↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for aligning robots with human preferences, such as Reinforcement Learning from Human Feedback (RLHF), are very data-intensive and thus impractical for real-world robotic applications. This significantly limits the deployment of advanced, pre-trained robot policies. The paper highlights this issue as a key obstacle towards more advanced and human-friendly robots.
To address the limitations of RLHF, the authors propose a novel method called Representation-Aligned Preference-based Learning (RAPL). RAPL leverages human feedback to fine-tune pre-trained vision encoders, aligning the robot’s visual representation with the user’s perception. A reward function is then constructed using this aligned representation, enabling efficient learning and improving the robot’s ability to adhere to human preferences. Experimental results, both in simulation and using real robots, demonstrate RAPL’s efficacy in reducing the need for human feedback and improving alignment with significantly less preference data.
Key Takeaways#
Why does it matter?#
This paper is important because it presents RAPL, a novel method for efficiently aligning visuomotor robot policies with human preferences using minimal feedback. This addresses a critical challenge in robotics, paving the way for more human-friendly and safer robots. The reduced human feedback requirement is particularly significant, making the approach more practical for real-world applications. Furthermore, the strong zero-shot generalization demonstrated opens up exciting avenues for future research.
Visual Insights#

🔼 Figure 1 illustrates the Representation-Aligned Preference-based Learning (RAPL) method. The core idea is to efficiently learn visual rewards for robots using minimal human feedback. Instead of directly providing feedback on robot actions, RAPL leverages human preferences to fine-tune a pre-trained vision encoder. This alignment ensures the robot’s visual representation better matches the user’s perspective. An optimal transport-based visual reward is then created using this aligned representation, enabling more effective policy alignment. The figure uses the example of a robot picking up a bag of chips to highlight the difference: before alignment (left), the robot grasps the bag improperly, risking damage; after alignment with RAPL (right), the robot grasps the bag correctly, demonstrating successful alignment with the user’s preferences.
read the caption
Figure 1: Representation-Aligned Preference-based Learning (RAPL), is an observation-only method for learning visual robot rewards from significantly less human preference feedback. (center) Unlike traditional reinforcement learning from human feedback, RAPL focuses human feedback on fine-tuning pre-trained vision encoders to align with the end-user’s visual representation. The aligned representation is used to construct an optimal transport-based visual reward for aligning the robot’s visuomotor policy. (left) Before alignment, the robot frequently picks up a bag of chips by squeezing the middle, risking damage to the contents. (right) After alignment with our RAPL reward, the robot adheres to the end-user’s preference and picks up the bag by its edges.
| Method | Franka Group | Franka Clutter | Kuka Group |
|---|---|---|---|
| RAPL ➡ | 0.59 | 0.61 | 0.47 |
| RLHF ➡ | 0.38 | 0.26 | 0.31 |
| MVP-OT ➡ | -0.1 | 0.08 | 0.02 |
| FT-MVP-OT ➡ | 0.19 | 0.11 | 0.02 |
| ImNet-OT ➡ | -0.09 | -0.02 | 0.12 |
| R3M-OT ➡ | 0.03 | -0.17 | -0.14 |
🔼 This table presents the Spearman’s rank correlation coefficients, which measure the monotonic relationship between the ground truth reward and the rewards predicted by different methods. Higher coefficients indicate stronger agreement between the predicted and actual rewards. The methods compared include RAPL (the proposed method), RLHF (Reinforcement Learning from Human Feedback), several variations employing optimal transport (OT) with different visual representation backbones, such as MVP-OT and Fine-Tuned-MVP-OT, as well as ImageNet-OT and R3M-OT. The correlation is calculated separately for three tasks: Franka Group, Franka Clutter, and Kuka Group, reflecting different robotic manipulation scenarios.
read the caption
Table 1: Spearman’s rank correlation coefficient between the GT reward and each learned visual reward.
