↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Traditional robot learning faces challenges due to the high cost and scarcity of labeled data. This paper introduces Moto, a novel approach that leverages abundant unlabeled video data to overcome these limitations. The core idea is to use latent motion tokens as a bridging “language” to represent motion information in videos, enabling unsupervised pre-training and efficient transfer learning.
Moto employs a two-stage training process. First, a latent motion tokenizer converts video data into latent motion tokens, capturing the essence of visual motion. Second, a generative model, Moto-GPT, is pre-trained to predict the next motion token autoregressively. This pre-training phase allows Moto-GPT to learn rich motion priors from videos. Finally, a co-fine-tuning strategy is used to seamlessly transfer these learned motion priors to real robot actions. The results demonstrate that Moto achieves superior performance in robot manipulation tasks compared to existing methods, especially with limited training data.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to robot learning using a bridging “language” of motion, addressing the limitations of high cost and scarcity of labeled data. It opens up new avenues for pre-training with large-scale video data and transferring knowledge efficiently to downstream tasks. The method demonstrates significant improvement in robot manipulation, achieving superior performance with limited training data compared to existing methods.
Visual Insights#

🔼 The figure illustrates the Moto framework, which uses latent motion tokens as an intermediary representation to bridge video data and robot manipulation. The latent motion tokens are generated from video data using a tokenizer. A model called Moto-GPT is then pre-trained using these tokens to predict the next token in a sequence, learning motion patterns and prior knowledge. This knowledge is then transferred to a robot control policy through co-fine-tuning, enabling robots to perform manipulation tasks more effectively. The figure also shows performance results, indicating significant improvements with the use of the Moto framework.
read the caption
Figure 1: The overview of Moto, which utilizes Latent Motion Tokens as a bridging “language” for autoregressive pretraining on video data. The Moto-GPT pre-trained through next motion token prediction learns a wealth of motion-related prior knowledge from videos, which can be seamlessly transferred to enhance downstream robot manipulation tasks with significant performance gains.
| Component | Parameter | Value |
|---|---|---|
| M-Former | num_queries | 8 |
| num_layers | 4 | |
| hidden_size | 768 | |
| num_heads | 12 | |
| ViT Decoder | patch_size | 16 |
| num_layers | 12 | |
| hidden_size | 768 | |
| num_heads | 12 | |
| VQ Codebook | num_codes | 128 |
| latent_dim | 32 |
🔼 Table 1 provides detailed information about the architecture and hyperparameters of the Latent Motion Tokenizer, a key component of the Moto framework. It breaks down the specific components of the tokenizer (M-Former, ViT Decoder, and VQ Codebook), listing the parameters and their corresponding values. This table is crucial for understanding the design and implementation of the tokenizer, which plays a vital role in converting video data into a latent representation suitable for autoregressive pre-training.
read the caption
Table 1: Implementation details of the Latent Motion Tokenizer.
In-depth insights#
Latent Motion Tokens#
The concept of “Latent Motion Tokens” presented in the research paper offers a novel approach to robot learning. It leverages the power of unsupervised learning by creating a compact representation of visual motion dynamics directly from video data, eliminating the need for expensive and time-consuming labeled datasets. These tokens act as a bridging language, effectively translating the richness of video information into a format suitable for autoregressive pre-training. This pre-training allows a model (Moto-GPT) to acquire a wealth of motion-related knowledge, which is then seamlessly transferred to downstream robotic manipulation tasks via co-fine-tuning. The approach’s strength lies in its focus on motion as the primary learning signal, aligning with the intuitive human way of skill acquisition through observation. This hardware-agnostic representation allows for easier transfer and generalization to different robotic platforms. Furthermore, the interpretability of these tokens adds a significant advantage, providing insights into the model’s learned motion representations and promoting better control over robotic actions. The effectiveness of this approach is demonstrated through superior performance on standard benchmarks, highlighting the value of incorporating latent space representations for robot learning.
