↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text watermarking methods often suffer from limitations in robustness and capacity. Many existing techniques are vulnerable to attacks such as word substitutions or sentence paraphrasing, limiting their practical applicability. They may also have low bit-rate, limiting the amount of information that can be embedded. Additionally, the reliance on lexical-based methods makes them susceptible to synonym replacement, compromising the effectiveness of the watermark.
This research introduces a novel approach to text watermarking using Large Language Models (LLMs). The core idea is to embed the watermark by using two fine-tuned LLM paraphrasers alternatively. The alternative paraphrasing creates subtle differences in the text semantics that a trained classifier can effectively detect. This technique offers significant improvements in robustness against various attacks, including word substitutions and sentence paraphrasing, demonstrating high accuracy (over 99.99% detection AUC) even under perturbations. The method’s ability to embed multi-bit watermarks further enhances its information capacity.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and robust multi-bit text watermarking method. Its use of LLMs for paraphrasing offers a significant advancement over existing techniques, increasing robustness against various attacks. The open-sourced codebase facilitates further research and real-world applications, making it relevant to researchers in multiple areas such as copyright protection, data provenance, and misinformation detection.
Visual Insights#

🔼 This figure illustrates the two-stage process of the proposed text watermarking system. The encoding stage uses an encoder (a paraphraser model fine-tuned with a specific key) to transform the original input text, embedding the watermark information. The decoder stage then takes the watermarked text and, using a trained classifier, extracts the embedded bits to recover the original watermark. The key acts as a secret, ensuring only authorized parties with the same key can successfully decode the watermark.
read the caption
Figure 1: The overview of our watermark pipeline. During encoding, we use an encoder to parapharse the input text given a user-chosen key. During decoding, we extract the bits from the text using the decoder.
| Method | Bit-wise Accuracy | Text-wise Accuracy | Fidelity | ||||
|---|---|---|---|---|---|---|---|
| Bit Acc | Bit Num | AUC | TPR@FPR=1% | TPR@FPR=0.01% | Similarity | ||
| — | — | — | — | — | — | — | |
| RemarkLLM (4bit) | 0.7663 | 4.0 | 0.7861 | 0.0% | 0.0% | 0.8096 | |
| RemarkLLM (8bit) | 0.6953 | 8.0 | 0.8023 | 3.7% | 0.0% | 0.7793 | |
| KGW (zero-bit) | - | - | 0.8652 | 25.9% | 18.1% | 0.7745 | |
| KGW (multi-bit) | 0.6381 | 4.46 | 0.8327 | 22.9% | 6.3% | 0.8123 | |
| KTH (zero-bit) | - | - | 0.8919 | 61.4% | 46.6% | 0.8200 | |
| KTH (multi-bit) | 0.6129 | 4.26 | 0.6775 | 10.9% | 2.3% | 0.8176 | |
| Waterfall(κ=0.5) | - | - | 0.7787 | 14.0% | 3.8% | 0.8499 | |
| Waterfall(κ=1) | - | - | 0.9392 | 62.4% | 35.5% | 0.8423 | |
| Ours | 0.9563 | 5.57 | 0.9981 | 98.0% | 78.0% | 0.8739 |
🔼 This table compares the performance of the proposed multi-bit text watermarking method against several baseline techniques. The evaluation metrics include bit-wise accuracy (how accurately individual bits of the watermark are recovered), text-wise accuracy (the area under the ROC curve (AUC) and true positive rates at 1% and 0.01% false positive rates), and fidelity (similarity between the original and watermarked texts). RemarkLLM, a baseline method, uses the T5 model from Raffel et al. (2020), while the other methods utilize the TinyLlama-1.1B model from Zhang et al. (2024a). The bit-wise accuracy is marked as ‘-’ for methods that don’t support multi-bit watermarks.
read the caption
Table 1: The performance of our watermark compared with baseline methods. The RemarkLLM method uses the T5 Raffel et al. (2020) model following their original settings. Other methods use TinyLlama-1.1B Zhang et al. (2024a) as the paraphraser. The bit-wise accuracy is marked as “-” if the method does not support multi-bit watermark code.