In-depth insights#
RAPL: Core Idea#
RAPL’s core idea is to efficiently align visuomotor robot policies with human preferences using minimal feedback. It achieves this by focusing human feedback on aligning the robot’s visual representation with that of the human, rather than directly learning a reward function from numerous pairwise comparisons of robot actions. This is done by fine-tuning a pre-trained vision encoder using triplet comparisons ranked by human preference, effectively teaching the robot what visual features matter to the user. Once aligned, a dense visual reward is constructed using feature matching (like optimal transport), enabling efficient policy optimization. This approach is particularly valuable because it reduces the significant human effort traditionally required in RLHF for visual reward learning, achieving comparable performance with far less data.
Sim-to-Real Transfer#
Sim-to-real transfer, a critical aspect of robotics research, seeks to bridge the gap between simulated and real-world environments. Success hinges on the fidelity of the simulator, accurately reflecting the complexities of the real world, including sensor noise, actuator limitations, and unforeseen environmental factors. The paper’s approach to minimizing human feedback in reward learning is particularly relevant to sim-to-real transfer. Reduced human feedback requirements mean that training can potentially be performed in simulation, with less need for costly and time-consuming real-world data collection. However, the robustness of learned rewards must be carefully considered, as any discrepancies between the simulated and real environments could lead to performance degradation or even catastrophic failures in the real world. Generalization across different robot embodiments is another crucial aspect. The methods discussed, if successful, should enable sim-to-real transfer by leveraging simulation training and transferring the learned policy to real robots with minimal further training. The demonstrated success in transferring across different robots suggests promising progress towards more practical sim-to-real methods.
Human Feedback#
Human feedback is crucial for aligning artificial intelligence (AI) systems, particularly in visuomotor robotics, with human preferences. Traditional approaches, like reinforcement learning from human feedback (RLHF), are often prohibitively expensive due to the large amounts of feedback needed for visual reward function learning. This paper addresses this limitation by focusing on efficiently leveraging human feedback through a novel method called Representation-Aligned Preference-based Learning (RAPL). RAPL cleverly uses human feedback to align the robot’s visual representation with that of the human user, thus enabling a more efficient reward learning process. By focusing the human input on fine-tuning pre-trained vision encoders, rather than directly constructing a reward function, RAPL significantly reduces the amount of human feedback needed, and achieves efficient and effective visuomotor policy alignment. The results demonstrate a substantial reduction in human feedback requirements while achieving high-quality policy alignment, making it a significant step towards more practical and user-friendly AI systems in robotics.
Reward Function#
The core challenge addressed in this paper is reward function learning for visuomotor robot policy alignment. Traditional reinforcement learning from human feedback (RLHF) methods struggle with the high cost of human feedback needed to train visual reward functions. This paper introduces Representation-Aligned Preference-Based Learning (RAPL), aiming to overcome this limitation by focusing human feedback on fine-tuning pre-trained vision encoders. This alignment facilitates construction of a dense visual reward via feature matching within the aligned representation space. RAPL’s efficiency comes from cleverly shifting the learning focus from directly specifying the reward to aligning the robot’s and human’s visual representations. The reward function then arises naturally from optimal transport between these aligned feature distributions, significantly reducing the human feedback burden. Experimental results indicate a high correlation between RAPL’s generated reward and human preferences, showcasing its potential for efficient reward learning in robotics.
Ablation Studies#
Ablation studies, if included in the research paper, would systematically assess the contribution of individual components within the proposed RAPL framework. This would involve removing or modifying specific parts (e.g., the optimal transport reward, specific visual representation learning methods, preference data size) to isolate their effects on overall performance. Results would highlight the importance of each component. For instance, removing the optimal transport reward might lead to a significant drop in reward quality, indicating its crucial role in aligning robot policies with human preferences. Similarly, evaluating various visual representation learning approaches would reveal which method yields the best alignment with human preferences. Analyzing the impact of the preference data size would show how much human feedback is minimally required for effective learning, emphasizing the efficiency of RAPL. By carefully examining these ablation results, the researchers can validate design choices and gain valuable insights into the key mechanisms of RAPL’s success in efficient visuomotor robot policy alignment.
