↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) often rely on CLIP-style vision encoders, which have limitations in capturing the full range of visual information. This paper introduces Florence-VL, a new family of MLLMs that uses a generative vision model (Florence-2) to obtain richer visual representations and a novel depth-breath fusion (DBFusion) architecture to effectively integrate these features into pretrained LLMs. The limitations of existing methods are addressed by using multiple visual features at different levels and with diverse prompts to capture more detailed visual information.
Florence-VL demonstrates significant performance improvements over existing MLLMs on various benchmarks, showcasing the effectiveness of the proposed approach. The training recipe and models are open-sourced, promoting further research and development in the field. The depth-breath fusion strategy shows superior performance compared to alternative methods like token and average pooling strategies.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the performance of multimodal large language models (MLLMs) by introducing a novel approach to integrating visual information. The open-sourcing of the models and training recipe also facilitates further research and development in the field, potentially accelerating progress towards more robust and versatile MLLMs.
Visual Insights#
🔼 This figure compares the image encoding methods used in LLaVA-style Multimodal Large Language Models (MLLMs) and the proposed Florence-VL model. LLaVA-style models rely on CLIP, a contrastive learning model, to produce a single, high-level image representation. In contrast, Florence-VL utilizes Florence-2, a generative model, trained on diverse visual tasks (image captioning, OCR, grounding). This allows Florence-VL to extract multiple, task-specific image features tailored to the downstream task, offering greater flexibility and potentially improved performance.
read the caption
Figure 1: Comparison of LLaVA-style MLLMs with our Florence-VL. LLaVA-style models use CLIP, pretrained with contrastive learning, to generate a single high-level image feature. In contrast, Florence-VL leverages Florence-2, pretrained with generative modeling across various vision tasks such as image captioning, OCR, and grounding. This enables Florence-VL to flexibly extract multiple task-specific image features using Florence-2 as the image encoder.
| # Vis tok | MMBench (EN) | POPE | MM-Vet | MME-P | Seed-image | HallusionBench | LLaVA-bench | AI2D | MathVista | MMMU | OCRBench | ChartQA | DocVQA | InfoVQA | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Token Integration | 1728 | 66.6 | 88.7 | 34.1 | 1536.3 | 70.9 | 45.0 | 63.3 | 56.9 | 28.1 | 36.4 | 40.8 | 23.0 | 44.6 | 29.5 | 50.3 |
| Average Pooling | 576 | 65.7 | 88.8 | 32.3 | 1551.3 | 70.3 | 45.7 | 64.6 | 56.6 | 27.4 | 36.0 | 41.2 | 24.6 | 44.8 | 29.3 | 50.4 |
| Channel Integration | 576 | 66.1 | 89.4 | 35.2 | 1543.5 | 70.3 | 46.8 | 65.0 | 57.2 | 28.0 | 35.6 | 41.4 | 24.3 | 44.5 | 29.4 | 50.8 |
🔼 This table presents a comparison of three different strategies for integrating visual features in a multimodal large language model (MLLM): Token Integration, Average Pooling, and Channel Integration. Token Integration concatenates all visual features along the token dimension, leading to a larger number of tokens, increased training time, and slower inference. Average Pooling averages all features, potentially resulting in information loss. Channel Integration concatenates features along the channel dimension, providing an efficient balance of information retention and processing speed. The results show that the Channel Integration method achieves the best performance and training efficiency.
read the caption
Table 1: Experiments for different fusion strategies. The vision token count is 1728 for token integration, which leads to longer training and inference times. The channel integration strategy shows better performance and training efficiency compared to the other two fusion methods.
In-depth insights#
Florence-VL’s Fusion#
Florence-VL’s fusion strategy is a key innovation, integrating visual features from Florence-2, a generative vision model, into pretrained LLMs. Depth-Breadth Fusion (DBFusion) is the core of this, effectively combining visual features extracted from different layers (depth) of Florence-2 and under multiple prompts (breadth). This approach contrasts with the single image-level feature extraction of CLIP-style models. The benefit is richer, more versatile visual representations better suited to diverse downstream tasks. Channel integration, rather than token concatenation or averaging, is used to combine these features efficiently without excessively increasing model size. The fusion process, coupled with a well-designed training recipe involving end-to-end pretraining and finetuning, enables Florence-VL to achieve significant improvements over existing MLLMs across various benchmarks. The careful selection of visual features and the fusion technique are crucial to Florence-VL’s strong performance, highlighting the importance of moving beyond simplistic visual feature extraction in MLLMs.
Generative Vision#
The concept of “Generative Vision” in the context of Vision-Language Models (VLMs) signifies a paradigm shift from traditional discriminative approaches. Instead of merely classifying or labeling images, generative vision models aim to understand and synthesize visual information, producing new images or modifying existing ones based on textual descriptions or other prompts. This capability is crucial for building more sophisticated VLMs capable of nuanced interactions with humans. Florence-VL leverages this generative power, using Florence-2, a generative vision foundation model, to extract multi-faceted visual features. This contrasts sharply with CLIP-style models, which rely on contrastive learning and offer a less versatile, single high-level representation. The depth and breadth of features derived from Florence-2 are key to improved performance across various vision-language tasks. Essentially, generative vision enables VLMs to move beyond simple image-text matching towards true visual understanding and generation, unlocking potential applications in creative content creation, detailed image editing, and advanced visual question answering.