In-depth insights#
LLM-based watermarking#
LLM-based watermarking represents a significant advancement in digital watermarking techniques, leveraging the power of large language models (LLMs) to embed imperceptible yet detectable information within text. This approach offers several key advantages: enhanced robustness against various attacks (e.g., paraphrasing, synonym replacement), increased capacity for embedding larger amounts of data, and improved invisibility due to LLM’s natural language generation capabilities. However, challenges remain, including maintaining semantic fidelity while embedding the watermark, designing effective and robust detection methods, and addressing potential vulnerabilities to adversarial attacks designed to remove or corrupt the watermark. The effectiveness of LLM-based watermarking is heavily dependent on the quality of the LLM used and the training strategies employed. Future research will likely focus on developing more sophisticated algorithms, exploring alternative LLM architectures, and enhancing the robustness and security of these watermarking schemes.
Paraphrase encoding#
Paraphrase encoding, in the context of robust multi-bit text watermarking, presents a novel approach to embedding information imperceptibly within text. Instead of relying on simple synonym replacement, it leverages the power of large language models (LLMs) to generate semantically similar paraphrases. The core idea is to fine-tune two LLMs to produce distinct yet meaningfully equivalent versions of the same sentence, encoding information in the subtle differences between these paraphrases. A trained decoder can then identify these differences to recover the embedded watermark. This technique offers significant advantages: it expands the action space for watermark injection, thus improving robustness against attacks such as word substitution, and maintains high fidelity to the original text’s meaning. The use of LLMs is key to the method’s effectiveness, offering robustness against simpler attacks by providing a much larger space of potential paraphrases compared to methods relying on simple synonym substitution. However, challenges remain; for instance, ensuring consistent performance across different text styles and preventing the decoder from learning superficial cues rather than true semantic differences. The success hinges on the careful fine-tuning of both the encoder (the paraphrasing LLMs) and decoder (the classifier), potentially requiring sophisticated training strategies such as reinforcement learning and adversarial training. Furthermore, the scalability of this approach for longer text or more complex watermarks remains a consideration. Ultimately, paraphrase encoding offers a promising pathway toward more robust and imperceptible text watermarking.
Robustness analysis#
A robust robustness analysis for a text watermarking system would involve evaluating its resilience against various attacks and perturbations. The primary focus should be on evaluating the accuracy of watermark detection after the watermarked text has been subjected to transformations. These transformations could include synonym replacement, word deletions, insertions, and sentence-level paraphrasing. The analysis should quantify the impact of different perturbation levels on detection accuracy, ideally using metrics like AUC (Area Under the Curve) and bit error rate. Beyond simple text manipulations, the analysis should also consider more sophisticated attacks, such as those employing language models to remove or alter the watermark. The evaluation should also investigate the impact of data distribution shifts and assess whether the watermarking algorithm maintains its effectiveness on out-of-distribution data. Quantifying the robustness to various attack strategies is key to establishing trust in the watermarking system. Finally, it’s crucial to provide clear guidelines on the types and magnitudes of transformations the system can withstand without significant performance degradation, specifying acceptable thresholds for these metrics to fully characterize the robustness of the proposed method.
Multi-bit watermark#
The concept of a multi-bit watermark in a text-based system presents a significant advancement over traditional single-bit methods. Instead of embedding just a 0 or 1, multiple bits of information can be encoded into each segment of the text, greatly increasing the capacity for data hiding. This has significant implications for copyright protection and data integrity. The paper likely explores various techniques for embedding these bits effectively and imperceptibly, perhaps utilizing advanced paraphrasing methods with LLMs to maintain the text’s semantic meaning while ensuring the watermark is robust against common perturbations and attacks. A key consideration is the trade-off between watermark capacity (number of bits per unit of text) and its robustness to alterations. Higher capacity could mean more information hidden, but it might also lead to increased susceptibility to removal or detection. The success of such a multi-bit system hinges on the effectiveness of both the encoding (embedding) and decoding (extraction) processes, which likely involve sophisticated algorithms and machine learning models.
