↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Retrieval-Augmented Generation (RAG) systems enhance large language models by incorporating external knowledge, often extracted from documents using Optical Character Recognition (OCR). However, OCR errors introduce noise, affecting the quality of the knowledge base and ultimately the RAG system’s performance. This paper investigates the impact of OCR errors.
To address this issue, the researchers created OHRBench, a new benchmark dataset with carefully selected documents and questions. They identified two main types of OCR noise: semantic and formatting noise. Their experiments on various OCR solutions revealed that none consistently produces high-quality results. The study demonstrates the vulnerability of RAG systems to OCR noise and explores the potential of using Vision-Language Models (VLMs) as an alternative to OCR in RAG, showing promising results.
Key Takeaways#
Why does it matter?#
This paper is crucial for RAG system developers and OCR researchers as it reveals the significant impact of OCR errors on RAG performance. It provides a new benchmark (OHRBench) for evaluating OCR solutions in the context of RAG, offering valuable insights for developing more robust and accurate systems. This is highly relevant given the increasing use of RAG systems in various applications. Furthermore, the exploration of VLMs as an alternative to OCR opens exciting new research avenues.
Visual Insights#

🔼 Figure 1 illustrates the creation and evaluation methodology of the OHRBench benchmark. First, a diverse dataset of 350 unstructured PDF documents from six real-world domains is collected. Human experts then extract ground truth structured data, which is then used to generate question-answer pairs (Q&As) based on the multimodal elements within the documents (text, tables, formulas). Second, two knowledge bases are created using this ground truth data: one containing OCR-processed structured data for evaluating existing OCR systems, and another with perturbed data simulating various levels of OCR noise (semantic and formatting) to test the effects of these inaccuracies. Finally, the impact of OCR noise on each component (retrieval, generation, and overall system performance) is systematically evaluated using these knowledge bases and the generated Q&As.
read the caption
Figure 1: Construction of OHRBench and evaluation protocol. (1) Benchmark Dataset: we collect PDF documents from six domains, extract human-verified ground truth structured data, and generate Q&As derived from multimodal document elements. (2) RAG Knowledge Base: OCR Processed Structured Data for benchmarking current OCR solutions and Perturbed Structured Data for assessing the impact of different OCR noise types. (3) Evaluation of OCR impact on each component and the overall RAG system.
| Statistic | Number |
|---|---|
| Documents | 350 |
| - Domain | 6 |
| - Total Pages | 4012 |
| - Avg. Tokens | 482.61/page |
| - Avg. Data Type | 1.45/page |
| Questions | 4598 |
| Avg. Question Token | 18.56 |
| Avg. Answer Token | 7.91 |
| (Evidence Source) | |
| - Text | 3334 (72.5%) |
| - Formula | 872 (19.0%) |
| - Table | 392 (8.5%) |
| (Answer Format) | |
| - Short Text Answer | 2482 (54.4%) |
| - Judgment | 849 (18.5%) |
| - Numeric | 894 (19.4%) |
| - Formula | 354 (7.7%) |
🔼 This table presents a summary of the statistics of the OHRBench dataset, which includes the number of documents, total pages, average tokens per page, average data types per page, question and answer statistics, and the breakdown of evidence sources and answer formats used in the dataset.
read the caption
Table 1: Dataset Statistics
In-depth insights#
OCR Noise Impact#
The impact of OCR noise on Retrieval Augmented Generation (RAG) systems is a critical concern. Imperfect OCR significantly degrades the quality of structured data extracted from unstructured documents, introducing both semantic errors (misrecognitions of words, formulas, etc.) and formatting errors (issues with layout, tables, and styling). This cascading effect negatively impacts all RAG pipeline stages: retrieval is hampered by noisy knowledge bases resulting in irrelevant document selection, while generation suffers due to incoherent or inaccurate input prompts. The analysis reveals semantic noise has a more pervasive effect than formatting noise, consistently degrading performance across various models and components. Addressing this requires improving OCR accuracy, particularly for complex layouts and multimodal elements, and developing RAG systems more robust to noisy inputs, perhaps via advanced techniques like data augmentation or noise-aware training. Investigating techniques beyond OCR, such as directly incorporating image data via vision-language models, shows promise for mitigating the problem.
RAG System Vulner#
A hypothetical section titled “RAG System Vulnerabilities” would explore the inherent weaknesses of Retrieval-Augmented Generation (RAG) systems. A key vulnerability is dependence on the quality of the retrieved information. If the knowledge base is inaccurate, incomplete, or biased, the RAG system will produce flawed outputs, regardless of the LLM’s capabilities. OCR errors are a significant source of such inaccuracies, as demonstrated by the paper. The non-uniform representation of structured data further exacerbates this problem. Another vulnerability is sensitivity to input noise. Minor errors in the retrieved text can significantly alter the LLM’s understanding and generate incorrect or nonsensical results. Therefore, improving OCR accuracy and developing noise-robust LLMs are crucial to mitigating these vulnerabilities. Finally, hallucinations remain a concern, even with factual input. LLMs may still generate incorrect information that’s not grounded in the retrieved context. Addressing RAG system vulnerabilities requires a multifaceted approach involving robust retrieval methods, improved OCR techniques, and advanced LLM architectures designed to handle noisy or incomplete data.
Benchmark: OHRBench#
The OHRBench benchmark, designed for evaluating the cascading impact of Optical Character Recognition (OCR) on Retrieval-Augmented Generation (RAG) systems, presents a significant contribution. Its value stems from addressing the critical, yet often overlooked, issue of OCR noise in RAG pipelines. OHRBench’s unique approach involves creating a dataset of unstructured PDFs across six diverse real-world domains, each containing multimodal elements to realistically simulate challenges in OCR processing. The benchmark doesn’t just evaluate the raw OCR accuracy; it goes deeper. By introducing and quantifying two types of OCR noise (semantic and formatting), it helps researchers analyze the downstream effects of noisy data on various RAG components including retrieval, generation, and overall performance. This fine-grained analysis enables a more thorough understanding of where OCR errors most significantly impact RAG systems and can guide the development of more robust and noise-resilient RAG architectures. Furthermore, OHRBench’s consideration of various existing OCR solutions allows for a comprehensive comparative study, highlighting the strengths and weaknesses of current approaches. The inclusion of questions derived from these multifaceted documents ensures practical relevance. Thus, OHRBench serves as a valuable tool for advancing the field of RAG, pushing it towards greater robustness and accuracy in the face of real-world challenges.
