↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multi-view image generation methods often involve modifying pre-trained models, which is computationally expensive and can degrade image quality. These methods also often require substantial high-quality 3D training data, which is scarce. This makes generating high-quality, multi-view images challenging.
The proposed method, MV-Adapter, solves this problem. It’s a versatile, plug-and-play adapter that enhances pre-trained models without major modifications, thus overcoming the computational limitations and mitigating risks associated with full model retraining. The results show that MV-Adapter improves the efficiency and adaptability of existing methods and achieves state-of-the-art results on various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces MV-Adapter, a novel and efficient method for multi-view image generation. It addresses limitations of existing methods by offering a plug-and-play adapter that enhances existing models without extensive retraining, leading to improved efficiency and adaptability. This opens avenues for further research in multi-view image generation and related fields.
Visual Insights#

🔼 This figure showcases the versatility of MV-Adapter, a plug-and-play adapter that enhances existing text-to-image (T2I) models to generate multi-view consistent images. The top three rows demonstrate MV-Adapter’s adaptability by integrating it with different T2I models: personalized models, distilled few-step models, and ControlNets. The bottom two rows highlight MV-Adapter’s versatility, showcasing its ability to generate multi-view images from various control signals, including text and image inputs, along with camera and geometry guidance. The images illustrate the diverse styles and views achievable, highlighting the adapter’s seamless integration with various T2I models.
read the caption
Figure 1: MV-Adapter is a versatile plug-and-play adapter that turns existing pre-trained text-to-image (T2I) diffusion models to multi-view image generators. Row 1,2,3: results by integrating MV-Adapter with personalized T2I models, distilled few-step T2I models, and ControlNets (Zhang et al., 2023), demonstrating its adaptability. Row 4,5: results under various control signals, including view-guided or geometry-guided generation with text or image inputs, showcasing its versatility.
| Method | FID ↓ | IS ↑ | CLIP Score ↑ |
|---|---|---|---|
| MVDream | 32.15 | 14.38 | 31.76 |
| SPAD | 48.79 | 12.04 | 30.87 |
| Ours (SD2.1) | 31.24 | 15.01 | 32.04 |
| Ours (SDXL) | 29.71 | 16.38 | 33.17 |
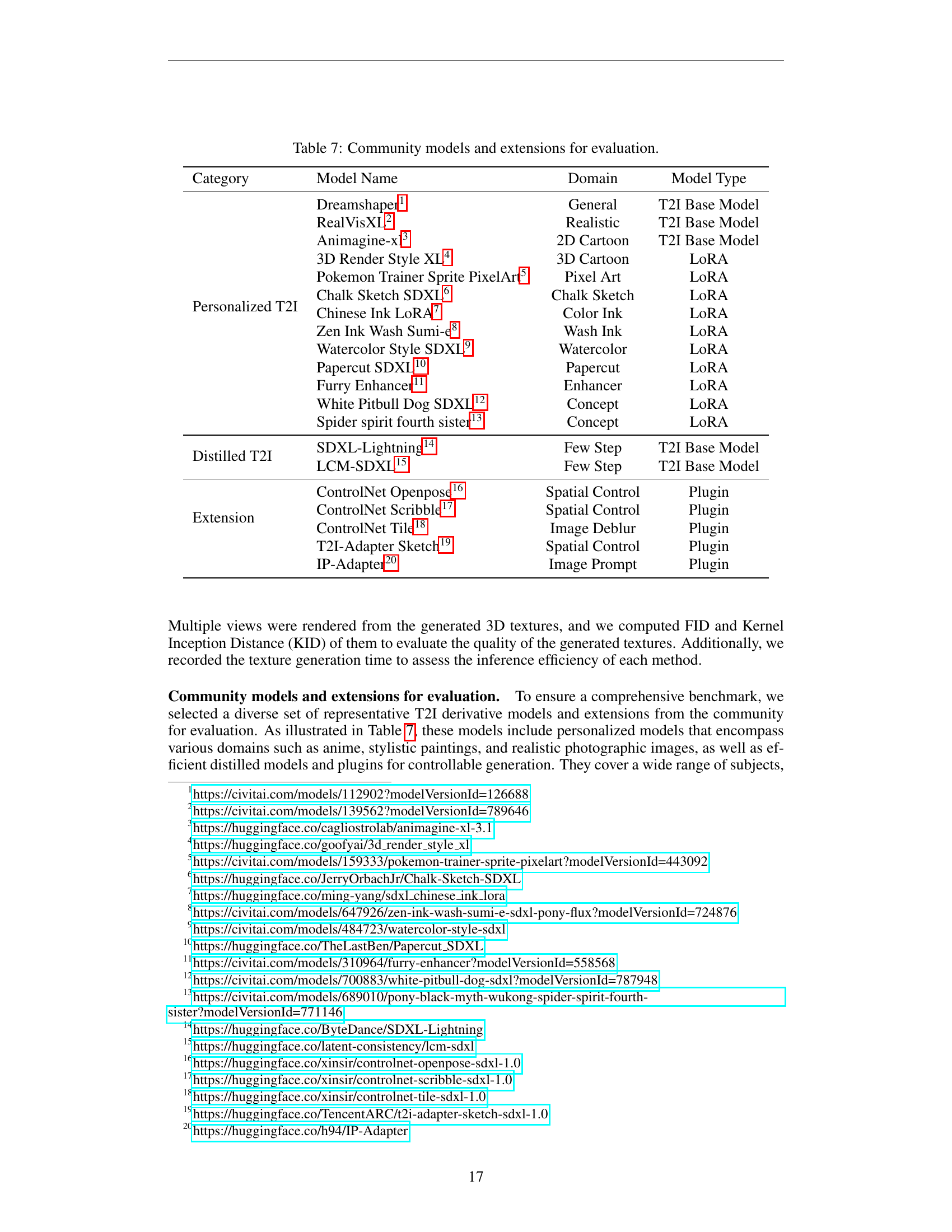
🔼 This table lists the various community models and extensions used in the experiments section of the paper. It’s broken down into three categories: Personalized T2I models, Distilled T2I models, and Extensions. Each row specifies a model, its domain (the style or type of image it generates), and its type (base model, LoRA, or plugin). This allows the reader to understand the range of models and techniques used to test the effectiveness and adaptability of the MV-Adapter across different base models and generation styles.
read the caption
Table 7: Community models and extensions for evaluation.
In-depth insights#
MV-Adapter: A Deep Dive#
An in-depth exploration of MV-Adapter would analyze its core functionality as a plug-and-play adapter enhancing existing text-to-image models for multi-view image generation. Key design elements, including the decoupled attention mechanism (duplicated self-attention layers for efficient 3D knowledge modeling) and the unified condition encoder (integrating camera and geometric information seamlessly), would be thoroughly examined. The analysis should assess the adapter’s adaptability across various base models and its versatility in handling different guidance modalities (text, image, camera, geometry). A critical component of the deep dive would be evaluating its efficiency relative to alternative full model fine-tuning approaches, highlighting its memory and computational advantages. Finally, the analysis would explore its limitations, such as dependence on the quality of the base model, and discuss potential future extensions, including applications in dynamic multi-view video generation and 3D scene generation.
Multi-view Consistency#
The concept of ‘Multi-view Consistency’ in the context of image generation focuses on the challenge of creating multiple views of a 3D object or scene that are internally consistent. Simply generating several images individually is insufficient; the views must realistically reflect the same underlying 3D structure. This requires addressing issues like perspective distortion, occlusion, and lighting variations across viewpoints. Achieving multi-view consistency is crucial for realistic 3D scene reconstruction and applications requiring coherent views from multiple camera angles. Methods to achieve this often leverage 3D geometric knowledge either implicitly by training on 3D datasets or explicitly by incorporating camera parameters and geometry into the generation process. Efficiency is a significant challenge, as processing multiple views simultaneously can be computationally demanding, especially with high-resolution images. Therefore, approaches that minimize computational cost while maintaining consistency are highly valued. Adapter-based methods, as discussed in the paper, offer a promising direction by modifying pre-trained models with minimal changes, preserving their efficiency while adding multi-view capabilities.
