↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many current vision-language models (VLMs) rely on excessively long visual tokens, leading to high computational costs. This paper identifies significant redundancy within these visual tokens, generated by popular vision encoders like CLIP and SigLIP. This redundancy negatively impacts efficiency without providing proportional gains in performance.
To address this, the authors introduce VisionZip, a simple yet effective method that selects a subset of the most informative visual tokens. VisionZip is training-free, meaning it can be applied directly to existing models without requiring retraining, and significantly improves inference speed while maintaining high accuracy across multiple benchmarks. The method also enables larger models (like a 13B parameter model) to outperform smaller models (like a 7B parameter model) in terms of both speed and accuracy. The authors analyze the reasons behind the token redundancy and encourage the research community to focus on better visual feature extraction, rather than just increasing the number of tokens.
Key Takeaways#
Why does it matter?#
This paper is important because it challenges the common assumption in vision-language models that longer visual tokens always improve performance. VisionZip offers a novel, efficient approach that reduces redundancy in existing visual tokens without sacrificing accuracy, opening new avenues for optimizing VLMs, especially for resource-constrained environments and complex tasks like multi-turn conversations. It also provides valuable insights into the nature of visual token redundancy and how to extract more effective visual features.
Visual Insights#

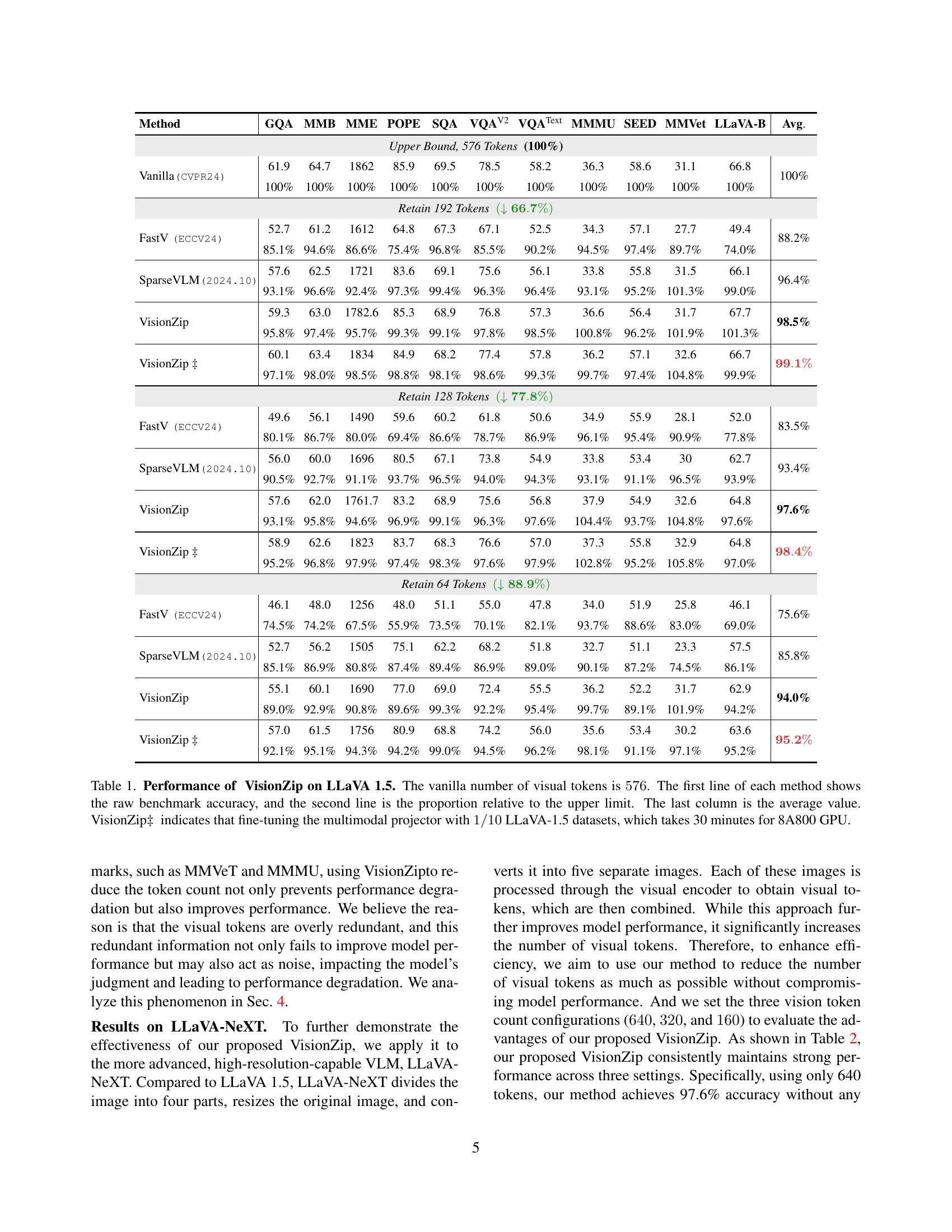
🔼 Figure 1 demonstrates the performance and efficiency gains achieved by VisionZip. Panel (a) showcases VisionZip’s superior performance compared to state-of-the-art efficient Vision-Language Models (VLMs) like FastV and SparseVLM across eleven benchmarks on the LLaVA-1.5 dataset. Remarkably, VisionZip achieves nearly 95% of the performance using only 10% of the original tokens. Panel (b) highlights the significant reduction in prefilling time (8 times faster) for the LLaVA-NeXT 7B model. Lastly, panel (c) illustrates that VisionZip improves inference speed by a factor of two for the LLaVA-NeXT 13B model while still outperforming the 7B model, showcasing its ability to achieve better results with improved efficiency.
read the caption
Figure 1: VisionZip Performance and Efficiency. (a) Our VisionZip significantly outperforms the current SOTA EfficientVLM model, like FastV, SparseVLM, achieving nearly 95% of the performance with only 10% of the tokens across 11 benchmarks on LLaVA-1.5. (b) VisionZip could reduce 8×\times× prefilling time for LLaVA-NeXT 7B. (c) VisionZip reduces GPU inference time by 2×\times× across 11 benchmarks, enabling the LLaVA-NeXT 13B model to infer faster than the 7B model while achieving better results.
| Method | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED | MMVet | LLaVA-B | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 576 Tokens (100%) | ||||||||||||
| Vanilla(CVPR24) | 61.9 | 64.7 | 1862 | 85.9 | 69.5 | 78.5 | 58.2 | 36.3 | 58.6 | 31.1 | 66.8 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Retain 192 Tokens (↓ 66.7%) | ||||||||||||
| FastV(ECCV24) | 52.7 | 61.2 | 1612 | 64.8 | 67.3 | 67.1 | 52.5 | 34.3 | 57.1 | 27.7 | 49.4 | 88.2% |
| 85.1% | 94.6% | 86.6% | 75.4% | 96.8% | 85.5% | 90.2% | 94.5% | 97.4% | 89.7% | 74.0% | ||
| SparseVLM(2024.10) | 57.6 | 62.5 | 1721 | 83.6 | 69.1 | 75.6 | 56.1 | 33.8 | 55.8 | 31.5 | 66.1 | 96.4% |
| 93.1% | 96.6% | 92.4% | 97.3% | 99.4% | 96.3% | 96.4% | 93.1% | 95.2% | 101.3% | 99.0% | ||
| VisionZip | 59.3 | 63.0 | 1782.6 | 85.3 | 68.9 | 76.8 | 57.3 | 36.6 | 56.4 | 31.7 | 67.7 | 98.5% |
| 95.8% | 97.4% | 95.7% | 99.3% | 99.1% | 97.8% | 98.5% | 100.8% | 96.2% | 101.9% | 101.3% | ||
| VisionZip ‡ | 60.1 | 63.4 | 1834 | 84.9 | 68.2 | 77.4 | 57.8 | 36.2 | 57.1 | 32.6 | 66.7 | 99.1% |
| 97.1% | 98.0% | 98.5% | 98.8% | 98.1% | 98.6% | 99.3% | 99.7% | 97.4% | 104.8% | 99.9% | ||
| Retain 128 Tokens (↓ 77.8%) | ||||||||||||
| FastV(ECCV24) | 49.6 | 56.1 | 1490 | 59.6 | 60.2 | 61.8 | 50.6 | 34.9 | 55.9 | 28.1 | 52.0 | 83.5% |
| 80.1% | 86.7% | 80.0% | 69.4% | 86.6% | 78.7% | 86.9% | 96.1% | 95.4% | 90.9% | 77.8% | ||
| SparseVLM(2024.10) | 56.0 | 60.0 | 1696 | 80.5 | 67.1 | 73.8 | 54.9 | 33.8 | 53.4 | 30 | 62.7 | 93.4% |
| 90.5% | 92.7% | 91.1% | 93.7% | 96.5% | 94.0% | 94.3% | 93.1% | 91.1% | 96.5% | 93.9% | ||
| VisionZip | 57.6 | 62.0 | 1761.7 | 83.2 | 68.9 | 75.6 | 56.8 | 37.9 | 54.9 | 32.6 | 64.8 | 97.6% |
| 93.1% | 95.8% | 94.6% | 96.9% | 99.1% | 96.3% | 97.6% | 104.4% | 93.7% | 104.8% | 97.6% | ||
| VisionZip ‡ | 58.9 | 62.6 | 1823 | 83.7 | 68.3 | 76.6 | 57.0 | 37.3 | 55.8 | 32.9 | 64.8 | 98.4% |
| 95.2% | 96.8% | 97.9% | 97.4% | 98.3% | 97.6% | 97.9% | 102.8% | 95.2% | 105.8% | 97.0% | ||
| Retain 64 Tokens (↓ 88.9%) | ||||||||||||
| FastV(ECCV24) | 46.1 | 48.0 | 1256 | 48.0 | 51.1 | 55.0 | 47.8 | 34.0 | 51.9 | 25.8 | 46.1 | 75.6% |
| 74.5% | 74.2% | 67.5% | 55.9% | 73.5% | 70.1% | 82.1% | 93.7% | 88.6% | 83.0% | 69.0% | ||
| SparseVLM(2024.10) | 52.7 | 56.2 | 1505 | 75.1 | 62.2 | 68.2 | 51.8 | 32.7 | 51.1 | 23.3 | 57.5 | 85.8% |
| 85.1% | 86.9% | 80.8% | 87.4% | 89.4% | 86.9% | 89.0% | 90.1% | 87.2% | 74.5% | 86.1% | ||
| VisionZip | 55.1 | 60.1 | 1690 | 77.0 | 69.0 | 72.4 | 55.5 | 36.2 | 52.2 | 31.7 | 62.9 | 94.0% |
| 89.0% | 92.9% | 90.8% | 89.6% | 99.3% | 92.2% | 95.4% | 99.7% | 89.1% | 101.9% | 94.2% | ||
| VisionZip ‡ | 57.0 | 61.5 | 1756 | 80.9 | 68.8 | 74.2 | 56.0 | 35.6 | 53.4 | 30.2 | 63.6 | 95.2% |
| 92.1% | 95.1% | 94.3% | 94.2% | 99.0% | 94.5% | 96.2% | 98.1% | 91.1% | 97.1% | 95.2% |
🔼 Table 1 presents a comprehensive comparison of VisionZip’s performance against other state-of-the-art methods on the LLaVA-1.5 benchmark. It evaluates performance across eleven different image understanding tasks. The table shows raw accuracy scores (the first line for each method) and then shows these scores as a percentage of the baseline model’s performance (the second line). Three different visual token reduction levels are evaluated (192, 128, and 64) to show how the efficiency and accuracy trade-off changes. A special notation (VisionZip‡) indicates when the multimodal projector was fine-tuned using a small subset (1/10) of the LLaVA-1.5 training data, to further optimize performance with the reduced number of visual tokens. The final column presents the average accuracy score across all eleven tasks.
read the caption
Table 1: Performance of VisionZip on LLaVA 1.5. The vanilla number of visual tokens is 576576576576. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. VisionZip‡ indicates that fine-tuning the multimodal projector with 1/101101/101 / 10 LLaVA-1.5 datasets, which takes 30 minutes for 8A800 GPU.
In-depth insights#
Visual Token Redundancy#
The concept of “Visual Token Redundancy” in vision-language models (VLMs) centers on the observation that many visual tokens generated by encoders like CLIP and SigLIP contain redundant information. The paper highlights that these tokens, while increasing computational cost, don’t significantly improve model performance. A significant portion of the visual tokens receive minimal attention, indicating a disproportionate allocation of computational resources. The authors propose VisionZip as a solution to identify and select a subset of informative visual tokens. This approach emphasizes the importance of focusing on extracting better visual features rather than simply increasing the number of tokens, which addresses the issue of efficiency without sacrificing performance. The observation of this redundancy challenges the prevalent VLM design paradigm and proposes a more efficient architecture that prioritizes informative tokens. This leads to improved efficiency and opens a new direction for future VLM research concentrating on feature quality.
VisionZip Algorithm#
The core of the VisionZip approach lies in its efficient visual token selection and merging strategy. It cleverly identifies dominant tokens carrying significant information, primarily by analyzing attention weights from the vision encoder. This contrasts with previous methods which rely heavily on text-visual attention from the LLM, often leading to suboptimal token selection. VisionZip’s text-agnostic nature allows it to be applied to various vision encoders and VLMs. The merging of remaining tokens based on contextual similarity addresses potential information loss and further enhances efficiency. The algorithm’s simplicity and effectiveness in improving inference speed without significant performance degradation make it a promising technique for deploying VLMs in resource-constrained environments and real-world applications requiring speedy multi-turn dialogues.
Efficiency Gains#
The research paper highlights significant efficiency gains achieved by VisionZip, a novel method for optimizing vision language models (VLMs). By strategically reducing the number of visual tokens, VisionZip drastically improves inference speed and reduces memory consumption. This is particularly crucial for resource-constrained environments and applications involving long video sequences or multiple images. The observed 8x reduction in prefilling time is a notable achievement, making real-time applications, such as autonomous driving, significantly more feasible. Furthermore, VisionZip’s approach enables better performance from larger, more computationally expensive 13B parameter models than smaller 7B models. These efficiency improvements result from addressing inherent redundancy within the visual tokens of existing VLMs, demonstrating that longer is not always better in terms of token length. The training-free nature of VisionZip also offers a significant advantage for practical deployment by simplifying the model optimization process.
Multi-task Adaptability#
The concept of ‘Multi-task Adaptability’ in the context of vision-language models (VLMs) refers to a model’s capacity to effectively handle diverse downstream tasks using a single, unified architecture. A highly adaptable VLM would not require extensive task-specific fine-tuning, instead leveraging its pre-trained knowledge to generalize well across various applications. This adaptability is crucial for practical deployment, reducing the need for separate models for each task and lowering development costs. Key factors influencing this adaptability include the model’s architecture, which must be robust enough to represent various types of data; the training data, which needs to be diverse and representative of many tasks, and the training methodology, which must focus on generalized feature learning rather than task-specific memorization. Successful multi-task adaptability leads to more efficient and versatile systems, capable of handling diverse real-world scenarios without compromising performance. However, achieving high multi-task performance is challenging, often resulting in a trade-off between specialization and generalization. Research into optimizing VLM architectures and training strategies for maximal multi-task adaptability remains an active area of development.
Future Research#
Future research directions stemming from this work on VisionZip could explore several promising avenues. Improving the token selection algorithm is crucial; while VisionZip effectively reduces redundancy, more sophisticated methods could further refine the selection process, perhaps incorporating dynamic token selection based on the specific input image or task. Investigating alternative token merging strategies beyond simple averaging could enhance performance. Exploring different visual encoders beyond CLIP and SigLIP, and analyzing the inherent redundancy in their outputs, is also vital to broaden VisionZip’s applicability. Finally, extending VisionZip’s functionality to handle diverse VLM architectures and multimodal tasks (beyond image and video) would significantly expand its impact. Further evaluation on diverse and larger datasets is also needed to solidify the findings and potentially uncover limitations under different circumstances.
More visual insights#
More on figures

