↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Existing video editing methods often struggle with maintaining cross-frame consistency, generalizability, and high-quality generation. They either focus on specific editing types or rely on additional controls like structural conditions or attention features, hindering flexibility and model efficiency. Furthermore, a lack of comprehensive video editing benchmarks hampers objective evaluation.
OmniCreator tackles these issues by using a self-supervised approach. It leverages a unified framework capable of both generation and editing. By conditioning a denoising process on text and video embeddings and using the original video as a denoising target, it learns semantic correspondence between text and video. This allows for universal editing across various types and scenarios and high-quality text-to-video generation. The introduced OmniBench-99 dataset facilitates comprehensive evaluation of generative video editing models.
Key Takeaways#
Why does it matter?#
This paper is highly important because it introduces OmniCreator, a novel framework that significantly advances text-guided video editing and generation. It addresses limitations of existing methods by achieving universality and high quality in a self-supervised manner. This opens new avenues for research, particularly in developing more robust, versatile generative models for video content creation and manipulation.
Visual Insights#

🔼 Figure 1 shows the capabilities of OmniCreator in performing universal text-guided video editing. The top row displays four main editing types: foreground editing, background editing, composite editing, and overall/style editing. The bottom part of the figure illustrates eight diverse editing scenarios that OmniCreator can handle. These scenarios are categorized into four main groups: object, environment, human/animal, and composite. Each scenario contains examples of video edits guided by specific text prompts. Appendix A provides a detailed explanation of the editing types and scenarios.
read the caption
Figure 1: OmniCreator enables universal text-guided video editing across four distinct editing types (top) and eight different scenarios (bottom). For comprehensive definitions of the editing types and scenarios, please refer to App. A.
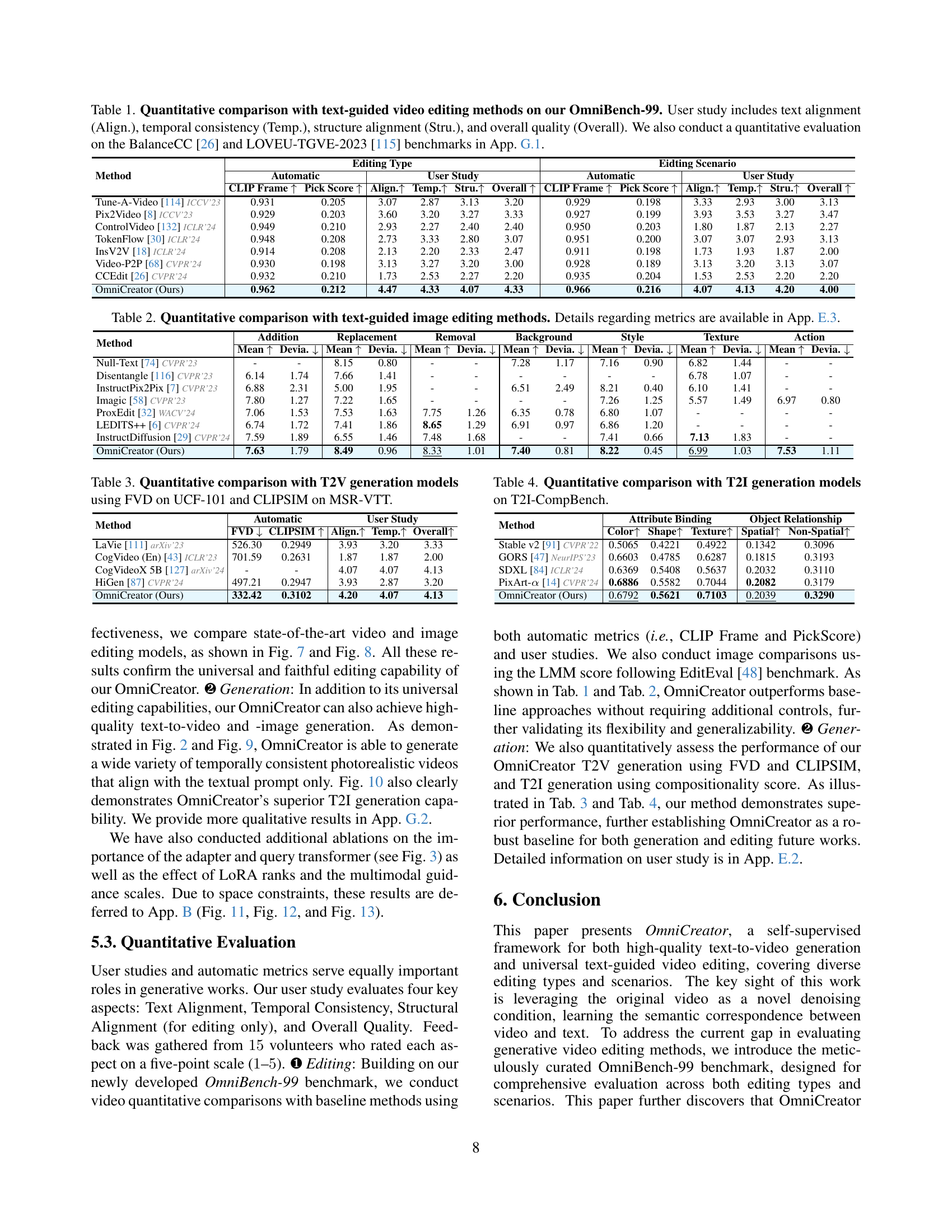
| Method | Editing Type | Editing Scenario | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Automatic | User Study | Automatic | User Study | |||||||||
| — | — | — | — | — | — | — | — | — | — | — | — | — |
| CLIP Frame ↑ | Pick Score ↑ | Align. ↑ | Temp. ↑ | Stru. ↑ | Overall ↑ | CLIP Frame ↑ | Pick Score ↑ | Align. ↑ | Temp. ↑ | Stru. ↑ | Overall ↑ | |
| — | — | — | — | — | — | — | — | — | — | — | — | — |
| Tune-A-Video [114] ICCV’23 | 0.931 | 0.205 | 3.07 | 2.87 | 3.13 | 3.20 | 0.929 | 0.198 | 3.33 | 2.93 | 3.00 | 3.13 |
| Pix2Video [8] ICCV’23 | 0.929 | 0.203 | 3.60 | 3.20 | 3.27 | 3.33 | 0.927 | 0.199 | 3.93 | 3.53 | 3.27 | 3.47 |
| ControlVideo [132] ICLR’24 | 0.949 | 0.210 | 2.93 | 2.27 | 2.40 | 2.40 | 0.950 | 0.203 | 1.80 | 1.87 | 2.13 | 2.27 |
| TokenFlow [30] ICLR’24 | 0.948 | 0.208 | 2.73 | 3.33 | 2.80 | 3.07 | 0.951 | 0.200 | 3.07 | 3.07 | 2.93 | 3.13 |
| InsV2V [18] ICLR’24 | 0.914 | 0.208 | 2.13 | 2.20 | 2.33 | 2.47 | 0.911 | 0.198 | 1.73 | 1.93 | 1.87 | 2.00 |
| Video-P2P [68] CVPR’24 | 0.930 | 0.198 | 3.13 | 3.27 | 3.20 | 3.00 | 0.928 | 0.189 | 3.13 | 3.20 | 3.13 | 3.07 |
| CCEdit [26] CVPR’24 | 0.932 | 0.210 | 1.73 | 2.53 | 2.27 | 2.20 | 0.935 | 0.204 | 1.53 | 2.53 | 2.20 | 2.20 |
| OmniCreator (Ours) | 0.962 | 0.212 | 4.47 | 4.33 | 4.07 | 4.33 | 0.966 | 0.216 | 4.07 | 4.13 | 4.20 | 4.00 |
🔼 Table 1 presents a quantitative comparison of various text-guided video editing methods, evaluated using the OmniBench-99 benchmark. The evaluation includes both automated metrics (CLIP Frame and PickScore) and a user study assessing text alignment, temporal consistency, structural alignment (for video-specific methods only), and overall quality. For a more comprehensive comparison, additional quantitative results using the BalanceCC [26] and LOVEU-TGVE-2023 [115] benchmarks are provided in Appendix G.1.
read the caption
Table 1: Quantitative comparison with text-guided video editing methods on our OmniBench-99. User study includes text alignment (Align.), temporal consistency (Temp.), structure alignment (Stru.), and overall quality (Overall). We also conduct a quantitative evaluation on the BalanceCC [26] and LOVEU-TGVE-2023 [115] benchmarks in App. G.1.
In-depth insights#
Unified Video Editing#
