↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for extracting features from large pre-trained diffusion models require adding noise to images, which reduces information and necessitates tuning the model’s timestep for each downstream task. This is inefficient and can harm the features’ quality. This paper addresses these issues.
The researchers propose CleanDIFT, a novel feature extraction method that uses clean images and a 30-minute fine-tuning process to create timestep-independent features. These features outperform standard diffusion features across diverse tasks, notably in semantic correspondence, demonstrating substantial gains in efficiency and accuracy. The method is generally applicable to various downstream tasks without the need for adjustments.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with diffusion models and their applications. It significantly improves feature extraction by eliminating noise dependence, enhancing downstream task performance, and offering substantial efficiency gains. This opens exciting avenues for applying diffusion models to various computer vision tasks and developing more efficient models.
Visual Insights#

🔼 This figure illustrates the core concept of CleanDIFT, a novel feature extraction method for diffusion models. CleanDIFT’s key innovation is extracting features directly from clean images, unlike existing methods which require adding noise to the image as a preprocessing step. The figure visually compares the standard diffusion feature extraction process (left side) with CleanDIFT (right side). The standard approach involves adding noise to an image, resulting in noisy features whose quality depends heavily on the chosen noise level (’timestep’). This requires tuning the timestep parameter for optimal performance on each downstream task. CleanDIFT, in contrast, operates on clean images, producing noise-free, timestep-independent features that consistently outperform standard diffusion features across various tasks. The improvement is attributed to avoiding the information loss caused by the addition of noise in conventional methods. The illustration shows the impact of noise on the image, the feature extraction process, and the need for timestep tuning in traditional methods.
read the caption
Figure 1: Our proposed CleanDIFT feature extraction method yields noise-free, timestep-independent, general-purpose features that significantly outperform standard diffusion features. CleanDIFT operates on clean images, while extracting diffusion features with existing approaches requires adding noise to an image before passing it through the model. Adding noise reduces the information present in the image and requires tuning a timestep per downstream task.
| Input | Ours | SD 2.1t=299 | Ground Truth |
|---|---|---|---|
 |  |  |  |
 |  | |  |
 |  |  |  |
🔼 This table presents a comparison of zero-shot unsupervised semantic correspondence matching performance using different feature extraction methods on the SPair-71k dataset. The key metric is Percentage of Correct Keypoints (PCK), averaged across all keypoints in the test set. The table shows that the proposed CleanDIFT features significantly outperform existing methods, demonstrating substantial improvements in matching accuracy. For a detailed discussion on the reproduction of numbers and a comparison with those reported in the original papers, refer to Table 5.
read the caption
Table 1: Zero-shot unsupervised semantic correspondence matching performance comparison on SPair71k [31]. Our improved features consistently lead to substantial improvements in matching performance. We report PCK on the test split of SPair71k, aggregated per point. Numbers are reproduced, for a discussion and comparison to reported numbers view Tab. 5.
In-depth insights#
Noise-Free Features#
The concept of “Noise-Free Features” in the context of diffusion models is a significant advancement. Traditional methods add noise to images before feature extraction, reducing information and requiring per-task timestep tuning. CleanDIFT directly addresses this by extracting features from clean images, eliminating the noise bottleneck and enabling the model to leverage the full image information. This leads to timestep-independent, general-purpose features that are readily applicable across diverse downstream tasks without the need for extensive task-specific adjustments. The method’s efficiency is remarkable as it only requires minimal fine-tuning (around 30 minutes) of a pre-trained diffusion model. Superior performance in multiple applications, including semantic correspondence and depth estimation, demonstrates the effectiveness of extracting noise-free features. This approach simplifies the workflow, enhancing both efficiency and accuracy compared to prior techniques. CleanDIFT thus presents a more robust and versatile method for harnessing the power of diffusion models in various vision tasks.
