↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) struggle with effectively unifying video comprehension and generation. Existing methods often rely on discrete video tokenization, limiting performance. The complex nature of video data, incorporating both spatial and temporal dynamics, poses a significant challenge.
The researchers propose “Divot,” a diffusion-powered video tokenizer. Divot leverages the diffusion process for self-supervised learning of video representations, overcoming the limitations of discrete tokenization. By using a Gaussian Mixture Model (GMM) to represent the continuous video features, Divot-LLM, integrated with a pre-trained LLM, achieves strong performance on various benchmarks, demonstrating effective video comprehension and generation capabilities.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to video tokenization and its integration with LLMs for both comprehension and generation. This addresses a key challenge in multimodal learning, bridging the gap between image-text models and the more complex video domain. The proposed diffusion-based method offers a powerful alternative to existing discrete tokenization techniques, potentially improving the performance of video-related LLMs significantly. Furthermore, the release of the model and code facilitates further research and development in this area.
Visual Insights#

🔼 This figure illustrates the Divot framework, which uses a diffusion model for self-supervised video representation learning. The process begins with a video tokenizer that extracts spatiotemporal features from a video. These features act as conditioning information for a diffusion model, which is trained to remove noise from corrupted video clips. Crucially, because the diffusion model learns to reconstruct the video from noisy input conditioned on the tokenizer’s features, the tokenizer is implicitly learning robust and effective representations of the video. Moreover, the diffusion model itself also acts as a de-tokenizer, enabling the generation of realistic video clips from the learned video representations. This dual functionality of the diffusion model allows for unified video comprehension and generation within a single framework.
read the caption
Figure 1: We utilize the diffusion procedure to learn a video tokenizer in a self-supervised manner for unified comprehension and generation, where the spatiotemporal representations serve as the condition of a diffusion model to de-noise video clips. Additionally, the proxy diffusion model functions as a de-tokenizer to decode realistic video clips from the video representations.
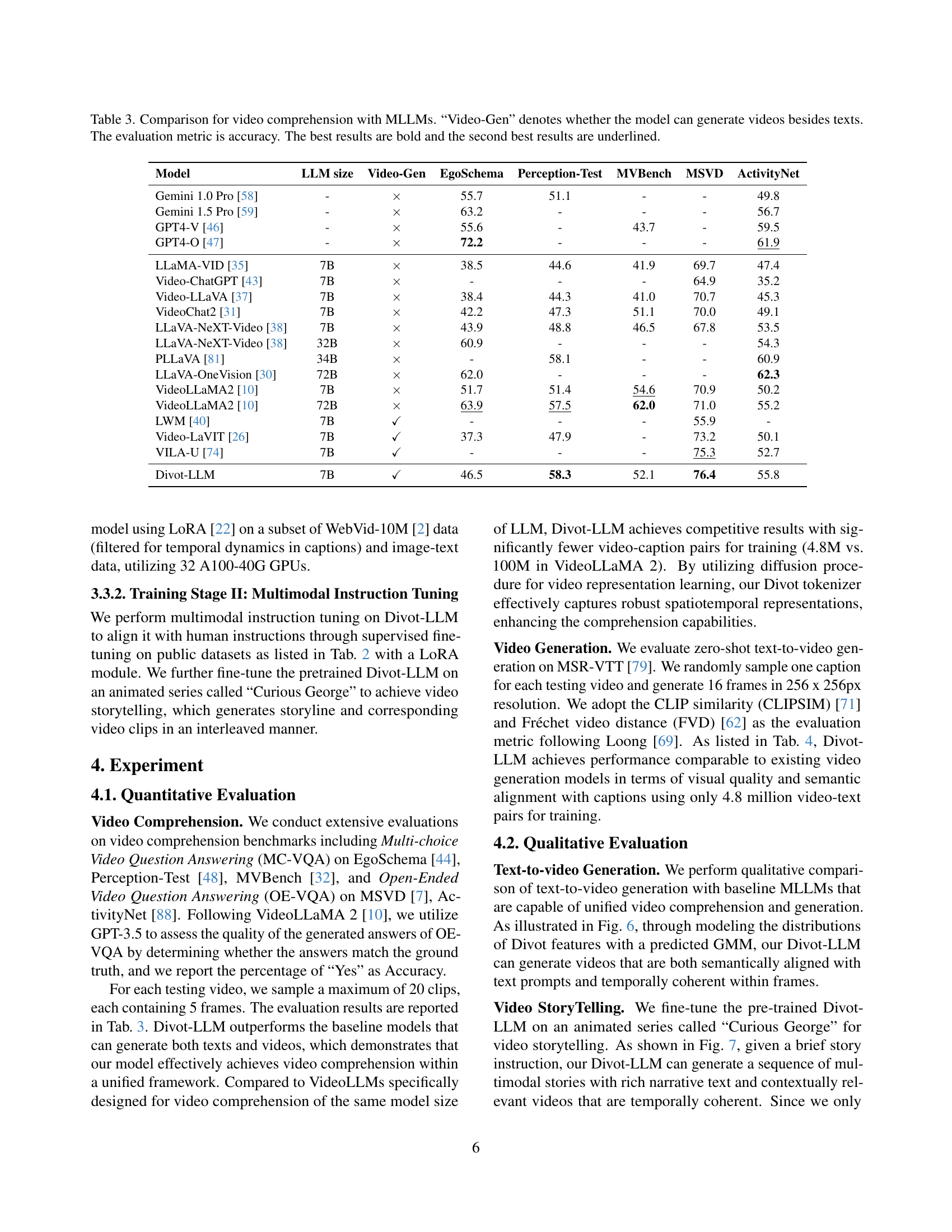
| Model | LLM size | Video-Gen | EgoSchema | Perception-Test | MVBench | MSVD | ActivityNet |
|---|---|---|---|---|---|---|---|
| Gemini 1.0 Pro [58] | - | × | 55.7 | 51.1 | - | - | 49.8 |
| Gemini 1.5 Pro [59] | - | × | 63.2 | - | - | - | 56.7 |
| GPT4-V [46] | - | × | 55.6 | - | 43.7 | - | 59.5 |
| GPT4-O [47] | - | × | 72.2 | - | - | - | 61.9 |
| LLaMA-VID [35] | 7B | × | 38.5 | 44.6 | 41.9 | 69.7 | 47.4 |
| Video-ChatGPT [43] | 7B | × | - | - | - | 64.9 | 35.2 |
| VideoLLaVA [37] | 7B | × | 38.4 | 44.3 | 41.0 | 70.7 | 45.3 |
| VideoChat2 [31] | 7B | × | 42.2 | 47.3 | 51.1 | 70.0 | 49.1 |
| LLaVA-NeXT-Video [38] | 7B | × | 43.9 | 48.8 | 46.5 | 67.8 | 53.5 |
| LLaVA-NeXT-Video [38] | 32B | × | 60.9 | - | - | - | 54.3 |
