↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) show impressive performance in many areas but struggle with basic audio-visual understanding, as highlighted by a new test called DeafTest. This test revealed that even advanced MLLMs struggle with simple tasks such as identifying louder or higher-pitched sounds, revealing a critical gap in their audio processing capabilities.
To address this issue, the researchers introduced AV-Odyssey Bench, a comprehensive benchmark containing 4,555 carefully designed questions involving text, images, and audio. This benchmark challenges MLLMs to integrate information from all three modalities to accurately answer questions. The results from AV-Odyssey show that even state-of-the-art models underperform significantly. This signifies a need for more advanced models and datasets focused on robust audio-visual integration.
Key Takeaways#
Why does it matter?#
This paper is crucial for multimodal LLM research because it reveals significant limitations in current models’ ability to understand audio-visual information. It introduces a novel benchmark, AV-Odyssey, for more comprehensive evaluation and paves the way for future dataset creation and model development that better integrate audio-visual cues. The DeafTest, used to evaluate basic listening abilities, also serves as a critical tool for highlighting fundamental limitations. This work addresses a crucial gap in the field, setting a new standard for evaluating multimodal models.
Visual Insights#

🔼 DeafTest is an evaluation benchmark consisting of four simple audio tasks designed to assess the fundamental audio understanding capabilities of multimodal large language models (MLLMs). Figure 1 showcases two of these tasks: loudness comparison and pitch comparison. In the loudness comparison task, the MLLM is presented with two audio clips and asked to identify which is louder. The pitch comparison task involves determining which of two audio clips has a higher pitch. These tasks assess the basic audio processing abilities of MLLMs before more complex reasoning is required, helping to determine if the model can truly ‘hear’ and interpret simple auditory information.
read the caption
Figure 1: Illustration of two out of four DeafTest tasks. Loudness comparison is used to determine the louder sound of two given sounds. Pitch comparison is to determine which sound has the higher pitch.
| Method | Sound Counting | Loudness Comparison | Pitch Comparison | Duration Comparison |
|---|---|---|---|---|
| Random | 50.0 | 50.0 | 50.0 | 50.0 |
| Gemini 1.5 Flash [70] | 55.0 | 62.0 | 54.0 | 89.0 |
| Gemini 1.5 Flash-8B [70] | 49.0 | 55.0 | 51.0 | 51.0 |
| Gemini 1.5 Pro [70] | 81.0 | 60.0 | 52.0 | 84.0 |
| Reka Core [71] | 54.0 | 43.0 | 42.0 | 40.0 |
| Reka Flash [71] | 48.0 | 58.0 | 51.0 | 44.0 |
| Reka Edge [71] | 47.0 | 56.0 | 50.0 | 44.0 |
| GPT-4o audio-preview [27] | 50.0 | 58.0 | 58.0 | 57.0 |
🔼 This table presents the results of four basic auditory tasks from the DeafTest, designed to evaluate the fundamental listening abilities of multimodal large language models (MLLMs). The tasks assess the models’ performance on simple auditory discriminations, including sound counting, loudness comparison, pitch comparison, and duration comparison. Each task is a two-choice question, meaning the model must select one of two options. The random baseline performance for these two-choice questions is 50%, providing a context for evaluating the model’s actual performance. The table shows the performance of several MLLMs (Gemini 1.5 Flash, Gemini 1.5 Flash-8B, Gemini 1.5 Pro, Reka Core, Reka Flash, Reka Edge, and GPT-40 Audio-preview) on each of the four tasks, expressed as percentages. This allows for a direct comparison of how well these models perform on these basic audio processing tasks compared to random chance.
read the caption
Table 1: Results on four basic auditory tasks (DeafTest). The questions are designed as two-choice questions. The random baseline performance is 50%.
In-depth insights#
Multimodal LLM Limits#
Multimodal LLMs, while showing promise, reveal significant limitations in truly understanding audio-visual information. DeafTest, a benchmark focusing on fundamental auditory tasks, highlights these models’ struggles with simple sound discrimination (loudness, pitch, duration), suggesting a core deficiency in basic audio processing. This is further supported by the AV-Odyssey Benchmark, which shows that even complex, multi-modal tasks are not accurately solved. The results indicate a shallow understanding of audio-visual relationships. Models often fail to correctly integrate audio cues, even in scenarios where visual information is abundant. Therefore, current multimodal LLMs primarily demonstrate surface-level pattern recognition rather than deep semantic understanding of audio-visual content. Further research and improved datasets are crucial to bridge this gap and develop models with improved audio-visual reasoning abilities.
AV-Odyssey Bench#
The AV-Odyssey Bench is a comprehensive benchmark designed to rigorously evaluate the true audio-visual understanding capabilities of Multimodal Large Language Models (MLLMs). It addresses limitations of existing benchmarks by incorporating diverse audio attributes, extensive domains, and interleaved audio-visual inputs. The benchmark’s design goes beyond simple pattern recognition and necessitates the models to truly integrate clues from both visual and audio streams for accurate inference. This focus makes the AV-Odyssey Bench a critical tool for evaluating progress in MLLM development, providing valuable insights for dataset creation and model improvement by focusing on the often-overlooked aspects of fundamental audio-visual processing.
DeafTest Results#
A hypothetical ‘DeafTest Results’ section would present a crucial analysis of basic audio comprehension in multimodal large language models (MLLMs). The results would likely reveal significant shortcomings, demonstrating that even simple auditory tasks, such as distinguishing loudness or pitch, pose considerable challenges for these advanced models. This finding would be particularly insightful because it highlights a foundational weakness: while MLLMs may excel at complex reasoning, their ability to process fundamental audio features is unexpectedly weak. The low accuracy rates across various tasks would underscore the need for improved training data and model architectures that better integrate and utilize low-level auditory information. A detailed breakdown by task, model, and metric would further enhance understanding of where these models currently fall short, and suggest specific areas of development for future model improvement. The contrast between human performance (near-perfect) and MLLM performance (significantly lower) would strongly emphasize the need for more robust evaluation benchmarks. The section would also, therefore, suggest avenues for future research to bridge this gap in audio understanding.
Audio-Visual Int.#
The heading ‘Audio-Visual Int.’ likely refers to the integration and interplay of audio and visual information within a multimodal model. A thoughtful exploration would examine how these modalities are fused, the challenges of multimodal alignment (matching audio events to visual elements), and the potential for emergent capabilities arising from this interaction. Data limitations and the biases introduced by the training datasets would also be critical areas to investigate. Crucially, an in-depth analysis needs to consider whether the model truly understands the combined meaning or just performs pattern recognition; hence, the effectiveness of its reasoning abilities in audio-visual scenarios becomes central to the discussion. It’s important to address whether the basic listening skills are sufficient to underpin high-level audio-visual understanding.
Future Work#
Future work should prioritize improving the foundational audio understanding capabilities of MLLMs. Addressing the limitations revealed by DeafTest is crucial before tackling more complex audio-visual reasoning tasks. This involves exploring new training methodologies that emphasize low-level auditory feature extraction and integration. Developing more comprehensive and nuanced audio-visual datasets is also essential, particularly focusing on diverse audio attributes and scenarios to improve generalizability and robustness. Research into effective methods for multi-modal information fusion is critical, investigating novel architectures and training strategies that facilitate seamless interaction and mutual enhancement between audio and visual streams. Finally, more rigorous benchmark evaluation methods are needed, potentially incorporating human evaluation to ground the assessment in human perception and understanding. This multi-pronged approach will advance MLLM capabilities towards true audio-visual comprehension.
More visual insights#
More on figures

