↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current large language models (LLMs) struggle with multilingual tasks, especially for low-resource languages. This limitation stems from the scarcity of training data and the inherent difficulty of balancing multiple languages during model training. This research introduces a novel approach to overcome these issues.
The researchers developed Marco-LLM, a multilingual LLM, using a two-stage continual pre-training strategy and a massive multilingual dataset. This method significantly improved performance on various multilingual benchmarks, showcasing substantial enhancements in any-to-any machine translation tasks. The study demonstrates the effectiveness of their multilingual training strategy in improving LLM performance across various languages, including those with limited resources.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multilingual NLP due to its novel approach of using massive multilingual continual pre-training to address the challenges of low-resource languages. It presents a significant advancement in the field by creating a multilingual LLM that outperforms existing models. Researchers can use this work as a stepping stone to create efficient and scalable multilingual LLMs, leading to breakthroughs in cross-lingual understanding and machine translation. Moreover, it provides valuable insights into continual pre-training strategies and data optimization for low-resource language, creating avenues for future research.
Visual Insights#

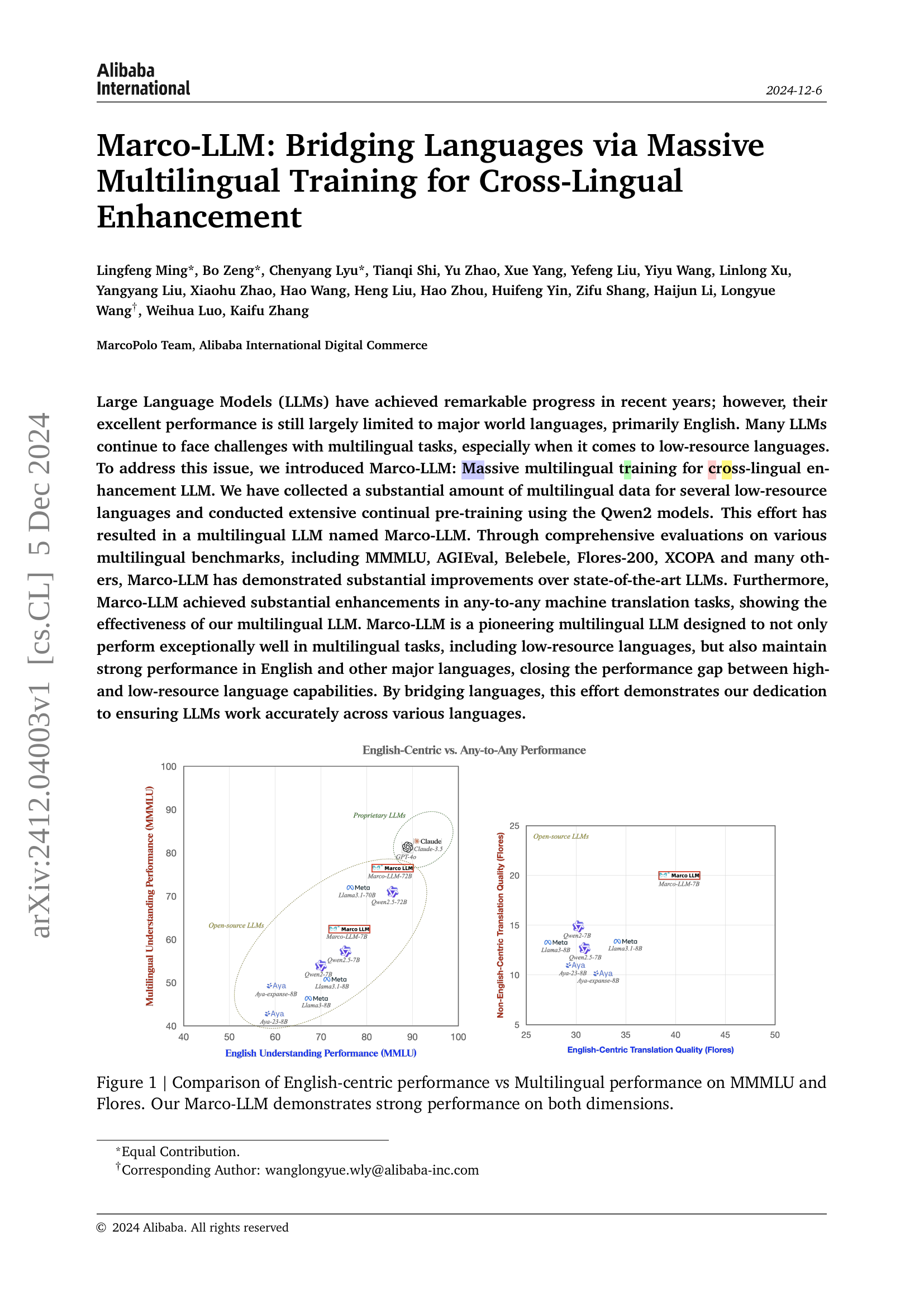
🔼 This figure compares the performance of Marco-LLM and other LLMs on two benchmark datasets: MMMLU and Flores. MMMLU assesses multilingual understanding capabilities across various subjects, while Flores evaluates any-to-any machine translation quality. The x-axis represents English-centric performance (e.g., English understanding or English-to-other language translation), and the y-axis shows multilingual performance. Each point represents an LLM. The plot shows that Marco-LLM achieves high performance on both English-centric and multilingual tasks, significantly outperforming other LLMs, especially in multilingual performance, closing the gap between high- and low-resource language capabilities. This demonstrates the success of Marco-LLM’s massive multilingual training approach.
read the caption
Figure 1: Comparison of English-centric performance vs Multilingual performance on MMMLU and Flores. Our Marco-LLM demonstrates strong performance on both dimensions.
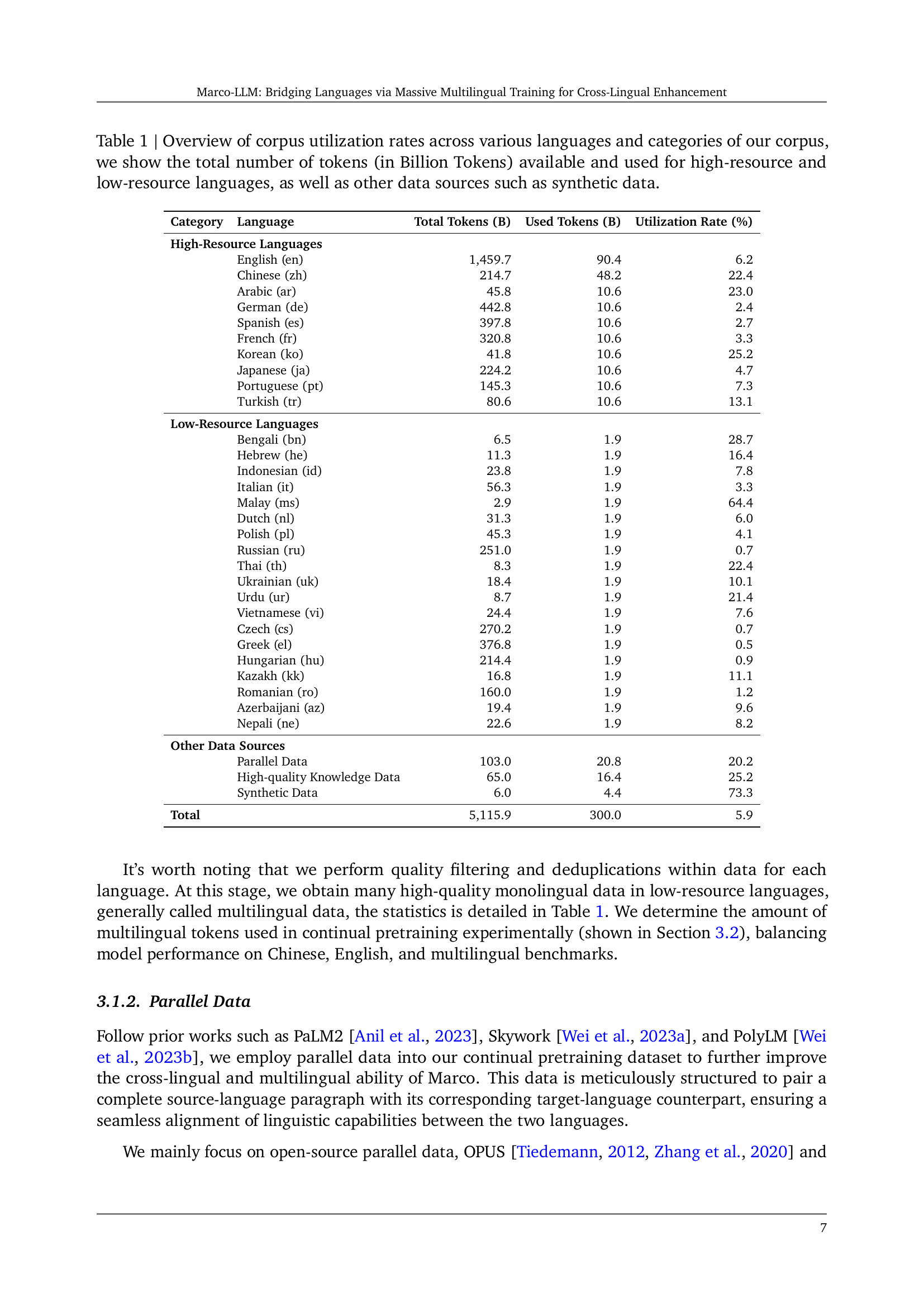
| Category | Language | Total Tokens (B) | Used Tokens (B) | Utilization Rate (%) |
|---|---|---|---|---|
| High-Resource Languages | ||||
| English (en) | 1,459.7 | 90.4 | 6.2 | |
| Chinese (zh) | 214.7 | 48.2 | 22.4 | |
| Arabic (ar) | 45.8 | 10.6 | 23.0 | |
| German (de) | 442.8 | 10.6 | 2.4 | |
| Spanish (es) | 397.8 | 10.6 | 2.7 | |
| French (fr) | 320.8 | 10.6 | 3.3 | |
| Korean (ko) | 41.8 | 10.6 | 25.2 | |
| Japanese (ja) | 224.2 | 10.6 | 4.7 | |
| Portuguese (pt) | 145.3 | 10.6 | 7.3 | |
| Turkish (tr) | 80.6 | 10.6 | 13.1 | |
| Low-Resource Languages | ||||
| Bengali (bn) | 6.5 | 1.9 | 28.7 | |
| Hebrew (he) | 11.3 | 1.9 | 16.4 | |
| Indonesian (id) | 23.8 | 1.9 | 7.8 | |
| Italian (it) | 56.3 | 1.9 | 3.3 | |
| Malay (ms) | 2.9 | 1.9 | 64.4 | |
| Dutch (nl) | 31.3 | 1.9 | 6.0 | |
| Polish (pl) | 45.3 | 1.9 | 4.1 | |
| Russian (ru) | 251.0 | 1.9 | 0.7 | |
| Thai (th) | 8.3 | 1.9 | 22.4 | |
| Ukrainian (uk) | 18.4 | 1.9 | 10.1 | |
| Urdu (ur) | 8.7 | 1.9 | 21.4 | |
| Vietnamese (vi) | 24.4 | 1.9 | 7.6 | |
| Czech (cs) | 270.2 | 1.9 | 0.7 | |
| Greek (el) | 376.8 | 1.9 | 0.5 | |
| Hungarian (hu) | 214.4 | 1.9 | 0.9 | |
| Kazakh (kk) | 16.8 | 1.9 | 11.1 | |
| Romanian (ro) | 160.0 | 1.9 | 1.2 | |
| Azerbaijani (az) | 19.4 | 1.9 | 9.6 | |
| Nepali (ne) | 22.6 | 1.9 | 8.2 | |
| Other Data Sources | ||||
| Parallel Data | 103.0 | 20.8 | 20.2 | |
| High-quality Knowledge Data | 65.0 | 16.4 | 25.2 | |
| Synthetic Data | 6.0 | 4.4 | 73.3 | |
| Total | 5,115.9 | 300.0 | 5.9 |
🔼 Table 1 provides a detailed breakdown of the data used to train the Marco-LLM model. It shows the total number of tokens (in billions) available and utilized for both high-resource and low-resource languages, as well as other data sources such as synthetic and parallel data. The table also indicates the utilization rate (percentage) for each language and category, offering insights into the balance of data representation within the training dataset.
read the caption
Table 1: Overview of corpus utilization rates across various languages and categories of our corpus, we show the total number of tokens (in Billion Tokens) available and used for high-resource and low-resource languages, as well as other data sources such as synthetic data.
