↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal language models struggle with visual perception tasks requiring reasoning about 3D structures or 2D objects. Fine-tuning these models on relevant data doesn’t generalize well, and using specialized vision tools is computationally expensive. This paper addresses these issues.
The researchers introduce AURORA, a training method that enhances multimodal language models by incorporating “Perception Tokens.” These tokens act as intermediate reasoning steps, similar to chain-of-thought prompts, allowing the models to reason over intermediate representations like depth maps and bounding boxes. AURORA significantly improves the models’ performance on various visual reasoning benchmarks, surpassing existing approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of current multimodal language models in visual reasoning tasks. By introducing a novel training method and perception tokens, it significantly enhances the models’ ability to perform complex visual reasoning, opening new avenues for research in this field and improving various applications.
Visual Insights#

🔼 The figure illustrates the concept of Perception Tokens and the Aurora framework. Perception Tokens are intermediate reasoning tokens that enhance visual reasoning in multimodal language models (MLMs). They act as auxiliary tokens, similar to chain-of-thought prompts, allowing MLMs to incorporate visual perception information, such as depth maps and bounding boxes, into their reasoning process. Aurora is a training framework that leverages Perception Tokens to enable MLMs to perform depth estimation and bounding box prediction during visual reasoning tasks. The example in the figure shows how a depth map, represented as Perception Tokens, is used to determine which point is closer to the camera.
read the caption
Figure 1: We introduce Perception Tokens, intermediate reasoning tokens that allow MLMs to go beyond using language in reasoning. With it, we develop Aurora, a framework that trains multimodal language models to leverage visual perception tokens, allowing them to use depth estimation and bounding box predictions while reasoning.
| Model | Direct Labeling Data | Depth Generation Data | CoT Data | BLINK 2 Points | HardBLINK 3 Points | HardBLINK 4 Points | HardBLINK 5 Points | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA OneVision | ✗ | ✗ | ✗ | 51.6 | 33.1 | 22.6 | 18.5 | 31.4 | ||||||||
| LLaVA 1.5 13B | ✗ | ✗ | ✗ | 54.0 | 35.5 | 37.9 | 29 | 39.1 | ||||||||
| Fine-tunned LLaVA | ✓ | ✗ | ✗ | 68.5 | 58.9 | 52.4 | 41.1 | 55.2 | ||||||||
| LLaVA-Aurora (Ours) | ✓ | ✓ | ✓ | 64.5 | 66.9 | 60.5 | 54.8 | 61.6 | ||||||||
| GPT-4o | ✗ | ✗ | ✗ | 53.2 | 58.9 | 50 | 36.3 | 49.6 | ||||||||
| GPT-4 Turbo | ✗ | ✗ | ✗ | 58.1 | 54.8 | 41.9 | 32.2 | 46.7 | ||||||||
| GPT-4 Turbo + Tool | ✗ | ✗ | ✗ | 70.2 | 57.2 | 44.3 | 26.6 | 49.6 |
🔼 This table presents a performance comparison of three different models on a relative depth estimation task. The models compared are: the original LLaVA 1.5 13B model, a fine-tuned version of LLaVA, and the LLaVA-AURORA model (the authors’ proposed method). The task involves determining which of two or more points in an image is closest to the camera. The performance is measured as the accuracy (%) of the model’s predictions. The difficulty of the task is varied by using different numbers of points (2, 3, 4, and 5 points) sampled from the image’s mid-height region (increasing difficulty with a larger number of points). The results show that LLaVA-AURORA, which uses depth tokens and intermediate reasoning steps significantly outperforms both the baseline and the fine-tuned models, especially when dealing with the more challenging configurations of 3, 4, and 5 points.
read the caption
Table 1: Performance comparison between our LLaVA-Aurora model, the fine-tunning baseline, and the original base model on the relative depth accuracy (%) task. Results demonstrate that our approach, utilizing depth tokens and intermediate reasoning steps, significantly outperforms both the baseline and the base model, particularly on more challenging configurations with 3, 4, and 5 points sampled from the image’s mid-height region.