🔼 Figure 2 illustrates the AV-Odyssey Benchmark, a comprehensive evaluation suite for multimodal large language models (MLLMs). The figure highlights three key aspects of the benchmark: 1) Comprehensive Audio Attributes: It assesses MLLMs’ understanding of various sound characteristics, including timbre, tone, space, melody, hallucination, time, and intricacy. 2) Extensive Domains: The benchmark covers a wide range of audio-visual scenarios from daily life to more specialized domains like music, making it robust and generalizable. 3) Interleaved Text, Audio, and Images: The benchmark presents problems that require models to integrate information from text, audio, and visual inputs simultaneously, mirroring real-world complexities. This design ensures that the MLLMs truly understand audio-visual information, and doesn’t just rely on superficial pattern recognition.
read the caption
Figure 2: Overview of AV-Odyssey Benchmark. AV-Odyssey Bench demonstrates three major features: 1. Comprehensive Audio Attributes; 2. Extensive Domains; 3. Interleaved Text, Audio, and Images.

🔼 This figure provides a visual overview of the 26 evaluation tasks included in the AV-Odyssey benchmark. These tasks are categorized into seven main classes based on the prominent audio attributes they assess: Timbre, Tone, Melody, Space, Time, Intricacy, and Hallucination. The figure uses a circular layout to display the various tasks within each category, making it easy to see the breadth and depth of the benchmark’s coverage of different audio-visual scenarios. Each task assesses a unique aspect of multimodal understanding, requiring models to integrate information from both audio and visual modalities in order to arrive at the correct answer.
read the caption
Figure 3: Overview of 26 evaluation tasks of AV-Odyssey Benchmark. We mainly categorize these tasks with the sound attributed into 7 classes.

🔼 Figure 4 presents example questions from the AV-Odyssey benchmark dataset. Each example showcases a different task from the benchmark, highlighting its multi-modal nature (text, image/video, and audio). The questions require models to integrate information from all modalities to provide a correct answer. This figure illustrates the diversity of tasks and complexity present in the AV-Odyssey benchmark, which tests multimodal large language models’ ability to understand and reason using audio-visual information.
read the caption
Figure 4: Sampled examples from our AV-Odyssey Benchmark.

🔼 This figure shows a pie chart that breaks down the 104 human-annotated errors made by Gemini 1.5 Pro on the AV-Odyssey benchmark. The errors are categorized into four main types: Audio Understanding (63%), Vision Understanding (10%), Text Understanding (8%), and Reasoning (13%). The remaining 6% of errors fall into the ‘Other’ category.
read the caption
Figure 5: Distribution of 104 human-annotated errors in the Gemini 1.5 Pro.

🔼 The figure shows an example where a model misidentifies the audio content. Specifically, the model incorrectly labels a lion’s roar as an elephant trumpeting sound. This highlights the model’s limitations in accurately understanding and classifying audio information, demonstrating an audio understanding error.
read the caption
Figure 6: An example of audio understanding error. More examples are provided in the Appendix.

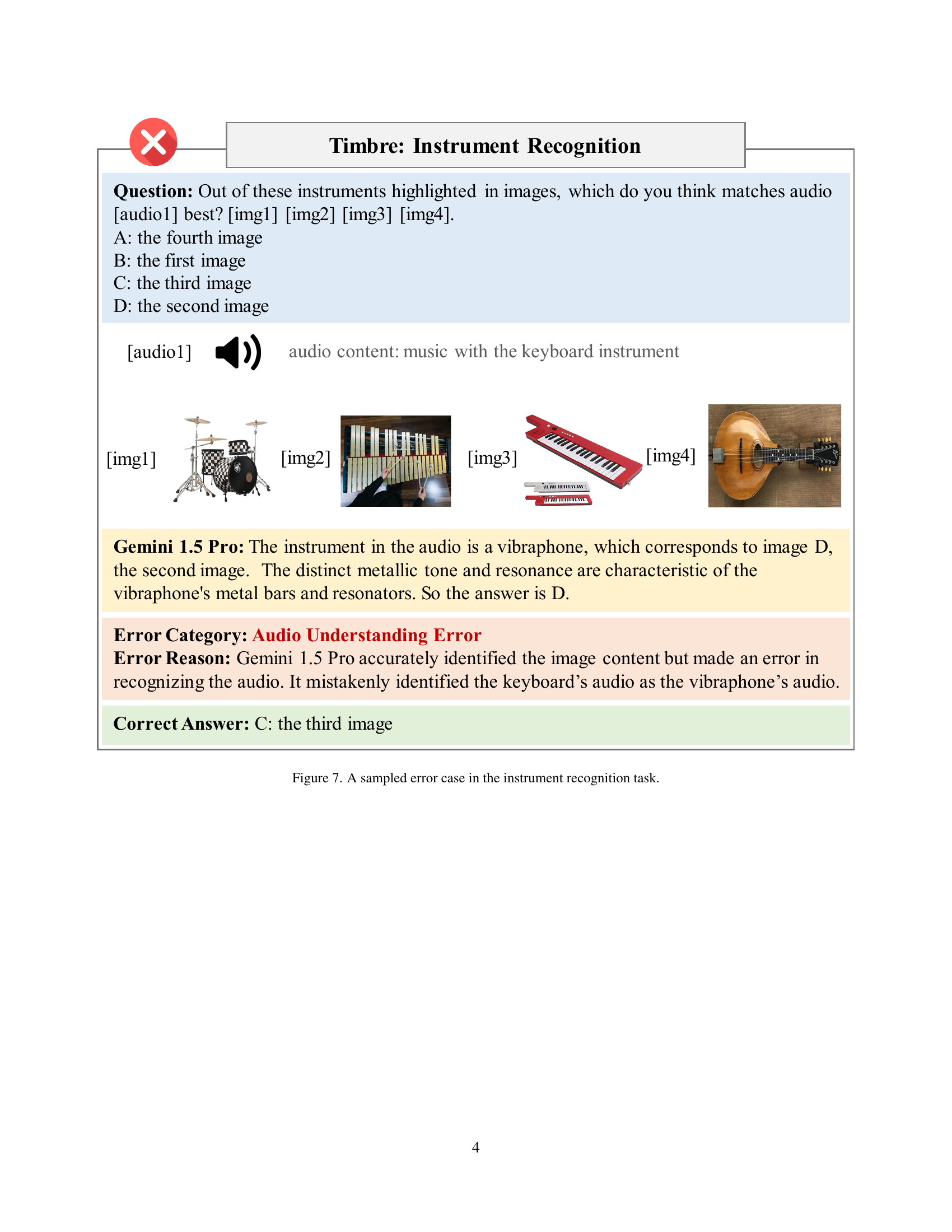
🔼 The figure shows a multiple-choice question where the model is asked to identify which instrument best matches an audio clip of keyboard music. The correct answer is the keyboard (C), but the model incorrectly chose the vibraphone (D), demonstrating a failure in audio understanding. The model focused on the timbre and resonance, incorrectly identifying them with a vibraphone instead of the keyboard.
read the caption
Figure 7: A sampled error case in the instrument recognition task.