CleanDIFT Method#
The CleanDIFT method proposes a novel approach to extract features from diffusion models, eliminating the need for noisy input images and timestep tuning. It achieves this by fine-tuning a diffusion backbone to directly process clean images, consolidating information across various diffusion timesteps into a single, consistent feature representation. This is done by aligning the model’s internal features with those of a standard diffusion model, creating timestep-independent features. The method’s efficiency is highlighted, requiring minimal finetuning, and its generality is demonstrated through superior performance across diverse downstream tasks compared to methods using noisy inputs. This results in improved accuracy and speed for tasks such as semantic correspondence and semantic segmentation. The key innovation lies in bypassing the noisy image preprocessing, thus directly harnessing the full information from clean images to produce high-quality, noise-free semantic features.
Downstream Tasks#
The effectiveness of diffusion models hinges on their ability to produce robust, general-purpose features applicable to a wide range of downstream tasks. The paper likely investigates several such tasks, assessing how well the novel CleanDIFT features perform compared to traditional diffusion feature extraction methods. Key downstream tasks are likely semantic correspondence, depth estimation, semantic segmentation, and image classification. Analyzing the performance across these diverse tasks reveals the true potential and limitations of CleanDIFT. Strong performance across varied tasks would indicate CleanDIFT’s superiority as a general-purpose feature extractor. The evaluation likely includes comparisons against existing state-of-the-art methods for each task, demonstrating improvements in metrics such as accuracy, IoU, or PCK. Furthermore, efficiency gains achieved through CleanDIFT, such as reduced computational cost, are crucial aspects in the downstream task analysis.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of this research, ablation studies would likely investigate the impact of various design choices on the performance of the proposed CleanDIFT method. This might include removing the projection heads, altering the similarity metric used for feature alignment, varying the training objective, or changing the architecture of the feature extractor. By observing the effects of these removals, the researchers can quantify the impact of each component and demonstrate the importance of their specific design choices. For instance, removing projection heads might lead to a significant drop in performance, showcasing their critical role in consolidating the information from multiple diffusion timesteps. Similarly, testing different similarity metrics could highlight the effectiveness of the chosen cosine similarity over alternatives. The results of these ablation experiments would provide crucial validation of the method’s design, strengthening the paper’s conclusions and improving the overall understanding of CleanDIFT’s strengths and limitations.
Future Work#
Future work in this area could explore several promising directions. Expanding CleanDIFT’s applicability to a wider array of diffusion models beyond Stable Diffusion is crucial to establish its generalizability and robustness. Investigating how CleanDIFT interacts with other feature extraction methods (e.g., fusing with DINOv2 features) warrants further research. The current work focuses on image data; extending it to video and other modalities is a natural extension. Theoretical analysis is needed to better understand why CleanDIFT works so effectively, and to provide formal guarantees for its performance. Furthermore, exploring the impact of different network architectures and training procedures on CleanDIFT’s efficacy would further enhance the methodology. Finally, assessing CleanDIFT’s sensitivity to various types of image noise and developing techniques to mitigate its impact on feature quality would improve its real-world applicability.