More visual insights#
More on figures

🔼 This figure shows example images from the X-Magical and IsaacGym simulated environments used in the paper’s experiments. The top row displays example robot behaviors that are considered high-reward by human participants, while the bottom row illustrates low-reward behaviors. This highlights the difference in quality or desirability of the robot’s actions from the human’s perspective. These examples are used to train and evaluate the reward function in the proposed Representation-Aligned Preference-based Learning (RAPL) method.
read the caption
Figure 2: X-Magical & IsaacGym tasks. Top row are high-reward behaviors and bottom row are low-reward behaviors according to the human’s preferences.

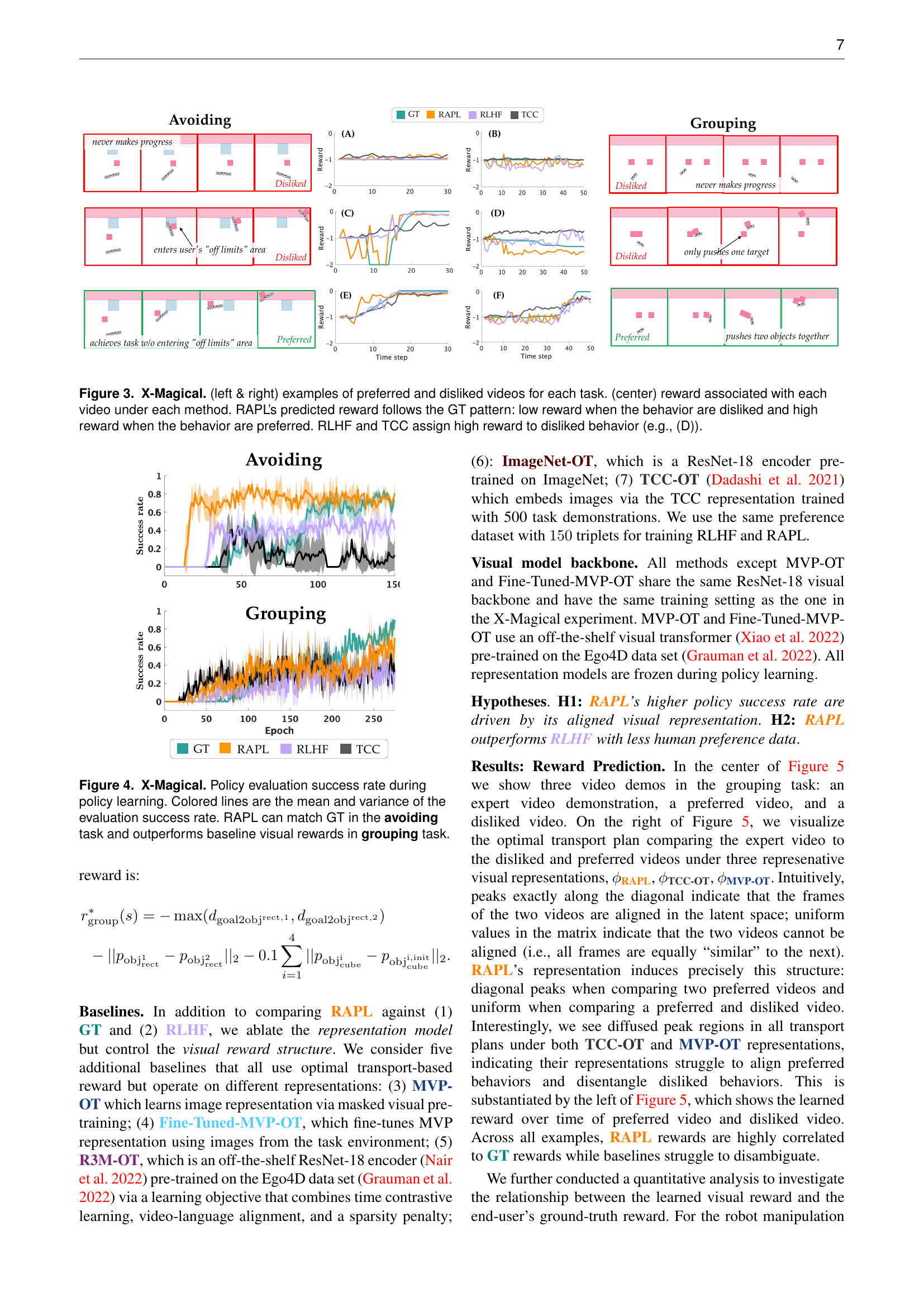
🔼 Figure 3 presents a comparison of reward prediction methods in the X-Magical simulation environment. The left and right panels showcase example videos deemed preferred and disliked, respectively, by a human evaluator for two distinct tasks (‘Avoiding’ and ‘Grouping’). The center panel displays the reward assigned to each video by four different methods: Ground Truth (GT), Representation-Aligned Preference-based Learning (RAPL), Reinforcement