↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Autoregressive (AR) models excel at generating high-quality images but suffer from slow generation speeds due to their sequential, token-by-token approach. This limitation hinders their application in high-resolution image and video generation, where numerous forward passes are required. Existing methods for speeding up the process either introduce additional computational costs or show marginal improvements.
To overcome these limitations, the researchers propose ZipAR, a parallel decoding framework. ZipAR leverages the spatial locality inherent in images; spatially distant pixels tend to have minimal interdependence. By exploiting this property, ZipAR decodes multiple tokens simultaneously, significantly reducing the number of forward passes needed. Experiments demonstrate that ZipAR can accelerate generation by up to 91% on the Emu3-Gen model without requiring any retraining, thus showing significant potential for advancing AR image generation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces ZipAR, a novel method that significantly speeds up auto-regressive image generation without requiring any model retraining. This addresses a major bottleneck in current AR models, opening new avenues for research in high-resolution image and video generation. Its simplicity and plug-and-play nature make it easily adaptable to existing models, fostering wider adoption and advancing the field.
Visual Insights#

🔼 Figure 1 showcases the significant speedup achieved by ZipAR, a novel parallel decoding method, in auto-regressive image generation. The figure compares image generation using the Emu3-Gen model with the standard next-token prediction approach (leftmost column) to generation using ZipAR with different parameter settings (remaining columns). The results demonstrate that ZipAR can reduce the number of forward steps required by up to 91%, substantially accelerating the image generation process without noticeable loss in image quality.
read the caption
Figure 1: Up to 91% forward step reduction with ZipAR. Samples are generated by Emu3-Gen model with next-token prediction paradigm (the first column) and ZipAR (the right three columns).
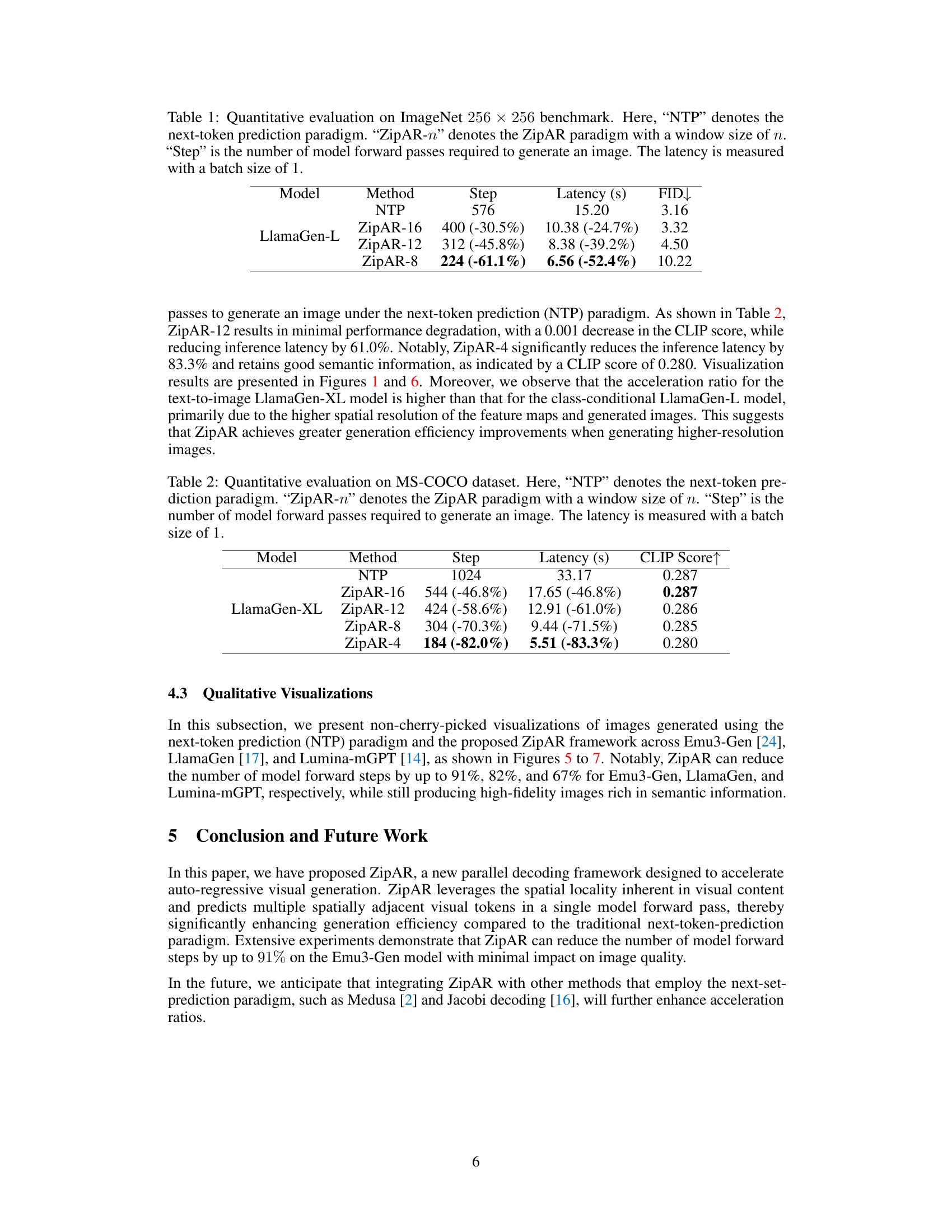
| Model | Method | Step | Latency (s) | FID↓ |
|---|---|---|---|---|
| LlamaGen-L | NTP | 576 | 15.20 | 3.16 |
| LlamaGen-L | ZipAR-16 | 400 (-30.5%) | 10.38 (-24.7%) | 3.32 |
| LlamaGen-L | ZipAR-12 | 312 (-45.8%) | 8.38 (-39.2%) | 4.50 |
| LlamaGen-L | ZipAR-8 | 224 (-61.1%) | 6.56 (-52.4%) | 10.22 |
🔼 Table 1 presents a quantitative comparison of the performance of different image generation methods on the ImageNet 256x256 benchmark. The methods compared are the standard next-token prediction (NTP) approach and variations of the proposed ZipAR method using different window sizes (ZipAR-n, where n represents the window size). For each method, the table shows the number of forward passes (‘Step’) required to generate a single image, the time taken to generate the image (‘Latency’), and the Fréchet Inception Distance (FID) score, which is a measure of image quality. A lower FID score indicates better image quality. The latency is measured using a batch size of 1. This table helps demonstrate the efficiency improvements of ZipAR compared to the baseline NTP method.
read the caption
Table 1: Quantitative evaluation on ImageNet 256×256256256256\times 256256 × 256 benchmark. Here, “NTP” denotes the next-token prediction paradigm. “ZipAR-n𝑛nitalic_n” denotes the ZipAR paradigm with a window size of n𝑛nitalic_n. “Step” is the number of model forward passes required to generate an image. The latency is measured with a batch size of 1.
In-depth insights#
ZipAR: Spatial Locality#
ZipAR leverages the spatial locality inherent in images, a key observation often overlooked in autoregressive image generation. Unlike methods that process pixels sequentially, ZipAR’s parallel decoding dramatically accelerates the process. By recognizing that spatially distant regions in an image exhibit minimal interdependence, ZipAR efficiently predicts sets of adjacent pixels concurrently, significantly reducing the number of forward passes needed. This clever approach hinges on the concept that neighboring pixels are much more informative to each other than those far apart. The effectiveness is demonstrated through significant speedups, showcasing ZipAR as a training-free, plug-and-play solution that boosts the efficiency of autoregressive models without requiring any retraining. The results highlight the impact of efficiently exploiting spatial relationships in image data, suggesting a significant shift in how future AR image models might be designed.
