↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Single-step diffusion models offer significant speed advantages but often compromise image quality. Existing methods struggle to match the fidelity of multi-step approaches, particularly in preserving fine details and ensuring global coherence. This paper addresses these issues by introducing a fundamentally different approach.
NitroFusion uses a dynamic adversarial framework with a pool of specialized discriminator heads, operating at different noise levels and spatial scales, to guide image generation. This approach mimics art critics providing diverse feedback, leading to high-quality images even with one step. It also introduces a strategic refresh mechanism and a multi-scale strategy to improve training stability and generation quality. The flexible deployment allows trade-offs between quality and speed, using 1-4 steps with the same model weights.
Key Takeaways#
Why does it matter?#
This paper is important because it presents NitroFusion, a novel approach to single-step diffusion models that significantly improves image quality. It addresses a critical limitation of existing single-step methods and opens new avenues for research in efficient and high-fidelity image generation, impacting various applications like real-time image synthesis.
Visual Insights#

🔼 This figure showcases the high-fidelity image generation capabilities of the NitroFusion model. It presents several example images produced by the one-step diffusion pipeline, demonstrating the model’s ability to generate vibrant and photorealistic images with exceptional detail in a single inference step. The improved efficiency and quality of the NitroFusion model is highlighted, expanding the potential of text-to-image synthesis for real-time applications.
read the caption
Figure 1: Our one-step diffusion pipeline generates vibrant and photorealistic images with exceptional detail in a single inference step, broadening the potential for text-to-image synthesis in applications like real-time interactive systems.
| Model | Steps (↓) | CLIP (↑) | FID (↓) | Aesthetic Score (↑) | Image Reward (↑) |
|---|---|---|---|---|---|
| SDXL-Base [34] | 25 | 0.320 | 23.30 | 5.58 | 0.782 |
| SDXL-Turbo [42] | 4 | 0.317 | 29.07 | 5.51 | 0.848 |
| SDXL-Lightning [23] | 4 | 0.312 | 28.95 | 5.75 | 0.749 |
| Hyper-SDXL [37] | 4 | 0.314 | 34.49 | 5.87 | 1.091 |
| DMD2 [52] | 4 | 0.316 | 24.57 | 5.54 | 0.880 |
| NitroSD-Realism | 4 | 0.313 | 29.09 | 5.60 | 0.945 |
| NitroSD-Vibrant | 4 | 0.312 | 39.76 | 5.85 | 1.034 |
| SDXL-Turbo [42] | 1 | 0.318 | 28.99 | 5.38 | 0.782 |
| SDXL-Lightning [23] | 1 | 0.313 | 29.23 | 5.65 | 0.557 |
| Hyper-SDXL [37] | 1 | 0.317 | 36.77 | 6.00 | 1.169 |
| DMD2 [52] | 1 | 0.320 | 23.91 | 5.47 | 0.825 |
| NitroSD-Realism | 1 | 0.320 | 25.61 | 5.56 | 0.856 |
| NitroSD-Vibrant | 1 | 0.314 | 38.49 | 5.92 | 0.991 |
🔼 This table presents a quantitative comparison of the proposed NitroFusion model against several state-of-the-art single-step and multi-step diffusion models. The comparison is based on multiple metrics, including CLIP score (measuring alignment between generated images and text prompts), FID (Fréchet Inception Distance, evaluating image quality and diversity), Aesthetic Score (based on user preferences), and ImageReward (also reflecting user preferences). Results are shown for both one-step and multi-step (2 and 4 steps) generation to illustrate the model’s performance at various speed-quality tradeoffs. The table allows for a direct assessment of NitroFusion’s relative strengths and weaknesses compared to competing approaches.
read the caption
Table 1: Quantitative Comparisons with State-of-the-Art Methods.
In-depth insights#
Dynamic Discriminator#
The concept of a “Dynamic Discriminator” in the context of single-step diffusion models represents a significant advancement in tackling the inherent challenges of compressing the entire denoising trajectory into a single step. Instead of a static discriminator, which can lead to overfitting and limited feedback, a dynamic approach introduces a pool of specialized discriminators. Each discriminator within this pool focuses on specific aspects of image quality at different noise levels, offering diverse and nuanced feedback. This strategy, inspired by the way a panel of art critics provide comprehensive feedback on different aspects of a painting, helps guide the generator towards higher-fidelity outputs. The dynamic nature of the discriminator pool is crucial, involving mechanisms for periodically refreshing the pool and preventing overfitting. This ensures the generator consistently receives diverse feedback across training and prevents it from stagnating. Overall, this technique is key to NitroFusion’s success in achieving high-fidelity single-step diffusion, addressing limitations found in previous single-step methods and bridging the quality gap between one-step and multi-step approaches.
Multi-Scale Training#