Adapter Architecture#
The core of the proposed MV-Adapter lies in its innovative adapter architecture. Instead of modifying the pre-trained model directly, a plug-and-play adapter is designed that enhances existing text-to-image (T2I) models, enabling multi-view consistent image generation. This approach is crucial because it avoids the computational cost and potential degradation associated with directly fine-tuning large T2I models. The adapter architecture cleverly incorporates decoupled attention layers, including multi-view attention and optional image cross-attention, working in parallel to preserve the original network structure and feature space. This parallel design ensures that new layers inherit the benefits of pre-trained layers while simultaneously modeling 3D geometric information. A unified condition guider further improves the flexibility of the adapter by integrating camera or geometry information, facilitating diverse applications like image-based 3D generation and texturing. The overall design prioritizes efficiency and adaptability, allowing the adapter to be easily integrated with various T2I models and their derivatives without extensive retraining. This intelligent combination of parallel processing, decoupled attention, and unified conditioning makes the MV-Adapter a highly efficient and versatile solution for multi-view image generation.
Ablation & Efficiency#
An ablation study in a research paper investigating efficiency typically involves systematically removing or altering components of a model or system to assess their individual contributions. In the context of a multi-view image generation model, this might entail removing specific attention mechanisms, comparing different encoder designs, or varying the number of trainable parameters. The goal is to quantify the impact of each component on both the model’s performance (e.g., image quality, consistency across views) and its efficiency (e.g., training time, computational cost). A well-designed ablation study can provide strong evidence for the efficacy of particular design choices and uncover crucial trade-offs between performance and efficiency. For example, it might reveal that a particular attention mechanism, while contributing to improved image quality, is computationally expensive and thus could be replaced by a less resource-intensive alternative with a minimal loss in overall performance. Ultimately, the ablation study should offer insights into the most effective and efficient architecture for the multi-view image generation task. It would likely analyze various aspects of efficiency, including training speed, memory consumption, and inference latency, providing a quantitative analysis alongside the qualitative assessment of generated image quality. The insights gleaned from this type of analysis would help guide future development, enabling the creation of more streamlined and computationally feasible models that maintain high performance.
Future Directions#
Future research directions stemming from this multi-view image generation work could productively explore several key areas. Extending the model’s capabilities to handle dynamic scenes and video generation would be a significant step forward, offering exciting possibilities for applications such as virtual reality and autonomous driving. This could involve leveraging temporal consistency models and adapting existing architectures for video processing. Further investigation into the limitations associated with relying on pre-trained models is also warranted. While the adapter-based approach is shown to be efficient, a deeper understanding of how it interacts with different base models is needed. Exploring alternative adapter architectures or exploring model-agnostic methods would enhance the generalizability and effectiveness of the system. Improving the efficiency of the model to handle higher-resolution images and more complex scenes is crucial for widespread adoption. This may necessitate advancements in computational techniques or exploration of more memory-efficient architectures. Lastly, the integration of additional types of conditioning information, beyond camera parameters and geometry, could unlock novel applications. Specifically, exploring the use of depth maps, semantic information, and physical properties would significantly broaden the applicability of the multi-view image generation framework.
More visual insights#
More on figures