The concept of “Unified Video Editing” points towards a system capable of handling diverse video manipulation tasks within a single, integrated framework. This contrasts with existing methods which often focus on specific editing types (e.g., foreground/background changes, object removal/addition) or rely on additional controls like attention mechanisms, structural conditions, or specialized tuning. A truly unified approach would ideally offer seamless transitions between different editing operations, enabling users to combine various effects without limitations. This necessitates a model architecture that can understand semantic correspondences between text and video, allowing for both generation of entirely new video sequences and fine-grained edits to existing footage using natural language instructions. The key advantages of a unified system include increased efficiency, improved user experience due to simpler interfaces, and greater overall flexibility, but significant challenges remain, such as handling temporal consistency, addressing complex interactions between diverse editing actions, and ensuring high visual quality across various editing scenarios.
Self-Supervised Learning#
Self-supervised learning in the context of this research paper is a crucial aspect of the OmniCreator framework. It leverages original text-video pairs as input, requiring no manual annotation, thereby eliminating tedious and costly annotation processes. The model learns the semantic correspondence between text and video by using the video itself as a denoising target. This self-supervised approach is instrumental in achieving the framework’s capabilities in both universal video editing and generation. The success of this method highlights the potential for developing more efficient and effective generative models for video, reducing dependence on large-scale labeled datasets, which are expensive and time-consuming to create.
OmniBench-99 Dataset#
The creation of the OmniBench-99 dataset is a significant contribution to the field of generative video editing. Existing benchmarks often lack the scope to fully evaluate the capabilities of models across diverse scenarios. OmniBench-99 addresses this limitation by focusing on both editing types and scenarios, incorporating 99 diverse videos spanning three distinct categories (human/animal, environment, and object). Each video includes prompts for four editing types, with additional prompts focusing on eight specific scenarios. This comprehensive approach allows for a more nuanced and thorough evaluation of models, enabling a more holistic understanding of their strengths and weaknesses in various contexts. The inclusion of both full-sentence and delta prompts further enhances the versatility of the dataset, facilitating more detailed analysis. The dataset’s design thus promotes a richer understanding of generative video editing models, going beyond a simple classification of editing types, to consider the complexities of applying those edits in the diverse real-world contexts reflected in the videos.
LoRA-Based Optimization#
LoRA (Low-Rank Adaptation) offers a powerful technique for optimizing large language models, especially within the context of video generation and editing. By applying LoRA to the spatial and temporal layers of a U-Net architecture, the computational cost of training and fine-tuning is significantly reduced without sacrificing performance. This is crucial in video editing, which often demands high computational resources due to the temporal dimension. The effectiveness of LoRA in this application stems from its ability to make small, targeted updates to the model’s parameters. Instead of updating the entire weight matrix, LoRA only modifies low-rank factor matrices, thus dramatically decreasing the number of parameters to train. This low-rank approximation enables more efficient training and faster inference, making the model practical for tasks with large datasets and complex video editing operations. However, finding the optimal rank for LoRA requires careful tuning, as overly low ranks may limit the model’s expressive power, while overly high ranks could negate the efficiency gains. Further research could explore adaptive methods for determining the optimal LoRA rank based on the task and data characteristics. The success of LoRA highlights the importance of exploring efficient optimization strategies when dealing with the immense computational requirements of advanced video editing models.
Future Research#
Future research directions for OmniCreator should prioritize enhancing its handling of complex temporal dynamics and fine-grained details, particularly concerning high-speed movement and intricate facial expressions. Addressing these limitations would involve exploring more sophisticated temporal modeling techniques, possibly integrating motion features from the original video. Further investigation into multimodal fusion strategies is warranted to better incorporate various forms of conditionals, improving control over visual aspects and enhancing the generation of diverse video styles and effects. OmniCreator’s potential should be explored for applications such as high-quality video editing for film and visual effects and expanding its capabilities to other modalities. Finally, ethical considerations regarding the use of generative video editing tools remain paramount and deserve careful attention in future work.
More visual insights#
More on figures