Future directions#
Future research could explore several promising avenues. Improving the robustness of the watermark against sophisticated attacks is crucial. This might involve developing more advanced encoding and decoding techniques, perhaps leveraging adversarial training methods or incorporating techniques from steganography. Investigating alternative methods of watermark embedding beyond paraphrasing could lead to more efficient or less perceptible watermarking schemes. Exploring techniques that operate at the word or sub-word level instead of the sentence level might increase the capacity or improve stealth. A thorough analysis of the watermark’s impact on downstream tasks such as machine translation or sentiment analysis is necessary to assess real-world applicability and potential limitations. Finally, developing more comprehensive and rigorous evaluation metrics that account for both detection accuracy and imperceptibility is vital to better compare and benchmark future watermarking systems. Addressing concerns around potential misuse for malicious purposes is also crucial and requires careful consideration of ethical implications.
More visual insights#
More on tables
| Method | Substitute ratio 5% | Substitute ratio 10% | Substitute ratio 20% | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| bitacc | AUC | TPR@1% | bitacc | AUC | TPR@1% | bitacc | AUC | TPR@1% | ||
| — | — | — | — | — | — | — | — | — | — | — |
| RemarkLLM (4bit) | 0.6118 | 0.6215 | 0.0% | 0.6315 | 0.6441 | 0.0% | 0.6488 | 0.6624 | 0.0 | |
| RemarkLLM (8bit) | 0.5685 | 0.6281 | 0.6% | 0.5783 | 0.6445 | 1.0% | 0.5921 | 0.6665 | 0.8% | |
| KGW (zero-bit) | - | 0.8458 | 21.4% | - | 0.8353 | 16.5% | - | 0.7779 | 7.0% | |
| KGW (multi-bit) | 0.6208 | 0.8052 | 20.9% | 0.6134 | 0.7914 | 18.9% | 0.5840 | 0.7471 | 12.8% | |
| KTH (zero-bit) | - | 0.8718 | 56.5% | - | 0.8541 | 51.8% | - | 0.8128 | 41.5% | |
| KTH (multi-bit) | 0.6018 | 0.6574 | 9.0% | 0.5955 | 0.6504 | 8.0% | 0.5610 | 0.6120 | 5.1% | |
| Waterfall(κ=0.5) | - | 0.7578 | 12.5% | - | 0.7344 | 9.1% | - | 0.6893 | 5.3% | |
| Waterfall(κ=1) | - | 0.9250 | 54.1% | - | 0.9096 | 28.9% | - | 0.8558 | 25.6% | |
| Ours | 0.9382 | 0.9945 | 93.5% | 0.9193 | 0.9871 | 86.4% | 0.8605 | 0.9469 | 51.6% | |
| Ours(advt) | 0.9459 | 0.9958 | 94.1% | 0.9352 | 0.9936 | 91.6% | 0.9138 | 0.9853 | 78.7% |
🔼 This table presents a comparison of the performance of different text watermarking methods, including the proposed method, under word substitution attacks. It shows how well each method maintains the watermark’s integrity when a certain percentage (5%, 10%, and 20%) of the words in the watermarked text are randomly replaced with other words. The metrics used for comparison include bit accuracy (Bit Acc), Area Under the Curve (AUC), True Positive Rate at a False Positive Rate of 1% (TPR@1%), and the fidelity of the paraphrased text.
read the caption
Table 2: The performance of our watermark compared with baseline methods under word substitution attack.
