↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current virtual dressing methods struggle with handling multiple garments and maintaining garment details while adhering to text prompts. Existing approaches often lack support for various attire combinations and fail to preserve garment details, resulting in limited performance across diverse scenarios.
AnyDressing tackles these limitations with a novel two-network architecture. GarmentsNet efficiently extracts garment features using a parallel processing design. DressingNet accurately injects multi-garment features into their corresponding regions using a Dressing-Attention mechanism and Instance-Level Garment Localization Learning. It also incorporates a Garment-Enhanced Texture Learning strategy to improve fine-grained texture details. This approach enhances text-image consistency and is easily integrated with other community plugins, achieving state-of-the-art results in multi-garment virtual dressing.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to virtual clothing generation, addressing limitations of existing methods. Its focus on multi-garment handling and plugin compatibility makes it highly relevant to current trends in image generation and virtual fashion technology. Researchers can leverage this work to develop more advanced virtual try-on and character customization applications. The efficient and scalable module proposed opens new avenues for research in multi-modal image synthesis and efficient large model adaptation.
Visual Insights#

🔼 Figure 1 showcases the versatility and compatibility of the AnyDressing model. Multiple rows demonstrate successful virtual dressing results across various scenes (realistic, stylized, complex garments), highlighting the model’s reliability in handling diverse contexts. The bottom row specifically demonstrates the model’s seamless integration with popular extensions like LoRA, ControlNet, and FaceID, enhancing its capabilities and adaptability.
read the caption
Figure 1: Customizable virtual dressing results of our AnyDressing. Reliability: AnyDressing is well-suited for a variety of scenes and complex garments. Compatibility: AnyDressing is compatible with LoRA [15] and plugins such as ControlNet [55] and FaceID [54].
| Method | Single Grament | Single Grament | Single Grament | Single Grament | Single Grament | Single Grament | Multiple Graments | Multiple Graments | Multiple Graments |
|---|---|---|---|---|---|---|---|---|---|
| [5] VITON-HD | CLIP-T ↑ | CLIP-I ↑ | CLIP-AS ↑ | CLIP-T ↑ | CLIP-I ↑ | CLIP-AS ↑ | CLIP-T ↑ | CLIP-I* ↑ | CLIP-AS ↑ |
| [54] IP-Adapter | 0.268 | 0.644 | 5.674 | 0.272 | 0.632 | 5.678 | 0.277 | 0.523 | 5.795 |
| [47] StableGarment | 0.285 | 0.583 | 5.781 | 0.281 | 0.587 | 5.648 | 0.284 | 0.556 | 5.735 |
| [4] MagicClothing | 0.288 | 0.640 | 5.703 | 0.298 | 0.619 | 5.784 | 0.266 | 0.583 | 5.540 |
| [40] IMAGDressing | 0.202 | 0.734 | 5.077 | 0.230 | 0.684 | 5.133 | 0.242 | 0.614 | 5.291 |
| Ours | 0.289 | 0.741 | 5.881 | 0.296 | 0.710 | 5.931 | 0.296 | 0.734 | 5.874 |
🔼 Table 1 presents a quantitative comparison of the proposed AnyDressing model against several baseline methods for virtual clothing generation. The evaluation is performed on two scenarios: single-garment dressing and multi-garment dressing. For each scenario and method, three metrics are reported: CLIP-T (measures text consistency between the generated image and the text prompt), CLIP-I (measures the consistency of generated clothing textures with the reference images), and CLIP-AS (overall aesthetic quality assessment). This provides a comprehensive comparison of performance across different models and demonstrates AnyDressing’s capabilities in handling both single and multiple garment virtual dressing tasks.
read the caption
Table 1: Quantitative comparisons with baseline methods for both single-garment and multi-garment evaluation.
In-depth insights#
Multi-Garment VD#
The concept of “Multi-Garment VD” (Virtual Dressing) presents a significant advancement in digital fashion technology. It moves beyond single-garment virtual try-ons, addressing the challenge of realistically rendering multiple clothing items simultaneously. This requires overcoming complex computational issues related to garment interaction, texture blending, and maintaining the integrity of each garment’s individual details. Successful multi-garment VD systems will need to incorporate advanced techniques like instance-level garment localization, ensuring accurate placement and realistic interactions between different garments on a virtual model. Adaptive attention mechanisms will be critical, allowing the model to prioritize certain garment features while preventing conflicts or blurring. Furthermore, the scalability of the approach needs consideration, allowing the system to handle an arbitrary number of garments efficiently. The ultimate success of multi-garment VD hinges on the ability to produce highly realistic and visually appealing results, respecting the stylistic properties of each garment and adhering faithfully to the user’s input. This can potentially revolutionize online fashion retail and the creative design process, offering a more immersive and user-friendly experience for consumers.