🔼 Figure 2 showcases example videos generated by OmniCreator using only text prompts as input, demonstrating its capacity for high-quality text-to-video generation. This highlights OmniCreator’s ability to function not just as a video editor, but also as a generative model for creating novel video content.
read the caption
Figure 2: OmniCreator samples for text-to-video generation. OmniCreator not only enables universal video editing but also generates high-quality videos from text prompts.

🔼 OmniCreator uses a self-supervised training approach where the original video is part of the denoising process. An adapter module helps the model understand temporal information in the video, and a query transformer aligns video and text embeddings for better denoising. Low-rank adaptations (LoRAs) are used to make the U-Net more efficient. During inference, the model takes a reference video and an editing text prompt to perform universal video editing.
read the caption
Figure 3: Overview of OmniCreator. During training, the original video also serves as a condition of the denoising process. To enable temporal information understanding, we incorporate an adapter. Additionally, we utilize a query transformer to effectively align video and text embeddings, which aids in the denoising process. For computational efficiency, LoRAs are integrated into the denoising U-Net. During inference, OmniCreator enables universal video editing by adopting a reference video alongside an editing text prompt.

🔼 Figure 4 demonstrates the effectiveness of the adapter and query transformer modules in aligning video and text embeddings. The left panel shows Euclidean distance, while the right panel shows cosine similarity. Each bar represents a different experimental condition: with adapter and query transformer, with adapter only, with query transformer only, and without either. The results illustrate the improved alignment achieved when both modules are used, demonstrating their contribution to effective multimodal fusion.
read the caption
Figure 4: Illustration of the alignment between video and text embeddings. We utilize Euclidean Distance (left, blue) and Cosine Similarity (right, red) to evaluate the impact of the Adapter (Ada.) and Query Transformer (Query) on the embedding alignment.

🔼 Figure 5 illustrates the concept of semantic correspondence in the OmniCreator framework. The top row displays a reference video and its original caption, establishing the ground truth. The middle row shows the results of using only one condition (text or video) for generation, demonstrating the limitations of relying on a single input modality. The bottom row compares the results of using a full-sentence prompt versus a delta prompt (only the editing instruction) for generation, highlighting the impact of specifying editing changes precisely. This comparison reveals the ability of delta prompts to effectively combine textual and video semantics for better control during the video editing process.
read the caption
Figure 5: Illustration of semantic correspondence. Top: Reference video and its original caption. Middle: Results using only one condition. Bottom: Effects of full sentence vs. delta prompt.

🔼 The figure shows a statistical overview of the OmniBench-99 dataset. It presents the distribution of videos across three categories (Human/Animal, Environment, Object) and the number of videos associated with each category. Additionally, it illustrates the distribution of editing prompts (Full sentence prompt and Delta prompt), and shows how many videos have been annotated with each type of prompt.
read the caption
Figure 6: Statistics of OmniBench-99.

🔼 Figure 7 shows a comparison of video editing results between OmniCreator and two baseline models, TokenFlow and CCEdit. The comparison focuses on various editing scenarios, using delta prompts (short, focused prompts specifying only the desired changes). Due to space limitations in the main paper, the figure only presents a subset of the editing scenarios. A complete comparison across all scenarios is available in Appendix G.2 of the paper.
read the caption
Figure 7: Video editing comparison with baselines. We follow the baseline’s prompt setting but only show delta prompts here. Due to space constraints, we only compare editing scenarios with TokenFlow and CCEdit, for complete comparisons, please refer to App. G.2.

🔼 Figure 8 shows a qualitative comparison of image editing results between OmniCreator and several baseline methods. Each row represents a different editing task (Addition, Replacement, Removal, Background, Style, Texture, Action). Within each row, the leftmost column shows the original reference image. Subsequent columns display the results from the different models, illustrating their respective performance in terms of editing precision, visual consistency, and adherence to the provided instructions. This allows for a direct visual assessment of OmniCreator’s capabilities in comparison to existing image editing techniques.
read the caption
Figure 8: Image editing comparison with baselines.