In-depth insights#
Visual Tokenization#
Visual tokenization, a crucial aspect of multimodal learning, bridges the gap between visual data and language models. Effective visual tokenization transforms raw image data into a discrete, tokenized representation that can be directly processed by a language model. This involves choosing an appropriate tokenization scheme, often depending on the task. For example, pixel-level tokenization might represent images as sequences of individual pixel values, while structured tokenization could encode higher-level features such as bounding boxes or object segments. The selection of a tokenization method significantly impacts the model’s ability to capture relevant visual information. A well-chosen method ensures that crucial visual details are preserved and efficiently incorporated into the language model’s reasoning process. Furthermore, the efficiency of tokenization is paramount. An efficient method reduces computational costs and memory usage while maintaining high accuracy. Therefore, careful consideration of the trade-offs between detail preservation and computational efficiency is needed in the design of a visual tokenization scheme.
AURORA Framework#
The AURORA framework is a novel approach to enhance visual reasoning in multimodal language models (MLMs). It addresses the limitations of current MLMs by introducing Perception Tokens, which are intrinsic image representations like depth maps or bounding boxes, enabling the MLM to reason over visual information more effectively. AURORA leverages a vector quantized variational autoencoder (VQVAE) to transform these intermediate visual representations into a tokenized format, seamlessly integrating them into the MLM’s chain-of-thought reasoning process. This allows the model to perform intermediate reasoning steps akin to those in human thought processes, significantly improving performance on tasks like object counting and relative depth estimation. The framework’s multi-task training approach and curriculum learning strategy further enhance its generalization ability and robustness, surpassing traditional finetuning methods across various benchmarks. The key innovation lies in treating visual perceptions as reasoning tokens, enabling more complex reasoning capabilities within MLMs. AURORA’s flexible design also facilitates the incorporation of new visual modalities, showcasing its potential for wider applicability and future developments in multimodal learning.
Multimodal Reasoning#
Multimodal reasoning, the capacity of AI systems to seamlessly integrate and interpret information from diverse modalities like text, images, and audio, is a rapidly advancing field. Current multimodal models often struggle with tasks requiring fine-grained perceptual understanding, such as relative depth estimation or precise object counting, which are easily solved by specialized vision systems. The core challenge lies in bridging the gap between high-level language reasoning and low-level visual representations. The introduction of ‘perception tokens,’ which act as intermediate reasoning steps, offers a promising solution. These tokens encode detailed visual information (like depth maps or bounding boxes) into a format that language models can process, effectively enabling reasoning over these visual features. This approach allows for more sophisticated visual reasoning within the context of the language model’s inherent capabilities, thereby overcoming the limitations of existing methods. The multi-task training framework further enhances the model’s ability to generalize, improving performance across diverse datasets, and proving more adaptable to new visual tasks than conventional finetuning. However, further research is needed to refine tokenization methods, explore the most suitable types of perception tokens for different tasks and assess the computational cost and potential scalability issues involved in using perception tokens.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a detailed comparison of the proposed model (LLaVA-AURORA) against various baselines and state-of-the-art methods across multiple relevant benchmarks. Quantitative metrics such as relative depth accuracy and object counting accuracy would be crucial, presented for each benchmark alongside statistical significance testing to support the claims of improvement. The choice of benchmarks themselves would be key—a strong section should justify the selection based on their recognition within the field and their relevance to the paper’s contributions. Qualitative results, perhaps visual examples of depth maps or bounding boxes generated by the model, would complement the quantitative findings and showcase the model’s capabilities. Detailed error analysis, explaining reasons for model failures or limitations, would demonstrate a thorough evaluation and provide valuable insights into future work. Finally, a discussion summarizing the overall performance, highlighting both strengths and weaknesses, and relating the results back to the paper’s hypothesis and contributions would complete the section effectively.
