↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current generative novel view synthesis (NVS) methods heavily rely on external multi-view alignment processes, such as pose estimation or pre-reconstruction. These methods suffer from instability, particularly when dealing with sparse views with insufficient overlap. This limits their flexibility and accessibility.
The proposed NVComposer tackles this by eliminating the need for explicit external alignment. It uses a novel dual-stream diffusion model to implicitly infer spatial relationships between views. Additionally, it incorporates a geometry-aware feature alignment module that enhances performance. The results show significant improvements in synthesis quality, especially with more unposed input views, demonstrating the feasibility and effectiveness of this approach.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly advances generative novel view synthesis (NVS). By eliminating the need for external alignment, it improves accessibility and enables NVS from sparse, unposed images. This opens new avenues for various applications and inspires further research into implicit geometric reasoning within generative models. The improved model accessibility lowers the barrier to entry for researchers without extensive resources.
Visual Insights#

🔼 This figure compares the performance of NVComposer and ViewCrafter for novel view synthesis (NVS) as the number of input views increases. NVComposer shows improved NVS quality with more views, demonstrating its ability to effectively utilize additional information. In contrast, ViewCrafter, which depends on external multi-view alignment and pre-reconstruction, experiences degraded performance with more views due to the instability of the external alignment process. This finding contradicts the common assumption that more views always lead to better NVS results.
read the caption
Figure 1: As the number of unposed input views increases, NVComposer (blue circle) effectively uses the extra information to improve NVS quality. In contrast, ViewCrafter [43] (green triangle), which relies on external multi-view alignment (via pre-reconstruction from DUSt3R [34]), suffers performance degradation as the number of views grows due to instability of the external alignment. This result contradicts the common expectation that “more views lead to better performance.” Please refer to Sec. 4.2 for full results.
| Model | Views | Easy PSNR↑ | Easy SSIM↑ | Easy LPIPS↓ | Easy DISTS↓ | Medium PSNR↑ | Medium SSIM↑ | Medium LPIPS↓ | Medium DISTS↓ | Hard PSNR↑ | Hard SSIM↑ | Hard LPIPS↓ | Hard DISTS↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MotionCtrl [36] | 1 | 15.0741 | 0.6071 | 0.3616 | 0.0999 | 12.0674 | 0.5667 | 0.5439 | 0.1584 | 11.6381 | 0.5276 | 0.5762 | 0.1633 |
| CameraCtrl [9] | 1 | 13.6082 | 0.5050 | 0.4234 | 0.1458 | 11.9639 | 0.4934 | 0.5217 | 0.1957 | 11.7599 | 0.4716 | 0.5478 | 0.2021 |
| DUSt3R [34] | 1 | 13.9443 | 0.5582 | 0.3914 | 0.1565 | 11.4854 | 0.4520 | 0.5570 | 0.2294 | 10.9003 | 0.4029 | 0.6089 | 0.2495 |
| 2 | 17.4837 | 0.6148 | 0.3582 | 0.1503 | 13.3077 | 0.4886 | 0.5434 | 0.2126 | 11.5381 | 0.4003 | 0.6407 | 0.2551 | |
| 3 | 17.2341 | 0.6097 | 0.3585 | 0.1504 | 13.2212 | 0.4978 | 0.5287 | 0.2056 | 11.9211 | 0.4387 | 0.5942 | 0.2313 | |
| 4 | 17.3545 | 0.6193 | 0.3541 | 0.1481 | 14.6845 | 0.5534 | 0.4892 | 0.1870 | 14.2381 | 0.5280 | 0.5295 | 0.1917 | |
| ViewCrafter [43] | 1 | 17.3750 | 0.6670 | 0.2849 | 0.1221 | 13.6015 | 0.6016 | 0.4315 | 0.1762 | 14.0781 | 0.5894 | 0.4293 | 0.1676 |
| 2 | 18.8906 | 0.6685 | 0.3079 | 0.1334 | 14.2891 | 0.5947 | 0.4478 | 0.1761 | 13.5859 | 0.5537 | 0.5100 | 0.1925 | |
| 3 | 18.4531 | 0.6548 | 0.3024 | 0.1294 | 14.1172 | 0.5913 | 0.4401 | 0.1717 | 13.7031 | 0.5620 | 0.4867 | 0.1784 | |
| 4 | 18.4844 | 0.6553 | 0.3068 | 0.1346 | 14.7421 | 0.6011 | 0.4230 | 0.1672 | 15.1875 | 0.5874 | 0.4327 | 0.1638 | |
| NVComposer (Ours) | 1 | 18.7227 | 0.7215 | 0.2354 | 0.0996 | 15.3101 | 0.6056 | 0.3445 | 0.1516 | 15.2115 | 0.6408 | 0.4048 | 0.1462 |
| 2 | 20.7395 | 0.7681 | 0.1781 | 0.0793 | 16.9100 | 0.6445 | 0.2742 | 0.1198 | 15.3461 | 0.6638 | 0.3789 | 0.1384 | |