🔼 Figure 9 presents several examples of high-quality videos generated by OmniCreator using only text prompts. These examples showcase the model’s ability to generate diverse and complex video scenes from various textual descriptions. The images illustrate the versatility and quality of the generated videos, highlighting the model’s success in text-to-video generation.
read the caption
Figure 9: Qualitative results of OmniCreator T2V samples.

🔼 This figure showcases several examples of images generated by the OmniCreator model from text prompts only. It demonstrates the model’s ability to create high-quality and diverse images from a wide range of text descriptions, highlighting its capacity for detailed and photorealistic generation. The diverse styles and subject matters across the images demonstrate the versatility of OmniCreator in text-to-image generation.
read the caption
Figure 10: Qualitative results of OmniCreator T2I samples.

🔼 This ablation study investigates the impact of the adapter and query transformer on video condition modeling within the OmniCreator framework. The figure showcases how different components of the model affect the ability to accurately reconstruct the reference video, particularly focusing on the background elements. The results demonstrate the significant contributions of both the adapter (which enables the model to understand temporal dynamics) and the query transformer (which facilitates alignment between text and video embeddings). The absence of either component impairs the quality of the reconstructed video, while including both leads to superior performance.
read the caption
Figure 11: Ablation on video condition modeling. Ada. indicates the adapter, and Query is the query transformer.

🔼 This ablation study investigates the impact of different LoRA (Low-Rank Adaptation) ranks on the model’s ability to learn and understand semantic relationships between text and video. The results demonstrate that the performance of the model is affected by the choice of LoRA rank, suggesting there is an optimal rank for balancing performance and computational efficiency. Using excessively low or high ranks hinders the model’s ability to capture semantic correlations adequately.
read the caption
Figure 12: Ablation on LoRA ranks. LoRA with different ranks exhibits different learning comprehension abilities

🔼 This ablation study investigates the effects of two scaling factors, 𝑤𝑡𝑥𝑡<binary data, 1 bytes><binary data, 1 bytes><binary data, 1 bytes> and 𝑤𝑣𝑖𝑑<binary data, 1 bytes><binary data, 1 bytes><binary data, 1 bytes>, on the performance of the OmniCreator model. The scaling factor 𝑤𝑡𝑥𝑡<binary data, 1 bytes><binary data, 1 bytes><binary data, 1 bytes> controls how closely the generated output adheres to the edit instruction provided in the text prompt, while 𝑤𝑣𝑖𝑑<binary data, 1 bytes><binary data, 1 bytes><binary data, 1 bytes> controls how similar the output is to the reference video. The figure shows that appropriate adjustment of these scaling factors is crucial for achieving optimal results in various editing scenarios.
read the caption
Figure 13: Ablation on multimodal guidance scales. wtxtsubscript𝑤txtw_{\mathrm{txt}}italic_w start_POSTSUBSCRIPT roman_txt end_POSTSUBSCRIPT controls consistency with the edit instruction, while wvidsubscript𝑤vidw_{\mathrm{vid}}italic_w start_POSTSUBSCRIPT roman_vid end_POSTSUBSCRIPT controls the similarity with reference video.

🔼 This figure demonstrates the process of generating text prompts for the OmniBench-99 dataset. It shows an example of how a center frame from a video is used, along with the video’s category (Human/Animal, Object, or Environment), to generate a main description of the frame and then prompts designed for different editing types (Foreground, Background, Style, Composite) and editing scenarios specific to the category. It also shows how delta prompts are created, specifying only the changes to be made.
read the caption
Figure 14: Text Prompt Demonstration.

🔼 Figure 15 presents a qualitative comparison of image editing results achieved using various methods. It showcases the effects of different approaches on several editing scenarios, such as adding, replacing, and removing objects; altering the background and textures; and changing the overall style or even actions within the image. This visual comparison allows for a direct assessment of each method’s ability to produce edits that are visually pleasing, contextually appropriate, and realistic in terms of maintaining coherence and integrity.
read the caption
Figure 15: Image editing comparison.

🔼 Figure 16 shows examples from the OmniBench-99 benchmark dataset. The dataset contains diverse videos categorized into three groups: Human/Animal, Object, and Environment. For each video, multiple prompts are provided to cover a range of editing types (Foreground, Background, Style, and Composite) and editing scenarios (Appearance, Motion/Pose, Addition, Removal, Replacement, Weather, Time, Background). The figure highlights the ‘delta prompts’—short, specific instructions focusing on localized edits—in yellow-brown to differentiate them from the full-sentence prompts.
read the caption
Figure 16: Examples of OmniBench-99 benchmark. The delta prompts are highlighted in yellow-brown.

🔼 This figure shows the user interface used for the user study. The interface is designed to allow users to evaluate video generation and editing results across various metrics such as Text Alignment, Temporal Consistency, Structure Alignment (for editing only), and Overall Quality. Each metric is rated on a 5-point scale, and users provide scores for several randomly selected videos for each prompt condition. A complete example of the interface is displayed, showing a user’s evaluation of video clips with a specific prompt.
read the caption
Figure 17: Demonstration of our user study interface. Here we demonstrate one complete sample.

🔼 This figure showcases a gallery of images generated by the OmniCreator model using only text prompts. The results demonstrate the model’s ability to generate diverse and visually compelling images based on varied textual descriptions, ranging from natural landscapes and underwater scenes to abstract styles and fantastical settings. The images highlight OmniCreator’s capacity for detailed rendering, accurate object representation, and adherence to the specified prompt’s semantics.
read the caption
Figure 18: Gallery of OmniCreator’s text-to-image generation results.