In-depth insights#
Multilingual LLM#
Multilingual LLMs represent a significant advancement in natural language processing, aiming to bridge the performance gap between high and low-resource languages. Their development is challenging due to data scarcity and linguistic diversity. Effective multilingual LLMs require massive multilingual datasets, carefully curated and processed to ensure high quality. Continual pre-training, incorporating both high and low-resource languages, is crucial for achieving robust performance across various tasks. Successful models demonstrate substantial improvements on multilingual benchmarks. Addressing bias and achieving preference alignment across different languages is also vital for creating fair and reliable systems. Future work should focus on expanding language coverage, improving efficiency, and addressing remaining challenges in low-resource scenarios.
Continual Pretraining#
Continual pretraining, as discussed in the research paper, is a crucial technique for enhancing the capabilities of large language models (LLMs), particularly in multilingual contexts. The core idea is to incrementally train the model on new data without forgetting previously learned information. This approach addresses the limitations of traditional pretraining methods, which often involve training a model from scratch on a massive dataset. The paper highlights several advantages. First, it is more efficient as it avoids the computational cost of retraining the entire model. Second, it allows for continuous improvement by incorporating new data and adapting to evolving language trends. Third, it enables a more effective way to handle low-resource languages, which typically lack extensive training data. By continuously incorporating data from low-resource languages, continual pretraining helps bridge the performance gap between high- and low-resource language tasks. This process is further enhanced by sophisticated strategies such as data mixing, which carefully balances the input from various languages to avoid catastrophic forgetting. The paper demonstrates that continual pretraining with a focus on multilingual data substantially improves the LLM’s ability to perform well on cross-lingual and multilingual benchmarks. It also leads to significant gains in machine translation.
Parallel Data Impact#
The impact of parallel data in multilingual language model training is multifaceted. High-quality parallel data significantly enhances cross-lingual understanding and machine translation, improving performance in low-resource languages. However, the inclusion of low-quality parallel data can hinder performance, especially in larger models. This suggests a sensitivity to data quality that’s more pronounced in larger models due to increased parameter redundancy. The optimal utilization of parallel data requires careful filtering and preprocessing to maximize its benefits. Balancing parallel data with monolingual data is also crucial, avoiding conflicts that can occur due to data inconsistency and impacting performance in various languages. Furthermore, the impact of parallel data may also interact with learning rate, leading to trade-offs in model adaptation and forgetting. Therefore, a comprehensive approach to parallel data management, which includes rigorous quality control, careful selection and optimization strategies, is essential for robust multilingual model development.
Post-training Methods#
Post-training methods for large language models (LLMs) are crucial for enhancing their performance and addressing limitations like bias and low-resource language support. These techniques refine a pre-trained model, typically focusing on specific downstream tasks. Supervised fine-tuning (SFT) involves training the model on a labeled dataset of input-output pairs, aligning its behavior with desired outputs for particular tasks. Direct preference optimization (DPO), another key strategy, prioritizes aligning the LLM’s preferences with human evaluations instead of direct output matching. Reinforcement learning from human feedback (RLHF) is used to further refine model behavior by using human feedback as a reward signal, iteratively improving its responses. Effective post-training often involves combining different methods to leverage their individual strengths, resulting in more robust and capable models. The choice of post-training methods depends on the specific application, the nature of the pre-trained model, and the availability of high-quality labeled data.
Future Research#
The paper’s ‘Future Research’ section would benefit from exploring several key areas. Expanding Marco-LLM’s multilingual capabilities to encompass a broader range of languages is crucial, especially focusing on those with limited resources. This requires expanding data collection efforts. Furthermore, research into improving the model’s efficiency and scalability is needed for wider deployment, particularly in resource-constrained settings. Investigating multilingual reasoning capabilities within the model would enhance its understanding of complex linguistic structures. Finally, addressing the performance gap between high and low-resource languages, particularly the persistent gap observed in training, requires further investigation into optimal training methodologies. This may involve exploring alternative training data or techniques to better bridge the resource gap and improve performance across the board.
More visual insights#
More on figures

🔼 This figure illustrates the training and evaluation process for the Marco-LLM model. It highlights the three main stages: 1) Massive Multilingual Continual Pre-training, which involves using a large multilingual dataset for initial model training; 2) Multilingual Supervised Fine-tuning, where the model is further trained using high-quality multilingual data focusing on specific tasks; and 3) Preference Alignment, which ensures the model’s output aligns with human preferences. The figure concludes by indicating extensive evaluation on multilingual benchmarks to validate Marco-LLM’s effectiveness.
read the caption
Figure 2: An overview of the training and evaluation paradigm of our Marco-LLM, we conducted massive multilingual continual pre-training, multilingual supervised finetuning and preference alignment. We further perform extensive evaluation on multilingual benchmarks to validate the efficacy of our Marco-LLM.

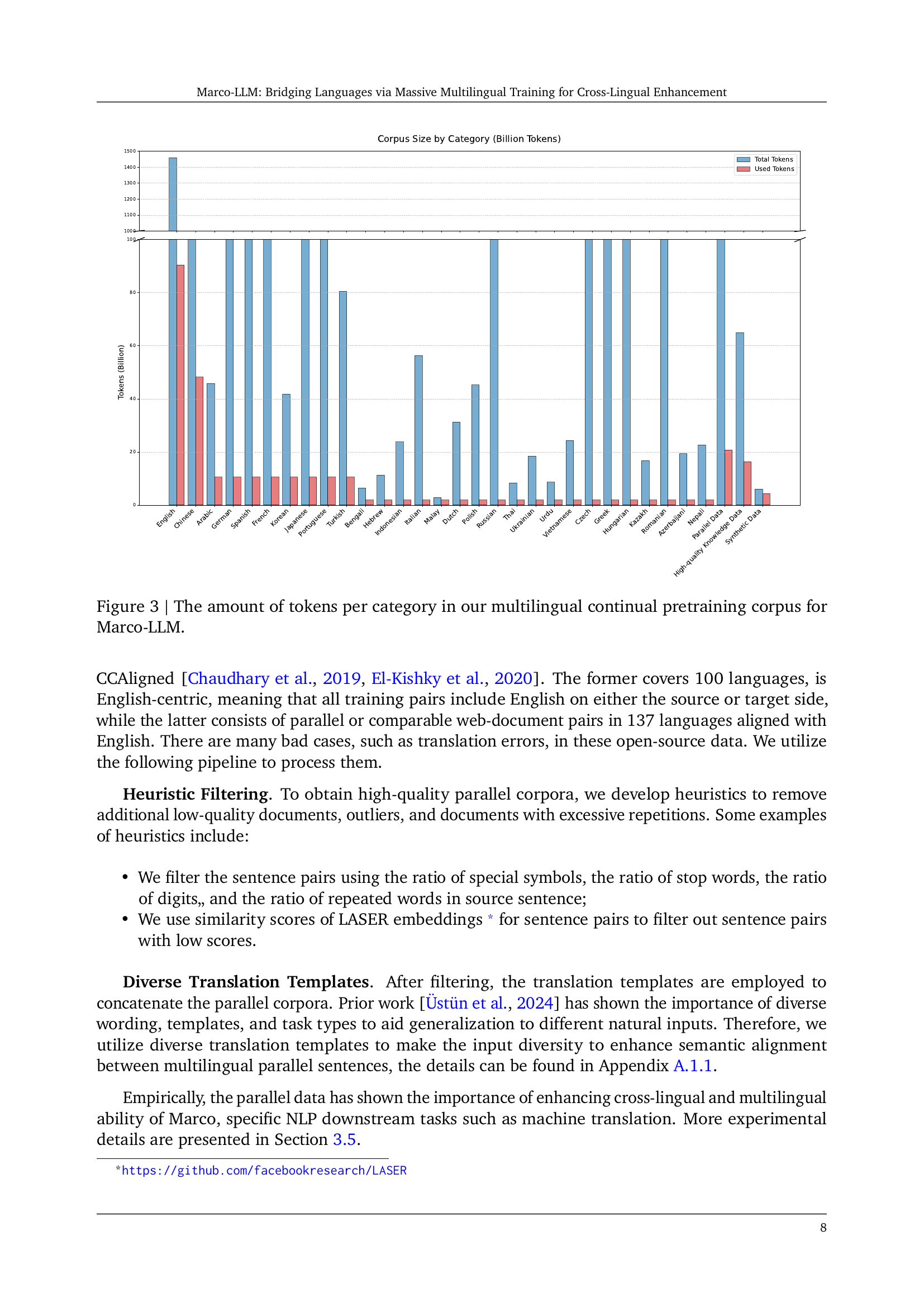
🔼 This figure shows the distribution of the training data used for Marco-LLM, categorized by language (high-resource vs. low-resource), data type (parallel data, high-quality knowledge data, synthetic data), and the overall volume in billions of tokens. The visualization allows for easy comparison of the amount of data used for various languages and data sources, giving insight into the balance of data in the Marco-LLM’s training regimen. High-resource languages have much more data compared to the low-resource languages.
read the caption
Figure 3: The amount of tokens per category in our multilingual continual pretraining corpus for Marco-LLM.

🔼 This figure displays the results of an ablation study on the impact of parallel data filtering in the continual pre-training of the Marco-LLM model. Three different sizes of the Marco-LLM were evaluated on the Flores benchmark: 1.5B, 7B, and 72B parameters. The ‘Marco-w/o-parallel-data-filtering’ condition represents the results obtained when the model was trained without filtering noisy data from the parallel corpus, while the ‘Marco’ condition represents the results obtained with parallel data filtering. This comparison helps to assess the effect of data quality on the model’s performance in machine translation across different model scales.
read the caption
Figure 7: The performance of different model size on Flores benchmark. Marco-w/o-parallel-data-filtering denotes that we continuously pre-trained Marco-LLM based on Qwen2 without applying any filtering to parallel data.