Depth-Breadth Fusion#
The concept of ‘Depth-Breadth Fusion’ in the context of vision-language models is a novel approach to leverage the richness of visual information. It tackles the limitations of single-level image representations by integrating features from different layers (depth) of a generative vision encoder like Florence-2. This allows the model to capture both high-level semantic understanding and low-level details crucial for various downstream tasks. Simultaneously, it explores multiple prompts (breadth) to obtain a diverse set of visual representations, each specializing in certain aspects of the image. The fusion strategy, effectively combining these features along the channel dimension, enables the model to achieve a more comprehensive and robust understanding of the visual input. This multifaceted approach surpasses the limitations of traditional methods that rely on single, generic image features, leading to improved performance on diverse vision-language benchmarks.
Benchmark Analysis#
A robust benchmark analysis is crucial for evaluating the performance of any model, especially in the complex domain of vision-language models. The authors should thoroughly detail the selection of benchmarks, justifying their relevance to the model’s capabilities. A diverse set of benchmarks, encompassing various aspects of visual understanding and reasoning (e.g., VQA, image captioning, visual question answering, and object detection), would strengthen the analysis. Furthermore, the choice of baseline models needs careful consideration to ensure fair comparison. The results should be presented transparently, with clear visualizations to aid interpretation. Statistical significance testing is important to determine if observed differences are meaningful. Finally, a discussion of limitations of the chosen benchmarks and potential biases is essential for a comprehensive analysis, promoting future research and improvement in benchmark design.
Future Enhancements#
Future enhancements for Florence-VL could significantly improve its capabilities. One key area is refining the Depth-Breadth Fusion (DBFusion) strategy. The current concatenation approach, while effective, could be enhanced with more sophisticated fusion techniques that dynamically adjust the balance between depth and breadth based on specific downstream task requirements. Adaptive vision encoders that select features on-the-fly would optimize computational efficiency. Additionally, exploring techniques to dynamically adjust the number of visual tokens used based on image complexity could enhance scalability and performance. Improving alignment between the vision encoder and language model through more advanced training techniques or architectural modifications is another promising direction. Finally, expanding the training data with more diverse and higher-quality datasets would likely boost overall model performance and generalization across different tasks and domains.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architecture of Florence-VL, a multimodal large language model. It begins by using Florence-2, a generative vision model, to extract visual features. Crucially, Florence-2 extracts features at multiple ‘depths’ (different levels of abstraction, from low-level details to high-level concepts) and ‘breadths’ (using various prompts to capture different aspects of the image, such as detailed captions, OCR text, and object grounding). These diverse visual features are then fused using a novel Depth-Breadth Fusion (DBFusion) mechanism. The fused features are finally projected into the input space of a large language model (LLM), allowing for effective multimodal understanding. The entire model is first fully pre-trained on image captioning data before undergoing a partial fine-tuning phase using instruction-tuning data.
read the caption
Figure 2: An overview of Florence-VL, which extracts visual features of different depths (levels of feature concepts) and breaths (prompts) from Florence-2, combines them using DBFusion, and project the fused features to an LLM’s input space. Florence-VL is fully pretrained on image captioning data and then partially finetuned on instruction-tuning data.

🔼 This figure visualizes the effectiveness of Florence-2 in capturing various levels of visual information compared to the CLIP model. PCA was applied to image features generated by Florence-2 using three different prompts: Detailed Caption (focuses on overall scene understanding), OCR (focuses on text extraction), and Grounding (highlights spatial relationships between objects). The results show that Florence-2, unlike CLIP, effectively captures fine-grained details such as text within the image. The visualization clearly demonstrates that Florence-2’s multi-faceted visual representations offer a richer, more nuanced understanding of the image than CLIP’s single high-level representation.
read the caption
Figure 3: Visualization of the first three PCA components: we apply PCA to image features generated from Detailed Caption, OCR, and Grounding prompts, excluding the background by setting a threshold on the first PCA component. The image features derived from the Detailed Caption prompt (second column) capture the general context of the image, those from the OCR prompt (third column) focus primarily on text information, and those from the Grounding prompt (fourth column) highlight spatial relationships between objects. Additionally, we visualize the final layer features from OpenAI CLIP (ViT-L/14@336) in the last column, showing that CLIP features often miss certain region-level details, such as text information in many cases.

