↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video generation models struggle with creating realistic, multi-shot videos due to difficulties in maintaining narrative coherence and visual consistency across multiple scenes. Existing methods often fail to generate videos with logical storylines or smooth transitions between shots.
VideoGen-of-Thought (VGoT) is proposed as a novel solution. This training-free architecture uses a collaborative approach, dividing video generation into distinct modules: script generation, keyframe generation, shot-level video generation, and a smoothing mechanism. This structured approach ensures both reasonable narratives and consistent visuals across shots, significantly improving the quality and coherence of generated multi-shot videos. The results demonstrate VGoT’s superiority to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the significant challenge of generating coherent, multi-shot videos, a limitation of current video generation models. It introduces a novel, collaborative framework that improves upon existing methods by addressing issues of narrative consistency and visual coherence. This work opens new avenues for research in video generation and storytelling.
Visual Insights#

🔼 Figure 1 illustrates the VideoGen-of-Thought (VGoT) framework. Panel (a) compares VGoT to existing multi-shot video generation methods, highlighting VGoT’s ability to maintain consistency and coherence across multiple shots, unlike previous methods. Panel (b) provides a detailed breakdown of the VGoT framework, which consists of four modules: a Script Module that generates detailed shot descriptions from five domains (character, background, relation, camera pose, HDR), a KeyFrame Module that creates keyframes based on these scripts, a Shot-Level Video Module that synthesizes video latents conditioned on keyframes and scripts, and a Smooth Module that ensures seamless transitions for a cohesive narrative.
read the caption