🔼 This figure visualizes the redundancy in visual tokens generated by popular vision encoders like CLIP and SigLIP. The left panel shows visualizations of attention weights for CLIP and SigLIP on a single image example, demonstrating that the attention is highly concentrated on a small subset of tokens. The right panel presents the distribution statistics of attention weights across all the visual tokens in a validation dataset. This clearly shows that most tokens have very low attention weights, while only a few tokens receive high attention. This visual and statistical evidence strongly supports the claim of significant redundancy within visual tokens.
read the caption
Figure 2: Redundancy Visualization. The visualization and distribution statistics of attention scores show attention concentrated on only a few tokens, while many tokens display very low attention scores, indicating significant redundancy in the visual tokens.

🔼 VisionZip is a novel method for improving the efficiency of Vision Language Models (VLMs) by reducing the number of visual tokens. It operates in two main steps. First, it identifies and selects ‘dominant’ visual tokens that carry the most significant information, as determined by their attention scores. Second, the remaining tokens are merged using a semantic similarity approach to create ‘contextual’ tokens. This process significantly reduces the number of input tokens to the Language Model without sacrificing performance, leading to faster inference speeds. Furthermore, fine-tuning the projector layer of the VLM can slightly improve performance, bringing it closer to the results obtained with the full set of tokens. The overall architecture is shown in the figure, highlighting VisionZip’s training-free nature and its integration within a typical VLM pipeline.
read the caption
Figure 3: Framework of VisionZip. VisionZip selects dominant tokens that aggregate substantial information based on visual token attention scores. Remaining tokens are merged based on semantic similarity to produce contextual tokens. VisionZip is a training-free method significantly reduces the number of image tokens, accelerating inference while maintaining performance. With efficient fine-tuning of the projector, even better results can be achieved with minimal performance loss compared to using the full token.