GFE and DA Modules#
The Garment-Specific Feature Extractor (GFE) and Dressing-Attention (DA) modules represent the core of the AnyDressing framework for multi-garment virtual dressing. GFE excels at efficiently and effectively extracting detailed features from multiple garments in parallel, avoiding the computational burden and potential for feature confusion inherent in simply replicating encoding networks. This parallel processing is key to the scalability of AnyDressing, allowing it to handle numerous garments simultaneously. The DA module is crucial for seamlessly integrating these extracted features into the image generation process. It elegantly handles multi-garment contexts, ensuring accurate and consistent placement of garment textures onto the character model. The design of the DA mechanism is sophisticated, integrating a self-attention module and a learnable cross-attention module to align the garment features with the latent features of the image, achieving a balance between faithfulness to the input garments and responsiveness to the text prompt. Furthermore, the incorporation of the Instance-Level Garment Localization (IGL) strategy within the DA module enhances its accuracy by focusing attention on each garment’s relevant region and preventing the bleeding of features from one item of clothing into another. The combination of GFE and DA represents a significant advancement in handling the complexity of multiple garments during image synthesis, producing detailed, coherent and visually pleasing virtual dressing results.
Texture Enhancement#
Enhancing texture quality is crucial in virtual dressing, as it directly impacts realism. The paper likely addresses this through several methods, possibly involving high-frequency loss functions to emphasize fine details. Perceptual loss functions could also be used to ensure the generated textures align with the style and characteristics of real-world clothing. The strategy might also involve a texture learning module, trained to improve the quality of generated fabric patterns and details. Another approach might be to leverage pre-trained models or utilize data augmentation techniques to learn a better representation of diverse textures. Efficient network architectures are essential for balancing realism with computational cost. The success of texture enhancement likely hinges on the interplay of all these factors—carefully designed loss functions, powerful learning mechanisms, and optimized training strategies.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a complex system. In the context of a research paper on multi-garment virtual dressing, this would involve removing or deactivating specific modules (e.g., Garment-Specific Feature Extractor, Instance-Level Garment Localization Learning, Garment-Enhanced Texture Learning) to observe the impact on the overall performance. The results would highlight the importance of each module, demonstrating whether they improve garment fidelity, text-image consistency, and plugin compatibility. A well-designed ablation study is crucial for understanding the architecture’s strengths and weaknesses. By isolating the effects of individual components, researchers can gain valuable insights into the design choices and provide evidence supporting the effectiveness of their proposed methods. Key performance indicators like CLIP scores (text and image consistency), perceptual quality, and texture details are vital metrics for assessing the impact of each ablation. Furthermore, it helps in justifying resource allocation and future directions. A thorough ablation study not only validates design choices but also guides potential improvements in future iterations of the virtual dressing system. Showing that each component contributes positively demonstrates a robust and well-considered model architecture. The study should present not only quantitative results but also illustrative examples of the generated images to underscore the visual differences between various ablated versions.
Future of VD#
The future of virtual dressing (VD) is bright, driven by advancements in AI and computer vision. Improved realism will be a key focus, moving beyond current limitations to create highly realistic fabric textures and accurate garment draping on diverse body types. Increased personalization is another crucial aspect, with VD systems becoming capable of generating outfits tailored to individual preferences, body shapes, and even personal styles. We can anticipate seamless integration with existing e-commerce platforms, allowing users to virtually ’try on’ clothes before purchasing, leading to reduced returns and improved customer satisfaction. Advanced features, such as realistic lighting and shadow effects, as well as interactive customization tools, will enhance user experience and enable more creative outfit exploration. Furthermore, ethical considerations surrounding privacy, data usage, and the potential for unrealistic body image representations will require careful attention. Finally, wider adoption across different industries, including fashion design, film production, and even healthcare, is likely as VD technology continues to mature.
More visual insights#
More on figures