🔼 This figure displays the accuracy trends across various training checkpoints for different languages when evaluated using the MMMLU benchmark. The x-axis represents the training steps, and the y-axis shows the accuracy. Multiple lines are plotted, each representing a different language. The figure demonstrates that the model exhibits rapid initial learning in the first 230 steps, followed by a period of performance stabilization. Importantly, it highlights a consistent performance gap between high-resource languages (like Chinese and Italian) and low-resource languages (like Yoruba). This gap remains approximately 29% throughout the training process. This observation underscores the challenge of achieving balanced performance across diverse language resources in multilingual language models.
read the caption
Figure 9: Accuracy trends across training checkpoints for different languages on MMMLU. The model shows rapid initial learning (0-230 steps) followed by performance stabilization. High-resource languages (ZH-CN, IT-IT) consistently outperform low-resource ones (YO-NG), with a persistent performance gap of 29%.

🔼 Figure 10 presents a comprehensive comparison of Marco-LLM’s performance against six other state-of-the-art multilingual language models across 28 different languages. The evaluation metric used is multilingual MT-bench, a benchmark designed to assess the quality of machine-translated text in diverse languages. For each language, a bar chart displays the win rate (blue), indicating instances where Marco-LLM produced superior translations; the loss rate (green), showing cases where the other baselines surpassed Marco-LLM; and the tie rate (red), representing instances of comparable translation quality between Marco-LLM and each of the other models. This figure provides a detailed visualization of Marco-LLM’s cross-lingual capabilities, highlighting its strengths and weaknesses across various languages, which enables a better understanding of its performance in multilingual translation.
read the caption
Figure 10: Performance comparison of Marco-LLM against baseline models across 28 languages on multilingual MT-bench. Each subplot shows the win rate (blue), loss rate (green), and tie rate (red) for a specific language. Win rates indicate Marco-LLM’s superior responses, loss rates represent baseline models’ better performance, and tie rates show equivalent quality responses.
More on tables
| Data | Stage-I | Stage-II |
|---|---|---|
| English (en) | 32% | 28% |
| Chinese (zh) | 17% | 15% |
| High-Resourced (Others) | 30% | 26% |
| Low-Resourced | 9% | 15% |
| Parallel Multilingual Data | 6% | 8% |
| High-quality Knowledge Data | 5% | 6% |
| Synthetic Data | 1% | 2% |
🔼 This table shows the proportion of different data sources used in each stage of the two-stage continual pretraining. It breaks down the percentage of English, Chinese, other high-resource languages, low-resource languages, parallel multilingual data, high-quality knowledge data, and synthetic data used in both Stage I and Stage II of the training process. This breakdown is crucial to understanding the strategy behind balancing the adaptation to new data with the preservation of knowledge learned in earlier stages.
read the caption
Table 2: The proportion of high-quality and multilingual sources.
| Stage | Training Tokens (B) | LR |
|---|---|---|
| Stage-I | 160 | 1e-5 |
| Stage-II | 140 | 6e-6 |
🔼 This table details the hyperparameters used during the two-stage continual pre-training process for the Marco-LLM model. It shows the amount of training tokens used in each stage (Stage-I and Stage-II) and the corresponding learning rate applied. The two-stage approach helps to balance the adaptation of multilingual capabilities and prevent catastrophic forgetting.
read the caption
Table 3: The training corpus tokens and learning rate in two Stage Continual Pretraining.
| Task | Dataset | Split | Metric | #Languages | #-shots |
|---|---|---|---|---|---|
| General | CEVAL | Val | Acc. | One | 5-shot |
| Knowledge | AGIEval | Test | Acc. | One | 5-shot |
| ARC | Test | Acc. | One | 25-shot | |
| MMLU | Test | Acc. | One | 5-shot | |
| Multilingual | XCOPA | Val | Acc. | Six | 5-shot |
| Understanding | X-MMLU | Val | Acc. | Thirteen | 5-shot |
| XStoryCloze | Val | Acc. | Six | 5-shot | |
| Question Answering | TyDiQA | Val | F1 | Six | 1-shot |
| Belebele | Test | Acc. | Twenty-Eight | 1-shot | |
| Machine Translation | Flores | Devtest | BLEU | Twenty-Eight | 1-shot |
| WMT-16 | Test | BLEU | Three | 1-shot |
🔼 This table presents a comprehensive evaluation of the Marco-LLM model across various natural language processing tasks. It includes benchmarks from four categories: general knowledge, multilingual understanding, question answering, and machine translation. Each benchmark is evaluated using metrics appropriate to the specific task, such as accuracy, F1 score, or BLEU. The table shows the number of languages included in each benchmark and the evaluation setting (e.g., 1-shot, 5-shot), providing a complete overview of the model’s performance across multiple languages and tasks.
read the caption
Table 4: Evaluation benchmarks overview. The table presents the comprehensive evaluation suite used in our experiments, spanning four major task categories: general knowledge, multilingual understanding, question answering, and machine translation. Each dataset is evaluated using either accuracy (Acc.), F1 score, or BLEU metric, covering a diverse range of languages from single-language (en, zh) to multilingual scenarios.
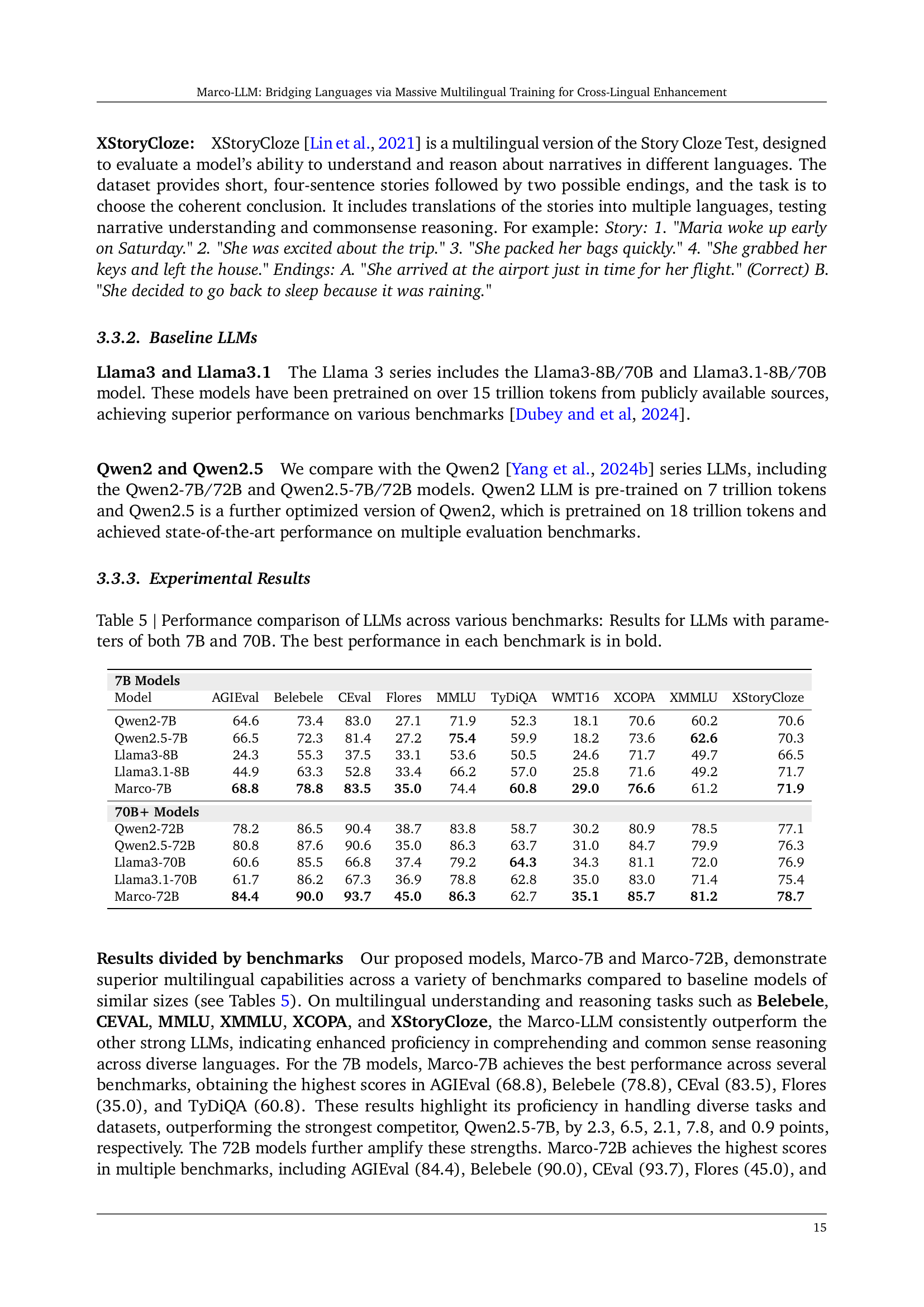
| Model | AGIEval | Belebele | CEval | Flores | MMLU | TyDiQA | WMT16 | XCOPA | XMMLU | XStoryCloze |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2-7B | 64.6 | 73.4 | 83.0 | 27.1 | 71.9 | 52.3 | 18.1 | 70.6 | 60.2 | 70.6 |
| Qwen2.5-7B | 66.5 | 72.3 | 81.4 | 27.2 | 75.4 | 59.9 | 18.2 | 73.6 | 62.6 | 70.3 |
| Llama3-8B | 24.3 | 55.3 | 37.5 | 33.1 | 53.6 | 50.5 | 24.6 | 71.7 | 49.7 | 66.5 |
| Llama3.1-8B | 44.9 | 63.3 | 52.8 | 33.4 | 66.2 | 57.0 | 25.8 | 71.6 | 49.2 | 71.7 |
| Marco-7B | 68.8 | 78.8 | 83.5 | 35.0 | 74.4 | 60.8 | 29.0 | 76.6 | 61.2 | 71.9 |
| 70B+ Models | ||||||||||
| Qwen2-72B | 78.2 | 86.5 | 90.4 | 38.7 | 83.8 | 58.7 | 30.2 | 80.9 | 78.5 | 77.1 |
| Qwen2.5-72B | 80.8 | 87.6 | 90.6 | 35.0 | 86.3 | 63.7 | 31.0 | 84.7 | 79.9 | 76.3 |
| Llama3-70B | 60.6 | 85.5 | 66.8 | 37.4 | 79.2 | 64.3 | 34.3 | 81.1 | 72.0 | 76.9 |
| Llama3.1-70B | 61.7 | 86.2 | 67.3 | 36.9 | 78.8 | 62.8 | 35.0 | 83.0 | 71.4 | 75.4 |
| Marco-72B | 84.4 | 90.0 | 93.7 | 45.0 | 86.3 | 62.7 | 35.1 | 85.7 | 81.2 | 78.7 |
🔼 This table presents a comparison of the performance of various Large Language Models (LLMs) across multiple benchmark datasets. It shows results for LLMs with 7 billion parameters (7B) and LLMs with 70 billion parameters (70B) and compares their performance across different tasks, including general knowledge, multilingual understanding, question answering, and machine translation. The best performance for each benchmark is highlighted in bold, allowing for easy identification of the top-performing models in each category.