🔼 This figure showcases various video clips generated by the OmniCreator model using only text prompts as input. Each video clip demonstrates the model’s ability to generate diverse and coherent video content from textual descriptions, highlighting its capabilities in text-to-video generation. The videos depict different scenes and styles, showcasing the range of content the model can produce.
read the caption
Figure 19: Gallery of OmniCreator’s text-to-video generation results.

🔼 This figure showcases various video clips generated by the OmniCreator model using only text prompts. Each row represents a different text prompt, demonstrating the model’s ability to generate diverse and coherent videos based on textual descriptions. The videos illustrate different scenes and styles, highlighting OmniCreator’s capacity for generating high-quality video content from text prompts alone.
read the caption
Figure 20: Gallery of OmniCreator’s text-to-video generation results.

🔼 This figure compares the results of different video editing models on the ‘Foreground’ editing type. The editing task focuses on modifying only the foreground of a video while leaving the background unchanged. The reference video is shown at the top, followed by the output of various models, including Tune-A-Video, Pix2Video, ControlVideo, TokenFlow, InsV2V, Video-P2P, CCEdit, and OmniCreator (the authors’ model). The figure allows for a visual comparison of the effectiveness of each model in preserving the background and accurately editing only the foreground as instructed by the prompt.
read the caption
Figure 21: Video editing comparison: Editing-Type-Foreground.

🔼 This figure compares the performance of different video editing models in modifying the background of a video. The models are given the same source video and a text prompt instructing a change to the background. The figure allows a visual comparison of the results from each model, showing how accurately and effectively each model changed the background while maintaining the rest of the video. This helps to evaluate the models’ ability to perform text-guided background editing.
read the caption
Figure 22: Video editing comparison: Editing-Type-Background.

🔼 This figure displays a comparison of video editing results across different models for the ‘Style’ editing type. The reference video is shown at the top, followed by the results from several other models, including Tune-A-Video, Pix2Video, ControlVideo, TokenFlow, InsV2V, Video-P2P, CCEdit, and finally OmniCreator (the authors’ model). Each row shows a series of frames from the edited video, allowing for visual comparison of the different models’ capabilities in modifying the style or overall aesthetic of the video according to the prompt, which in this case is ‘Oil painting style.’
read the caption
Figure 23: Video editing comparison: Editing-Type-Style.

🔼 This figure compares the performance of different video editing models on composite video editing tasks. Composite editing involves making multiple changes to a video, such as altering both the foreground and background simultaneously. The figure shows the results of each model’s attempt to edit a video according to a specific composite editing prompt. By visually comparing the results, one can assess the strengths and weaknesses of each model in terms of maintaining visual consistency, accurately implementing the changes specified in the prompt, and achieving a high-quality, coherent output.
read the caption
Figure 24: Video editing comparison: Editing-Type-Composite.

🔼 This figure compares the performance of different video editing models on the specific task of weather editing within the environment scenario. The original video shows a particular weather condition. Each row in the figure represents a different video editing model, demonstrating their ability to modify the original video’s weather based on a text prompt (e.g., changing clear skies to stormy skies with rain and mist). The comparison allows for a visual assessment of each model’s capability to accurately and realistically alter the weather conditions in a video while maintaining consistency with the original visual context.
read the caption
Figure 25: Video editing comparison: Editing-Scenario-Environment-Weather.

🔼 This figure shows a comparison of different video editing models’ performance on the ‘Environment-Time’ editing scenario. The goal is to change the time of day depicted in a video. The reference video is shown alongside the results from several models, including Tune-A-Video, Pix2Video, ControlVideo, TokenFlow, InsV2V, Video-P2P, CCEdit and OmniCreator. The comparison highlights the ability of each model to accurately reflect the specified time change (e.g., sunset) while preserving the overall visual style and integrity of the video.
read the caption
Figure 26: Video editing comparison: Editing-Scenario-Environment-Time.

🔼 This figure compares the performance of different video editing models on a specific editing scenario: changing the background of an environmental video. The reference video shows an initial scene, and each row demonstrates how different models (Tune-A-Video, Pix2Video, ControlVideo, TokenFlow, InsV2V, Video-P2P, CCEdit) modify the background according to the same textual prompt, with the last row showing OmniCreator’s results.
read the caption
Figure 27: Video editing comparison: Editing-Scenario-Environment-Background.

🔼 This figure compares the results of several video editing models on the task of adding objects to a video. The models are presented with a video and a text prompt instructing them to add an object (in this case, multiple bees). Each row shows the results from a different model, including the reference video and the outputs generated by Tune-A-Video, Pix2Video, ControlVideo, TokenFlow, InsV2V, Video-P2P, CCEdit, and OmniCreator. This allows for a visual comparison of each model’s ability to accurately and realistically integrate the new objects into the scene while maintaining consistency with the overall video style and structure. The differences in the results highlight the varying capabilities of each model in terms of object placement, integration, and preserving context.
read the caption
Figure 28: Video editing comparison: Editing-Scenario-Object-Addition.

🔼 This figure compares the results of various video editing models on the task of object removal within a specific scenario. The reference video shows an object, and the goal is to edit the video to remove the object, leaving the rest of the video intact. Each row shows the results from a different video editing model, showcasing their ability to remove the target object cleanly and effectively while preserving the rest of the video’s background and context.
read the caption
Figure 29: Video editing comparison: Editing-Scenario-Object-Removal.

🔼 This figure shows a comparison of different video editing models’ performance on the task of object replacement. The models are given a video and a text prompt instructing them to replace a specific object with another. The figure visually demonstrates the differences in editing quality, accuracy, and visual coherence, enabling a qualitative assessment of the effectiveness of each model in executing this type of video manipulation.
read the caption
Figure 30: Video editing comparison: Editing-Scenario-Object-Replacement.