Parallel Decoding#
Parallel decoding in autoregressive image generation aims to accelerate the slow generation process inherent in sequential, next-token prediction methods. By exploiting the spatial locality of images, where nearby pixels exhibit strong correlations, parallel decoding techniques concurrently generate multiple tokens, significantly reducing the number of forward passes required. This is achieved by identifying spatially adjacent tokens that can be predicted simultaneously, mitigating the need to wait for preceding tokens in a raster scan. Several methods exist for implementing parallel decoding, such as predicting multiple tokens across rows or employing multiple decoding heads. However, ZipAR stands out by leveraging the spatial locality and using a simple, training-free approach, offering a plug-and-play solution to significantly reduce generation time with minimal impact on image quality. The effectiveness of this method hinges on the careful selection of a window size determining the spatial adjacency of tokens which balances parallelism with the need to maintain high image quality.
Autoregressive Speedup#
Autoregressive models, while powerful for image generation, suffer from slow speeds due to their sequential, token-by-token generation process. The core idea behind accelerating these models lies in exploiting the inherent spatial locality present in images. Spatially distant image regions exhibit minimal interdependence, meaning that the prediction of a given pixel doesn’t critically rely on distant pixels already generated. Parallel decoding methods attempt to capitalize on this by simultaneously predicting multiple tokens, significantly reducing the number of sequential steps required. The success of these methods hinges on carefully balancing the parallelization with the need to maintain accuracy. Techniques like defining a ‘window size’ control the number of simultaneously decoded tokens to ensure accuracy isn’t unduly compromised by parallel processing. Efficient decoding methods are crucial for making autoregressive generation practical for high-resolution images and videos; achieving a significant speedup without sacrificing image quality remains a primary goal.
Visual Tokenization#
Visual tokenization, a crucial preprocessing step in autoregressive image generation, involves converting an image into a sequence of discrete tokens. This process is analogous to word tokenization in natural language processing, where sentences are broken down into individual words. Effective visual tokenization is critical for model performance; poorly chosen tokens can hinder the model’s ability to capture meaningful patterns and generate high-quality images. Several approaches exist, each with strengths and weaknesses, such as vector quantization (VQ) which converts image patches to discrete codes. The choice of tokenization method impacts both the computational efficiency and the expressive power of the model. High-resolution images require a large number of tokens, potentially leading to increased computational burden and memory usage. Optimizing tokenization for specific model architectures and image characteristics is therefore essential for successful autoregressive image generation. Future research could explore adaptive or hierarchical methods that dynamically adjust token resolution or representation based on image content, leading to more efficient and effective image generation.
Future Extensions#
Future research could explore several promising avenues. Extending ZipAR’s parallel decoding to handle more complex visual structures, such as those found in videos, would be a significant advancement. This might involve incorporating temporal dependencies between frames. Investigating the optimal window size for ZipAR in various scenarios is another important area. The current fixed window size works well, but a dynamic approach which adjusts the window size based on image content could potentially lead to further improvements. Another interesting direction would be to combine ZipAR with other efficient decoding methods, such as speculative decoding or Jacobi methods, to achieve even greater acceleration. Exploring alternative spatial locality patterns beyond simple raster order could also yield improvements in decoding efficiency. Finally, a thorough empirical analysis on a broader range of visual generation models, including those with varying architectures and training objectives, would solidify ZipAR’s effectiveness as a widely applicable acceleration technique.
More visual insights#
More on figures