read the caption
Table 5: Performance comparison of LLMs across various benchmarks: Results for LLMs with parameters of both 7B and 70B. The best performance in each benchmark is in bold.
| Language | Llama3-8B | Llama3.1-8B | Qwen2-7B | Qwen2.5-7B | Marco-7B |
|---|---|---|---|---|---|
| Chinese (zh) | 55.1 | 63.5 | 75.8 | 75.5 | 76.0 |
| English (en) | 69.6 | 74.2 | 77.4 | 78.0 | 77.9 |
| Arabic (ar) | 40.5 | 52.6 | 61.3 | 64.5 | 66.0 |
| German (de) | 47.3 | 59.8 | 69.5 | 69.0 | 72.9 |
| Spanish (es) | 57.0 | 64.9 | 70.4 | 71.9 | 72.6 |
| French (fr) | 56.0 | 63.5 | 69.8 | 71.2 | 72.5 |
| Japanese (ja) | 63.4 | 74.9 | 76.7 | 76.4 | 77.3 |
| Korean (ko) | 43.2 | 63.8 | 76.0 | 79.7 | 78.3 |
| Portuguese (pt) | 56.8 | 64.7 | 70.7 | 72.3 | 72.3 |
| Turkish (tr) | 51.1 | 62.9 | 66.0 | 66.6 | 73.4 |
| Azerbaijani (az) | 39.1 | 48.2 | 52.2 | 53.2 | 69.4 |
| Bengali (bn) | 45.9 | 49.8 | 63.9 | 62.3 | 68.9 |
| Hebrew (he) | 50.2 | 56.6 | 69.8 | 68.6 | 77.3 |
| Indonesian (id) | 64.0 | 66.1 | 77.3 | 77.8 | 82.3 |
| Italian (it) | 68.1 | 69.4 | 80.3 | 79.4 | 83.4 |
| Polish (pl) | 62.2 | 60.7 | 77.2 | 76.3 | 80.9 |
| Malay (ms) | 56.8 | 57.7 | 73.2 | 73.9 | 80.2 |
| Dutch (nl) | 61.0 | 65.2 | 80.2 | 71.6 | 82.1 |
| Romanian (ro) | 65.6 | 67.4 | 77.3 | 72.6 | 80.8 |
| Russian (ru) | 69.2 | 70.7 | 81.2 | 77.1 | 83.2 |
| Thai (th) | 54.8 | 53.3 | 69.1 | 73.7 | 72.9 |
| Ukrainian (uk) | 60.9 | 60.4 | 72.7 | 70.4 | 79.9 |
| Urdu (ur) | 50.0 | 56.7 | 63.9 | 59.9 | 71.3 |
| Vietnamese (vi) | 67.6 | 70.3 | 76.1 | 79.0 | 81.2 |
| Czech (cs) | 59.2 | 63.6 | 76.9 | 70.0 | 78.2 |
| Greek (el) | 68.1 | 67.7 | 65.0 | 67.2 | 77.1 |
| Hungarian (hu) | 59.8 | 61.0 | 63.3 | 57.9 | 69.7 |
| Kazakh (kk) | 41.3 | 44.0 | 43.1 | 45.9 | 66.1 |
| Nepali (ne) | 37.0 | 41.56 | 36.33 | 42.1 | 65.8 |
| Avg. Scores | 55.9 | 61.2 | 69.4 | 69.1 | 75.5 |
🔼 This table presents a detailed comparison of the performance of five different 7B-parameter Large Language Models (LLMs) across 29 languages. The models are evaluated on a suite of multilingual benchmarks described earlier in the paper. For each language, the table shows the performance score achieved by each of the five LLMs. The highest score for each language is highlighted in bold, enabling easy identification of the best-performing model for each language.
read the caption
Table 6: Average performance on multilingual benchmarks shown in Table 4 for five 7B-parameter LLMs divided by 29 languages. The best performance for each language is highlighted in bold.
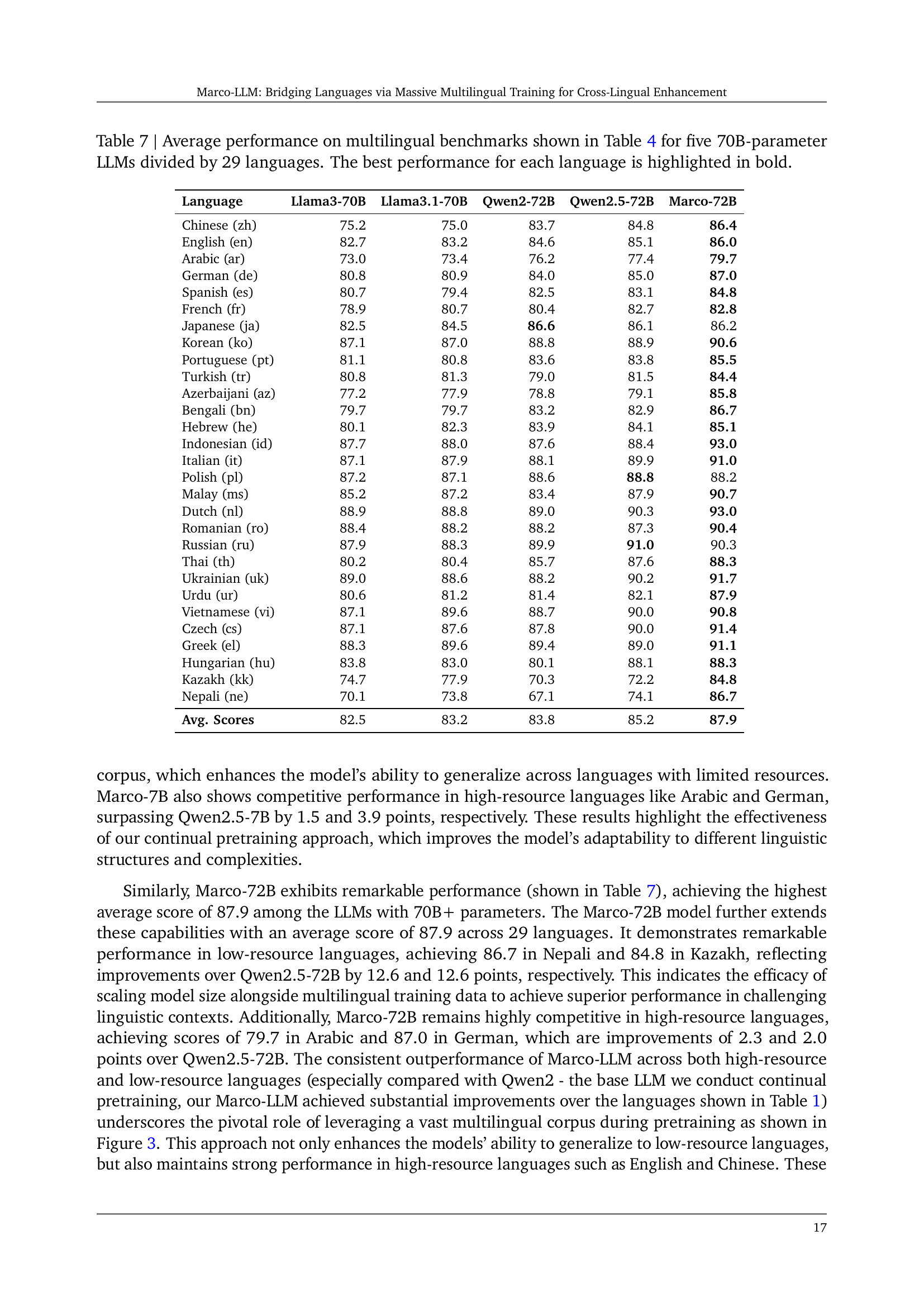
| Language | Llama3-70B | Llama3.1-70B | Qwen2-72B | Qwen2.5-72B | Marco-72B |
|---|---|---|---|---|---|
| Chinese (zh) | 75.2 | 75.0 | 83.7 | 84.8 | 86.4 |
| English (en) | 82.7 | 83.2 | 84.6 | 85.1 | 86.0 |
| Arabic (ar) | 73.0 | 73.4 | 76.2 | 77.4 | 79.7 |
| German (de) | 80.8 | 80.9 | 84.0 | 85.0 | 87.0 |
| Spanish (es) | 80.7 | 79.4 | 82.5 | 83.1 | 84.8 |
| French (fr) | 78.9 | 80.7 | 80.4 | 82.7 | 82.8 |
| Japanese (ja) | 82.5 | 84.5 | 86.6 | 86.1 | 86.2 |
| Korean (ko) | 87.1 | 87.0 | 88.8 | 88.9 | 90.6 |
| Portuguese (pt) | 81.1 | 80.8 | 83.6 | 83.8 | 85.5 |
| Turkish (tr) | 80.8 | 81.3 | 79.0 | 81.5 | 84.4 |
| Azerbaijani (az) | 77.2 | 77.9 | 78.8 | 79.1 | 85.8 |
| Bengali (bn) | 79.7 | 79.7 | 83.2 | 82.9 | 86.7 |
| Hebrew (he) | 80.1 | 82.3 | 83.9 | 84.1 | 85.1 |
| Indonesian (id) | 87.7 | 88.0 | 87.6 | 88.4 | 93.0 |
| Italian (it) | 87.1 | 87.9 | 88.1 | 89.9 | 91.0 |
| Polish (pl) | 87.2 | 87.1 | 88.6 | 88.8 | 88.2 |
| Malay (ms) | 85.2 | 87.2 | 83.4 | 87.9 | 90.7 |
| Dutch (nl) | 88.9 | 88.8 | 89.0 | 90.3 | 93.0 |
| Romanian (ro) | 88.4 | 88.2 | 88.2 | 87.3 | 90.4 |
| Russian (ru) | 87.9 | 88.3 | 89.9 | 91.0 | 90.3 |
| Thai (th) | 80.2 | 80.4 | 85.7 | 87.6 | 88.3 |
| Ukrainian (uk) | 89.0 | 88.6 | 88.2 | 90.2 | 91.7 |
| Urdu (ur) | 80.6 | 81.2 | 81.4 | 82.1 | 87.9 |
| Vietnamese (vi) | 87.1 | 89.6 | 88.7 | 90.0 | 90.8 |
| Czech (cs) | 87.1 | 87.6 | 87.8 | 90.0 | 91.4 |
| Greek (el) | 88.3 | 89.6 | 89.4 | 89.0 | 91.1 |
| Hungarian (hu) | 83.8 | 83.0 | 80.1 | 88.1 | 88.3 |
| Kazakh (kk) | 74.7 | 77.9 | 70.3 | 72.2 | 84.8 |
| Nepali (ne) | 70.1 | 73.8 | 67.1 | 74.1 | 86.7 |
| Avg. Scores | 82.5 | 83.2 | 83.8 | 85.2 | 87.9 |
🔼 This table presents a detailed comparison of the performance of five different 70B-parameter Large Language Models (LLMs) across 29 languages. The LLMs are evaluated on the multilingual benchmarks described in Table 4 of the paper. For each language, the table shows the average performance score achieved by each of the five LLMs. The highest score for each language is highlighted in bold, allowing for easy identification of the top-performing model for each language. This provides a comprehensive view of the relative strengths and weaknesses of each LLM across a range of languages, highlighting their multilingual capabilities.