🔼 This figure shows a comparison of different video editing models’ performance on the task of human appearance editing. The models are given the same reference video and a text prompt instructing them to change the appearance of a person in the video (in this case, to make the person wear a blue coat). The figure displays frames from each model’s output video, allowing for a visual comparison of the editing results. This allows for assessment of each model’s ability to accurately reflect the prompt’s instructions while maintaining overall video quality and coherence.
read the caption
Figure 31: Video editing comparison: Editing-Scenario-Human-Appearance.
More on tables
| Method | Addition | Replacement | Removal | Background | Style | Texture | Action | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Null-Text [74] CVPR’23 | - | - | 8.15 | 0.80 | - | - | 7.28 | 1.17 | 7.16 | 0.90 | 6.82 | 1.44 | - | - |
| Disentangle [116] CVPR’23 | 6.14 | 1.74 | 7.66 | 1.41 | - | - | - | - | - | - | 6.78 | 1.07 | - | - |
| InstructPix2Pix [7] CVPR’23 | 6.88 | 2.31 | 5.00 | 1.95 | - | - | 6.51 | 2.49 | 8.21 | 0.40 | 6.10 | 1.41 | - | - |
| Imagic [58] CVPR’23 | 7.80 | 1.27 | 7.22 | 1.65 | - | - | - | - | 7.26 | 1.25 | 5.57 | 1.49 | 6.97 | 0.80 |
| ProxEdit [32] WACV’24 | 7.06 | 1.53 | 7.53 | 1.63 | 7.75 | 1.26 | 6.35 | 0.78 | 6.80 | 1.07 | - | - | - | - |
| LEDITS++ [6] CVPR’24 | 6.74 | 1.72 | 7.41 | 1.86 | 8.65 | 1.29 | 6.91 | 0.97 | 6.86 | 1.20 | - | - | - | - |
| InstructDiffusion [29] CVPR’24 | 7.59 | 1.89 | 6.55 | 1.46 | 7.48 | 1.68 | - | - | 7.41 | 0.66 | 7.13 | 1.83 | - | - |
| OmniCreator (Ours) | 7.63 | 1.79 | 8.49 | 0.96 | 8.33 | 1.01 | 7.40 | 0.81 | 8.22 | 0.45 | 6.99 | 1.03 | 7.53 | 1.11 |
🔼 Table 2 presents a quantitative comparison of OmniCreator against other state-of-the-art text-guided image editing methods. The table evaluates performance across several image editing tasks, such as addition, removal, replacement, background change, style transfer, texture alteration, and action modification. Specific metrics used in the evaluation are detailed in Appendix E.3 of the paper.
read the caption
Table 2: Quantitative comparison with text-guided image editing methods. Details regarding metrics are available in App. E.3.
| Method | Automatic | User Study | |||
|---|---|---|---|---|---|
| Method | FVD ↓ | CLIPSIM ↑ | Align. ↑ | Temp. ↑ | Overall ↑ |
| LaVie [111] arXiv’23 | 526.30 | 0.2949 | 3.93 | 3.20 | 3.33 |
| CogVideo (En) [43] ICLR’23 | 701.59 | 0.2631 | 1.87 | 1.87 | 2.00 |
| CogVideoX 5B [127] arXiv’24 | - | - | 4.07 | 4.07 | 4.13 |
| HiGen [87] CVPR’24 | 497.21 | 0.2947 | 3.93 | 2.87 | 3.20 |
| OmniCreator (Ours) | 332.42 | 0.3102 | 4.20 | 4.07 | 4.13 |
🔼 This table presents a quantitative comparison of various text-to-video (T2V) generation models. The comparison uses two metrics: Fréchet Video Distance (FVD), calculated on the UCF-101 dataset, and CLIP Similarity (CLIPSIM), computed using the MSR-VTT dataset. These metrics evaluate the quality and fidelity of the generated videos compared to ground truth. The table helps assess the performance of different T2V models in generating high-quality videos faithful to the given text prompts.
read the caption
Table 3: Quantitative comparison with T2V generation models using FVD on UCF-101 and CLIPSIM on MSR-VTT.