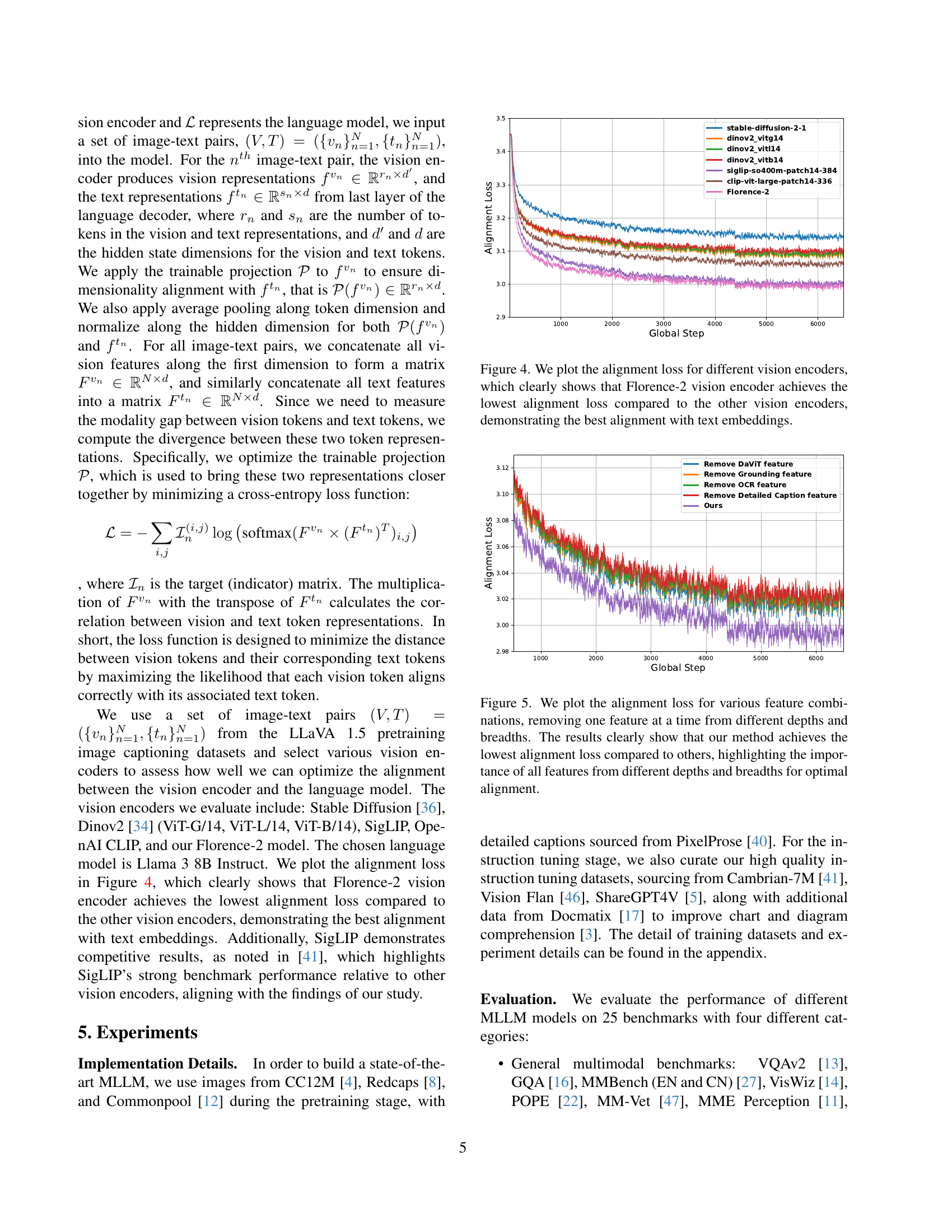
🔼 This figure presents a comparison of the alignment loss between various vision encoders and a language model. The alignment loss is a measure of how well the visual representations from the encoder align with the textual representations from the language model. Lower alignment loss indicates better alignment. The results show that Florence-2 achieves the lowest alignment loss, indicating the strongest alignment between its visual features and text embeddings compared to other vision encoders like Stable Diffusion, DINOv2, SigLIP, and OpenAI CLIP.
read the caption
Figure 4: We plot the alignment loss for different vision encoders, which clearly shows that Florence-2 vision encoder achieves the lowest alignment loss compared to the other vision encoders, demonstrating the best alignment with text embeddings.