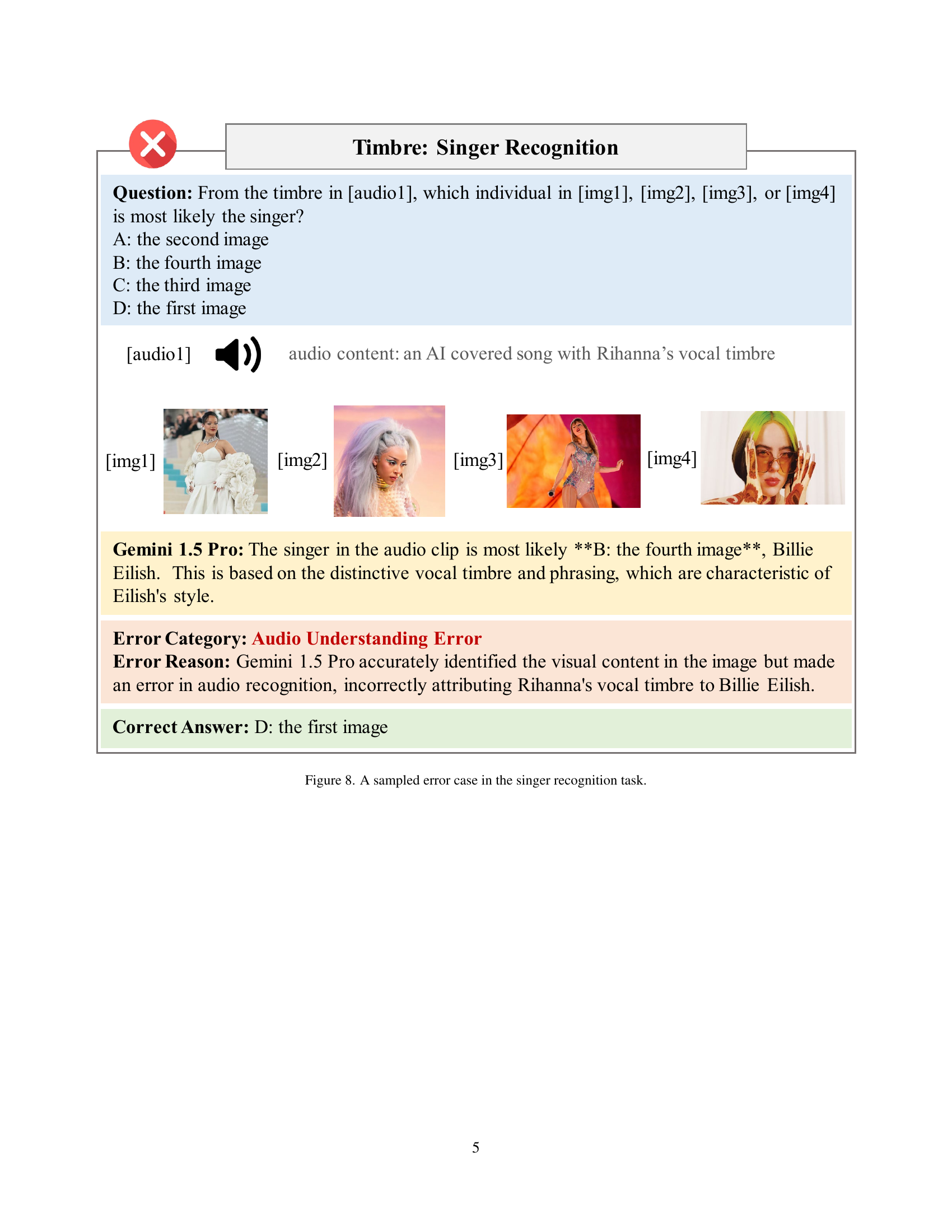
🔼 This figure shows a sample error from the singer recognition task in the AV-Odyssey benchmark. The task required the model to identify the singer based on their vocal timbre in an audio clip and choose from four images of different singers. The model incorrectly identified the singer in the audio as Billie Eilish, when it was actually Rihanna. This highlights the model’s limitation in accurately identifying singers based solely on vocal timbre, even in simple scenarios. The image provides the audio clip, the options to choose from, the model’s incorrect response and the correct answer.
read the caption
Figure 8: A sampled error case in the singer recognition task.

🔼 The figure shows a multiple choice question in which the model is asked to identify which image best corresponds to the sound of gunfire. The correct answer is an image depicting a soldier firing a gun, while the model incorrectly chooses an image of a machine gun. This highlights the model’s difficulty distinguishing between the sound of different types of gunfire, emphasizing the complexity of audio-visual tasks.
read the caption
Figure 9: A sampled error case in the gunshot recognition task.

🔼 The figure showcases a sample error from the bird recognition task within the AV-Odyssey benchmark. It highlights a multimodal large language model’s (MLLM) failure to correctly identify both the visual (bird species) and audio (bird sounds) components. The model incorrectly identifies a common grackle as a Brewer’s Blackbird and subsequently mismatches the bird sound, illustrating the challenges faced by MLLMs in accurately integrating audio-visual information for complex tasks.
read the caption
Figure 10: A sampled error case in the bird recognition task.

🔼 This figure shows an example where the model incorrectly identifies the sound of a frog as a cat’s meow while correctly identifying the image as a cat. This highlights the model’s struggles in accurately associating audio with the correct visual element and demonstrates a failure in audio recognition.
read the caption
Figure 11: A sampled error case in the animal recognition task.