Multi-scale training in image generation models aims to improve the quality and detail of generated images by incorporating information from various spatial scales. By using discriminators that operate on both global (full image) and local (patch) levels, the model learns to balance high-level semantic understanding with low-level texture and detail. This approach addresses limitations of single-scale training, where the model might struggle to capture fine details while maintaining overall coherence. Global discriminators ensure the image is semantically sound and consistent, while local discriminators focus on fine-grained details and texture, preventing low-resolution artifacts. The dynamic combination of these perspectives helps the model achieve a higher level of visual fidelity, crucial for generating high-quality and visually appealing images. However, implementing such a system introduces new challenges like balancing the information from multiple scales and preventing overfitting or lack of diversity in the learned features. Careful design of the discriminators, appropriate loss functions, and training strategies are crucial for effective multi-scale training. Furthermore, efficient computation and memory management become critical when handling different resolutions simultaneously.
One-Step Distillation#
One-step distillation in diffusion models aims to drastically reduce the inference time by compressing the entire denoising process into a single step. This offers significant speed advantages over multi-step methods, crucial for real-time applications. However, the primary challenge lies in maintaining the high-fidelity image quality achieved by multi-step approaches. Existing methods often struggle with blurry outputs or loss of detail due to the difficulty of accurately approximating the complex multi-step trajectory in a single transformation. Adversarial approaches, while promising, can suffer from instability and a lack of diversity. Therefore, effective one-step distillation requires innovative techniques that carefully balance speed and quality, addressing the limitations of direct trajectory approximation and the inherent challenges of adversarial training. Key improvements could include more sophisticated distillation strategies, employing diverse discriminator architectures to guide the generation process more effectively and utilizing novel loss functions or training techniques to mitigate instability and promote better image quality.
Flexible Deployment#
The concept of “Flexible Deployment” in the context of a single-step diffusion model like NitroFusion is a significant advancement. It highlights the model’s ability to function effectively across varying computational budgets and desired image quality levels. Instead of requiring separate models for different numbers of denoising steps, NitroFusion allows users to dynamically adjust the number of steps (1-4) without retraining or loading different weights. This flexibility is crucial for real-world applications. Lower step counts prioritize speed, ideal for real-time or interactive systems, while increasing steps improves image quality, suiting applications needing high-fidelity results. This adaptability offers a significant advantage over traditional approaches that require distinct models optimized for a fixed number of steps, resulting in a more efficient and versatile system. The implementation likely involves a mechanism that cleverly manages the denoising process, allowing graceful scaling of computational resources according to the chosen number of refinement steps. This trade-off between speed and quality empowers users to tailor the model’s performance to their specific needs and resource constraints, making it a powerful and practical tool for various applications.
Future Directions#
Future research directions for single-step diffusion models like NitroFusion should prioritize several key areas. Improving classifier-free guidance (CFG) integration is crucial for enhancing user control and addressing ambiguity in text prompts. This requires careful consideration of how CFG interacts with the dynamic adversarial framework to avoid instability. Exploring training with natural images, instead of solely relying on synthetic data, could significantly improve the quality and diversity of generated images, but it necessitates addressing potential alignment issues between image and text. Optimizing the adversarial training strategy is important for boosting training efficiency and reducing overfitting. This might involve investigating advanced techniques such as adaptive learning rate schedules and more sophisticated discriminator architectures. Finally, extending the model’s adaptability to various artistic styles through a modular framework allows for easier incorporation of style-specific information and further improves efficiency. This may be achieved by creating a more generalized dynamic discriminator pool that learns diverse artistic patterns. The success of future research hinges on the effective integration and advancement of these research directions to produce more versatile and robust single-step diffusion models.
More visual insights#
More on figures
🔼 This figure illustrates the distillation process of NitroFusion, a method that transforms a multi-step teacher diffusion model into a fast, one-step student model. The key innovation is the Dynamic Adversarial Framework. It uses a large pool of discriminator heads, each specializing in different aspects of image quality at various noise levels. In each training iteration, a subset of these heads is randomly selected to provide diverse and unbiased feedback to the student generator. This dynamic approach prevents overfitting and ensures that the student model generates high-quality images, even in a single step.
read the caption
Figure 2: Our method distils a multi-step teacher model into an efficient one-step student generator. The Dynamic Adversarial Framework provides dynamic, stable feedback via a large dynamic Discriminator Head Pool, dynamically sampling a subset of heads in each iteration to provide unbiased and stable feedback to judge real or fake, effectively balancing one-step efficiency with high-quality generation.