Learning from Human Feedback (RLHF), and Temporal Cycle Consistency (TCC). The key finding is that RAPL’s reward predictions closely match the human preferences (high rewards for liked videos, low for disliked), unlike RLHF and TCC which sometimes assign high rewards to disliked behaviors.
read the caption
Figure 3: X-Magical. (left & right) examples of preferred and disliked videos for each task. (center) reward associated with each video under each method. RAPL’s predicted reward follows the GT pattern: low reward when the behavior are disliked and high reward when the behavior are preferred. RLHF and TCC assign high reward to disliked behavior (e.g., (D)).

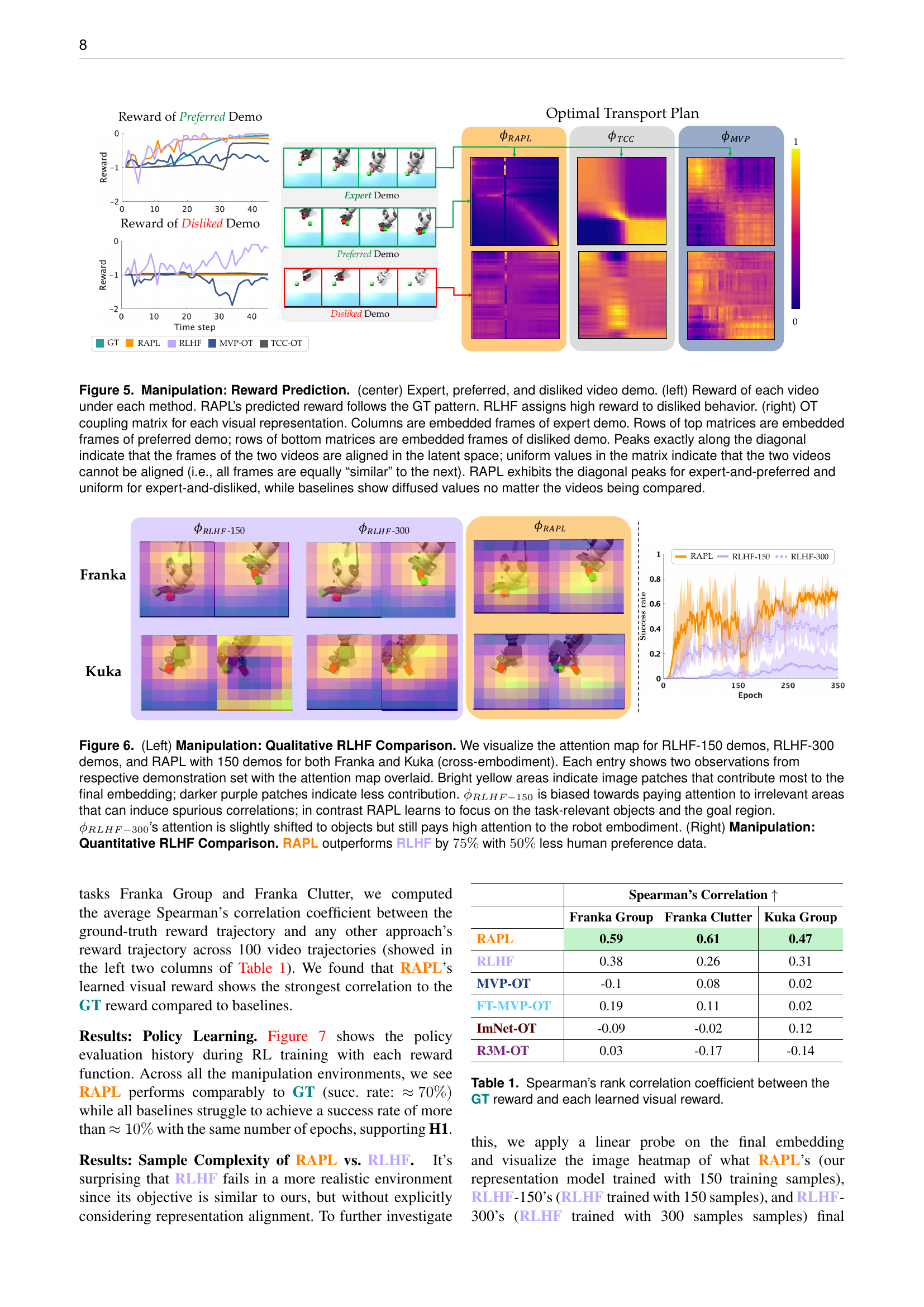
🔼 This figure displays the results of policy evaluation success rates during the training process of different reward learning methods in the X-Magical simulation environment. The plot shows the mean and standard deviation of success rates across multiple trials. The goal is to compare RAPL to a ground truth reward (GT), RLHF (Reinforcement Learning from Human Feedback), and TCC (Temporal Cycle Consistency) methods. The results demonstrate that RAPL achieves comparable performance to the ground truth in the ‘avoiding’ task and outperforms the baseline methods (RLHF and TCC) in the ‘grouping’ task. This highlights RAPL’s effectiveness in learning visual rewards for robotic policy alignment.
