↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-guided image editing methods are slow due to their multi-step diffusion processes, hindering real-world applications. This slowness results from the time-consuming inversion and sampling steps involved. Existing few-step methods, while faster, still don’t reach the speed needed for real-time applications.
SwiftEdit solves this by introducing a novel one-step inversion framework and a mask-guided editing technique with an attention rescaling mechanism. This approach enables instant text-guided image editing (in 0.23 seconds), significantly outperforming existing methods while maintaining competitive editing quality. The method is demonstrated to be effective and efficient through extensive experiments, highlighting its potential for practical use.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SwiftEdit, a groundbreaking approach to text-guided image editing that is significantly faster than existing methods. This advancement has the potential to revolutionize various applications, such as real-time editing tools and on-device image manipulation. Its novel one-step inversion framework and mask-guided editing technique open exciting new avenues for research in efficient image manipulation and on-device AI.
Visual Insights#

🔼 This figure showcases SwiftEdit’s ability to perform fast and localized image edits using only text prompts. It eliminates the need for users to manually define masks. Three example edits are shown, highlighting the diverse range of editing tasks SwiftEdit can handle. The speed of the process is emphasized: each edit takes only 0.23 seconds on a single A100 GPU. The examples demonstrate editing actions such as changing objects within an image (apples to puppies), changing the scene (forest to sea), and modifying object attributes (closed mouth to open mouth). This visually demonstrates the core functionality and efficiency of SwiftEdit.
read the caption
Figure 1: SwiftEdit empowers instant, localized image editing using only text prompts, freeing users from the need to define masks. In just 0.23 seconds on a single A100 GPU, it unlocks a world of creative possibilities demonstrated across diverse editing scenarios.
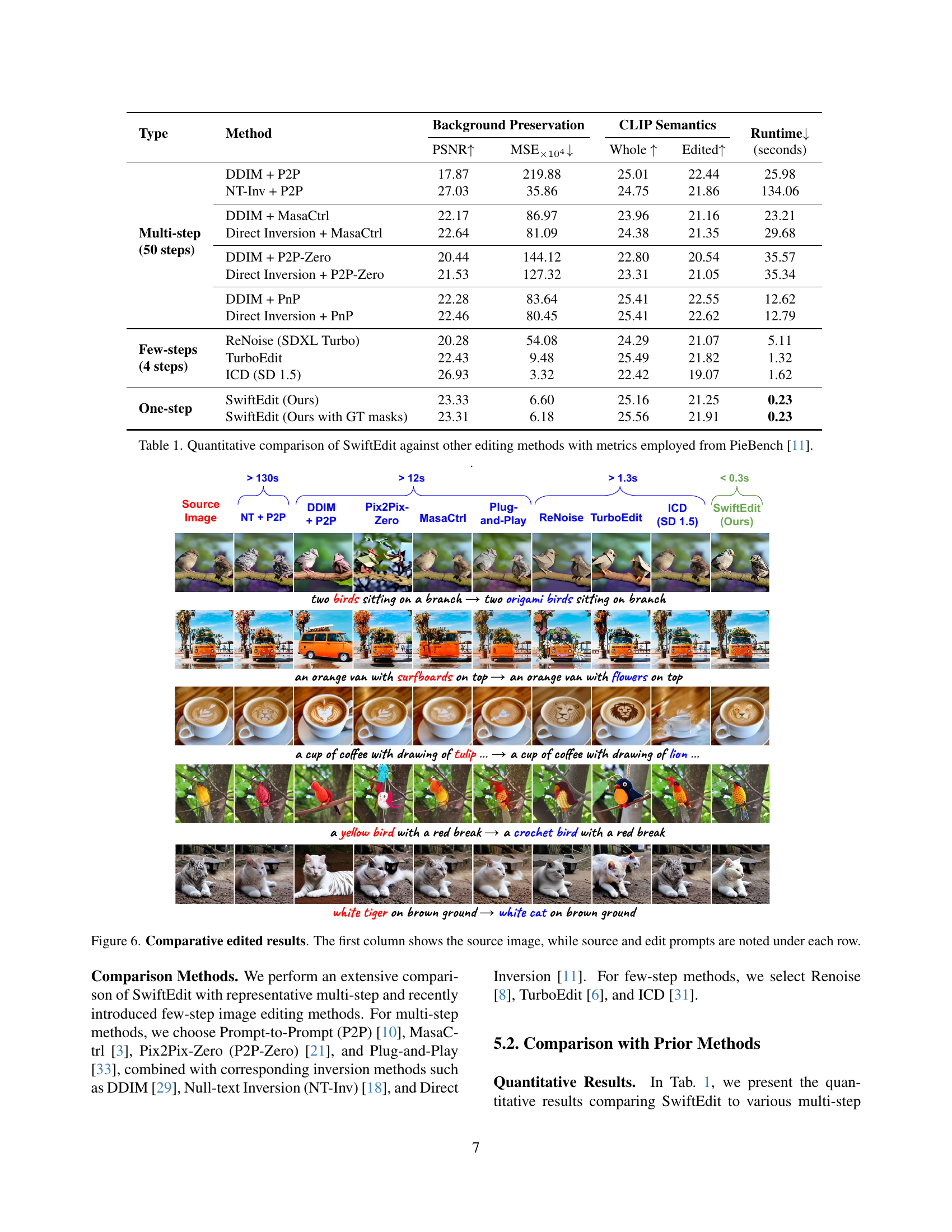
| Type | Method | Background Preservation PSNR ↑ | Background Preservation MSE ↓ × 10⁴ | CLIP Semantics Whole ↑ | CLIP Semantics Edited ↑ | Runtime (seconds) ↓ |
|---|---|---|---|---|---|---|
| Multi-step (50 steps) | DDIM + P2P | 17.87 | 219.88 | 25.01 | 22.44 | 25.98 |
| NT-Inv + P2P | 27.03 | 35.86 | 24.75 | 21.86 | 134.06 | |
| DDIM + MasaCtrl | 22.17 | 86.97 | 23.96 | 21.16 | 23.21 | |
| Direct Inversion + MasaCtrl | 22.64 | 81.09 | 24.38 | 21.35 | 29.68 | |
| DDIM + P2P-Zero | 20.44 | 144.12 | 22.80 | 20.54 | 35.57 | |
| Direct Inversion + P2P-Zero | 21.53 | 127.32 | 23.31 | 21.05 | 35.34 | |
| DDIM + PnP | 22.28 | 83.64 | 25.41 | 22.55 | 12.62 | |
| Direct Inversion + PnP | 22.46 | 80.45 | 25.41 | 22.62 | 12.79 | |
| Few-steps (4 steps) | ReNoise (SDXL Turbo) | 20.28 | 54.08 | 24.29 | 21.07 | 5.11 |
| TurboEdit | 22.43 | 9.48 | 25.49 | 21.82 | 1.32 | |
| ICD (SD 1.5) | 26.93 | 3.32 | 22.42 | 19.07 | 1.62 | |
| One-step | SwiftEdit (Ours) | 23.33 | 6.60 | 25.16 | 21.25 | 0.23 |