More visual insights#
More on figures

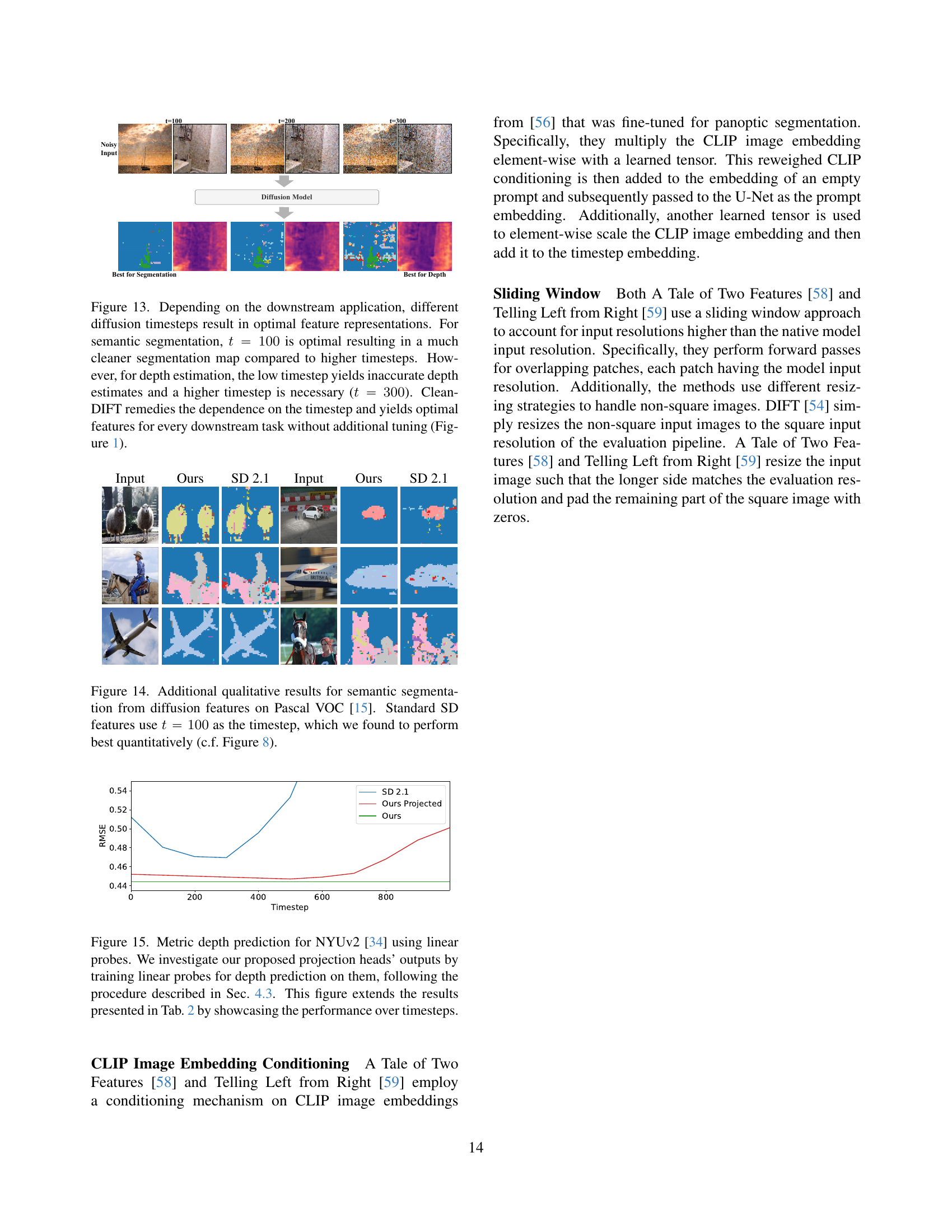
🔼 This figure compares the reconstruction of an image using a diffusion model with and without added noise. Panel (a) shows a reconstruction without noise, where the model is directly given a clean image. Panel (b) shows reconstruction with added noise (t=261), a typical approach for existing diffusion feature extraction methods, where the model attempts to recover the clean image from a noisy input. By comparing the two panels, it highlights that adding noise greatly reduces the information available for feature extraction, leading to lower quality features. This is because the model is trained to remove noise, making its internal representation primarily centered on noise patterns rather than semantic content. The proposed method avoids this issue by extracting features directly from clean images.
read the caption
Figure 2: Deterioration of Diffusion Features. As current methods need to pass noisy images to the model to obtain useful features, they significantly reduce the information available. We alleviate this problem by obtaining useful features without noise, improving the performance of downstream tasks.