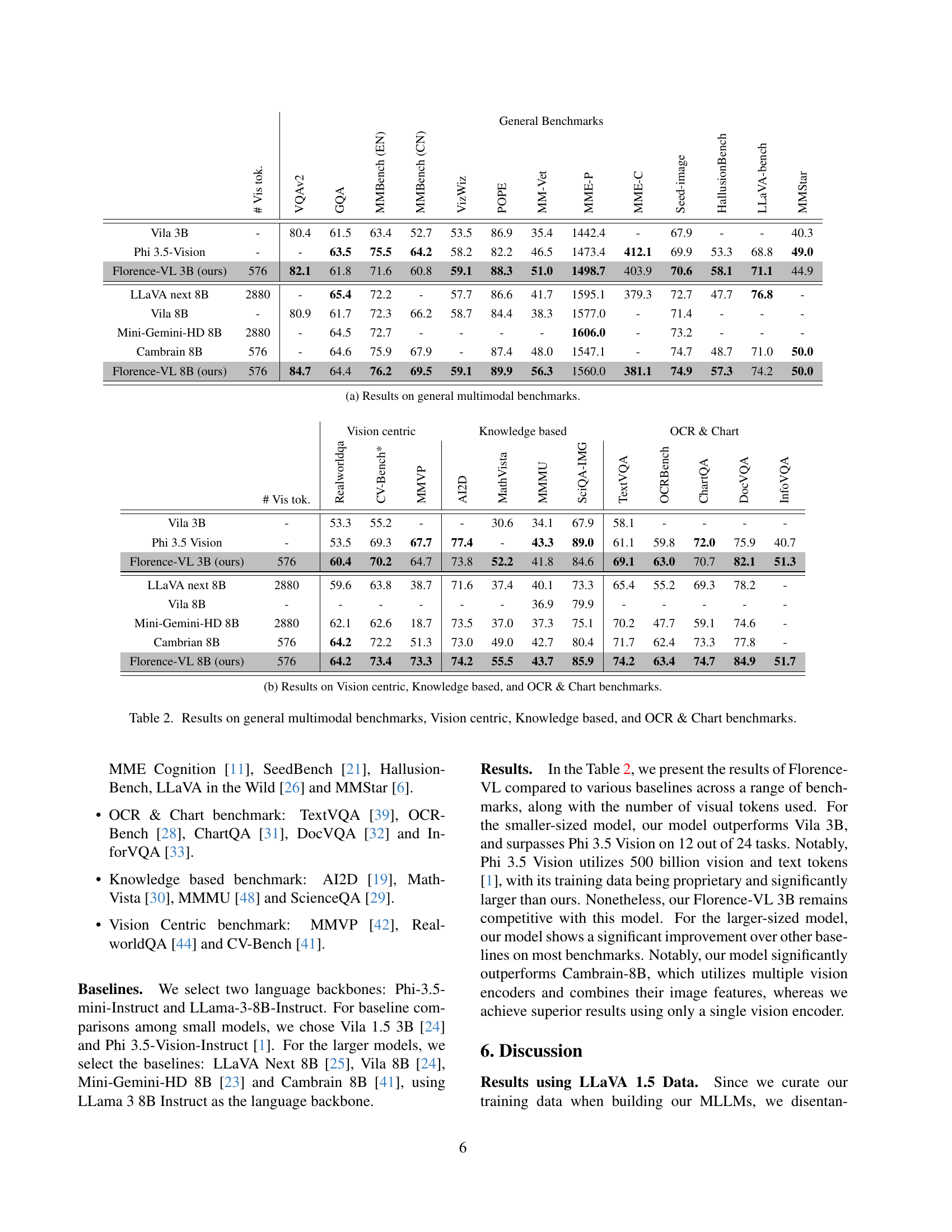
🔼 Figure 5 shows the results of an ablation study on the impact of different visual features on the alignment loss between vision and text representations in a multimodal large language model. Four sets of visual features (using different combinations of depth and breadth of features) are compared: the complete set of features, and the sets that remove either the detailed caption features, OCR features, or grounding features. The graph clearly demonstrates that the combination of all features results in the lowest alignment loss, underscoring the importance of combining features from both different depths (levels of detail) and breadths (various tasks) for optimal cross-modal alignment and model performance.
read the caption
Figure 5: We plot the alignment loss for various feature combinations, removing one feature at a time from different depths and breadths. The results clearly show that our method achieves the lowest alignment loss compared to others, highlighting the importance of all features from different depths and breadths for optimal alignment.
More on tables
| # Vis tok. | VQAv2 | GQA | MMBench (EN) | MMBench (CN) | VizWiz | POPE | MM-Vet | MME-P | MME-C | Seed-image | HallusionBench | LLaVA-bench | MMStar | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vila 3B | - | 80.4 | 61.5 | 63.4 | 52.7 | 53.5 | 86.9 | 35.4 | 1442.4 | - | 67.9 | - | - | 40.3 |