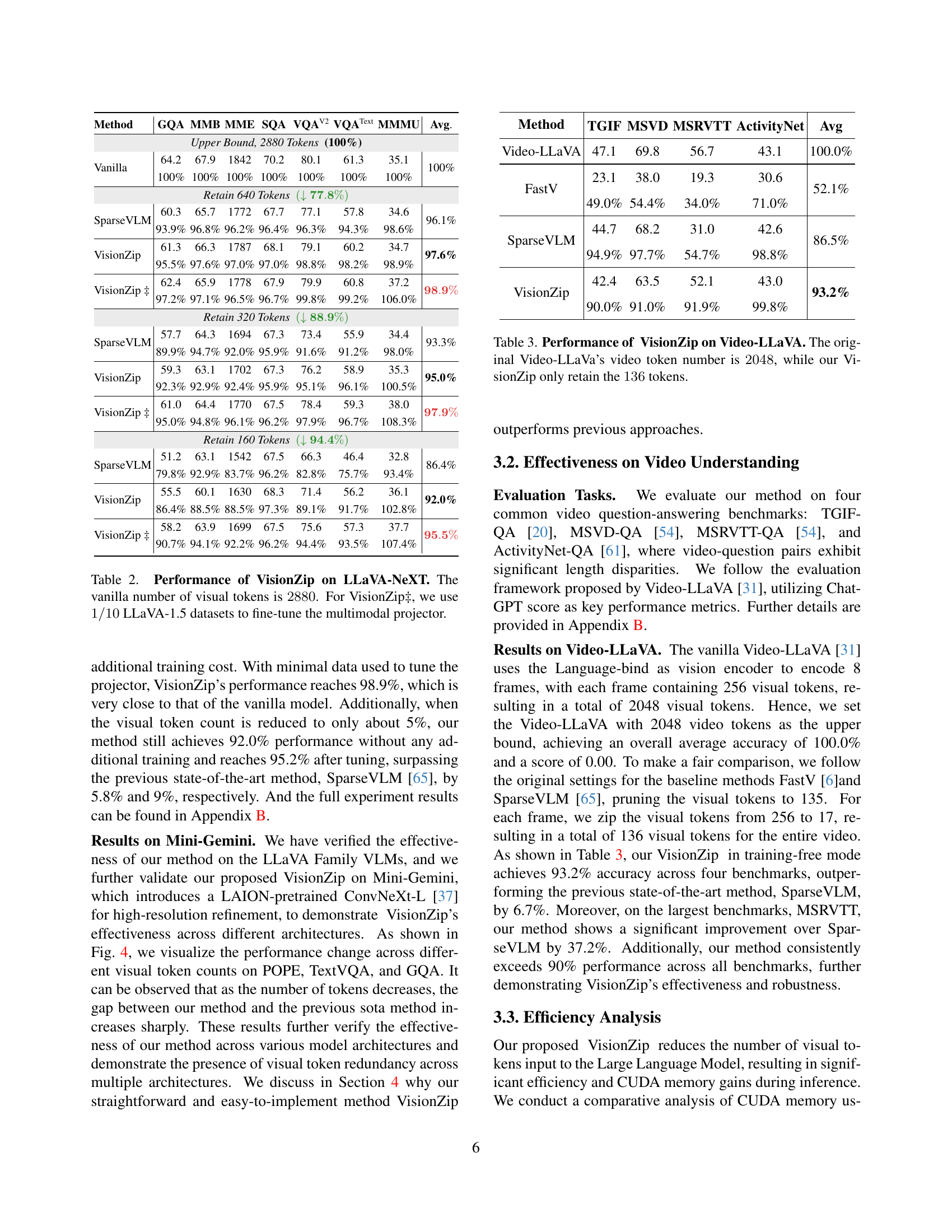
🔼 The figure shows the performance comparison of VisionZip against several other methods on the Mini-Gemini model. It demonstrates the effect of reducing the number of visual tokens on the model’s accuracy across three different benchmarks (TextVQA, GQA, and POPE). The x-axis represents the number of visual tokens used, and the y-axis represents the accuracy. The lines show that VisionZip maintains a high level of accuracy even with a drastically reduced number of tokens, outperforming other efficient methods. This illustrates the efficiency and effectiveness of VisionZip in reducing the computational cost of VLMs without significant performance loss.
read the caption
Figure 4: Performance of VisionZip on the Mini-Gemini.

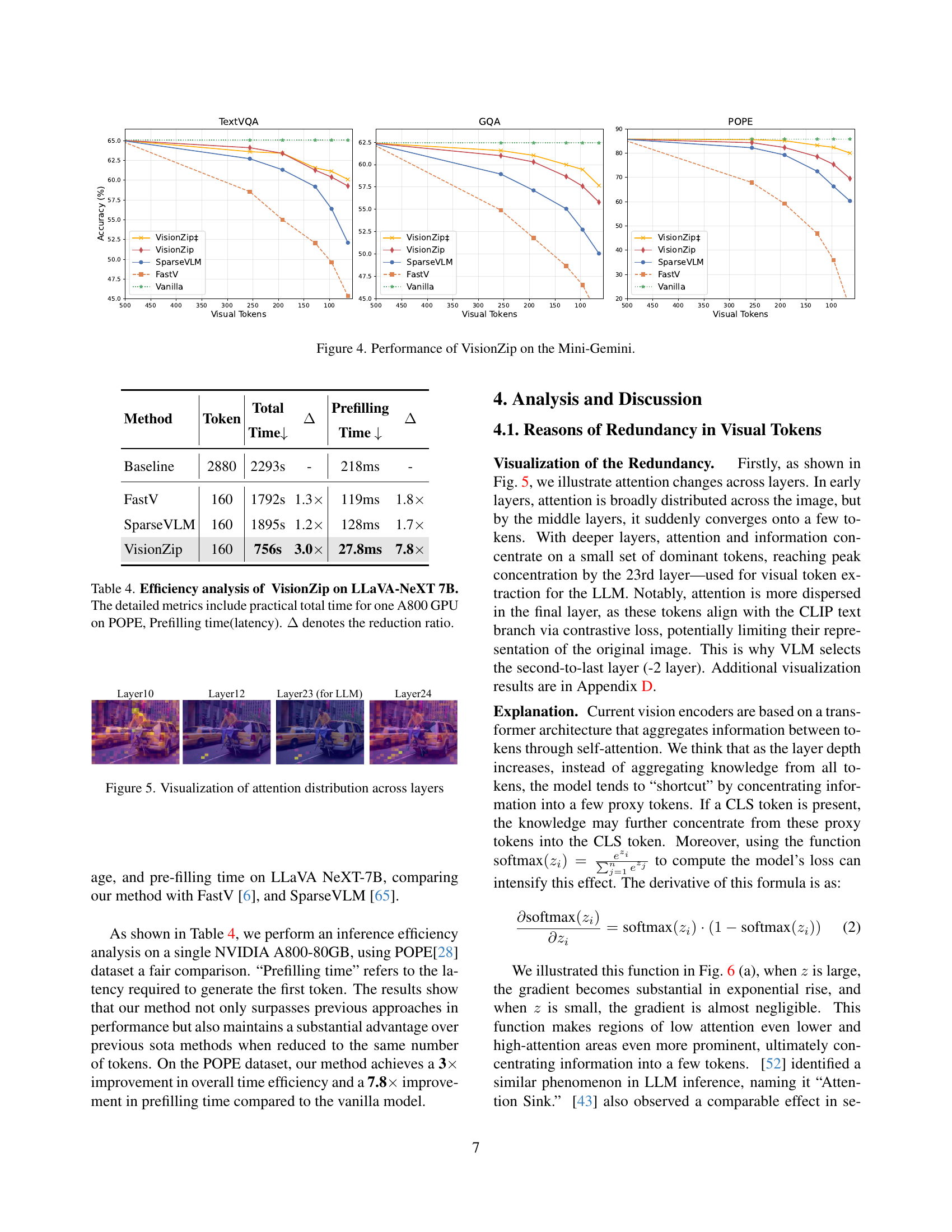
🔼 This figure visualizes how the attention mechanism of a vision encoder changes across different layers of a Vision Language Model (VLM). It shows that in the initial layers, attention is broadly distributed across the entire image. However, as the network deepens, attention becomes increasingly concentrated on a small subset of tokens. This concentration intensifies until reaching a peak around layer 23 before becoming slightly more dispersed again in the final layer. This pattern of attention distribution illustrates how the VLM progressively aggregates visual information into a smaller number of highly informative tokens while discarding less salient features.
read the caption
Figure 5: Visualization of attention distribution across layers

🔼 Figure 6(a) shows the gradient of the softmax function used in calculating the model’s loss. The steep rise for large z values and near-zero gradient for small z values explain how the attention mechanism concentrates on a small number of tokens, as those tokens with high attention scores will have a stronger gradient, while tokens with lower attention scores will have a weaker gradient, leading to a concentration of attention on a few dominant tokens. Figure 6(b) illustrates the feature misalignment problem. The attention heatmap for a ‘man’ is shown and highlights that the highest attention is not focused on the man himself, but rather on the background and less relevant areas. This shows that visual tokens from important features do not necessarily have high attention values, resulting in a misalignment where important visual information is not captured effectively.
read the caption
Figure 6: Reason of redundancy and feature misalignment

🔼 This table presents the results of applying VisionZip with different quantization levels (8-bit and 4-bit) to the ScienceQA benchmark. It demonstrates the compatibility of VisionZip with quantization techniques and shows that VisionZip maintains good performance even with reduced precision. The table compares the performance (Precision and Memory Accuracy) and inference speed (Size and Time) of the full-precision model against the model using VisionZip with 8-bit and 4-bit quantization. The ‘†’ symbol indicates that VisionZip was used. This highlights the efficiency gains achievable through VisionZip without significant performance loss.
read the caption
Table 6: Compatibility of VisionZip on various quantization levels for ScienceQA. † represents use of VisionZip.

🔼 This table compares the performance and efficiency of different Vision Language Models (VLMs) on the TextVQA benchmark. It shows the inference time (Size, Time), accuracy (Acc), and memory usage (Memory) for a 7B parameter VLM and a 13B parameter VLM. Both baselines and the models enhanced with VisionZip (indicated by †) are included for comparison. The results demonstrate that VisionZip improves the 13B VLM’s performance while making it more efficient than the 7B baseline, highlighting its advantages in optimizing both model size and processing speed.
read the caption
Table 7: VisionZip boosts the 13B model’s performance and efficiency over the 7B model on TextVQA. † represents use of VisionZip.

