↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video diffusion models struggle with precise text understanding, limiting their ability to generate videos that faithfully reflect nuanced text descriptions. Large Language Models (LLMs) have shown promise for improving text comprehension but integrating them directly into existing video generation frameworks is challenging due to feature distribution mismatches between different text encoding paradigms.
Mimir introduces a novel token fusion mechanism to address these challenges. By carefully harmonizing the outputs of traditional text encoders and decoder-only LLMs, Mimir allows video diffusion models to leverage the superior text understanding capabilities of LLMs without compromising their ability to generate high-quality videos. Experiments demonstrate that Mimir significantly outperforms state-of-the-art methods in generating videos that closely match the textual descriptions, particularly in scenarios involving intricate spatial relationships, detailed color specifications, and complex temporal dynamics.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation and large language models. It directly addresses the challenge of integrating LLMs into video diffusion models for improved text understanding, a critical bottleneck in current research. The proposed method, Mimir, offers a novel solution with significant performance gains, opening new avenues for enhancing the quality and semantic richness of generated videos. Its findings will likely inspire further research on effectively harmonizing different text encoding methods to enhance various text-to-video generation tasks.
Visual Insights#

🔼 This figure showcases four video clips generated by the Mimir model, each illustrating its ability to vividly render detailed spatiotemporal scenes from concise text prompts. The first row shows an eagle soaring over a snow-covered forest, highlighting the model’s ability to create realistic and immersive natural landscapes. The second row depicts a woman in a red dress in a futuristic neon-lit setting, emphasizing its capacity for capturing atmospheric details and conveying a sense of mood. The third row demonstrates the model’s ability to generate physically accurate details, such as the petals of a flower in full bloom. Finally, the fourth row highlights Mimir’s ability to produce videos with accurate and nuanced illumination, as seen in the desert landscape which seamlessly transitions from day to night.
read the caption
Figure 1: Samples generated by Mimir. Our model demonstrates a powerful spatiotemporal imagination for input text prompts, e.g., (row-3) physically accurate petals, (row-4) the desert with illumination harmonization, which closely match human cognition.