| Phi 3.5-Vision | - | - | 63.5 | 75.5 | 64.2 | 58.2 | 82.2 | 46.5 | 1473.4 | 412.1 | 69.9 | 53.3 | 68.8 | 49.0 |
| Florence-VL 3B (ours) | 576 | 82.1 | 61.8 | 71.6 | 60.8 | 59.1 | 88.3 | 51.0 | 1498.7 | 403.9 | 70.6 | 58.1 | 71.1 | 44.9 |
| LLaVA next 8B | 2880 | - | 65.4 | - | - | 57.7 | 86.6 | 41.7 | 1595.1 | 379.3 | 72.7 | 47.7 | 76.8 | - |
| Vila 8B | - | 80.9 | 61.7 | 72.3 | 66.2 | 58.7 | 84.4 | 38.3 | 1577.0 | - | 71.4 | - | - | - |
| Mini-Gemini-HD 8B | 2880 | - | 64.5 | - | - | - | - | - | 1606.0 | - | 73.2 | - | - | - |
| Cambrain 8B | 576 | - | 64.6 | 75.9 | 67.9 | - | 87.4 | 48.0 | 1547.1 | - | 74.7 | 48.7 | 71.0 | 50.0 |
| Florence-VL 8B (ours) | 576 | 84.7 | 64.4 | 76.2 | 69.5 | 59.1 | 89.9 | 56.3 | 1560.0 | 381.1 | 74.9 | 57.3 | 74.2 | 50.0 |
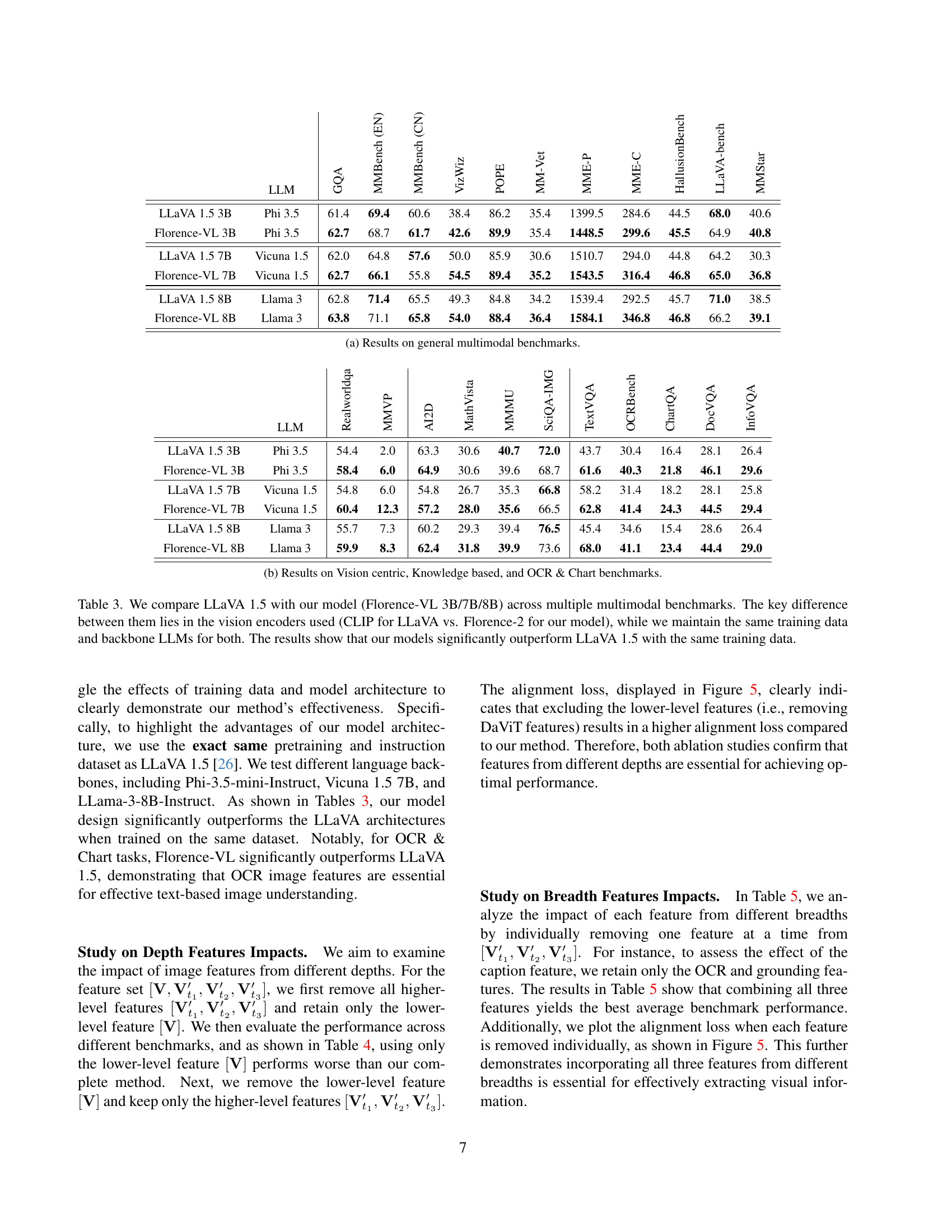
🔼 This table presents the performance comparison of different vision-language models on a range of general multimodal benchmarks. The benchmarks assess various aspects of visual understanding and reasoning capabilities. The models are evaluated based on their accuracy across the benchmarks, providing a comprehensive overview of their strengths and weaknesses. The table includes metrics that quantify the models’ performance on different tasks.
read the caption
(a) Results on general multimodal benchmarks.