🔼 The figure illustrates the inference pipeline of the MV-Adapter. The input consists of text, optionally an image, and camera or geometry guidance. This information is fed into a condition guider which encodes it into a suitable format. The encoded condition is then passed, along with the input features from the pre-trained T2I model’s image layers, into the MV-Adapter’s attention modules. These modules consist of attention layers for multi-view generation and optional image cross-attention layers. The final output from the MV-Adapter is then incorporated into the original pre-trained T2I model to produce the multi-view images.
read the caption
Figure 2: Inference pipeline.

🔼 The figure illustrates the architecture of MV-Adapter, a plug-and-play module designed to enhance existing text-to-image (T2I) models for multi-view image generation. It comprises two main components: a condition guider, which encodes either camera or geometry information from the input, and decoupled attention layers. These layers consist of a multi-view attention mechanism for ensuring consistency across multiple views, and optional image cross-attention for image-conditioned generation. The pre-trained U-Net is employed to extract fine-grained details from the reference image. After training, MV-Adapter can be seamlessly integrated into various T2I models (including personalized and distilled versions), enabling them to generate multi-view images while preserving their individual strengths.
read the caption
Figure 3: Overview of MV-Adapter. Our MV-Adapter consists of two components: 1) a condition guider that encodes camera or geometry condition; 2) decoupled attention layers that contain multi-view attention for learning multi-view consistency, and optional image cross-attention to support image-conditioned generation, where we use the pre-trained U-Net to encode fine-grained information of the reference image. After training, MV-Adapter can be inserted into any personalized or distilled T2I to generate multi-view images while leveraging the specific strengths of base models.