🔼 This figure shows a sample error case from the transportation recognition task within the AV-Odyssey benchmark. The model incorrectly identified the sound of an airplane as a motorcycle sound, despite correctly identifying the image of a motorcycle. This highlights a failure in audio understanding, where the model misinterprets the audio despite accurate visual recognition.
read the caption
Figure 12: A sampled error case in the transportation recognition task.

🔼 This figure shows a multiple-choice question from the AV-Odyssey benchmark’s material recognition task. The question asks the model to identify which of four materials (shown in images) is most likely to produce the sound of someone stepping or hitting on fallen leaves (played in an audio clip). The model incorrectly answers, highlighting a potential text understanding error. The model’s response suggests it misunderstood the question, focusing on identifying the source image of the audio rather than identifying the correct material based on the audio. The correct answer is an image depicting a leaf-littered path.
read the caption
Figure 13: A sampled error case in the material recognition task.

🔼 The figure shows an example where Gemini 1.5 Pro misidentified the sound of traffic as that of a subway train. The model correctly identified the image content showing a street scene but failed to accurately understand the audio. This highlights the model’s difficulty in accurately associating sounds with visual scenes, a key challenge in audio-visual comprehension tasks.
read the caption
Figure 14: A sampled error case in the scene recognition task.

🔼 The figure showcases a sample error from the hazard recognition task within the AV-Odyssey benchmark. It visually presents the question, the model’s incorrect answer, the correct answer, and a detailed breakdown of the error’s cause. The question involves identifying the image depicting a hazard that aligns with the audio clip of a fire. The model misinterprets the sound of fire burning as the sound of boiling water, illustrating a flaw in its audio understanding capabilities and highlights the complexity of audio-visual comprehension tasks.
read the caption
Figure 15: A sampled error case in the hazard recognition task.

🔼 The figure shows an example where a multimodal large language model (MLLM) fails to correctly identify the action in a video based on the corresponding audio. The model incorrectly identifies the audio of someone running on a treadmill as the sound of playing basketball.
read the caption
Figure 16: A sampled error case in the action recognition task.

🔼 The figure shows an example where the Gemini 1.5 Pro model misidentifies the sound of eating juicy grapes as the sound of eating crispy chips. The model correctly identifies the image (grapes), but incorrectly identifies the audio. This highlights a limitation in audio understanding within the model, specifically in distinguishing between similar sounds with different textures.
read the caption
Figure 17: A sampled error case in the eating sound recognition task.

🔼 This figure shows a case where the model incorrectly identifies the emotion conveyed in an audio clip. The task is to match the audio (an angry voice) to one of four images representing different emotions. The model incorrectly selects an image depicting disgust, demonstrating a failure in accurately interpreting audio-based emotional cues. The image shows four options; a woman showing disgust, a man showing surprise, an eggplant emoji showing anger, and a sad face emoji showing sadness. The model chose the image of a woman with a disgusted face, even though the audio was of an angry voice.
read the caption
Figure 18: A sampled error case in the speech sentiment analysis task.

🔼 The figure shows an example where the model (Gemini 1.5 Pro) failed to answer a question about a meme because the content was mistakenly flagged for security reasons. The question asked about the humor in a meme given an audio clip and a sequence of images. Gemini 1.5 Pro was unable to provide any answer. The correct answer involved the contrast between the calm audio and the cat’s expressionless face in the meme images. This highlights the model’s limitations in handling sensitive content and its inability to fully understand the nuances of humor in multimodal contexts.
read the caption
Figure 19: A sampled error case in the meme understanding task.

🔼 This figure shows a case where the model incorrectly identifies the sentiment of cheerful music as sad. The model correctly identified the visual content of the image (a crying emoji face), but failed in audio recognition, highlighting its limitations in accurately understanding musical emotions.
read the caption
Figure 20: A sampled error case in the music sentiment analysis task.

🔼 Gemini 1.5 Pro incorrectly classified the audio as country music instead of classical music, despite accurately identifying the image content. This highlights the model’s limitations in audio understanding and genre classification.
read the caption
Figure 21: A sampled error case in the music genre classification task.

🔼 This figure shows a case where the Gemini 1.5 Pro model failed to correctly identify the audio that best matches the dance in a video. The task was to select the audio clip that most accurately corresponds to the style and rhythm of the dance shown. The model failed to answer, likely due to limitations in the model’s ability to integrate visual and audio cues to make complex decisions about audio-visual synchronicity. The model’s failure to answer highlights the challenges of multimodal understanding, even in relatively simple tasks.
read the caption
Figure 22: A sampled error case in the dance and music matching task.

🔼 The figure shows an example where the Gemini 1.5 Pro model incorrectly matches a fast-paced, cheerful music clip with a scene from an action movie. The model fails to recognize that the humorous tone of the audio, indicated by comical screams, is more characteristic of a comedy than an action film.
read the caption
Figure 23: A sampled error case in the film and music matching task.

🔼 This figure showcases a case where Gemini 1.5 Pro misidentifies a music score. The audio features slow-paced music with a sustained vocal at the end. The model incorrectly identifies the audio as moderately paced with a swing feel and syncopated rhythm, leading to a mismatched score selection. The error highlights the model’s limitations in accurately interpreting tempo, articulation, and the interplay of rhythmic and melodic elements in music.
read the caption
Figure 24: A sampled error case in the music score matching task.

🔼 This figure shows a sample error case in the audio 3D angle estimation task of the AV-Odyssey benchmark. The task involves estimating the azimuth and elevation angles of a sound source relative to a person in an image. The model incorrectly identifies the person and misinterprets spatial audio cues, leading to an inaccurate angle estimation. The correct and predicted answers are shown, highlighting the model’s inability to properly integrate visual and audio information for spatial reasoning.
read the caption
Figure 25: A sampled error case in the audio 3D angle estimation task.

🔼 The figure shows an example where the model fails to accurately estimate the distance of a sound source using audio and visual cues. The model correctly identifies the visual elements but fails to integrate the spatial audio information from the 4-channel spatial audio recording, leading to an inaccurate distance estimation. This highlights the model’s limitations in multi-modal reasoning and its reliance on visual cues over more precise spatial audio information.
read the caption
Figure 26: A sampled error case in the audio distance estimation task.

🔼 The figure shows a sample error from the audio time estimation task of the AV-Odyssey benchmark. The task requires identifying the start and end times of an action in a video based solely on an accompanying audio clip. The example highlights a model’s misidentification of the correct timeframe for a specific action (putting utensils in a drawer). The model incorrectly identified the timeframe based on the audio, demonstrating limitations in precise temporal alignment between audio and visual inputs.
read the caption
Figure 27: A sampled error case in the audio time estimation task.