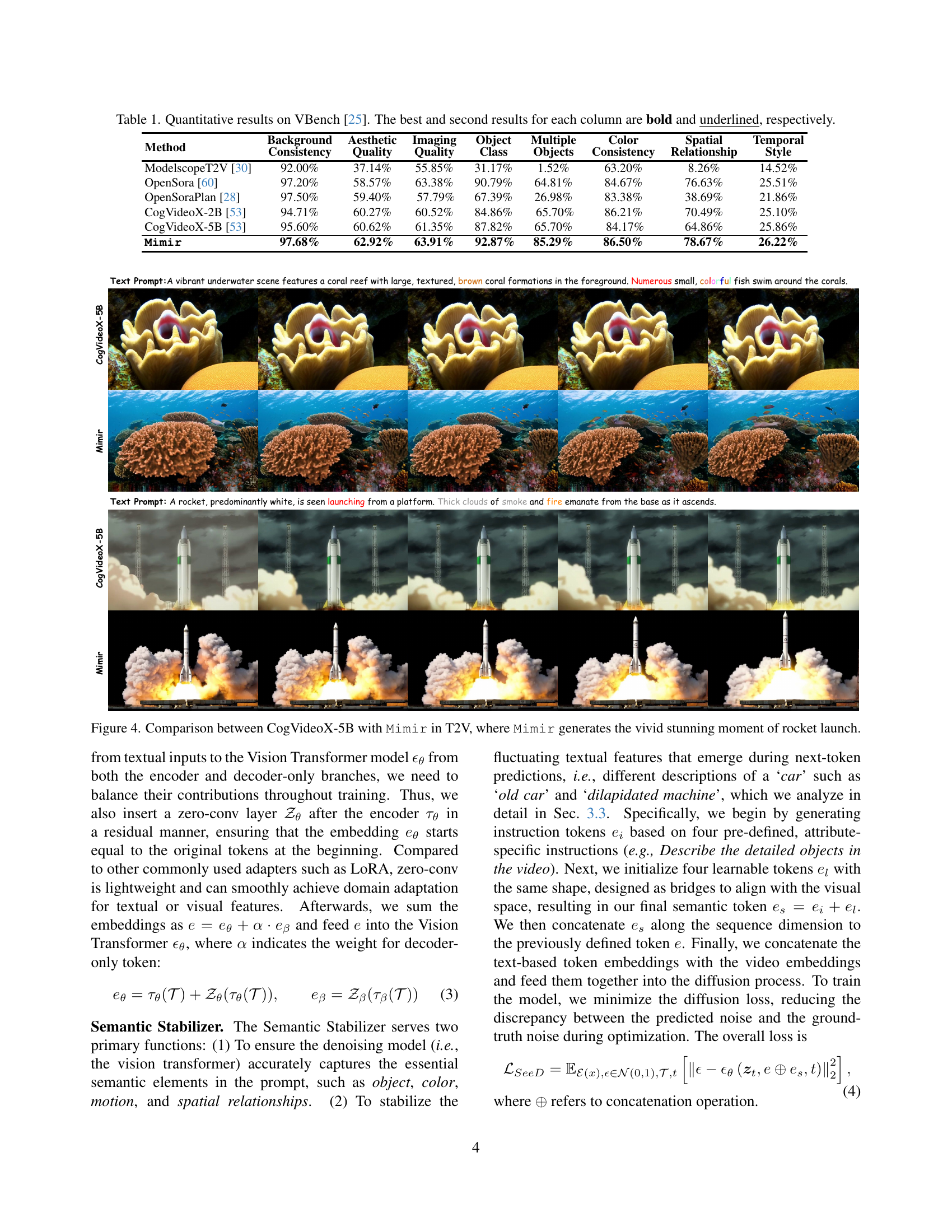
| Method | Background Consistency | Aesthetic Quality | Imaging Quality | Object Class | Multiple Objects | Color Consistency | Spatial Relationship | Temporal Style |
|---|---|---|---|---|---|---|---|---|
| ModelscopeT2V [30] | 92.00% | 37.14% | 55.85% | 31.17% | 1.52% | 63.20% | 8.26% | 14.52% |
| OpenSora [60] | 97.20% | 58.57% | 63.38% | 90.79% | 64.81% | 84.67% | 76.63% | 25.51% |
| OpenSoraPlan [28] | 97.50% | 59.40% | 57.79% | 67.39% | 26.98% | 83.38% | 38.69% | 21.86% |
| CogVideoX-2B [53] | 94.71% | 60.27% | 60.52% | 84.86% | 65.70% | 86.21% | 70.49% | 25.10% |
| CogVideoX-5B [53] | 95.60% | 60.62% | 61.35% | 87.82% | 65.70% | 84.17% | 64.86% | 25.86% |
| Mimir | 97.68% | 62.92% | 63.91% | 92.87% | 85.29% | 86.50% | 78.67% | 26.22% |
🔼 This table presents a quantitative comparison of the Mimir model against several state-of-the-art text-to-video generation models using the VBench benchmark [25]. The results are evaluated across multiple metrics, including background consistency, aesthetic quality, imaging quality, object class accuracy, the ability to generate multiple objects, color consistency, spatial relationships between objects, and temporal style consistency. The best and second-best performing models for each metric are highlighted in bold and underlined, respectively, to clearly show Mimir’s performance relative to other methods.
read the caption
Table 1: Quantitative results on VBench [25]. The best and second results for each column are bold and underlined, respectively.
In-depth insights#
Mimir: Precise Video#
The heading “Mimir: Precise Video” suggests a system, likely a model or algorithm, designed for generating highly detailed and accurate videos based on textual input. Precision is the keyword, implying superior control over the video generation process compared to existing methods. Mimir likely addresses the common limitations of current video diffusion models, which often struggle with accurately representing specific details, fine-grained motions, and complex spatial relationships described in text prompts. The name “Mimir,” referencing the Norse god of wisdom, further suggests a system characterized by superior understanding and intelligent generation. The focus on precise video generation implies a novel architecture or training methodology, potentially incorporating advances in large language models (LLMs) for enhanced semantic understanding or improvements to diffusion model architectures for better detail preservation. A key aspect would likely be the ability to translate nuanced textual descriptions, even those with ambiguous or complex instructions, into visually precise and faithful video renderings. This means effectively handling diverse aspects such as object attributes, interactions, lighting conditions, and temporal dynamics, all key aspects of high-quality video.