🔼 This figure demonstrates the effectiveness of VisionZip in multi-turn conversations compared to previous text-relevant methods for visual token selection. The example shows that previous methods struggle to maintain relevance across multiple turns because their visual token selection relies on text-based attention, leading to irrelevant information in later turns. In contrast, VisionZip, selecting tokens in a text-agnostic manner, consistently focuses on relevant visual information throughout the conversation.
read the caption
Figure 7: Example comparison of VisionZip and previous text-relevant method in multi-turn conversation

🔼 This figure demonstrates the impact of VisionZip on video understanding. The top row shows a 3-minute video clip processed by the Video-LLaVA model. Because Video-LLaVA only processes a small number of frames, its understanding is limited. The bottom row shows the same clip processed by VisionZip. VisionZip achieves the same length in visual tokens by utilizing a significantly larger number of frames. This increased frame count allows VisionZip to capture more information and produce a more detailed and accurate understanding of the video.
read the caption
Figure 8: Advantage of VisionZip in video understanding task. With the same visual token length, using VisionZip allows encoding more frames, significantly enhancing the model’s capacity to understand longer video sequences and capture more detailed information.

🔼 This figure visualizes the redundancy in visual tokens generated by the CLIP model. It displays a series of images, each overlaid with a heatmap showing the attention weights assigned to different visual tokens. The color intensity of each point in the heatmap corresponds to the attention weight, with brighter colors indicating higher attention. This visualization demonstrates that a relatively small subset of visual tokens receive most of the attention, while the majority of tokens have very low attention weights. This highlights the presence of significant redundancy within the visual token representations produced by CLIP.
read the caption
Figure 9: Visualization of Redundancy in the CLIP Model

🔼 This figure visualizes the redundancy in visual tokens generated by the CLIP model. It shows a grid of images, each overlaid with a heatmap representing the attention weights of the visual tokens. The heatmaps illustrate that a small number of tokens receive high attention weights, indicating that most visual tokens are redundant and do not contribute significantly to information representation.
read the caption
Figure 10: Visualization of Redundancy in the CLIP Model

🔼 This figure visualizes the redundancy of visual tokens generated by the SigLIP model. It shows a series of images, each overlaid with a heatmap indicating the attention weights of different visual tokens. The heatmaps demonstrate that a small number of tokens receive high attention, while most tokens receive very low attention. This indicates that a significant portion of the visual tokens are redundant and could likely be removed without affecting performance significantly.
read the caption
Figure 11: Visualization of Redundancy in the SigLIP Model

🔼 This figure visualizes how the attention distribution in the CLIP model changes across different layers. In the initial layers, attention is spread broadly across the image. As the network processes the image through deeper layers, attention becomes increasingly concentrated on only a few key tokens, indicating a concentration of information into a smaller subset of tokens. The final layer shows a slightly more diffuse attention pattern, potentially due to the alignment with text tokens. This visualization helps to understand the redundancy of visual tokens because much of the information is already captured by a few dominant tokens.
read the caption
Figure 12: Visualization of Attention Distribution Change