Figure 1: Illustration of VideoGen-of-Thought (VGoT). (a) Comparison of existing methods with VGoT in multi-shot video generation. Existing methods struggle with maintaining consistency and logical coherence across multiple shots, while VGoT effectively addresses these challenges through a multi-shot generation approach. (b) Overview of our proposed framework VGoT, which is consist of the Script Module which generates detailed shot descriptions from five domains, the KeyFrame Module to create keyframes from scripts, the Shot-Level Video Module which synthesizes video latents on conditional with keyframes and scripts, and the Smooth Module ensures seamless transitions across shots, resulting in a cohesive video narrative.
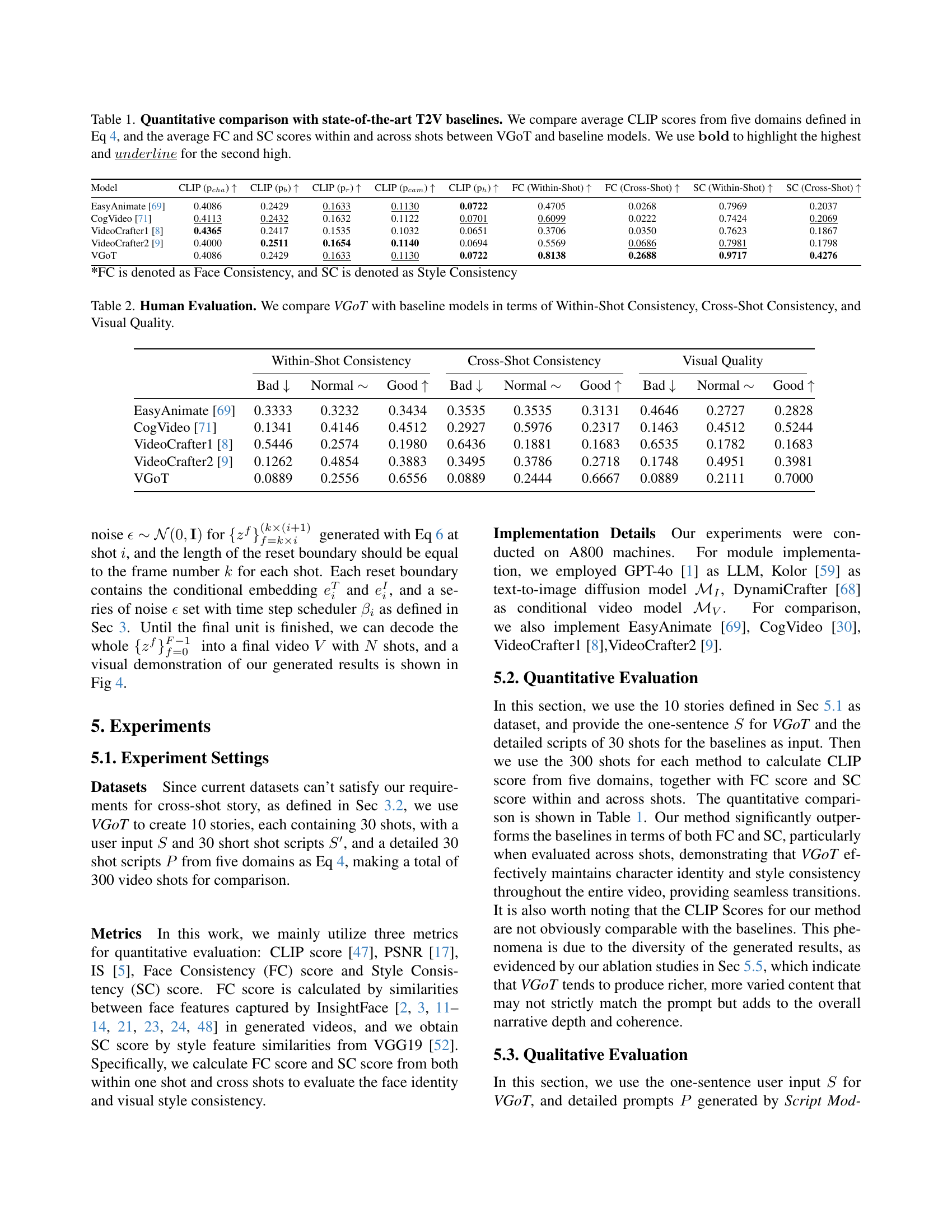
| Model | CLIP (pcha) ↑ | CLIP (pb) ↑ | CLIP (pr) ↑ | CLIP (pcam) ↑ | CLIP (ph) ↑ | FC (Within-Shot) ↑ | FC (Cross-Shot) ↑ | SC (Within-Shot) ↑ | SC (Cross-Shot) ↑ |
|---|---|---|---|---|---|---|---|---|---|
| EasyAnimate [69] | 0.4086 | 0.2429 | 0.1633 | 0.1130 | 0.0722 | 0.4705 | 0.0268 | 0.7969 | 0.2037 |
| CogVideo [71] | 0.4113 | 0.2432 | 0.1632 | 0.1122 | 0.0701 | 0.6099 | 0.0222 | 0.7424 | 0.2069 |
| VideoCrafter1 [8] | 0.4365 | 0.2417 | 0.1535 | 0.1032 | 0.0651 | 0.3706 | 0.0350 | 0.7623 | 0.1867 |
| VideoCrafter2 [9] | 0.4000 | 0.2511 | 0.1654 | 0.1140 | 0.0694 | 0.5569 | 0.0686 | 0.7981 | 0.1798 |
| VGoT | 0.4086 | 0.2429 | 0.1633 | 0.1130 | 0.0722 | 0.8138 | 0.2688 | 0.9717 | 0.4276 |
🔼 Table 1 presents a quantitative comparison of the proposed VideoGen-of-Thought (VGoT) model against several state-of-the-art text-to-video (T2V) baselines. The comparison uses five metrics derived from CLIP scores (assessing character, background, relations, camera pose, and HDR aspects of generated video) and Face Consistency (FC) and Style Consistency (SC) scores (measuring both within-shot and cross-shot consistency). Higher scores indicate better performance. The table highlights the best-performing model for each metric using bold text and the second-best model using underlined text.
read the caption
Table 1: Quantitative comparison with state-of-the-art T2V baselines. We compare average CLIP scores from five domains defined in Eq 4, and the average FC and SC scores within and across shots between VGoT and baseline models. We use 𝕓𝕠𝕝𝕕𝕓𝕠𝕝𝕕\mathbb{bold}blackboard_b blackboard_o blackboard_l blackboard_d to highlight the highest and underline¯¯𝑢𝑛𝑑𝑒𝑟𝑙𝑖𝑛𝑒\underline{underline}under¯ start_ARG italic_u italic_n italic_d italic_e italic_r italic_l italic_i italic_n italic_e end_ARG for the second high.
