↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current one-step diffusion models for image generation suffer from training instability and lack negative prompt support, limiting their flexibility. Existing solutions often involve computationally expensive or resource-intensive methods. The lack of negative prompt capabilities also reduces the practicality and effectiveness of such models.
To address these issues, this paper introduces SNOOPI. SNOOPI employs Proper Guidance-SwiftBrush (PG-SB) to enhance training stability by using a random-scale classifier-free guidance. It also introduces a novel training-free method called Negative-Away Steer Attention (NASA) for seamlessly integrating negative prompts into the generation process. These methods significantly improve the performance of one-step models across multiple benchmarks, setting a new state-of-the-art.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances one-step diffusion models, a crucial area in image generation research. Its focus on stability and negative prompt integration addresses limitations of existing methods, paving the way for more efficient and controllable image synthesis applications. The proposed techniques have the potential to impact various fields such as computer graphics and multimedia. Researchers can leverage the findings to improve their own one-step diffusion model designs and explore new avenues in model optimization and prompt engineering.
Visual Insights#

🔼 Figure 1 compares the image generation results of several one-step diffusion models, including the proposed SNOOPI model and existing methods like SwiftBrush, DMD, YOSO, and PG-SB. All models are trained using the PixArt-α backbone and prompted with the text ‘Vincent van Gogh’. The figure highlights how PG-SB improves training stability in image-free distillation compared to other methods. Furthermore, it shows SNOOPI’s ability to incorporate negative prompts (demonstrated with a red image), effectively removing unwanted features and providing finer control over image generation than models without negative prompt capabilities.
read the caption
Figure 1: Comparison of various methods, including SNOOPI and alternatives (SwiftBrush, DMD, YOSO, PG-SB), using the PixArt-α𝛼\alphaitalic_α backbone. Each method generates an image with the prompt ”Vincent van Gogh” (green). PG-SB helps stabilize the training process of image-free distillation, addressing the typical instability in such training. SNOOPI, a combination of PG-SB and the NASA module, enables effective negative prompting (red) even for one and few-step models, allowing for the removal of specific unwanted features and providing enhanced control over image attributes.
| κ | FID ↓ | CLIP ↑ | Precision ↑ | Recall ↑ |
|---|---|---|---|---|
| 2 | 10.77 | 0.31 | 0.54 | 0.53 |
| 3 | 9.60 | 0.32 | 0.59 | 0.50 |
| 4 | 10.35 | 0.32 | 0.60 | 0.47 |
| 5 | 11.53 | 0.33 | 0.61 | 0.44 |
| mathcal{U}(2,5) | 9.86 | 0.32 | 0.60 | 0.48 |
🔼 This table presents the results of experiments conducted on the zero-shot MS COCO-2014 30K benchmark using the Stable Diffusion v2.1 model with the PNDM scheduler. The experiment varied the Classifier-Free Guidance (CFG) scale (κ) and measured the model’s performance across four metrics: FID (Fréchet Inception Distance), CLIP (Contrastive Language–Image Pre-training) score, Precision, and Recall. Lower FID indicates better image quality, while higher CLIP, Precision, and Recall scores suggest improved image-text alignment and generation quality. The results highlight how different CFG scales impact the model’s performance on this benchmark.
read the caption
Table 1: Results on the zero-shot MS COCO-2014 30K benchmark [24] of SDv2.1 [38] when using PNDM Scheduler with different CFG scale κ𝜅\kappaitalic_κ.
In-depth insights#
One-Step Distillation#
One-step distillation, as explored in the context of text-to-image diffusion models, presents a compelling approach to significantly improve efficiency without compromising the quality of generated images. The core idea revolves around distilling the knowledge of a complex, multi-step diffusion model into a simpler, one-step model, thereby accelerating the image generation process. This technique offers substantial practical advantages by reducing computational costs and inference times, making it particularly attractive for real-world applications where speed and resource efficiency are crucial. However, achieving successful one-step distillation faces several key challenges, including the instability of existing training methods (such as those relying on a fixed guidance scale) and the absence of support for negative prompt guidance. The latter significantly limits the level of control over generated image details and stylistic features. Addressing these challenges requires innovative methods to stabilize training, enhance robustness across diverse model architectures, and effectively integrate negative prompting capabilities to enable more precise control during generation. The paper, therefore, focuses on developing novel approaches for overcoming these limitations, thereby unlocking the full potential of one-step diffusion models for high-quality, efficient image synthesis.
PG-SB Guidance#
The proposed PG-SB (Proper Guidance - SwiftBrush) method tackles the instability issues in existing one-step diffusion model distillation techniques. The core innovation is the introduction of a randomized guidance scale during training, instead of using a fixed scale as in previous methods like SwiftBrush. This approach enhances training stability by broadening the output distributions of the teacher models. The varied guidance scale prevents overfitting to specific scales and improves the robustness of the VSD loss, making it less sensitive to the choice of model backbone. This dynamic adjustment of guidance improves the generalization capabilities and overall efficiency of the distillation process, leading to more robust and stable one-step models. The results highlight PG-SB’s effectiveness in achieving competitive performance across diverse model architectures, showcasing its adaptability and improved stability over the original SwiftBrush method. This is particularly relevant given the importance of efficiency and stability in practical applications of one-step diffusion models.
NASA Attention#
The proposed ‘NASA Attention’ mechanism offers a novel approach to integrating negative prompts into one-step diffusion models, a significant improvement over existing methods. Unlike classifier-free guidance (CFG), which struggles with one-step models due to their lack of iterative refinement, NASA operates in the intermediate feature space of the diffusion model. This allows for selective suppression of unwanted features by modulating cross-attention layers, thus directly influencing the attention weights assigned to negative prompt features. This feature-space manipulation is more effective than manipulating text embeddings alone, resulting in significantly cleaner and more aligned image generation. The use of cross-attention layers is particularly insightful, as it leverages their ability to capture semantic relationships between image regions and text features for precise control. NASA’s training-free nature and adaptability to diverse backbones are also crucial advantages, enhancing its practicality and ease of integration into various one-step diffusion models. However, future work could explore broader applicability to architectures lacking cross-attention and optimal scaling strategies for negative feature removal.