Future Extensions#
Future research directions stemming from this work could explore several promising avenues. Extending the framework to encompass a wider variety of visual tasks beyond relative depth and object counting is crucial. This would involve developing novel perception tokens and training methodologies tailored to diverse visual features. Investigating the integration of advanced reasoning techniques, such as attention mechanisms or graph neural networks, alongside perception tokens may lead to further performance improvements in complex reasoning tasks. The impact of different tokenization strategies should be thoroughly investigated, potentially exploring hybrid approaches that combine various representations. A comprehensive analysis of model robustness and generalization capability across diverse datasets and unseen scenarios is vital. Finally, exploring applications of this enhanced visual reasoning framework in practical settings, such as robotics or autonomous driving, would showcase its potential to significantly impact real-world problems.
More visual insights#
More on figures

🔼 Figure 2 showcases two example tasks: relative depth estimation and object counting. The left side displays how the original LLaVA model fails on these tasks. The right side shows how the improved LLaVA-AURORA model, incorporating visual perception tokens as intermediate reasoning steps, successfully completes these tasks. The addition of perception tokens allows LLaVA-AURORA to effectively leverage visual information, thus improving performance on tasks requiring perceptual understanding, which the standard LLaVA model struggled with. The figure visually demonstrates the significant improvement achieved by integrating visual perception tokens.
read the caption
Figure 2: We demonstrate relative depth estimation and counting questions where LLaVA fails. In contrast, by learning to utilize visual perception tokens as intermediate reasoning steps, LLaVA-Aurora successfully complete these tasks requiring perceptual understanding.

🔼 The figure illustrates the AURORA training framework. AURORA leverages a Vector Quantized Variational Autoencoder (VQVAE) to convert visual representations (like depth maps) into a set of discrete tokens called ‘perception tokens’. These tokens are then integrated into a multimodal language model (MLM) during a multi-task training phase. The MLM learns to generate and utilize these perception tokens as intermediate reasoning steps to solve visual reasoning tasks. This process allows the MLM to incorporate low-level image features into its reasoning process, improving performance on tasks where pure language processing is insufficient.