Moto-GPT Pretraining#
The Moto-GPT pretraining phase is crucial to Moto’s success, focusing on learning rich motion representations from unlabeled video data. Unsupervised learning is achieved using a novel Latent Motion Tokenizer, which converts video frames into discrete tokens capturing motion dynamics. This clever approach circumvents the high cost and scarcity of labeled data typical in robotics. Autoregressive training of Moto-GPT, using a GPT-style transformer, predicts the next motion token given preceding tokens and initial frame information. This predicts plausible motion trajectories and allows for assessment of their rationality. The model effectively learns diverse motion knowledge and motion priors, acting as a bridge between raw visual input and downstream robot control. Pre-trained Moto-GPT exhibits a strong ability to generate plausible trajectories, which is vital for transferring learned knowledge to robot actions during the subsequent co-fine-tuning stage.
Co-fine-tuning Strategy#
The paper introduces a novel co-fine-tuning strategy to effectively bridge the gap between pre-trained models and real-world robot control. This strategy is crucial because the pre-trained model, Moto-GPT, operates in a latent motion token space, which needs to be translated into actionable commands for a physical robot. The core idea is to seamlessly integrate latent motion token prediction with robot action execution during the fine-tuning phase. This is achieved by concatenating action query tokens with the latent motion tokens as input to Moto-GPT. This co-fine-tuning allows the model to utilize its pre-trained knowledge of motion dynamics while simultaneously learning to map latent tokens to appropriate robot actions. The action query tokens are processed through a separate action head, which predicts low-level actions in the robot’s action space, ensuring precise control. This approach is remarkably effective because it leverages the rich motion priors acquired during the pre-training stage while also adapting the model to the specific demands of robot control. The co-fine-tuning process is carefully designed to maintain the integrity of the pre-trained motion prediction mechanism, enhancing the robustness and efficiency of the robot policy. This is evidenced by superior experimental results across various benchmarks, showing that Moto-GPT significantly outperforms models without the co-fine-tuning stage.
Benchmark Results#
Benchmark results are crucial for evaluating the effectiveness of a new method. In this context, a thoughtful analysis would involve examining the metrics used (e.g., success rate, task completion time, overall performance), comparing the proposed method against existing state-of-the-art approaches, and analyzing the results across different datasets or environments to assess the generalizability of the method. Particular attention should be given to the choice of benchmarks, ensuring they are relevant, challenging, and representative of the target application. A deep dive into the results may uncover strengths and weaknesses of the approach under various conditions, providing insights for future improvements. For instance, are there specific tasks where the proposed method excels, or are there particular challenges where it underperforms? Such insights, when coupled with error analysis, can inform the development of even more robust and effective methods. Robustness and data efficiency are also important considerations to evaluate, shedding light on the practical value and applicability of the technique. Finally, a discussion of limitations adds further credibility to the evaluation, painting a complete picture of the proposed method’s capabilities and areas for improvement.
Future of Moto#
The future of Moto hinges on addressing its limitations and capitalizing on its strengths. Extending the scope of pre-training data beyond robotics-focused videos to encompass a wider range of human actions and interactions could dramatically boost Moto’s generalizability and robustness. This would require careful consideration of data curation and potentially novel training strategies. Improving the efficiency of the Latent Motion Tokenizer is crucial. Reducing the computational cost while maintaining expressive motion representation would make Moto more practical for real-world applications. Developing more sophisticated action prediction models that seamlessly bridge the gap between latent motion tokens and low-level robot control is another key area for development. Integrating advanced planning and reasoning capabilities into Moto’s architecture could also significantly improve its ability to perform complex, multi-step manipulation tasks. Finally, exploring transfer learning scenarios is vital. Can knowledge gained in simulation or from one robot platform be transferred easily and effectively to new platforms and scenarios? Addressing these challenges would pave the way for Moto to become a truly versatile and powerful tool in various fields involving robot manipulation and other forms of dynamic visual data analysis.