| 3 | 21.5278 | 0.7981 | 0.1522 | 0.0716 | 17.7071 | 0.7418 | 0.2759 | 0.1097 | 15.3825 | 0.6822 | 0.3699 | 0.1324 | |
| 4 | 22.5519 | 0.8226 | 0.1188 | 0.0537 | 19.5346 | 0.7847 | 0.2030 | 0.0851 | 17.8181 | 0.7359 | 0.2644 | 0.0988 |
🔼 This table presents a quantitative comparison of different novel view synthesis (NVS) methods on the RealEstate10K dataset. It evaluates the performance of several models, including controllable video generation models (MotionCtrl and CameraCtrl), a reconstructive model (DUSt3R), and generative models (ViewCrafter and NVComposer). The evaluation considers varying numbers of input views, categorizing scene difficulty based on the angular distance between views. Metrics include PSNR, SSIM, LPIPS, and DISTS, providing a comprehensive assessment of the generated novel views’ quality across different difficulty levels and varying numbers of input views. The table highlights the impact of the number of input views on the performance of each method and helps understand the strengths and weaknesses of each approach in generating realistic novel views.
read the caption
Table 1: NVS evaluation with varying numbers of input views on RealEstate10K [47] for controllable video models MotionCtrl [36] and CameraCtrl [9], reconstructive model DUSt3R [34], and generative models ViewCrafter [43] and NVComposer. θtargetsubscript𝜃target\theta_{\text{target}}italic_θ start_POSTSUBSCRIPT target end_POSTSUBSCRIPT denotes the rotation angle between the anchor view and the furthest target view, while θcondsubscript𝜃cond\theta_{\text{cond}}italic_θ start_POSTSUBSCRIPT cond end_POSTSUBSCRIPT indicates the angle between the anchor view and the furthest conditional view (when multiple conditions are used).
In-depth insights#
Pose-Free Multi-view NVS#
Pose-free multi-view novel view synthesis (NVS) presents a significant advancement in computer vision by eliminating the need for explicit camera pose estimation, a common bottleneck in traditional multi-view NVS methods. This approach enhances the flexibility and accessibility of NVS systems, especially in scenarios with sparse or challenging view overlaps, where accurate pose estimation is difficult to achieve. The core idea involves enabling the generative model to implicitly learn spatial and geometric relationships between multiple input views, directly inferring the relative camera poses. This removes the dependency on external alignment processes, allowing for a more robust and efficient NVS pipeline. While traditional methods rely on pre-reconstruction or explicit pose estimation steps, pose-free NVS methods offer a more end-to-end solution by integrating pose estimation within the generative framework. This leads to improved robustness and better handling of occlusion and sparse data. The challenge lies in designing sophisticated model architectures that can effectively capture complex scene geometry and camera relationships without relying on explicit pose information. The potential benefits of this approach are considerable, paving the way for more versatile and accessible generative NVS systems applicable to a broader range of scenarios and datasets.
Dual-Stream Diffusion#
The proposed “Dual-Stream Diffusion” model is a novel architecture designed to address the limitations of existing generative novel view synthesis (NVS) methods. Unlike traditional approaches that rely on external multi-view alignment, this model implicitly infers spatial and geometric relationships between multiple views. This is achieved through a dual-stream architecture that simultaneously generates target views and estimates camera poses, eliminating the need for explicit pose estimation or pre-reconstruction. The model’s effectiveness is further enhanced by a geometry-aware feature alignment module, which leverages geometric priors from dense stereo models to improve view consistency and generation quality. This dual-stream approach shows the potential to improve the flexibility and accessibility of generative NVS, particularly in scenarios with sparse and unposed input images, while also enhancing the overall quality of synthesized views.