SNOOPI Framework#
The SNOOPI framework presents a novel approach to one-step diffusion model distillation, focusing on enhanced stability and negative prompt integration. Proper Guidance-SwiftBrush (PG-SB) addresses instability issues in existing methods by introducing a randomized guidance scale during training, leading to more robust performance across different model backbones. This dynamic approach avoids the limitations of fixed guidance scales, enhancing the adaptability of the distillation process. Furthermore, Negative-Away Steer Attention (NASA) provides a unique solution for incorporating negative prompts into one-step generation. Unlike previous methods, NASA works directly within the cross-attention layers, effectively steering the attention mechanism away from undesired image features without the need for iterative refinement, a critical advancement for efficient image synthesis. In essence, SNOOPI combines improved training stability with the ability to control image generation through negative prompts, achieving a new state-of-the-art in one-step diffusion models. The comprehensive experimental results demonstrate the effectiveness of both PG-SB and NASA, showcasing significant improvements in image quality and control metrics across various benchmarks.
Future Directions#
Future research could explore several promising avenues. Improving the stability and efficiency of one-step diffusion models remains crucial. While SNOOPI offers advancements, further investigation into the VSD loss function and its interaction with various model architectures is warranted. Developing more sophisticated negative prompt integration techniques beyond NASA could unlock finer-grained control over generated images. Extending SNOOPI’s capabilities to few-step models would bridge the gap between speed and fidelity. Finally, exploring the application of SNOOPI to other generative tasks beyond image synthesis, such as video or 3D model generation, presents exciting opportunities. This would involve adapting the core principles of proper guidance and negative steer attention to the unique challenges of these different modalities. Ultimately, the goal is to create even more efficient and versatile generative models capable of high-quality outputs with minimal computational resources.
More visual insights#
More on figures

🔼 Figure 2 illustrates the impact of different training approaches on the Fréchet Inception Distance (FID) score, a metric measuring the quality of generated images. The x-axis represents training iterations, while the y-axis represents the FID 2K score. Three different models (SwiftBrush, SwiftBrush with the ‘Two Time-scale Update Rule’ modification, and the proposed PG-SB method) are compared for two different diffusion model backbones (SDv1.5 and PixArt-α). The graph clearly shows that SwiftBrush and its modification exhibit unstable training, leading to significant fluctuations in FID scores. Conversely, the PG-SB approach demonstrates much more stable training, resulting in a consistently lower and more desirable FID score, indicating better image quality.
read the caption
Figure 2: FID 2K progression throughout training. The default baseline is SwiftBrush for both SDv1.5 and PixArt-α𝛼\alphaitalic_α. DMD2Trick indicates the Two Time-scale Update Rule technique [54], which increases the update frequency of the LoRA teacher to 5 times after each student update. These baselines demonstrate notable instability, leading to variability in image quality metrics such as FID. In contrast, our approach, which employs CFG with randomly selected values from a uniform distribution, results in a more stable training process and generates higher-quality samples.

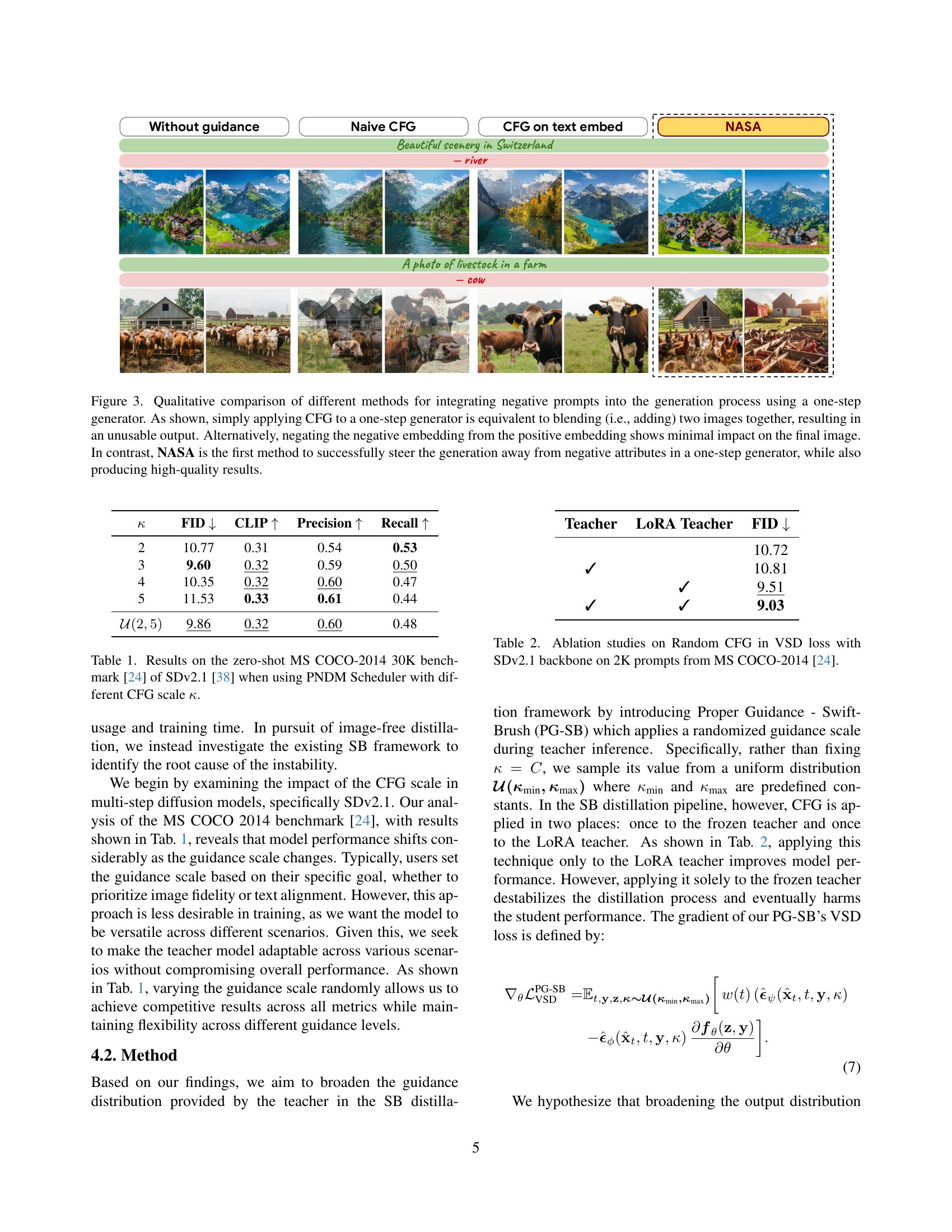
🔼 Figure 3 compares three approaches for using negative prompts in one-step image generation. Simply applying classifier-free guidance (CFG) directly, as done in multi-step models, results in a visually poor blend of the positive and negative images. Subtracting the negative embedding from the positive embedding also fails to effectively remove unwanted features. In contrast, the authors’ proposed Negative-Away Steer Attention (NASA) method successfully removes undesired elements while maintaining high-quality image generation, showcasing its effectiveness as the first method able to integrate negative prompts into the one-step generation process.