| # Vis tok. | Realworldqa | CV-Bench* | MMVP | AI2D | MathVista | MMMU | SciQA-IMG | TextVQA | OCRBench | ChartQA | DocVQA | InfoVQA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vila 3B | - | 53.3 | 55.2 | - | - | 30.6 | 34.1 | 67.9 | 58.1 | - | - | - | - |
| Phi 3.5 Vision | - | 53.5 | 69.3 | 67.7 | 77.4 | - | 43.3 | 89.0 | 61.1 | 59.8 | 72.0 | 75.9 | 40.7 |
| Florence-VL 3B (ours) | 576 | 60.4 | 70.2 | 64.7 | 73.8 | 52.2 | 41.8 | 84.6 | 69.1 | 63.0 | 70.7 | 82.1 | 51.3 |
| LLaVA next 8B | 2880 | 59.6 | 63.8 | 38.7 | 71.6 | 37.4 | 40.1 | 73.3 | 65.4 | 55.2 | 69.3 | 78.2 | - |
| Vila 8B | - | - | - | - | - | - | 36.9 | 79.9 | - | - | - | - | - |
| Mini-Gemini-HD 8B | 2880 | 62.1 | 62.6 | 18.7 | 73.5 | 37.0 | 37.3 | 75.1 | 70.2 | 47.7 | 59.1 | 74.6 | - |
| Cambrian 8B | 576 | 64.2 | 72.2 | 51.3 | 73.0 | 49.0 | 42.7 | 80.4 | 71.7 | 62.4 | 73.3 | 77.8 | - |
| Florence-VL 8B (ours) | 576 | 64.2 | 73.4 | 73.3 | 74.2 | 55.5 | 43.7 | 85.9 | 74.2 | 63.4 | 74.7 | 84.9 | 51.7 |
🔼 Table 2b presents the performance comparison of various Multimodal Large Language Models (MLLMs) across a range of vision-centric, knowledge-based, and OCR & Chart tasks. It shows the results for different models, including Florence-VL (with both 3B and 8B parameter variants), along with several baselines and other state-of-the-art models. The table details the performance of each model on multiple benchmarks within each category, offering a comprehensive evaluation of their capabilities in diverse multimodal tasks. This is particularly useful for assessing the specific strengths and weaknesses of each model in different domains.
read the caption
(b) Results on Vision centric, Knowledge based, and OCR & Chart benchmarks.
| LLM | GQA | MMBench (EN) | MMBench (CN) | VizWiz | POPE | MM-Vet | MME-P | MME-C | HallusionBench | LLaVA-bench | MMStar | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA 1.5 3B | Phi 3.5 | 61.4 | 69.4 | 60.6 | 38.4 | 86.2 | 35.4 | 1399.5 | 284.6 | 44.5 | 68.0 | 40.6 |
| Florence-VL 3B | Phi 3.5 | 62.7 | 68.7 | 61.7 | 42.6 | 89.9 | 35.4 | 1448.5 | 299.6 | 45.5 | 64.9 | 40.8 |
| LLaVA 1.5 7B | Vicuna 1.5 | 62.0 | 64.8 | 57.6 | 50.0 | 85.9 | 30.6 | 1510.7 | 294.0 | 44.8 | 64.2 | 30.3 |
| Florence-VL 7B | Vicuna 1.5 | 62.7 | 66.1 | 55.8 | 54.5 | 89.4 | 35.2 | 1543.5 | 316.4 | 46.8 | 65.0 | 36.8 |
| LLaVA 1.5 8B | Llama 3 | 62.8 | 71.4 | 65.5 | 49.3 | 84.8 | 34.2 | 1539.4 | 292.5 | 45.7 | 71.0 | 38.5 |
| Florence-VL 8B | Llama 3 | 63.8 | 71.1 | 65.8 | 54.0 | 88.4 | 36.4 | 1584.1 | 346.8 | 46.8 | 66.2 | 39.1 |
🔼 This table presents a comprehensive evaluation of the Florence-VL model across a diverse range of benchmarks. It’s broken down into four categories: general multimodal benchmarks (assessing overall performance across multiple tasks), vision-centric benchmarks (focus on vision-specific capabilities), knowledge-based benchmarks (testing reasoning and factual understanding), and OCR & Chart benchmarks (evaluating performance on text extraction from images and chart understanding). For each category, the table shows the performance of Florence-VL alongside various baseline models (different sizes and architectures), allowing for direct comparisons and highlighting the model’s strengths and weaknesses in different areas.
read the caption
Table 2: Results on general multimodal benchmarks, Vision centric, Knowledge based, and OCR & Chart benchmarks.
| LLM | Realworldqa | MMVP | AI2D | MathVista | MMMU | SciQA-IMG | TextVQA | OCRBench | ChartQA | DocVQA | InfoVQA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA 1.5 3B | Phi 3.5 | 54.4 | 2.0 | 63.3 | 30.6 | 40.7 | 72.0 | 43.7 | 30.4 | 16.4 | 28.1 | 26.4 |
| Florence-VL 3B | Phi 3.5 | 58.4 | 6.0 | 64.9 | 30.6 | 39.6 | 68.7 | 61.6 | 40.3 | 21.8 | 46.1 | 29.6 |
| LLaVA 1.5 7B | Vicuna 1.5 | 54.8 | 6.0 | 54.8 | 26.7 | 35.3 | 66.8 | 58.2 | 31.4 | 18.2 | 28.1 | 25.8 |
| Florence-VL 7B | Vicuna 1.5 | 60.4 | 12.3 | 57.2 | 28.0 | 35.6 | 66.5 | 62.8 | 41.4 | 24.3 | 44.5 | 29.4 |
| LLaVA 1.5 8B | Llama 3 | 55.7 | 7.3 | 60.2 | 29.3 | 39.4 | 76.5 | 45.4 | 34.6 | 15.4 | 28.6 | 26.4 |
| Florence-VL 8B | Llama 3 | 59.9 | 8.3 | 62.4 | 31.8 | 39.9 | 73.6 | 68.0 | 41.1 | 23.4 | 44.4 | 29.0 |
🔼 This table presents the quantitative results of Florence-VL and various baseline models on general multimodal benchmarks. The metrics assess performance across different tasks involving diverse visual and textual inputs. It shows a comparison of the performance of Florence-VL models with varying sizes (3B, 7B, 8B parameters) against other state-of-the-art Multimodal Large Language Models (MLLMs). The benchmarks cover image captioning, question answering, visual reasoning, and other multimodal understanding tasks.