Token Fusion: LLMs#
The concept of ‘Token Fusion: LLMs’ in a video generation context suggests a powerful approach. It likely involves integrating the strengths of Large Language Models (LLMs) with traditional video diffusion models at the token level. LLMs excel at semantic understanding and contextual generation, providing a rich understanding of text prompts far beyond what standard text encoders can achieve. This richer understanding is crucial for generating videos with more complex and nuanced content. However, directly integrating LLMs is challenging because of their unique architecture (decoder-only) and how that differs from the typical encoder-based video diffusion models. Token fusion acts as the bridge, combining the encoded representations of text from both an LLM and a traditional encoder, harmonizing their outputs to be compatible with the video generation process. This carefully designed integration likely yields videos with improved accuracy, imagination, and temporal consistency that are closely aligned with the user’s intent as expressed in the text prompt. Success depends heavily on the fusion mechanism’s effectiveness in resolving any feature distribution mismatch between these distinct text representation methods.
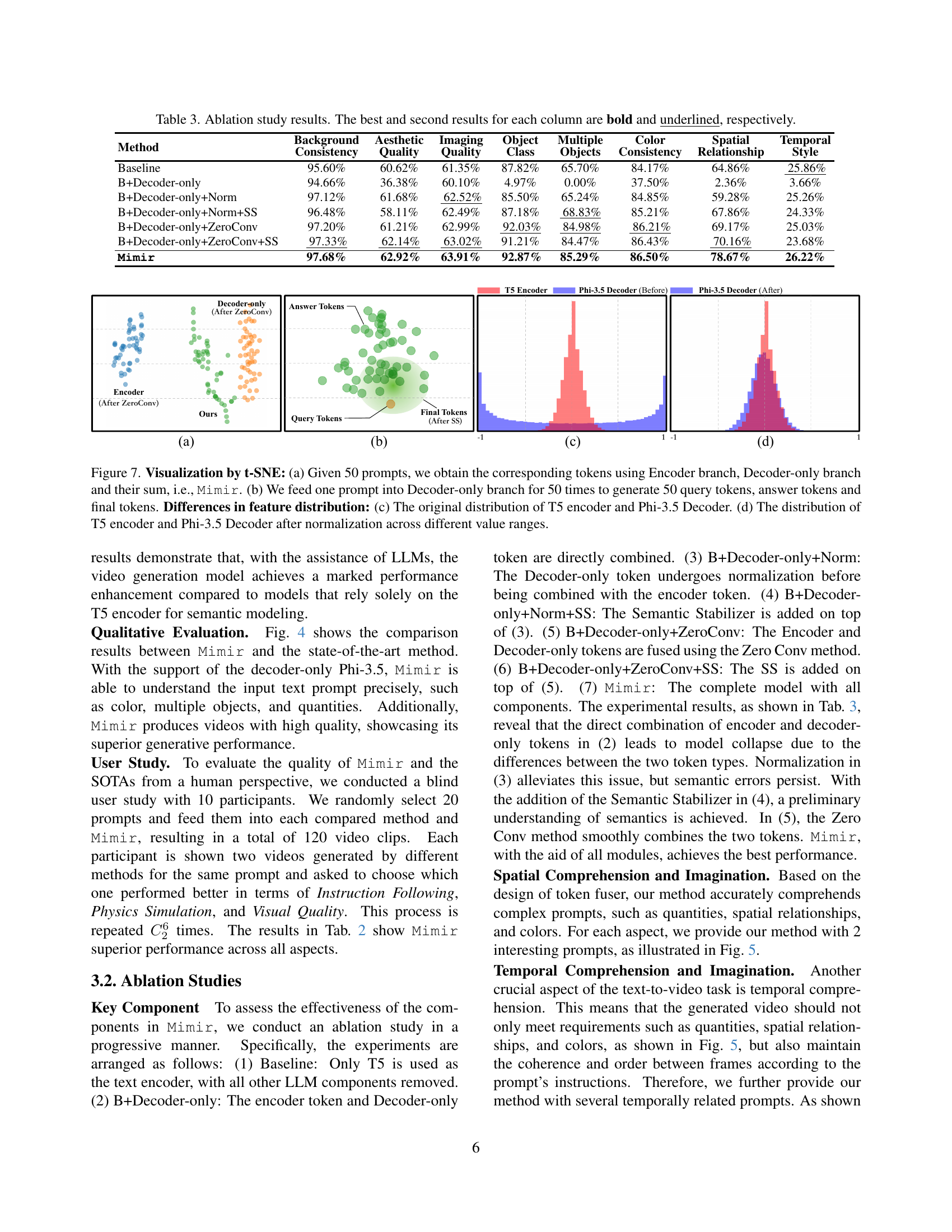
Ablation Study: Mimir#
An ablation study on Mimir, a video diffusion model designed for precise text understanding, would systematically remove components to assess their individual contributions. Removing the Token Fuser, which harmonizes text encoders and LLMs, would likely show a significant drop in text comprehension and video quality, highlighting its importance in bridging the gap between different text-modeling paradigms. Omitting the Semantic Stabilizer might lead to volatile text feature representations and reduced video coherence, as it mitigates the inherent variability of decoder-only language models. Analyzing the impact of removing the Zero-Conv layers, which preserve semantic space during training, would reveal their effectiveness in non-destructive token fusion. Finally, comparing results with and without instruction tuning would demonstrate the importance of this technique in prioritizing user interests. Through this systematic investigation, the ablation study would quantitatively and qualitatively validate the critical role of each Mimir component in achieving high-quality, textually-coherent video generation.