🔼 The figure shows an example where a multimodal large language model (MLLM) fails to accurately synchronize audio and video. The task was to identify which audio clip best matches a given video. The model incorrectly chose an audio clip with random offsets, speed-ups, and slow-downs, demonstrating a lack of understanding in aligning events across different modalities.
read the caption
Figure 28: A sampled error case in the audio-visual synchronization task.
🔼 This figure shows a sample error case from the AV-Odyssey benchmark’s action sequencing task. Gemini 1.5 Pro incorrectly identified the order of actions based on the audio cues, indicating issues with both audio understanding and reasoning capabilities. The correct sequence is shown for comparison, highlighting the model’s inability to accurately interpret temporal relationships between actions.
read the caption
Figure 29: A sampled error case in the action sequencing task.

🔼 The figure showcases a common mistake made by the Gemini 1.5 Pro model during the hallucination evaluation task. The model incorrectly identifies a sitar as being present in an audio clip that actually only contains drums. This highlights the model’s tendency to hallucinate or falsely perceive elements not present in the input audio, demonstrating limitations in its audio understanding capabilities.
read the caption
Figure 30: A sampled error case in the hallucination evaluation task.

🔼 The figure displays an example where a multimodal large language model (MLLM) incorrectly predicts the action a person is performing. The model is presented with an image of a person standing near a coffee container and an audio clip of sounds associated with the action. The MLLM incorrectly identifies the action as ‘wrapping up coffee’ due to errors in understanding the temporal relationship between the visual input and the audio clip.
read the caption
Figure 31: A sampled error case in the action prediction task.