read the caption
Figure 3: The overall Aurora training framework. We first learn visual perception tokens using VQVAE. We then finetune MLMs with a multi-task training approach where we distill intrinsic image representations (e.g., depth map) into MLMs by training them to decode the visual tokens as intermediate reasoning steps towards completing the tasks.

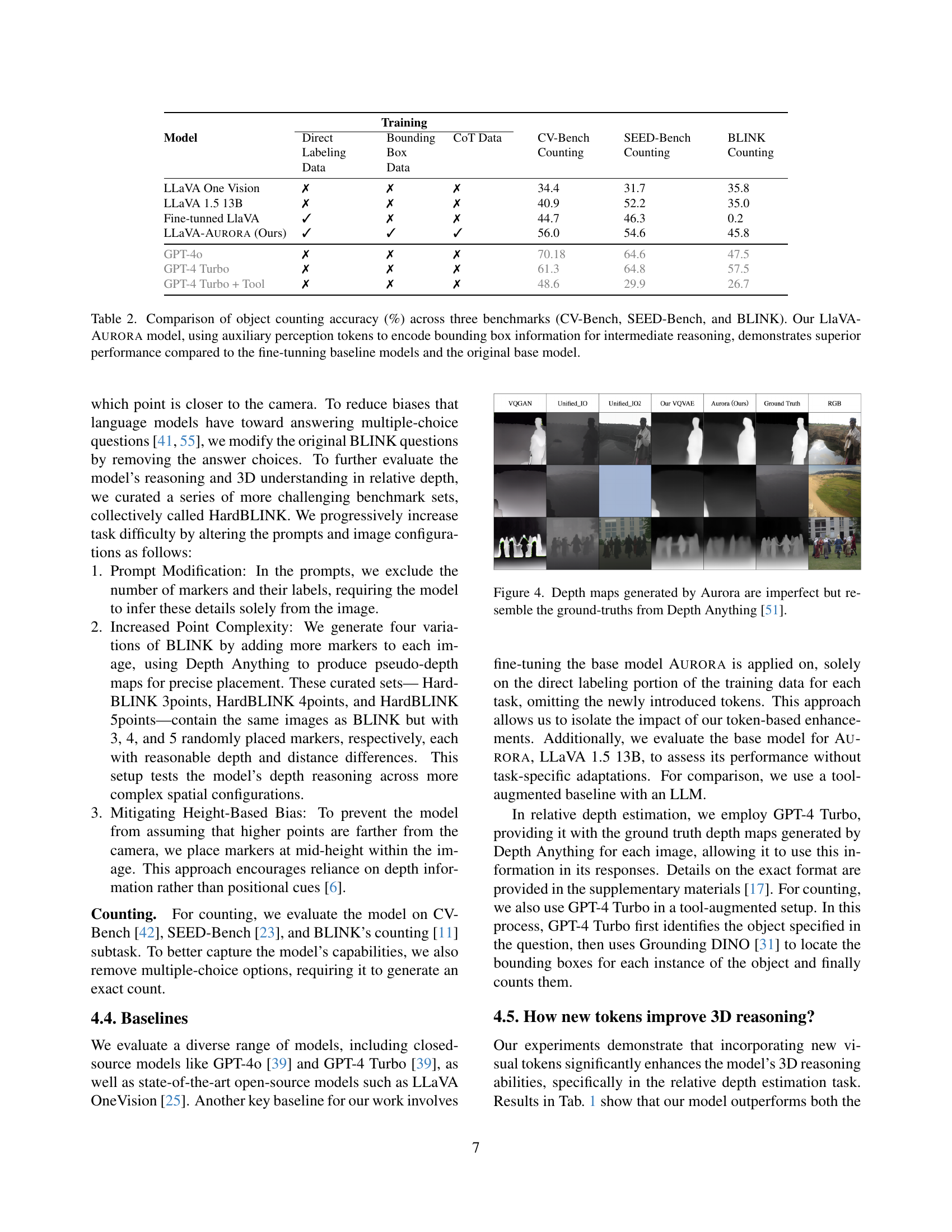
🔼 Figure 4 presents a qualitative comparison of depth maps generated by the AURORA model and ground truth depth maps from the Depth Anything model [51]. The AURORA model’s depth maps, while not perfect, show a reasonable resemblance to the ground truth, indicating the model’s ability to generate depth information that is useful for visual reasoning tasks. The comparison highlights the model’s capacity to produce depth maps which, although imperfect, capture the relative depth of objects in a scene and are useful as input to downstream visual reasoning tasks.
read the caption
Figure 4: Depth maps generated by Aurora are imperfect but resemble the ground-truths from Depth Anything [51].

🔼 This figure presents a qualitative comparison of depth maps generated by a model trained with and without a reconstruction loss. It visually demonstrates the impact of the reconstruction loss on the accuracy and detail of the predicted depth maps, allowing for a direct visual assessment of the improvement in the quality of depth estimation.
read the caption
Figure 5: Qualitative comparison of predicted depth maps with and without reconstruction loss.

🔼 Figure 6 illustrates the three types of data used to train the model for the relative depth estimation task. The first, ‘Depth Generation Data,’ shows the model generating a depth map represented as a sequence of tokens. The second, ‘Chain of Thought Data,’ demonstrates a multi-step reasoning process to determine the closest point to the camera, using both the coordinates of the points and the depth map generated as intermediate steps. Finally, ‘Direct Labeling Data’ shows a simple question-answering approach where the model directly identifies the nearest point.
read the caption
Figure 6: Examples of sub-datasets for the depth task: (1) depth generation, (2) Chain-of-Thought reasoning, and (3) direct labeling.