🔼 This figure illustrates the AnyDressing pipeline, which takes N garments as input and generates an image of a character wearing those garments. The process begins with the GarmentsNet, which uses a Garment-Specific Feature Extractor (GFE) to analyze the individual garments. This information is then passed to the DressingNet, which uses a Dressing-Attention (DA) mechanism and an Instance-Level Garment Localization Learning strategy to integrate the garment features into the final image generation process. Finally, a Garment-Enhanced Texture Learning (GTL) process is used to refine details and generate a high-quality image. The diagram visually details the flow of information through these different modules.
read the caption
Figure 2: Overview of AnyDressing. Given N𝑁Nitalic_N target garments, AnyDressing customizes a character dressed in multiple target garments. The GarmentsNet leverages the Garment-Specific Feature Extractor (GFE) module to extract detailed features from multiple garments. The DressingNet integrates these features for virtual dressing using a Dressing-Attention (DA) module and an Instance-Level Garment Localization Learning mechanism. Moreover, the Garment-Enhanced Texture Learning (GTL) strategy further enhances texture details.

🔼 This figure provides a qualitative comparison of AnyDressing with several state-of-the-art virtual dressing models. It showcases the results of both single-garment and multi-garment dressing tasks, highlighting AnyDressing’s ability to maintain clothing style and texture consistency, while accurately reflecting the text prompt and avoiding background contamination. The superior performance of AnyDressing is evident in the detailed results, especially when handling multiple garments.
read the caption
Figure 3: Qualitative comparisons with state-of-the-art methods. Please zoom in for more details.

🔼 This figure showcases AnyDressing’s versatility and compatibility with various community plugins. It presents several example images generated using AnyDressing, each integrated with a different plugin (e.g., ControlNet, IP-Adapter-FaceID, LoRA). This demonstrates AnyDressing’s ability to enhance and customize image generation by incorporating additional controls and features beyond the standard text prompts, resulting in varied and highly controlled image outputs.
read the caption
Figure 4: Examples of plug-in results of AnyDressing.

🔼 This figure shows the ablation study on the Garment-Specific Feature Extractor (GFE) and Instance-Level Garment Localization (IGL) modules. The ablation is conducted on the base model, the model with GFE, and the model with both GFE and IGL. The results demonstrate that GFE reduces garment confusion and improves garment consistency, while IGL enhances the fidelity to the text prompts and minimizes background contamination.
read the caption
Figure 5: Ablation results on GFE and IGL modules.

🔼 This figure shows the ablation study on the Garment-Enhanced Texture Learning (GTL) module. The GTL module aims to improve the fine-grained texture details in the generated images by incorporating perceptual and high-frequency losses. The figure visually compares the results with and without the GTL module, demonstrating that GTL enhances the texture quality of the generated garments.
read the caption
Figure 6: Ablation results on GTL module.

