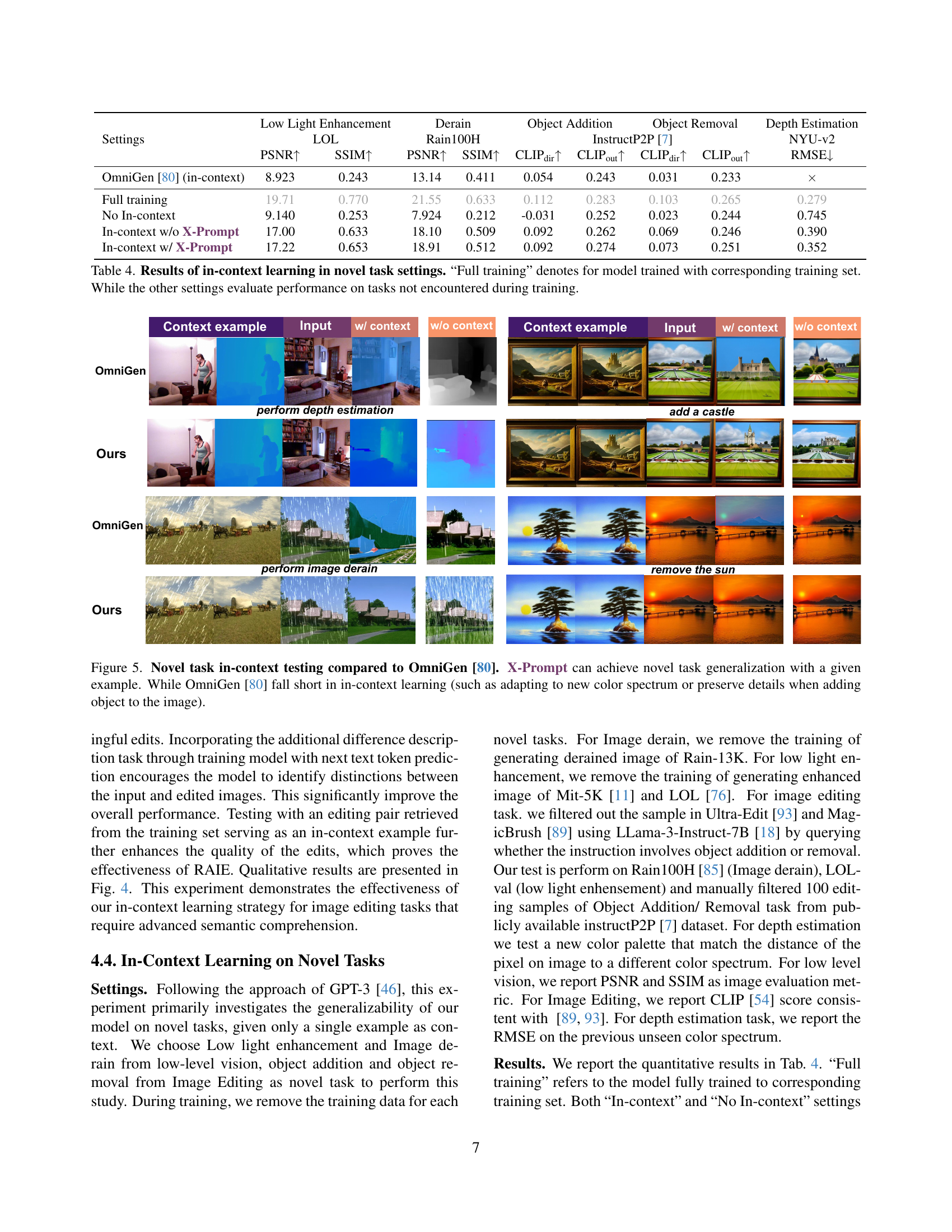
🔼 Figure 5 presents a comparison of X-Prompt and OmniGen [80] on novel, unseen tasks using in-context learning. X-Prompt demonstrates successful generalization to these new tasks, adapting to diverse requests like changing color palettes or adding details to images. Conversely, OmniGen shows limitations in in-context learning, struggling to handle requests requiring such adaptations.
read the caption
Figure 5: Novel task in-context testing compared to OmniGen [80]. X-Prompt can achieve novel task generalization with a given example. While OmniGen [80] fall short in in-context learning (such as adapting to new color spectrum or preserve details when adding object to the image).