read the caption
Figure 3: Qualitative comparison of different methods for integrating negative prompts into the generation process using a one-step generator. As shown, simply applying CFG to a one-step generator is equivalent to blending (i.e., adding) two images together, resulting in an unusable output. Alternatively, negating the negative embedding from the positive embedding shows minimal impact on the final image. In contrast, NASA is the first method to successfully steer the generation away from negative attributes in a one-step generator, while also producing high-quality results.

🔼 Figure 4 illustrates the Negative-Away Steer Attention (NASA) method. The left side shows a high-level overview of the process: positive and negative text prompts are input into a text encoder, generating corresponding positive and negative text features. These features are then fed into the NASA module, which modifies the one-step diffusion model’s generation process to avoid the negative features and enhance the positive ones, resulting in a refined output image. The right side details the internal workings of the NASA module at layer ’l’. It shows how positive and negative key-value pairs (K+, V+, K-, V-) interact with queries (Ql) via cross-attention mechanisms to produce positive (Z+) and negative (Z-) attention outputs. Finally, the weighted negative output (Z-) is subtracted from the positive output (Z+), yielding the final NASA output (ZNASA).
read the caption
Figure 4: Left: An overview of the Negative-Away Steer Attention (NASA) pipeline. Positive (green) and negative (red) prompts are fed into a text encoder to generate positive and negative text features. The NASA module then processes these features, which adjusts the one-step diffusion model to steer the output image away from the negative features, refining it based on the positive features. Right: The details of the NASA module. It processes queries (𝐐lsubscript𝐐𝑙\mathbf{Q}_{l}bold_Q start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT) in layer l𝑙litalic_l, note we will omit the subscript l𝑙litalic_l in subsequent notations to improve readability, with positive (𝐕+,𝐊+superscript𝐕superscript𝐊\mathbf{V}^{+},\mathbf{K}^{+}bold_V start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , bold_K start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT) and negative (𝐕−,𝐊−superscript𝐕superscript𝐊\mathbf{V}^{-},\mathbf{K}^{-}bold_V start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT , bold_K start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT) key-value pairs to create positive (𝐙+superscript𝐙\mathbf{Z}^{+}bold_Z start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT) and negative (𝐙−superscript𝐙\mathbf{Z}^{-}bold_Z start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT) attention outputs. The final output (𝐙NASAsuperscript𝐙NASA\mathbf{Z}^{\text{NASA}}bold_Z start_POSTSUPERSCRIPT NASA end_POSTSUPERSCRIPT) is calculated by subtracting the weighted negative features (𝐙−superscript𝐙\mathbf{Z}^{-}bold_Z start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT) from the positive features (𝐙+superscript𝐙\mathbf{Z}^{+}bold_Z start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT).

🔼 Figure 5 shows how different scaling factors (0.0 to 1.0) in the NASA module affect image generation using the SDXL-DMD2 model. The figure demonstrates the progressive impact of the NASA module on visual details and overall composition of the generated images, ranging from a lack of detail and poor composition at 0.0, to a high level of detail and well-composed image at 1.0. Each row shows the results for a single prompt, highlighting the gradual shift in image quality and composition with increasing scale values.
read the caption
Figure 5: Effect of different scale values (0.0 to 1.0) in NASA with SDXL-DMD2 model, illustrating the progressive influence on visual details and composition.