| SwiftEdit (Ours with GT masks) | 23.31 | 6.18 | 25.56 | 21.91 | 0.23 |
🔼 This table presents a quantitative comparison of the proposed SwiftEdit method against various other image editing techniques. The comparison uses metrics from the PieBench benchmark [11], specifically focusing on background preservation (PSNR and MSE), and editing semantics (CLIP Whole and CLIP Edited). Runtime is also included, highlighting the speed advantage of SwiftEdit. The methods are categorized into multi-step (50 steps), few-step (4 steps), and one-step approaches, enabling a clear comparison of performance across different methodologies.
read the caption
Table 1: Quantitative comparison of SwiftEdit against other editing methods with metrics employed from PieBench [11].
In-depth insights#
One-Step Inversion#
The concept of ‘One-Step Inversion’ in the context of text-guided image editing is a significant advancement. Traditional methods rely on multi-step diffusion processes, which are computationally expensive and time-consuming. One-step inversion aims to bypass this limitation by directly mapping a source image into the latent space of a pre-trained model in a single step. This drastically reduces the inference time and opens doors for real-time applications. The core challenge lies in effectively inverting one-step diffusion models, as techniques suitable for multi-step models often fail to produce accurate and usable results in a single step. The success of one-step inversion relies heavily on the architecture and training strategy of the inversion network. A two-stage training process, typically using synthetic data for initial training and real images for fine-tuning, appears to be highly effective. Furthermore, incorporating techniques like attention rescaling within the inversion framework allows for fine-grained control over the editing process. This approach helps achieve localized image editing with precise control over background preservation. Therefore, one-step inversion represents a paradigm shift in efficiency and speed for text-guided image editing, paving the way for various real-world applications and user experiences.
Mask-Guided Editing#
Mask-guided editing in image processing leverages masks to spatially constrain edits, ensuring modifications are localized to specific regions. This approach is crucial for preserving the integrity of unaffected areas while selectively altering targeted sections. The precision offered by masks is particularly valuable when dealing with complex images, preventing undesired changes. Effective mask generation, whether manual or automated, is critical for successful mask-guided editing. Automated methods often rely on sophisticated segmentation algorithms to identify regions of interest, while manual approaches offer greater control but require more user effort. The choice between manual and automated methods depends on factors such as image complexity, available tools, and desired level of precision. Beyond simple binary masks, advanced techniques employ more sophisticated mask representations, incorporating concepts such as soft masks or multi-channel masks to allow for finer control over the editing process. Combining mask-guided editing with other image processing techniques, such as inpainting or blending, allows for powerful composite operations. These combined approaches can create highly realistic and effective modifications, especially in applications where maintaining background integrity is paramount.