| Method | Translate bitacc | Translate AUC | Translate TPR@1% | LlamaPara bitacc | LlamaPara AUC | LlamaPara TPR@1% | PegasusPara bitacc | PegasusPara AUC | PegasusPara TPR@1% |
|---|---|---|---|---|---|---|---|---|---|
| RemarkLLM (4bit) | 0.6885 | 0.7142 | 0.0% | 0.7063 | 0.7311 | 0.0% | 0.7033 | 0.7248 | 0.0% |
| RemarkLLM (8bit) | 0.6124 | 0.6904 | 1.4% | 0.6023 | 0.6751 | 1.5% | 0.6018 | 0.6687 | 1.2% |
| KGW (zero-bit) | - | 0.4872 | 0.2% | - | 0.4872 | 0.2% | - | 0.4900 | 0.0% |
| KGW (multi-bit) | 0.4997 | 0.5829 | 1.6% | 0.4765 | 0.5383 | 1.5% | 0.4817 | 0.5654 | 1.5% |
| KTH (zero-bit) | - | 0.8600 | 30.6% | - | 0.8559 | 32.0% | - | 0.8618 | 43.7% |
| KTH (multi-bit) | 0.4923 | 0.4990 | 0.8% | 0.4952 | 0.4957 | 1.7% | 0.4949 | 0.5025 | 1.3% |
| Waterfall(κ=0.5) | - | 0.6041 | 4.0% | - | 0.5833 | 1.9% | - | 0.5981 | 5.0% |
| Waterfall(κ=1) | - | 0.7432 | 11.8% | - | 0.6519 | 3.1% | - | 0.7283 | 13.2% |
| Ours | 0.8206 | 0.9310 | 67.4% | 0.7137 | 0.8649 | 43.9% | 0.7388 | 0.8616 | 53.7% |
| Ours(advt) | 0.9003 | 0.9709 | 78.1% | 0.8487 | 0.9239 | 36.8% | 0.8648 | 0.9546 | 45.7% |
🔼 This table presents a comparison of the performance of the proposed watermarking method against several baseline methods. The performance is evaluated under sentence paraphrasing attacks, a common robustness test for text watermarking techniques. The table shows the bit accuracy, Area Under the ROC Curve (AUC), and True Positive Rate at a False Positive Rate of 1% (TPR@FPR=1%) for each method, across three different types of sentence paraphrasing: Translation (to Spanish and back to English), Llama2-based paraphrasing, and Pegasus-based paraphrasing. This allows for a comprehensive evaluation of how well each method maintains watermark integrity despite these common text manipulations.
read the caption
Table 3: The performance of our watermark compared with baseline methods under sentence paraphrasing attack.
| Dataset | Bit-wise Accuracy | Text-wise Accuracy | Fidelity | |||||
|---|---|---|---|---|---|---|---|---|
| Bit Acc | Bit Num | AUC | TPR@FPR=1% | TPR@FPR=0.01% | Similarity | |||
| HH | 0.9582 | 5.856 | 0.9991 | 97.9% | 92.1% | 0.8823 | ||
| PKU | 0.9613 | 5.325 | 0.9959 | 96.7% | 1.8% | 0.8923 | ||
| Reward | 0.9572 | 5.684 | 0.9962 | 96.7% | 51.4% | 0.8711 | ||
| UltraF | 0.9519 | 6.234 | 0.9931 | 94.5% | 55.7% | 0.8830 | ||
| FineWeb | 0.9461 | 6.066 | 0.9880 | 93.3% | 19.3% | 0.8463 | ||
| Pile | 0.9140 | 6.026 | 0.9713 | 83.8% | 36.1% | 0.8430 |
🔼 This table presents the performance of the proposed multi-bit text watermarking model when evaluated on out-of-distribution (OOD) datasets. The model, initially trained on the C4 dataset, is tested on several other datasets (HH, PKU, Reward, UltraF, FineWeb, and Pile). For each dataset, the table shows the bit-wise accuracy (Bit Acc), the number of bits injected (Bit Num), the area under the receiver operating characteristic curve (AUC), the true positive rate at 1% and 0.01% false positive rates (TPR@FPR=1%, TPR@FPR=0.01%), and the similarity between the original and watermarked texts. This evaluation demonstrates the model’s generalization ability and robustness across different text domains.
read the caption
Table 4: The performance of our watermark, which is trained on the C4 dataset, evaluated on texts collected in other tasks.