VLM-based RAG#
Vision-Language Models (VLMs) offer a compelling alternative to traditional OCR-based Retrieval Augmented Generation (RAG) systems. VLMs can directly process images of documents, bypassing the often error-prone OCR step. This significantly mitigates the cascading negative effects of OCR noise, particularly semantic and formatting errors, on retrieval and generation accuracy. While VLMs may not yet fully match the performance of high-quality OCR followed by robust RAG pipelines in all scenarios, integrating VLMs with OCR-extracted text as complementary inputs represents a promising hybrid approach. This could leverage the strengths of both methods: VLMs handle complex layouts and multimodal elements well, while OCR provides precise text for situations where VLMs may struggle. Future research should focus on optimizing VLM architectures and training data for document understanding to further enhance their performance in RAG applications, and investigating effective fusion strategies to combine VLM and OCR outputs for optimal results. The potential for improved robustness and accuracy makes VLM-based or hybrid VLM/OCR RAG approaches a significant area of ongoing research.
Future Research#
Future research directions stemming from the paper “OCR Hinders RAG” could explore several promising avenues. Improving OCR robustness is paramount; this might involve training OCR models on datasets specifically designed to mimic the complexities of real-world document layouts and multimodal elements. Furthermore, investigating the synergy between VLMs and OCR is crucial. While VLMs offer a compelling alternative to OCR in RAG, combining both approaches (leveraging OCR for textual data and VLMs for image data) could yield even more accurate and robust results. Developing more sophisticated noise-handling techniques for RAG is another key area. This could involve creating novel LLM architectures that are more resilient to noisy input data or developing advanced data cleaning methods specifically designed for knowledge bases. Finally, exploring diverse OCR solutions tailored for specific document types within the RAG context would greatly advance the system’s performance. By focusing on these directions, future research can significantly improve the accuracy and reliability of RAG systems, particularly in scenarios involving complex and unstructured data.
More visual insights#
More on figures

🔼 Figure 2 illustrates the complexity of document layouts within the OHRBench dataset. The dataset includes a diverse range of documents from various domains, and this figure highlights the prevalence of different layout features. Each number displayed on the image represents the quantity of PDF pages possessing a particular attribute (such as ‘Multi-Elements Pages’, ‘Hard Reading Order’, ‘Complex Formula’, ‘Complex Table’, or ‘High Text Density’). These attributes represent challenges in creating high-quality knowledge bases for RAG systems, because of the complex layouts present in the documents. For a detailed definition of each attribute, please refer to Appendix Section II of the paper.
read the caption
Figure 2: The layout of documents in OHRBench is complex. Each number indicates the count of PDF pages with that attribute. Criteria for these attributes can be found in Appendix Sec. II

🔼 This figure showcases how semantic noise from OCR impacts different data types. Three levels of noise (mild, moderate, severe) are applied to examples of plain text, equations, and tables. Each example demonstrates the type and severity of errors introduced by OCR, illustrating how inaccuracies cascade through different data representations. These perturbed examples are derived from actual OCR results to enhance realism.
read the caption
Figure 3: Illustration of different levels of Semantic Noise on plain text, equation, and table, which are all perturbed based on existing OCR results.

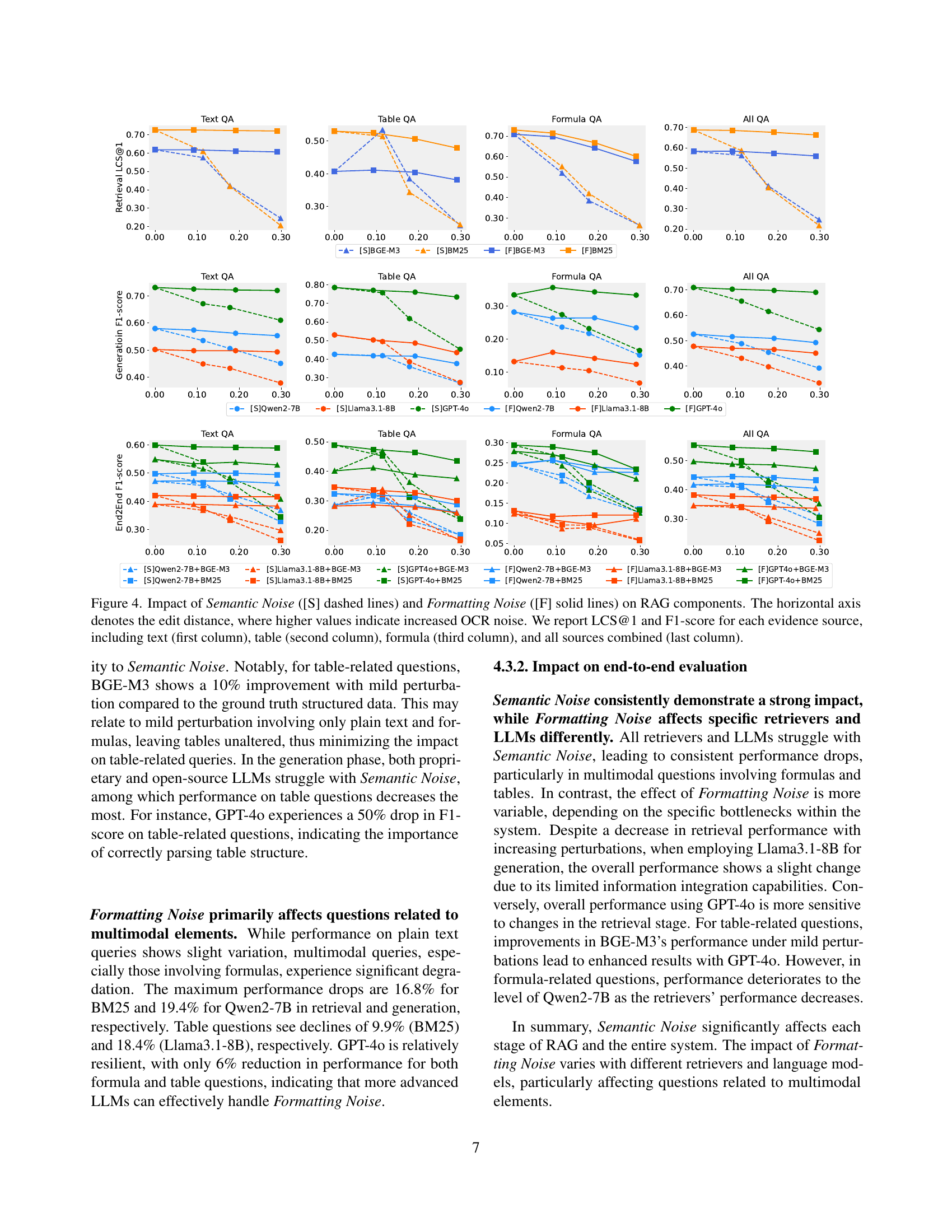
🔼 This figure analyzes the effects of OCR errors (Semantic and Formatting Noise) on various components of Retrieval Augmented Generation (RAG) systems. The x-axis represents the degree of OCR error, measured by edit distance (higher values = more error). The y-axis shows the performance metrics LCS@1 (retrieval) and F1-score (generation). Results are presented for different evidence types (text, tables, formulas) and a combined measure showing the overall performance of RAG. This visualization allows for a comparison of the impact of each noise type across multiple evidence sources.
read the caption
Figure 4: Impact of Semantic Noise ([S] dashed lines) and Formatting Noise ([F] solid lines) on RAG components. The horizontal axis denotes the edit distance, where higher values indicate increased OCR noise. We report LCS@1 and F1-score for each evidence source, including text (first column), table (second column), formula (third column), and all sources combined (last column).