More visual insights#
More on figures

🔼 This figure illustrates the three-stage training process of the Moto model. Stage 1 shows the unsupervised training of the Latent Motion Tokenizer, which converts visual motions between video frames into compact latent motion tokens. Stage 2 depicts the autoregressive pre-training of Moto-GPT using these tokens and video instructions to learn motion priors. Finally, Stage 3 shows the co-fine-tuning of Moto-GPT on action-labeled trajectories to predict robot actions. This stage utilizes learnable action query tokens, incorporating the learned motion priors to achieve precise robot control, while simultaneously maintaining the next-motion-token prediction objective.
read the caption
Figure 2: Overview of Moto’s three training stages: (1) The Latent Motion Tokenizer encodes key visual motions between video frames into compact latent tokens in an unsupervised manner using pure video data. (2) Moto-GPT is pre-trained with autoregressive motion token prediction to learn motion priors from video-instruction pairs. (3) Moto-GPT is co-fine-tuned on action-labeled trajectories to predict robot actions based on the output of learnable action query tokens while maintaining the next-motion-token prediction objective.

🔼 The Latent Motion Tokenizer is an autoencoder that takes two consecutive video frames as input. The encoder compresses these frames into a set of discrete latent motion tokens. The decoder then uses these tokens and the first frame to reconstruct the second frame. The process regularizes the decoder to ensure it effectively captures and represents the motion that occurred between the two frames.
read the caption
Figure 3: The Latent Motion Tokenizer produces discrete motion tokens from two consecutive video frames. It regularizes the decoder to reconstruct the second frame based on the first one and the discrete tokens, effectively capturing the motion between frames.

🔼 Figure 4 illustrates the three robot manipulation tasks used to evaluate the performance of different models within the SIMPLER benchmark. These tasks showcase the robot’s ability to perform common manipulation actions. Specifically, the tasks involve: 1) picking up a Coke can in various orientations (horizontal, vertical, and upright); 2) moving a designated object closer to another target object; and 3) opening and closing a drawer. These tasks test the model’s dexterity, planning ability, and object recognition capabilities in a controlled environment.
read the caption
Figure 4: Illustration of the evaluation tasks in SIMPLER [31].

🔼 Figure 5 shows the four distinct environments used in the CALVIN benchmark. Each environment features a table with a sliding door, a drawer, and colored blocks, plus a light bulb controlled by a switch and an LED button. The image highlights how these environmental elements differ in positioning, texture, and overall layout, offering differing challenges for robot manipulation tasks.
read the caption
Figure 5: Illustration of the four different environments in CALVIN, adapted from the original figure in Mees et al. [40].

🔼 This figure shows the reconstruction quality of the Latent Motion Tokenizer. The tokenizer takes two consecutive frames from a video as input. It encodes the motion between these frames into a discrete latent motion token. This token, along with the first frame, is fed into the decoder to reconstruct the second frame. The images in Figure 6 show examples of the original second frame (ground truth), and the frame reconstructed by the decoder, demonstrating the accuracy of the reconstruction.
read the caption
Figure 6: Qualitative examples of reconstruction results, where discrete motion tokens obtained from the Latent Motion Tokenizer based on the initial and next frame, are fed into the decoder along with the initial frame to reconstruct the target frame.