read the caption
Table 7: Average performance on multilingual benchmarks shown in Table 4 for five 70B-parameter LLMs divided by 29 languages. The best performance for each language is highlighted in bold.
| Model | MMMLU | TydiQA | AGIEval | CEval | Belebele |
|---|---|---|---|---|---|
| 7B Models | |||||
| Aya-23-8B | 41.0 | 47.2 | 37.1 | 43.9 | 52.5 |
| Aya-expanse-8B | 48.2 | 28.3 | 36.7 | 48.5 | 64.3 |
| Llama3-8B | 46.6 | 39.7 | 43.4 | 50.8 | 50.7 |
| Llama3.1-8B | 49.2 | 53.0 | 41.8 | 55.6 | 63.9 |
| Qwen2-7B | 52.2 | 29.2 | 57.1 | 81.8 | 69.4 |
| Qwen2.5-7B | 56.0 | 39.0 | 59.0 | 77.9 | 70.0 |
| Marco-Chat-7B | 60.1 | 57.7 | 61.5 | 86.4 | 79.3 |
| 70B Models | |||||
| Aya-23-35B | 50.1 | 50.2 | 44.4 | 53.6 | 66.3 |
| Aya-expanse-32B | 58.9 | 30.0 | 45.7 | 56.9 | 72.7 |
| Llama3-70B | 64.3 | 52.0 | 57.1 | 66.7 | 76.2 |
| Llama3.1-70B | 71.7 | 53.1 | 55.0 | 71.6 | 84.4 |
| Qwen2-72B | 69.2 | 40.3 | 66.0 | 90.6 | 85.3 |
| Qwen2.5-72B | 69.0 | 48.4 | 67.5 | 88.2 | 88.9 |
| Marco-72B | 76.1 | 61.0 | 72.7 | 94.5 | 89.6 |
🔼 This table presents a comparative analysis of various Large Language Models (LLMs) across multiple widely used evaluation benchmarks. The benchmarks assess different aspects of LLM capabilities, such as multilingual understanding, commonsense reasoning, and knowledge. The table allows for a direct comparison of the models’ performance on each benchmark, highlighting the strengths and weaknesses of each LLM. The ‘best’ performance for each benchmark is clearly identified in bold.
read the caption
Table 8: Performance comparison of LLMs across multiple major benchmarks. Best performance in each benchmark is marked in bold.
| Language | Qwen2 | Qwen2.5 | Llama3 | Llama3.1 | Aya-23 | Aya-expanse | Marco-Chat | GPT-4 |
|---|---|---|---|---|---|---|---|---|
| 7B Models | ||||||||
| Arabic | 50.9 | 56.6 | 40.5 | 42.2 | 42.1 | 48.8 | 60.6 | 62.7 |
| Bengali | 42.6 | 45.3 | 36.4 | 39.8 | 27.4 | 33.4 | 54.4 | 60.0 |
| German | 57.3 | 62.3 | 53.5 | 55.6 | 43.3 | 53.9 | 65.9 | 68.0 |
| Spanish | 60.3 | 65.3 | 55.8 | 59.1 | 47.9 | 56.1 | 67.7 | 68.2 |
| French | 61.1 | 65.0 | 55.8 | 58.9 | 46.9 | 55.5 | 67.6 | 67.5 |
| Hindi | 44.5 | 46.6 | 41.4 | 45.8 | 38.9 | 46.2 | 54.3 | 62.2 |
| Indonesian | 56.6 | 61.4 | 51.0 | 54.3 | 46.7 | 53.3 | 62.3 | 66.1 |
| Italian | 60.2 | 64.7 | 53.3 | 56.3 | 47.1 | 55.3 | 65.4 | 68.3 |
| Japanese | 56.3 | 61.0 | 42.3 | 52.1 | 45.6 | 51.5 | 64.2 | 64.4 |
| Korean | 54.1 | 59.1 | 46.5 | 50.8 | 43.6 | 50.7 | 63.0 | 63.6 |
| Chinese | 62.0 | 64.3 | 51.4 | 55.5 | 45.7 | 52.5 | 66.5 | 65.9 |
| Portuguese | 59.9 | 64.4 | 55.5 | 59.0 | 46.9 | 55.8 | 67.6 | 68.8 |
| Swahili | 34.9 | 35.7 | 37.5 | 40.3 | 26.2 | 32.0 | 43.9 | 53.1 |
| Yoruba | 30.5 | 32.8 | 31.0 | 31.4 | 26.4 | 29.9 | 37.2 | 38.0 |
| Avg. Score | 52.2 | 56.0 | 46.6 | 50.1 | 41.0 | 48.2 | 60.1 | 62.6 |
| 70B Models | ||||||||
| Arabic | 72.0 | 74.3 | 60.6 | 71.1 | 51.8 | 61.6 | 79.3 | 71.1 |
| Bengali | 68.3 | 67.2 | 53.8 | 66.5 | 32.9 | 43.9 | 76.6 | 64.8 |
| German | 74.4 | 72.5 | 71.4 | 77.0 | 55.5 | 64.7 | 80.7 | 75.7 |
| Spanish | 77.0 | 77.5 | 74.3 | 79.3 | 58.0 | 67.5 | 82.6 | 76.8 |
| French | 75.6 | 76.0 | 73.1 | 77.9 | 58.1 | 67.5 | 80.7 | 75.8 |
| Hindi | 69.9 | 69.1 | 65.0 | 72.7 | 47.6 | 58.8 | 76.9 | 70.1 |
| Indonesian | 73.1 | 73.3 | 70.6 | 75.7 | 55.5 | 65.4 | 79.0 | 73.7 |
| Italian | 75.3 | 72.5 | 73.3 | 77.8 | 57.8 | 66.5 | 81.6 | 75.8 |
| Japanese | 74.1 | 74.7 | 65.6 | 73.8 | 54.5 | 64.3 | 81.6 | 71.6 |
| Korean | 72.3 | 71.8 | 64.5 | 72.7 | 53.7 | 62.4 | 78.8 | 71.3 |
| Chinese | 77.5 | 76.7 | 69.5 | 74.8 | 54.1 | 63.4 | 82.0 | 72.5 |
| Portuguese | 76.8 | 76.9 | 73.7 | 78.9 | 58.3 | 67.2 | 81.7 | 76.2 |
| Swahili | 47.3 | 48.8 | 51.1 | 64.0 | 33.6 | 38.4 | 63.7 | 68.1 |
| Yoruba | 34.6 | 35.5 | 33.6 | 41.2 | 30.4 | 33.4 | 44.0 | 47.3 |
| Avg. Score | 69.2 | 69.0 | 64.3 | 71.7 | 50.1 | 58.9 | 76.1 | 70.8 |
🔼 This table presents the performance comparison of various Large Language Models (LLMs) on the Massive Multitask Language Understanding (MMMLU) benchmark. It breaks down the results by language, showing the accuracy scores for models with 7 billion parameters and models with 70 billion parameters. The best performing model for each language is highlighted in bold, allowing for easy comparison of model performance across different languages and parameter sizes.
read the caption
Table 9: MMMLU Results: Performance of various LLMs across different languages in the MMMLU dataset for both 7B and 70B models. The best performance in each language is highlighted in bold.
| Language | Qwen2 | Qwen2.5 | Llama-3 | Llama3.1 | Aya-23 | Aya-expanse | Marco-Chat |
|---|---|---|---|---|---|---|---|
| 7B Models | |||||||
| Azerbaijani | 59.9 | 60.4 | 41.3 | 57.7 | 34.1 | 49.9 | 72.3 |
| Bengali | 64.9 | 64.2 | 46.8 | 57.2 | 28.7 | 41.6 | 75.1 |
| Czech | 75.4 | 75.9 | 54.3 | 73.4 | 61.6 | 76.9 | 84.4 |
| Greek | 68.7 | 75.2 | 59.0 | 74.3 | 65.2 | 80.3 | 81.4 |
| Hebrew | 74.2 | 72.7 | 45.9 | 59.3 | 61.7 | 77.9 | 82.1 |
| Hungarian | 57.3 | 63.0 | 45.1 | 52.4 | 35.0 | 44.0 | 68.0 |
| Indonesian | 77.2 | 78.4 | 61.9 | 75.0 | 64.7 | 77.6 | 82.8 |
| Italian | 78.2 | 81.9 | 60.6 | 71.8 | 67.0 | 75.7 | 86.8 |
| Japanese | 78.0 | 69.8 | 49.9 | 64.7 | 64.2 | 74.1 | 83.1 |
| Kazakh | 48.0 | 51.2 | 36.0 | 49.1 | 28.3 | 38.0 | 73.1 |
| Malay | 78.9 | 77.1 | 57.9 | 67.4 | 53.2 | 73.3 | 83.4 |
| Dutch | 58.7 | 74.6 | 56.3 | 70.1 | 66.2 | 72.1 | 85.3 |
| Nepali | 44.3 | 49.4 | 38.9 | 46.7 | 32.9 | 40.8 | 70.0 |
| Polish | 78.4 | 70.3 | 55.0 | 65.0 | 61.1 | 73.9 | 73.3 |
| Romanian | 72.4 | 74.0 | 55.2 | 68.7 | 65.9 | 74.8 | 73.2 |
| Russian | 79.7 | 73.3 | 52.7 | 70.2 | 64.1 | 74.3 | 87.9 |
| Ukrainian | 76.1 | 73.2 | 51.1 | 69.8 | 61.8 | 76.2 | 83.4 |
| Urdu | 64.9 | 64.4 | 49.0 | 59.2 | 35.6 | 50.2 | 76.2 |
| Thai | 72.3 | 74.5 | 43.0 | 57.2 | 37.6 | 41.8 | 76.9 |
| Vietnamese | 80.0 | 77.0 | 53.8 | 68.3 | 61.4 | 73.2 | 86.3 |
| Avg. Scores | 69.4 | 70.0 | 50.7 | 63.9 | 52.5 | 64.3 | 79.3 |
| 70B Models | |||||||
| Azerbaijani | 79.9 | 81.6 | 63.3 | 79.7 | 51.9 | 58.3 | 85.6 |
| Bengali | 84.9 | 87.3 | 75.3 | 81.4 | 42.1 | 64.8 | 89.2 |
| Czech | 89.7 | 91.9 | 79.0 | 86.8 | 79.6 | 85.8 | 91.8 |
| Greek | 89.2 | 92.6 | 87.0 | 89.4 | 80.1 | 83.6 | 91.9 |
| Hebrew | 85.0 | 86.9 | 75.9 | 78.9 | 77.0 | 83.1 | 86.0 |
| Hungarian | 72.8 | 89.3 | 58.0 | 74.1 | 53.6 | 50.8 | 87.0 |
| Indonesian | 88.9 | 91.7 | 82.6 | 87.3 | 77.8 | 81.1 | 93.1 |
| Italian | 89.8 | 90.4 | 83.8 | 87.9 | 81.1 | 77.7 | 91.1 |
| Japanese | 87.8 | 90.2 | 82.2 | 86.9 | 73.7 | 78.2 | 90.1 |
| Kazakh | 73.6 | 76.0 | 54.1 | 78.2 | 40.7 | 55.1 | 81.7 |
| Malay | 88.7 | 91.2 | 87.7 | 88.7 | 74.8 | 76.4 | 92.1 |
| Dutch | 90.9 | 93.2 | 80.4 | 87.1 | 80.8 | 85.7 | 94.4 |
| Nepali | 70.6 | 80.1 | 55.7 | 76.0 | 39.9 | 50.1 | 84.4 |
| Polish | 86.4 | 89.7 | 75.0 | 88.7 | 73.9 | 83.7 | 90.6 |
| Romanian | 88.4 | 92.1 | 73.4 | 86.3 | 75.7 | 77.7 | 90.6 |
| Russian | 90.0 | 94.1 | 86.1 | 87.2 | 73.2 | 84.6 | 92.7 |
| Ukrainian | 90.9 | 93.4 | 84.1 | 90.2 | 74.3 | 79.8 | 93.0 |
| Urdu | 83.1 | 86.4 | 78.9 | 90.2 | 47.2 | 63.7 | 88.2 |
| Thai | 86.2 | 87.1 | 79.7 | 82.7 | 53.6 | 63.8 | 87.6 |
| Vietnamese | 88.8 | 92.0 | 81.7 | 83.9 | 75.8 | 69.2 | 92.2 |
| Avg. Scores | 85.3 | 88.9 | 76.2 | 84.4 | 66.3 | 72.7 | 89.6 |
🔼 This table presents a comprehensive comparison of various large language models (LLMs) on the Belebele benchmark. The Belebele benchmark is specifically designed to evaluate the performance of LLMs on reading comprehension tasks across a wide variety of languages, including many low-resource languages. The table displays the performance of each model (Qwen2, Qwen2.5, Llama-3, Llama3.1, Aya-23, Aya-expanse, Marco-Chat) for both 7B and 70B parameter models across multiple languages. The performance metric used is accuracy. This allows for a direct comparison of the models’ abilities to understand and answer reading comprehension questions across different linguistic backgrounds. Results are presented separately for 7B and 70B parameter models, facilitating analysis of the impact of model size on performance across languages.