read the caption
Figure 4: X-Magical. Policy evaluation success rate during policy learning. Colored lines are the mean and variance of the evaluation success rate. RAPL can match GT in the avoiding task and outperforms baseline visual rewards in grouping task.

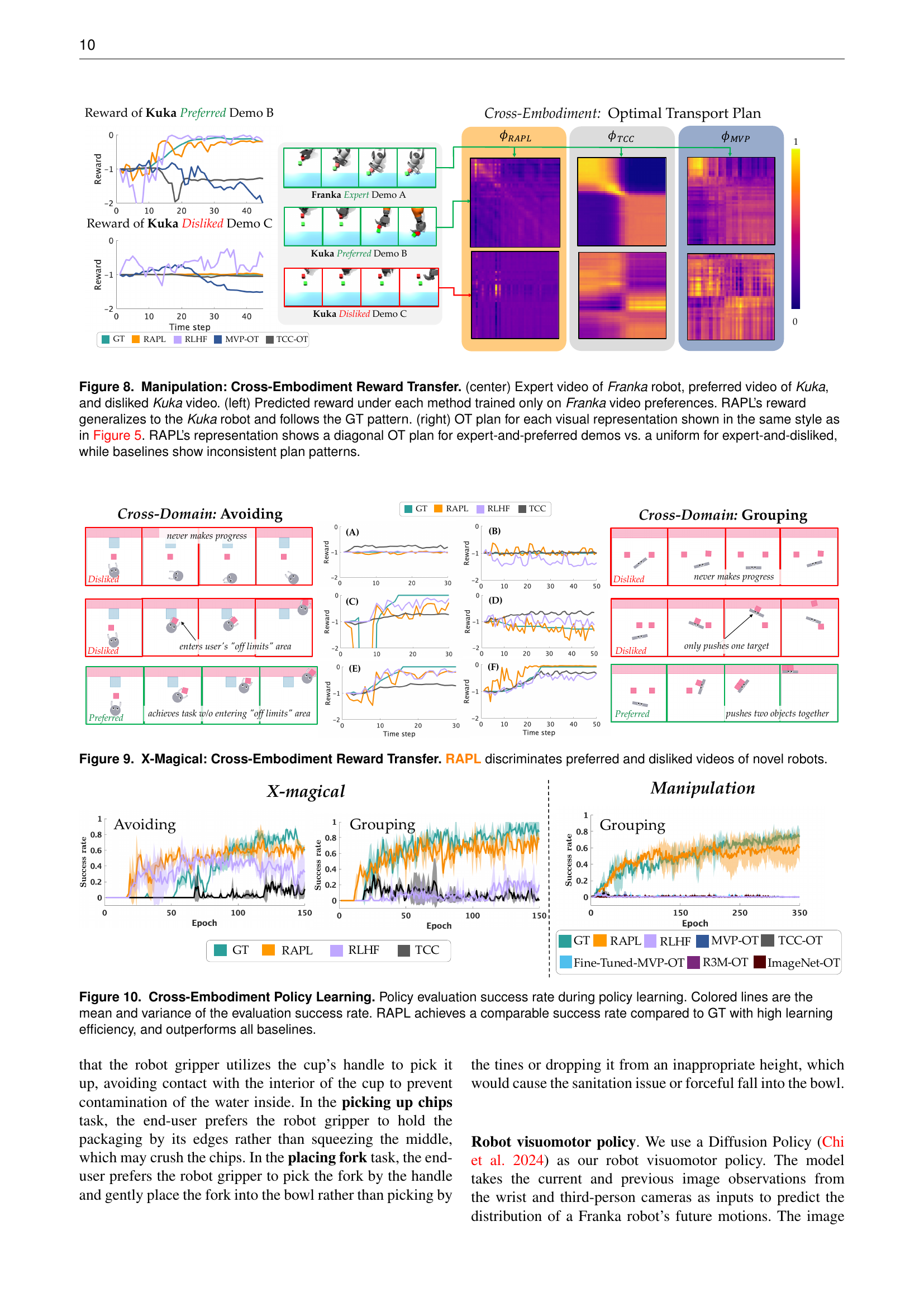
🔼 Figure 5 demonstrates the effectiveness of RAPL in learning a visual reward function that aligns with human preferences. The figure shows a comparison of RAPL against several baseline methods (GT, RLHF, MVP-OT, TCC-OT). Three video demonstrations are shown: an expert demonstration, a preferred demonstration, and a disliked demonstration. The left panel shows the reward assigned to each video by each method. RAPL correctly assigns higher rewards to preferred videos and lower rewards to disliked videos, unlike RLHF which assigns high rewards to disliked videos. The right panel displays optimal transport (OT) coupling matrices for each method. The OT matrices visualize the similarity between the expert video and the preferred/disliked videos in the learned visual representation space. RAPL shows clear diagonal peaks in the OT matrix for the expert-preferred comparison (high similarity), while showing uniform values for expert-disliked (low similarity). In contrast, the baseline methods show diffuse patterns, indicating poor alignment and inability to distinguish preferred from disliked videos.
read the caption
Figure 5: Manipulation: Reward Prediction. (center) Expert, preferred, and disliked video demo. (left) Reward of each video under each method. RAPL’s predicted reward follows the GT pattern. RLHF assigns high reward to disliked behavior. (right) OT coupling matrix for each visual representation. Columns are embedded frames of expert demo. Rows of top matrices are embedded frames of preferred demo; rows of bottom matrices are embedded frames of disliked demo. Peaks exactly along the diagonal indicate that the frames of the two videos are aligned in the latent space; uniform values in the matrix indicate that the two videos cannot be aligned (i.e., all frames are equally “similar” to the next). RAPL exhibits the diagonal peaks for expert-and-preferred and uniform for expert-and-disliked, while baselines show diffused values no matter the videos being compared.