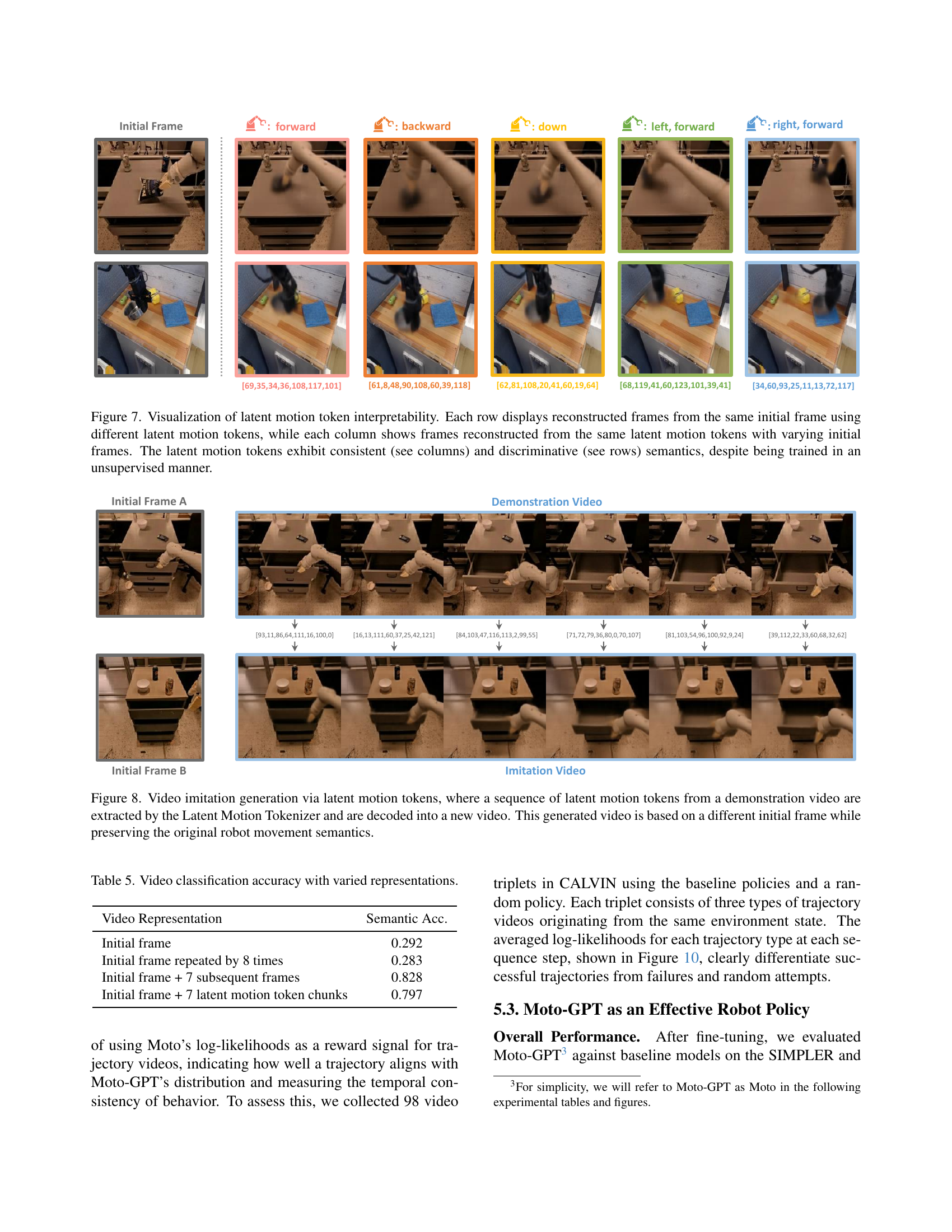
🔼 This figure visualizes the interpretability of latent motion tokens. Each row uses a different set of tokens to reconstruct frames from the same initial image, demonstrating the discriminative nature of the tokens (each row shows a distinct motion). Each column uses the same set of tokens on different initial images, showing consistent results despite the variability in starting points. This consistency and discriminative power highlight the effectiveness of the unsupervised training method in capturing meaningful motion semantics.
read the caption
Figure 7: Visualization of latent motion token interpretability. Each row displays reconstructed frames from the same initial frame using different latent motion tokens, while each column shows frames reconstructed from the same latent motion tokens with varying initial frames. The latent motion tokens exhibit consistent (see columns) and discriminative (see rows) semantics, despite being trained in an unsupervised manner.

🔼 This figure visualizes the process of video imitation using latent motion tokens. A sequence of latent motion tokens is extracted from a demonstration video using the Latent Motion Tokenizer. These tokens are then used to generate a new video sequence with a different initial frame. Importantly, the generated video retains the original robot movements’ semantic meaning from the demonstration video, proving that the latent motion tokens effectively capture and transfer the essence of the robot’s actions.
read the caption
Figure 8: Video imitation generation via latent motion tokens, where a sequence of latent motion tokens from a demonstration video are extracted by the Latent Motion Tokenizer and are decoded into a new video. This generated video is based on a different initial frame while preserving the original robot movement semantics.