| PLLaVA [81] | 34B | × | - | 58.1 | - | - | 60.9 |
| LLaVA-OneVision [30] | 72B | × | 62.0 | - | - | - | 62.3 |
| VideoLLaMA2 [10] | 7B | × | 51.7 | 51.4 | 54.6 | 70.9 | 50.2 |
| VideoLLaMA2 [10] | 72B | × | 63.9 | 57.5 | 62.0 | 71.0 | 55.2 |
| LWM [40] | 7B | ✓ | - | - | - | 55.9 | - |
| Video-LaVIT [26] | 7B | ✓ | 37.3 | 47.9 | - | 73.2 | 50.1 |
| VILA-U [74] | 7B | ✓ | - | - | - | 75.3 | 52.7 |
| Divot-LLM | 7B | ✓ | 46.5 | 58.3 | 52.1 | 76.4 | 55.8 |
🔼 This table details the datasets used in training the Divot video tokenizer and the Divot-LLM model. It breaks down the data by training stage (tokenizer training, pre-training of the Divot-LLM, and fine-tuning stages), data type (pure video, video-text, image-text, etc.), and specific dataset names (WebVid-10M, Panda-70M, etc.). This provides context on the types of data used to build both components of the Divot system.
read the caption
Table 2: Datasets used for training the tokenizer and Divot-LLM.
In-depth insights#
Diffusion Video Tokens#
The concept of “Diffusion Video Tokens” represents a significant advancement in video representation learning. It leverages the power of diffusion models to create tokens that capture both spatial and temporal information within video data, unlike traditional methods which often struggle to adequately model temporal dynamics. This approach offers several key benefits. First, the self-supervised nature of diffusion models allows for learning robust representations directly from unlabeled video data, reducing reliance on expensive manual annotations. Second, the continuous nature of these tokens potentially enables more nuanced and expressive representations compared to discrete methods, leading to improved performance in both comprehension and generation tasks. The duality of the diffusion process – acting as both a tokenizer and de-tokenizer – is a crucial advantage. It allows for seamless translation between video and its tokenized representation and enables efficient video generation from text or other prompts.
Divot-LLM: Model#
Divot-LLM represents a novel approach to unifying video comprehension and generation within a Large Language Model (LLM) framework. Its core innovation is the Divot tokenizer, a diffusion-powered system that learns video representations in a self-supervised manner. This tokenizer effectively captures both the spatial and temporal dynamics of videos, addressing a key challenge in prior video-LLM architectures. Unlike discrete tokenizers, Divot utilizes a continuous representation, better suited for nuanced video understanding. The model leverages a pre-trained video diffusion model, acting as both a tokenizer and de-tokenizer, thus facilitating seamless video-to-text and text-to-video transformations. Divot-LLM integrates this tokenizer with a pre-trained LLM, enabling video comprehension via video-to-text autoregression. For video generation, Divot-LLM innovatively models the continuous Divot features using a Gaussian Mixture Model (GMM), avoiding the limitations of simpler regression approaches. This probabilistic modeling enables more diverse and realistic video generation. The combination of a powerful, continuous video tokenizer and a probabilistic generation mechanism makes Divot-LLM a significant advancement in multimodal video understanding and creation.
GMM for Video Gen#