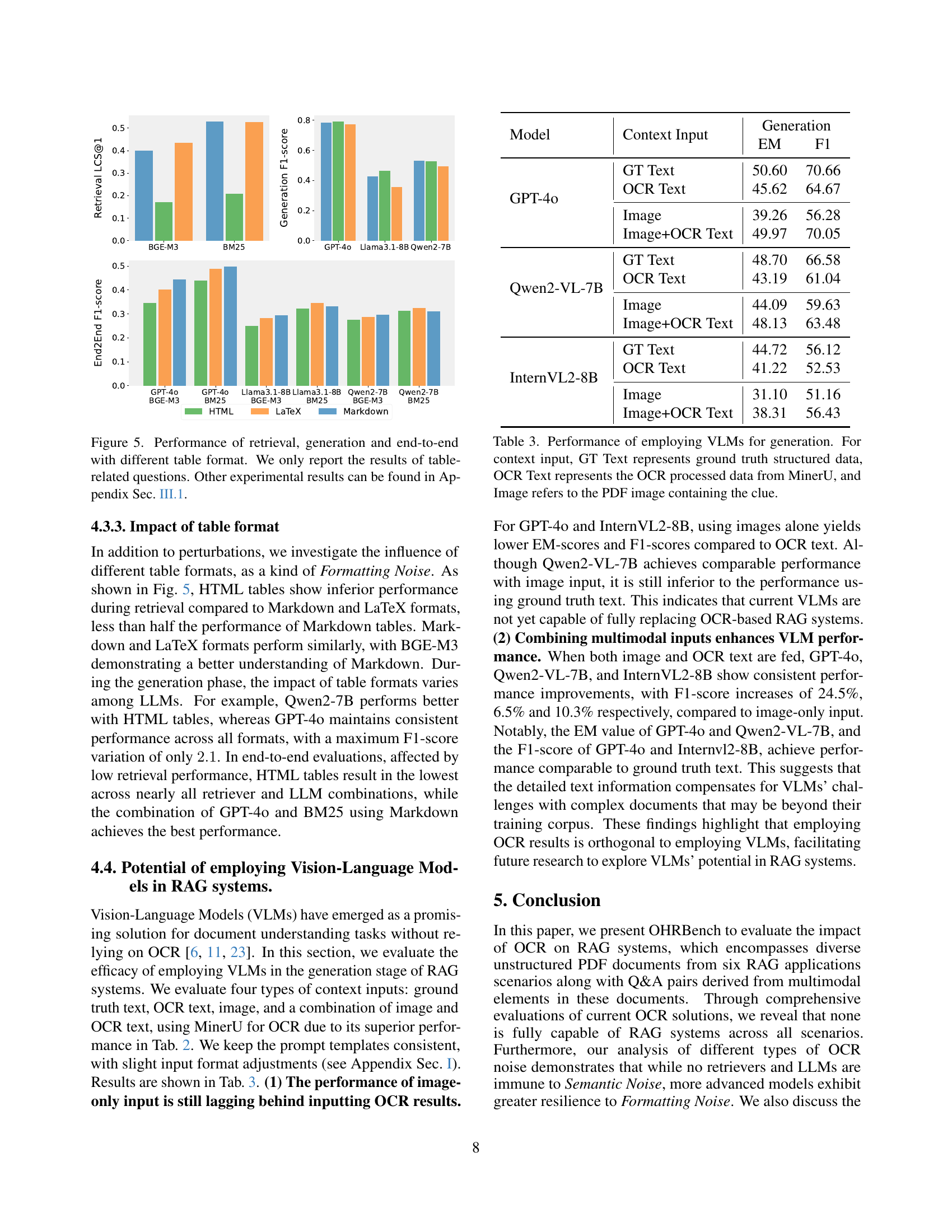
🔼 This figure displays the performance of different components of a Retrieval-Augmented Generation (RAG) system when dealing with tables in various formats. It shows how the choice of table format (Markdown, LaTeX, HTML) affects the retrieval of relevant information, the generation of answers by large language models, and the overall end-to-end performance of the RAG system. Only results related to questions about tables are included in the figure; other experimental results are detailed in Appendix Section III.1.
read the caption
Figure 5: Performance of retrieval, generation and end-to-end with different table format. We only report the results of table-related questions. Other experimental results can be found in Appendix Sec. III.1.