| Original Text | Watermarked Text | Similarity |
|---|---|---|
| “When it comes to fantasy sports and betting on NASCAR races, there’s nothing wrong with it,” Gaughan said. “I wanted to go all in on gambling last year,” NASCAR executive Steve O’Donnell said. “We have so many people that are linked to the cars. I think the integrity is a big piece to it,” O’Donnell said. Nevada’s effective monopoly on sports betting ended last spring, when the Supreme Court ruled the ban should be | “There’s nothing wrong with fantasy sports and betting on NASCAR races,” Gaughan said. Steve said I wanted to go all in on gambling last year. “We have so many people that are linked to the cars,” O’Donnell said. The integrity of the car is a big piece to it because they are linked to it. Nevada’s effective monopoly on sports betting ended last spring, as the Supreme Court ruled that the ban should be | 0.9177 |
| President Trump’s decision Monday to revive plans to freeze federal employee pay in 2020 and to institute a series of cuts to federal employee retirement programs was met with great consternation from stakeholder groups, although the ideas stand little chance of becoming law. Increasing employee contributions toward federal defined benefit annuity programs by 1 percent per year until those payments reach 50 percent of the total cost. Eliminating cost of living adjustments for FERS retirees, and reducing CSRS cost of living adjustments by 0.5 percent. | President Trump’s decision Monday to resume plans to freeze federal employee pay and to cut retirement benefits for federal employees generated consternation from stakeholder groups, despite having little hope of becoming law. The employee contributions to the annuity programs are up by 1 percent a year until they reach five percent of the total cost. There are cost of living adjustments for FERS retirees and cost adjustments for COLA, which are reduced by 0.5 percent. | 0.8947 |