User Study: T2V#
A user study focusing on Text-to-Video (T2V) generation offers valuable insights into user perception and experience with the technology. It’s crucial to evaluate not just the technical aspects but also the human-centered experience. A well-designed user study would likely involve tasks assessing video quality, realism, adherence to textual prompts, and the overall satisfaction with the generated content. Participants might be asked to rate videos across various dimensions, perhaps using Likert scales or comparative rankings. Qualitative data, such as open-ended feedback or think-aloud protocols, should be included to understand the why behind users’ ratings. Analyzing differences in user preferences based on demographic factors (e.g., age, tech-savviness) reveals valuable insights into potential target audiences and areas for improvement. The study should also address the ethical implications of the technology and incorporate guidelines for responsible use to ensure the T2V system is developed and used ethically. A holistic approach, considering technical performance, user perception, and ethical implications, is crucial for maximizing the value and impact of the user study and the resulting T2V model.
Future: T2V Research#
Future research in text-to-video (T2V) generation should prioritize bridging the gap between the capabilities of large language models (LLMs) and video diffusion models. Current methods often struggle with precise text understanding and generating high-quality videos that accurately reflect complex instructions. Therefore, future work needs to focus on developing advanced token fusion techniques, such as those presented in Mimir, which harmoniously integrate the strengths of both LLMs and video diffusion models. Furthermore, research into improving the training data is critical; more diverse and high-quality datasets are needed to enhance model generalization and reduce reliance on specific training domains. Addressing issues of video length and temporal consistency is also paramount. Current models often produce short, low-resolution videos prone to errors; innovative approaches to generating longer, temporally coherent videos that maintain quality need to be explored. Finally, mitigating the ethical concerns associated with T2V technology is crucial. Future research should investigate robust detection methods to combat potential misuse, such as generating fake videos or promoting misinformation. Collaborative efforts between researchers and policymakers are needed to develop responsible guidelines for ethical T2V applications.
More visual insights#
More on figures