🔼 This figure compares two different architectures for incorporating new attention layers into a pre-trained text-to-image model: a serial architecture and a parallel architecture. The serial architecture adds the new layers sequentially after the pre-trained layers, potentially hindering the utilization of pre-trained knowledge. In contrast, the parallel architecture adds the new layers in parallel with the pre-trained layers, allowing the new layers to effectively leverage the existing image priors. This parallel design is more efficient and enables the model to better learn multi-view consistency and image-conditioned generation.
read the caption
Figure 4: Serial vs parallel architecture.

🔼 Figure 5 showcases the versatility of MV-Adapter by demonstrating its seamless integration with various community-developed text-to-image (T2I) models and extensions. Each row in the figure presents results obtained using a different pre-trained T2I model or a modified version incorporating additional functionalities. This illustrates how MV-Adapter adapts to various model architectures and enhances them for multi-view image generation without extensive retraining. Specific model details are available in the Appendix.
read the caption
Figure 5: Results with community models and extensions. Each sample corresponds to a distinct T2I model or extension. Information about the models can be found in the Appendix.

🔼 This table presents a quantitative comparison of different methods for camera-guided text-to-multiview image generation. It compares the performance of various models, including MVDream, SPAD, and the proposed MV-Adapter, across three metrics: Fréchet Inception Distance (FID), Inception Score (IS), and CLIP Score. Lower FID values indicate better image quality, while higher IS and CLIP scores represent better image-text alignment. The results highlight the performance of the MV-Adapter, particularly in its ability to generate high-quality, consistent multi-view images aligned with the textual input.
read the caption
Table 1: Quantitative comparison on camera-guided text-to-multiview generation.

🔼 This table presents a quantitative comparison of different methods for camera-guided image-to-multiview generation. The metrics used for comparison are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Higher PSNR and SSIM values indicate better image quality, while a lower LPIPS value suggests that the generated images are more perceptually similar to the ground truth. The table allows for a direct comparison of the performance of various methods on this specific task, showing the relative strengths and weaknesses of each approach in terms of visual fidelity and perceptual similarity.
read the caption
Table 2: Quantitative comparison on camera-guided image-to-multiview generation.

🔼 Figure 6 presents a qualitative comparison of camera-guided text-to-multiview image generation results. It shows the outputs of several different methods, highlighting the improved visual fidelity and alignment between generated images and the input text achieved by the MV-Adapter. The figure showcases that MV-Adapter produces more visually realistic and consistent images, better reflecting the input prompt compared to other methods.
read the caption
Figure 6: Qualitative comparison on camera-guided text-to-multiview generation. our MV-Adapter achieves higher visual fidelity and image-text consistency.

🔼 This figure presents a qualitative comparison of multi-view image generation results using different methods. It shows input images and the outputs generated by various approaches, including ImageDream, Zero123++, CRM, SV3D, Ouroboros3D, Era3D, and the authors’ proposed MV-Adapter (at two resolutions). The goal is to visually demonstrate the performance of MV-Adapter in comparison with other state-of-the-art methods in terms of image quality and consistency across multiple views.
read the caption
Figure 7: Qualitative comparison on camera-guided image-to-multiview generation.

🔼 This figure showcases the versatility of the MV-Adapter by demonstrating its ability to generate multi-view consistent images when integrated with various community-developed text-to-image models. Each row displays a different pre-trained model (indicated by name in the image) and showcases the consistent generation of multiple views from a single textual description. The results highlight how MV-Adapter can adapt to diverse model styles while maintaining the quality and consistency across views.
read the caption
Figure 8: Results of geometry-guided text-to-multiview generation with community models.

🔼 This table presents a quantitative comparison of different methods for 3D texture generation. The comparison uses the Fréchet Inception Distance (FID) and Kernel Inception Distance (KID) metrics, calculated from multi-view renderings of the generated textures. Lower FID and KID scores indicate better texture quality. The table also shows the inference time for each method, highlighting the speed improvements achieved by the proposed method.
read the caption
Table 3: Quantitative comparison on 3D texture generation. FID and KID (×10−4absentsuperscript104\times 10^{-4}× 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT) are evaluated on multi-view renderings. Our models achieves best texture quality with faster inference.