🔼 This figure shows a case where the model incorrectly identifies the action being performed in a video clip. The task is to determine what the person in the video is doing based on the audio and visual information. The image shows a person near a countertop holding a rag. The model incorrectly determines that the person is wiping the counter with the rag. However, the correct answer is that the person is rinsing the chopping board.
read the caption
Figure 32: A sampled error case in the action tracing task.
More on tables
| Benchmark / Dataset | Modality | Questions | Answer Type | Customized Question | Timbre | Tone | Melody | Space | Time | Hallucination | Intricacy | Multiple Domains | Interleaved | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MME Bench [21] | Image | 2194 | Y/N | ✓ | - | - | - | - | - | - | - | ✓ | ✗ | |
| MMBench [42] | Image(s) | 2974 | A/B/C/D | ✓ | - | - | - | - | - | - | - | ✓ | ✗ | |
| SEED-Bench-2 [32] | Image(s) & Video | 24371 | A/B/C/D | ✓ | - | - | - | - | - | - | - | ✓ | ✓ | |
| AVQA Dataset [81] | Video & Audio | 57335 | A/B/C/D | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | |
| Pano-AVQA Dataset [88] | Video & Audio | 51700 | defined words & bbox | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| Music-AVQA Dataset [33] | Video & Audio | 45867 | defined words | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | |
| SAVE Bench [68] | Image & Video & Audio | 4350 | free-form | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| OmniBench [37] | Image & Audio | 1142 | A/B/C/D | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | |
| AV-Odyssey Bench (ours) | Image(s) & Video & Audio(s) | 4555 | A/B/C/D | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares various multimodal large language model (MLLM) benchmarks and datasets, highlighting their differences in terms of modality (e.g., image, video, audio), number of questions, answer type (e.g., Yes/No, multiple choice), and the specific audio attributes considered (e.g., timbre, tone, melody). The table helps to illustrate the limitations of existing benchmarks in terms of their scope and ability to fully assess the audio-visual capabilities of MLLMs, motivating the need for a more comprehensive benchmark.
read the caption
Table 2: Comparisons between MLLM benchmarks / datasets.
| Statistics | Number |
|---|---|
| Total Questions | 4555 |
| Total Tasks | 26 |
| Domains | 10 |
| Questions with Multiple Images, Singe Audio | 2610 |
| Questions with Single Image, Multiple Audios | 891 |
| Questions with Singe Image, Singe Audio | 434 |
| Questions with Singe Video, Singe Audio | 220 |
| Questions with Single Video, Multiple Audios | 400 |
| Correct Option Distribution (A:B:C:D) | 1167:1153:1119:1116 |
| Average Audio Time | 16.32 seconds |
| Average Image Resolution | 1267.72 × 891.40 |
| Average Video Resolution | 1678.69 × 948.56 |
| Average Video Time | 15.58 seconds |
🔼 Table 3 presents a detailed statistical overview of the AV-Odyssey Benchmark dataset. It provides the total number of questions and tasks included, the number of domains covered, and a breakdown of question types based on the combination of input modalities (single image, multiple images, single audio, multiple audios, single video, multiple videos). Furthermore, it shows the distribution of correct answers across the four answer choices (A, B, C, and D), along with the average duration of audio clips, and the average resolutions and duration of image and video data used in the benchmark.
read the caption
Table 3: Detailed statistics of AV-Odyssey Benchmark.
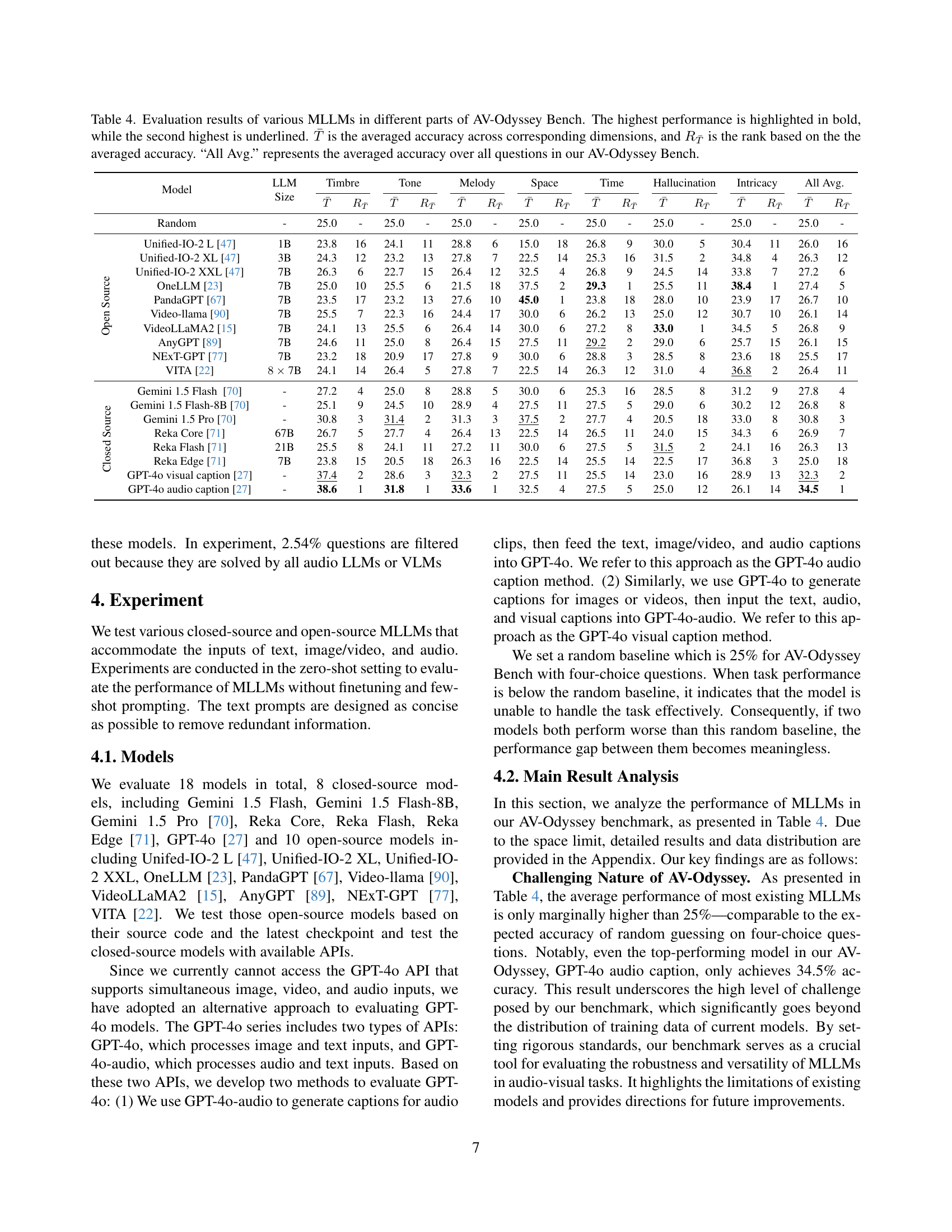
🔼 Table 4 presents a comprehensive evaluation of various Multimodal Large Language Models (MLLMs) on the AV-Odyssey benchmark. The benchmark is divided into several sub-sections representing different audio-visual attributes. For each MLLM, the table shows the model size, the average accuracy (T) across all sub-sections, the ranking (RT) based on this average accuracy, and then individual average accuracies for each sub-section. The highest accuracy in each column is bolded, and the second highest is underlined. Finally, the table provides the overall average accuracy across all questions in the entire AV-Odyssey benchmark.
read the caption
Table 4: Evaluation results of various MLLMs in different parts of AV-Odyssey Bench. The highest performance is highlighted in bold, while the second highest is underlined. T¯¯𝑇\bar{T}over¯ start_ARG italic_T end_ARG is the averaged accuracy across corresponding dimensions, and RT¯subscript𝑅¯𝑇R_{\bar{T}}italic_R start_POSTSUBSCRIPT over¯ start_ARG italic_T end_ARG end_POSTSUBSCRIPT is the rank based on the the averaged accuracy. “All Avg.” represents the averaged accuracy over all questions in our AV-Odyssey Bench.