SwiftEdit Efficiency#
SwiftEdit’s efficiency stems from its novel one-step inversion framework and mask-guided editing technique. Unlike prior multi-step methods, SwiftEdit achieves instant text-guided image editing in just 0.23 seconds on a single A100 GPU, representing at least a 50x speedup. This remarkable speed is attributed to the one-step inversion process that bypasses the computationally expensive multi-step inversion and sampling typically involved. The mask-guided editing, enabled by the attention rescaling mechanism, further enhances efficiency by focusing edits to specified regions, minimizing processing time on irrelevant image areas. The framework’s speed makes it highly practical for real-world applications and on-device deployments, opening exciting possibilities for real-time interactive image editing scenarios. Furthermore, the generalizability of SwiftEdit’s one-step inversion network eliminates the need for domain-specific network training and retraining for different inputs, contributing to overall efficiency. The competitive results demonstrated by SwiftEdit in terms of editing quality alongside this unmatched speed highlights its significant contribution towards efficient text-guided image editing.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a model. In this context, it would likely investigate the impact of the two-stage training process, the attention rescaling mechanism (ARM), and the choice of one-step diffusion model (like SwiftBrushv2) on the overall performance of SwiftEdit. The two-stage training, moving from synthetic to real images, is crucial for the model’s ability to generalize to unseen data. Removing either stage would likely demonstrate a decrease in editing quality. The attention rescaling, by controlling editing strength within specified masks, is vital for high-quality edits that preserve background details; disabling it should show a decline in background preservation. Finally, replacing SwiftBrushv2 with other one-step models could assess its suitability and highlight any unique advantages it offers for this task. The ablation study would thus provide concrete evidence of each component’s importance and justify the design choices made in SwiftEdit.
Future Directions#
Future research should explore improving the efficiency and scalability of SwiftEdit. This includes optimizing the inversion network, possibly through architectural innovations or more efficient training methods. Extending SwiftEdit to handle more complex editing tasks, such as object manipulation beyond simple attribute changes, and video editing is crucial. Investigating robustness to diverse image styles and resolutions, and the impact of varying training data composition on model performance, would solidify its reliability. Finally, and critically, thorough examination of the ethical implications and potential for misuse is vital to prevent the technology from being applied harmfully. Addressing issues of bias and ensuring responsible deployment are paramount.
More visual insights#
More on figures