In-depth insights#
Multi-shot video gen#
Multi-shot video generation is a challenging problem in computer vision because it necessitates not only high-quality video synthesis but also a coherent and consistent narrative across multiple shots. Existing approaches often struggle to maintain visual consistency and logical continuity between scenes, leading to disjointed and unrealistic outputs. A key challenge lies in managing temporal coherence, ensuring smooth transitions and avoiding abrupt shifts in style or content between consecutive shots. Successful multi-shot video generation requires sophisticated methods for planning shot composition, character portrayal, and narrative progression. The integration of techniques from natural language processing, such as story understanding and prompt engineering, shows promise for guiding the generation process and ensuring logical story development across the various shots. A modular architecture, breaking down the task into sub-problems like script generation, keyframe synthesis, and video refinement, can improve the manageability and efficacy of the overall approach. Furthermore, leveraging identity-preserving embeddings to maintain consistency in character appearance across shots is crucial. Future research should focus on developing more robust methods for narrative planning and consistency management, as well as exploring more sophisticated evaluation metrics to assess the quality and coherence of generated multi-shot videos.
Collaborative VGOT#
The concept of “Collaborative VGOT” suggests a multi-faceted approach to video generation, moving beyond single-shot models. Collaboration likely refers to the interaction of multiple modules working in concert. Each module could specialize in a different aspect of video creation, such as script generation, keyframe creation, and video synthesis. This modular design could enhance the coherence and consistency of the final output. The term also implies a departure from traditional training methods, perhaps adopting a training-free or collaborative training approach. This collaborative architecture presents a novel paradigm in video generation, aiming to tackle the challenges of multi-shot video generation. A key strength is potentially greater control over the narrative, improving logical flow and visual consistency, while reducing computational costs associated with large-scale training. However, potential challenges could include the complexity of coordinating multiple modules and ensuring seamless transitions between their outputs. The effectiveness of such a collaborative system ultimately hinges on careful design and interaction of its components.
Prompt engineering#
Prompt engineering plays a crucial role in guiding the performance of large language models (LLMs). Careful crafting of prompts is essential for achieving desired outputs, especially in complex scenarios like multi-shot video generation. The paper highlights the significance of prompt design in ensuring both visual and narrative coherence. The approach presented moves beyond simple instructions, incorporating structured prompts drawing inspiration from cinematic scriptwriting. This structured approach, encompassing character descriptions, background details, relationships, camera angles, and lighting information, facilitates the generation of cohesive narratives across multiple shots. The iterative nature of prompt generation further ensures continuity and logical flow within the generated video sequence. The effectiveness of this method underscores the importance of prompt engineering not merely as input preparation, but as an integral part of the overall generative process. Future directions for this area might involve exploring dynamic prompt adaptation techniques, allowing for more nuanced control over the video generation process in response to the evolving narrative.
Consistency methods#
Consistency methods in video generation aim to address the challenge of creating coherent and believable videos, especially in multi-shot scenarios. Maintaining consistency across shots is crucial, as it significantly impacts the viewer’s experience and overall narrative understanding. These methods tackle various aspects of consistency, including temporal consistency (smooth transitions between shots), visual consistency (consistent style, lighting, and character appearances), and narrative consistency (logical story flow and character development). Approaches often involve sophisticated techniques such as latent space manipulation, cross-attention mechanisms, or identity-preserving embeddings to ensure seamless transitions and visual coherence. A key challenge lies in balancing the need for consistency with the creative freedom necessary to generate diverse and interesting content. Overly rigid methods may hinder creativity, while overly loose methods can compromise believability. Therefore, effective consistency methods strike a delicate balance, ensuring coherence without sacrificing the visual richness and storytelling potential of the generated videos. Future research will likely focus on improving computational efficiency and scalability, while exploring more nuanced approaches to capture the subtle complexities of temporal continuity and narrative consistency.