| Task ID | Task Name | Task Category | Class | Number |
|---|---|---|---|---|
| 1 | Instrument Recognition | Timbre | 28 | 200 |
| 2 | Singer Recognition | Timbre | 20 | 200 |
| 3 | Gunshot Recognition | Timbre | 13 | 200 |
| 4 | Bird Recognition | Timbre | 39 | 200 |
| 5 | Animal Recognition | Timbre | 13 | 200 |
| 6 | Transportation Recognition | Timbre | 8 | 200 |
| 7 | Material Recognition | Timbre | 10 | 200 |
| 8 | Scene Recognition | Timbre | 8 | 200 |
| 9 | Hazard Recognition | Timbre | 8 | 108 |
| 10 | Action Recognition | Timbre | 20 | 196 |
| 11 | Eating Sound Recognition | Timbre | 20 | 200 |
| 12 | Speech Sentiment Analysis | Tone | 7 | 200 |
| 13 | Meme Understanding | Tone | N/A | 20 |
| 14 | Music Sentiment Analysis | Melody | 7 | 197 |
| 15 | Music Genre Classification | Melody | 8 | 200 |
| 16 | Dance and Music Matching | Melody | 10 | 200 |
| 17 | Film and Music Matching | Melody | 5 | 200 |
| 18 | Music Score Matching | Melody | N/A | 200 |
| 19 | Audio 3D Angle Estimation | Space | N/A | 20 |
| 20 | Audio Distance Estimation | Space | N/A | 20 |
| 21 | Audio Time Estimation | Time | N/A | 200 |
| 22 | Audio-Visual Synchronization | Time | N/A | 200 |
| 23 | Action Sequencing | Time | N/A | 200 |
| 24 | Hallucination Evaluation | Hallucination | 19 | 200 |
| 25 | Action Prediction | Intricacy | N/A | 199 |
| 26 | Action Tracing | Intricacy | N/A | 195 |
🔼 Table 5 presents a detailed breakdown of the tasks included in the AV-Odyssey benchmark. It lists each task’s name, its category (e.g., Timbre, Tone, Melody), and the number of classes and questions associated with that task. This provides a comprehensive overview of the benchmark’s structure and the distribution of different audio-visual challenges it presents.
read the caption
Table 5: Detailed task statistics in AV-Odyssey Bench.
| Model | LLM Size | Instrument Recognition | Singer Recognition | Gunshot Recognition | Bird Recognition | Animal Recognition | Transportation Recognition | Material Recognition | Scene Recognition | Hazard Recognition | Action Recognition | Eating Sound Recognition |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Source | ||||||||||||
| Unified-IO-2 L [47] | 1B | 20.5 | 22.5 | 25.5 | 18.5 | 27.0 | 26.5 | 23.0 | 28.0 | 21.3 | 20.9 | 26.5 |
| Unified-IO-2 XL [47] | 3B | 20.0 | 23.5 | 24.0 | 20.5 | 27.5 | 26.0 | 27.5 | 30.0 | 19.4 | 19.9 | 26.5 |
| Unified-IO-2 XXL [47] | 7B | 29.5 | 24.0 | 23.5 | 29.0 | 23.5 | 25.5 | 30.5 | 26.5 | 23.1 | 27.0 | 25.5 |
| OneLLM [23] | 7B | 26.0 | 21.5 | 27.0 | 26.0 | 22.0 | 20.0 | 29.5 | 24.5 | 26.9 | 23.0 | 29.5 |
| PandaGPT [67] | 7B | 20.0 | 21.5 | 23.0 | 17.5 | 26.0 | 26.5 | 28.0 | 27.0 | 23.1 | 21.4 | 24.5 |
| Video-llama [90] | 7B | 22.5 | 24.5 | 27.0 | 26.5 | 27.0 | 23.5 | 28.0 | 25.0 | 25.0 | 26.0 | 25.5 |
| VideoLLaMA2 [15] | 7B | 22.5 | 24.0 | 27.0 | 17.0 | 23.5 | 27.5 | 26.5 | 26.5 | 19.4 | 23.0 | 25.5 |
| AnyGPT [89] | 7B | 22.5 | 28.5 | 28.0 | 17.5 | 24.0 | 25.5 | 23.0 | 28.0 | 25.9 | 20.4 | 27.5 |
| NExT-GPT [77] | 7B | 21.0 | 23.5 | 25.5 | 21.5 | 25.5 | 25.5 | 21.0 | 24.0 | 19.4 | 23.0 | 24.0 |
| VITA [22] | 8 × 7B | 22.0 | 20.5 | 24.5 | 21.5 | 27.5 | 25.0 | 23.5 | 28.5 | 21.3 | 19.4 | 29.5 |
| Closed Source | ||||||||||||
| Gemini 1.5 Flash [70] | - | 24.5 | 24.0 | 23.5 | 17.0 | 32.5 | 26.0 | 22.5 | 29.5 | 34.3 | 48.0 | 21.5 |
| Gemini 1.5 Flash-8B [70] | - | 16.5 | 22.5 | 24.0 | 19.0 | 28.0 | 26.5 | 27.0 | 29.0 | 26.9 | 32.7 | 24.5 |
| Gemini 1.5 Pro [70] | - | 33.0 | 26.0 | 29.0 | 25.0 | 25.5 | 26.0 | 29.5 | 30.0 | 38.0 | 57.7 | 22.5 |
| Reka Core [71] | 67B | 32.5 | 20.0 | 26.5 | 25.0 | 24.0 | 27.0 | 30.0 | 27.0 | 25.0 | 34.2 | 21.5 |
| Reka Flash [71] | 21B | 20.0 | 22.5 | 26.5 | 26.0 | 28.5 | 26.5 | 26.5 | 29.0 | 28.7 | 22.4 | 25.0 |
| Reka Edge [71] | 7B | 21.5 | 24.0 | 30.5 | 20.0 | 19.5 | 22.5 | 20.5 | 25.5 | 25.9 | 23.5 | 29.0 |
| GPT-4o visual caption [27] | - | 33.0 | 30.5 | 24.0 | 26.5 | 43.0 | 42.0 | 32.5 | 39.0 | 49.1 | 67.3 | 30.5 |
| GPT-4o audio caption [27] | - | 40.0 | 38.0 | 27.5 | 26.5 | 45.0 | 42.0 | 27.0 | 41.0 | 42.6 | 62.2 | 35.5 |
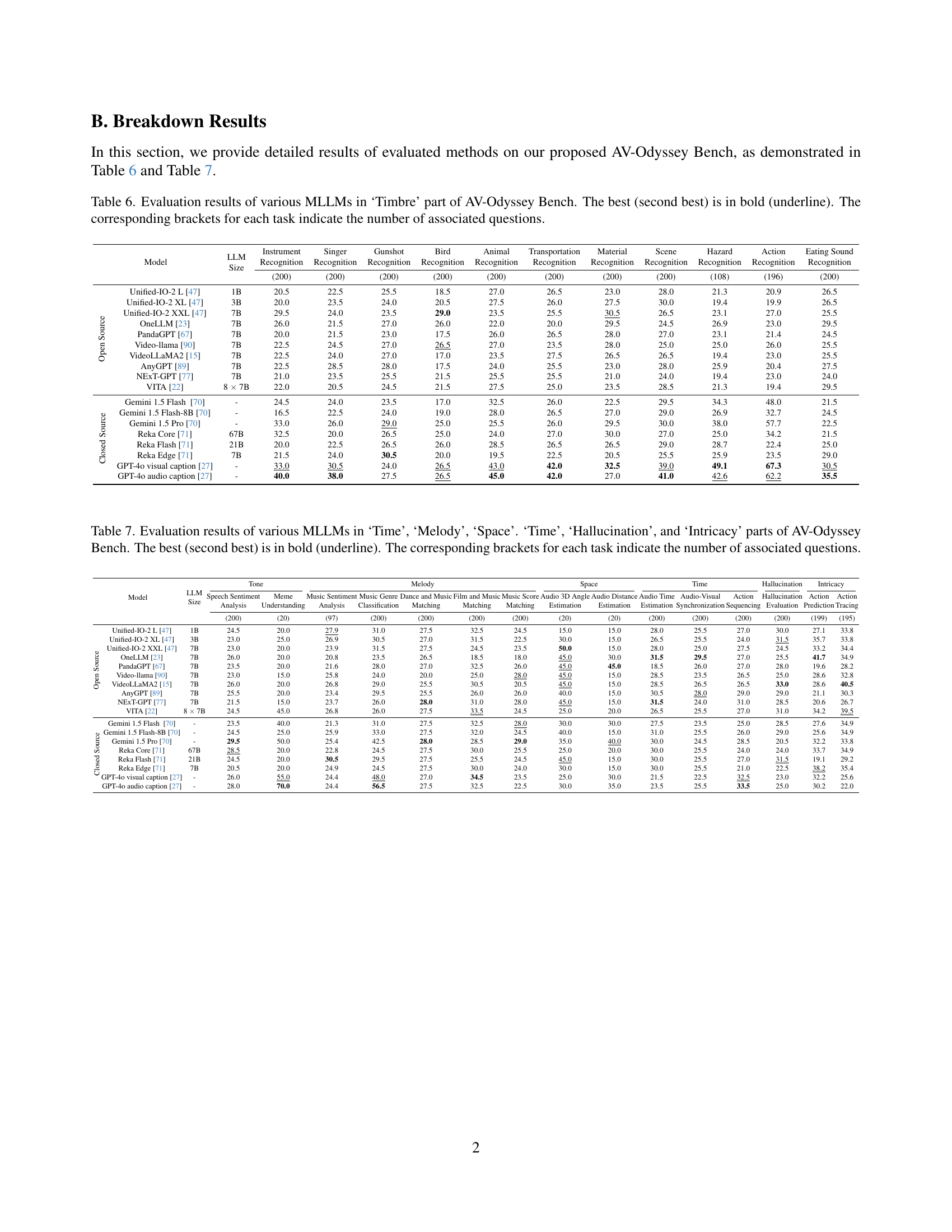
🔼 Table 6 presents the performance of various multimodal large language models (MLLMs) on the ‘Timbre’ portion of the AV-Odyssey benchmark. The benchmark assesses the models’ ability to understand and reason using audio-visual information focusing on timbre, a key attribute of sound. The table shows each model’s accuracy (percentage correct) on several tasks related to timbre, including instrument, singer, gunshot, bird, animal, transportation, material, scene, hazard, and action recognition, as well as eating sound recognition. The best and second-best performing model for each task is highlighted in bold and underlined, respectively. Parenthetical values after each task name denote the number of questions associated with that task.