🔼 This figure compares SwiftEdit’s performance against other state-of-the-art image editing methods. It showcases how SwiftEdit, a one-step diffusion-based method, achieves significantly faster editing speeds (runtime) than the multi-step and few-step alternatives while maintaining competitive performance in terms of image quality. Specifically, it measures background preservation using the Peak Signal-to-Noise Ratio (PSNR) and assesses the accuracy of the edits by using the CLIP score. The chart visually demonstrates that SwiftEdit achieves superior results in terms of speed without significant compromise in the quality of the edits.
read the caption
Figure 2: Comparing our one-step SwiftEdit with few-step and multi-step diffusion editing methods in terms of background preservation (PSNR), editing semantics (CLIP score), and runtime. Our method delivers lightning-fast text-guided editing while achieving competitive results.

🔼 This figure illustrates the two-stage training process for a one-step inversion network. Stage 1 uses synthetic data generated by the SwiftBrushv2 model to pre-train the network. This initial training helps the network learn fundamental image features and representations. In Stage 2, the training shifts to real images, allowing the network to adapt to the variations and complexities of real-world data. This two-stage approach enables the network to instantly invert any input image, without requiring further fine-tuning or retraining, achieving efficient and versatile image inversion for various applications.
read the caption
Figure 3: Proposed two-stage training for our one-step inversion framework. In stage 1, we warms up our inversion network on synthetic data generated by SwiftBrushv2. At stage 2, we shift our focus to real images, enabling our inversion framework to instantly invert any input images without additional fine-tuning or retraining.

🔼 This figure compares the inverted noise predicted by the one-step inversion network trained with and without the stage 2 regularization loss. The stage 2 training incorporates real images and a perceptual loss, aiming to improve the quality of reconstruction while maintaining the ability of the model to produce editable noise. The figure visually demonstrates the impact of this additional training on the characteristics of the inverted noise, highlighting the differences that impact image editing capabilities.
read the caption
Figure 4: Comparison of inverted noise predicted by our inversion network when trained without and with stage 2 regularization loss.

🔼 The figure illustrates how the model generates an editing mask. Two noise maps are produced by the inversion network, one using the source prompt and another using the editing prompt. By comparing these two maps, the model automatically identifies regions that need modification, creating a mask (represented as M) to highlight these areas. This mask is then used to guide the editing process, ensuring that edits are only applied to the intended regions while preserving the rest of the image.
read the caption
(a) Self-guided editing mask extraction. Given source and editing prompts, our inversion network predicts two different noise maps, highlighting the editing regions M𝑀Mitalic_M.

🔼 This figure compares image editing results using two different methods: a global scaling approach (varying the global image condition scale sx) and the proposed edit-aware attention rescaling method (ARaM). It demonstrates that ARaM offers better control over the editing process, leading to higher-quality edits with improved background preservation. The figure visually showcases several edited images to highlight the differences between these two approaches.
read the caption
(b) Effect of global scale and our edit-aware scale. Comparison of edited results between varying global image condition scale s𝐱subscript𝑠𝐱s_{{\bf x}}italic_s start_POSTSUBSCRIPT bold_x end_POSTSUBSCRIPT with our ARaM.

🔼 This figure demonstrates how the parameter sy, which controls the strength of the text-based edit, affects the editing outcome. By varying sy, the model can adjust the intensity of the change applied to the image, allowing for fine-grained control over the edit’s impact. Higher values of sy result in more pronounced edits, while lower values produce subtler modifications. The editing mask, which isolates the area to be modified, is assumed to be provided or generated beforehand.
read the caption
(c) Effect of editing strength scale. Visualization of edited results when varying mask-based text-alignment scale sysubscript𝑠𝑦s_{y}italic_s start_POSTSUBSCRIPT italic_y end_POSTSUBSCRIPT.