The section ‘GMM for Video Gen’ likely details the application of Gaussian Mixture Models (GMMs) for generating videos. Instead of directly regressing to video features from an LLM, GMMs provide a probabilistic framework. This allows the model to capture the inherent variability and complexity within video data, leading to more realistic and less deterministic video generation. The approach likely involves training the LLM to predict the parameters (means, variances, and mixture probabilities) of a GMM that models the distribution of continuous video representations from a video tokenizer. During inference, sampling from this learned GMM provides the input for a video decoder, potentially a diffusion model, to generate novel video sequences. This probabilistic method addresses the limitations of deterministic regression that produces overly averaged or repetitive outputs, leading to more diverse and natural-looking video generations. The key advantage is the ability to generate diverse videos from a single text prompt, showcasing the power of GMMs in handling the high dimensionality and complex temporal dynamics present in video data. This approach moves beyond simpler methods and tackles the complex problem of high-quality video synthesis.
Ablation Study#
An ablation study systematically removes components of a model to determine their individual contributions. In the context of a video tokenizer, this might involve testing variations of the model architecture, such as removing the spatial-temporal transformer or the Perceiver Resampler. The impact on both video comprehension and generation tasks would be carefully measured to gauge the importance of each component. Results could reveal that, for instance, the spatial-temporal transformer is critical for capturing temporal dynamics, while the Perceiver Resampler is essential for efficient LLM integration. Such insights would guide future model improvements and help understand the strengths and weaknesses of each module. Furthermore, an ablation study might investigate alternative loss functions or training procedures, for example, replacing the GMM with a simpler MSE regression or using a different diffusion model. By comparing results across these variations, researchers can gain a deep understanding of the design choices that impact performance and identify promising areas for optimization. Ultimately, the findings would highlight the robustness and efficiency of the overall approach.
Future Work#
Future work for the Divot model could involve several key areas. Extending the model’s capabilities to longer videos is crucial, as the current model is limited to short clips. Improving the quality and diversity of generated videos is also important, potentially by exploring advanced diffusion models or incorporating more diverse training data. Investigating the use of more powerful LLMs could significantly enhance Divot-LLM’s performance across comprehension and generation tasks. Exploring different architectures for the video tokenizer, beyond the current ViT-based approach, may lead to more efficient and effective representations. Finally, more rigorous benchmarking against a wider range of tasks and datasets, including those focusing on more nuanced aspects of video understanding such as action recognition and temporal reasoning, would further validate the robustness of the model.
More visual insights#
More on figures