🔼 This figure visualizes how the attention distribution across different layers of a CLIP model changes. It shows that in the early layers, attention is spread broadly across the image. However, as the network goes deeper, attention becomes increasingly concentrated on a smaller subset of tokens. By the final layers, most of the attention is focused on only a few tokens, indicating that these tokens carry the majority of the information while many other tokens contain redundant information.
read the caption
Figure 13: Visualization of Attention Distribution Change
More on tables
| Method | GQA | MMB | MME | SQA | VQAV2 | VQAText | MMMU | Avg. |
|---|---|---|---|---|---|---|---|---|
| Upper Bound, 2880 Tokens (100%) | 100% | |||||||
| Vanilla | 64.2 | 67.9 | 1842 | 70.2 | 80.1 | 61.3 | 35.1 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Retain 640 Tokens (↓ 77.8%) | 96.1% | |||||||
| SparseVLM | 60.3 | 65.7 | 1772 | 67.7 | 77.1 | 57.8 | 34.6 | 96.1% |
| 93.9% | 96.8% | 96.2% | 96.4% | 96.3% | 94.3% | 98.6% | ||
| VisionZip | 61.3 | 66.3 | 1787 | 68.1 | 79.1 | 60.2 | 34.7 | 97.6% |
| 95.5% | 97.6% | 97.0% | 97.0% | 98.8% | 98.2% | 98.9% | ||
| VisionZip ‡ | 62.4 | 65.9 | 1778 | 67.9 | 79.9 | 60.8 | 37.2 | 98.9% |
| 97.2% | 97.1% | 96.5% | 96.7% | 99.8% | 99.2% | 106.0% | ||
| Retain 320 Tokens (↓ 88.9%) | 93.3% | |||||||
| SparseVLM | 57.7 | 64.3 | 1694 | 67.3 | 73.4 | 55.9 | 34.4 | 93.3% |
| 89.9% | 94.7% | 92.0% | 95.9% | 91.6% | 91.2% | 98.0% | ||
| VisionZip | 59.3 | 63.1 | 1702 | 67.3 | 76.2 | 58.9 | 35.3 | 95.0% |
| 92.3% | 92.9% | 92.4% | 95.9% | 95.1% | 96.1% | 100.5% | ||
| VisionZip ‡ | 61.0 | 64.4 | 1770 | 67.5 | 78.4 | 59.3 | 38.0 | 97.9% |
| 95.0% | 94.8% | 96.1% | 96.2% | 97.9% | 96.7% | 108.3% | ||
| Retain 160 Tokens (↓ 94.4%) | 86.4% | |||||||
| SparseVLM | 51.2 | 63.1 | 1542 | 67.5 | 66.3 | 46.4 | 32.8 | 86.4% |
| 79.8% | 92.9% | 83.7% | 96.2% | 82.8% | 75.7% | 93.4% | ||
| VisionZip | 55.5 | 60.1 | 1630 | 68.3 | 71.4 | 56.2 | 36.1 | 92.0% |
| 86.4% | 88.5% | 88.5% | 97.3% | 89.1% | 91.7% | 102.8% | ||
| VisionZip ‡ | 58.2 | 63.9 | 1699 | 67.5 | 75.6 | 57.3 | 37.7 | 95.5% |
| 90.7% | 94.1% | 92.2% | 96.2% | 94.4% | 93.5% | 107.4% |
🔼 This table presents the performance of the VisionZip model on the LLaVA-NeXT benchmark for image understanding. It compares VisionZip’s performance against baseline models (Vanilla), as well as other state-of-the-art efficient VLMs such as FastV and SparseVLM. The table shows results for three different configurations of VisionZip, each using a reduced number of visual tokens (640, 320, and 160) compared to the baseline model (2880 tokens). Results are expressed as percentages relative to the baseline’s performance (100%). The results demonstrate the effectiveness of VisionZip in maintaining performance while significantly reducing the number of visual tokens. A version of VisionZip, denoted VisionZip‡, includes additional fine-tuning of the multimodal projector using a small subset (1/10) of the LLaVA-1.5 dataset to further improve performance after the reduction of visual tokens.
read the caption
Table 2: Performance of VisionZip on LLaVA-NeXT. The vanilla number of visual tokens is 2880288028802880. For VisionZip‡, we use 1/101101/101 / 10 LLaVA-1.5 datasets to fine-tune the multimodal projector.
| Method | TGIF | MSVD | MSRVTT | ActivityNet | Avg |
|---|---|---|---|---|---|
| Video-LLaVA | 47.1 | 69.8 | 56.7 | 43.1 | 100.0% |
| FastV | 23.1 | 38.0 | 19.3 | 30.6 | 52.1% |
| 49.0% | 54.4% | 34.0% | 71.0% | ||
| SparseVLM | 44.7 | 68.2 | 31.0 | 42.6 | 86.5% |
| 94.9% | 97.7% | 54.7% | 98.8% | ||
| VisionZip | 42.4 | 63.5 | 52.1 | 43.0 | 93.2% |
| 90.0% | 91.0% | 91.9% | 99.8% |
🔼 This table presents the performance comparison of VisionZip against baseline methods (FastV and SparseVLM) on the Video-LLaVA benchmark. The original Video-LLaVA model uses 2048 visual tokens. VisionZip drastically reduces this number to only 136 tokens while aiming to maintain or improve performance. The table shows the performance of each method on four video question-answering datasets (TGIF-QA, MSVD-QA, MSRVTT-QA, and ActivityNet-QA). The results are displayed as percentages, with the Video-LLaVA’s performance serving as the 100% baseline. This demonstrates VisionZip’s efficiency in reducing computational cost while preserving a high level of accuracy.
read the caption
Table 3: Performance of VisionZip on Video-LLaVA. The original Video-LLaVa’s video token number is 2048204820482048, while our VisionZip only retain the 136136136136 tokens.
| Token | Accuracy | Δ |
|---|---|---|
| Baseline 576→64 | 51.1 | |
| Ex1 526→64 | 46.4 | -9.2% |
| Ex2 128→64 | 52.5 | +2.7% |
🔼 This table presents a detailed efficiency analysis of the VisionZip model on the LLaVA-NeXT 7B benchmark, focusing on the POPE dataset. It compares the total inference time and the prefilling time (latency, the time to generate the first token) of VisionZip against baseline methods. The reduction ratio (Δ) shows how much faster VisionZip is in comparison to these methods. The metrics provide insights into the performance improvement and efficiency gains achieved by VisionZip in reducing visual token redundancy.
read the caption
Table 4: Efficiency analysis of VisionZip on LLaVA-NeXT 7B. The detailed metrics include practical total time for one A800 GPU on POPE, Prefilling time(latency). ΔΔ\Deltaroman_Δ denotes the reduction ratio.
| Precision | Memory | Acc |
|---|---|---|
| 7B-Full | 18,952 | 70.2 |
| 13B-Full | 36,721 | 73.5 |
| 13B-8bit-† | 16,632 | 70.8 |
| 13B-4bit-† | 10,176 | 70.3 |
🔼 This table presents a quantitative analysis of the impact of feature misalignment on model performance. It demonstrates how selecting only a subset of the most important tokens, instead of using all available visual tokens, affects the model’s accuracy. The experiment compares a baseline model using all tokens against reduced-token models (various counts), highlighting the trade-off between computational efficiency and accuracy. It specifically investigates whether a text-agnostic token selection approach (like VisionZip) can overcome information loss associated with discarding many tokens. The results are shown for three different scenarios to evaluate how effective different token-reduction strategies are, showcasing the effects of feature misalignment that occurs when using a smaller set of tokens for representing the image.
read the caption
Table 5: Quantitative analysis for the feature misalignment
| Size | Time | Acc |
|---|---|---|
| 7B | 1,714s | 61.3 |
| 13B | 2,516s | 64.3 |
| 13B† | 1,246s | 62.2 |