Geometry-Aware Feature#
The concept of “Geometry-Aware Features” in novel view synthesis (NVS) aims to integrate geometric information into the feature representations used by generative models. This is crucial because traditional methods often struggle with complex scenes, especially when dealing with sparse or unposed images. By incorporating geometry, the model can better understand spatial relationships between different viewpoints, leading to more accurate and consistent novel view generation. Methods might involve incorporating depth maps, point clouds, or other geometric representations either explicitly as additional inputs or implicitly by training the model on data with strong geometric priors. The key benefit is improved robustness to challenges like occlusion and limited overlap between input views, resulting in higher-quality, more realistic novel views. A successful geometry-aware approach should seamlessly fuse geometric information with the image features, avoiding interference or hindering the generative process. The core challenge lies in finding effective ways to represent and integrate this geometric information without overwhelming or confusing the model’s learning process, making it a significant area of ongoing research and development within NVS.
Ablation Studies & Analysis#
The ablation studies section of a research paper is critical for evaluating the contributions of individual components to the overall system performance. In this case, it would likely involve systematically removing or altering different parts of the proposed NVComposer model to assess their impact on novel view synthesis (NVS) quality. Key experiments could include disabling the dual-stream diffusion model, which implicitly estimates camera poses, to demonstrate its necessity in handling sparse, unposed images. The geometry-aware feature alignment module would also be a focus, with experiments assessing the impact of removing the geometric priors from the dense stereo model. By comparing the quantitative results (e.g., PSNR, SSIM, LPIPS) across these ablation experiments, the paper would build a strong case for the effectiveness of each module. A thoughtful analysis would go beyond simple quantitative comparisons, considering the qualitative impact of each component on the generated novel views, such as visual artifacts or consistency. The discussion should explain how the findings reinforce the overall claims made in the paper regarding the model’s flexibility and accessibility by avoiding external alignment. Finally, the analysis might explore the trade-offs between different components, for example, the computational cost versus improvement in accuracy gained by including specific modules. This section’s thoroughness and insightfulness will be crucial in convincing readers of the model’s design choices and its superiority over existing approaches.
Future Work & Limitations#
Future research directions for NVComposer could involve exploring more sophisticated geometry-aware feature alignment techniques. The current approach leverages a pre-trained dense stereo model; however, integrating learned geometry representations or incorporating more advanced 3D understanding could significantly enhance performance. Improving the model’s ability to handle extreme viewpoint changes and severe occlusions is another crucial area. Current results show improvements with added views, but challenges remain in generating plausible novel views under difficult viewing conditions. Further investigation into the implicit pose estimation mechanism is also needed. While the dual-stream diffusion model implicitly learns pose relationships, explicitly modeling and refining this component could lead to better control and more accurate camera pose prediction for enhanced view consistency. Lastly, extending the framework to handle dynamic scenes and exploring the incorporation of temporal consistency constraints is an exciting prospect, paving the way for generative video synthesis applications. Addressing these limitations would significantly enhance NVComposer’s versatility and applicability to a wider range of real-world scenarios.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of NVComposer, a novel view synthesis model. It showcases two main components: 1) an image-pose dual-stream diffusion model, which simultaneously generates new views and estimates the corresponding camera poses without explicit external alignment; and 2) a geometry-aware feature alignment adapter that leverages geometric information from a pre-trained dense stereo model (DUSt3R [34]) to improve the accuracy and consistency of generated views. The dual-stream model processes input image-pose bundles, implicitly inferring spatial relationships between multiple conditional views to synthesize novel views. The adapter incorporates geometric priors to enhance view consistency. This design enables NVComposer to generate high-quality novel views from sparse, unposed images, eliminating the need for explicit multi-view alignment.
read the caption
Figure 2: Framework illustration of NVComposer. It contains an image-pose dual-stream diffusion model that generates novel views while implicitly estimating camera poses for conditional images, and a geometry-aware feature alignment adapter that uses geometric priors distilled from pretrained dense stereo models [34].