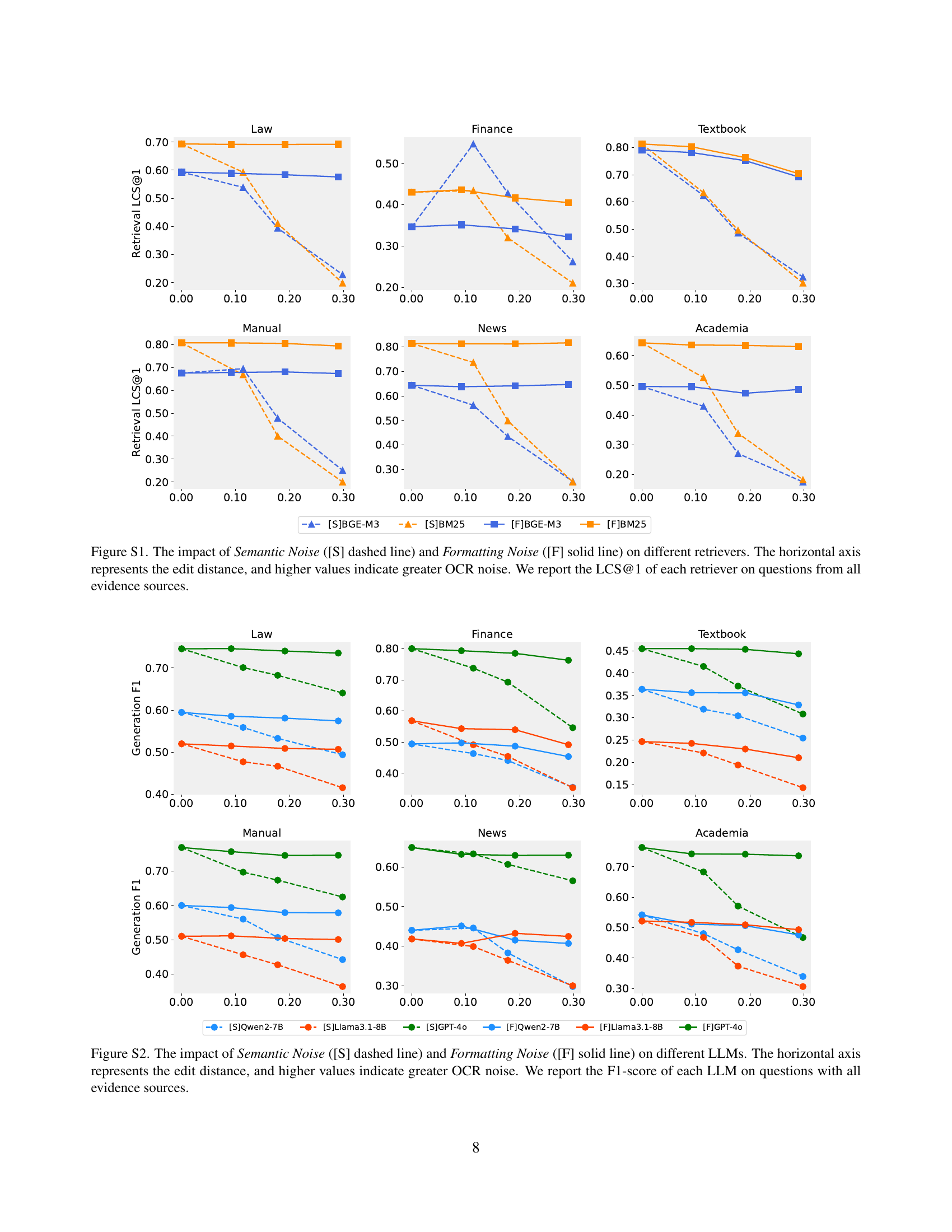
🔼 This figure illustrates how different types of noise introduced by OCR affect the performance of two different retrieval methods (BGE-M3 and BM25) across six real-world datasets. The x-axis represents the amount of OCR error, measured by edit distance. A higher edit distance indicates more error. The y-axis shows the retrieval performance, specifically the LCS@1 score (Longest Common Subsequence at rank 1), which measures the accuracy of retrieving the correct answer. Separate lines are shown for Semantic Noise and Formatting Noise. The plot allows for a comparison of the two retrieval methods under varying levels of each noise type across datasets.
read the caption
Figure S1: The impact of Semantic Noise ([S] dashed line) and Formatting Noise ([F] solid line) on different retrievers. The horizontal axis represents the edit distance, and higher values indicate greater OCR noise. We report the LCS@1 of each retriever on questions from all evidence sources.

🔼 This figure displays the effects of Semantic Noise and Formatting Noise on the performance of various Large Language Models (LLMs). The x-axis represents the ’edit distance,’ a measure of how different the OCR-processed text is from the original text; a higher edit distance means more noise. The y-axis shows the F1-score, a metric evaluating the accuracy of the LLM’s answers, considering both precision and recall. Separate lines represent each LLM’s performance when using either Semantic Noise ([S]) or Formatting Noise ([F]). The results are aggregated across all question types and show how the introduced noise impacts the ability of LLMs to generate accurate answers.
read the caption
Figure S2: The impact of Semantic Noise ([S] dashed line) and Formatting Noise ([F] solid line) on different LLMs. The horizontal axis represents the edit distance, and higher values indicate greater OCR noise. We report the F1-score of each LLM on questions with all evidence sources.

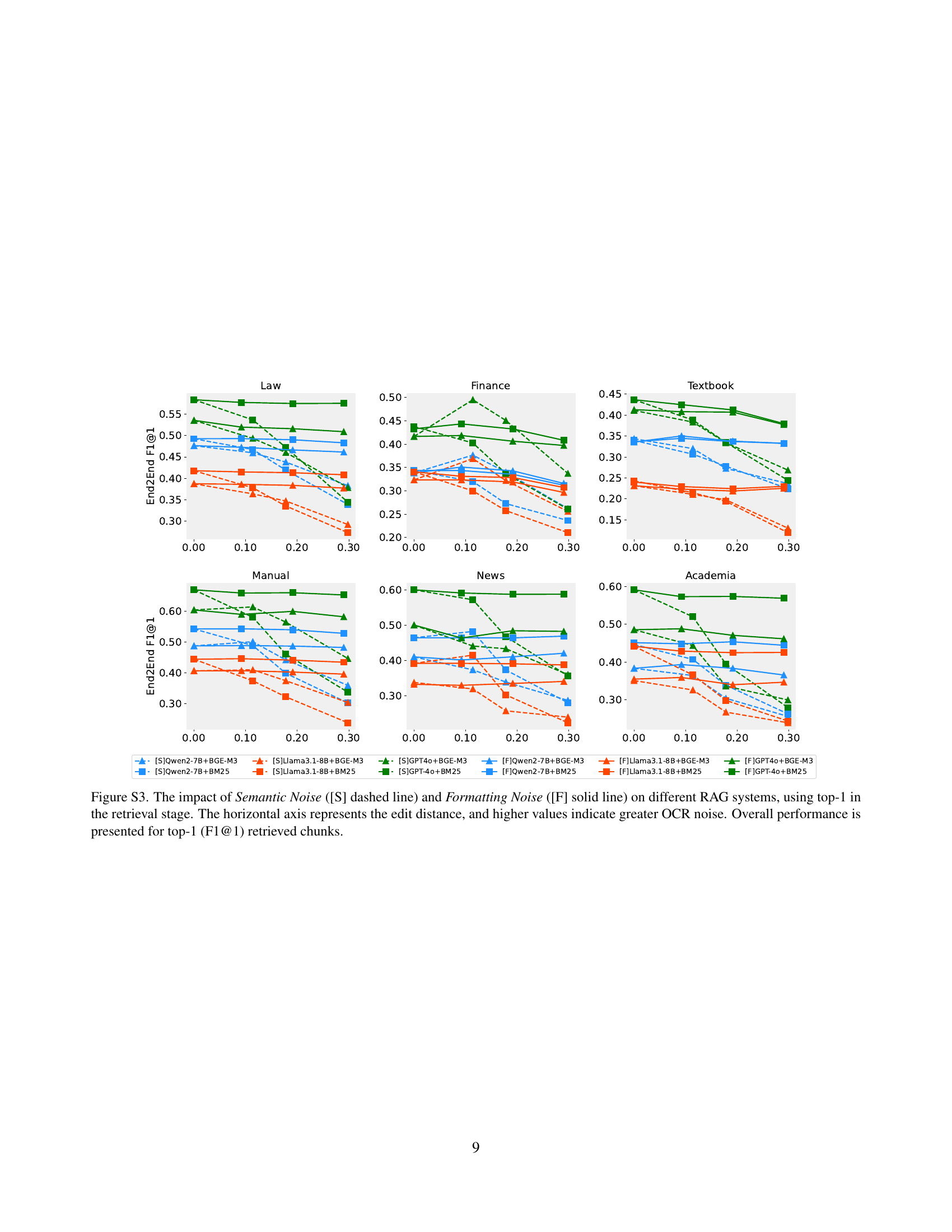
🔼 Figure S3 illustrates how different types of OCR noise (semantic and formatting) impact the overall performance of various RAG systems. The x-axis represents the edit distance, a measure of how different the OCR output is from the ground truth. Higher edit distance indicates more OCR noise. The y-axis shows the F1@1 score, a measure of the accuracy of the top-retrieved chunk in the retrieval step, for each RAG system. The graph demonstrates how increasing OCR noise reduces the accuracy of retrieval and overall system performance across different RAG models.