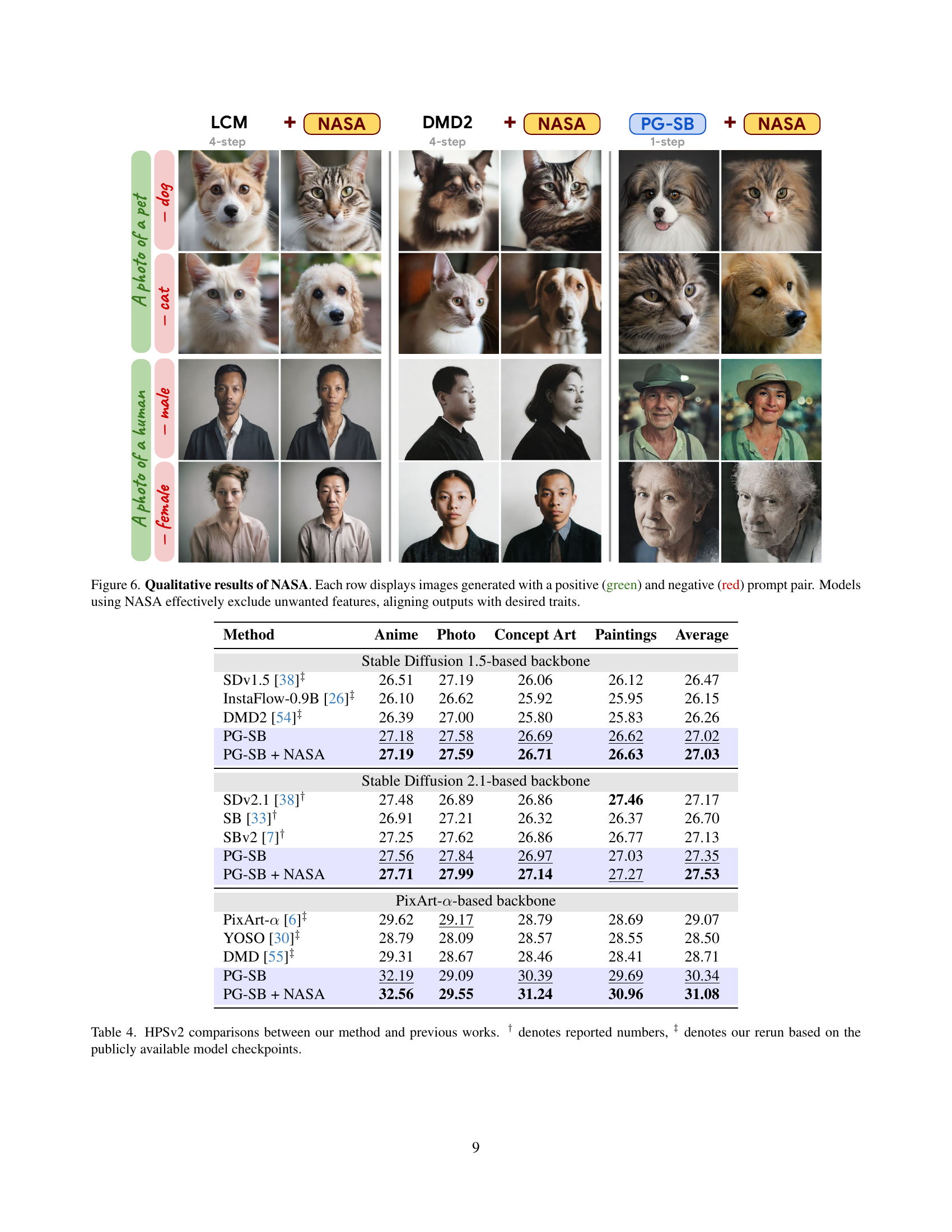
🔼 Figure 6 showcases the effectiveness of the Negative-Away Steer Attention (NASA) module in controlling image generation. Each row presents a pair of prompts: a positive prompt (in green) describing the desired image content, and a negative prompt (in red) specifying features to be excluded. The images generated by models with and without the NASA module are displayed side-by-side, demonstrating how NASA successfully removes the unwanted attributes specified in the negative prompt while retaining the key elements from the positive prompt. This highlights NASA’s ability to precisely control the generated images, aligning outputs more closely with the desired traits specified.
read the caption
Figure 6: Qualitative results of NASA. Each row displays images generated with a positive (green) and negative (red) prompt pair. Models using NASA effectively exclude unwanted features, aligning outputs with desired traits.

🔼 This figure showcases the visual quality of images generated using the PG-SB model, specifically using the PixArt-α backbone. It presents a diverse array of images demonstrating the model’s capability to generate various subjects, styles, and compositions, offering a qualitative assessment of its performance and versatility.
read the caption
Figure 7: Additional qualitative images generated by our PG-SB model with the PixArt-α𝛼\alphaitalic_α backbone.

🔼 This figure displays a diverse collection of images generated using the PG-SB (Proper Guidance - SwiftBrush) model, which is a modified version of the SwiftBrush model. The key improvement in PG-SB is the use of a randomized guidance scale for training stability. These images showcase the model’s ability to generate a variety of styles and subjects, demonstrating its versatility and effectiveness in producing high-quality results. All images in this figure were generated using the Stable Diffusion 1.5 model as the backbone for the PG-SB model.
read the caption
Figure 8: Additional qualitative images generated by our PG-SB model with the SDv1.5 backbone.

🔼 This figure displays a collection of images generated using the PG-SB model, specifically employing the Stable Diffusion 2.1 (SDv2.1) backbone. The images showcase the model’s capability to produce diverse and high-quality outputs, highlighting the visual style and realism achieved through the PG-SB method. The variety of subjects and artistic styles in the images demonstrates the versatility and effectiveness of the model. Each image serves as a visual example of the model’s performance, providing qualitative evidence of its ability to generate detailed, coherent, and visually appealing results.
read the caption
Figure 9: Additional qualitative images generated by our PG-SB model with the SDv2.1 backbone.
More on tables
| Teacher | LoRA Teacher | FID ↓ |
|---|---|---|
| 10.72 | ||
| ✓ | 10.81 | |
| ✓ | 9.51 | |
| ✓ | ✓ | 9.03 |
🔼 This table presents ablation study results evaluating the impact of applying the classifier-free guidance (CFG) with a randomized scale (instead of a fixed scale) to different parts of the variational score distillation (VSD) loss function. The experiment uses the Stable Diffusion 2.1 model as a backbone and a set of 2000 prompts from the MS COCO-2014 dataset. It compares the performance (measured by FID score) when applying the randomized CFG to either only the LoRA teacher, only the frozen teacher, or both, providing insights into which components benefit most from the randomized CFG approach and how this affects the overall model stability and performance during training.
read the caption
Table 2: Ablation studies on Random CFG in VSD loss with SDv2.1 backbone on 2K prompts from MS COCO-2014 [24].