read the caption
Table 10: Performance comparison of language models on Belebele benchmark [Bandarkar et al., 2024] across different languages.
| GPT4 | DeepL | Aya-32B | Aya-35B | Qwen2-72B | Qwen2.5-72B | Llama3-70B | Llama3.1-70B | Marco-7B | Marco-72B | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| En→XX | |||||||||||
| En2Ar | 40.4 | 48.1 | 50.0 | 31.5 | 24.4 | 17.1 | 29.9 | 29.2 | 33.5 | 41.5 | 61.2 |
| En2De | 45.9 | 48.7 | 49.3 | 32.3 | 33.1 | 37.7 | 40.4 | 43.0 | 44.7 | 41.6 | 47.7 |
| En2Es | 33.1 | 32.9 | 34.6 | 28.4 | 20.6 | 32.0 | 31.7 | 31.5 | 32.5 | 33.1 | 37.2 |
| En2Fr | 54.4 | 59.1 | 57.9 | 50.5 | 34.5 | 52.3 | 53.2 | 52.6 | 55.2 | 54.9 | 58.8 |
| En2It | 37.2 | 41.5 | 39.1 | 32.4 | 25.3 | 34.2 | 34.8 | 34.8 | 36.6 | 36.2 | 40.6 |
| En2Ja | 34.6 | 36.8 | 41.1 | 31.0 | 9.6 | 29.6 | 33.0 | 14.3 | 33.0 | 36.9 | 37.7 |
| En2Ko | 28.5 | 32.9 | 33.7 | 27.2 | 12.3 | 19.2 | 24.8 | 0.1 | 27.7 | 29.0 | 31.6 |
| En2Nl | 34.8 | 37.0 | 36.3 | 25.4 | 24.2 | 28.4 | 30.9 | 32.0 | 34.7 | 33.0 | 35.9 |
| En2Pl | 30.3 | 33.4 | 33.7 | 24.8 | 16.5 | 20.4 | 26.0 | 28.6 | 29.5 | 28.3 | 30.6 |
| En2Pt | 54.8 | 45.7 | 56.0 | 44.0 | 41.7 | 50.1 | 52.6 | 52.0 | 54.8 | 54.5 | 57.9 |
| En2Ru | 36.8 | 40.5 | 40.9 | 32.3 | 23.8 | 33.6 | 36.1 | 35.6 | 37.9 | 37.7 | 43.4 |
| En2Tr | 36.9 | 45.0 | 44.2 | 33.1 | 26.4 | 22.8 | 30.4 | 32.7 | 36.8 | 35.8 | 37.7 |
| En2Uk | 37.0 | 42.9 | 41.6 | 33.5 | 17.0 | 25.2 | 30.0 | 36.5 | 36.8 | 36.3 | 44.3 |
| En2Zh | 44.2 | 48.6 | 50.6 | 26.0 | 15.6 | 28.0 | 33.9 | 13.3 | 31.3 | 45.3 | 48.6 |
| Avg. Scores | 39.2 | 42.4 | 43.5 | 32.3 | 23.2 | 30.8 | 34.8 | 31.2 | 37.5 | 38.9 | 43.8 |
| XX→En | |||||||||||
| Ar2En | 42.7 | 47.7 | 46.8 | 33.3 | 41.1 | 41.5 | 44.6 | 37.1 | 46.1 | 48.0 | 58.0 |
| De2En | 47.7 | 51.0 | 51.3 | 30.8 | 40.9 | 46.9 | 48.4 | 46.3 | 49.4 | 50.6 | 54.7 |
| Es2En | 34.3 | 36.9 | 36.3 | 24.8 | 33.8 | 34.5 | 35.3 | 33.7 | 35.0 | 40.2 | 47.2 |
| Fr2En | 48.9 | 50.8 | 52.7 | 27.7 | 45.1 | 48.8 | 49.5 | 47.5 | 50.7 | 51.5 | 56.8 |
| It2En | 36.7 | 40.2 | 40.2 | 28.6 | 37.5 | 36.7 | 38.2 | 36.5 | 38.4 | 42.9 | 49.2 |
| Ja2En | 30.4 | 37.0 | 36.7 | 20.5 | 22.6 | 29.8 | 31.9 | 26.2 | 32.3 | 36.3 | 49.5 |
| Ko2En | 33.3 | 39.3 | 38.2 | 21.9 | 25.9 | 32.1 | 34.5 | 28.7 | 33.8 | 37.0 | 49.0 |
| Nl2En | 36.0 | 37.7 | 38.7 | 23.3 | 32.8 | 35.9 | 36.3 | 34.8 | 37.0 | 39.8 | 46.4 |
| Pl2En | 33.5 | 35.8 | 37.0 | 19.6 | 27.6 | 33.7 | 34.7 | 32.1 | 35.3 | 38.4 | 45.9 |
| Pt2En | 53.1 | 55.8 | 56.3 | 37.9 | 50.7 | 53.0 | 53.5 | 51.8 | 54.9 | 54.5 | 60.3 |
| Ru2En | 38.7 | 43.3 | 42.9 | 23.6 | 36.2 | 39.0 | 40.2 | 37.9 | 41.0 | 43.8 | 49.2 |
| Tr2En | 42.6 | 48.5 | 47.7 | 31.1 | 36.5 | 39.9 | 42.3 | 37.9 | 43.1 | 43.4 | 52.0 |
| Uk2En | 43.4 | 47.2 | 47.3 | 27.4 | 38.8 | 41.6 | 43.7 | 40.5 | 44.9 | 46.3 | 58.8 |
| Zh2En | 31.3 | 36.8 | 37.7 | 24.3 | 26.7 | 31.0 | 35.4 | 29.0 | 34.7 | 38.2 | 45.5 |
| Avg. Scores | 36.8 | 43.4 | 43.6 | 26.8 | 35.4 | 38.9 | 40.6 | 37.2 | 41.2 | 43.6 | 51.6 |
🔼 Table 11 presents a comprehensive comparison of the performance of various Large Language Models (LLMs) and Machine Translation (MT) systems on the Flores benchmark. Flores is a multilingual machine translation benchmark that focuses on low-resource languages. The table shows the BLEU scores, a metric measuring the quality of machine translation, for each model across multiple language pairs. These pairs are categorized by source language (English or other) and target language, allowing for an assessment of translation accuracy in various scenarios. The best-performing model for each language pair is highlighted in bold, allowing for easy identification of superior performance. This table helps to demonstrate the relative strengths and weaknesses of different models, especially regarding their ability to handle the diverse linguistic characteristics presented in low-resource languages.
read the caption
Table 11: Performance comparison of various LLMs and MT systems on the Flores benchmark. The best performance in each column is highlighted in bold.