🔼 Figure 6 presents a comparison of RAPL with RLHF for robot manipulation tasks. The left part visualizes attention maps for different models (RLHF-150, RLHF-300, and RAPL) across two robot embodiments (Franka and Kuka), highlighting the focus areas in image observations. It demonstrates that RLHF pays attention to irrelevant areas, while RAPL focuses on task-relevant objects and goals. The right part shows a quantitative comparison, indicating that RAPL outperforms RLHF in terms of success rate while needing significantly less human preference data.
read the caption
Figure 6: (Left) Manipulation: Qualitative RLHF Comparison. We visualize the attention map for RLHF-150 demos, RLHF-300 demos, and RAPL with 150 demos for both Franka and Kuka (cross-embodiment). Each entry shows two observations from respective demonstration set with the attention map overlaid. Bright yellow areas indicate image patches that contribute most to the final embedding; darker purple patches indicate less contribution. ϕRLHF−150subscriptitalic-ϕ𝑅𝐿𝐻𝐹150\phi_{RLHF-150}italic_ϕ start_POSTSUBSCRIPT italic_R italic_L italic_H italic_F - 150 end_POSTSUBSCRIPT is biased towards paying attention to irrelevant areas that can induce spurious correlations; in contrast RAPL learns to focus on the task-relevant objects and the goal region. ϕRLHF−300subscriptitalic-ϕ𝑅𝐿𝐻𝐹300\phi_{RLHF-300}italic_ϕ start_POSTSUBSCRIPT italic_R italic_L italic_H italic_F - 300 end_POSTSUBSCRIPT’s attention is slightly shifted to objects but still pays high attention to the robot embodiment. (Right) Manipulation: Quantitative RLHF Comparison. RAPL outperforms RLHF by 75%percent7575\%75 % with 50%percent5050\%50 % less human preference data.

🔼 This figure displays the success rate of robot policy learning across different visual reward methods. It shows how the success rate changes over time (epochs) during training for different methods: GT (ground truth), RAPL, RLHF, MVP-OT, TCC-OT, Fine-Tuned-MVP-OT, and R3M-OT. The x-axis represents the number of training epochs, and the y-axis shows the success rate in achieving the task. This allows for a comparison of the learning efficiency and overall performance of each reward method in a robot manipulation task.
read the caption
Figure 7: Manipulation: Policy Learning. Success rate during robot policy learning under each visual reward.

🔼 Figure 8 demonstrates the cross-embodiment generalization capability of RAPL. It shows three videos: an expert demonstration (Franka robot), a preferred Kuka robot demonstration, and a disliked Kuka robot demonstration. The left panel displays the reward prediction for each method (trained only on Franka data), revealing that RAPL accurately predicts preferences even for the different Kuka robot. The right panel visualizes optimal transport (OT) plans for various visual representations, highlighting RAPL’s ability to consistently show diagonal patterns (for expert/preferred video pairs) and uniform patterns (for expert/disliked video pairs). In contrast, other methods exhibit inconsistent patterns.
read the caption
Figure 8: Manipulation: Cross-Embodiment Reward Transfer. (center) Expert video of Franka robot, preferred video of Kuka, and disliked Kuka video. (left) Predicted reward under each method trained only on Franka video preferences. RAPL’s reward generalizes to the Kuka robot and follows the GT pattern. (right) OT plan for each visual representation shown in the same style as in Figure 5. RAPL’s representation shows a diagonal OT plan for expert-and-preferred demos vs. a uniform for expert-and-disliked, while baselines show inconsistent plan patterns.

🔼 Figure 9 demonstrates the zero-shot generalization capability of the proposed RAPL method across different robot embodiments in the X-Magical environment. It showcases RAPL’s ability to maintain its ability to discriminate between preferred and disliked robot behaviors even when the robot used to generate the preference data differs from the robot being evaluated. This highlights RAPL’s robustness and generalizability beyond the specific robot used during the training phase of the visual reward model.
read the caption
Figure 9: X-Magical: Cross-Embodiment Reward Transfer. RAPL discriminates preferred and disliked videos of novel robots.