| NASA | SDXL-LCM | SDXL-DMD2 | SDXL-DMD2 | PG-SB |
|---|---|---|---|---|
| 4 steps | 4 steps | 1 step | 1 step | |
| ✗ | 43% | 27% | 25% | 38% |
| ✓ | 97% | 100% | 100% | 92% |
🔼 This table compares the effectiveness of the Negative-Away Steer Attention (NASA) module in removing unwanted features from images generated by different models. It shows the success rate of unwanted feature removal for four models: SDXL-LCM, SDXL-DMD2 (both 4-step and 1-step versions), and PG-SB, with and without the NASA module. The success rate is calculated as the percentage of images that successfully exclude the features specified by the negative prompt, averaged over six positive-negative prompt pairs. Each model generated 100 images for each pair of prompts, and human evaluators assessed the results.
read the caption
Table 3: Comparison of success rate of unwanted feature removal in generated images between models with and without NASA.
| Method | Anime | Photo | Concept Art | Paintings | Average |
|---|---|---|---|---|---|
| Stable Diffusion 1.5-based backbone | |||||
| SDv1.5 [38]‡ | 26.51 | 27.19 | 26.06 | 26.12 | 26.47 |
| InstaFlow-0.9B [26]‡ | 26.10 | 26.62 | 25.92 | 25.95 | 26.15 |
| DMD2 [54]‡ | 26.39 | 27.00 | 25.80 | 25.83 | 26.26 |
| PG-SB | 27.18 | 27.58 | 26.69 | 26.62 | 27.02 |
| PG-SB + NASA | 27.19 | 27.59 | 26.71 | 26.63 | 27.03 |
| Stable Diffusion 2.1-based backbone | |||||
| SDv2.1 [38]† | 27.48 | 26.89 | 26.86 | 27.46 | 27.17 |
| SB [33]† | 26.91 | 27.21 | 26.32 | 26.37 | 26.70 |
| SBv2 [7]† | 27.25 | 27.62 | 26.86 | 26.77 | 27.13 |
| PG-SB | 27.56 | 27.84 | 26.97 | 27.03 | 27.35 |
| PG-SB + NASA | 27.71 | 27.99 | 27.14 | 27.27 | 27.53 |
| PixArt-α-based backbone | |||||
| PixArt-α [6]‡ | 29.62 | 29.17 | 28.79 | 28.69 | 29.07 |
| YOSO [30]‡ | 28.79 | 28.09 | 28.57 | 28.55 | 28.50 |
| DMD [55]‡ | 29.31 | 28.67 | 28.46 | 28.41 | 28.71 |
| PG-SB | 32.19 | 29.09 | 30.39 | 29.69 | 30.34 |
| PG-SB + NASA | 32.56 | 29.55 | 31.24 | 30.96 | 31.08 |
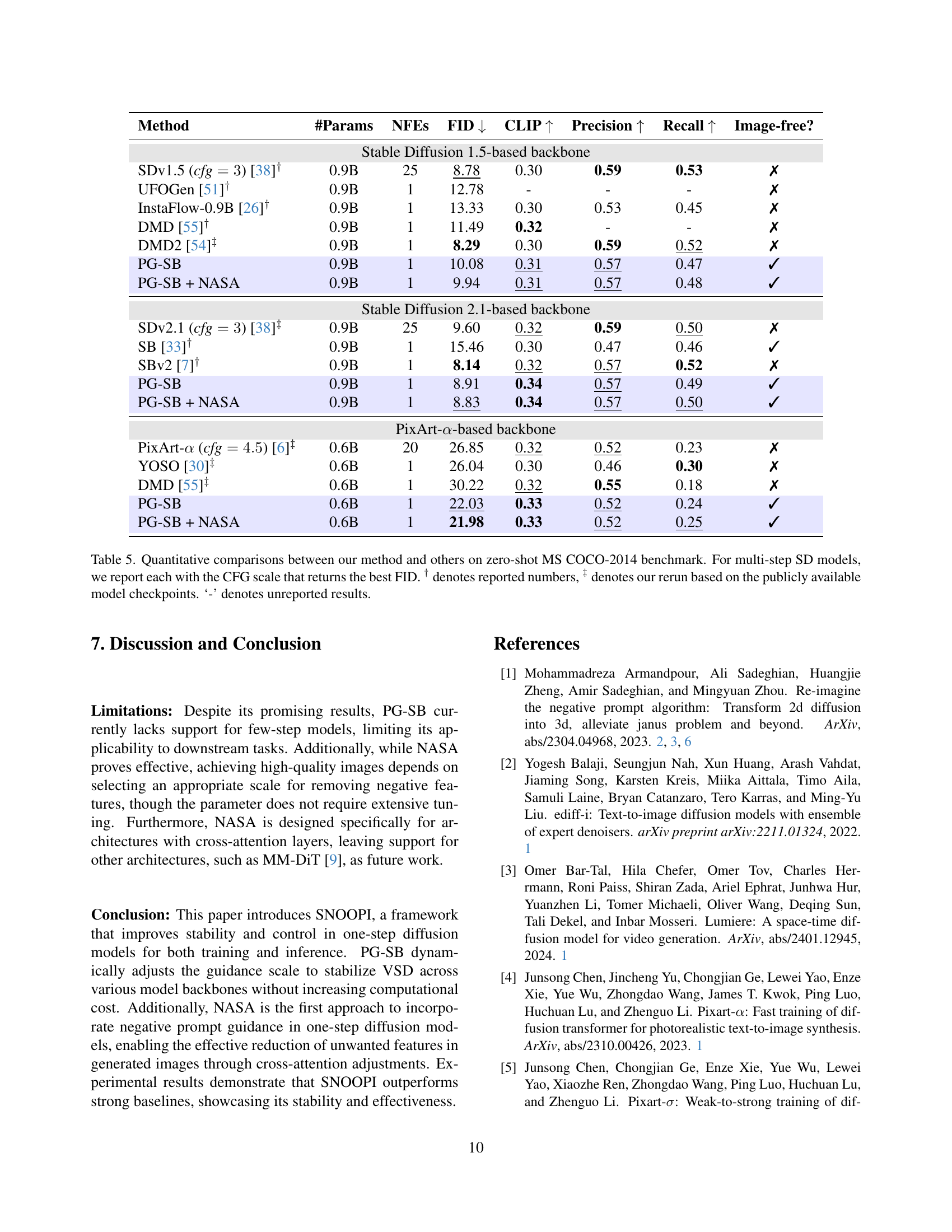
🔼 This table presents a comparison of Human Preference Score v2 (HPSv2) results for various text-to-image diffusion models, including different backbones (Stable Diffusion 1.5, Stable Diffusion 2.1, PixArt-a). It compares the performance of the proposed method (PG-SB and PG-SB + NASA) against several existing state-of-the-art models. The HPSv2 scores are shown for four image categories (Anime, Photo, Concept Art, Paintings), along with the average score across all categories. The notation † indicates scores reported by the original papers, while ‡ indicates scores obtained by rerunning the models using publicly available checkpoints to ensure consistent evaluation. The table highlights the improvement achieved by the proposed method in HPSv2, demonstrating its superior image quality compared to other models.