🔼 The figure illustrates the core concept of the Mimir model. Traditional text encoders, while effective for fine-tuning existing text-to-video (T2V) models, suffer from limitations in text comprehension. Conversely, decoder-only large language models (LLMs) excel at understanding text but cannot be directly integrated into existing T2V models due to differences in feature distributions and the inherent instability of their features. The Mimir model overcomes this challenge by introducing a token fuser that harmonizes the outputs from both text encoders and LLMs, enabling precise text understanding and high-quality video generation.
read the caption
Figure 2: The core idea of Mimir. Text Encoder is well suited for fine-tuning pre-trained T2V models (✓), however it struggles with limited text comprehension (✗). In contrast, Decoder-only LLM excels at precise text understanding (✓), but cannot be directly used in established video generation models since the feature distribution gap and the feature volatility (✗) . Therefore, we propose the token fuser in Mimir to harmonize multiple tokens, achieving precise text understanding (✓) in T2V generation (✓).

🔼 Mimir uses a text encoder and a decoder-only large language model to process text prompts, generating embeddings eθ and eβ respectively. An instruction prompt is also processed by the decoder-only model, creating instruction token ei. To address potential training convergence issues due to differing feature distributions between eθ and eβ, Mimir’s token fuser normalizes and scales eβ, applies Zero-Conv to preserve semantic space, and sums the results with eθ to produce a combined embedding e ∈ ℝn x 4096. Four learnable tokens el are initialized and added to ei to stabilize semantic features, resulting in es. Finally, the fuser concatenates e and es to generate the video.
read the caption
Figure 3: The framework of Mimir. Given a text prompt, we employ a text encoder and a decoder-only large language model to obtain eθsubscript𝑒𝜃e_{\theta}italic_e start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT and eβsubscript𝑒𝛽e_{\beta}italic_e start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT. Additionally, we add an instruction prompt which, after processing by the decoder-only model, yields the corresponding instruction token eisubscript𝑒𝑖e_{i}italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. See token details in Sec. 2.2. To prevent any convergence issue in training caused by the feature distribution gap of eθsubscript𝑒𝜃e_{\theta}italic_e start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT and eβsubscript𝑒𝛽e_{\beta}italic_e start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT, the proposed token fuser first applies a normalization layer and a learnable scale to eβsubscript𝑒𝛽e_{\beta}italic_e start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT. It then uses Zero-Conv to preserve the original semantic space in the early of training. These modified tokens are then summed to produce e∈ℝn×4096𝑒superscriptℝ𝑛4096e\in\mathbb{R}^{n\times 4096}italic_e ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × 4096 end_POSTSUPERSCRIPT. Meanwhile, we initialize four learnable tokens elsubscript𝑒𝑙e_{l}italic_e start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT, which are added to eisubscript𝑒𝑖e_{i}italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT to stabilize divergent semantic features. Finally, the token fuser concatenates e𝑒eitalic_e and essubscript𝑒𝑠e_{s}italic_e start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT to generate videos.