read the caption
Figure S3: The impact of Semantic Noise ([S] dashed line) and Formatting Noise ([F] solid line) on different RAG systems, using top-1 in the retrieval stage. The horizontal axis represents the edit distance, and higher values indicate greater OCR noise. Overall performance is presented for top-1 (F1@1) retrieved chunks.

🔼 This figure illustrates the generation of perturbed table data to simulate OCR errors. The upper-left quadrant shows the ground truth table, while the upper-right shows the output from the MinerU OCR system, demonstrating the types of errors introduced. The lower-left and lower-right quadrants depict tables with moderate and severe perturbations applied based on the errors observed in the MinerU output. These perturbed tables were created to incorporate the identified errors into the benchmark, simulating real-world scenarios and testing the robustness of the RAG systems. Manual modifications to the LaTeX code were made to ensure clear display of the table structure.
read the caption
Figure S4: One of the real table cases used to guide the introduction of Semantic Noise. The upper left is the original table in the ground truth, and the upper right is a real example from the OCR result of MinerU. The lower left and lower right are the results of moderate and severe perturbation to the original table after using the real example as guidance. For a better show, we modified some latex codes manually so that most part of the table structure can be displayed normally.
More on tables
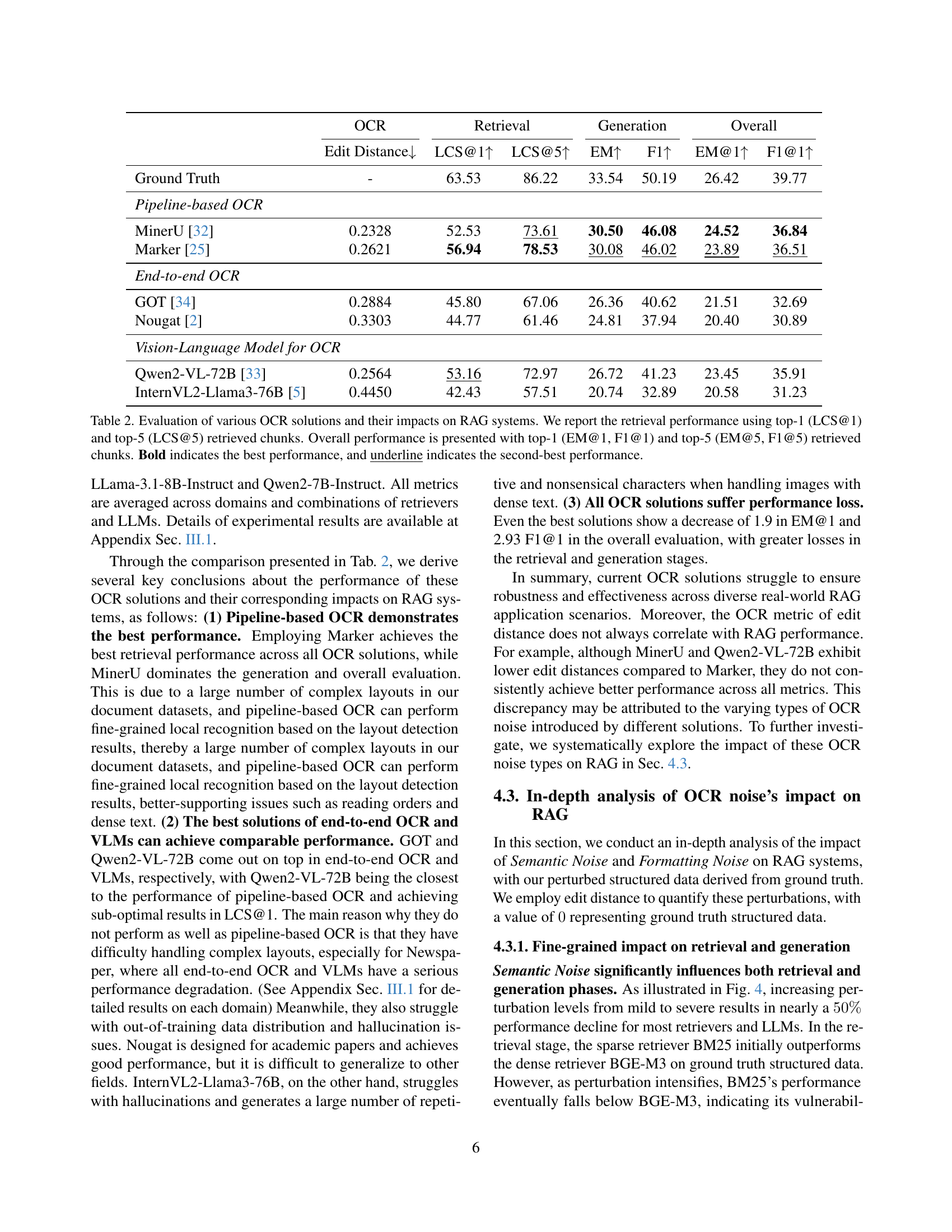
| Metric | OCR | Retrieval | Generation | Overall | |||
|---|---|---|---|---|---|---|---|
| Edit Distance ↓ | LCS@1 ↑ | LCS@5 ↑ | EM ↑ | F1 ↑ | EM@1 ↑ | F1@1 ↑ | |
| Ground Truth | - | 63.53 | 86.22 | 33.54 | 50.19 | 26.42 | 39.77 |
| Pipeline-based OCR | |||||||
| MinerU [32] | 0.2328 | 52.53 | 73.61 | 30.50 | 46.08 | 24.52 | 36.84 |
| Marker [25] | 0.2621 | 56.94 | 78.53 | 30.08 | 46.02 | 23.89 | 36.51 |
| End-to-end OCR | |||||||
| GOT [34] | 0.2884 | 45.80 | 67.06 | 26.36 | 40.62 | 21.51 | 32.69 |
| Nougat [2] | 0.3303 | 44.77 | 61.46 | 24.81 | 37.94 | 20.40 | 30.89 |
| Vision-Language Model for OCR | |||||||
| Qwen2-VL-72B [33] | 0.2564 | 53.16 | 72.97 | 26.72 | 41.23 | 23.45 | 35.91 |
| InternVL2-Llama3-76B [5] | 0.4450 | 42.43 | 57.51 | 20.74 | 32.89 | 20.58 | 31.23 |
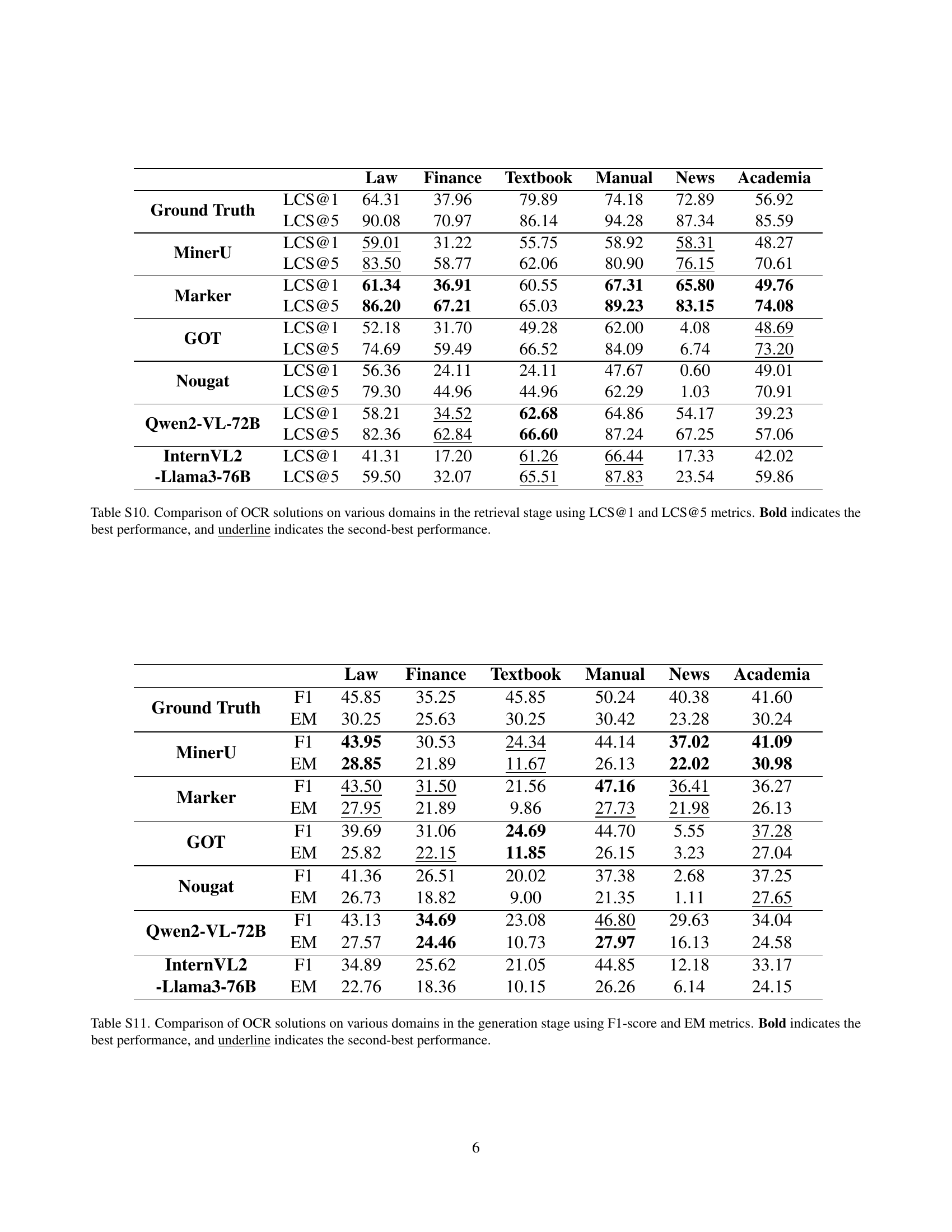
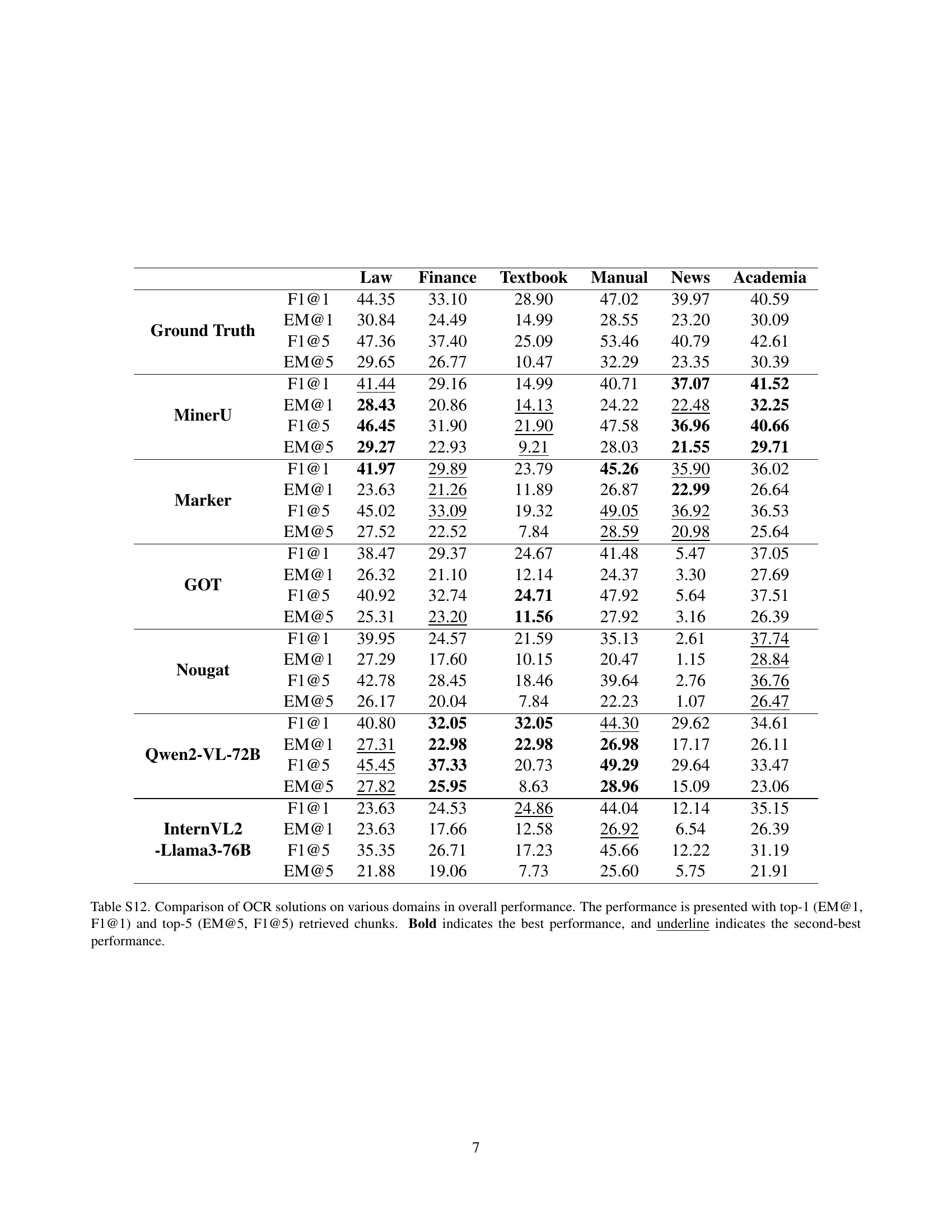