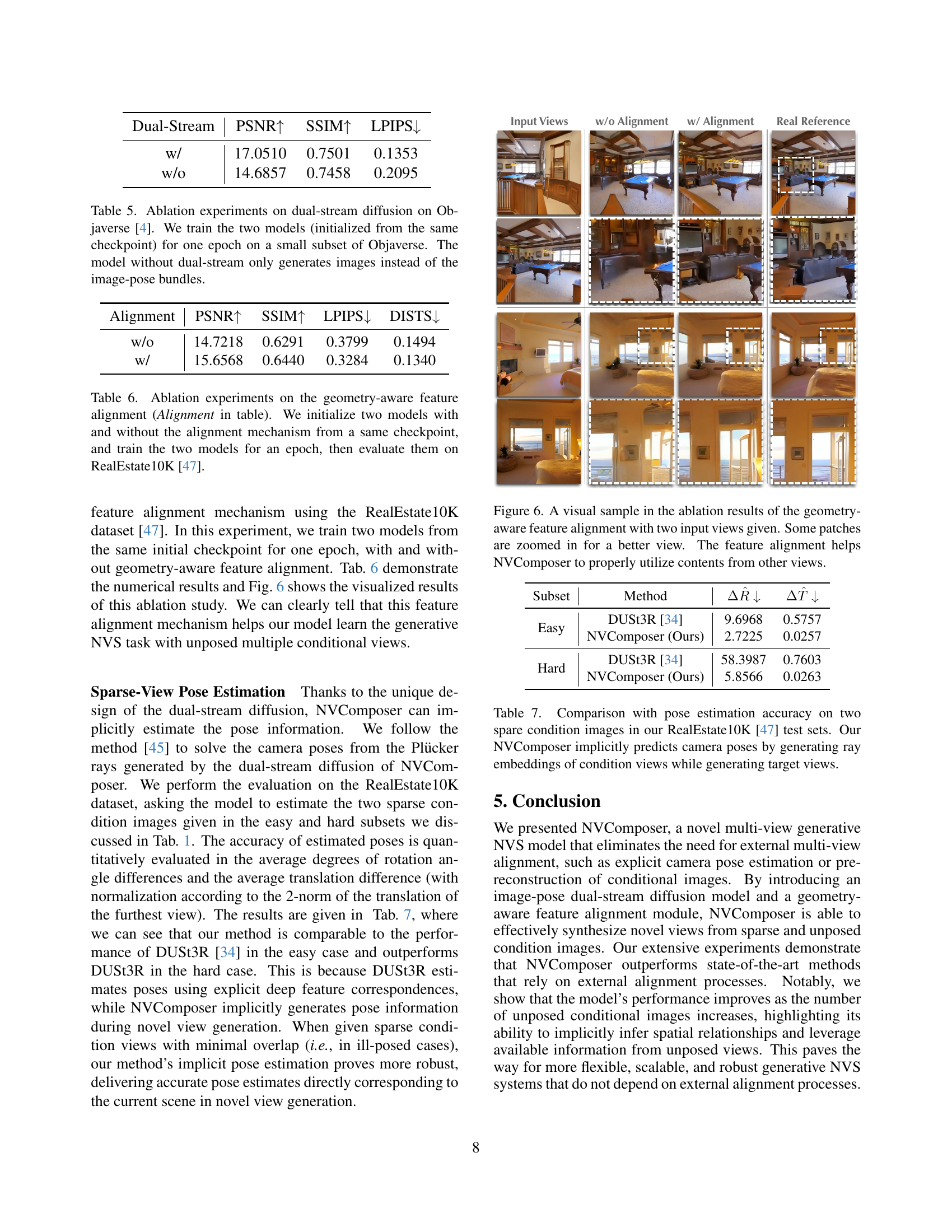
🔼 The geometry-aware feature alignment adapter in NVComposer enhances the model’s understanding of spatial relationships between views. It takes internal features from the dual-stream diffusion model and aligns them with 3D point maps generated by the external DUSt3R model. This alignment is done using bilinear upsampling (x2, x4, x8) and channel-wise MLPs (red bars) to integrate geometric priors into the generative process, improving the accuracy and consistency of novel view synthesis. This adapter allows NVComposer to implicitly learn geometric relationships from the dense stereo model without requiring explicit reconstruction during inference.
read the caption
Figure 3: Structure of the geometry-aware feature alignment adapter in NVComposer, which aligns the internal features of the dual-stream diffusion models with the 3D point maps produces by DUSt3R [34] during training. Block with notation “×2absent2\times 2× 2”, “×4absent4\times 4× 4”, and “×8absent8\times 8× 8” refer to bilinear upsampling on spatial dimensions. The four red bars refer to the channel-wise MLPs.