🔼 This figure shows the fraction of variance in diffusion features explained by the clean image and the added noise at different timesteps. The x-axis represents the timestep (t), ranging from 0 (clean image) to 999 (pure noise). The y-axis represents the fraction of variance explained. Two lines are plotted: one shows the variance explained by the clean image at t=0, and the other shows the variance explained by the added noise at t=999. The figure demonstrates that even at relatively low timesteps (like t=261, used by the DIFT method), a significant portion of the features’ variance is directly attributable to the added noise, highlighting a limitation of using noisy images for feature extraction.
read the caption
Figure 3: Fraction of variance of diffusion features explained by 1) encoding the clean image at t=0𝑡0t=0italic_t = 0 (no additive noise), and 2) encoding just the added noise ϵbold-italic-ϵ\boldsymbol{\epsilon}bold_italic_ϵ at t=999𝑡999t=999italic_t = 999. Even at relatively low timesteps such as t=261𝑡261t=261italic_t = 261 as used by DIFT [54], a substantial part of the features directly depends only on the added noise.

🔼 The figure illustrates the training process of CleanDIFT. A clean image is input to a trainable feature extraction model (CleanDIFT), while a noisy version of the same image (with noise level determined by timestep ’t’) is fed into a frozen diffusion model. Projection heads are used during training to align the features extracted by CleanDIFT with the features from the noisy diffusion model at each timestep. Crucially, for downstream applications, these projection heads are discarded, and only the noise-free features directly from the CleanDIFT model are utilized.
read the caption
Figure 4: Our training setup. We train our model to predict features from a clean input image, while the frozen diffusion model is fed the noisy image. The projection heads project our model’s features onto the noisy diffusion model features, given the noising timestep t𝑡titalic_t. For downstream tasks, we discard the projection heads and directly use our model’s internal representations as features.

🔼 This figure compares the performance of semantic correspondence matching using standard noisy diffusion features and CleanDIFT features at various noise levels. The x-axis represents the timestep (t), while the y-axis represents the percentage of correctly matched keypoints (PCK). The results show that CleanDIFT features consistently outperform standard noisy diffusion features across all timesteps. Furthermore, it demonstrates that merely providing a clean image to a diffusion model without the addition of noise (i.e., a non-zero timestep) does not improve performance, highlighting the importance of CleanDIFT’s noise-free approach.
read the caption
Figure 5: Following [54], we evaluate semantic correspondence matching accuracy for different noise levels. Our feature extractor outperforms the standard noisy diffusion features across all timesteps t𝑡titalic_t. We additionally demonstrate that simply providing the diffusion model with a clean image and a non-zero timestep does not result in improved performance.

🔼 This figure compares semantic correspondence results obtained using standard diffusion features (DIFT [54] with SD 2.1 at timestep t=261) against results from CleanDIFT features. The images visually demonstrate that CleanDIFT features produce significantly fewer incorrect matches in semantic correspondence tasks compared to the standard approach. This showcases the improved accuracy and reliability of the proposed CleanDIFT feature extraction method.
read the caption
Figure 6: Semantic correspondence results using DIFT [54] features with the standard SD 2.1 (t=261𝑡261t=261italic_t = 261) and our CleanDIFT features. Our clean features show significantly less incorrect matches than the base diffusion model.