Future improvements#
Future improvements for multi-shot video generation models like VideoGen-of-Thought could focus on several key areas. Enhancing narrative control is crucial; current methods often struggle with maintaining a truly coherent and compelling storyline across multiple shots. More sophisticated mechanisms for managing character interactions, plot development, and scene transitions are needed. Improving visual fidelity and consistency remains a challenge; while advancements have been made, the generated videos can still suffer from artifacts or inconsistencies in lighting, character appearance, and background details. Addressing these issues requires further research into advanced rendering techniques and better integration of visual elements. Scalability and efficiency are also important considerations; current models are often computationally expensive, limiting their practicality for widespread use. Exploring more efficient architectures and training methods would significantly enhance the usability and accessibility of multi-shot video generation technology. Finally, expanding the scope of supported input modalities is a key area for growth. Moving beyond simple text prompts to accommodate more complex input such as sketches, storyboards, or even natural language descriptions could unlock more creative and expressive video generation capabilities.
More visual insights#
More on figures

🔼 This figure illustrates the workflow of the VideoGen-of-Thought (VGoT) model. Starting with a user prompt (a single sentence describing a short story), the system generates detailed shot descriptions, encompassing character details, background setting, relationships between characters, camera angles, and HDR lighting. These descriptions serve as input for generating consistent keyframes, leveraging text-to-image diffusion models and identity-preserving embeddings to ensure character consistency across shots. These keyframes, along with the shot descriptions, are used to generate individual video clips (shots). Finally, a smoothing mechanism ensures seamless transitions between shots, resulting in a coherent, multi-shot video that reflects the initial story prompt.
read the caption
Figure 2: The FlowChart of VideoGen-of-Thought. Left: Shot descriptions are generated based on user prompts, describing various attributes including character details, background, relations, camera pose, and lighting HDR. Pre-shot descriptions provide a broader context for the upcoming scenes. Middle Top: Keyframes are generated using a text-to-image diffusion model conditioned with identity-preserving (IP) embeddings, which ensures consistent representation of characters throughout the shots. IP portraits help maintain visual identity consistency. Right: The shot-level video clips are generated from keyframes, followed by shot-by-shot smooth inference to ensure temporal consistency across different shots. This collaborative framework ultimately produces a cohesive narrative-driven video.

🔼 Figure 3 presents a visual comparison of videos generated by VideoGen-of-Thought (VGoT) and several baseline methods. All methods are given the same input: a one-sentence prompt instructing them to generate a 30-shot video depicting the life of a classic American woman, Mary, from birth to death. The figure highlights VGoT’s superior ability to generate high-quality, visually consistent, and narratively coherent videos compared to other state-of-the-art approaches.
read the caption
Figure 3: Visual comparison of VGoT and baselines

🔼 This figure showcases several multi-shot videos generated using the VideoGen-of-Thought (VGoT) model. Each video is based on a different one-sentence prompt, highlighting the model’s ability to create coherent and visually appealing videos with multiple shots, from a short, simple story description. The examples illustrate the variety of stories and scenes VGoT can generate, demonstrating its capacity for multi-shot video generation.
read the caption
Figure 4: Visual showcases of VGoT generated multi-shot videos.