🔼 Figure 7 illustrates three types of data used for training a model to count objects in images. The first example shows bounding box predictions, where the model identifies objects and outputs the coordinates of their bounding boxes using perception tokens (PIXEL_X). The second example demonstrates Chain-of-Thought reasoning, where the model goes through a step-by-step process, first identifying bounding boxes for the objects of interest and then counting them. Finally, the third example showcases direct labeling, in which the model is directly given the question and answer, thus learning to count objects without intermediate reasoning steps. This multifaceted training approach helps the model learn to count accurately through different reasoning strategies.
read the caption
Figure 7: Examples of sub-datasets for the counting task: (1) bounding box prediction, (2) Chain-of-Thought reasoning, and (3) direct labeling.
More on tables
| Model | Direct Labeling Data | Bounding Box Data | CoT Data | CV-Bench Counting | SEED-Bench Counting | BLINK Counting | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA One Vision | ✗ | ✗ | ✗ | 34.4 | 31.7 | 35.8 | |||||
| LLaVA 1.5 13B | ✗ | ✗ | ✗ | 40.9 | 52.2 | 35.0 | |||||
| Fine-tunned LlaVA | ✓ | ✗ | ✗ | 44.7 | 46.3 | 0.2 | |||||
| LLaVA-Aurora (Ours) | ✓ | ✓ | ✓ | 56.0 | 54.6 | 45.8 | |||||
| GPT-4o | ✗ | ✗ | ✗ | 70.18 | 64.6 | 47.5 | |||||
| GPT-4 Turbo | ✗ | ✗ | ✗ | 61.3 | 64.8 | 57.5 | |||||
| GPT-4 Turbo + Tool | ✗ | ✗ | ✗ | 48.6 | 29.9 | 26.7 |
🔼 Table 2 presents a comparative analysis of object counting accuracy across three established benchmarks: CV-Bench, SEED-Bench, and BLINK. The results showcase the performance of various models, including the original LLaVA 1.5 13B model, a fine-tuned version of LLaVA, and the novel LLaVA-AURORA model. LLaVA-AURORA leverages the technique of incorporating perception tokens, representing bounding box information, to enhance intermediate reasoning during the object counting process. This table highlights the superior performance of LLaVA-AURORA compared to both the fine-tuned LLaVA model and the original base model, demonstrating the effectiveness of the proposed method.
read the caption
Table 2: Comparison of object counting accuracy (%) across three benchmarks (CV-Bench, SEED-Bench, and BLINK). Our LlaVA-Aurora model, using auxiliary perception tokens to encode bounding box information for intermediate reasoning, demonstrates superior performance compared to the fine-tunning baseline models and the original base model.
| Model | BLINK [11] 2 points | HardBLINK 3 Points | HardBLINK 4 Points | HardBLINK 5 Points | Average | ||||
|---|---|---|---|---|---|---|---|---|---|
| VQGAN [10] (16384 codes) | 82.2 | 66.1 | 53 | 37 | 59.6 | ||||
| Unified-IO | 70.2 | 75.8 | 75.8 | 75.8 | 74.4 | ||||
| Unified-IO2 | 54 | 37.9 | 21 | 27.4 | 35.1 | ||||
| LLaVA-Aurora (Ours) | 91.9 | 78.2 | 71.7 | 75.8 | 79.2 | ||||
| Our VQVAE (128 codes) | 96.7 | 94.3 | 95.2 | 96.7 | 95.7 |
🔼 This table presents a supplementary analysis of depth map generation quality using the BLINK dataset’s relative depth subtask. It compares the performance of various models, including the authors’ model (LLaVA-AURORA), Unified-IO, and Unified-IO 2, in generating accurate depth maps. The evaluation metric is relative depth estimation accuracy, calculated by extracting depth values from the generated maps at specific coordinates and comparing them to ground truth. The varying number of marked points (2, 3, 4, and 5) in each benchmark image provides a complexity gradient for assessing model performance. The results show that LLaVA-AURORA consistently outperforms other models.