🔼 This table shows the number of dominant and contextual visual tokens used by the VisionZip model for different settings on two vision language models: LLaVA-1.5 and Mini-Gemini. Dominant tokens are the most informative tokens selected by VisionZip, while contextual tokens are generated by merging the remaining, less informative tokens. The table shows how many dominant and contextual tokens are used with different numbers of retained total tokens.
read the caption
Table 8: Token number settings for VisionZip in LLaVA-1.5 [32] and Mini-Gemini [30]
| Retain 64 | Retain 128 | Retain 192 | ||||
|---|---|---|---|---|---|---|
| Dominant | Contextual | Dominant | Contextual | Dominant | Contextual | |
| LLaVA-1.5 | 54 | 10 | 108 | 20 | 162 | 30 |
| Mini-Gemini | 54 | 10 | 108 | 20 | 162 | 30 |
🔼 This table details the number of dominant and contextual visual tokens used in the VisionZip method for the LLaVA-NeXT model [33]. It shows different configurations, with varying numbers of retained tokens, to demonstrate the flexibility of the method. For each configuration, the counts of dominant tokens (highly informative tokens) and contextual tokens (merged tokens summarizing additional details) are given. These numbers illustrate the trade-off between model efficiency and performance.
read the caption
Table 9: Token number settings for VisionZip in LLaVA-NeXT [33]
| Retain 160 | Retain 320 | Retain 640 | ||||
|---|---|---|---|---|---|---|
| Dominant | Contextual | Dominant | Contextual | Dominant | Contextual | |
| LLaVA NeXT | 135 | 25 | 270 | 50 | 540 | 100 |
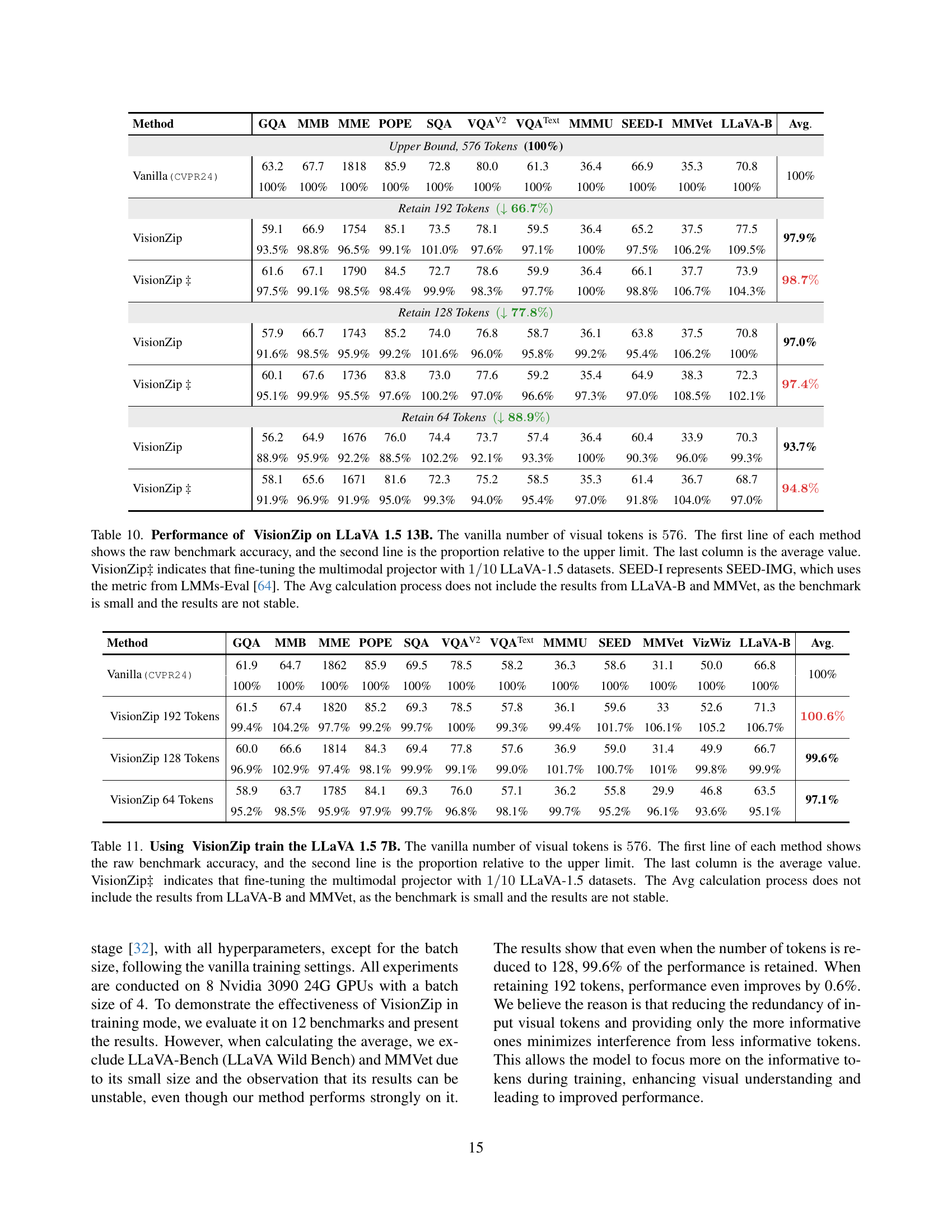
🔼 This table presents the performance comparison of the VisionZip method against the baseline LLaVA 1.5 13B model and other state-of-the-art methods (FastV and SparseVLM) across eleven image understanding benchmarks. The baseline model uses 576 visual tokens. VisionZip is tested with reduced numbers of visual tokens (192, 128, and 64), both with and without fine-tuning the model’s projector using a small subset of the LLaVA-1.5 dataset (indicated by ‡). The table shows the accuracy of each method for each benchmark, expressed as a percentage of the baseline’s performance (100%). The average accuracy across all benchmarks (excluding LLaVA-B and MMVet due to their small size and instability) is also provided for each configuration. The SEED-I column uses the metric from the LMMs-Eval [64] benchmark.
read the caption
Table 10: Performance of VisionZip on LLaVA 1.5 13B. The vanilla number of visual tokens is 576576576576. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. VisionZip‡ indicates that fine-tuning the multimodal projector with 1/101101/101 / 10 LLaVA-1.5 datasets. SEED-I represents SEED-IMG, which uses the metric from LMMs-Eval [64]. The Avg calculation process does not include the results from LLaVA-B and MMVet, as the benchmark is small and the results are not stable.
| Method | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED-I | MMVet | LLaVA-B | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 576 Tokens (100%) | ||||||||||||
| Vanilla(CVPR24) | 63.2 | 67.7 | 1818 | 85.9 | 72.8 | 80.0 | 61.3 | 36.4 | 66.9 | 35.3 | 70.8 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Retain 192 Tokens (↓ 66.7%) | ||||||||||||
| VisionZip | 59.1 | 66.9 | 1754 | 85.1 | 73.5 | 78.1 | 59.5 | 36.4 | 65.2 | 37.5 | 77.5 | 97.9% |
| 93.5% | 98.8% | 96.5% | 99.1% | 101.0% | 97.6% | 97.1% | 100% | 97.5% | 106.2% | 109.5% | ||
| VisionZip ‡ | 61.6 | 67.1 | 1790 | 84.5 | 72.7 | 78.6 | 59.9 | 36.4 | 66.1 | 37.7 | 73.9 | 98.7% |
| 97.5% | 99.1% | 98.5% | 98.4% | 99.9% | 98.3% | 97.7% | 100% | 98.8% | 106.7% | 104.3% | ||
| Retain 128 Tokens (↓ 77.8%) | ||||||||||||
| VisionZip | 57.9 | 66.7 | 1743 | 85.2 | 74.0 | 76.8 | 58.7 | 36.1 | 63.8 | 37.5 | 70.8 | 97.0% |
| 91.6% | 98.5% | 95.9% | 99.2% | 101.6% | 96.0% | 95.8% | 99.2% | 95.4% | 106.2% | 100% | ||
| VisionZip ‡ | 60.1 | 67.6 | 1736 | 83.8 | 73.0 | 77.6 | 59.2 | 35.4 | 64.9 | 38.3 | 72.3 | 97.4% |
| 95.1% | 99.9% | 95.5% | 97.6% | 100.2% | 97.0% | 96.6% | 97.3% | 97.0% | 108.5% | 102.1% | ||
| Retain 64 Tokens (↓ 88.9%) | ||||||||||||
| VisionZip | 56.2 | 64.9 | 1676 | 76.0 | 74.4 | 73.7 | 57.4 | 36.4 | 60.4 | 33.9 | 70.3 | 93.7% |
| 88.9% | 95.9% | 92.2% | 88.5% | 102.2% | 92.1% | 93.3% | 100% | 90.3% | 96.0% | 99.3% | ||
| VisionZip ‡ | 58.1 | 65.6 | 1671 | 81.6 | 72.3 | 75.2 | 58.5 | 35.3 | 61.4 | 36.7 | 68.7 | 94.8% |
| 91.9% | 96.9% | 91.9% | 95.0% | 99.3% | 94.0% | 95.4% | 97.0% | 91.8% | 104.0% | 97.0% |
🔼 Table 11 presents a comprehensive evaluation of VisionZip’s performance when integrated into the training process of the LLaVA 1.5 7B model. It compares the model’s accuracy across eleven benchmark datasets, varying the number of visual tokens used (192, 128, and 64) while using VisionZip in the training stage. The table shows both the raw accuracy scores and the accuracy relative to a baseline model using the full 576 visual tokens (100%). A separate row also displays the results when fine-tuning the multimodal projector of VisionZip using a subset (1/10) of the LLaVA-1.5 dataset. Note that two benchmarks, LLaVA-B and MMVet, are excluded from the average accuracy calculation due to their smaller size and reported instability of results.
read the caption
Table 11: Using VisionZip train the LLaVA 1.5 7B. The vanilla number of visual tokens is 576576576576. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. VisionZip‡ indicates that fine-tuning the multimodal projector with 1/101101/101 / 10 LLaVA-1.5 datasets. The Avg calculation process does not include the results from LLaVA-B and MMVet, as the benchmark is small and the results are not stable.
| Method | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED | MMVet | VizWiz | LLaVA-B | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vanilla (CVPR24) | 61.9 | 64.7 | 1862 | 85.9 | 69.5 | 78.5 | 58.2 | 36.3 | 58.6 | 31.1 | 50.0 | 66.8 | 100% | |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | |||
| VisionZip 192 Tokens | 61.5 | 67.4 | 1820 | 85.2 | 69.3 | 78.5 | 57.8 | 36.1 | 59.6 | 33 | 52.6 | 71.3 | 100.6% | |
| 99.4% | 104.2% | 97.7% | 99.2% | 99.7% | 100% | 99.3% | 99.4% | 101.7% | 106.1% | 105.2 | 106.7% | |||
| VisionZip 128 Tokens | 60.0 | 66.6 | 1814 | 84.3 | 69.4 | 77.8 | 57.6 | 36.9 | 59.0 | 31.4 | 49.9 | 66.7 | 99.6% | |
| 96.9% | 102.9% | 97.4% | 98.1% | 99.9% | 99.1% | 99.0% | 101.7% | 100.7% | 101% | 99.8% | 99.9% | |||
| VisionZip 64 Tokens | 58.9 | 63.7 | 1785 | 84.1 | 69.3 | 76.0 | 57.1 | 36.2 | 55.8 | 29.9 | 46.8 | 63.5 | 97.1% | |
| 95.2% | 98.5% | 95.9% | 97.9% | 99.7% | 96.8% | 98.1% | 99.7% | 95.2% | 96.1% | 93.6% | 95.1% |