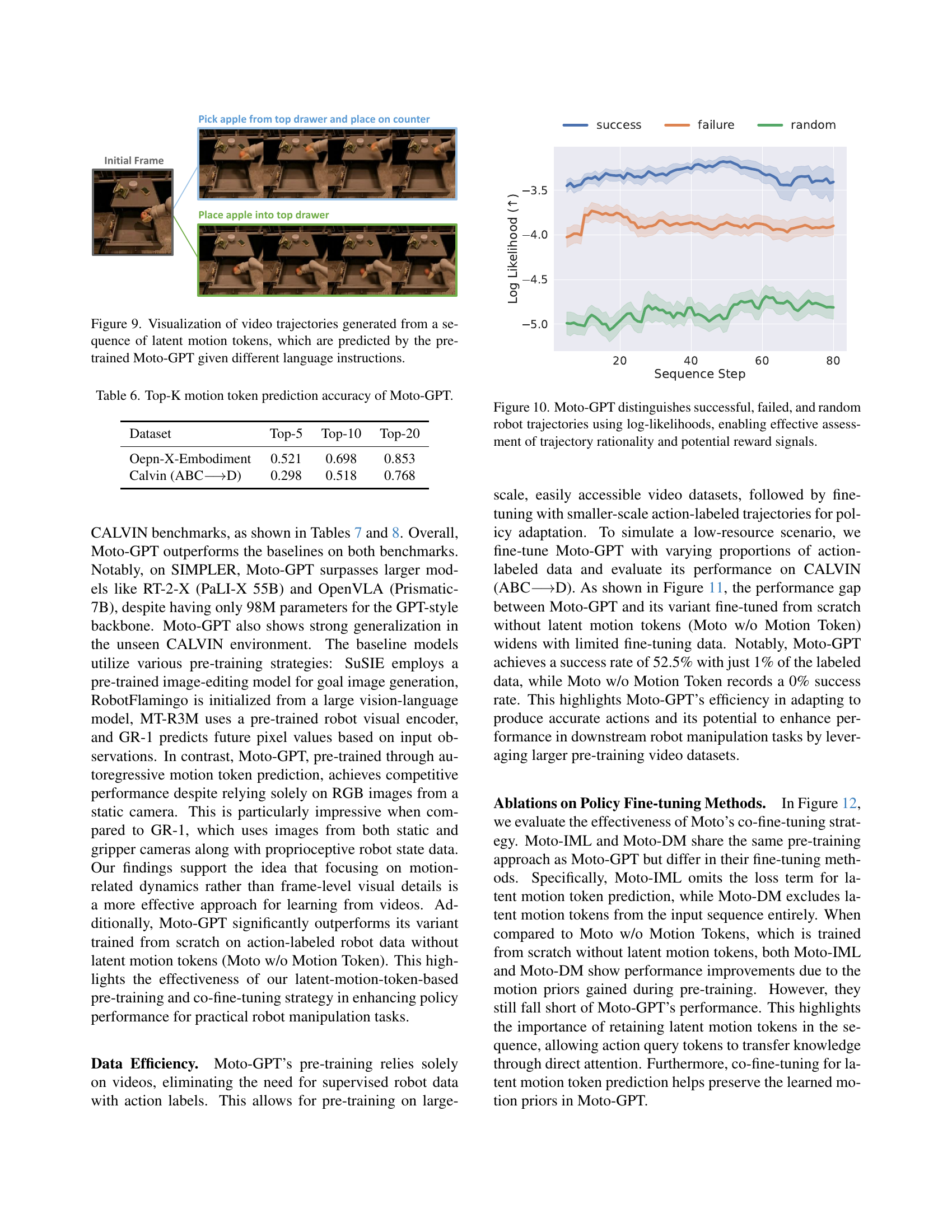
🔼 This figure visualizes the ability of the pre-trained Moto-GPT model to generate video trajectories from language instructions. It shows several example videos, each starting with the same initial frame but progressing differently based on different text prompts given to the model. The model uses sequences of latent motion tokens, which capture the essence of motion in a compact form, to predict the future frames of each video. The variety in the generated videos demonstrates the model’s capacity to understand and respond to natural language instructions and its ability to generate diverse and plausible motion sequences.
read the caption
Figure 9: Visualization of video trajectories generated from a sequence of latent motion tokens, which are predicted by the pre-trained Moto-GPT given different language instructions.