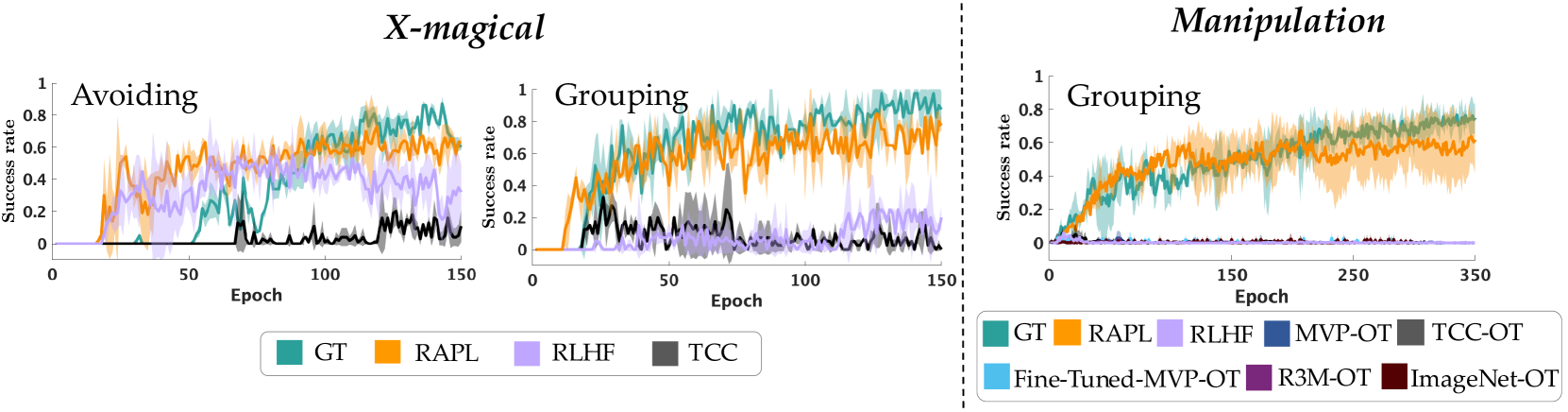
🔼 Figure 10 presents the results of a policy learning experiment designed to evaluate the effectiveness of different visual reward methods in cross-embodiment scenarios. The experiment measured the success rate of each policy during training. The success rate is defined as the percentage of times the robot successfully completed the task based on the evaluation criterion. The x-axis shows the number of training epochs, while the y-axis represents the success rate. The plot shows that the RAPL (Representation-Aligned Preference-based Learning) method achieves a success rate comparable to the ground truth (GT), demonstrating high learning efficiency. Moreover, RAPL significantly outperforms all the baseline methods (RLHF, MVP-OT, TCC-OT, Fine-tuned MVP-OT, R3M-OT, and ImageNet-OT), indicating that RAPL is superior in learning effective visual rewards in cross-embodiment situations.
read the caption
Figure 10: Cross-Embodiment Policy Learning. Policy evaluation success rate during policy learning. Colored lines are the mean and variance of the evaluation success rate. RAPL achieves a comparable success rate compared to GT with high learning efficiency, and outperforms all baselines.

🔼 This figure shows the results of aligning a pre-trained visuomotor policy using the RAPL method. The top row displays the robot’s undesired behaviors before alignment: grasping the inside of a cup, crushing a bag of chips, and dropping a fork. The bottom row shows the improved behavior after applying RAPL rewards, demonstrating alignment with user preferences by correctly grasping the cup’s handle, bag’s edge and the fork’s handle.
read the caption
Figure 11: Diffusion Policy Alignment Results. (Top) The pre-trained visuomotor policy exhibits undesired behaviors: grasping the interior of the cup (left), crushing the chips (middle), and making contact with the tines of the fork and dropping it out of the bowl (right). (Bottom) After alignment using RAPL rewards, the robot’s behaviors are aligned with the end-user’s preferences.
Full paper#