🔼 This table presents the performance comparison of VisionZip against baseline and other state-of-the-art methods on the LLaVA-NeXT 7B model for image understanding tasks. It shows the performance (accuracy) for each method across various benchmarks, with results presented as both raw scores and percentages relative to a baseline with the full number of visual tokens (2880). Different configurations of VisionZip, using reduced numbers of visual tokens (640, 320, and 160), are shown. The table also indicates where the VisionZip results include fine-tuning of the model’s multimodal projector using a subset of the LLaVA-1.5 dataset. Finally, an average performance across all benchmarks is provided.
read the caption
Table 12: Performance of VisionZip on LLaVA NeXT 7B. The vanilla number of visual tokens is 2880288028802880. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. VisionZip‡ indicates that fine-tuning the multimodal projector with 1/101101/101 / 10 LLaVA-1.5 datasets. SEED-I represents SEED-IMG, which uses the metric from LMMs-Eval [64].
| Method | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED-I | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 2880 Tokens (100%) | 100% | |||||||||
| Vanilla | 64.2 | 67.9 | 1842 | 86.4 | 70.2 | 80.1 | 61.3 | 35.1 | 70.2 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Retain 640 Tokens (↓ 77.8%) | ||||||||||
| VisionZip | 61.3 | 66.3 | 1787 | 86.3 | 68.1 | 79.1 | 60.2 | 34.7 | 66.7 | 97.5% |
| 95.5% | 97.6% | 97.0% | 99.9% | 97.0% | 98.8% | 98.2% | 98.9% | 95.0% | ||
| VisionZip ‡ | 62.4 | 65.9 | 1778 | 87.6 | 67.9 | 79.9 | 60.8 | 37.2 | 67.8 | 98.9% |
| 97.2% | 97.1% | 96.5% | 101.4% | 96.7% | 99.8% | 99.2% | 106.0% | 96.6% | ||
| Retain 320 Tokens (↓ 88.9%) | ||||||||||
| VisionZip | 59.3 | 63.1 | 1702 | 82.1 | 67.3 | 76.2 | 58.9 | 35.3 | 63.4 | 94.5% |
| 92.3% | 92.9% | 92.4% | 95.0% | 95.9% | 95.1% | 96.1% | 100.5% | 90.3% | ||
| VisionZip ‡ | 61.0 | 64.4 | 1770 | 86.2 | 67.5 | 78.4 | 59.3 | 38.0 | 65.9 | 97.6% |
| 95.0% | 94.8% | 96.1% | 99.8% | 96.2% | 97.9% | 96.7% | 108.3% | 93.9% | ||
| Retain 160 Tokens (↓ 94.4%) | ||||||||||
| VisionZip | 55.5 | 60.1 | 1630 | 74.8 | 68.3 | 71.4 | 56.2 | 36.1 | 58.3 | 91.5% |
| 86.4% | 88.5% | 88.5% | 86.6% | 97.3% | 89.1% | 91.7% | 102.8% | 83.0% | ||
| VisionZip ‡ | 58.2 | 63.9 | 1699 | 83.4 | 67.5 | 75.6 | 57.3 | 37.7 | 62.9 | 95.0% |
| 90.7% | 94.1% | 92.2% | 96.5% | 96.2% | 94.4% | 93.5% | 107.4% | 89.6% |
🔼 Table 13 presents the performance comparison of the VisionZip method on the LLaVA-NeXT 13B model for image understanding tasks. It evaluates the model’s performance with varying numbers of visual tokens (2880, 640, 320, and 160) against the baseline model. The table shows both raw accuracy and the percentage relative to the baseline’s performance. VisionZip‡ denotes results obtained after fine-tuning the model’s multimodal projector using a subset (1/10) of the LLaVA-1.5 dataset. SEED-I refers to the SEED-IMG benchmark which uses metrics from LMMs-Eval [64]. The average score across all benchmarks is also included.
read the caption
Table 13: Performance of VisionZip on LLaVA NeXT 13B. The vanilla number of visual tokens is 2880288028802880. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. VisionZip‡ indicates that fine-tuning the multimodal projector with 1/101101/101 / 10 LLaVA-1.5 datasets. SEED-I represents SEED-IMG, which uses the metric from LMMs-Eval [64].
| Method | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED-I | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 2880 Tokens (100%) | ||||||||||
| Vanilla 13B | 65.4 | 70.0 | 1901 | 86.2 | 73.5 | 81.8 | 64.3 | 36.2 | 71.9 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Vanilla 7B | 64.2 | 67.9 | 1842 | 86.4 | 70.2 | 80.1 | 61.3 | 35.1 | 70.2 | 97.2% |
| 98.2% | 96.3% | 96.9% | 100.2% | 95.5% | 97.9% | 95.3% | 97.0% | 97.6% | ||
| Retain 640 Tokens (↓ 77.8%) | ||||||||||
| VisionZip | 63.0 | 68.6 | 1871 | 85.7 | 71.2 | 79.7 | 62.2 | 36.4 | 68.8 | 97.5% |
| 96.3% | 98.0% | 98.4% | 99.4% | 96.7% | 96.9% | 96.7% | 100.5% | 95.7% | ||
| VisionZip ‡ | 63.7 | 66.6 | 1829 | 86.3 | 73.2 | 81.2 | 64.4 | 38.1 | 69.2 | 98.8% |
| 97.4% | 95.1% | 96.2% | 100.1% | 99.6% | 99.3% | 100.2% | 105.2% | 96.2% | ||
| Retain 320 Tokens (↓ 88.9%) | ||||||||||
| VisionZip | 60.7 | 67.2 | 1805 | 82.0 | 70.3 | 76.8 | 60.9 | 35.6 | 65.2 | 94.7% |
| 92.8% | 96.0% | 95.0% | 95.1% | 95.6% | 93.9% | 94.7% | 98.3% | 90.7% | ||
| VisionZip ‡ | 62.5 | 66.9 | 1861 | 85.7 | 72.7 | 80.0 | 63.2 | 36.9 | 67.9 | 97.8% |
| 95.6% | 95.6% | 97.9% | 99.4% | 98.9% | 97.8% | 98.3% | 101.9% | 94.4% | ||
| Retain 160 Tokens (↓ 94.4%) | ||||||||||
| VisionZip | 57.8 | 64.9 | 1739 | 76.6 | 69.3 | 72.4 | 58.4 | 37.0 | 61.1 | 91.3% |
| 88.4% | 92.7% | 91.5% | 88.9% | 94.3% | 88.5% | 90.8% | 102.2% | 84.8% | ||
| VisionZip ‡ | 59.7 | 65.3 | 1766 | 84.0 | 72.0 | 77.6 | 60.8 | 36.0 | 64.4 | 94.6% |
| 91.3% | 93.3% | 92.9% | 97.4% | 98.0% | 94.9% | 94.6% | 99.4% | 89.6% |
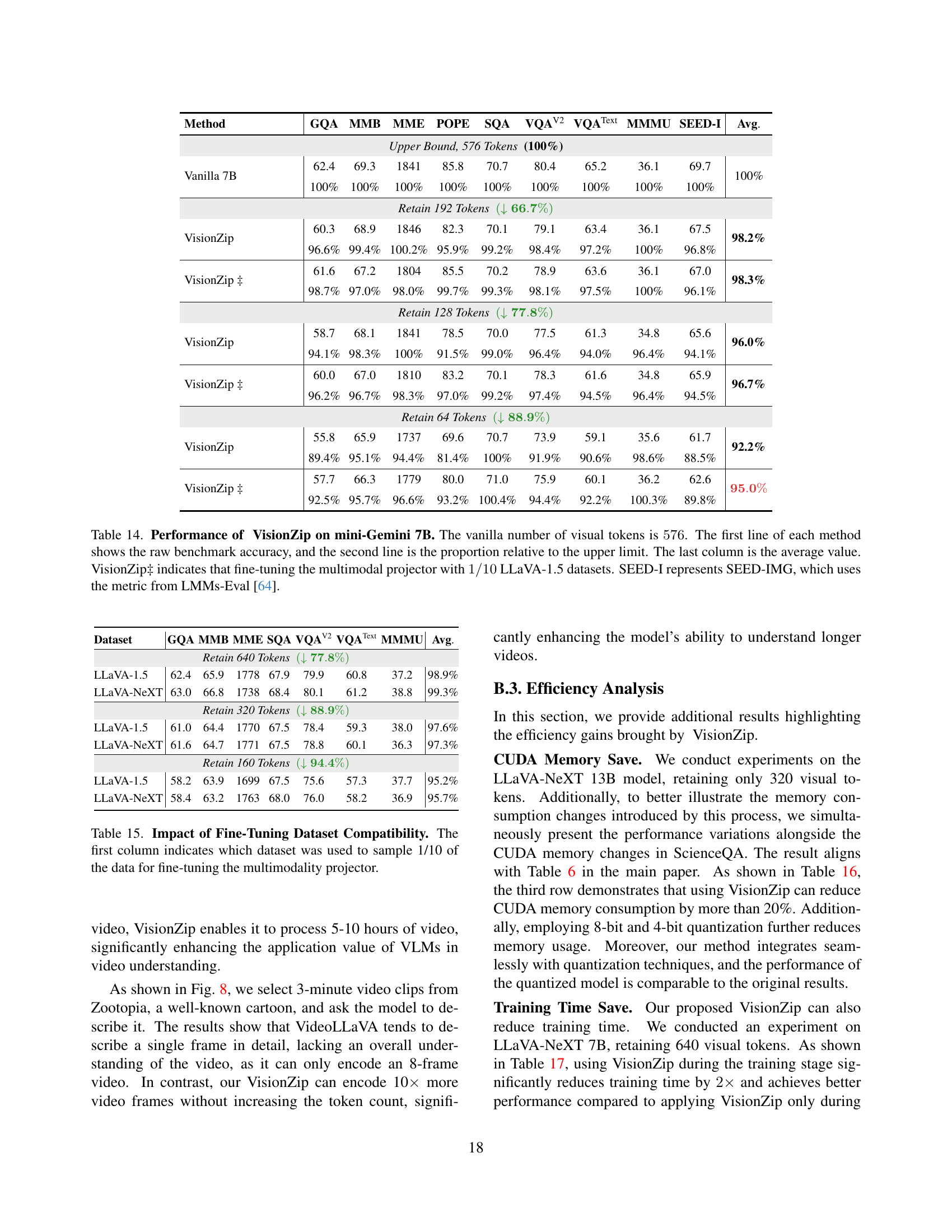
🔼 Table 14 presents the performance comparison of VisionZip against several baseline methods on the Mini-Gemini 7B model for image understanding tasks. The model’s performance is evaluated across multiple benchmarks, with the original model’s performance on all benchmarks considered as 100%. VisionZip is tested under three different configurations of retained visual tokens (192, 128, and 64), showing its performance with and without fine-tuning of the multimodal projector using a subset of the LLaVA-1.5 dataset (indicated by VisionZip‡). Each row represents a method, with the first line showing the raw accuracy and the second line showing the percentage relative to the baseline model. The final column provides the average performance across all benchmarks.
read the caption
Table 14: Performance of VisionZip on mini-Gemini 7B. The vanilla number of visual tokens is 576576576576. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. VisionZip‡ indicates that fine-tuning the multimodal projector with 1/101101/101 / 10 LLaVA-1.5 datasets. SEED-I represents SEED-IMG, which uses the metric from LMMs-Eval [64].
| Method | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED-I | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 576 Tokens (100%) | ||||||||||
| Vanilla 7B | 62.4 | 69.3 | 1841 | 85.8 | 70.7 | 80.4 | 65.2 | 36.1 | 69.7 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Retain 192 Tokens (↓ 66.7%) | ||||||||||
| VisionZip | 60.3 | 68.9 | 1846 | 82.3 | 70.1 | 79.1 | 63.4 | 36.1 | 67.5 | 98.2% |
| 96.6% | 99.4% | 100.2% | 95.9% | 99.2% | 98.4% | 97.2% | 100% | 96.8% | ||
| VisionZip ‡ | 61.6 | 67.2 | 1804 | 85.5 | 70.2 | 78.9 | 63.6 | 36.1 | 67.0 | 98.3% |
| 98.7% | 97.0% | 98.0% | 99.7% | 99.3% | 98.1% | 97.5% | 100% | 96.1% | ||
| Retain 128 Tokens (↓ 77.8%) | ||||||||||
| VisionZip | 58.7 | 68.1 | 1841 | 78.5 | 70.0 | 77.5 | 61.3 | 34.8 | 65.6 | 96.0% |