🔼 This figure showcases a comparison of video generation results between two models: CogVideoX-5B and Mimir. The models were prompted to generate a video of a rocket launch. The comparison highlights Mimir’s superior ability to generate more vivid and stunning visuals of the rocket launch, with more realistic details and a more dynamic depiction of the event.
read the caption
Figure 4: Comparison between CogVideoX-5B with Mimir in T2V, where Mimir generates the vivid stunning moment of rocket launch.

🔼 This figure showcases Mimir’s ability to understand and generate images based on complex spatial descriptions. It demonstrates the model’s capabilities in several key areas: * Quantities: Accurately representing the specified number of objects (e.g., ’two apples,’ ’three apples’). * Spatial Relationships: Correctly positioning objects relative to each other (e.g., ‘sitting to the left of,’ ‘sitting to the right of’). * Colors: Accurately rendering the specified colors of objects (e.g., ’neon pink elephant,’ ‘chartreuse zebra’). The examples illustrate Mimir’s capacity for spatial reasoning and creative image synthesis beyond simply following basic instructions.
read the caption
Figure 5: Mimir demonstrates spatial comprehension and imagination, e.g., quantities, spatial relationships, colors, etc.

🔼 Figure 6 showcases Mimir’s ability to understand and generate videos depicting temporal concepts such as direction of movement, sequences of actions, and appearances/disappearances of objects over time. Examples include a puppy looking left and right, a lion looking right and then left, a bird turning its head and then flapping its wings, a rabbit raising its ears and then jumping, and the moon changing phases. The figure highlights Mimir’s capability to accurately represent and synchronize these temporal elements within the generated video content.
read the caption
Figure 6: Mimir demonstrates temporal comprehension and imagination, e.g., direction, order of motion and appearance / disappearance.

🔼 This figure uses t-SNE to visualize the token distributions from different components of the Mimir model. Panel (a) shows the combined token embeddings from the text encoder and decoder-only LLM for 50 different prompts, representing the Mimir model’s integrated output. Panel (b) demonstrates the variability of the decoder-only LLM by showing 50 separate sets of query, answer, and final tokens generated from the same prompt, highlighting the LLM’s inherent dynamism and capacity for diverse outputs. Panels (c) and (d) compare the distributions of T5 encoder tokens and Phi-3.5 decoder tokens, showing the difference between their original distributions (c) and how normalization brings them closer together (d), illustrating the effectiveness of the normalization strategy used in Mimir’s token fuser.
read the caption
Figure 7: Visualization by t-SNE: (a) Given 50 prompts, we obtain the corresponding tokens using Encoder branch, Decoder-only branch and their sum, i.e., Mimir. (b) We feed one prompt into Decoder-only branch for 50 times to generate 50 query tokens, answer tokens and final tokens. Differences in feature distribution: (c) The original distribution of T5 encoder and Phi-3.5 Decoder. (d) The distribution of T5 encoder and Phi-3.5 Decoder after normalization across different value ranges.

🔼 Figure 8 showcases additional examples of videos generated by the Mimir model. These examples highlight Mimir’s ability to generate high-quality videos from various text prompts, demonstrating the model’s capabilities in handling different aspects of video generation including detailed descriptions of scenes, animation, and complex spatiotemporal relationships. The examples serve as further evidence of Mimir’s strong text comprehension and video generation capabilities.
read the caption
Figure 8: We present more cases generated by Mimir.

🔼 This figure illustrates the data preprocessing pipeline used in the paper. The pipeline consists of several stages: First, collected videos undergo basic filtration, removing videos that do not meet basic criteria (e.g., too short, incorrect aspect ratio). Next, quality filtration removes videos with poor quality based on metrics like black area percentage, brightness, and black frame rate. Aesthetic filtration removes videos that do not meet aesthetic criteria. Finally, watermark filtration removes videos containing watermarks and a re-captioning step generates new captions for the videos. The result of this pipeline is a set of high-quality videos with accurate captions, ready for use in training the model.
read the caption
Figure 9: The pipeline for preparing data.

🔼 This figure compares the video generation results of Mimir using both short, imprecise prompts and long, detailed prompts. It showcases Mimir’s ability to generate high-quality videos even with concise instructions, highlighting the effectiveness of its token fuser in expanding semantic understanding.
read the caption
Figure 10: The comparison between results with short & course prompts and long & fine prompts.

🔼 This figure showcases the model’s ability to accurately render colors specified in text prompts. It demonstrates that the model can generate videos where objects have colors that precisely match the input descriptions. This is particularly impressive in cases with multiple objects, each requiring a different, specific color. The color accuracy highlights the effectiveness of the proposed token fusion method in ensuring semantic consistency between the text and the generated video.
read the caption
Figure 11: More examples in terms of color rendering.

🔼 This figure demonstrates the model’s ability to understand and accurately represent spatial relationships described in text prompts. It showcases examples where objects are correctly positioned relative to each other (e.g., left, right, top, bottom) and examples demonstrating understanding of absolute positions.
read the caption
Figure 12: More examples in terms of absolute & relative position.

🔼 This figure visually demonstrates Mimir’s capacity for accurate quantitative understanding. It presents several examples of video clips generated based on prompts specifying precise counts of objects. Each row features a different prompt and showcases the video sequence generated by Mimir, correctly reflecting the stated number of objects (e.g., one lotus flower, two butterflies, three birds). This highlights the model’s ability to process and accurately represent numerical information within the video generation process.
read the caption
Figure 13: More examples in terms of counting.