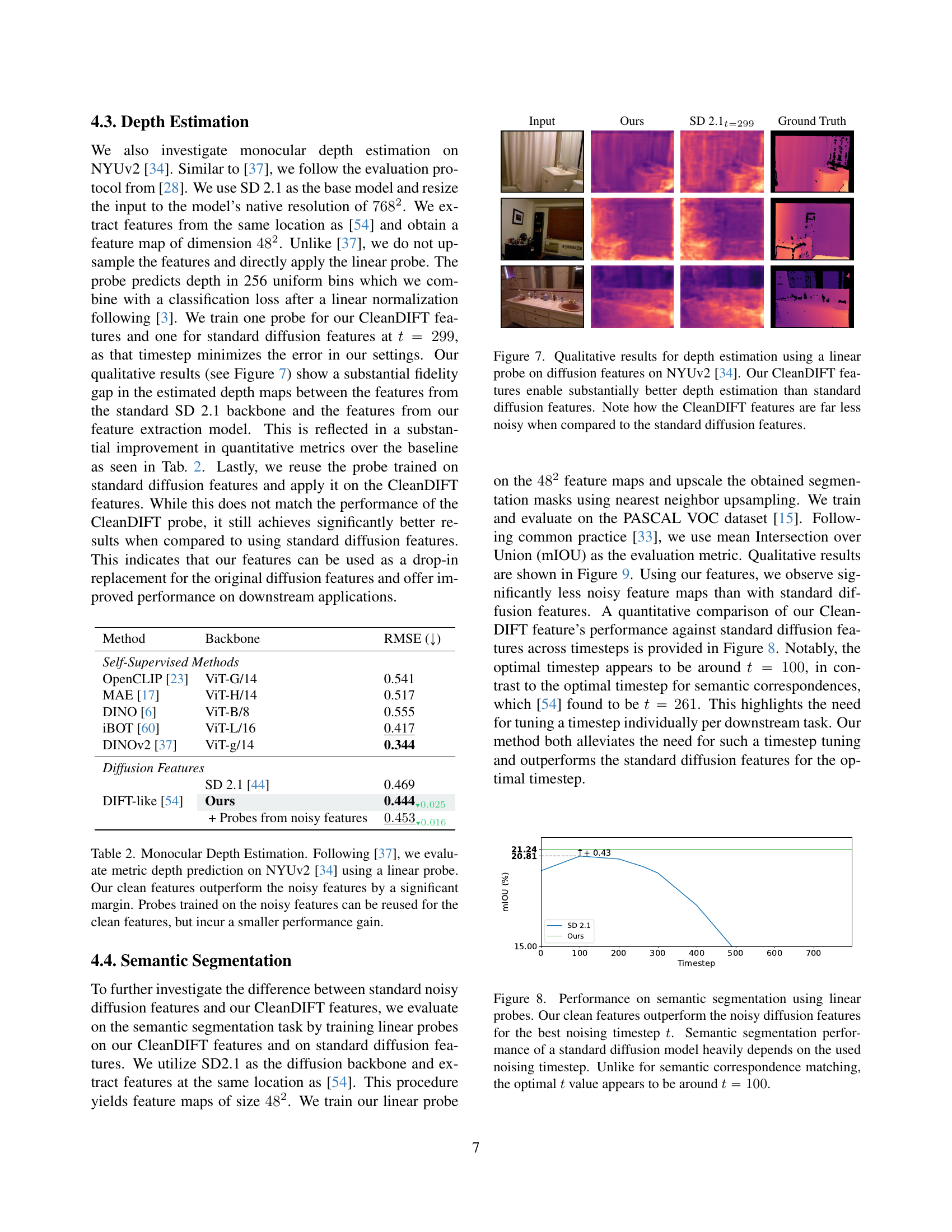
🔼 This figure presents a qualitative comparison of depth estimation results obtained using standard diffusion features and CleanDIFT features on the NYUv2 dataset. The images show that CleanDIFT features produce depth maps with significantly less noise and finer details compared to those generated using standard diffusion features, leading to a substantial improvement in the accuracy and quality of depth estimation. The visual difference highlights the effectiveness of CleanDIFT in extracting cleaner and more informative features from the input images.
read the caption
Figure 7: Qualitative results for depth estimation using a linear probe on diffusion features on NYUv2 [34]. Our CleanDIFT features enable substantially better depth estimation than standard diffusion features. Note how the CleanDIFT features are far less noisy when compared to the standard diffusion features.