🔼 This figure shows examples of X-Prompt’s ability to handle diverse contexts for image generation. The top row demonstrates style transfer, where the model applies a specific artistic style to an image based on a style example. The bottom row showcases action preservation; using an example image pair of a person performing an action, the model replicates that action with different characters, preserving the action while changing the character’s appearance.
read the caption
Figure 6: X-Prompt can support diversified context to achieve style personalization and action preservation.

🔼 Figure 7 showcases examples of high-quality images generated by the X-Prompt model. These images demonstrate the model’s ability to produce visually appealing and aesthetically pleasing results, highlighting its effectiveness in text-to-image generation. The model was trained on a subset of the LAION-Aesthetics dataset, which is known for its high-quality images, contributing to the model’s ability to generate similar high-quality outputs. The figure visually supports the claim that X-Prompt excels at producing aesthetically pleasing images, which is a key aspect of its superior performance in text-to-image generation.
read the caption
Figure 7: Qualitative results of text-to-image generation. High-quality text-to-image generation cases with high aesthetic qualities after training on Laion-Aesthetics [59].

🔼 Figure 8 showcases the model’s performance on diverse, low-level vision tasks. The top row displays semantic segmentation results where the model segments different objects within the image into distinct classes. The second row demonstrates normal estimation, predicting the surface normals at each pixel. The next rows illustrate the model’s ability to deblur, denoise, and derain images. For each task, the figure presents a comparison between the input image, the model’s output, and the ground truth. This provides a visual assessment of the model’s effectiveness in these tasks.