read the caption
(a) Results on general multimodal benchmarks.
| Features used | MMBench (EN) | POPE | MM-Vet | MME-P | Seed-image | HallusionBench | LLaVA-bench | AI2D | MathVista | MMMU | OCRBench | ChartQA | DocVQA | InfoVQA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [\mathbf{V}] | 64.3 | 86.1 | 31.1 | 1510.7 | 66.0 | 44.8 | 64.2 | 54.7 | 26.7 | 35.2 | 31.2 | 18.3 | 27.9 | 25.7 |
| [\mathbf{V},\mathbf{V}{t{1}}^{\prime},\mathbf{V}{t{2}}^{\prime},\mathbf{V}{t{3}}^{\prime}] | 66.1 | 89.4 | 35.2 | 1543.5 | 70.3 | 46.8 | 65.0 | 57.2 | 28.0 | 35.6 | 41.4 | 24.3 | 44.5 | 29.4 |
🔼 Table 2b presents a breakdown of the performance of various models on three categories of benchmarks: Vision-centric, Knowledge-based, and OCR & Chart. Vision-centric tasks focus on visual understanding and perception. Knowledge-based tasks require reasoning and factual knowledge. OCR & Chart tasks involve extracting information from text in images or charts. The table shows the performance (measured as accuracy) of different models—including the Florence-VL models of varying sizes and several baselines—on each benchmark.
read the caption
(b) Results on Vision centric, Knowledge based, and OCR & Chart benchmarks.
| GQA | MMBench (EN) | MMBench (CN) | VizWiz | POPE | MM-Vet | MME-P | MME-C | Seed-image | HallusionBench | LLaVA-bench | MMStar | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Florence-VL 7B | 62.7 | 66.1 | 55.8 | 54.5 | 89.4 | 35.2 | 1543.5 | 316.4 | 70.3 | 46.8 | 65.0 | 36.8 |
| Remove Caption Feature 𝐕′t1 | 62.2 | 64.9 | 56.1 | 53.5 | 89.3 | 31.8 | 1477.8 | 354.3 | 69.0 | 44.9 | 65.2 | 36.0 |
| Remove OCR Feature 𝐕′t2 | 62.0 | 65.6 | 55.4 | 56.0 | 88.8 | 30.2 | 1506.3 | 345.4 | 67.6 | 45.4 | 62.6 | 35.2 |
| Remove Grounding Feature 𝐕′t3 | 63.0 | 66.6 | 56.8 | 56.5 | 88.8 | 32.9 | 1494.8 | 338.9 | 70.8 | 44.7 | 65.1 | 36.2 |
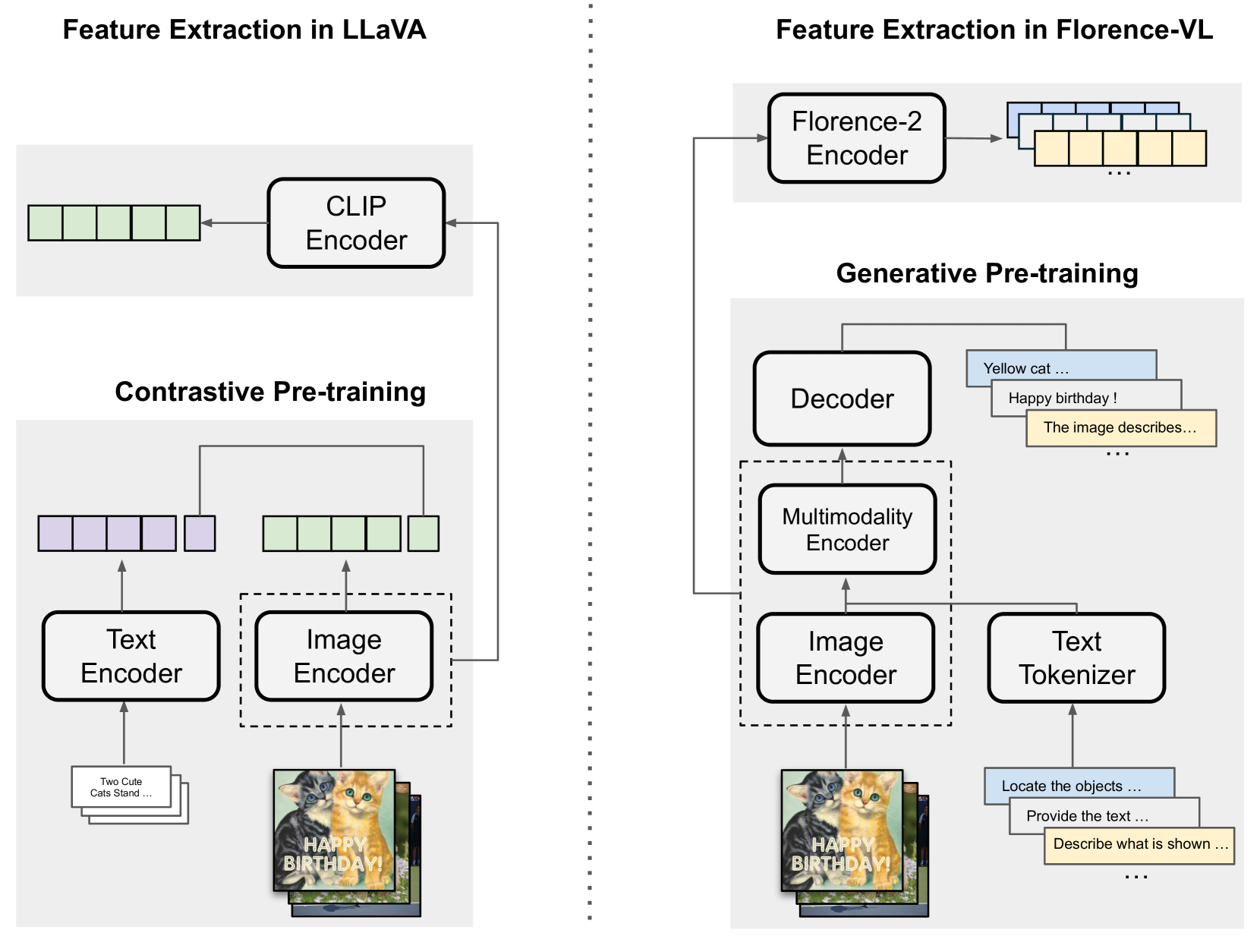
🔼 This table compares the performance of LLaVA 1.5 and Florence-VL (in 3B, 7B, and 8B parameter versions) across a range of multimodal benchmark datasets. The key difference between the models is the vision encoder used: LLaVA 1.5 employs CLIP, while Florence-VL utilizes Florence-2. Importantly, both models were trained using the same training data and underlying large language models (LLMs). The results demonstrate that Florence-VL achieves significantly better performance than LLaVA 1.5, highlighting the advantages of using Florence-2 as the vision encoder.