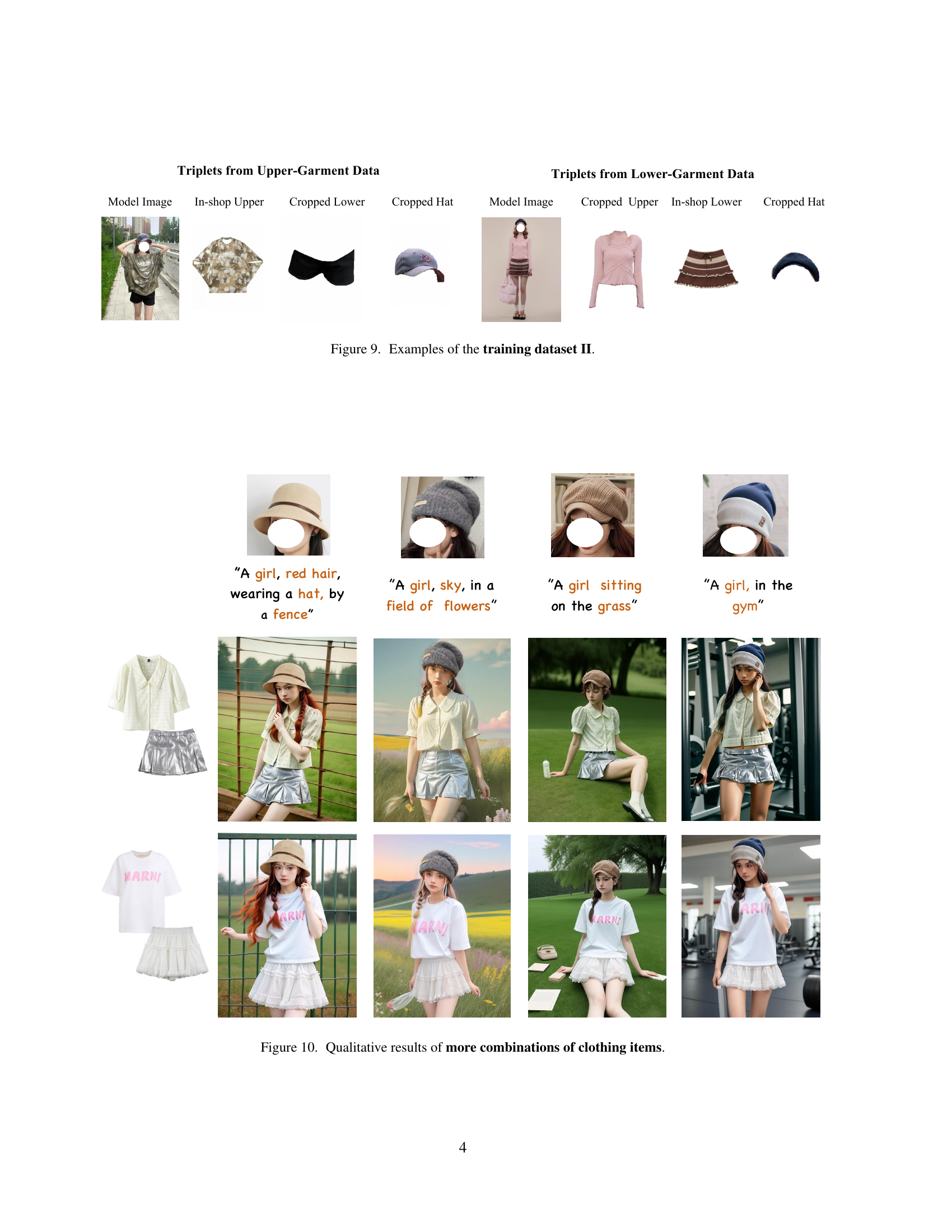
🔼 This figure displays examples of the training dataset used in the AnyDressing model. Each example shows a triplet of images: a model image (a person wearing clothing), an in-shop image of the upper garment, and an image of the lower garment extracted from the model image using a human parsing model. The dataset is designed to train the model to handle multiple clothing items simultaneously, while also accommodating variations in style and texture. The consistent use of a model image ensures that the model focuses on garment-centric details, rather than the broader context of the image.
read the caption
Figure 7: Examples of the training dataset I.

🔼 This figure shows a screenshot of the online survey used in the user study. The survey presents five generated images from different methods for a given reference garment and a text prompt. Participants are asked to rate each image based on four criteria: how well it matches the text prompt, how consistent the clothing textures are with the reference garment, the overall image quality, and a final comprehensive judgment combining all three factors.
read the caption
Figure 8: Screenshot of user study.

🔼 Figure 9 shows examples of the second training dataset used in the AnyDressing model. This dataset expands on the first by including a hat as an additional garment, resulting in image triplets containing a model image, an in-shop upper garment, a cropped lower garment, and a cropped hat image. Similarly, triplets are generated from lower garment data, resulting in images with a cropped upper garment, an in-shop lower garment, and a cropped hat. This extension demonstrates the ability of the model to handle additional garments.
read the caption
Figure 9: Examples of the training dataset II.

🔼 This figure displays various example images generated by AnyDressing, showcasing its ability to handle multiple clothing items simultaneously. Each row presents results for different combinations of garments, illustrating the model’s versatility in generating images with diverse clothing styles and combinations, all while adhering to the textual prompt given. The model successfully integrates multiple clothing items without causing significant garment confusion or misalignment.
read the caption
Figure 10: Qualitative results of more combinations of clothing items.