🔼 This table compares the training costs of MV-Adapter with other full-tuning methods for multi-view image generation. It shows a significant reduction in training time and memory usage achieved by MV-Adapter compared to training the full model. This highlights the efficiency of MV-Adapter’s plug-and-play adapter mechanism, which requires only a small number of parameters to be updated. The table lists the number of trainable parameters, memory usage, and training speed (iterations per second) for each method, allowing for a direct comparison of resource requirements.
read the caption
Table 4: Comparison of training costs with full-tuning methods (batch size set to 1).

🔼 This table presents a quantitative analysis of different attention architectures used in the MV-Adapter model. It compares the performance of a serial architecture, where attention layers are sequentially connected, against a parallel architecture, which processes attention layers in parallel. The metrics used for comparison likely include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results showcase the benefits of the parallel architecture in terms of image quality and consistency.
read the caption
Table 5: Quantitative ablation studies on attention architecture.

🔼 This ablation study compares the performance of MV-Adapter using a serial attention architecture versus a parallel attention architecture. The serial architecture connects new multi-view and image cross-attention layers sequentially after the original spatial self-attention layers. The parallel architecture adds these new layers in parallel with the original spatial self-attention layers. The results visually demonstrate the improved performance and reduced artifacts when using the parallel architecture, highlighting its effectiveness in leveraging pre-trained weights and preventing information loss during training.
read the caption
Figure 9: Qualitative ablation study on the adaptability of MV-Adapter.

🔼 Figure 10 presents a qualitative comparison of texture generation results using different methods. It showcases the visual outputs of various techniques, including text-conditioned and image-conditioned approaches. This comparison helps evaluate the performance of different approaches, such as MV-Adapter in comparison with baseline methods like TEXTure, Text2Tex, Paint3D, SyncMVD, and FlashTex. The figure highlights the differences in texture quality, detail, and consistency achieved by each method, providing insights into their respective strengths and weaknesses.
read the caption
Figure 10: Qualitative comparison on texture generation. We compare our text- and image-conditioned models with baseline methods.

🔼 This ablation study compares the performance of MV-Adapter using two different attention architectures: a serial architecture and a parallel architecture. The serial architecture connects the original spatial self-attention layers and the newly added multi-view attention and image cross-attention layers sequentially. In contrast, the parallel architecture connects these layers in parallel. The images illustrate the results of both architectures on an image-to-multiview generation task. The parallel architecture is shown to produce higher quality and more consistent results compared to the serial architecture, which demonstrates the importance of the parallel design for effective multi-view image generation.
read the caption
Figure 11: Qualitative ablation study on the attention architecture.

🔼 This table presents a quantitative comparison of 3D reconstruction results obtained using different methods. It compares the performance of Era3D and two versions of the proposed MV-Adapter (trained on Stable Diffusion 2.1 and Stable Diffusion XL respectively) in terms of Chamfer distance and volume Intersection over Union (IoU). Lower Chamfer distance indicates better accuracy in 3D reconstruction, and higher IoU suggests a better alignment between the reconstructed model and the ground truth.
read the caption
Table 6: Quantitative comparison on 3D reconstruction.

🔼 This figure shows the results of applying a multi-view LoRA (Low-Rank Adaptation) to a text-to-image diffusion model. The LoRA was specifically trained to modify only the attention layers within the model, targeting multi-view consistency. Six different views of the generated image are presented, each taken from a different azimuth angle (0°, 45°, 90°, 180°, 270°, 315°). These angles represent views from the front, front-left, left side, back, right side, and front-right of the subject, respectively. This visualization demonstrates the model’s ability to generate consistent and coherent multi-view representations of the object based on a textual input.
read the caption
Figure 12: Results of multi-view LoRA (set target modules to attention layers). The azimuth angles of the images from left to right are 0∘,45∘,90∘,180∘,270∘,315∘superscript0superscript45superscript90superscript180superscript270superscript3150^{\circ},45^{\circ},90^{\circ},180^{\circ},270^{\circ},315^{\circ}0 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 45 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 90 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 180 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 270 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 315 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT, corresponding to the front, front-left, left, back, right, and front-right of the object.