🔼 Figure 5 demonstrates the Attention Rescaling for Mask-aware Editing (ARaM) technique. ARaM uses a mask (which can be user-provided or automatically generated by the model) to control the influence of the source image features during the editing process. This allows for localized edits while preserving the background. Subfigure (a) shows how the mask is extracted using the difference in inverted noise maps generated with source and edit prompts. Subfigure (b) compares the effects of using a global scaling factor versus ARaM, highlighting the improved preservation of background elements and clearer editing semantics with ARaM. Subfigure (c) illustrates how the editing strength can be further controlled via the scaling factor applied to the mask within the editing region.
read the caption
Figure 5: Illustration of Attention Rescaling for Mask-aware Editing (ARaM). We apply attention rescaling with our self-guided editing mask to achieve local image editing and enable editing strength control.

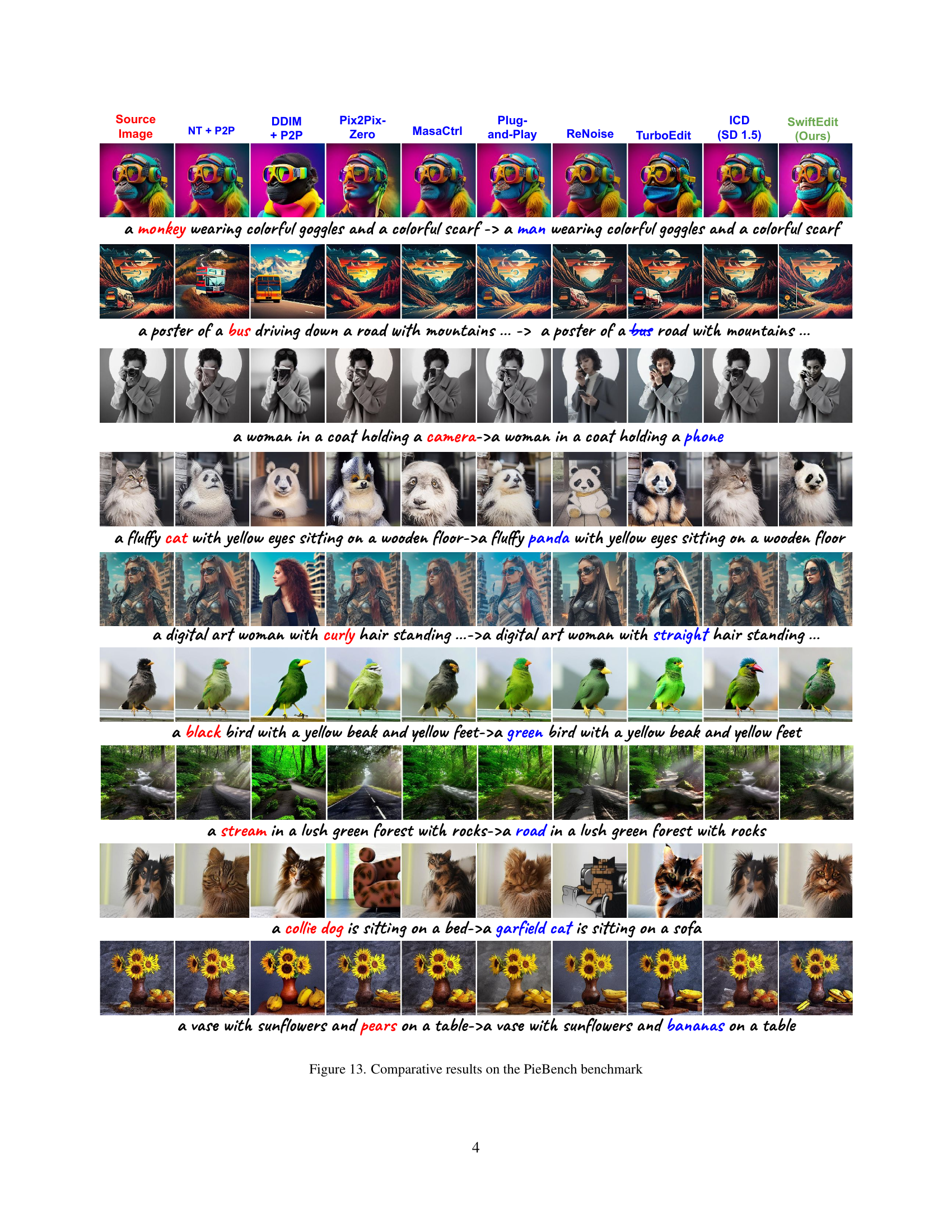
🔼 Figure 6 presents a comparison of image editing results using various methods. Each row showcases a source image and its edits using different techniques: NT + P2P, DDIM + P2P, Pix2Pix-Zero, MasaCtrl, Plug-and-Play, ReNoise, TurboEdit, ICD (SD 1.5), and SwiftEdit (the proposed method). The source and edit prompts used for each method are specified below each image.
read the caption
Figure 6: Comparative edited results. The first column shows the source image, while source and edit prompts are noted under each row.