🔼 Figure 8 shows the performance comparison of semantic segmentation using linear probes trained on CleanDIFT features and standard noisy diffusion features. The x-axis represents the noise timestep (t), and the y-axis represents the mean Intersection over Union (mIOU) score, a common metric for evaluating semantic segmentation accuracy. The graph reveals that CleanDIFT features consistently achieve higher mIOU scores across various timesteps. Notably, while noisy diffusion features exhibit a strong dependence on the choice of timestep (with the optimal performance around t=100), CleanDIFT features demonstrate more consistent performance, suggesting their robustness and reduced sensitivity to the noise level. This highlights the benefit of using noise-free features for semantic segmentation.
read the caption
Figure 8: Performance on semantic segmentation using linear probes. Our clean features outperform the noisy diffusion features for the best noising timestep t𝑡titalic_t. Semantic segmentation performance of a standard diffusion model heavily depends on the used noising timestep. Unlike for semantic correspondence matching, the optimal t𝑡titalic_t value appears to be around t=100𝑡100t=100italic_t = 100.

🔼 Figure 9 presents a qualitative comparison of semantic segmentation results obtained using standard Stable Diffusion (SD) features and CleanDIFT features on the Pascal VOC dataset. The standard SD features utilize a timestep (t) of 100, determined in Figure 8 to yield the best quantitative performance. The comparison highlights the significant reduction in noise present in the segmentation maps generated by CleanDIFT features compared to those produced by standard SD features. This visual demonstration underscores CleanDIFT’s effectiveness in generating cleaner and less noisy feature representations.
read the caption
Figure 9: Qualitative results for semantic segmentation from diffusion features on Pascal VOC [15]. Standard SD features use t=100𝑡100t=100italic_t = 100 as the timestep, which we found to perform best quantitatively (c.f. Figure 8). Note how the CleanDIFT segmentation maps are far less noisy compared to those of the standard diffusion features.

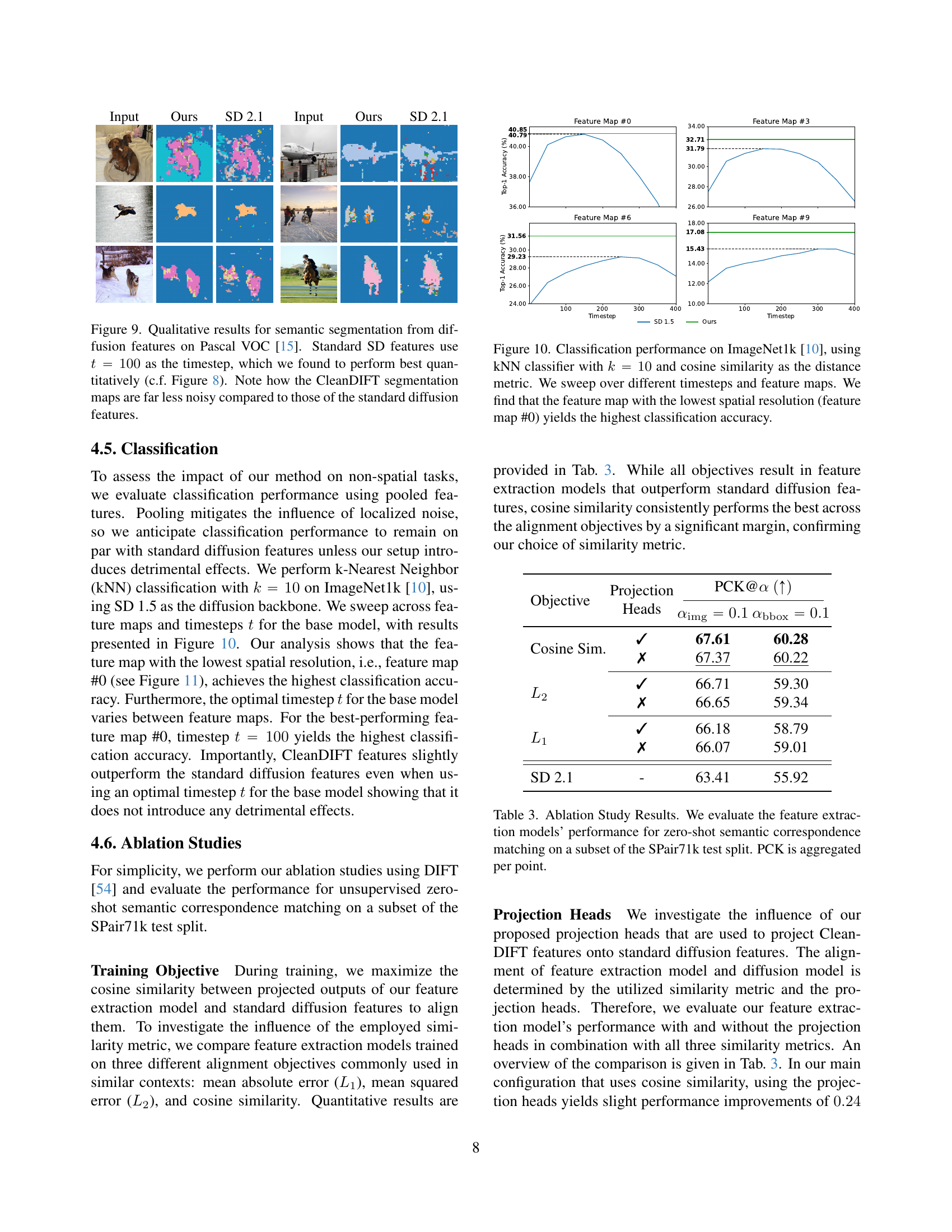
🔼 This figure displays the classification accuracy achieved using a k-Nearest Neighbors (kNN) classifier with k=10 on the ImageNet1k dataset. The results show the impact of different diffusion timesteps and feature maps from the diffusion model on the classification performance. Notably, using feature map #0 (the feature map with the lowest spatial resolution) consistently yields the highest classification accuracy across various timesteps.
read the caption