| 94.1% | 98.3% | 100% | 91.5% | 99.0% | 96.4% | 94.0% | 96.4% | 94.1% | ||
| VisionZip ‡ | 60.0 | 67.0 | 1810 | 83.2 | 70.1 | 78.3 | 61.6 | 34.8 | 65.9 | 96.7% |
| 96.2% | 96.7% | 98.3% | 97.0% | 99.2% | 97.4% | 94.5% | 96.4% | 94.5% | ||
| Retain 64 Tokens (↓ 88.9%) | ||||||||||
| VisionZip | 55.8 | 65.9 | 1737 | 69.6 | 70.7 | 73.9 | 59.1 | 35.6 | 61.7 | 92.2% |
| 89.4% | 95.1% | 94.4% | 81.4% | 100% | 91.9% | 90.6% | 98.6% | 88.5% | ||
| VisionZip ‡ | 57.7 | 66.3 | 1779 | 80.0 | 71.0 | 75.9 | 60.1 | 36.2 | 62.6 | 95.0% |
| 92.5% | 95.7% | 96.6% | 93.2% | 100.4% | 94.4% | 92.2% | 100.3% | 89.8% |
🔼 This table presents an ablation study analyzing the impact of using different fine-tuning datasets on the performance of VisionZip. It shows the results of fine-tuning the multi-modal projector with 1/10th of either the LLaVA-1.5 or LLaVA-NeXT datasets, for three different visual token counts (640, 320, and 160). The goal is to determine the effect of dataset compatibility on VisionZip’s performance when reducing the number of visual tokens.
read the caption
Table 15: Impact of Fine-Tuning Dataset Compatibility. The first column indicates which dataset was used to sample 1/10 of the data for fine-tuning the multimodality projector.
| Dataset | GQA | MMB | MME | SQA | VQAV2 | VQAText | MMMU | Avg. |
|---|---|---|---|---|---|---|---|---|
| Retain 640 Tokens (↓ 77.8%**) | ||||||||
| LLaVA-1.5 | 62.4 | 65.9 | 1778 | 67.9 | 79.9 | 60.8 | 37.2 | 98.9% |
| LLaVA-NeXT | 63.0 | 66.8 | 1738 | 68.4 | 80.1 | 61.2 | 38.8 | 99.3% |
| Retain 320 Tokens (↓ 88.9%**) | ||||||||
| LLaVA-1.5 | 61.0 | 64.4 | 1770 | 67.5 | 78.4 | 59.3 | 38.0 | 97.6% |
| LLaVA-NeXT | 61.6 | 64.7 | 1771 | 67.5 | 78.8 | 60.1 | 36.3 | 97.3% |
| Retain 160 Tokens (↓ 94.4%**) | ||||||||
| LLaVA-1.5 | 58.2 | 63.9 | 1699 | 67.5 | 75.6 | 57.3 | 37.7 | 95.2% |
| LLaVA-NeXT | 58.4 | 63.2 | 1763 | 68.0 | 76.0 | 58.2 | 36.9 | 95.7% |
🔼 This table presents a performance comparison of different vision models on the LLaVA-NeXT 13B benchmark. It shows the results of using VisionZip (with and without quantization) against a baseline vanilla model and other relevant efficient VLMs. The raw accuracy, accuracy relative to the baseline (100%), and average accuracy are provided across multiple benchmark tasks. CUDA memory usage for a single NVIDIA A800 GPU on the SQA task is also included for comparison. The table highlights the tradeoff between accuracy and efficiency when using VisionZip for reduction in visual tokens.
read the caption
Table 16: Performance and Memory of VisionZip on LLaVA NeXT 13B with the Quantization. The vanilla number of visual tokens is 2880288028802880. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. SEED-I represents SEED-IMG, which uses the metric from LMMs-Eval [64]. The memory refers to the practical CUDA memory usage on a single Nvidia A800 GPU for SQA.
| Method | Memory | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED-I | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 2880 Tokens (100%) | |||||||||||
| Vanilla 13B | 36721Mb | 65.4 | 70.0 | 1901 | 86.2 | 73.5 | 81.8 | 64.3 | 36.2 | 71.9 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| Vanilla 7B | 18952Mb | 64.2 | 67.9 | 1842 | 86.4 | 70.2 | 80.1 | 61.3 | 35.1 | 70.2 | 97.2% |
| 98.2% | 96.3% | 96.9% | 100.2% | 95.5% | 97.9% | 95.3% | 97.0% | 97.6% | |||
| Retain 320 Tokens (↓ 88.9%) | |||||||||||
| VisionZip | 28810Mb | 60.7 | 67.2 | 1805 | 82.0 | 70.3 | 76.8 | 60.9 | 35.6 | 65.2 | 94.7% |
| 92.8% | 96.0% | 95.0% | 95.1% | 95.6% | 93.9% | 94.7% | 98.3% | 90.7% | |||
| VisionZip-8bit | 16632Mb | 60.6 | 67.1 | 1798 | 81.4 | 70.8 | 76.8 | 60.5 | 37.0 | 65.4 | 95.0% |
| 92.7% | 95.9% | 94.6% | 94.4% | 96.3% | 93.9% | 94.1% | 102.2% | 91.0% | |||
| VisionZip-4bit | 10176Mb | 60.3 | 65.1 | 1773 | 82.1 | 70.3 | 76.6 | 60.0 | 36.1 | 65.1 | 94.0% |
| 92.2% | 93.0% | 93.3% | 95.2% | 95.6% | 93.6% | 93.3% | 99.7% | 90.5% |
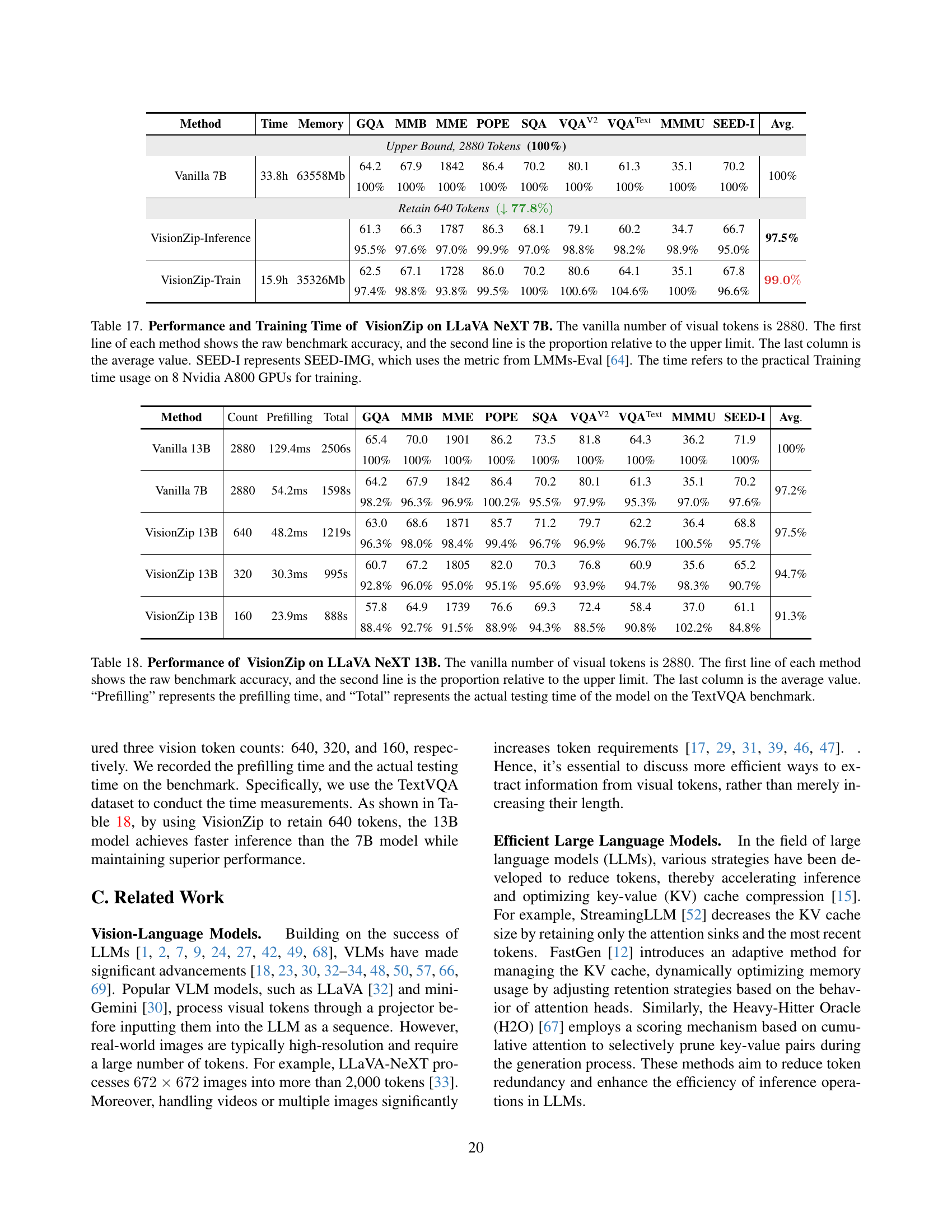
🔼 This table presents a comparison of the performance and training time of the VisionZip model against a baseline LLaVA-NeXT 7B model across multiple benchmarks. It shows the impact of VisionZip’s visual token reduction strategy on accuracy and training efficiency. The results are shown for different numbers of retained visual tokens (640, 320, and 160). The percentage accuracy relative to a baseline (full 2880 tokens) is displayed, alongside the training time in hours. The average performance across all benchmarks is provided for each model. The experiment was conducted on 8 Nvidia A800 GPUs.
read the caption
Table 17: Performance and Training Time of VisionZip on LLaVA NeXT 7B. The vanilla number of visual tokens is 2880288028802880. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. SEED-I represents SEED-IMG, which uses the metric from LMMs-Eval [64]. The time refers to the practical Training time usage on 8 Nvidia A800 GPUs for training.
| Method | Time | Memory | GQA | MMB | MME | POPE | SQA | VQAV2 | VQAText | MMMU | SEED-I | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper Bound, 2880 Tokens (100%) | ||||||||||||
| Vanilla 7B | 33.8h | 63558Mb | 64.2 | 67.9 | 1842 | 86.4 | 70.2 | 80.1 | 61.3 | 35.1 | 70.2 | 100% |
| 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | ||||
| Retain 640 Tokens (↓ 77.8%) | ||||||||||||
| VisionZip-Inference | 61.3 | 66.3 | 1787 | 86.3 | 68.1 | 79.1 | 60.2 | 34.7 | 66.7 | 97.5% | ||
| 95.5% | 97.6% | 97.0% | 99.9% | 97.0% | 98.8% | 98.2% | 98.9% | 95.0% | ||||
| VisionZip-Train | 15.9h | 35326Mb | 62.5 | 67.1 | 1728 | 86.0 | 70.2 | 80.6 | 64.1 | 35.1 | 67.8 | 99.0% |
| 97.4% | 98.8% | 93.8% | 99.5% | 100% | 100.6% | 104.6% | 100% | 96.6% |
🔼 This table presents the performance of the VisionZip method on the LLaVA-NeXT 13B model for image understanding tasks. It compares the performance of VisionZip with different numbers of visual tokens (640, 320, 160) against the baseline (full 2880 tokens) and other state-of-the-art methods. The results are shown as both raw accuracy and the percentage relative to the full-token baseline. Additionally, the table includes prefilling time (latency to generate the first token) and total inference time on the TextVQA benchmark, highlighting the efficiency gains achieved by VisionZip.
read the caption
Table 18: Performance of VisionZip on LLaVA NeXT 13B. The vanilla number of visual tokens is 2880288028802880. The first line of each method shows the raw benchmark accuracy, and the second line is the proportion relative to the upper limit. The last column is the average value. “Prefilling” represents the prefilling time, and “Total” represents the actual testing time of the model on the TextVQA benchmark.
Full paper#