🔼 This figure presents the results of a user study comparing SwiftEdit with two other image editing methods: Null-text Inversion and TurboEdit. 140 participants evaluated the editing results based on background preservation and editing semantics using 20 random edit prompts from the PieBench dataset. The chart shows the preference rate for each method, demonstrating SwiftEdit’s superior performance.
read the caption
Figure 7: User Study.

🔼 This figure shows qualitative results of using different one-step text-to-image generation models combined with the proposed one-step inversion framework. Each row demonstrates the source image and the edited image results using four different models (InstaFlow, DMDv2, SBv1, SBv2), highlighting how the framework adapts to different model architectures and achieves varied results in image editing across different models.
read the caption
Figure 8: Qualitative results when combining our inversion framework with other one-step text-to-image generation models.

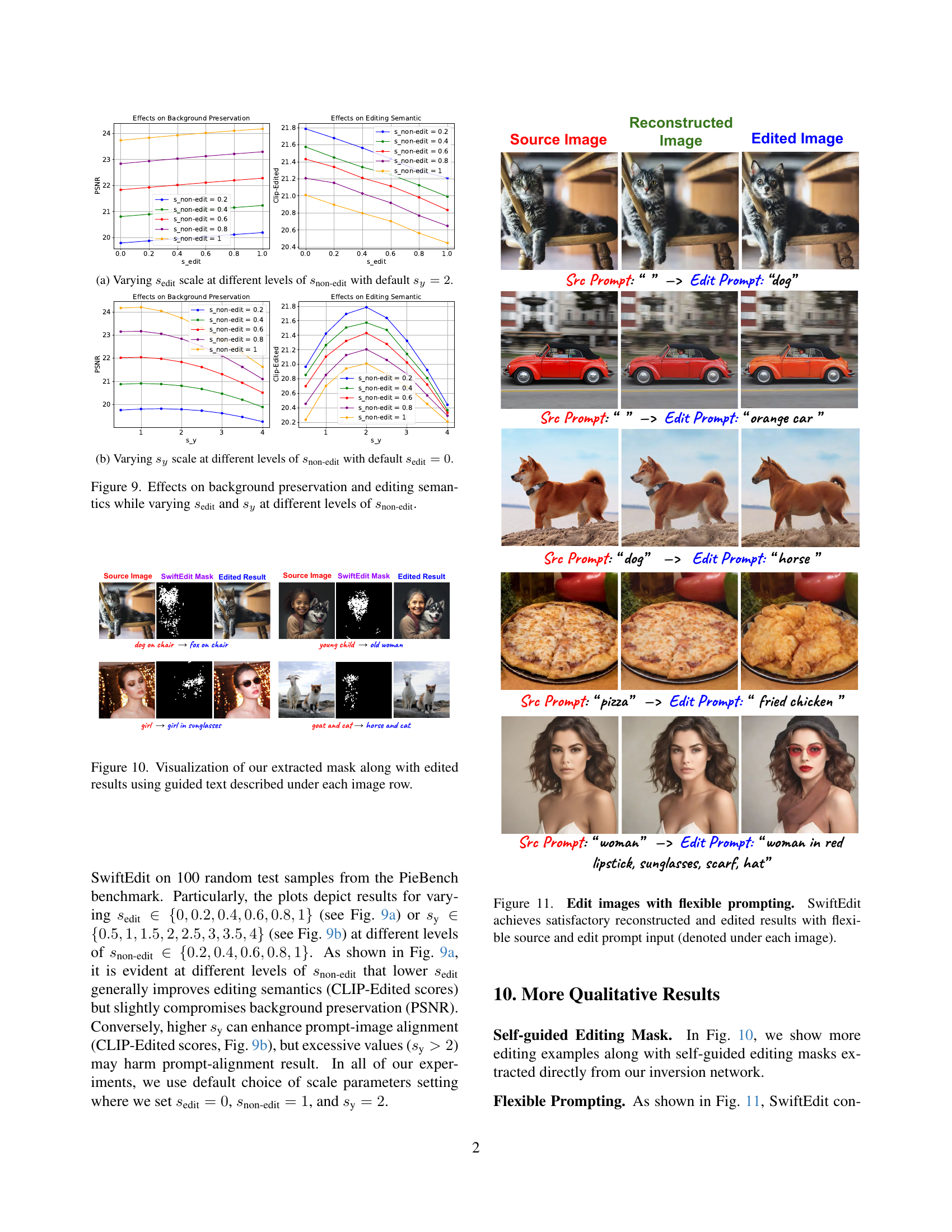
🔼 This figure shows the effect of varying the scale parameter, sedit, on background preservation and editing semantics. The x-axis represents sedit, ranging from 0 to 1. Multiple lines are plotted, each representing a different value of the snon-edit parameter (0.2, 0.4, 0.6, 0.8, and 1). The y-axis on the left shows the PSNR (Peak Signal-to-Noise Ratio), a measure of background preservation, and the y-axis on the right shows the CLIP-Edited score, representing editing semantics. The default value of sy is set to 2. The plot demonstrates the trade-off between background preservation and editing quality as sedit changes for various levels of snon-edit. Specifically, lower sedit values generally lead to better editing semantics but slightly compromise background preservation, whereas higher sedit values enhance background preservation but may not be optimal for edits.