🔼 Figure 2 illustrates the Divot model’s tokenization and de-tokenization processes. During training, the model takes sparsely sampled video frames as input to its tokenizer. This tokenizer generates spatiotemporal representations of the video. These representations are then used to condition a U-Net, a type of neural network, which is trained using a self-supervised approach. The U-Net’s task is to remove noise from noisy representations (VAE latents) of densely sampled video frames. The success of the U-Net in denoising is directly tied to how well the tokenizer captures relevant information from the video. In essence, the training process teaches the tokenizer to create effective representations by training the network to reconstruct a high-quality version of the original video based on those representations. Critically, the same U-Net then also functions as a de-tokenizer. During inference (when using the model after training), the tokenizer produces video representations that are passed to the de-tokenizer (which is the same U-Net) to generate realistic video clips.
read the caption
Figure 2: Overview of Divot tokenization and de-tokenization. During training, sparsely sampled video frames are fed into the tokenizer to obtain spatiotemporal representations. These representations serve as the conditions for a U-Net, which is trained to de-noise the noisy VAE latents of densely sampled video frames. During inference, the video representations from the Divot tokenizer can be decoded into realistic video clips with the U-Net.

🔼 Divot-LLM uses the Divot tokenizer to feed video features into a pre-trained language model (LLM). For video comprehension, next-word prediction is performed on video-caption data. Video generation is achieved by using learnable queries within the LLM to model the distribution of Divot features using a Gaussian Mixture Model (GMM). During inference, video features are sampled from this GMM and used by the de-tokenizer to generate video clips.
read the caption
Figure 3: Overview of Divot-LLM. Video features from the Divot tokenizer are fed into the LLM to perform next-word prediction for video comprehension, while learnable queries are input into the LLM to model the distributions of Divot features using a Gaussian Mixture Model (GMM) for video generation. During inference, video features are sampled from the predicted GMM distribution to decode videos using the de-tokenizer.

🔼 Figure 4 illustrates three different approaches for using a large language model (LLM) to generate videos based on video representations from the Divot tokenizer. (a) MSE Regression: The LLM directly predicts video features, with training focused on minimizing the difference between the prediction and the actual features using mean squared error. (b) Diffusion Modeling: The LLM output is used as a condition for a denoising network; this network aims to predict the noise added to the video features during a diffusion process. (c) GMM Modeling: The LLM predicts the parameters (means, variances, and mixture probabilities) of a Gaussian Mixture Model (GMM), which models the probability distribution of the video features. This probabilistic approach is designed to better capture the diversity of video features.
read the caption
Figure 4: Paradigms for modeling video representations from the Divot tokenizer with a LLM for video generation. (a) MSE Regression, where the LLM output is trained to minimize its distance with video features using Mean Squared Error (MSE) loss; (b) Diffusion Modeling, where the LLM output is fed into a denoising network as the condition to predict the noise added to video features; (c) GMM Modeling, where the LLM output is trained to predict the parameters of a Gaussian Mixture Model (GMM) for modeling video feature distributions.

🔼 Figure 5 showcases the reconstruction capabilities of the Divot model. The Divot tokenizer processes sparsely sampled video frames (low frame rate) to extract spatiotemporal features, which capture both the spatial information of the individual frames and the temporal dynamics across the sequence. These features, acting as a compressed representation of the video, are then fed into a de-tokenizer (part of the Divot framework). The de-tokenizer reconstructs a higher frame rate video. The reconstructed video maintains the semantic content of the original, while demonstrating temporal coherence and alignment with the original video’s meaning.
read the caption
Figure 5: Reconstructed videos, where the Divot tokenizer obtains spatiotemporal representations of sparsely sampled video frames and the de-tokenizer decodes these representations into semantically aligned and temporally coherent video clips.