🔼 This table presents a comprehensive evaluation of different Optical Character Recognition (OCR) methods on their impact on Retrieval-Augmented Generation (RAG) systems. It compares the performance of various OCR solutions, including pipeline-based, end-to-end, and vision-language models, across multiple metrics. The metrics used include edit distance (to assess OCR accuracy), top-1 and top-5 Longest Common Subsequence (LCS) scores for retrieval (to measure how well the retrieved chunks matched the ground truth), and exact match (EM) and F1 scores for generation (to evaluate the quality of LLM answers generated based on the retrieved information). The table highlights the best and second-best performing OCR solutions for each metric, providing insights into the relative strengths and weaknesses of each approach in a RAG context.
read the caption
Table 2: Evaluation of various OCR solutions and their impacts on RAG systems. We report the retrieval performance using top-1 (LCS@1) and top-5 (LCS@5) retrieved chunks. Overall performance is presented with top-1 (EM@1, F1@1) and top-5 (EM@5, F1@5) retrieved chunks. Bold indicates the best performance, and underline indicates the second-best performance.
| Model | Context Input | Generation EM | Generation F1 |
|---|---|---|---|
| GPT-4o | GT Text | 50.60 | 70.66 |
| OCR Text | 45.62 | 64.67 | |
| Image | 39.26 | 56.28 | |
| Image+OCR Text | 49.97 | 70.05 | |
| Qwen2-VL-7B | GT Text | 48.70 | 66.58 |
| OCR Text | 43.19 | 61.04 | |
| Image | 44.09 | 59.63 | |
| Image+OCR Text | 48.13 | 63.48 | |
| InternVL2-8B | GT Text | 44.72 | 56.12 |
| OCR Text | 41.22 | 52.53 | |
| Image | 31.10 | 51.16 | |
| Image+OCR Text | 38.31 | 56.43 |
🔼 This table presents the performance of Vision-Language Models (VLMs) in text generation for RAG systems. Four different types of input contexts are compared: ground truth structured text, OCR-processed text from MinerU, the image from the PDF, and a combination of both image and OCR text. The evaluation metrics are Exact Match (EM) and F1 score, assessing the accuracy and completeness of the generated text.
read the caption
Table 3: Performance of employing VLMs for generation. For context input, GT Text represents ground truth structured data, OCR Text represents the OCR processed data from MinerU, and Image refers to the PDF image containing the clue.
| Domains | PDFs | Pages | Pages with Q&As |
|---|---|---|---|
| Law | 60 | 918 | 505 |
| Finance | 12 | 1733 | 235 |