read the caption
Table 4: HPSv2 comparisons between our method and previous works. † denotes reported numbers, ‡ denotes our rerun based on the publicly available model checkpoints.
| Method | #Params | NFEs | FID ↓ | CLIP ↑ | Precision ↑ | Recall ↑ | Image-free? |
|---|---|---|---|---|---|---|---|
| Stable Diffusion 1.5-based backbone | |||||||
| SDv1.5 (cfg=3)† | 0.9B | 25 | 8.78 | 0.30 | 0.59 | 0.53 | ✗ |
| UFOGen† | 0.9B | 1 | 12.78 | - | - | - | ✗ |
| InstaFlow-0.9B† | 0.9B | 1 | 13.33 | 0.30 | 0.53 | 0.45 | ✗ |
| DMD† | 0.9B | 1 | 11.49 | 0.32 | - | - | ✗ |
| DMD2‡ | 0.9B | 1 | 8.29 | 0.30 | 0.59 | 0.52 | ✗ |
| PG-SB | 0.9B | 1 | 10.08 | 0.31 | 0.57 | 0.47 | ✓ |
| PG-SB + NASA | 0.9B | 1 | 9.94 | 0.31 | 0.57 | 0.48 | ✓ |
| Stable Diffusion 2.1-based backbone | |||||||
| SDv2.1 (cfg=3)‡ | 0.9B | 25 | 9.60 | 0.32 | 0.59 | 0.50 | ✗ |
| SB† | 0.9B | 1 | 15.46 | 0.30 | 0.47 | 0.46 | ✓ |
| SBv2† | 0.9B | 1 | 8.14 | 0.32 | 0.57 | 0.52 | ✗ |
| PG-SB | 0.9B | 1 | 8.91 | 0.34 | 0.57 | 0.49 | ✓ |
| PG-SB + NASA | 0.9B | 1 | 8.83 | 0.34 | 0.57 | 0.50 | ✓ |
| PixArt-α-based backbone | |||||||
| PixArt-α (cfg=4.5)‡ | 0.6B | 20 | 26.85 | 0.32 | 0.52 | 0.23 | ✗ |
| YOSO‡ | 0.6B | 1 | 26.04 | 0.30 | 0.46 | 0.30 | ✗ |
| DMD‡ | 0.6B | 1 | 30.22 | 0.32 | 0.55 | 0.18 | ✗ |
| PG-SB | 0.6B | 1 | 22.03 | 0.33 | 0.52 | 0.24 | ✓ |
| PG-SB + NASA | 0.6B | 1 | 21.98 | 0.33 | 0.52 | 0.25 | ✓ |
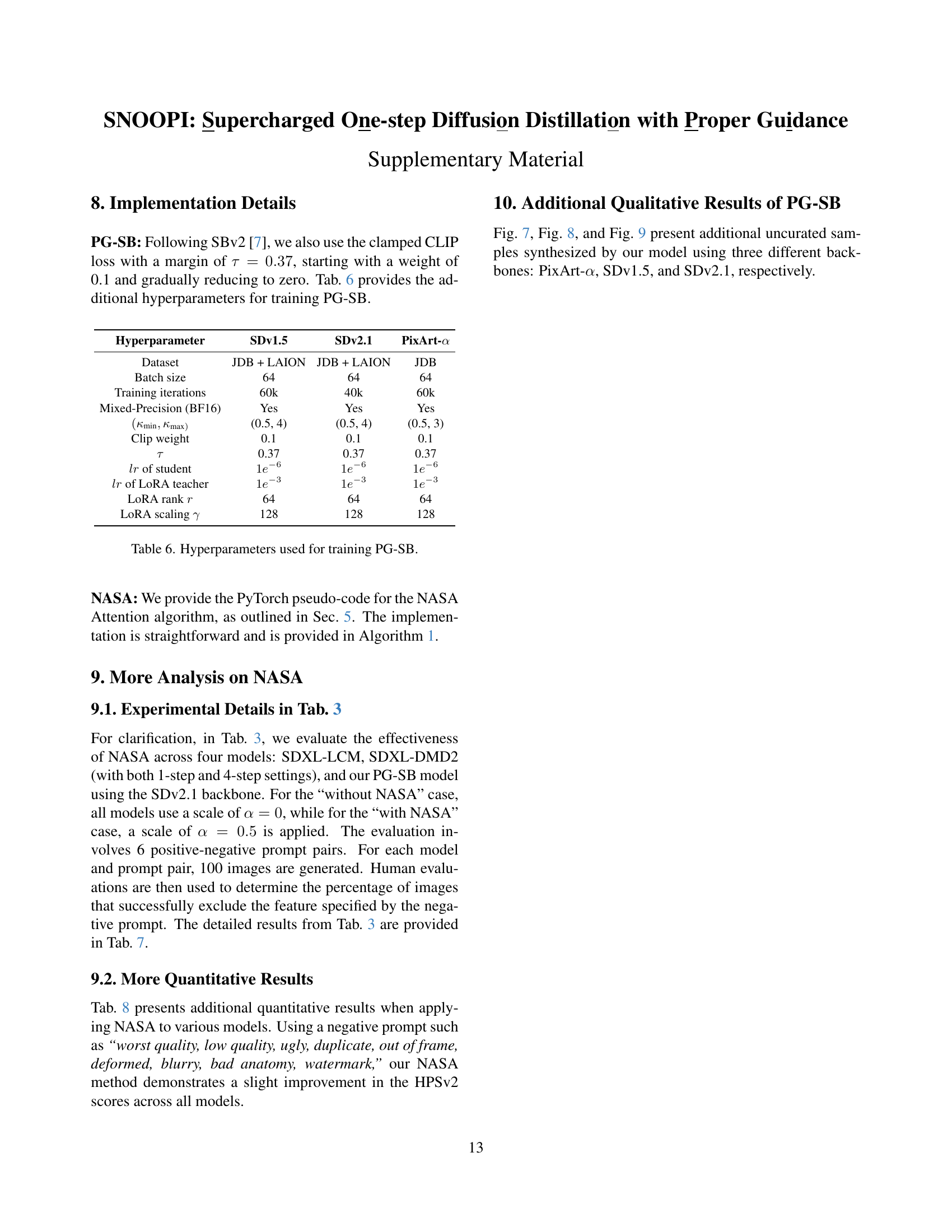
🔼 This table presents a quantitative comparison of various text-to-image generation models on the MS COCO-2014 benchmark, focusing on zero-shot performance. The models are evaluated across multiple metrics: number of function evaluations (NFEs), Fréchet Inception Distance (FID), CLIP score, precision, recall, and whether the model is image-free. For multi-step Stable Diffusion models, results are shown using the CFG scale that yielded the best FID score. Note that some results are taken from previously published works (denoted by †) while others are replicated by the authors of the current paper (denoted by ‡), using publicly available checkpoints; missing values are indicated by ‘-’. The table allows for a direct comparison of the efficiency (NFEs), image quality (FID, CLIP, Precision, Recall), and resource requirements (Image-free) of different approaches.
read the caption
Table 5: Quantitative comparisons between our method and others on zero-shot MS COCO-2014 benchmark. For multi-step SD models, we report each with the CFG scale that returns the best FID. † denotes reported numbers, ‡ denotes our rerun based on the publicly available model checkpoints. ‘-’ denotes unreported results.