🔼 This figure shows the ablation study results of the Garment-Specific Feature Extractor (GFE) module and the Instance-Level Garment Localization (IGL) learning mechanism. It compares the results of the base model against models incorporating GFE and then IGL. The images illustrate that the GFE module significantly reduces garment confusion and improves garment consistency. Adding the IGL further improves fidelity to the text prompts and minimizes background contamination by ensuring that each garment’s attention focuses on the correct area.
read the caption
Figure 11: More ablation results on GFE and IGL modules.

🔼 This figure displays qualitative comparison results between AnyDressing and four other state-of-the-art virtual try-on methods for single-garment scenarios. Each row represents a different method, while each column shows the results for a different text prompt and reference garment. The figure allows for a visual comparison of the generated images, enabling an assessment of each method’s ability to faithfully reproduce the garment’s textures and styles while adhering to the text description.
read the caption
Figure 12: More qualitative comparisons I.

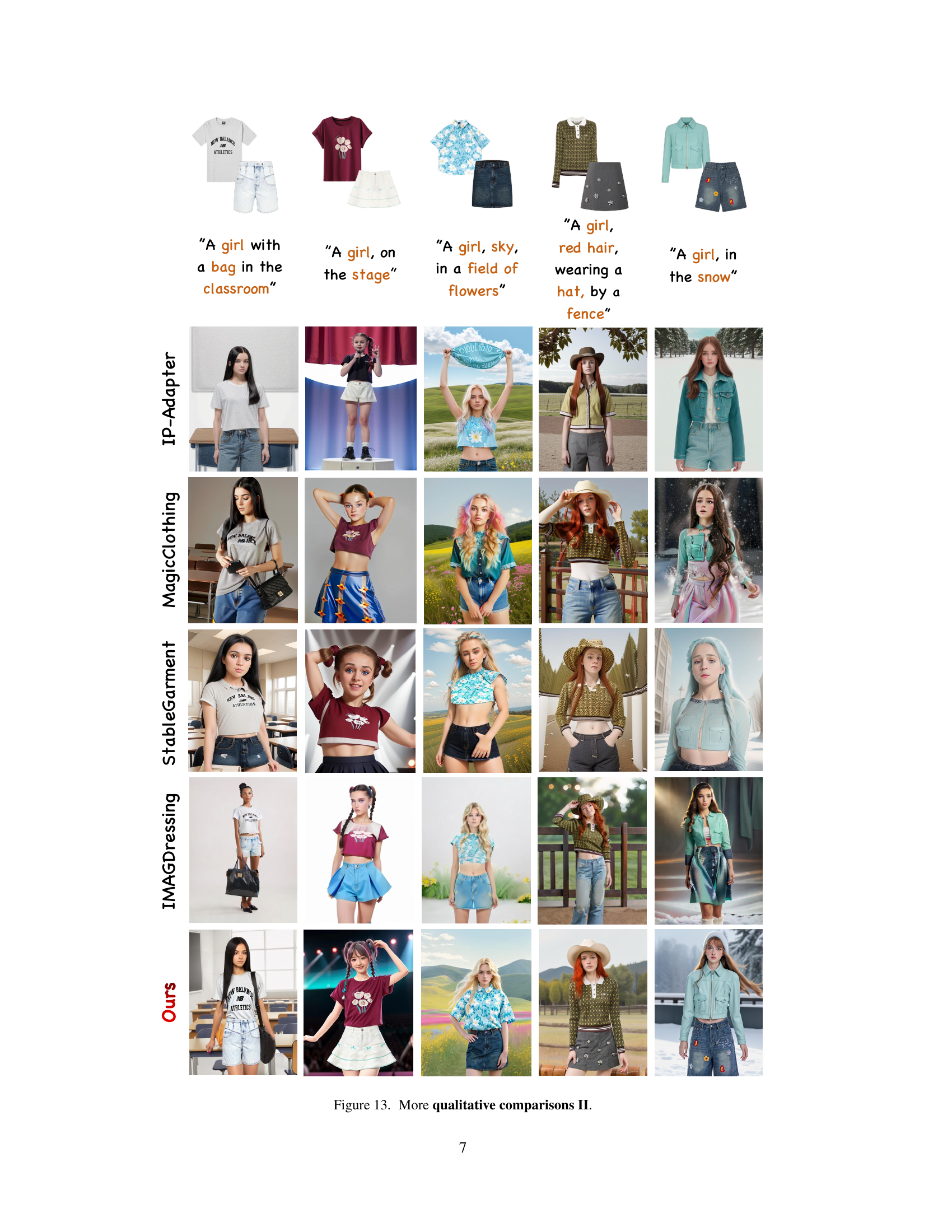
🔼 Figure 13 presents more qualitative comparisons between AnyDressing and other state-of-the-art virtual dressing methods. It shows the results of generating images of characters wearing various combinations of clothing items based on text prompts. The figure highlights the differences in clothing style, texture consistency, and overall image quality between AnyDressing and competing methods.
read the caption
Figure 13: More qualitative comparisons II.