🔼 This figure shows how Moto-GPT, a model trained to predict motion trajectories using latent motion tokens, can assess the quality of different robot trajectories. By calculating the log-likelihoods of successful, failed, and randomly generated trajectories, Moto-GPT effectively distinguishes between them. This capability demonstrates Moto-GPT’s ability to evaluate the rationality of a trajectory, making it potentially useful for generating reward signals in reinforcement learning algorithms.
read the caption
Figure 10: Moto-GPT distinguishes successful, failed, and random robot trajectories using log-likelihoods, enabling effective assessment of trajectory rationality and potential reward signals.

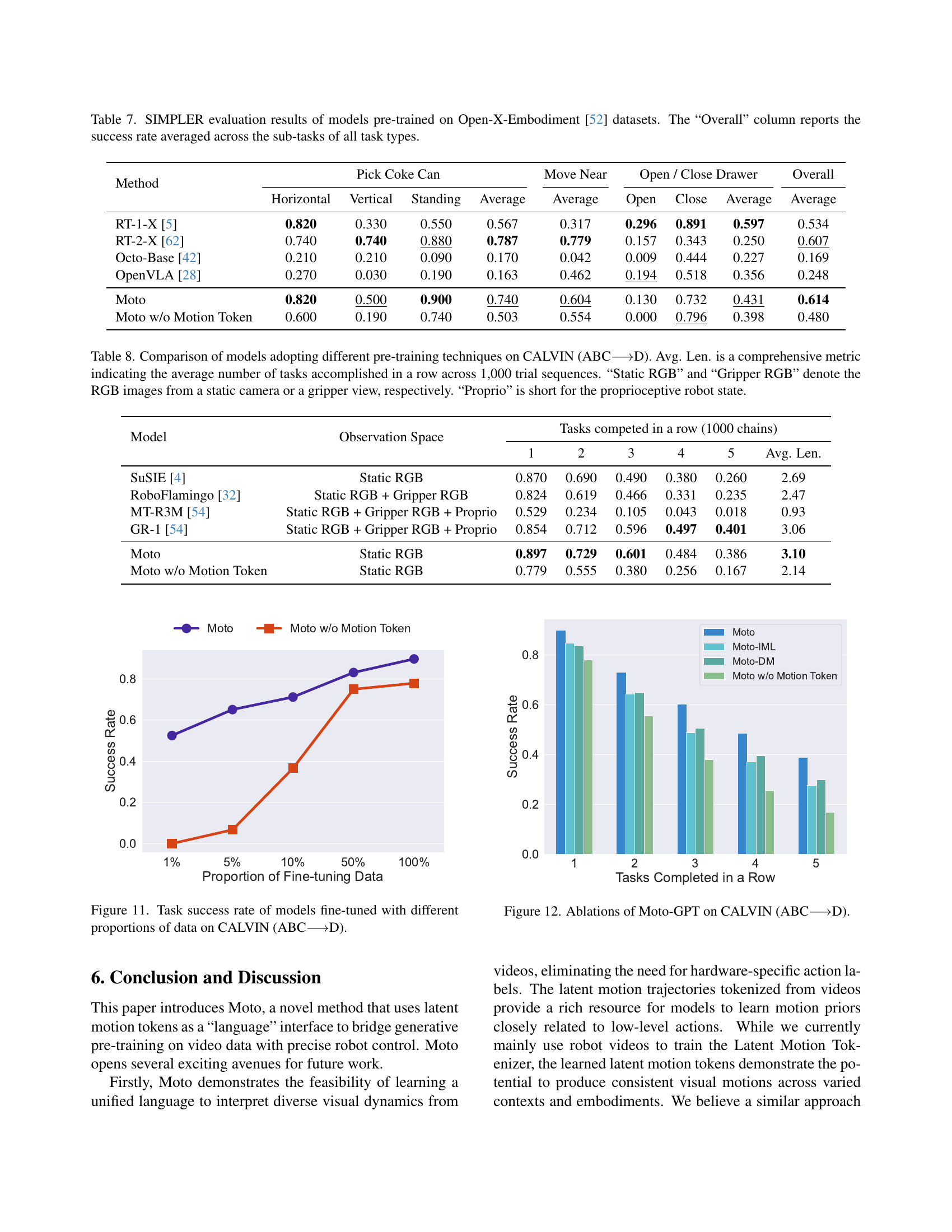
🔼 This figure shows the success rate achieved by different models on the CALVIN benchmark’s D environment. The models were fine-tuned using varying amounts of labeled data from CALVIN’s A, B, and C environments. The x-axis represents the proportion of training data used, ranging from 1% to 100%. The y-axis shows the success rate. The graph highlights the performance difference between Moto-GPT (the proposed method) and a model trained from scratch without leveraging motion priors. It demonstrates Moto-GPT’s superior data efficiency, achieving a high success rate even with limited training data.