| Hyperparameter | SDv1.5 | SDv2.1 | PixArt-α |
|---|---|---|---|
| Dataset | JDB + LAION | JDB + LAION | JDB |
| Batch size | 64 | 64 | 64 |
| Training iterations | 60k | 40k | 60k |
| Mixed-Precision (BF16) | Yes | Yes | Yes |
| (κmin,κmax) | (0.5, 4) | (0.5, 4) | (0.5, 3) |
| Clip weight | 0.1 | 0.1 | 0.1 |
| τ | 0.37 | 0.37 | 0.37 |
| lr of student | 1e-6 | 1e-6 | 1e-6 |
| lr of LoRA teacher | 1e-3 | 1e-3 | 1e-3 |
| LoRA rank r | 64 | 64 | 64 |
| LoRA scaling γ | 128 | 128 | 128 |
🔼 This table details the hyperparameters used during the training process of the Proper Guidance-SwiftBrush (PG-SB) model. It lists specific settings for three different diffusion model backbones: Stable Diffusion v1.5, Stable Diffusion v2.1, and PixArt-a. The hyperparameters include dataset used, batch size, number of training iterations, use of mixed precision training, the range of the guidance scale (κmin, κmax), the initial and final weight of the CLIP loss, the margin used in the CLIP loss, and the learning rate for both the student and LoRA teacher models, along with the rank and scaling factor of the LoRA adapter.
read the caption
Table 6: Hyperparameters used for training PG-SB.
| Positive prompt | Negative prompt | SDXL-LCM | SDXL-DMD2 | SDXL-DMD2 | PG-SB |
|---|---|---|---|---|---|
| “A photo of a person” | “male” | 52% → 99% | 26% → 100% | 29% → 100% | 42% → 81% |
| “A photo of a person” | “female” | 48% → 100% | 74% → 100% | 71% → 100% | 58% → 88% |
| “A photo of a person” | “young” | 55% → 100% | 44% → 100% | 7% → 100% | 39% → 96% |
| “A photo of a person” | “old” | 45% → 92% | 56% → 100% | 93% → 100% | 61% → 79% |
| “A photo of a pet” | “cat” | 36% → 100% | 12% → 100% | 60% → 100% | 32% → 99% |
| “A photo of a pet” | “dog” | 64% → 100% | 88% → 100% | 40% → 100% | 68% → 99% |
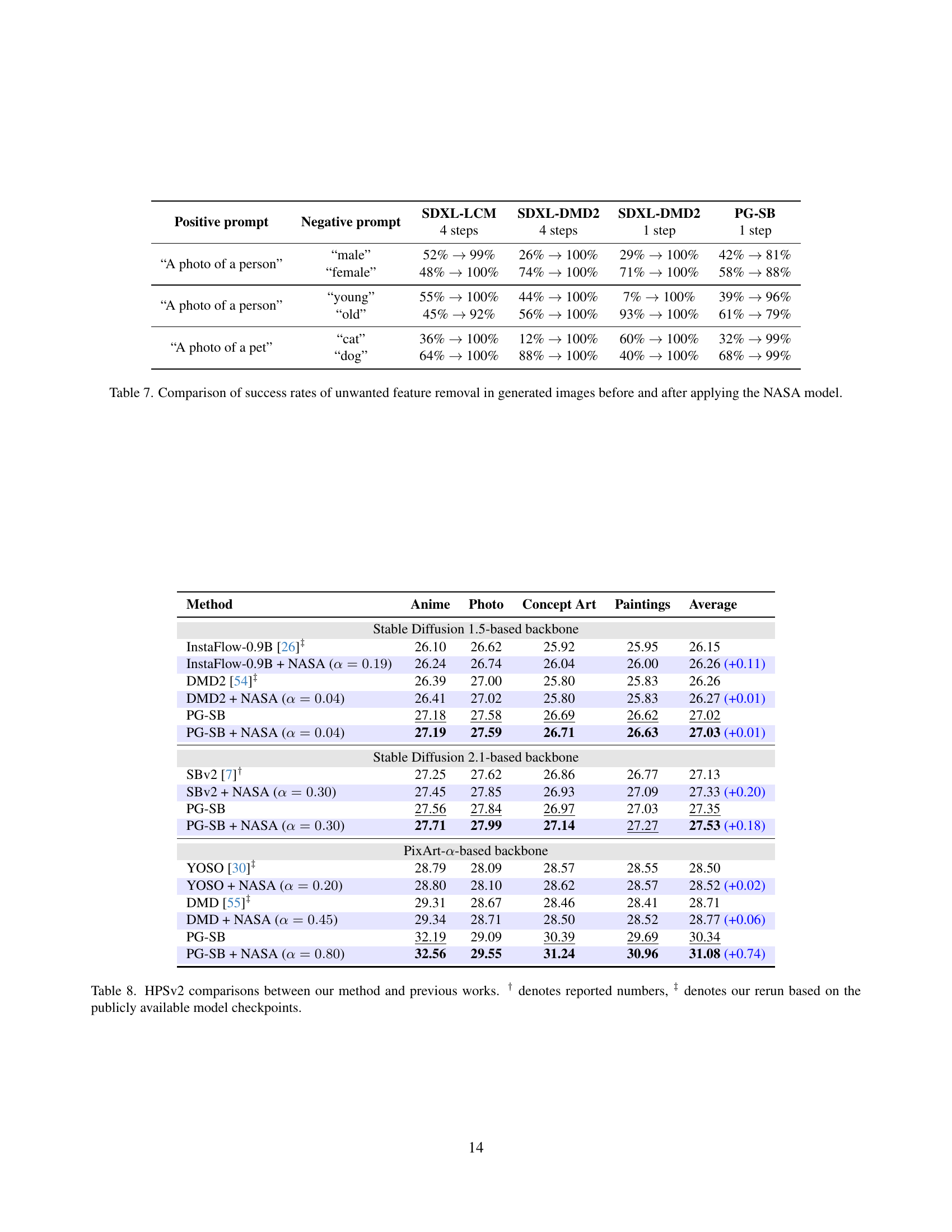
🔼 This table presents a comparison of success rates in removing unwanted features from images generated by different models. It compares the performance of four models (SDXL-LCM, SDXL-DMD2 4-step, SDXL-DMD2 1-step, and PG-SB 1-step) before and after incorporating the NASA module, which aims to enhance the control over unwanted features in image generation. The success rate is measured as the percentage of generated images where the specified negative feature is successfully excluded, given a positive and negative prompt pair. For each model, the success rate is reported for several different positive/negative prompt combinations.