| Bob ”Bus Bob” Krause, 59, of Waikiki, an Oahu Transit System bus driver, died at home. He was born in Bremen, Germany. He is survived by parents Hans Krause and Sonja Aiwohi, brother Ralph and sisters Lorraine Kinnamon and Charmaine Moniz. Celebration of life: 2 p.m. Friday at Outrigger Canoe Club Waikiki. Additional celebration of life: 4:30 p.m. on weekend of May 4 and 5 at K | Bob ”Bus Bob” Krause, the head driver of the Oahu Transit System, died at home. His parents lived in Germany when he was born. He has surviving relatives, including his mother, sister, and brother. The celebration of life is on Friday at the outrigger canoe club. There is a celebration of life on Friday, May 4 and 5 at K | 0.8743 |
| Occasional diarrhea is a common occurrence. Most people will experience an episode of diarrhea at least once or twice a year that will disappear in a couple of days. Luckily, there are many foods to eat that may help a person reduce the symptoms of diarrhea. There are also some foods to avoid when dealing with a bout of diarrhea, and some additional home care tips to consider. Anyone who is experiencing persistent diarrhea should see a doctor, as a person may become dehydrated over time. | Occasional diarrhea is a common occurrence. People will get sick more often than they used to do. There are many foods to eat that may help a person reduce the symptoms of diarrhea. A lot of people avoid foods when they are dealing with a bout of diarrhea and a few home care ideas to consider are worth checking out. Anyone who is suffering from persistent diarrhea should see a doctor, as a person may become dehydrated over time. | 0.8392 |
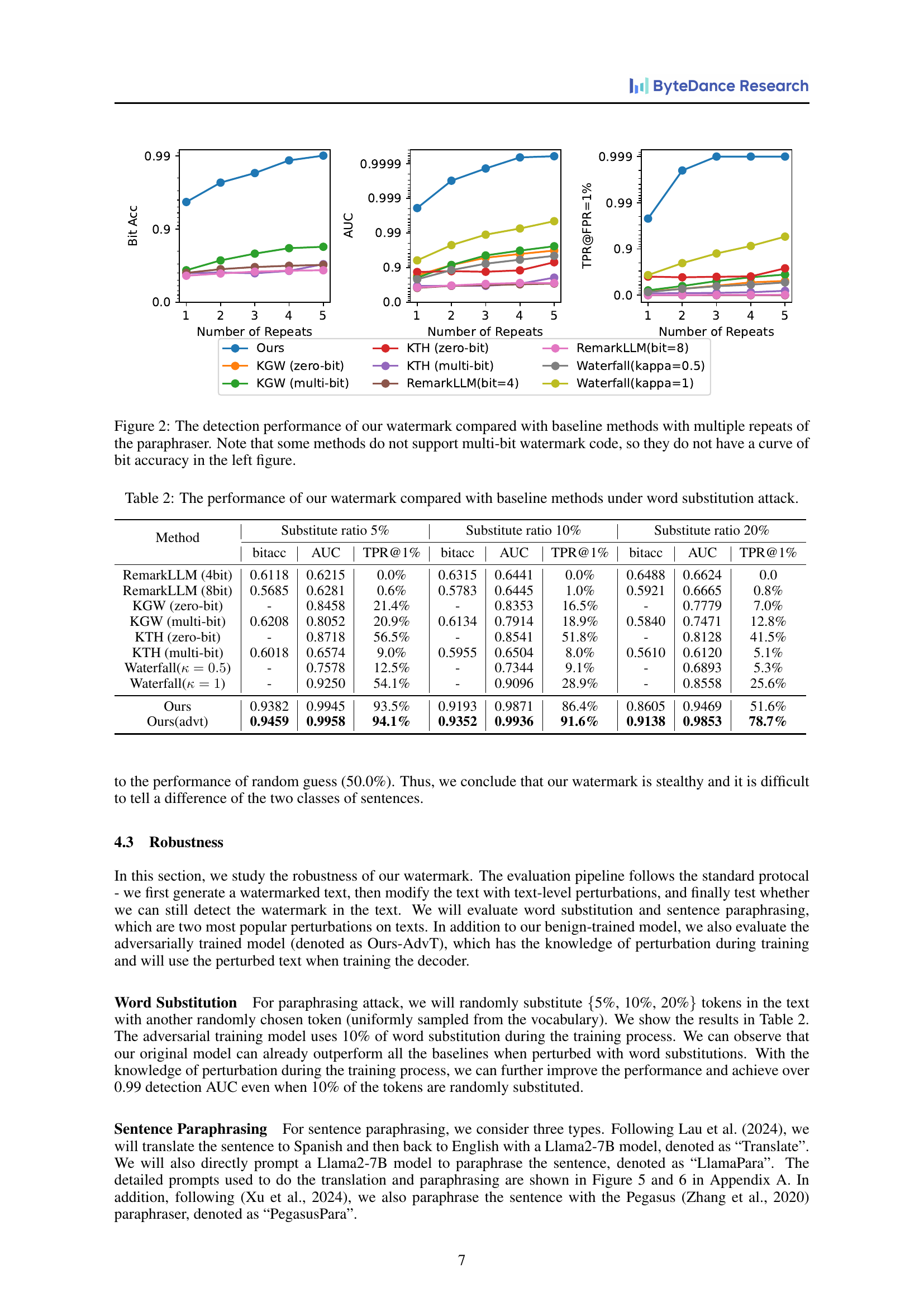