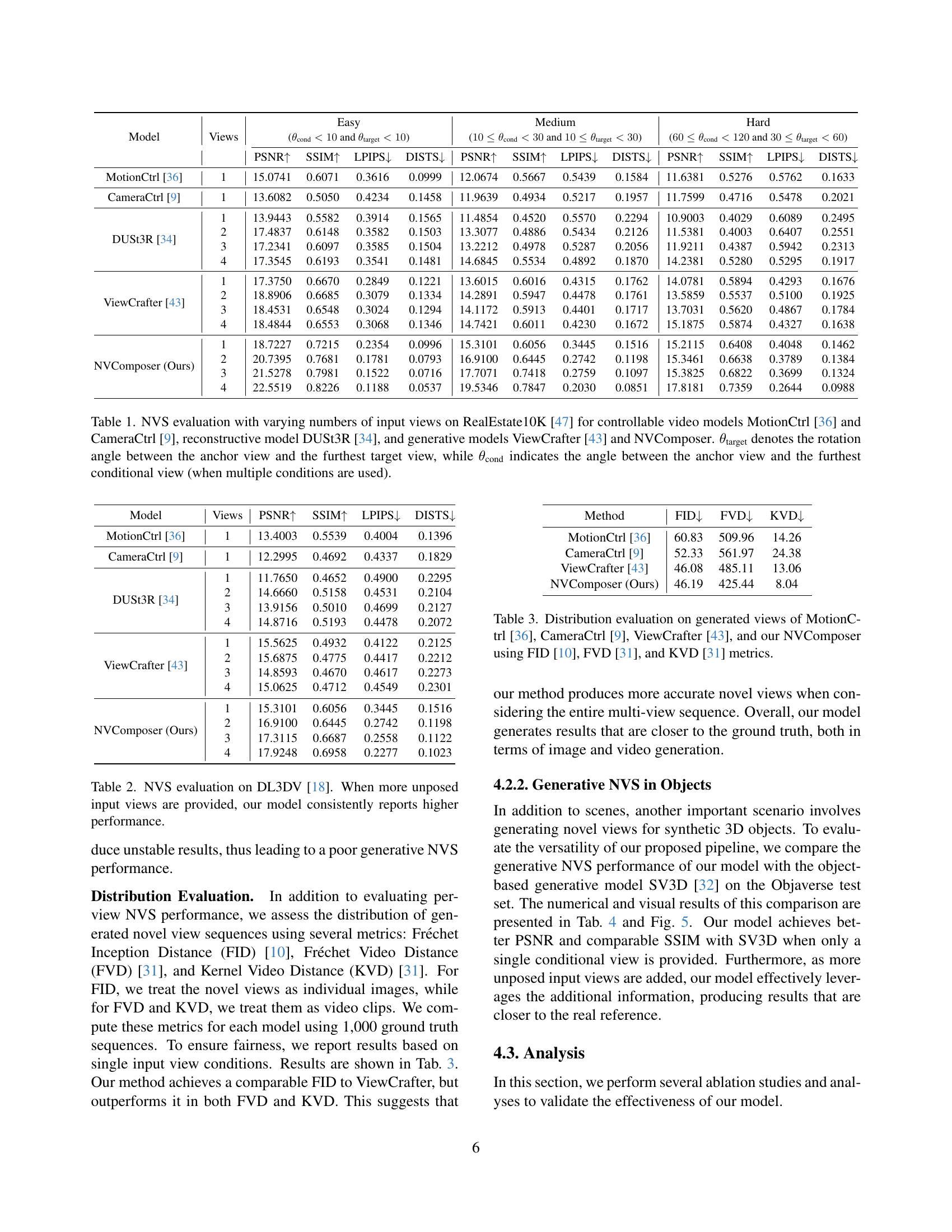
🔼 Figure 4 presents a qualitative comparison of novel view synthesis (NVS) results from different methods on the RealEstate10K and DL3DV datasets. The methods compared include MotionCtrl, CameraCtrl, DUSt3R, ViewCrafter, and the proposed NVComposer. MotionCtrl and CameraCtrl, using a single input view, exhibit inaccurate camera trajectory estimations. While DUSt3R and ViewCrafter demonstrate improved camera control with two input views, they also show artifacts caused by occlusions or misalignments in the multi-view input. In contrast, NVComposer yields results more closely matching the ground truth, showcasing its superior performance in handling occlusions and generating visually accurate novel views. Detailed zoomed-in regions of the first three scenes are included for closer inspection, with further comparisons available in the supplementary material.