read the caption
Table 7: Comparison of success rates of unwanted feature removal in generated images before and after applying the NASA model.
| Method | Anime | Photo | Concept Art | Paintings | Average |
|---|---|---|---|---|---|
| Stable Diffusion 1.5-based backbone | |||||
| InstaFlow-0.9B [26]‡ | 26.10 | 26.62 | 25.92 | 25.95 | 26.15 |
| InstaFlow-0.9B + NASA (α=0.19) | 26.24 | 26.74 | 26.04 | 26.00 | 26.26 (+0.11) |
| DMD2 [54]‡ | 26.39 | 27.00 | 25.80 | 25.83 | 26.26 |
| DMD2 + NASA (α=0.04) | 26.41 | 27.02 | 25.80 | 25.83 | 26.27 (+0.01) |
| PG-SB | 27.18 | 27.58 | 26.69 | 26.62 | 27.02 |
| PG-SB + NASA (α=0.04) | 27.19 | 27.59 | 26.71 | 26.63 | 27.03 (+0.01) |
| Stable Diffusion 2.1-based backbone | |||||
| SBv2 [7]† | 27.25 | 27.62 | 26.86 | 26.77 | 27.13 |
| SBv2 + NASA (α=0.30) | 27.45 | 27.85 | 26.93 | 27.09 | 27.33 (+0.20) |
| PG-SB | 27.56 | 27.84 | 26.97 | 27.03 | 27.35 |
| PG-SB + NASA (α=0.30) | 27.71 | 27.99 | 27.14 | 27.27 | 27.53 (+0.18) |
| PixArt-α-based backbone | |||||
| YOSO [30]‡ | 28.79 | 28.09 | 28.57 | 28.55 | 28.50 |
| YOSO + NASA (α=0.20) | 28.80 | 28.10 | 28.62 | 28.57 | 28.52 (+0.02) |
| DMD [55]‡ | 29.31 | 28.67 | 28.46 | 28.41 | 28.71 |
| DMD + NASA (α=0.45) | 29.34 | 28.71 | 28.50 | 28.52 | 28.77 (+0.06) |
| PG-SB | 32.19 | 29.09 | 30.39 | 29.69 | 30.34 |
| PG-SB + NASA (α=0.80) | 32.56 | 29.55 | 31.24 | 30.96 | 31.08 (+0.74) |
🔼 This table presents a comparison of HPSv2 (Human Preference Score v2) scores across different text-to-image generation models. The models are grouped by the underlying Stable Diffusion version (1.5, 2.1, or PixArt-a) used as a backbone. For each model and backbone, the table shows HPSv2 scores broken down by image category (Anime, Photo, Concept Art, Paintings). It includes scores for both baseline models and models with enhancements, particularly those involving the PG-SB (Proper Guidance - SwiftBrush) method and the NASA (Negative-Away Steer Attention) method proposed in this paper. Scores marked with † represent values reported in the original publications, while those marked with ‡ are scores re-generated by the authors of this paper based on publicly available model checkpoints to ensure fair comparison across all methods.
read the caption
Table 8: HPSv2 comparisons between our method and previous works. † denotes reported numbers, ‡ denotes our rerun based on the publicly available model checkpoints.
Full paper#