read the caption
Table 6: Evaluation results of various MLLMs in ‘Timbre’ part of AV-Odyssey Bench. The best (second best) is in bold (underline). The corresponding brackets for each task indicate the number of associated questions.
| Model | LLM | Size | Tone | Melody | Melody | Melody | Melody | Melody | Space | Space | Time | Time | Time | Hallucination | Intricacy | Intricacy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Source | Speech Sentiment Analysis | Meme Understanding | Music Sentiment Analysis | Music Genre Classification | Dance and Music Matching | Film and Music Matching | Music Score Matching | Audio 3D Angle Estimation | Audio Distance Estimation | Audio Time Estimation | Audio-Visual Synchronization | Action Sequencing | Hallucination Evaluation | Action Prediction | Action Tracing | |
| Open Source | 200 | 20 | 97 | 200 | 200 | 200 | 200 | 20 | 20 | 200 | 200 | 200 | 200 | 199 | 195 | |
| Unified-IO-2 L [47] | 1B | 24.5 | 20.0 | 27.9 | 31.0 | 27.5 | 32.5 | 24.5 | 15.0 | 15.0 | 28.0 | 25.5 | 27.0 | 30.0 | 27.1 | 33.8 |
| Unified-IO-2 XL [47] | 3B | 23.0 | 25.0 | 26.9 | 30.5 | 27.0 | 31.5 | 22.5 | 30.0 | 15.0 | 26.5 | 25.5 | 24.0 | 31.5 | 35.7 | 33.8 |
| Unified-IO-2 XXL [47] | 7B | 23.0 | 20.0 | 23.9 | 31.5 | 27.5 | 24.5 | 23.5 | 50.0 | 15.0 | 28.0 | 25.0 | 27.5 | 24.5 | 33.2 | 34.4 |
| OneLLM [23] | 7B | 26.0 | 20.0 | 20.8 | 23.5 | 26.5 | 18.5 | 18.0 | 45.0 | 30.0 | 31.5 | 29.5 | 27.0 | 25.5 | 41.7 | 34.9 |
| PandaGPT [67] | 7B | 23.5 | 20.0 | 21.6 | 28.0 | 27.0 | 32.5 | 26.0 | 45.0 | 45.0 | 18.5 | 26.0 | 27.0 | 28.0 | 19.6 | 28.2 |
| Video-llama [90] | 7B | 23.0 | 15.0 | 25.8 | 24.0 | 20.0 | 25.0 | 28.0 | 45.0 | 15.0 | 28.5 | 23.5 | 26.5 | 25.0 | 28.6 | 32.8 |
| VideoLLaMA2 [15] | 7B | 26.0 | 20.0 | 26.8 | 29.0 | 25.5 | 30.5 | 20.5 | 45.0 | 15.0 | 28.5 | 26.5 | 26.5 | 33.0 | 28.6 | 40.5 |
| AnyGPT [89] | 7B | 25.5 | 20.0 | 23.4 | 29.5 | 25.5 | 26.0 | 26.0 | 40.0 | 15.0 | 30.5 | 28.0 | 29.0 | 29.0 | 21.1 | 30.3 |
| NExT-GPT [77] | 7B | 21.5 | 15.0 | 23.7 | 26.0 | 28.0 | 31.0 | 28.0 | 45.0 | 15.0 | 31.5 | 24.0 | 31.0 | 28.5 | 20.6 | 26.7 |
| VITA [22] | 8 × 7B | 24.5 | 45.0 | 26.8 | 26.0 | 27.5 | 33.5 | 24.5 | 25.0 | 20.0 | 26.5 | 25.5 | 27.0 | 31.0 | 34.2 | 39.5 |
| Closed Source | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | |
| Gemini 1.5 Flash [70] | - | 23.5 | 40.0 | 21.3 | 31.0 | 27.5 | 32.5 | 28.0 | 30.0 | 30.0 | 27.5 | 23.5 | 25.0 | 28.5 | 27.6 | 34.9 |
| Gemini 1.5 Flash-8B [70] | - | 24.5 | 25.0 | 25.9 | 33.0 | 27.5 | 32.0 | 24.5 | 40.0 | 15.0 | 31.0 | 25.5 | 26.0 | 29.0 | 25.6 | 34.9 |
| Gemini 1.5 Pro [70] | - | 29.5 | 50.0 | 25.4 | 42.5 | 28.0 | 28.5 | 29.0 | 35.0 | 40.0 | 30.0 | 24.5 | 28.5 | 20.5 | 32.2 | 33.8 |
| Reka Core [71] | 67B | 28.5 | 20.0 | 22.8 | 24.5 | 27.5 | 30.0 | 25.5 | 25.0 | 20.0 | 30.0 | 25.5 | 24.0 | 24.0 | 33.7 | 34.9 |
| Reka Flash [71] | 21B | 24.5 | 20.0 | 30.5 | 29.5 | 27.5 | 25.5 | 24.5 | 45.0 | 15.0 | 30.0 | 25.5 | 27.0 | 31.5 | 19.1 | 29.2 |
| Reka Edge [71] | 7B | 20.5 | 20.0 | 24.9 | 24.5 | 27.5 | 30.0 | 24.0 | 30.0 | 15.0 | 30.0 | 25.5 | 21.0 | 22.5 | 38.2 | 35.4 |
| GPT-4o visual caption [27] | - | 26.0 | 55.0 | 24.4 | 48.0 | 27.0 | 34.5 | 23.5 | 25.0 | 30.0 | 21.5 | 22.5 | 32.5 | 23.0 | 32.2 | 25.6 |
| GPT-4o audio caption [27] | - | 28.0 | 70.0 | 24.4 | 56.5 | 27.5 | 32.5 | 22.5 | 30.0 | 35.0 | 23.5 | 25.5 | 33.5 | 25.0 | 30.2 | 22.0 |
🔼 Table 7 presents a comprehensive evaluation of various Multimodal Large Language Models (MLLMs) across six key aspects within the AV-Odyssey benchmark: Time, Melody, Space, Hallucination, and Intricacy. Each aspect represents a set of tasks designed to assess different audio-visual comprehension abilities. The table details the performance of both closed-source and open-source MLLMs, showing their accuracy (percentage) for each task. The best-performing model for each task is highlighted in bold, while the second-best is underlined. The number of questions associated with each task is also indicated in parentheses for context.
read the caption
Table 7: Evaluation results of various MLLMs in ‘Time’, ‘Melody’, ‘Space’. ‘Time’, ‘Hallucination’, and ‘Intricacy’ parts of AV-Odyssey Bench. The best (second best) is in bold (underline). The corresponding brackets for each task indicate the number of associated questions.
Full paper#