read the caption
Figure 4: Visual comparison of NVS results on the RealEstate10K [47] and DL3DV [18] test sets. MotionCtrl [36] and CameraCtrl [9] uses the first view as input while other methods use two views as input. MotionCtrl and CameraCtrl produce incorrect camera trajectories. DUSt3R and ViewCrafter exhibit better camera control but introduce artifacts due to occlusions or misaligned multi-view inputs. Our model generates views that are visually closer to the reference. We provide zoomed-in details of the first three scenes in white boxes for a closer look. Additional visual comparisons can be found in the supplementary material.

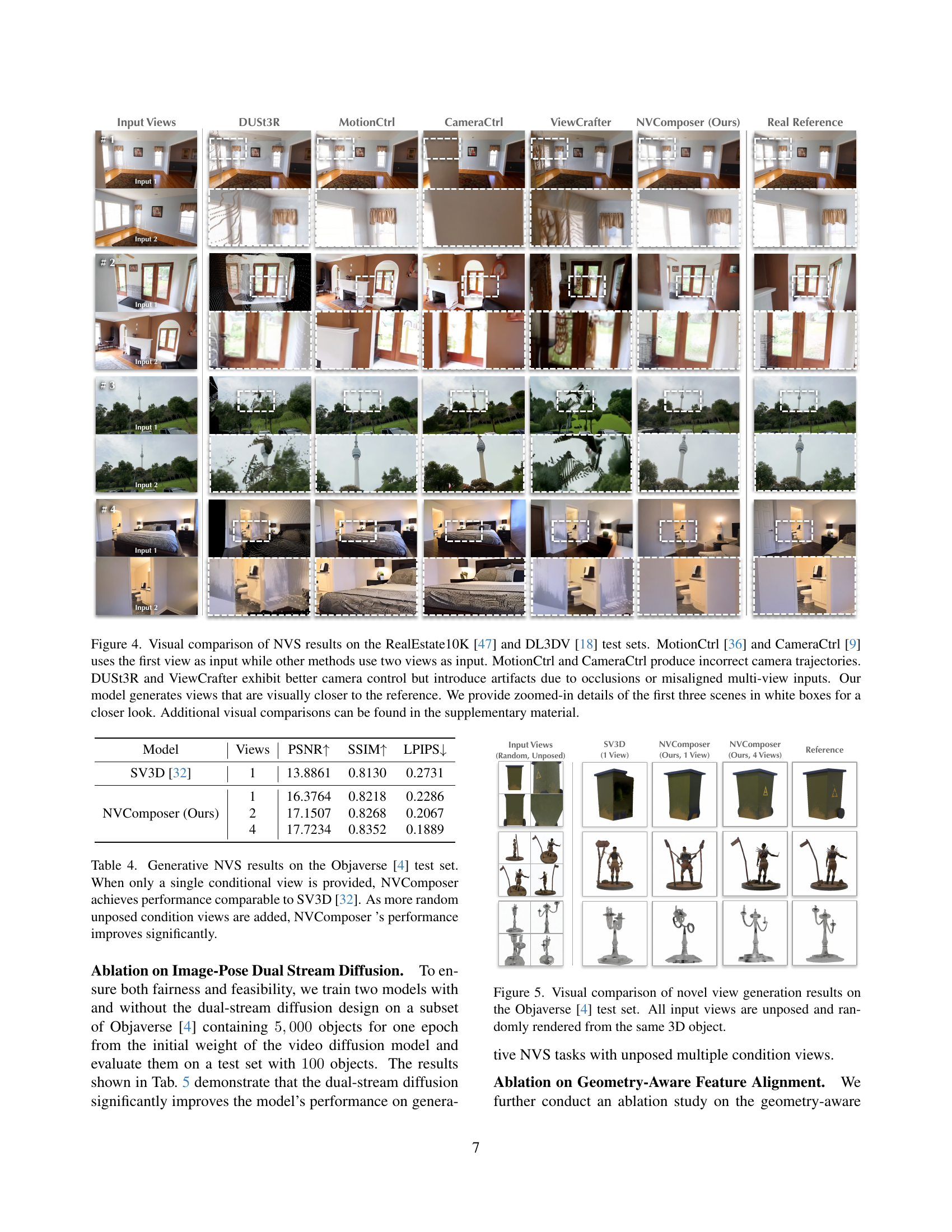
🔼 Figure 5 presents a visual comparison of novel view synthesis results obtained using different methods on the Objaverse dataset. The test set includes various 3D objects, and for each object, the input views are unposed and randomly rendered from the same 3D model. This ensures a consistent evaluation across different models, showcasing their ability to generate novel viewpoints from various perspectives. The figure facilitates a direct comparison of the visual quality and accuracy of novel view generation across the different approaches.