Figure 10: Classification performance on ImageNet1k [10], using kNN classifier with k=10𝑘10k=10italic_k = 10 and cosine similarity as the distance metric. We sweep over different timesteps and feature maps. We find that the feature map with the lowest spatial resolution (feature map #0) yields the highest classification accuracy.
More on tables
| Input | Ours | SD 2.1 |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
🔼 This table presents a comparison of monocular depth estimation results on the NYUv2 dataset. It compares the performance of a linear probe trained on standard noisy diffusion features against a linear probe trained on the proposed CleanDIFT noise-free features. The results show that CleanDIFT features significantly improve depth estimation accuracy. Furthermore, it demonstrates that while a probe trained on noisy features can be applied to CleanDIFT features, the performance gain is smaller than when using a probe specifically trained on CleanDIFT features.
read the caption
Table 2: Monocular Depth Estimation. Following [37], we evaluate metric depth prediction on NYUv2 [34] using a linear probe. Our clean features outperform the noisy features by a significant margin. Probes trained on the noisy features can be reused for the clean features, but incur a smaller performance gain.
| Input | Ours | SD 2.1 |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
🔼 This table presents the ablation study results for evaluating the impact of different training objectives and the use of projection heads on the performance of the feature extraction model. The model’s performance is measured using the Percentage of Correct Keypoints (PCK) metric, which is averaged across all keypoints in a subset of the SPair71k test set for zero-shot semantic correspondence matching.
read the caption
Table 3: Ablation Study Results. We evaluate the feature extraction models’ performance for zero-shot semantic correspondence matching on a subset of the SPair71k test split. PCK is aggregated per point.
| Objective | Projection Heads | PCK@α (↑) αimg=0.1 | PCK@α (↑) αbbox=0.1 |
|---|---|---|---|
| Cosine Sim. | ✓ | 67.61 | 60.28 |
| ✗ | 67.37 | 60.22 | |
| L2 | ✓ | 66.71 | 59.30 |
| ✗ | 66.65 | 59.34 | |
| L1 | ✓ | 66.18 | 58.79 |
| ✗ | 66.07 | 59.01 | |
| SD 2.1 | - | 63.41 | 55.92 |
🔼 This table presents a detailed breakdown of the performance of three different methods (DIFT, A Tale of Two Features, and Telling Left from Right) for zero-shot unsupervised semantic correspondence matching on the SPair71k dataset. The performance is measured using the Percentage of Correct Keypoints (PCK) metric at α=0.1, considering both the image size and bounding box size as error margins. Results are shown for each category within the dataset, with the three categories exhibiting the largest performance improvements highlighted. The table also includes comparisons with the original results reported in the referenced papers.