| Textbook | 133 | 133 | 133 |
| Manual | 15 | 932 | 225 |
| Newspaper | 116 | 116 | 116 |
| Academia | 10 | 204 | 156 |
| Total | 350 | 4012 | 1370 |
🔼 Table S1 provides a detailed breakdown of the dataset used in the OHRBench benchmark. It shows the distribution of PDF documents across six real-world application domains (Law, Finance, Textbook, Manual, News, and Academia). For each domain, the table lists the number of documents, total number of pages in those documents, and the number of pages that contain questions and answers (Q&As) used in the benchmark’s evaluation. This information is crucial for understanding the scale and diversity of the dataset, as well as the balance of data across different domains.
read the caption
Table S1: Document statistics of each domain
| Attribute | Counts | Description |
|---|---|---|
| Multi-Elements Pages | 1848 | Pages containing at least two types of elements, such as text, images, tables, and formulas. |
| Hard Reading Order | 1025 | Pages not presented in a single-column format. |
| Complex Formula | 1924 | Pages with formulas requiring at least 10 tokens for description. |
| Complex Table | 1283 | Pages with tables having more than 4 rows or columns, or containing merged cells. |
| High Text Density | 1003 | Pages with more than 800 tokens (separated by spaces). |
🔼 Table S2 details the characteristics of the PDF documents included in the OHRBench dataset. It lists five attributes representing common complexities found in real-world documents: the presence of multiple data types (text, formulas, tables), non-standard reading order, complex formulas, complex tables, and high text density. For each attribute, the table provides a count of how many pages in the dataset exhibit that characteristic, offering a quantitative measure of document complexity.
read the caption
Table S2: Counts and description of each attribute which is present in our datasets
🔼 This table presents the prompt template used for generating question-answer pairs for the OHRBench benchmark dataset. The prompt instructs GPT-4 to generate RAG-style questions with varying difficulty levels (Easy, Medium, Hard), ensuring the questions are self-contained and do not rely on external knowledge, while including specific constraints on entity mention and answer diversity. The output should be a JSON object with the question, answer, context (verbatim excerpt from the document), difficulty level, answer format, and evidence source.