read the caption
Figure 5: Visual comparison of novel view generation results on the Objaverse [4] test set. All input views are unposed and randomly rendered from the same 3D object.
More on tables
| Model | Views | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DISTS ↓ |
|---|---|---|---|---|---|
| MotionCtrl [36] | 1 | 13.4003 | 0.5539 | 0.4004 | 0.1396 |
| CameraCtrl [9] | 1 | 12.2995 | 0.4692 | 0.4337 | 0.1829 |
| DUSt3R [34] | 1 | 11.7650 | 0.4652 | 0.4900 | 0.2295 |
| 2 | 14.6660 | 0.5158 | 0.4531 | 0.2104 | |
| 3 | 13.9156 | 0.5010 | 0.4699 | 0.2127 | |
| 4 | 14.8716 | 0.5193 | 0.4478 | 0.2072 | |
| ViewCrafter [43] | 1 | 15.5625 | 0.4932 | 0.4122 | 0.2125 |
| 2 | 15.6875 | 0.4775 | 0.4417 | 0.2212 | |
| 3 | 14.8593 | 0.4670 | 0.4617 | 0.2273 | |
| 4 | 15.0625 | 0.4712 | 0.4549 | 0.2301 | |
| NVComposer (Ours) | 1 | 15.3101 | 0.6056 | 0.3445 | 0.1516 |
| 2 | 16.9100 | 0.6445 | 0.2742 | 0.1198 | |
| 3 | 17.3115 | 0.6687 | 0.2558 | 0.1122 | |
| 4 | 17.9248 | 0.6958 | 0.2277 | 0.1023 |
🔼 Table 2 presents a quantitative evaluation of novel view synthesis (NVS) performance using the DL3DV dataset. The table compares the performance of the proposed NVComposer model against several baseline methods (MotionCtrl, CameraCtrl, DUSt3R, and ViewCrafter). The key metric is PSNR (higher is better), which measures the quality of the generated views relative to ground truth. The results are shown for different numbers of unposed input views (1, 2, 3, 4), demonstrating the impact of using multiple input views on the quality of the synthesized novel views. As the number of input views increases, NVComposer consistently shows improvements in PSNR, indicating its ability to leverage additional information effectively.
read the caption
Table 2: NVS evaluation on DL3DV [18]. When more unposed input views are provided, our model consistently reports higher performance.
| Method | FID↓ | FVD↓ | KVD↓ |
|---|---|---|---|
| MotionCtrl [36] | 60.83 | 509.96 | 14.26 |
| CameraCtrl [9] | 52.33 | 561.97 | 24.38 |
| ViewCrafter [43] | 46.08 | 485.11 | 13.06 |
| NVComposer (Ours) | 46.19 | 425.44 | 8.04 |
🔼 This table presents a quantitative comparison of the quality of generated video sequences by four different methods: MotionCtrl, CameraCtrl, ViewCrafter, and NVComposer. The evaluation is performed using three metrics: Fréchet Inception Distance (FID), Fréchet Video Distance (FVD), and Kernel Video Distance (KVD). Lower FID, FVD, and KVD scores indicate higher similarity between the generated videos and real-world videos, suggesting improved generation quality.