| Trans. Dir. | Qwen2-7B | Qwen2.5-7B | Llama3-8B | Llama3.1-8B | Aya-expanse-8B | Aya-23-8B | Marco-7B |
|---|---|---|---|---|---|---|---|
| Ar2Ja | 16.2 | 14.3 | 13.1 | 17.5 | 16.9 | 17.1 | 21.8 |
| Es2Ja | 17.2 | 10.7 | 11.2 | 18.1 | 18.3 | 19.9 | 22.4 |
| Fr2Ja | 19.9 | 14.0 | 14.1 | 21.6 | 17.6 | 22.3 | 25.8 |
| Hu2Ja | 15.2 | 9.6 | 12.3 | 16.0 | 10.7 | 12.6 | 20.3 |
| Hu2Ko | 10.5 | 6.9 | 9.4 | 10.2 | 9.2 | 11.0 | 14.0 |
| Ja2Ar | 9.8 | 7.4 | 8.6 | 11.1 | 12.3 | 9.6 | 15.5 |
| Ja2Es | 16.1 | 15.0 | 15.9 | 16.7 | 12.9 | 16.2 | 19.1 |
| Ja2Ko | 16.3 | 12.1 | 12.2 | 17.3 | 18.7 | 17.2 | 22.6 |
| Ja2Th | 11.7 | 11.4 | 11.1 | 11.6 | 0.8 | 2.0 | 16.4 |
| Ja2Zh | 19.5 | 17.6 | 6.9 | 10.2 | 14.9 | 12.7 | 22.9 |
| Kk2Ar | 7.3 | 5.5 | 7.1 | 8.6 | 2.3 | 5.7 | 11.6 |
| Kk2Fr | 13.8 | 8.9 | 17.9 | 14.1 | 5.6 | 10.6 | 20.5 |
| Kk2Ja | 11.7 | 6.0 | 10.4 | 12.2 | 4.1 | 9.6 | 16.8 |
| Kk2Ko | 8.3 | 4.7 | 9.6 | 9.3 | 4.5 | 7.5 | 13.1 |
| Kk2Pt | 12.7 | 8.8 | 15.2 | 10.2 | 4.2 | 9.7 | 16.9 |
| Kk2Th | 6.7 | 7.1 | 8.9 | 10.4 | 0.4 | 1.2 | 12.7 |
| Kk2Zh | 11.9 | 10.8 | 10.2 | 13.1 | 3.0 | 7.6 | 18.5 |
| Ko2Ja | 22.4 | 21.2 | 17.5 | 22.3 | 23.9 | 19.3 | 26.2 |
| Ko2Th | 11.9 | 9.7 | 11.2 | 12.2 | 0.8 | 2.0 | 14.7 |
| Ko2Zh | 20.0 | 20.3 | 10.2 | 16.2 | 16.6 | 14.7 | 22.7 |
| Th2Ar | 11.3 | 9.1 | 8.7 | 5.5 | 1.7 | 6.8 | 15.4 |
| Th2Es | 16.4 | 15.1 | 16.4 | 9.1 | 1.5 | 10.0 | 18.6 |
| Th2Fr | 22.2 | 20.3 | 19.3 | 12.4 | 5.1 | 14.2 | 25.2 |
| Th2Ja | 16.5 | 15.4 | 12.6 | 14.5 | 0.0 | 5.5 | 22.7 |
| Th2Kk | 2.2 | 1.7 | 4.4 | 5.4 | 0.3 | 0.8 | 9.3 |
| Th2Ko | 12.2 | 9.4 | 8.3 | 7.6 | 0.8 | 5.1 | 16.5 |
| Th2Zh | 18.8 | 18.0 | 9.5 | 9.2 | 0.0 | 6.4 | 22.3 |
| Tr2Ja | 17.7 | 7.3 | 11.9 | 20.0 | 19.6 | 21.4 | 23.2 |
| Uk2Fr | 27.5 | 24.3 | 31.2 | 33.0 | 31.5 | 33.0 | 34.6 |
| Uk2Ja | 17.3 | 13.0 | 14.1 | 20.1 | 16.9 | 21.8 | 26.6 |
| Uk2Kk | 3.4 | 2.7 | 7.9 | 8.3 | 0.7 | 1.8 | 12.4 |
| Uk2Ko | 13.2 | 8.9 | 10.7 | 15.8 | 16.0 | 17.3 | 18.9 |
| Uk2Th | 12.4 | 11.2 | 13.7 | 15.2 | 1.1 | 2.9 | 19.9 |
| Uk2Zh | 20.7 | 18.4 | 11.6 | 9.8 | 16.1 | 17.8 | 25.6 |
| Ur2Ar | 8.0 | 7.4 | 5.2 | 4.8 | 3.4 | 6.4 | 10.7 |
| Ur2Ko | 8.7 | 6.8 | 8.5 | 9.3 | 4.5 | 9.0 | 12.8 |
| Zh2Ar | 11.9 | 9.8 | 10.6 | 13.5 | 14.9 | 13.6 | 17.0 |
| Zh2Fr | 24.5 | 21.7 | 21.8 | 25.7 | 24.5 | 21.3 | 28.9 |
| Zh2Ja | 19.2 | 15.0 | 10.9 | 18.4 | 14.4 | 17.3 | 27.7 |
| Zh2Ko | 14.2 | 10.4 | 9.7 | 14.8 | 15.7 | 15.4 | 21.2 |
| Zh2Pt | 22.6 | 20.9 | 19.5 | 20.5 | 21.0 | 21.5 | 25.4 |
| Zh2Th | 13.3 | 10.8 | 12.8 | 13.9 | 1.0 | 2.5 | 19.8 |
| Avg. Score | 14.6 | 11.9 | 12.2 | 13.9 | 9.7 | 11.9 | 19.7 |
🔼 Table 12 presents a detailed comparison of Any2Any (any-to-any) machine translation performance across various language pairs, using several large language models (LLMs). The LLMs compared are instruction-tuned versions of Qwen2, Qwen2.5, Llama 3, and Llama 3.1, alongside the authors’ Marco-LLM. The table shows BLEU scores for each language pair translation, indicating the quality of the translation produced by each model. The best performing model for each language pair is highlighted in bold, enabling easy identification of superior performance in specific translation scenarios.
read the caption
Table 12: Any2Any translation performance on Flores benchmark across various language pairs for LLMs. The table compares results from the Instruct models of Qwen2, Qwen2.5, Llama3, Llama3.1, and Marco-LLM, with the best performance highlighted in bold for each translation direction.
| ID | Template (in English) |
|---|---|
| A | <src_lang> phrase: <input> ◇ <tgt_lang> phrase: <output> |
| B | <src_lang> text: <input> ◇ <tgt_lang> text: <output> |
| C | Translate the text from <src_lang> to <tgt_lang>: ◇ <src_lang> text: <input> ◇ <tgt_lang> text: <output> |
| D | Translate the words from <src_lang> to <tgt_lang>: ◇ <src_lang> words: <input> ◇ <tgt_lang> words: <output> |
| E | Convert the phrase from <src_lang> to <tgt_lang>: ◇ <src_lang> phrase: <input> ◇ <tgt_lang> phrase: <output> |
| F | Render the <src_lang> sentence <input> to <tgt_lang>: <output> |
| G | Provide the translation of the sentence <input> from <src_lang> to <tgt_lang>: <output> |
| H | Change the phrase <input> to <tgt_lang>, the translated phrase is: <output> |
| I | Please change the sentence <input> to <tgt_lang>, and the resulting translation is: <output> |
| J | Change the phrase <input> to <tgt_lang>, resulting in: <output> |
| K | The sentence <input> in <src_lang> means <output> in <tgt_lang> |
🔼 This table details the various sentence templates used to generate parallel data for the Marco-LLM model training. Each template provides instructions for translating text from a source language to a target language. The variations in wording are designed to increase the diversity of the training data and improve model generalization. Placeholders within the templates represent the source language, target language, input text, and resulting output text. The symbol ‘◇◇\Diamond◇’ indicates a line break within the template. The table aids in understanding how the researchers constructed their parallel dataset, which is a key part of the Marco-LLM’s multilingual capabilities.
read the caption
Table 13: Translation templates used in our experiments. Note: The translation templates are used to construct our parallel data, where ◇◇\Diamond◇ indicates the position of a line break. The placeholders, , , and
| Method | Prompt |
|---|---|
| Keywords-based Explanation | Suppose that you are a/an {role_1} in {subject}. Please explain the following keywords and meet the following requirements: (1) The keywords: {keywords}; (2) Each keyword explanation should contain at least three sentences. You can generate a story about the keyword for better explanation; (3) The explanations suit {role_2} students; (4) Summarize the explanations. Your answer should be a list of keywords. Make the explanations correct, useful, understandable, and diverse. |
| Keywords-based Story | Assume that you are a/an {role_1} in {subject}. Before you teach students new vocabulary, please write a {type_passage} about the new knowledge and meet the following requirements: (1) It must contain keywords: {keywords}; (2) Its setting should be {scene}; (3) Should be between {min_length} and {max_length} words in length; (4) The writing style should be {style}; (5) The suitable audience is {role_2}; (6) Should end with {ending}; (7) Should be written in {language}. |
| Few-shot Based SFT Data | I want you to act as a Sample Generator. Your goal is to draw inspiration from the Given Sample to create a brand new sample. This new sample should belong to the same domain as the Given Sample but be even rarer. The length and complexity of the Created Sample should be similar to that of the Given Sample. The Created Sample must be reasonable and understandable by humans. The terms Given Sample, Created Sample, ‘given sample’, and ‘created sample’ are not allowed to appear in the Created Sample. |
Given Sample: | |
(1) Sample doc 1 | |
(2) Sample doc 2 | |
(3) Sample doc 3 | |
| (4) … | |
Created Sample: |
🔼 This table details the prompt templates used to generate synthetic data for training the Marco-LLM. It breaks down the prompts used for three methods of synthetic data generation: Keywords-based Explanation, Keywords-based Story, and Few-shot Based SFT Data. Each method has multiple prompts, showcasing the diverse approaches used to generate a wide variety of synthetic training examples. These prompts vary in style, content, and structure to provide a comprehensive and diverse dataset.
read the caption
Table 14: Prompt Templates for Synthetic Data.
| Language | Qwen2 | Qwen2.5 | Llama-3 | Llama3.1 | Aya-23 | Aya-expanse | Marco-Chat |
|---|---|---|---|---|---|---|---|
| 7B Models | |||||||
| Arabic | 47.5 | 48.0 | 58.8 | 68.3 | 67.2 | 45.0 | 78.4 |
| Bengali | 42.3 | 61.6 | 56.8 | 64.3 | 50.6 | 21.3 | 74.6 |
| English | 29.0 | 42.7 | 24.4 | 41.6 | 53.6 | 49.6 | 44.4 |
| Finnish | 27.1 | 48.4 | 54.8 | 47.3 | 44.7 | 23.5 | 51.5 |
| Indonesian | 28.6 | 38.4 | 34.5 | 31.8 | 33.4 | 30.2 | 48.1 |
| Japanese | 0.8 | 8.7 | 17.6 | 31.8 | 71.0 | 41.7 | 70.5 |
| Korean | 38.2 | 45.6 | 25.4 | 57.9 | 76.0 | 20.3 | 77.9 |
| Russian | 22.4 | 33.7 | 31.2 | 40.8 | 49.9 | 25.7 | 46.6 |
| Swahili | 17.5 | 8.9 | 30.1 | 45.2 | 11.8 | 13.3 | 31.3 |
| Telugu | 28.7 | 22.8 | 48.8 | 83.3 | 5.5 | 11.3 | 35.2 |
| Thai | 39.7 | 55.7 | 54.3 | 70.8 | 55.2 | 29.3 | 76.2 |
| Avg. Scores | 29.2 | 39.0 | 39.7 | 53.0 | 47.2 | 28.3 | 57.7 |
| 70B Models | |||||||
| Arabic | 42.5 | 61.6 | 72.7 | 62.4 | 67.5 | 40.9 | 78.4 |
| Bengali | 47.1 | 65.7 | 55.9 | 68.1 | 43.6 | 28.0 | 73.3 |
| English | 43.0 | 45.5 | 46.6 | 41.2 | 53.6 | 46.8 | 51.2 |
| Finnish | 55.8 | 39.0 | 57.0 | 50.9 | 52.5 | 26.0 | 57.0 |
| Indonesian | 39.9 | 47.8 | 44.0 | 31.9 | 35.8 | 27.6 | 46.5 |
| Japanese | 38.6 | 44.7 | 43.8 | 49.9 | 73.6 | 22.1 | 68.4 |
| Korean | 41.1 | 43.2 | 43.8 | 63.0 | 73.1 | 29.5 | 69.4 |
| Russian | 38.5 | 43.2 | 42.5 | 36.3 | 52.4 | 35.5 | 45.9 |
| Swahili | 18.6 | 21.3 | 46.0 | 33.8 | 20.4 | 12.5 | 49.2 |
| Telugu | 36.9 | 41.4 | 45.5 | 80.4 | 26.6 | 22.9 | 62.8 |
| Thai | 41.5 | 68.2 | 74.0 | 66.4 | 52.7 | 38.7 | 76.5 |
| Avg. Scores | 40.3 | 48.4 | 52.0 | 53.1 | 50.2 | 30.0 | 61.0 |
🔼 This table presents a performance comparison of various large language models (LLMs) on the TyDiQA benchmark. TyDiQA is a question answering benchmark dataset designed to evaluate multilingual capabilities across diverse languages. The table shows the performance of several LLMs, broken down by specific languages, allowing for a detailed comparison of their strengths and weaknesses in multilingual question answering. The results provide insight into which models handle diverse languages effectively and highlight the challenges of building robust multilingual NLP systems.