🔼 This figure showcases Mimir’s ability to generate videos depicting sequential actions performed by an object over time. Multiple example videos are shown, each demonstrating accurate temporal understanding. The model correctly sequences actions, even in scenarios involving more complex patterns of motion.
read the caption
Figure 14: More examples in terms of action sequence over time.

🔼 This figure showcases the model’s ability to realistically depict changes in lighting conditions over time. The examples demonstrate a smooth and natural progression of light, from the gradual fading of stars at dawn to the fiery brilliance of a sunrise over the sea, and finally to the subtle illumination of sunlight filtering through forest leaves in the evening, and ending with moonlight reflecting on a glacier. The model accurately captures and harmonizes changes in illumination, including transitions between day and night and subtle shifts in light intensity and color.
read the caption
Figure 15: More examples in terms of light changes, showcasing the illumination harmonization over time.
More on tables
| Method | ModelScopeT2V | OpenSora | OpenSoraPlan | CogVideoX-2b | CogVideoX-5b | Mimir |
|---|---|---|---|---|---|---|
| Instruction Following ↑ | 2.45% | 52.15% | 27.75% | 63.50% | 72.15% | 82.00% |
| Physics Simulation ↑ | 3.50% | 47.95% | 54.75% | 52.85% | 57.30% | 83.65% |
| Visual Quality ↑ | 1.60% | 49.20% | 41.50% | 54.80% | 63.25% | 89.65% |
🔼 This user study compares the performance of Mimir against several state-of-the-art text-to-video models across three key aspects: instruction following, physics simulation, and visual quality. For each aspect, a user study was performed to assess which model produced the best results, evaluating performance on a scale. The highest scores for each category are highlighted in bold and underlined to clearly indicate the best-performing models in the user study. This table helps demonstrate Mimir’s user-perceived strengths relative to existing methods.
read the caption
Table 2: User study results. The best and second results for each column are bold and underlined, respectively.
| Method | Background Consistency | Aesthetic Quality | Imaging Quality | Object Class | Multiple Objects | Color Consistency | Spatial Relationship | Temporal Style |
|---|---|---|---|---|---|---|---|---|
| Baseline | 95.60% | 60.62% | 61.35% | 87.82% | 65.70% | 84.17% | 64.86% | 25.86% |
| B+Decoder-only | 94.66% | 36.38% | 60.10% | 4.97% | 0.00% | 37.50% | 2.36% | 3.66% |
| B+Decoder-only+Norm | 97.12% | 61.68% | 62.52% | 85.50% | 65.24% | 84.85% | 59.28% | 25.26% |
| B+Decoder-only+Norm+SS | 96.48% | 58.11% | 62.49% | 87.18% | 68.83% | 85.21% | 67.86% | 24.33% |
| B+Decoder-only+ZeroConv | 97.20% | 61.21% | 62.99% | 92.03% | 84.98% | 86.21% | 69.17% | 25.03% |
| B+Decoder-only+ZeroConv+SS | 97.33% | 62.14% | 63.02% | 91.21% | 84.47% | 86.43% | 70.16% | 23.68% |
| Mimir | 97.68% | 62.92% | 63.91% | 92.87% | 85.29% | 86.50% | 78.67% | 26.22% |
🔼 This ablation study analyzes the impact of different components of the Mimir model on its performance. The table shows quantitative results across various metrics (Background Consistency, Aesthetic Quality, Imaging Quality, Object Class, Multiple Objects, Color Consistency, Spatial Relationship, and Temporal Style) for several model variants. The variants progressively include key components of the Mimir architecture: a decoder-only model, normalization, a semantic stabilizer, and a zero-convolution layer. Comparing the results across these variants highlights the contribution of each component to the overall performance improvements achieved by the complete Mimir model. The best and second-best results in each metric are highlighted for easy comparison.
read the caption
Table 3: Ablation study results. The best and second results for each column are bold and underlined, respectively.
Full paper#