read the caption
Figure 8: Qualitative results of diversed tasks, such as semantic segmentation, norm estimation, image deblur, denoise and derain.

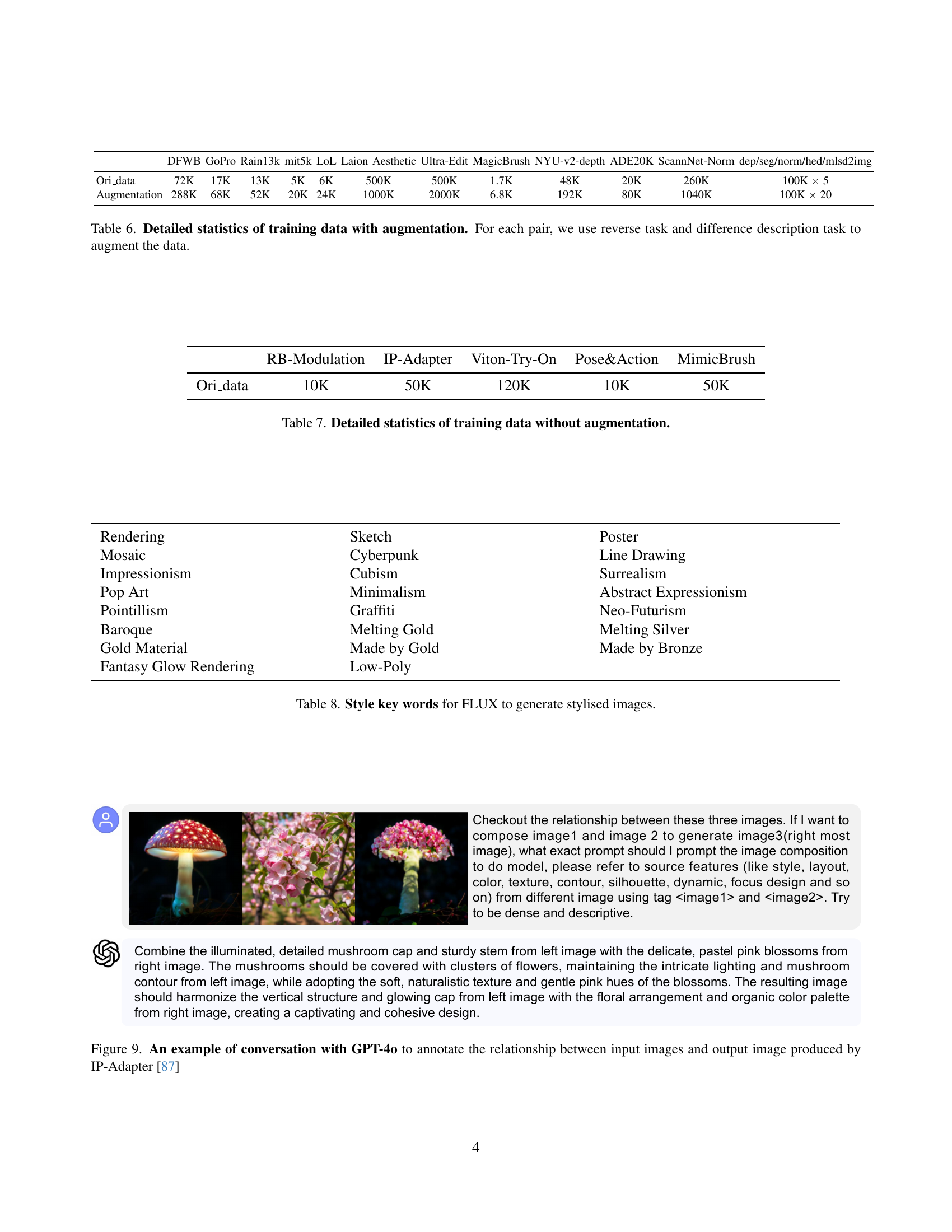
🔼 Figure 9 shows a conversation with GPT-4, a large language model, to describe the relationship between input and output images generated by the IP-Adapter model [87]. The IP-Adapter model combines two input images to create a new image. GPT-4 is used to provide a detailed textual description that explains how the features (style, layout, color, texture, etc.) from each of the input images are used and combined in the final output image. This detailed description serves as training data to enhance the model’s understanding of image manipulation tasks.
read the caption
Figure 9: An example of conversation with GPT-4o to annotate the relationship between input images and output image produced by IP-Adapter [87]

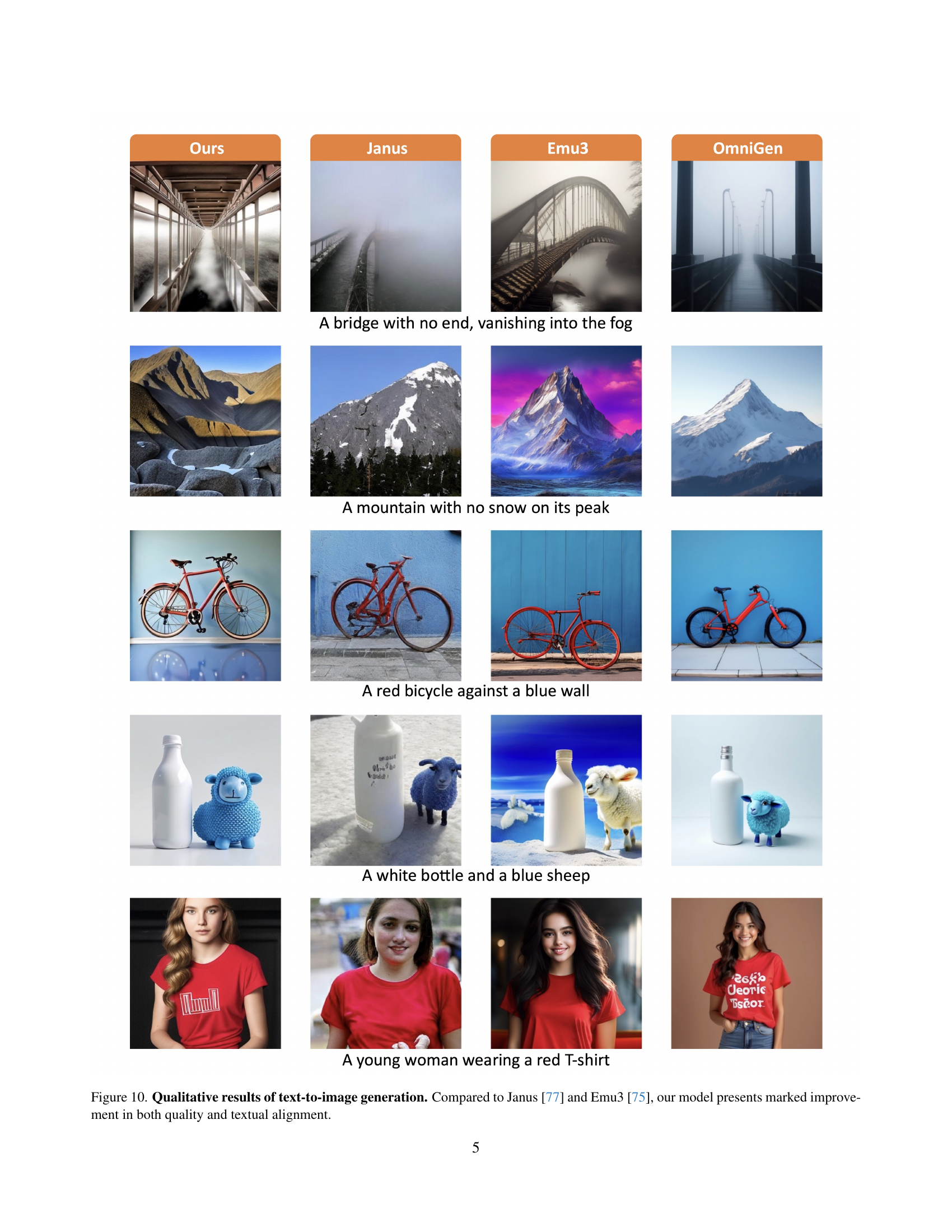
🔼 Figure 10 presents a qualitative comparison of text-to-image generation results between the proposed X-Prompt model and two existing models, Janus [77] and Emu3 [75]. For several prompts, the generated images from each model are displayed side-by-side. This allows for a visual assessment of the image quality and how well the generated images match the textual description in each prompt. The caption highlights that X-Prompt demonstrates superior performance in both the quality of the generated images and the alignment between the image content and the corresponding text prompt.
read the caption
Figure 10: Qualitative results of text-to-image generation. Compared to Janus [77] and Emu3 [75], our model presents marked improvement in both quality and textual alignment.
More on tables