read the caption
(a) Varying seditsubscript𝑠edits_{\text{edit}}italic_s start_POSTSUBSCRIPT edit end_POSTSUBSCRIPT scale at different levels of snon-editsubscript𝑠non-edits_{\text{non-edit}}italic_s start_POSTSUBSCRIPT non-edit end_POSTSUBSCRIPT with default sy=2subscript𝑠𝑦2s_{y}=2italic_s start_POSTSUBSCRIPT italic_y end_POSTSUBSCRIPT = 2.

🔼 This figure shows the effects of varying the scaling factor sy on background preservation and editing semantics at different levels of snon-edit, while keeping sedit constant at 0. It visually demonstrates how changes in sy, which controls the strength of text-image alignment in the editing mask, impact the balance between preserving the original image’s background and achieving the desired edits based on the text prompt. The graph plots PSNR (Peak Signal-to-Noise Ratio), reflecting background preservation quality, and CLIP-Edited score, measuring how well the edits match the prompt’s semantics. Different lines represent different values of snon-edit, illustrating how the interaction between sy and snon-edit affects the overall result.
read the caption
(b) Varying sysubscript𝑠𝑦s_{y}italic_s start_POSTSUBSCRIPT italic_y end_POSTSUBSCRIPT scale at different levels of snon-editsubscript𝑠non-edits_{\text{non-edit}}italic_s start_POSTSUBSCRIPT non-edit end_POSTSUBSCRIPT with default sedit=0subscript𝑠edit0s_{\text{edit}}=0italic_s start_POSTSUBSCRIPT edit end_POSTSUBSCRIPT = 0.