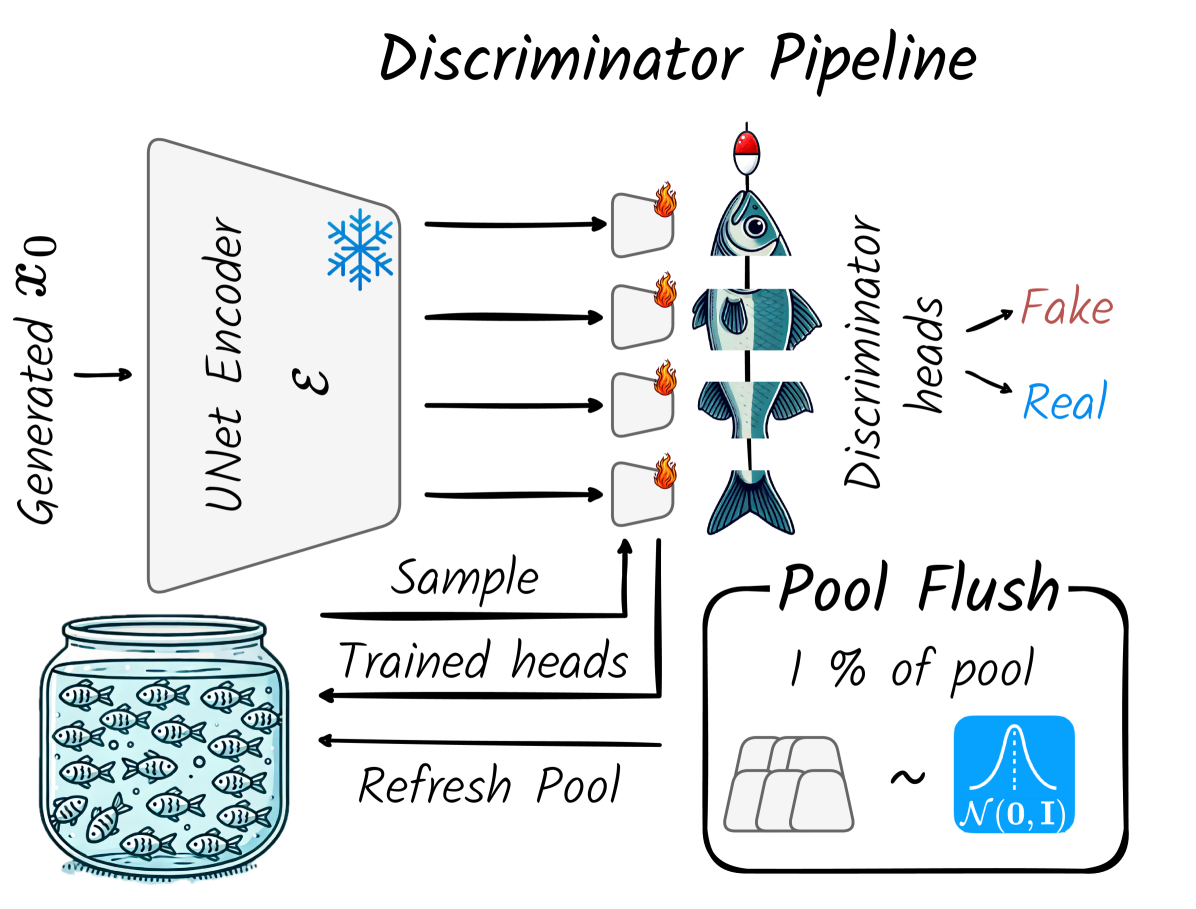
🔼 The figure illustrates the architecture of the discriminator used in the NitroFusion model. It shows a frozen UNet backbone, acting as a feature extractor, with multiple lightweight discriminator heads attached at different levels. These heads are dynamically sampled for training at each iteration. A key aspect is the ‘pool refresh’ mechanism which periodically reinitializes 1% of the heads, preventing overfitting and maintaining a diverse range of feedback for high-quality image generation.
read the caption
Figure 3: Our discriminator employs a frozen UNet backbone with a dynamic pool of discriminator heads. At each iteration, a subset of heads is sampled and trained, with 1% of all heads randomly reinitialized to maintain diverse signals and prevent overfitting.