read the caption
Table 3: Distribution evaluation on generated views of MotionCtrl [36], CameraCtrl [9], ViewCrafter [43], and our NVComposer using FID [10], FVD [31], and KVD [31] metrics.
| Model | Views | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|
| SV3D [32] | 1 | 13.8861 | 0.8130 | 0.2731 |
| NVComposer (Ours) | 1 | 16.3764 | 0.8218 | 0.2286 |
| 2 | 17.1507 | 0.8268 | 0.2067 | |
| 4 | 17.7234 | 0.8352 | 0.1889 |
🔼 Table 4 presents a comparison of novel view synthesis (NVS) performance on the Objaverse dataset [4], specifically focusing on the impact of the number of input views. The results demonstrate that NVComposer, even with a single input view, achieves comparable performance to the state-of-the-art method SV3D [32]. Importantly, the table shows a significant improvement in NVComposer’s performance as more unposed and randomly selected input views are added. This highlights the effectiveness of NVComposer in leveraging multiple views to enhance the quality of the synthesized novel views.
read the caption
Table 4: Generative NVS results on the Objaverse [4] test set. When only a single conditional view is provided, NVComposer achieves performance comparable to SV3D [32]. As more random unposed condition views are added, NVComposer ’s performance improves significantly.
| Dual-Stream | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| w/ | 17.0510 | 0.7501 | 0.1353 |
| w/o | 14.6857 | 0.7458 | 0.2095 |
🔼 This table presents the ablation study results focusing on the impact of the dual-stream diffusion model in NVComposer. Two models were trained for one epoch on a subset of the Objaverse dataset. One model incorporated the dual-stream architecture, while the other did not. Both models were initialized from the same checkpoint. The key difference is that the model without the dual-stream generates only images, while the model with dual-stream generates both images and their associated pose information (image-pose bundles). The table compares the performance of these two models using metrics such as PSNR, SSIM, and LPIPS.
read the caption
Table 5: Ablation experiments on dual-stream diffusion on Objaverse [4]. We train the two models (initialized from the same checkpoint) for one epoch on a small subset of Objaverse. The model without dual-stream only generates images instead of the image-pose bundles.
| Alignment | PSNR↑ | SSIM↑ | LPIPS↓ | DISTS↓ |
|---|---|---|---|---|
| w/o | 14.7218 | 0.6291 | 0.3799 | 0.1494 |
| w/ | 15.6568 | 0.6440 | 0.3284 | 0.1340 |
🔼 This table presents the results of an ablation study comparing two models trained on the RealEstate10K dataset. Both models started from the same checkpoint, but one incorporated the geometry-aware feature alignment mechanism, while the other did not. The models were trained for a single epoch, after which their performance on several metrics (PSNR, SSIM, LPIPS, and DISTS) was evaluated and compared to determine the effectiveness of the geometry-aware feature alignment in improving novel view synthesis.
read the caption
Table 6: Ablation experiments on the geometry-aware feature alignment (Alignment in table). We initialize two models with and without the alignment mechanism from a same checkpoint, and train the two models for an epoch, then evaluate them on RealEstate10K [47].
| Subset | Method | $\Delta\hat{R}\downarrow$ | $\Delta\hat{T}\downarrow$ |
|---|---|---|---|
| Easy | DUSt3R [34] | 9.6968 | 0.5757 |
| NVComposer (Ours) | 2.7225 | 0.0257 | |
| Hard | DUSt3R [34] | 58.3987 | 0.7603 |
| NVComposer (Ours) | 5.8566 | 0.0263 |
🔼 This table compares the accuracy of camera pose estimation between NVComposer and the DUSt3R method. The evaluation is performed on a subset of the RealEstate10K dataset, using two sparsely sampled condition images. Accuracy is measured in terms of the average angular rotation and translation differences between estimated and ground truth poses. NVComposer implicitly estimates poses by generating ray embeddings of the condition views during novel view synthesis, while DUSt3R uses explicit methods. The results show that NVComposer outperforms DUSt3R, especially in challenging scenarios with small overlap between views.
read the caption
Table 7: Comparison with pose estimation accuracy on two spare condition images in our RealEstate10K [47] test sets. Our NVComposer implicitly predicts camera poses by generating ray embeddings of condition views while generating target views.
Full paper#