read the caption
Table 4: Reproduced results for zero-shot unsupervised semantic correspondence matching, evaluated on SPair71k [31]. The three categories for which we observe the largest overall gains are marked in blue. We report PCK@α=0.1𝛼0.1\alpha=0.1italic_α = 0.1 with an error margin relative to bounding box sizes on the test split of SPair71k, aggregated per point and per category. We compare our reproductions against the papers’ reported numbers in Tab. 5
| Method | Our Features | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Dog | Horse | Motor | Person | Plant | Sheep | Train | TV | All |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DIFT [54] | ✗ | 63.41 | 55.10 | 80.40 | 34.55 | 46.15 | 52.26 | 48.02 | 75.86 | 39.46 | 75.57 | 55.00 | 61.71 | 53.32 | 46.53 | 56.36 | 57.68 | 71.30 | 63.63 | 59.57 |
| ✓ | 63.72 | 55.90 | 80.50 | 35.40 | 49.36 | 53.46 | 48.08 | 75.78 | 43.10 | 76.20 | 55.69 | 61.01 | 54.17 | 49.14 | 62.56 | 58.37 | 74.63 | 71.54 | 61.43¹⁸ | |
| A Tale of Two Features [58] | ✗ | 71.26 | 62.23 | 87.01 | 37.24 | 53.78 | 54.32 | 51.20 | 78.61 | 46.50 | 78.93 | 64.43 | 69.47 | 62.23 | 69.27 | 59.28 | 68.03 | 65.40 | 53.81 | 63.73 |
| ✓ | 71.12 | 62.70 | 87.42 | 38.33 | 54.78 | 54.67 | 51.20 | 78.52 | 47.86 | 79.38 | 64.88 | 69.18 | 62.61 | 69.72 | 62.82 | 68.87 | 67.51 | 59.04 | 64.81¹⁸ | |
| Telling Left from Right [59] | ✗ | 78.14 | 66.37 | 89.60 | 43.74 | 53.29 | 66.61 | 59.94 | 82.66 | 51.75 | 82.79 | 68.95 | 74.91 | 65.84 | 71.67 | 57.71 | 72.24 | 83.46 | 49.66 | 68.64 |
| ✓ | 77.17 | 65.65 | 89.58 | 44.24 | 54.27 | 67.24 | 60.63 | 82.33 | 56.57 | 82.53 | 68.37 | 75.91 | 65.99 | 71.37 | 62.29 | 70.42 | 84.58 | 59.84 | 69.99¹⁸ |
🔼 This table compares the reproduced results of zero-shot semantic correspondence matching performance on the SPair71k dataset [31] against the values reported in three different papers ([54], [58], [59]). The discrepancies in performance are attributed to the fact that the papers [58] and [59] utilize a CLIP image embedding conditioning mechanism [56] which was fine-tuned for the related task of panoptic segmentation. Since this additional conditioning mechanism is not a zero-shot approach, the authors of the current paper excluded it from their reproduction for a fair comparison.
read the caption
Table 5: Reproduced vs reported numbers for zero-shot semantic correspondences, evaluated on SPair71k [31]. A Tale of Two Features [58] and Telling Left from Right [59] report higher PCK values than our reproduction because they utilize a conditioning mechanism on CLIP image embeddings from [56] that was fine-tuned for panoptic segmentation. As this task is related to semantic correspondence matching, we do not consider using this conditioning mechanism fair in comparison to other zero-shot approaches for semantic correspondences. Therefore, we exclude it from our reproductions.
Full paper#