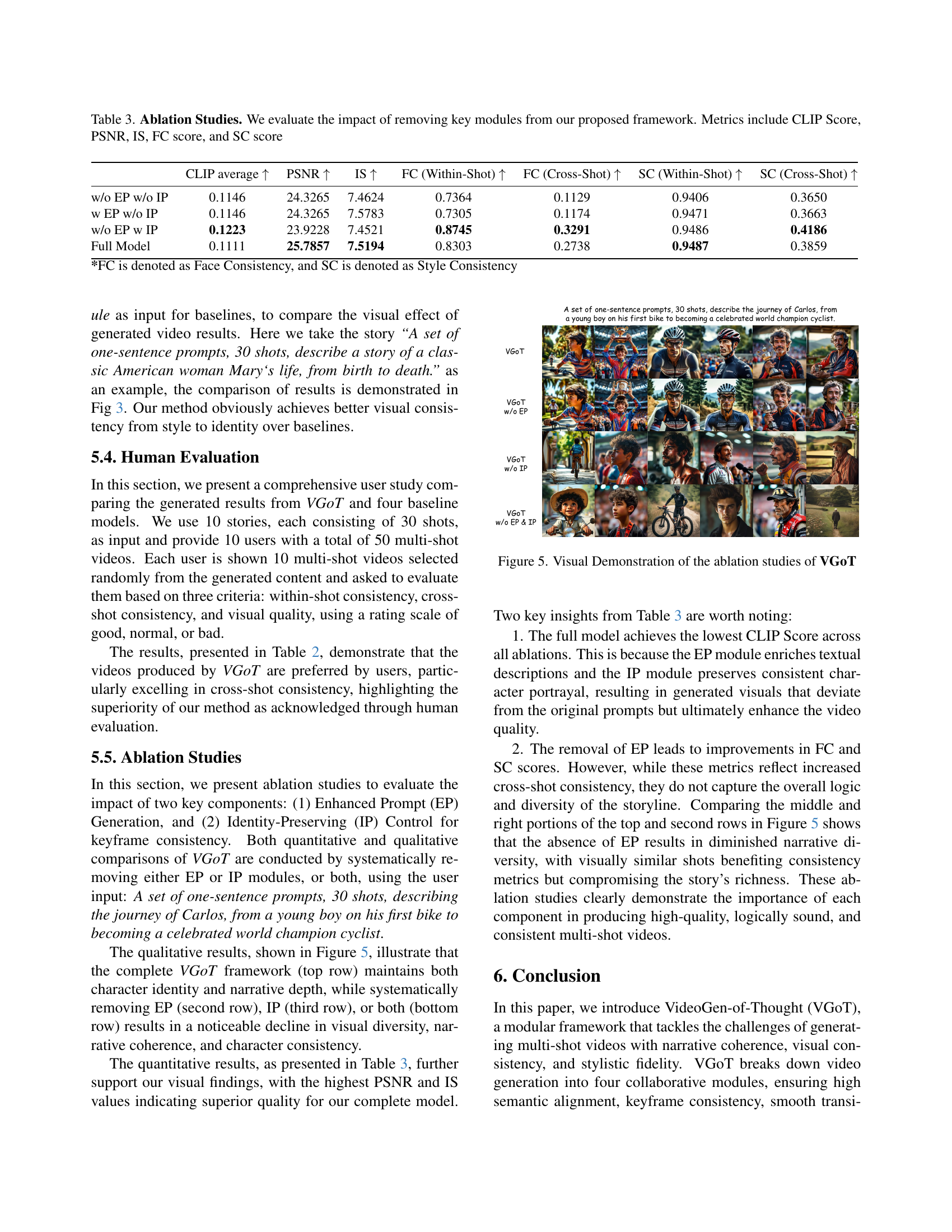
🔼 This figure shows a visual comparison of videos generated by VGoT with and without different components. Specifically, it demonstrates the impact of removing the identity-preserving (IP) embeddings and/or the enhanced prompt (EP) generation on the final video output. By comparing these variations, the figure visually highlights the contributions of each component to the overall quality, consistency, and coherence of the generated multi-shot videos.
read the caption
Figure 5: Visual Demonstration of the ablation studies of VGoT

🔼 This figure showcases visual examples of multi-shot videos generated by the VideoGen-of-Thought (VGoT) model. Each row represents a different story, with multiple shots arranged to display the narrative flow generated by the model. The figure demonstrates the model’s ability to create visually coherent and consistent videos across multiple shots, maintaining character consistency and storytelling throughout.
read the caption
Figure 6: VGoT Visual complement of the multi-camera video generated.