🔼 This figure compares the image generation quality of two new models, NitroSD-Realism and NitroSD-Vibrant, with several other models. It shows the results of generating images using different models, including multi-step models (SDXL, DMD2, and Hyper-SDXL) and single-step models (SDXL-Turbo, SDXL-Lightning). The comparison highlights the improved fidelity and detail achieved by the new NitroSD models, especially when compared to other single-step methods. The prompts used for image generation are also displayed.
read the caption
Figure 4: Visual comparison of our models (NitroSD-Realism and NitroSD-Vibrant) against multi-step SDXL [34], our teacher models (4-step DMD2 [52] and 8-step Hyper-SDXL [37]), and selected 1-step state-of-the-art baselines [42, 23].

🔼 This figure shows the results of a user preference study comparing the image quality of NitroSD-Realism and NitroSD-Vibrant against other baseline models. The study involved participants choosing between pairs of images generated by different models, allowing for a quantitative evaluation of user preference for each model. This helps to demonstrate the relative quality of NitroSD models compared to other state-of-the-art single and multi-step diffusion models.
read the caption
Figure 5: User preferences study with other baseline models.

🔼 Figure 6 presents a visual comparison of the performance of the models NitroSD-Realism and NitroSD-Vibrant against other state-of-the-art approaches across multiple inference steps (1, 2, and 4). The figure highlights a key advantage of NitroFusion: the progressive improvement in image clarity and overall quality as the number of inference steps increases. This demonstrates the model’s ability to refine generated images effectively with increased computational cost.
read the caption
Figure 6: Visual comparison of our models (NitroSD-Realism and NitroSD-Vibrant) with other approaches across multiple steps, highlighting the clarity and improving quality of our method from 1-step to 4-step inference.

🔼 This figure shows the results of an ablation study, which systematically removes components from the NitroFusion model to assess their individual contributions. By comparing the generated images with different components removed, it is possible to understand how these components impact the overall quality and characteristics of the generated images. The ablation study includes removing the multi-scale dual-objective GAN training, the pool refresh mechanism, and the dynamic discriminator pool. The results show the impact of each of these components on the generation quality.
read the caption
Figure 7: Qualitative study of ablative configurations

🔼 This figure demonstrates the adaptability of the NitroSD-Realism model to various artistic styles. By applying the model’s weights to pre-trained models specialized in anime and oil painting, the authors showcase its ability to generate images consistent with these styles without requiring additional training. This highlights the model’s generalization capabilities beyond the dataset it was originally trained on, indicating its robustness and potential for broader applications.
read the caption
Figure 8: Results from applying NitroSD-Realism to anime [3] and oil painting [5] base models. Our model effectively adapts to different artistic styles.

🔼 Figure 9 presents a visual comparison of the progressive enhancement in image quality and detail achieved through a bottom-up refinement process in the NitroFusion model. It shows the results generated by the NitroSD-Realism and NitroSD-Vibrant models at 1, 2, and 4 steps of refinement. This helps to illustrate how increasing the number of steps improves image sharpness, clarity, and overall visual fidelity, demonstrating the model’s ability to produce high-quality images with flexible and efficient deployment.
read the caption
Figure 9: 1- to 4-step refinement process of our NitroSD-Realism and -Vibrant, illustrating the progressive enhancement of image quality and detail across steps.

🔼 Figure 10 presents a visual comparison of image generation results between NitroFusion (the model proposed in the paper) and several state-of-the-art single-step and multi-step diffusion models. For multiple prompts, it shows the outputs of the 25-step SDXL baseline model, the single-step SDXL-Turbo, SDXL-Lightning, and DMD2 models, the 4-step DMD2 model, and finally, the single-step results of NitroSD-Realism and NitroSD-Vibrant. This allows for a direct comparison of image quality and detail across different models and approaches, highlighting the strengths of NitroFusion in terms of achieving high fidelity even in a single-step generation.
read the caption
Figure 10: Additional visual comparison with state-of-the-art approaches.
Full paper#