| Type | Methods | Depth Est. (RMSE↓) | Semantic Seg. (mIoU↑) | Surface Normal Est. (Mean Angle Error↓) | Lowlight Enhans. (LOL) (PSNR↑) | Lowlight Enhans. (LOL) (SSIM↑) | Deblur (GoPro) (PSNR↑) | Deblur (GoPro) (SSIM↑) | Derain (Rain100L) (PSNR↑) | Derain (Rain100L) (SSIM↑) |
|---|---|---|---|---|---|---|---|---|---|---|
| Domain Specific Model | DepthAnything [83] | 0.206 | ||||||||
| Marigold [32] | 0.224 | |||||||||
| Mask DINO [36] | 60.80 | |||||||||
| Mask2Former [13] | 56.10 | |||||||||
| Bae et al. [3] | 14.90 | |||||||||
| InvPT [86] | 19.04 | |||||||||
| AirNet [35] | 18.18 | 0.735 | 24.35 | 0.781 | 32.98 | 0.951 | ||||
| InstructIR [15] | 23.00 | 0.836 | 29.40 | 0.886 | 36.84 | 0.937 | ||||
| Unified Model (continuous) | Painter [73] | 0.288 | 49.90 | × | 22.40 | 0.872 | × | × | 29.87 | 0.882 |
| InstructCV [22] | 0.297 | 47.23 | × | × | × | × | × | × | × | |
| InstructDiffusion [25] | × | × | × | × | × | 23.58 | - | 19.82 | 0.741 | |
| OmniGen [80] | 0.480 | × | × | 13.38 | 0.392 | 13.39 | 0.321 | 12.02 | 0.233 | |
| Unified Model (discrete) | Unified-IO [43] | 0.387 | 25.71 | - | × | × | × | × | × | × |
| Lumina-mGPT [41] | × | 20.87 | 22.10 | × | × | 17.59 | 0.536 | 16.61 | 0.365 | |
| Ours | 0.277 | 31.21 | 19.17 | 19.71 | 0.810 | 21.04 | 0.761 | 25.53 | 0.843 |
🔼 Table 2 presents a comparative analysis of X-Prompt against specialized models designed for individual tasks and general-purpose vision models. The comparison focuses on six representative tasks categorized into high-level visual understanding and low-level image processing. High-level tasks involve complex visual interpretations, while low-level tasks focus on fundamental image manipulations. The table highlights the performance of each model on each task, indicating whether a model could successfully complete the task or not using ‘×’ to represent failure.