read the caption
Figure 11: Task success rate of models fine-tuned with different proportions of data on CALVIN (ABC⟶⟶\longrightarrow⟶D).
More on tables
| Parameter | Value |
|---|---|
| batch_size | 256 |
| optimizer | AdamW |
| lr_max | 1e-4 |
| lr_schedule | cosine decay |
| weight_decay | 1e-4 |
| warmup_steps | 1000 |
🔼 This table details the hyperparameters used during the training of the Latent Motion Tokenizer model. It includes parameters such as batch size, optimizer type (AdamW), maximum learning rate, learning rate scheduling method (cosine decay), weight decay, and the number of warmup steps.
read the caption
Table 2: Training hyperparameters for Latent Motion Tokenizer.
| Component | Parameter | Value |
|---|---|---|
| GPT backbone | num_layers | 12 |
| hidden_size | 768 | |
| num_heads | 12 | |
| Action Head | num_layers | 2 |
| hidden_size | 384 |
🔼 Table 3 provides detailed specifications of the architecture and hyperparameters used in the Moto-GPT model. It lists the components of the model (GPT backbone and Action Head), along with their respective parameters (such as number of layers, hidden size, and number of heads). This information is crucial for understanding the model’s complexity and how it was configured for training and experimentation.
read the caption
Table 3: Implementation details of Moto-GPT.
| Parameter | Value |
|---|---|
| batch_size | 512 |
| optimizer | AdamW |
| lr_max | 1e-4 |
| lr_schedule | cosine decay |
| weight_decay | 1e-4 |
| warmup_epochs | 1 |
🔼 This table details the hyperparameters used during the training phase of the Moto-GPT model. It includes settings for batch size, optimizer, learning rate, learning rate scheduling, weight decay, and warmup epochs. These parameters are crucial for effective model training and influence factors like convergence speed and generalization performance.
read the caption
Table 4: Training hyperparameters for Moto-GPT.
| Video Representation | Semantic Acc. |
|---|---|
| Initial frame | 0.292 |
| Initial frame repeated by 8 times | 0.283 |
| Initial frame + 7 subsequent frames | 0.828 |
| Initial frame + 7 latent motion token chunks | 0.797 |
🔼 This table presents the results of a video classification experiment. The goal is to assess how well different video representations can be used to predict semantic labels for 34 tasks from the CALVIN dataset. Four different video representations were used: only the initial frame; the initial frame repeated eight times; the initial frame plus seven subsequent frames; and the initial frame plus seven latent motion token chunks. The accuracy of a video classifier trained on each of these representations is reported, demonstrating the impact of different input features on video classification performance. This experiment helps assess the effectiveness of using the Latent Motion Tokens to represent visual motions for downstream robot manipulation tasks.
read the caption
Table 5: Video classification accuracy with varied representations.
| Dataset | Top-5 | Top-10 | Top-20 |
|---|---|---|---|
| Oepn-X-Embodiment | 0.521 | 0.698 | 0.853 |
| Calvin (ABC⟶D) | 0.298 | 0.518 | 0.768 |
🔼 This table presents the top-K accuracy results for Moto-GPT’s motion token prediction task. It shows the model’s ability to accurately predict the next latent motion token in a sequence, given the preceding tokens and contextual information. The accuracy is evaluated across different datasets, providing insights into Moto-GPT’s performance on various video data. Top-K accuracy means the percentage of times the correct token is within the top K predicted tokens.