read the caption
Table 3: We compare LLaVA 1.5 with our model (Florence-VL 3B/7B/8B) across multiple multimodal benchmarks. The key difference between them lies in the vision encoders used (CLIP for LLaVA vs. Florence-2 for our model), while we maintain the same training data and backbone LLMs for both. The results show that our models significantly outperform LLaVA 1.5 with the same training data.
| OCRBench | ChartQA | DocVQA | InfoVQA | Average | |
|---|---|---|---|---|---|
| Florence-VL 7B | 41.4 | 24.3 | 44.5 | 29.4 | 34.9 |
| OCR | 40.9 | 22.9 | 44.4 | 29.0 | 34.2 |
🔼 This table compares the performance of using only lower-level visual features (from the DaViT vision encoder) against using both lower-level and higher-level visual features (from Florence-2). The results show that combining features from different levels (depth) significantly improves the model’s performance across various benchmarks.
read the caption
Table 4: The comparison between keeping only the lower-level feature [𝐕]delimited-[]𝐕[\mathbf{V}][ bold_V ] and our method, which includes both lower- and higher-level features, clearly demonstrates that maintaining both types of features achieves better performance.
| AI2D | MathVista | MMMU | SciQA-IMG | Average | |
|---|---|---|---|---|---|
| Florence-VL 7B | 57.2 | 28.0 | 35.6 | 66.5 | 46.8 |
| Caption | 56.8 | 27.5 | 36.9 | 65.5 | 46.7 |
| OCR | 55.7 | 27.0 | 35.8 | 65.6 | 46.0 |
| Grounding | 56.7 | 27.9 | 36.9 | 66.4 | 47.0 |
🔼 This ablation study investigates the impact of individual high-level visual features extracted by Florence-2 on the overall performance of the Florence-VL model. By systematically removing one high-level feature (Detailed Caption, OCR, Grounding) at a time while keeping other features, the table quantifies the effect on various downstream tasks. The results demonstrate the importance of all three high-level visual features in achieving optimal performance, highlighting the complementary nature of different visual representations.
read the caption
Table 5: Ablation study was conducted by removing one high level image feature at a time, demonstrating that all high-level features are essential for maintaining optimal performance.
Full paper#