🔼 This figure provides a visual comparison of the multi-shot videos generated by the proposed VideoGen-of-Thought (VGoT) model and four baseline methods (EasyAnimate, CogVideo, VideoCrafter1, VideoCrafter2) across five different story prompts. Each row showcases the videos generated for a particular story, demonstrating the visual differences in the coherence, consistency, and overall quality of the generated videos between VGoT and the baselines. The stories cover a variety of scenarios and involve diverse visual styles.
read the caption
Figure 7: Visual comparison of VGoT with baselines Supplement.
More on tables
| Within-Shot Consistency | Cross-Shot Consistency | Visual Quality | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bad ↓ | Normal ∼ | Good ↑ | Bad ↓ | Normal ∼ | Good ↑ | Bad ↓ | Normal ∼ | Good ↑ | ||
| EasyAnimate [69] | 0.3333 | 0.3232 | 0.3434 | 0.3535 | 0.3535 | 0.3131 | 0.4646 | 0.2727 | 0.2828 | |
| CogVideo [71] | 0.1341 | 0.4146 | 0.4512 | 0.2927 | 0.5976 | 0.2317 | 0.1463 | 0.4512 | 0.5244 | |
| VideoCrafter1 [8] | 0.5446 | 0.2574 | 0.1980 | 0.6436 | 0.1881 | 0.1683 | 0.6535 | 0.1782 | 0.1683 | |
| VideoCrafter2 [9] | 0.1262 | 0.4854 | 0.3883 | 0.3495 | 0.3786 | 0.2718 | 0.1748 | 0.4951 | 0.3981 | |
| VGoT | 0.0889 | 0.2556 | 0.6556 | 0.0889 | 0.2444 | 0.6667 | 0.0889 | 0.2111 | 0.7000 |
🔼 This table presents a human evaluation comparing VideoGen-of-Thought (VGoT) with four baseline models across three key aspects of video generation quality: Within-Shot Consistency (the smoothness and coherence within individual video shots), Cross-Shot Consistency (the smooth transitions and overall coherence across multiple shots), and Visual Quality (the overall clarity, detail, and realism of the video). For each aspect, the table shows the proportion of evaluations that rated each model as ‘Bad’, ‘Normal’, or ‘Good’. This allows for a direct comparison of the subjective quality of videos generated by VGoT and the baselines.
read the caption
Table 2: Human Evaluation. We compare VGoT with baseline models in terms of Within-Shot Consistency, Cross-Shot Consistency, and Visual Quality.
| CLIP average ↑ | PSNR ↑ | IS ↑ | FC (Within-Shot) ↑ | FC (Cross-Shot) ↑ | SC (Within-Shot) ↑ | SC (Cross-Shot) ↑ | |
|---|---|---|---|---|---|---|---|
| w/o EP w/o IP | 0.1146 | 24.3265 | 7.4624 | 0.7364 | 0.1129 | 0.9406 | 0.3650 |
| w EP w/o IP | 0.1146 | 24.3265 | 7.5783 | 0.7305 | 0.1174 | 0.9471 | 0.3663 |
| w/o EP w IP | 0.1223 | 23.9228 | 7.4521 | 0.8745 | 0.3291 | 0.9486 | 0.4186 |
| Full Model | 0.1111 | 25.7857 | 7.5194 | 0.8303 | 0.2738 | 0.9487 | 0.3859 |
🔼 This table presents the results of ablation studies conducted to assess the impact of removing key modules from the proposed VideoGen-of-Thought (VGoT) framework. The studies systematically remove modules to isolate their individual effects. The metrics used to evaluate performance are CLIP Score (a measure of similarity between generated videos and text descriptions), PSNR (Peak Signal-to-Noise Ratio, a measure of image quality), IS (Inception Score, a measure of image quality and diversity), FC score (Face Consistency, evaluating consistency of facial features across shots), and SC score (Style Consistency, measuring consistency of visual style across shots). The table allows for a quantitative comparison of the full model’s performance against versions with one or more modules removed, providing insight into each module’s contribution to the overall system.
read the caption
Table 3: Ablation Studies. We evaluate the impact of removing key modules from our proposed framework. Metrics include CLIP Score, PSNR, IS, FC score, and SC score
Full paper#