read the caption
Table 2: Comparison of X-Prompt with task-specific and vision generalist baselines across six representative tasks, covering both high-level visual understanding and low-level image processing. ’×\times×’ indicates that the method is incapable of performing the task.
| Type | Methods | CLIPdir ↑ | CLIPout ↑ | CLIPimg ↑ | DINO ↑ |
|---|---|---|---|---|---|
| Continuous | InstructPix2Pix [7] | 0.081 | 0.276 | 0.852 | 0.750 |
| MagicBrush [89] | 0.106 | 0.278 | 0.933 | 0.899 | |
| UltraEdit [93] | 0.093 | 0.274 | 0.899 | 0.848 | |
| Discrete | Lumina-mGPT [41] | 0.025 | 0.253 | 0.810 | 0.751 |
| Ours (w/o text pred.) | 0.067 | 0.263 | 0.823 | 0.785 | |
| Ours (w/ text pred.) | 0.083 | 0.271 | 0.857 | 0.781 | |
| Ours + RAIE | 0.097 | 0.279 | 0.862 | 0.792 |
🔼 Table 3 presents a comparative analysis of various image editing methods using the MagicBrush [89] benchmark dataset. It showcases the performance of different models in terms of image editing quality, using metrics like CLIP direction and CLIP output, and CLIP image scores, alongside DINO scores. This allows for a quantitative assessment of how effectively each method executes the image editing tasks defined in the benchmark.
read the caption
Table 3: Image Editing Results. Comparison of different methods on the MagicBrush [89] testset.
| Settings | Low Light Enhancement | Derain | Object Addition | Object Removal | Depth Estimation | ||||
|---|---|---|---|---|---|---|---|---|---|
| LOL | Rain100H | InstructP2P [7] | NYU-v2 | ||||||
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | CLIPdir↑ | CLIPout↑ | CLIPdir↑ | CLIPout↑ | RMSE↓ | |
| OmniGen [80] (in-context) | 8.923 | 0.243 | 13.14 | 0.411 | 0.054 | 0.243 | 0.031 | 0.233 | × |
| Full training | 19.71 | 0.770 | 21.55 | 0.633 | 0.112 | 0.283 | 0.103 | 0.265 | 0.279 |
| No In-context | 9.140 | 0.253 | 7.924 | 0.212 | -0.031 | 0.252 | 0.023 | 0.244 | 0.745 |
| In-context w/o X-Prompt | 17.00 | 0.633 | 18.10 | 0.509 | 0.092 | 0.262 | 0.069 | 0.246 | 0.390 |
| In-context w/ X-Prompt | 17.22 | 0.653 | 18.91 | 0.512 | 0.092 | 0.274 | 0.073 | 0.251 | 0.352 |
🔼 Table 4 presents the results of an experiment on in-context learning using a model trained on a variety of image generation tasks. The table compares the model’s performance on novel tasks (tasks not seen during training) under different conditions: with full training data, with in-context examples (but without full training), and with in-context examples using the proposed X-Prompt method. This allows for evaluating the effectiveness of the in-context learning approach and the proposed X-Prompt enhancement on unseen tasks.