🔼 Figure 2 illustrates the decoding methods of autoregressive visual generation models. (a) shows the standard training and decoding pipeline for these models, where each forward pass produces one token. (b) shows how Medusa and Jacobi accelerate the process by predicting multiple adjacent tokens sequentially. (c) MAR improves on this by predicting multiple tokens in random order, rather than sequentially. (d) ZipAR, the proposed method, predicts multiple spatially adjacent tokens for improved efficiency.
read the caption
Figure 2: (a) An overview of the training and decoding pipeline for auto-regressive (AR) visual generation models. For models trained with a next-token prediction objective, each forward pass generates a single visual token. (b) Medusa [2] and Jacobi [16] decoding predict multiple adjacent tokens in sequence order. (c) MAR [13] predicts multiple tokens in a random order. (d) The proposed ZipAR predicts multiple spatially adjacent tokens.

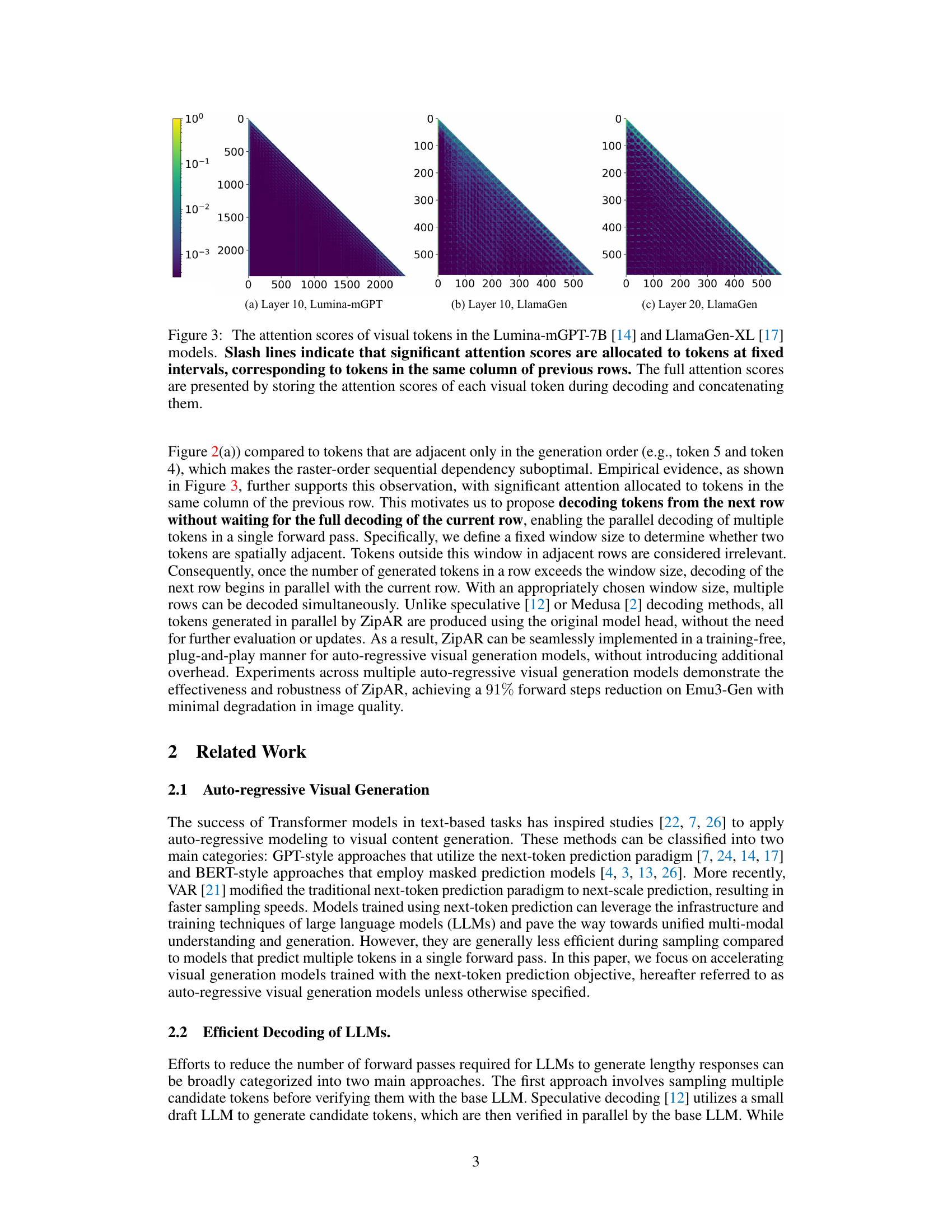
🔼 Figure 3 visualizes the attention patterns of two large language models (LLMs), Lumina-mGPT-7B and LlamaGen-XL, during image generation. The heatmaps show how strongly each token (representing a part of the image) attends to other tokens. Crucially, the diagonal slash lines highlight a strong correlation between tokens in the same column across different rows, demonstrating spatial locality in the attention mechanisms. This implies that the models are not purely sequential in their processing; they utilize contextual information from spatially related tokens to generate the image more efficiently.
read the caption
Figure 3: The attention scores of visual tokens in the Lumina-mGPT-7B [14] and LlamaGen-XL [17] models. Slash lines indicate that significant attention scores are allocated to tokens at fixed intervals, corresponding to tokens in the same column of previous rows. The full attention scores are presented by storing the attention scores of each visual token during decoding and concatenating them.

🔼 Figure 4 illustrates the ZipAR framework’s operation using a simplified example. The figure shows how multiple rows of image tokens (represented by Xi,j) are processed concurrently. The window size, a key parameter in ZipAR, is set to 2. This parameter dictates the spatial range of token dependencies considered for parallel decoding. With a window size of 2, the algorithm can initiate the decoding of tokens in the next row (e.g., X1,0, X1,1, X1,2) once the tokens in the current row within the window are generated. This parallel processing accelerates image generation by reducing the number of sequential steps required by traditional autoregressive methods.