🔼 This figure displays more qualitative results of AnyDressing, showcasing the model’s ability to generate diverse and high-quality images across a range of scenarios and garment combinations. Various combinations of clothing items, along with personalized text prompts, demonstrate the model’s ability to maintain consistency in clothing style, texture, and overall image quality while adhering to the specified prompts.
read the caption
Figure 14: More qualitative results I.

🔼 Figure 15 showcases more qualitative results of the AnyDressing model. The figure displays multiple images generated by the model, each showcasing a man dressed in different outfits and poses. The clothing styles are diverse, ranging from casual sportswear to more formal attire. The backgrounds are also varied, depicting settings like a park, city street, office building, and beach. Each set of images uses the same set of garments but with different poses and backgrounds, demonstrating the versatility and control offered by the AnyDressing model in generating varied depictions while maintaining the integrity of the chosen clothing items.
read the caption
Figure 15: More qualitative results II.

🔼 Figure 16 shows additional qualitative results from the AnyDressing model. It presents diverse examples of virtual dressing results generated by the model with various clothing items in various styles and scenarios, showcasing the model’s ability to handle different combinations of clothing items and produce coherent, high-quality results.
read the caption
Figure 16: More qualitative results III.

🔼 This figure showcases the versatility of AnyDressing by demonstrating its seamless integration with ControlNet [55] and FaceID [54]. It displays diverse results generated using AnyDressing, incorporating pose control from ControlNet and identity preservation from FaceID, resulting in a wide range of realistic and stylized virtual dressing outputs.
read the caption
Figure 17: More results of combining ControlNet [55] and FaceID [54].
More on tables
| Method | Texture Consistency ↑ | Align with Prompt ↑ | Image Quality ↑ | Comprehensive Evaluation ↑ |
|---|---|---|---|---|
| IP-Adapter [54] | 0.45% | 6.65% | 11.95% | 2.20% |
| StableGarment [47] | 1.60% | 4.85% | 2.65% | 2.05% |
| MagicClothing [4] | 2.05% | 9.00% | 9.70% | 3.75% |
| IMAGDressing [40] | 2.10% | 2.50% | 3.90% | 1.70% |
| Ours | 93.80% | 77.00% | 71.80% | 90.30% |
🔼 This table presents the results of a user study comparing AnyDressing to several baseline methods for multi-garment virtual dressing. Users were shown sets of images generated by each method for various prompts and asked to rate them across several aspects: consistency with the reference garments, alignment with the prompt, overall image quality, and a comprehensive evaluation combining these aspects. The results show a significant preference for AnyDressing across all evaluation criteria.
read the caption
Table 2: User study with baseline methods.
| Texture | Consistency ↑ |
|---|
🔼 This table presents the results of an ablation study conducted on the AnyDressing model. It shows the impact of removing or adding different components of the model on its performance, as measured by CLIP-T, CLIP-I*, and CLIP-AS scores. The components tested are: Garment-Specific Feature Extractor (GFE), Instance-Level Garment Localization (IGL), and Garment-Enhanced Texture Learning (GTL). The table helps to understand the contribution of each module to the overall performance of the model and identify which modules are most crucial for achieving good results.
read the caption
Table 3: Ablation study of AnyDressing.
Full paper#