🔼 Table 5 presents examples of watermarked text generated using the proposed method. The table showcases both the original text and its watermarked counterpart, categorized as either class-0 or class-1 based on the embedded watermark bit. The color-coding (blue for class-0 and green for class-1) helps visually distinguish between the two categories. This is crucial for understanding the method’s ability to subtly embed watermarks without significantly altering the original text’s meaning or readability.
read the caption
Table 5: Examples of watermarked texts. Blue and green texts correspond to class-0 and class-1 texts respectively.
| Method | Bit-wise Accuracy | Text-wise Accuracy | Fidelity | |||||
|---|---|---|---|---|---|---|---|---|
| Bit Acc | Bit Num | AUC | TPR@FPR=1% | TPR@FPR=0.01% | Similarity | |||
| — | — | — | — | — | — | — | — | — |
| KGW (zero-bit) | - | - | 0.8625 | 24.4% | 13.7% | 0.8842 | ||
| KGW (multi-bit) | 0.6302 | 5.17 | 0.8498 | 15.2% | 8.3% | 0.8986 | ||
| KTH (zero-bit) | - | - | 0.8735 | 26.5% | 12.5% | 0.9075 | ||
| KTH (multi-bit) | 0.5756 | 5.075 | 0.7296 | 13.3% | 2.0% | 0.9073 | ||
| Waterfall(κ=1) | - | - | 0.7568 | 13.3% | 3.7% | 0.8809 | ||
| Waterfall(κ=2) | - | - | 0.9213 | 49.3% | 26.9% | 0.8743 | ||
| Waterfall(κ=4) | - | - | 0.9951 | 96.3% | 89.8% | 0.8350 | ||
| Ours | 0.9605 | 5.874 | 0.9973 | 97.6% | 77.6% | 0.8631 |
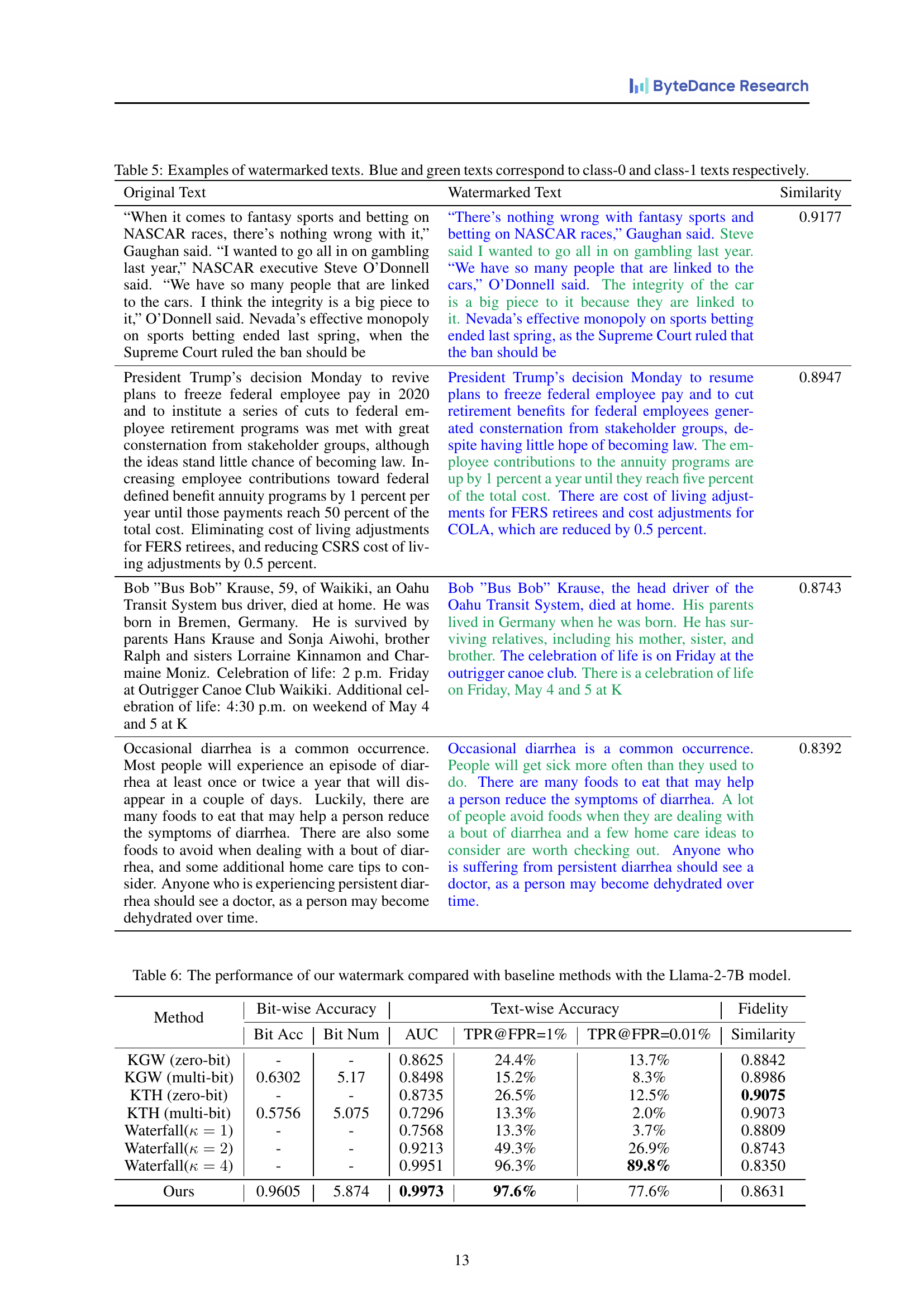
🔼 This table presents a comparison of the performance of the proposed multi-bit text watermarking method against several baseline methods. The key difference is that this evaluation uses the larger Llama-2-7B language model instead of the smaller TinyLlama-1.1B model used in the primary experiments. The performance metrics include bit-wise accuracy (Bit Acc, Bit Num), text-wise accuracy (AUC, TPR@FPR=1%, TPR@FPR=0.01%), and text fidelity (Similarity). This allows for a direct comparison of how model size affects watermarking performance and robustness.
read the caption
Table 6: The performance of our watermark compared with baseline methods with the Llama-2-7B model.
Full paper#