read the caption
Table 15: Performance comparison of language models on TydiQA benchmark [Clark et al., 2020] across different languages.
| Category | Qwen2 | Qwen2.5 | Llama3 | Llama3.1 | Aya-23 | Aya-expanse | Marco |
|---|---|---|---|---|---|---|---|
| 7B Models | |||||||
| Average | 81.8 | 77.9 | 50.8 | 55.6 | 43.9 | 48.5 | 86.4 |
| Hard | 63.1 | 51.8 | 33.9 | 36.9 | 32.6 | 32.4 | 79.9 |
| Other | 84.9 | 82.8 | 53.5 | 56.3 | 44.9 | 48.3 | 81.0 |
| Humanities | 84.3 | 79.6 | 47.2 | 53.8 | 43.2 | 50.3 | 84.8 |
| Social Science | 91.3 | 87.8 | 58.9 | 64.9 | 51.2 | 54.3 | 90.4 |
| STEM | 73.9 | 69.4 | 47.2 | 51.5 | 40.1 | 44.7 | 88.3 |
| 70B Models | |||||||
| Average | 90.6 | 88.2 | 66.7 | 71.6 | 53.6 | 56.9 | 94.5 |
| Hard | 77.8 | 73.3 | 51.1 | 56.0 | 35.2 | 36.5 | 94.0 |
| Other | 92.0 | 88.4 | 63.1 | 69.2 | 52.8 | 54.7 | 92.5 |
| Humanities | 92.8 | 91.0 | 66.5 | 70.0 | 56.9 | 60.3 | 95.2 |
| Social Science | 94.8 | 91.5 | 75.6 | 82.0 | 61.8 | 66.4 | 95.7 |
| STEM | 88.4 | 84.9 | 64.2 | 68.5 | 48.1 | 51.4 | 94.6 |
🔼 This table presents a performance comparison of various Large Language Models (LLMs) on the CEVAL benchmark. CEVAL is a comprehensive evaluation suite designed to assess the capabilities of Chinese language models across a range of tasks. The table breaks down the performance across different categories within the benchmark, offering a detailed view of how well each LLM performs on various aspects of Chinese language understanding and reasoning. It allows for comparison across models of different sizes (7B parameters and 70B+ parameters) by displaying their average scores in various categories. The categories are designed to measure diverse abilities including general knowledge, difficulty of tasks, and specific subject matters. This detailed analysis helps assess the strengths and weaknesses of each LLM, especially regarding its multilingual comprehension capabilities.
read the caption
Table 16: Performance comparison on the CEVAL benchmark across different categories.
| Category | Qwen2 | Qwen2.5 | Llama3 | Llama3.1 | Aya-23 | Aya-expanse | Marco-Chat |
|---|---|---|---|---|---|---|---|
| 7B Models | |||||||
| Chinese | 59.5 | 57.1 | 37.7 | 62.5 | 36.5 | 34.4 | 65.3 |
| English | 54.0 | 61.5 | 41.5 | 51.0 | 37.9 | 39.9 | 56.6 |
| Gaokao | 64.5 | 63.4 | 41.5 | 53.0 | 40.3 | 37.3 | 71.0 |
| Gaokao-Chinese | 77.6 | 67.9 | 47.6 | 58.5 | 46.3 | 42.3 | 80.5 |
| Gaokao-English | 89.5 | 85.3 | 79.1 | 89.5 | 82.0 | 67.0 | 93.1 |
| Gaokao-Geography | 81.4 | 80.4 | 49.8 | 75.9 | 50.8 | 50.3 | 86.9 |
| Gaokao-History | 86.0 | 82.1 | 55.7 | 74.9 | 51.1 | 49.8 | 89.8 |
| Gaokao-Biology | 81.9 | 80.5 | 52.9 | 76.2 | 43.8 | 35.7 | 87.6 |
| Gaokao-Chemistry | 56.5 | 55.6 | 32.4 | 46.9 | 29.5 | 30.4 | 74.4 |
| Gaokao-MathQA | 45.3 | 55.3 | 32.5 | 16.2 | 27.4 | 27.4 | 60.7 |
| Gaokao-Physics | 45.0 | 44.5 | 15.5 | 34.0 | 30.5 | 26.0 | 57.5 |
| Gaokao-MathCloze | 17.0 | 18.6 | 8.5 | 5.1 | 1.7 | 6.8 | 8.5 |
| LogiQA-ZH | 60.8 | 54.7 | 42.1 | 61.1 | 36.3 | 37.8 | 68.2 |
| LSAT-AR | 26.5 | 23.9 | 23.5 | 30.9 | 21.3 | 23.0 | 29.6 |
| LSAT-LR | 57.3 | 66.3 | 54.5 | 84.5 | 41.0 | 45.3 | 79.2 |
| LSAT-RC | 66.2 | 74.4 | 69.5 | 89.2 | 55.8 | 56.1 | 75.8 |
| LogiQA-EN | 46.7 | 50.4 | 43.5 | 59.6 | 36.7 | 35.3 | 61.4 |
| SAT-Math | 82.7 | 88.6 | 68.2 | 44.1 | 35.9 | 49.1 | 62.3 |
| SAT-EN | 83.0 | 84.5 | 82.0 | 91.3 | 77.2 | 64.1 | 84.0 |
| SAT-EN-Without-Passage | 46.6 | 42.2 | 46.1 | 44.7 | 42.2 | 39.8 | 52.9 |
| Math | 82.7 | 48.5 | 20.0 | 57.6 | 7.1 | 13.6 | 12.8 |
| Aqua-RAT | 59.8 | 74.8 | 52.0 | 61.0 | 24.0 | 32.7 | 51.2 |
| JEC-QA-KD | 38.0 | 33.1 | 17.5 | 26.9 | 18.2 | 17.8 | 37.5 |
| JEC-QA-CA | 34.7 | 27.4 | 19.1 | 26.0 | 20.4 | 21.1 | 38.4 |
| Average | 57.1 | 59.0 | 43.4 | 41.8 | 37.1 | 36.7 | 61.5 |
| 70B Models | |||||||
| Chinese | 66.3 | 66.0 | 51.0 | 49.3 | 43.5 | 42.1 | 74.5 |
| English | 65.7 | 69.4 | 65.3 | 62.5 | 45.5 | 50.6 | 70.4 |
| Gaokao | 71.8 | 71.9 | 54.1 | 53.0 | 47.6 | 46.6 | 80.6 |
| Gaokao-Chinese | 85.0 | 84.6 | 56.5 | 58.5 | 50.8 | 52.4 | 92.7 |
| Gaokao-English | 89.5 | 92.2 | 90.9 | 89.5 | 88.9 | 71.6 | 96.1 |
| Gaokao-Geography | 88.9 | 87.9 | 74.9 | 75.9 | 66.3 | 65.8 | 96.0 |
| Gaokao-History | 92.3 | 87.2 | 71.1 | 74.9 | 68.9 | 63.4 | 95.3 |
| Gaokao-Biology | 86.2 | 86.2 | 74.3 | 76.2 | 54.8 | 53.3 | 95.2 |
| Gaokao-Chemistry | 68.1 | 66.2 | 39.6 | 46.9 | 37.2 | 35.8 | 84.1 |
| Gaokao-MathQA | 60.7 | 66.1 | 45.0 | 16.2 | 29.1 | 36.8 | 74.6 |
| Gaokao-Physics | 53.5 | 56.5 | 23.0 | 34.0 | 31.5 | 32.0 | 75.0 |
| Gaokao-MathCloze | 22.0 | 20.3 | 11.9 | 5.1 | 0.9 | 8.5 | 16.1 |
| LogiQA-ZH | 70.2 | 70.1 | 61.1 | 61.1 | 46.2 | 46.2 | 82.3 |
| LSAT-AR | 32.2 | 27.4 | 31.7 | 30.9 | 19.6 | 20.9 | 40.0 |
| LSAT-LR | 73.1 | 88.0 | 80.8 | 84.5 | 60.0 | 59.4 | 94.5 |
| LSAT-RC | 77.7 | 85.5 | 84.8 | 89.2 | 72.9 | 62.1 | 91.1 |
| LogiQA-EN | 56.8 | 59.6 | 55.8 | 59.6 | 43.9 | 40.3 | 75.7 |
| SAT-Math | 90.5 | 84.1 | 86.4 | 44.1 | 43.6 | 66.8 | 74.6 |
| SAT-EN | 89.8 | 91.3 | 89.8 | 91.3 | 87.9 | 77.7 | 90.8 |
| SAT-EN w/o Passage | 49.0 | 49.5 | 55.3 | 44.7 | 44.7 | 45.6 | 69.4 |
| Math | 46.5 | 63.1 | 34.2 | 57.6 | 8.9 | 25.7 | 22.6 |
| AQUA-RAT | 75.2 | 76.0 | 69.3 | 61.0 | 28.0 | 32.0 | 75.2 |
| JEC-QA-KD | 39.0 | 35.5 | 34.4 | 26.9 | 23.2 | 19.3 | 41.4 |
| JEC-QA-CA | 39.9 | 20.3 | 28.9 | 26.0 | 24.1 | 19.5 | 44.6 |
| Avg. Scores | 66.0 | 67.5 | 57.1 | 55.0 | 44.4 | 45.7 | 72.7 |
🔼 This table presents a detailed comparison of the performance of several large language models (LLMs) on the AGIEval benchmark, specifically focusing on the 7B parameter models. The AGIEval benchmark is designed to evaluate the reasoning and problem-solving abilities of AI models on tasks that mimic human examinations. The table breaks down the performance across various subcategories of the AGIEval dataset, including general categories like Chinese and English, and more specialized categories like Gaokao (Chinese college entrance exam) sub-sections (Chinese, English, Geography, History, Biology, Chemistry, MathQA, Physics, MathCloze), LogiQA (logical reasoning) sub-sections (Chinese and English), LSAT (Law School Admission Test) sub-sections (Analytical Reasoning, Logical Reasoning, Reading Comprehension), SAT (Scholastic Assessment Test) sub-sections (Math, English, English without passage), and other categories like Math, Aqua-RAT (reading comprehension), JEC-QA (Knowledge and Common Sense Reasoning). For each subcategory, the performance of each LLM is measured and presented, with the highest-performing model for each subcategory highlighted in bold. This allows for a granular comparison of model capabilities across diverse reasoning tasks and language contexts.
read the caption
Table 17: Agieval 7B Results: Performance of various models across different categories of the Agieval dataset. The best performance in each category is highlighted in bold.
Full paper#