🔼 This figure shows the results of applying a multi-view LoRA (Low-Rank Adaptation) to a pre-trained text-to-image model. The LoRA was trained to modify the attention and convolutional layers of the base model, enabling it to generate consistent images across multiple viewpoints. Six images are shown, each representing a different camera angle around the object: 0 degrees (front), 45 degrees (front-left), 90 degrees (left), 180 degrees (back), 270 degrees (right), and 315 degrees (front-right). This demonstrates the model’s ability to generate a consistent representation of the object from various perspectives.
read the caption
Figure 13: Results of multi-view LoRA (set target modules to attention layers, convolutional layers, etc.). The azimuth angles of the images from left to right are 0∘,45∘,90∘,180∘,270∘,315∘superscript0superscript45superscript90superscript180superscript270superscript3150^{\circ},45^{\circ},90^{\circ},180^{\circ},270^{\circ},315^{\circ}0 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 45 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 90 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 180 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 270 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 315 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT, corresponding to the front, front-left, left, back, right, and front-right of the object.

🔼 This figure showcases the results of using the MV-Adapter on a Stable Diffusion model. It demonstrates the model’s ability to generate multiple consistent views of an object from different angles. Each row represents a different object and base model. The six images in each row show the object viewed from six different viewpoints: front, front-left, left, back, right, and front-right, clearly illustrating the model’s ability to maintain consistency across varying perspectives. The MV-Adapter’s approach, using decoupled attention layers instead of LoRA, allows for superior performance and adaptability.
read the caption
Figure 14: Results of MV-Adapter, which introduces decoupled attention mechanism rather than LoRA. The azimuth angles of the images from left to right are 0∘,45∘,90∘,180∘,270∘,315∘superscript0superscript45superscript90superscript180superscript270superscript3150^{\circ},45^{\circ},90^{\circ},180^{\circ},270^{\circ},315^{\circ}0 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 45 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 90 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 180 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 270 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT , 315 start_POSTSUPERSCRIPT ∘ end_POSTSUPERSCRIPT, corresponding to the front, front-left, left, back, right, and front-right of the object.

🔼 This figure showcases the results of camera-guided image-to-multiview generation using low-resolution input images. It demonstrates the model’s ability to generate high-quality, multi-view consistent images even when starting with lower resolution input. This highlights the model’s robustness and its potential for applications where high-resolution images might not be readily available.
read the caption
Figure 15: Results on camera-guided image-to-multiview generation with low-resolution images as input.

🔼 This figure visualizes the results of using MV-Adapter to generate images from arbitrary viewpoints. The model was trained to produce eight anchor views, and new views are generated by clustering viewpoints and using the four nearest anchor views as input. The visualizations show the consistent generation of various views of the same subject, demonstrating the model’s ability to generate images from any angle.
read the caption
Figure 16: Visualization results using MV-Adapter to generate arbitrary viewpoints.

🔼 This figure shows a qualitative comparison of the results produced by the MV-Adapter model when using two different base models: Stable Diffusion 2.1 (SD2.1) and Stable Diffusion XL (SDXL). It visually demonstrates the impact of the base model’s quality on the final multi-view image generation. The images illustrate that a higher-quality base model (SDXL) leads to superior results in terms of detail and overall image quality when compared to a lower-quality model (SD2.1).
read the caption
Figure 17: Qualitative comparison of our MV-Adapter based on SD2.1 and SDXL.

🔼 This figure presents the results of a user study comparing MV-Adapter’s image-to-multiview generation capabilities against several baseline methods. Participants were shown pairs of multi-view images and asked to select their preferred image based on two criteria: image quality and multi-view consistency. The bar chart visually represents the percentage of times each method was chosen as preferred for each criterion. The results highlight MV-Adapter’s superior performance in terms of image quality, while demonstrating comparable performance to the leading baseline method in terms of multi-view consistency. This suggests MV-Adapter successfully balances high-quality image generation with the preservation of multi-view consistency.
read the caption
Figure 18: Results of user study on image-to-multi-view generation.

🔼 This figure displays various multi-view image generation results obtained by integrating the MV-Adapter with different community-developed text-to-image models. Each row showcases a different base model, demonstrating the versatility of the MV-Adapter in adapting to various artistic styles and levels of realism. The images depict a range of subjects and styles, highlighting the adaptability of the approach across different model architectures and input modalities. Note that the MV-Adapter is a plug-and-play adapter, meaning it doesn’t require extensive retraining of the base models.
read the caption
Figure 19: Additional results on camera-guided text-to-multiview generation with community models.
Full paper#