| Method | Attribute Binding | Object Relationship | ||||
|---|---|---|---|---|---|---|
| Color ↑ | Shape ↑ | Texture ↑ | Spatial ↑ | Non-Spatial ↑ | ||
| Stable v2 [91] CVPR’22 | 0.5065 | 0.4221 | 0.4922 | 0.1342 | 0.3096 | |
| GORS [47] NeurIPS’23 | 0.6603 | 0.4785 | 0.6287 | 0.1815 | 0.3193 | |
| SDXL [84] ICLR’24 | 0.6369 | 0.5408 | 0.5637 | 0.2032 | 0.3110 | |
| PixArt-α [14] CVPR’24 | 0.6886 | 0.5582 | 0.7044 | 0.2082 | 0.3179 | |
| OmniCreator (Ours) | 0.6792 | 0.5621 | 0.7103 | 0.2039 | 0.3290 |
🔼 This table presents a quantitative comparison of OmniCreator’s text-to-image (T2I) generation capabilities against other state-of-the-art models using the T2I-CompBench benchmark. The benchmark assesses various aspects of image generation quality, focusing particularly on the model’s ability to correctly represent different attributes of objects and their relationships. The table likely shows scores (such as precision, recall, or F1-scores) for each model across different attributes such as color, shape, texture, spatial relationships, and non-spatial relationships. This allows for a detailed comparison of how well different models perform on various aspects of image generation complexity.
read the caption
Table 4: Quantitative comparison with T2I generation models on T2I-CompBench.
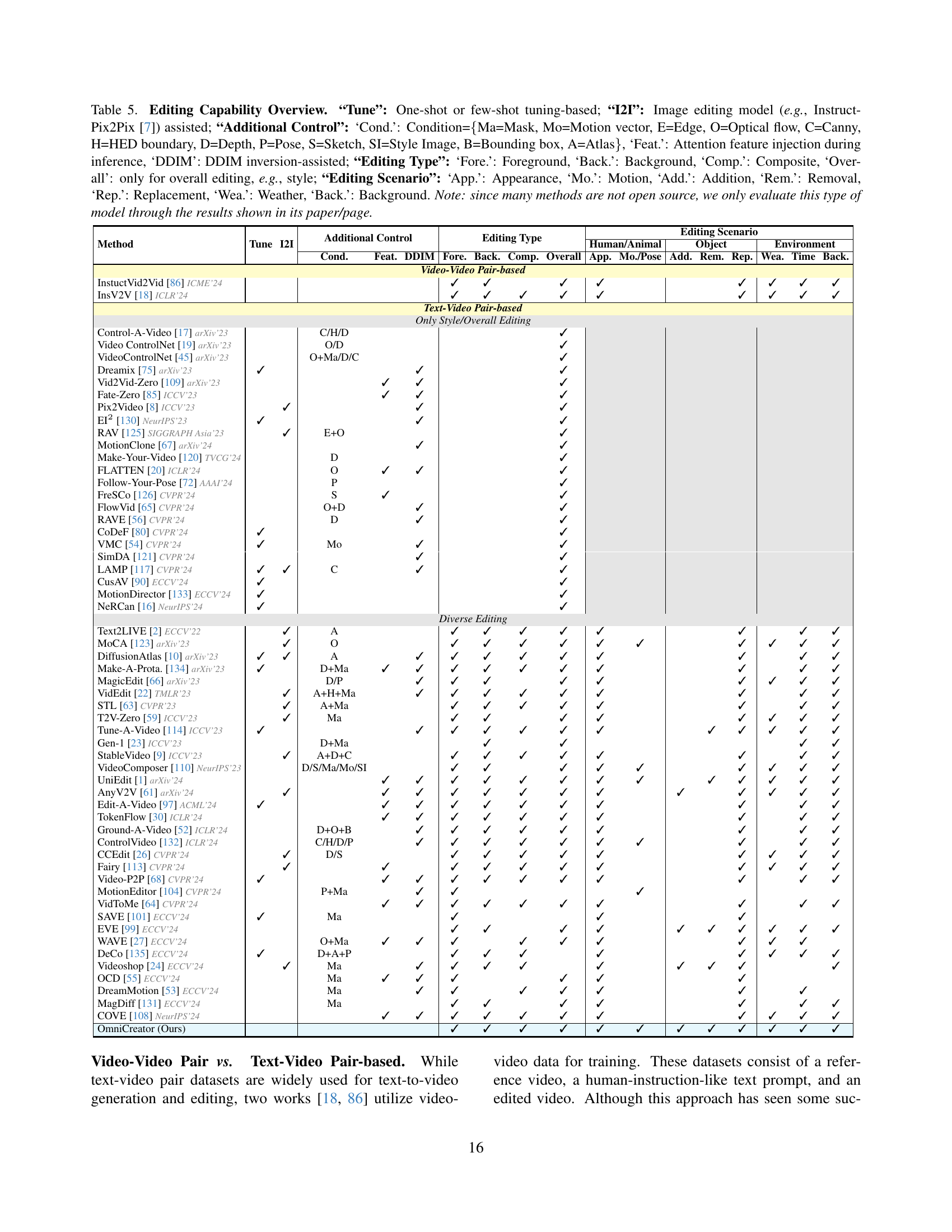
| Method | Tune | I2I | Additional Control | Editing Type | Editing Scenario |
|---|---|---|---|---|---|
| Human/Animal | Object | Environment | |||
| — | — | — | — | — | |
| Cond. | Feat. | DDIM | Fore. | Back. | Comp. |
| — | — | — | — | — | — |
| Video-Video Pair-based | |||||
| InstuctVid2Vid [86] ICME’24 | |||||
| InsV2V [18] ICLR’24 | |||||
| Text-Video Pair-based | |||||
| Only Style/Overall Editing | |||||
| Control-A-Video [17] arXiv’23 | C/H/D | ||||
| Video ControlNet [19] arXiv’23 | O/D | ||||
| VideoControlNet [45] arXiv’23 | O+Ma/D/C | ||||
| Dreamix [75] arXiv’23 | ✓ | ||||
| Vid2Vid-Zero [109] arXiv’23 | |||||
| Fate-Zero [85] ICCV’23 | |||||
| Pix2Video [8] ICCV’23 | ✓ | ||||
| EI2 [130] NeurIPS’23 | ✓ | ||||
| RAV [125] SIGGRAPH Asia’23 | E+O | ||||
| MotionClone [67] arXiv’24 | |||||
| Make-Your-Video [120] TVCG’24 | D | ||||
| FLATTEN [20] ICLR’24 | O | ✓ | |||
| Follow-Your-Pose [72] AAAI’24 | P | ||||
| FreSCo [126] CVPR’24 | S | ||||
| FlowVid [65] CVPR’24 | O+D | ✓ | |||
| RAVE [56] CVPR’24 | D | ✓ | |||
| CoDeF [80] CVPR’24 | ✓ | ||||
| VMC [54] CVPR’24 | ✓ | Mo | |||
| SimDA [121] CVPR’24 | |||||
| LAMP [117] CVPR’24 | ✓ | C | |||
| CusAV [90] ECCV’24 | ✓ | ||||
| MotionDirector [133] ECCV’24 | ✓ | ||||
| NeRCan [16] NeurIPS’24 | ✓ | ||||
| Diverse Editing | |||||
| Text2LIVE [2] ECCV’22 | A | ||||
| MoCA [123] arXiv’23 | O | ✓ | ✓ | ||
| DiffusionAtlas [10] arXiv’23 | ✓ | A | ✓ | ✓ | |
| Make-A-Prota. [134] arXiv’23 | D+Ma | ✓ | ✓ | ✓ | |
| MagicEdit [66] arXiv’23 | D/P | ✓ | ✓ | ||
| VidEdit [22] TMLR’23 | A+H+Ma | ✓ | ✓ | ||
| STL [63] CVPR’23 | A+Ma | ✓ | ✓ | ||
| T2V-Zero [59] ICCV’23 | Ma | ✓ | ✓ | ||
| Tune-A-Video [114] ICCV’23 | ✓ | ✓ | ✓ | ✓ | |
| Gen-1 [23] ICCV’23 | D+Ma | ||||
| StableVideo [9] ICCV’23 | A+D+C | ✓ | ✓ | ||
| VideoComposer [110] NeurIPS’23 | D/S/Ma/Mo/SI | ✓ | ✓ | ||
| UniEdit [1] arXiv’24 | |||||
| AnyV2V [61] arXiv’24 | |||||
| Edit-A-Video [97] ACML’24 | ✓ | ||||
| TokenFlow [30] ICLR’24 | |||||
| Ground-A-Video [52] ICLR’24 | D+O+B | ✓ | ✓ | ||