read the caption
Figure 4: A toy example of the ZipAR framework. The window size is set to 2222 in this toy example.

🔼 Figure 5 presents a comparison of image generation results using the Emu3-Gen model. The first column showcases images generated using the standard next-token prediction method. The subsequent three columns display images generated with the ZipAR framework under various configurations. All images share the same prompts, allowing for a direct comparison of image quality and generation efficiency across different methods. A classifier-free guidance value of 6.0 was consistently used throughout the experiment. This figure visually demonstrates the impact of ZipAR on accelerating image generation.
read the caption
Figure 5: Samples generated by Emu3-Gen model with next-token prediction paradigm (the first column) and ZipAR under different configurations (the right three columns). The classifier-free guidance is set to 6.0.

🔼 Figure 6 presents a comparison of image generation results using the LlamaGen-XL model. The first column shows images generated using the standard next-token prediction method. The subsequent three columns illustrate the results obtained using the ZipAR method with varying configurations (different window sizes). All images share the same prompts and classifier-free guidance parameter (set to 7.5). This figure visually demonstrates the impact of ZipAR on accelerating image generation while maintaining image quality.
read the caption
Figure 6: Samples generated by LlamaGen-XL model with next-token prediction paradigm (the first column) and ZipAR under different configurations (the right three columns). The classifier-free guidance is set to 7.5.

🔼 Figure 7 showcases image samples generated using the Lumina-mGPT-7B-768 model. The leftmost column displays images created using the standard next-token prediction method. The remaining three columns illustrate images generated with the ZipAR method, each using a different configuration (various window sizes). A consistent classifier-free guidance value of 3 was used across all generated samples.
read the caption
Figure 7: Samples generated by Lumina-mGPT-7B-768 model with next-token prediction paradigm (the first column) and ZipAR under different configurations (the right three columns). The classifier-free guidance is set to 3.
Full paper#