read the caption
Table 4: Results of in-context learning in novel task settings. “Full training” denotes for model trained with corresponding training set. While the other settings evaluate performance on tasks not encountered during training.
| Model | Resolution | PSNR | SSIM |
|---|---|---|---|
| SDXL-VAE (16x) | 512 | 27.51 | 0.810 |
| SDXL-VAE (16x) | 1024 | 32.13 | 0.922 |
| Chemeleon-VQVAE (16x) | 512 | 26.34 | 0.805 |
| Chemeleon-VQVAE (16x) | 1024 | 29.77 | 0.906 |
| Emu3-VQVAE (8x) | 512 | 27.78 | 0.833 |
🔼 Table 5 presents a comparison of image reconstruction quality using different models on the Rain-100L dataset. The table shows that increasing the input image resolution from 512x512 to 1024x1024 significantly improves the reconstruction quality, as measured by PSNR and SSIM scores. This improvement is attributed to the fact that higher resolutions provide more detail for the model to reconstruct, reducing information loss during compression. The table includes results from three autoregressive models and one diffusion model (SDXL-VAE).
read the caption
Table 5: Reconstruction quality tested on Rain-100L. Increasing resolution can greatly enhance reconstruction quality.
| DFWB | GoPro | Rain13k | mit5k | LoL | Laion_Aesthetic | Ultra-Edit | MagicBrush | NYU-v2-depth | ADE20K | ScannNet-Norm | dep/seg/norm/hed/mlsd2img | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ori_data | 72K | 17K | 13K | 5K | 6K | 500K | 500K | 1.7K | 48K | 20K | 260K | 100K × 5 |
| Augmentation | 288K | 68K | 52K | 20K | 24K | 1000K | 2000K | 6.8K | 192K | 80K | 1040K | 100K × 20 |
🔼 Table 6 presents a detailed breakdown of the training data used in the study, highlighting the impact of data augmentation techniques. It shows the original dataset sizes for various tasks (e.g., GoPro, Rain13K, etc.), then indicates how these were significantly expanded through data augmentation strategies. These strategies involved creating ‘reverse tasks’ (e.g., if the original task was removing rain, the reverse task would be adding rain) and generating descriptive text explaining the differences between input and output images for each task. The table provides a clear picture of the substantial increase in the training dataset size after incorporating these augmentation methods.
read the caption
Table 6: Detailed statistics of training data with augmentation. For each pair, we use reverse task and difference description task to augment the data.
| RB-Modulation | IP-Adapter | Viton-Try-On | Pose&Action | MimicBrush | |
|---|---|---|---|---|---|
| Ori_data | 10K | 50K | 120K | 10K | 50K |
🔼 Table 7 presents a detailed breakdown of the dataset used for training the model, specifically focusing on data without augmentation. It shows the original number of data points for each task before any data augmentation techniques were applied. This helps clarify the initial size of the training data used to establish the model’s foundation, separate from the effects of data augmentation.
read the caption
Table 7: Detailed statistics of training data without augmentation.
| Rendering | Sketch | Poster |
|---|---|---|
| Mosaic | Cyberpunk | Line Drawing |
| Impressionism | Cubism | Surrealism |
| Pop Art | Minimalism | Abstract Expressionism |
| Pointillism | Graffiti | Neo-Futurism |
| Baroque | Melting Gold | Melting Silver |
| Gold Material | Made by Gold | Made by Bronze |
| Fantasy Glow Rendering | Low-Poly |
🔼 This table lists keywords used as input prompts for the FLUX model to generate stylized images. These keywords represent various artistic styles, rendering techniques, and material properties to control the visual characteristics of the generated images.
read the caption
Table 8: Style key words for FLUX to generate stylised images.
Full paper#