🔼 This figure analyzes the effects of varying the scaling factors
seditandsyon background preservation and editing semantics, while holdingsnon-editconstant at different levels. The plots show how changes insedit(controlling edit strength) andsy(controlling text alignment) impact PSNR (background preservation) and CLIP-Edited scores (editing semantics) under varioussnon-editsettings. The goal is to illustrate the interplay between these factors in achieving a balance between preserving the original image and successfully implementing the edits.read the caption
Figure 9: Effects on background preservation and editing semantics while varying seditsubscript𝑠edits_{\text{edit}}italic_s start_POSTSUBSCRIPT edit end_POSTSUBSCRIPT and sysubscript𝑠𝑦s_{y}italic_s start_POSTSUBSCRIPT italic_y end_POSTSUBSCRIPT at different levels of snon-editsubscript𝑠non-edits_{\text{non-edit}}italic_s start_POSTSUBSCRIPT non-edit end_POSTSUBSCRIPT.

🔼 This figure visualizes the self-guided editing masks generated by the model alongside the corresponding edited images. Each row displays a source image, the generated mask highlighting the areas targeted for editing, and the final edited image. The text below each row provides the original and target prompts, showing how the model interprets and applies the text instructions for image manipulation. The masks illustrate the model’s understanding of which regions need modification to achieve the desired edit based on the text prompts.
read the caption
Figure 10: Visualization of our extracted mask along with edited results using guided text described under each image row.

🔼 Figure 11 showcases SwiftEdit’s capability to handle flexible prompting during image editing. The figure presents several examples where both the source prompt (describing the original image) and the edit prompt (specifying the desired changes) are varied, demonstrating the model’s ability to successfully reconstruct and edit images even with minimal or nuanced descriptions. The results highlight the robustness and flexibility of the SwiftEdit model in responding accurately to different and flexible prompt combinations.
read the caption
Figure 11: Edit images with flexible prompting. SwiftEdit achieves satisfactory reconstructed and edited results with flexible source and edit prompt input (denoted under each image).

🔼 Figure 12 showcases SwiftEdit’s capability to perform face identity and expression editing using simple text prompts. Starting with a single portrait image, various facial identities (e.g., Beckham, Ronaldo) and expressions (e.g., smiling, angry) can be generated by simply providing the desired identity and expression in the text prompt. The entire process is completed in a mere 0.23 seconds, highlighting SwiftEdit’s speed and efficiency.
read the caption
Figure 12: Face identity and expression editing via simple prompts. Given a portrait input image, SwiftEdit can perform a variety of facial identities along with expression editing scenarios guided by simple text within just 0.23 seconds.
More on tables
| Method | PSNR ↑ | LPIPS ↓ × 10³ | MSE ↓ × 10⁴ | SSIM ↑ × 10² |
|---|---|---|---|---|
| w/o stage 1 | 22.26 | 111.57 | 7.03 | 72.39 |
| w/o stage 2 | 17.95 | 305.23 | 17.46 | 55.97 |
| w/o IP-Adapter | 18.57 | 165.78 | 16.11 | 63.87 |
| Full Setting (Ours) | 24.35 | 89.69 | 4.59 | 76.34 |
🔼 This table presents the ablation study results on the effect of different components in the proposed one-step inversion framework on real image reconstruction. It shows the performance of the model with different components removed, such as the first stage of training, the second stage of training, and the IP-Adapter. The metrics used for evaluation are PSNR, LPIPS, MSE, and SSIM. This allows for a quantitative assessment of the contribution of each component to the overall performance of the framework.
read the caption
Table 2: Impact of inversion framework design on real image reconstruction.
| Setting | Whole () | Edited() | ||
|---|---|---|---|---|
| Setting 1 | ✗ | ✗ | 22.91 | 19.07 |
| Setting 2 | ✗ | ✓ | 22.98 | 19.01 |
| Setting 3 | ✓ | ✗ | 24.19 | 20.55 |
| Setting 4 (Full) | ✓ | ✓ | 25.16 | 21.25 |
🔼 This table shows the impact of different loss functions on the editing semantics score in the SwiftEdit model. Specifically, it compares the CLIP scores (Whole and Edited) achieved when including or excluding the reconstruction loss from Stage 1 (Cstage1) and the perceptual and regularization losses from Stage 2 (Cstage2). This demonstrates the contribution of each loss component to the model’s performance in producing edits aligned with text prompts.
read the caption
Table 3: Effect of loss on editing semantics score.
Full paper#