read the caption
Table 6: Top-K motion token prediction accuracy of Moto-GPT.
| Method | Pick Coke Can | Move Near | Open / Close Drawer | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|
| Horizontal | Vertical | Standing | Average | Average | Open | Close | Average | Average | |
| RT-1-X [5] | 0.820 | 0.330 | 0.550 | 0.567 | 0.317 | 0.296 | 0.891 | 0.597 | 0.534 |
| RT-2-X [62] | 0.740 | 0.740 | 0.880 | 0.787 | 0.779 | 0.157 | 0.343 | 0.250 | 0.607 |
| Octo-Base [42] | 0.210 | 0.210 | 0.090 | 0.170 | 0.042 | 0.009 | 0.444 | 0.227 | 0.169 |
| OpenVLA [28] | 0.270 | 0.030 | 0.190 | 0.163 | 0.462 | 0.194 | 0.518 | 0.356 | 0.248 |
| Moto | 0.820 | 0.500 | 0.900 | 0.740 | 0.604 | 0.130 | 0.732 | 0.431 | 0.614 |
| Moto w/o Motion Token | 0.600 | 0.190 | 0.740 | 0.503 | 0.554 | 0.000 | 0.796 | 0.398 | 0.480 |
🔼 This table presents a comprehensive comparison of the performance of several robot manipulation models on the SIMPLER benchmark. Each model was pre-trained using the Open-X-Embodiment dataset. The table shows success rates for three sub-tasks within the benchmark: Pick Coke Can (with horizontal, vertical, and standing variations), Move Near, and Open/Close Drawer. The ‘Overall’ column provides the average success rate across all three tasks. This allows for a direct comparison of model effectiveness in various manipulation scenarios.
read the caption
Table 7: SIMPLER evaluation results of models pre-trained on Open-X-Embodiment [52] datasets. The “Overall” column reports the success rate averaged across the sub-tasks of all task types.
| Model | Observation Space | 1 | 2 | 3 | 4 | 5 | Avg. Len. | |
|---|---|---|---|---|---|---|---|---|
| SuSIE [4] | Static RGB | 0.870 | 0.690 | 0.490 | 0.380 | 0.260 | 2.69 | |
| RoboFlamingo [32] | Static RGB + Gripper RGB | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.47 | |
| MT-R3M [54] | Static RGB + Gripper RGB + Proprio | 0.529 | 0.234 | 0.105 | 0.043 | 0.018 | 0.93 | |
| GR-1 [54] | Static RGB + Gripper RGB + Proprio | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 | |
| Moto | Static RGB | 0.897 | 0.729 | 0.601 | 0.484 | 0.386 | 3.10 | |
| Moto w/o Motion Token | Static RGB | 0.779 | 0.555 | 0.380 | 0.256 | 0.167 | 2.14 |
🔼 Table 8 presents a comparison of various models’ performance on the CALVIN benchmark (specifically, the ABC→D setting, where training occurs on environments A, B, and C and testing occurs on environment D). The models utilize different pre-training techniques. The table shows the average number of tasks each model successfully completes consecutively across 1000 trial sequences (Avg. Len.). This metric offers a comprehensive evaluation of performance in complex, multi-step tasks. The table also specifies the type of sensory data used by each model: Static RGB (RGB images from a fixed camera), Gripper RGB (RGB images from a camera mounted on the robot gripper), and Proprio (proprioceptive robot state data, indicating the robot’s internal state such as joint angles and velocities).
read the caption
Table 8: Comparison of models adopting different pre-training techniques on CALVIN (ABC⟶⟶\longrightarrow⟶D). Avg. Len. is a comprehensive metric indicating the average number of tasks accomplished in a row across 1,000 trial sequences. “Static RGB” and “Gripper RGB” denote the RGB images from a static camera or a gripper view, respectively. “Proprio” is short for the proprioceptive robot state.
Full paper#