read the caption
Table 3: While not the main aim of our work, we report the depth generation performance across benchmarks with 2, 3, 4, and 5 marked points using BLINK [11]’s relative depth subtask images. We report relative depth estimation accuracy (%), calculated by programmatically extracting depth values at specific coordinates from model-generated depth maps. Our model consistently outperforms other multimodal models, including Unified-IO [33] and Unified-IO 2 [34]
| Model | Coordinates | Depth | HardBLINK 3 Points | HardBLINK 4 Points | HardBLINK 5 Points | ||||
|---|---|---|---|---|---|---|---|---|---|
| Direct Labeling Baseline | ✗ | ✗ | 58.9 | 52.4 | 41.1 | ||||
| Step (2) only | ✗ | ✓ | 56.4 | 56.4 | 50 | ||||
| LLaVA-Aurora (Ours) | ✓ | ✓ | 66.9 | 60.5 | 54.8 |
🔼 This table presents the results of an ablation study on the relative depth estimation task using the harder BLINK dataset. Three model variations were compared: a direct labeling baseline (no chain-of-thought), a model using only the depth map generation step in the prompt, and the AURORA model (which includes both the coordinate identification and depth map generation steps). The table shows that the AURORA model, incorporating both steps in the chain-of-thought, achieved significantly better performance across all configurations of the harder BLINK dataset (3, 4, and 5 points). This highlights the importance of guiding the model through a multi-step reasoning process for improved accuracy in depth estimation tasks.
read the caption
Table 4: Performance comparison of models trained with different Chain of Thought question prompt variations for relative depth estimation on the harder BLINK datasets. Models with both steps in the prompts (Aurora) achieve the best performance.
| Model | Token Type | CV-Bench Counting | SEED-Bench Counting | BLINK Counting | ||||
|---|---|---|---|---|---|---|---|---|
| LLaVA-Aurora | Standard | 52.2 | 50.6 | 38.3 | ||||
| LLaVA-Aurora | Perception | 56.0 | 54.6 | 45.8 |
🔼 This table presents a comparison of the performance of a model using perception tokens versus standard text tokens for object counting tasks across three benchmark datasets: BLINK, SEED-Bench, and CV-Bench. The results show that using perception tokens consistently leads to improved accuracy in object counting.
read the caption
Table 5: Comparison of model performance using perception tokens and standard tokens for the object counting task across three benchmarks: BLINK, SEED-Bench, and CV-Bench. Perception tokens consistently improve accuracy.
| Model | Recons Loss | BLINK | Visual Genome | |||
|---|---|---|---|---|---|---|
| LLaVA 1.5 | ✓ | 0.092 | 0.074 | |||
| LLaVA 1.5 | ✗ | 0.087 | 0.076 |
🔼 This table presents a comparison of Mean Squared Error (MSE) for depth map prediction using two models: one trained with a reconstruction loss and another without it. The MSE is calculated on two datasets: the BLINK dataset (a subset used for evaluating relative depth) and the Visual Genome dataset (a subset used for evaluating depth map generation). Lower MSE values indicate better depth map prediction accuracy. The table helps to evaluate the contribution of the reconstruction loss to the model’s overall performance in terms of depth estimation accuracy.
read the caption
Table 6: MSE evaluation of models with and without reconstruction loss on subsets BLINK and Visual Genome datasets.
| Model | CV-Bench Depth |
|---|---|
| LLaVA 1.5 13B | 62.2 |
| Fine-tunned LLaVA | 60.0 |
| Aurora (Ours) | 64.8 |
🔼 Table 7 presents a performance comparison on the CV-Bench Depth subtask, demonstrating the generalization capability of the AURORA model. It compares the performance of three models: the LLaVA 1.5 13B base model, a fine-tuned version of LLaVA, and the AURORA model. The results show that AURORA achieves the best performance on this depth estimation task, highlighting its ability to generalize to unseen data and different tasks.
read the caption
Table 7: Performance comparison on the CV-Bench Depth subtask, highlighting our model’s generalization ability.
Full paper#