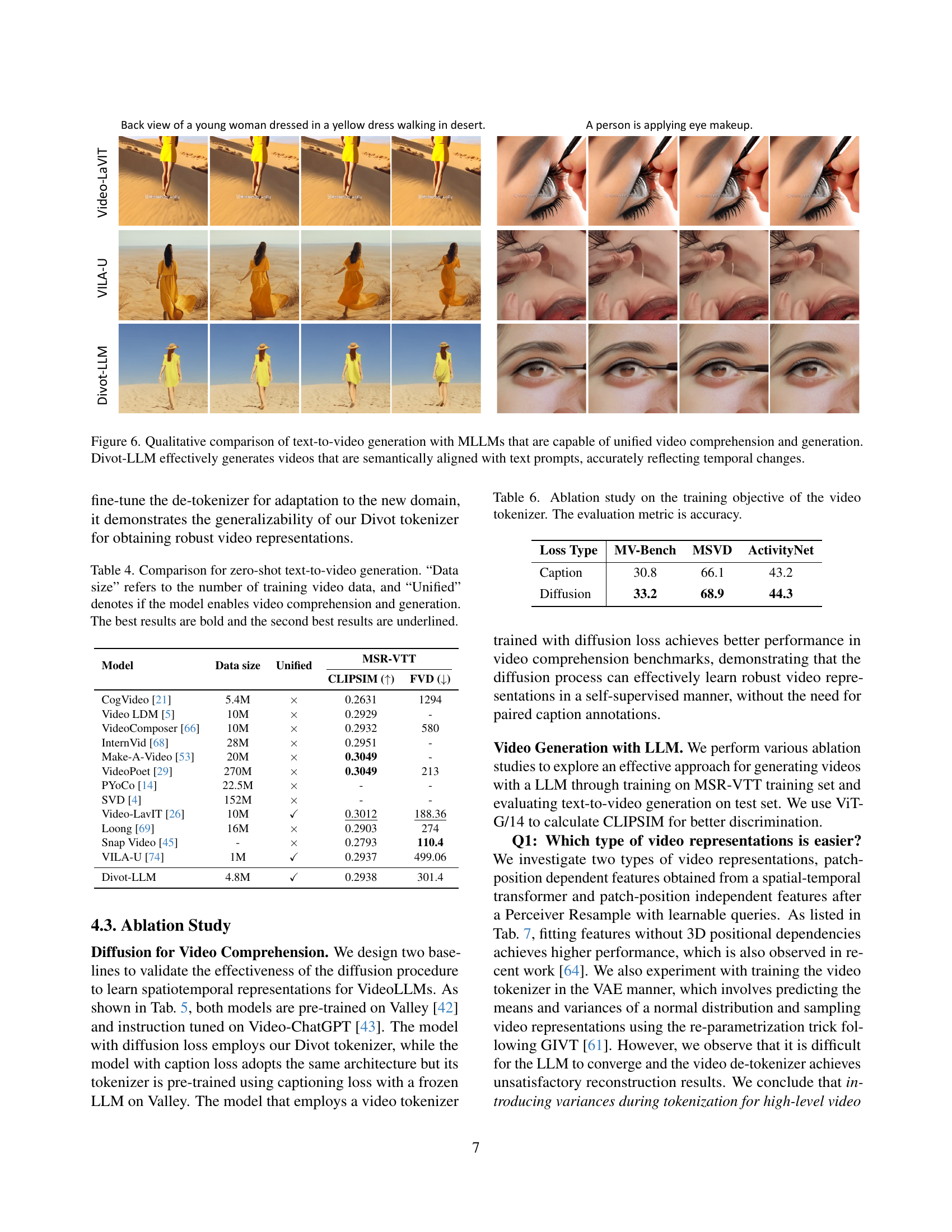
🔼 Figure 6 presents a qualitative comparison of video generation capabilities between Divot-LLM and other state-of-the-art Multimodal Large Language Models (MLLMs). The figure showcases example video clips generated from text prompts by various models. The key takeaway is that Divot-LLM produces videos which closely match the semantics of the input text, and also accurately reflect the temporal progression and changes described in the prompts. This demonstrates Divot-LLM’s ability to seamlessly unify video comprehension and generation.
read the caption
Figure 6: Qualitative comparison of text-to-video generation with MLLMs that are capable of unified video comprehension and generation. Divot-LLM effectively generates videos that are semantically aligned with text prompts, accurately reflecting temporal changes.

🔼 Figure 7 showcases the video storytelling capabilities of the Divot-LLM model. Given a short story prompt, the model generates a sequence of interleaved text and video segments that tell a cohesive story. The video clips are contextually relevant to the narrative and temporally coherent, demonstrating the model’s ability to integrate visual and textual content in a dynamic and meaningful way.
read the caption
Figure 7: Qualitative examples of video storytelling by Divot-LLM. Given a story instruction, Divot-LLM can generate rich textual narratives along with corresponding video clips that are temporally coherent in an interleaved manner.

🔼 Figure 8 showcases the video reconstruction capabilities of the Divot model. The left column displays sparsely sampled input video frames (at 2 frames per second). The Divot tokenizer processes these frames to extract spatiotemporal representations, which capture both spatial details and temporal dynamics. These representations are then fed into the de-tokenizer (a denoising U-Net), which reconstructs the video at a higher frame rate (8 fps), resulting in the semantically and temporally coherent video clips shown in the right column. The reconstruction demonstrates the model’s ability to generate realistic and detailed videos from limited input information.
read the caption
Figure 8: More qualitative examples of reconstructed videos, where the Divot tokenizer obtains spatiotemporal representations of sparsely sampled video frames and the de-tokenizer decodes these representations into semantically aligned and temporally coherent video clips.

🔼 Figure 9 showcases several examples of videos generated by the Divot-LLM model in response to text prompts. The model successfully produces videos that accurately reflect the textual descriptions while maintaining temporal consistency throughout each video. The visual quality of the videos is high, and the scenes depicted change smoothly over time, demonstrating the model’s ability to both understand and generate coherent video narratives.
read the caption
Figure 9: More qualitative examples of text-to-video generation by Divot-LLM, which effectively generates videos that are both semantically aligned with text prompts and temporally coherent across frames.

🔼 Figure 10 showcases Divot-LLM’s video comprehension capabilities through qualitative examples. It demonstrates the model’s ability to accurately answer questions about video content, including details about object appearance, actions, and unusual events. The examples highlight the model’s nuanced understanding of the temporal sequence and the overall context within video clips.
read the caption
Figure 10: Qualitative examples of video comprehension by Divot-LLM.
Full paper#