read the caption
Table S3: Q&A Generation Prompt
| System | |
|---|---|
| System: | You are an expert, you have been provided with a question and documents retrieved based on that question. Your task is to search the content and answer these questions using the retrieved information. |
| You MUST answer the questions briefly with one or two words or very short sentences, devoid of additional elaborations. | |
| Write the answers within | |
| User: | |
| Question: {question} | |
| Retrieved Documents: {retrieved_documents} |
🔼 This table presents the prompt template used for Large Language Models (LLMs) during the Retrieval-Augmented Generation (RAG) process. It shows the instructions given to the LLM to ensure that the responses are concise and accurate, using only the provided information without additional elaborations. The prompt emphasizes retrieving the precise answer directly from the provided source document.
read the caption
Table S4: LLMs prompt for RAG generation
| System | User | |
|---|---|---|
| You are an expert, you have been provided with a question and a document image retrieved based on that question. Your task is to answer the question using the content from the given document image. | Question: {question} | |
| You MUST answer the questions briefly with one or two words or very short sentences, devoid of additional elaborations. | ||
| Write the answers within <response></response> |
🔼 This table presents the prompt template used for generating responses using Vision-Language Models (VLMs) when only the image of the document is provided as input. It shows the instructions given to the VLM to ensure it answers concisely, using only one or two words or very short sentences.
read the caption
Table S5: Prompt template for VLM generation with image-only inputs
| System: | |
|---|---|
| You are an expert, you have been provided with a question, a document image, and its OCR result retrieved based on that question. Your task is to search for the content and answer these questions using both the retrieved information and the document image. | |
| You MUST answer the questions briefly with one or two words or very short sentences, devoid of additional elaborations. | |
| Write the answers within <response></response>. | |
| User: | |
| Question: {question} | |
| Retrieved Documents: {retrieved_documents} |
🔼 This table presents the prompt template used for Vision-Language Models (VLMs) in the RAG system when both image and text are used as inputs. It outlines instructions given to the VLM to generate a concise answer (one or two words or a very short sentence) to a given question using the combined image and OCR-processed text.
read the caption
Table S6: Prompt template for VLM generation with image+text inputs
| Simple Prompt: | |
|---|---|
| Please do OCR on the image and give all the text content in markdown format. The formula should be wrapped in $$ and the table should be parsed in LaTeX format. Only output the OCR results without any extra explanations or comments. |
| Detailed Prompt: | |
|---|---|
| You are a powerful OCR assistant tasked with converting PDF images to Markdown format. You MUST obey the following criteria: |
- Plain text processing:
- Precisely recognize all text in the PDF image without making assumptions in Markdown format.
- Formula Processing:
- Convert all formulas to LaTeX.
- Use $ $ to wrap inline formulas.
- Use $$ $$ to wrap block formulas.
- Table Processing:
- Convert tables to LaTeX.
- Use \begin{table} \end{table} to wrap tables.
- Figure Handling:
- Ignore figures from the PDF image; do not describe or convert images.
- Output Format:
- Ensure the Markdown output has a clear structure with appropriate line breaks.
- Maintain the original layout and format as closely as possible.
Follow these guidelines strictly to ensure accurate and consistent conversion. Only output the OCR results without any extra explanations or comments.|
🔼 This table presents the prompt templates used for training Vision-Language Models (VLMs) for Optical Character Recognition (OCR) in the context of the OHRBench benchmark. It details two prompt options: a simple prompt providing basic instructions for OCR, and a detailed prompt giving more specific directions to ensure accuracy and consistency in the extracted data. The detailed instructions cover plain text processing, formula conversion, table parsing, and image handling, with specific formatting requirements in Markdown and LaTeX. The goal is to generate high-quality structured data for use in RAG systems.
read the caption
Table S7: Prompt template for VLMs OCR
| System | ||
|---|---|---|
| System: | You are able to mimic the various errors introduced in OCR recognition. You are given examples with ground truth and OCR results with errors. Your job is to refer to the examples and generate three samples with increasing perturbations based on the user input. | |
| The new perturbed document could include the following OCR errors: | ||
| 1. formatting issues, character recognition errors (like misrecognized letters or numbers), and slight variations in wording. | ||
| 2. Redundant content and typos for plain text and formula. | ||
| 3. Randomly add and delete table structure controlling character ‘&’ for tabular data. | ||
| 4. Randomly add extra columns and rows for tabular data. | ||
| 5. Randomly make misaligned columns and rows for tabular data. | ||
| - In the first perturbed document, make mild perturbation with 10% changes. | ||
| - In the second perturbed document, make moderate perturbation with 30% changes. | ||
| - In the third perturbed document, make severe perturbation with 50% changes. | ||
| Output the three perturbed documents within | ||
| You should refer to the following perturbed example to generate the perturbed document. | ||
| Example ground truth: | {gt_sample} | |
| Example results with mild perturbation: | {mild_sample} | |
| Example results with moderate perturbation: | {moderate_sample} | |
| Example results with severe perturbation: | {severe_sample} | |
| User: |
🔼 This table presents the prompt template used to introduce semantic noise into the dataset. The prompt instructs the model to mimic OCR errors (typos, misrecognized numbers/letters, slight wording variations, redundant content, table structure errors) based on provided examples of ground truth and perturbed data, generating samples with increasing levels of noise (mild, moderate, severe). The prompt includes examples of original, mildly, moderately, and severely perturbed data for reference. The goal is to create a more realistic and challenging dataset that reflects the imperfections commonly found in real-world OCR outputs.
read the caption
Table S8: Prompt template for Semantic Noise introduction
| Retrieval | Generation | Overall | ||||
|---|---|---|---|---|---|---|
| LCS@1 ↑ | LCS@5 ↑ | EM ↑ | F1 ↑ | EM@1 ↑ | F1@1 ↑ | |
| Simple Prompt | ||||||
| Qwen2-VL-72B | 52.50 | 72.27 | 26.29 | 40.65 | 23.09 | 35.30 |
| InternVL2-Llama3-76B | 41.23 | 57.31 | 20.07 | 32.36 | 20.03 | 30.40 |
| Detailed Prompt | ||||||
| Qwen2-VL-72B | 53.16 | 72.97 | 26.72 | 41.23 | 23.45 | 35.91 |
| InternVL2-Llama3-76B | 42.43 | 57.51 | 20.74 | 32.89 | 20.58 | 31.23 |
🔼 This table presents a comparison of the performance of Vision-Language Models (VLMs) for Optical Character Recognition (OCR) when using different prompts. It shows that a more detailed prompt consistently yields superior OCR results compared to a simpler prompt. This highlights the importance of prompt engineering for optimizing VLM performance in OCR tasks.
read the caption
Table S9: Effects of Different OCR Prompts on VLMs for OCR. The detailed prompt is used due to its consistently superior performance.
Full paper#