| ControlVideo [132] ICLR’24 | C/H/D/P | ✓ | ✓ | ||
| CCEdit [26] CVPR’24 | D/S | ✓ | ✓ | ||
| Fairy [113] CVPR’24 | |||||
| Video-P2P [68] CVPR’24 | |||||
| MotionEditor [104] CVPR’24 | P+Ma | ✓ | |||
| OmniCreator (Ours) |
🔼 This table provides a comprehensive overview of various text-guided video editing methods, categorized by their approaches and capabilities. It examines the techniques used (one-shot/few-shot tuning, image-to-image methods), additional control mechanisms (condition-based, attention features, DDIM inversion), editing types (foreground, background, composite, overall), and editing scenarios (appearance, motion, addition, removal, replacement, weather, background). The table highlights the diversity of techniques, showing which methods employ each approach. It’s important to note that due to limited open-source availability for some methods, evaluation was based on results reported in the respective papers. The table is a valuable resource for understanding the capabilities and limitations of different video editing techniques.
read the caption
Table 5: Editing Capability Overview. “Tune”: One-shot or few-shot tuning-based; “I2I”: Image editing model (e.g., InstructPix2Pix [7]) assisted; “Additional Control”: ‘Cond.’: Condition={Ma=Mask, Mo=Motion vector, E=Edge, O=Optical flow, C=Canny, H=HED boundary, D=Depth, P=Pose, S=Sketch, SI=Style Image, B=Bounding box, A=Atlas}, ‘Feat.’: Attention feature injection during inference, ‘DDIM’: DDIM inversion-assisted; “Editing Type”: ‘Fore.’: Foreground, ‘Back.’: Background, ‘Comp.’: Composite, ‘Overall’: only for overall editing, e.g., style; “Editing Scenario”: ‘App.’: Appearance, ‘Mo.’: Motion, ‘Add.’: Addition, ‘Rem.’: Removal, ‘Rep.’: Replacement, ‘Wea.’: Weather, ‘Back.’: Background. Note: since many methods are not open source, we only evaluate this type of model through the results shown in its paper/page.
| Method | LOVEU | BalanceCC | ||
|---|---|---|---|---|
| ControlVideo [132] arXiv’23 | 0.930 | 0.201 | 0.950 | 0.210 |
| Tune-A-Video [114] ICCV’23 | 0.924 | 0.204 | 0.937 | 0.206 |
| Pix2Video [8] ICCV’23 | 0.916 | 0.201 | 0.939 | 0.208 |
| RAV [125] SIGGRAPH Asia’24 | 0.909 | 0.196 | 0.928 | 0.201 |
| TokenFlow [30] ICLR’24 | 0.940 | 0.205 | 0.949 | 0.210 |
| InsV2V [18] ICLR’24 | 0.911 | 0.208 | - | - |
| Video-P2P [68] CVPR’24 | 0.935 | 0.201 | - | - |
| CCEdit [26] CVPR’24 | - | - | 0.936 | 0.213 |
| OmniCreator (Ours) | 0.958 | 0.209 | 0.963 | 0.214 |
🔼 Table 6 presents a quantitative comparison of various text-guided video editing methods, focusing specifically on editing types. The comparison uses two established benchmarks: LOVEU-TGVE-2023 and BalanceCC. These benchmarks primarily evaluate the performance of different methods based on four main editing types (Foreground, Background, Overall/Style, and Composite). The table displays the performance of OmniCreator and several other state-of-the-art methods using two automatic metrics: CLIP Frame and PickScore. The inclusion of this table highlights the effectiveness of the OmniCreator model in comparison to other existing methods within a standardized, established evaluation framework.
read the caption
Table 6: Additional Quantitative Comparison on LOVEU-TGVE-2023 and BalanceCC benchmarks, which only focus on editing-type evaluations.
Full paper#