↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Existing video generation models struggle to produce videos with multiple events arranged in a specific temporal order. They often fail to generate all events, misorder them, or produce visually jarring transitions between events. This is because these models primarily rely on single text prompts lacking explicit timing information. This limits their ability to create videos reflecting the natural flow and temporal structure of real-world events.
MinT tackles this by directly incorporating event timestamps into its input. It uses a novel time-based positional encoding method called ReRoPE to align video frames with their corresponding events. By training the model on temporally-grounded video data, MinT achieves significant improvements in generating coherent videos with smoothly connected events and precise control over the timing of each event. This represents a substantial advance in the field, enabling more realistic and nuanced video synthesis for various applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation because it introduces MinT, a novel approach offering precise temporal control over multiple events in generated videos. This addresses a major limitation of existing models and opens avenues for more realistic and controllable video synthesis, impacting fields like film production and virtual reality.
Visual Insights#

🔼 This figure showcases the capabilities of the MinT model in generating videos with multiple events, each controlled by text prompts and precise start and end timestamps. The model successfully synthesizes these events into a coherent video, maintaining consistent subjects and backgrounds throughout. The duration of each event is also flexible, demonstrating MinT’s temporal control. The example videos include a series of hand gestures, everyday activities, facial expressions, and cat movements.
read the caption
Figure 1: Time-controlled multi-event video generation with MinT. Given a sequence of event text prompts and their desired start and end timestamps, MinT synthesizes smoothly connected events with consistent subjects and backgrounds. In addition, it can control the time span of each event flexibly. Here, we show the results of sequential gestures, daily activities, facial expressions, and cat movements.
| Method | FID ↓ | FVD ↓ | VQ ↑ | DD ↑ | CLIP-T ↑ | TA ↑ | TC ↑ | #Cuts ↓ |
|---|---|---|---|---|---|---|---|---|
| Dataset: HoldOut | ||||||||
| MEVG | 57.57 | 495.75 | 2.56 | 3.39 | 0.266 | 2.72 | 2.25 | 0.108 |
| Ours | 22.04 | 218.21 | 2.60 | 3.30 | 0.272 | 3.00 | 2.47 | 0.025 |
| Dataset: StoryBench | ||||||||
| MEVG | 56.51 | 732.94 | 3.27 | 3.80 | 0.265 | 2.83 | 3.03 | 0.150 |
| Ours | 21.85 | 314.59 | 3.36 | 3.76 | 0.273 | 3.37 | 3.29 | 0.014 |
🔼 This table presents a quantitative comparison of image-to-video (I2V) generation results on two benchmark datasets: HoldOut and StoryBench. It evaluates different models using metrics derived from VideoScore, a state-of-the-art video quality assessment model. Specifically, it measures visual quality (VQ), dynamic degree (DD), text-to-video alignment (TA), and temporal consistency (TC). The number of cuts (#Cuts) per video is also reported. The table highlights MinT’s superior performance in terms of visual quality and smooth event transitions, similar to its performance in text-to-video generation.
read the caption
Table 1: I2V results on HoldOut and StoryBench. VQ, DD, TA, and TC stand for visual quality, dynamic degree, text-to-video alignment, and temporal consistency from VideoScore. #Cuts is the average number of cuts per video. Similar to T2V, MinT also achieves better visual quality and smooth event transition.
In-depth insights#
Temporal Control#
The concept of ‘Temporal Control’ in video generation is a significant advancement, enabling precise control over the timing and duration of events within a generated video. Existing methods often struggle with generating multiple events smoothly and in the correct temporal order, often neglecting some events or misplacing them. This paper addresses this limitation by introducing a novel approach that directly binds each event to a specific timeframe. This temporal grounding is crucial because it allows the model to focus on one event at a time during generation, instead of attempting to process all events simultaneously. The innovation lies in the use of a time-based positional encoding method, which facilitates time-aware interactions between event descriptions and video tokens. This mechanism enables the model to smoothly connect events by guiding cross-attention operations to focus on the relevant time windows for each event. The resulting videos exhibit improved coherence, with events seamlessly transitioning from one to the next. The flexibility to control the duration of each event is a significant improvement, offering more creative possibilities compared to existing methods that use fixed-length event clips. This precise temporal control is a key step toward producing videos that more closely resemble real-world sequences of events, enhancing realism and applicability in various domains.
Multi-Event Video#
The concept of “Multi-Event Video” generation signifies a significant advancement in video synthesis. Existing methods often struggle with generating videos containing multiple events described in a single prompt, frequently omitting events or failing to maintain the correct temporal order. The core challenge lies in effectively coordinating the timing and sequencing of multiple events within a coherent narrative. This necessitates not just generating individual events accurately but also smoothly transitioning between them. Successfully addressing this requires sophisticated temporal control mechanisms within the model, enabling it to plan the duration and sequence of events proactively. Furthermore, the ability to bind each event to a specific timeframe allows for fine-grained control over the overall video structure. Research in this area is actively exploring various methods for temporal control, including time-aware positional encodings and autoregressive generation approaches. However, autoregressive methods often suffer from accumulated errors and limited control over the overall video length. The development of robust, temporally controlled multi-event video generation remains a crucial area of research, pushing the boundaries of video synthesis towards greater realism and expressiveness.
ReRoPE Encoding#
The proposed ReRoPE (Rescaled Rotary Position Embedding) encoding method is a crucial innovation for enabling temporal control in multi-event video generation. Standard RoPE, while effective for positional encoding, struggles when applied directly to variable-length events. ReRoPE addresses this by rescaling all event durations to a uniform length before applying RoPE, thus ensuring that the attention mechanism consistently focuses on the relevant temporal context for each event. This is critical as it prevents the model from being biased towards the middle timestamps of longer events and enables smooth transitions between adjacent events. The rescaling step creates a consistent time-based positional encoding space, regardless of the actual durations of the input events. The careful design of ReRoPE, leveraging ideas from Rotary Position Embeddings and positional interpolation, directly facilitates the model’s ability to attend to video frames within the correct time range for each event, generating coherent and temporally accurate videos. By mitigating the issues encountered with vanilla RoPE in multi-event scenarios, ReRoPE demonstrably enhances the quality and temporal consistency of generated videos, which is a significant contribution to the field.
Ablation Study#
An ablation study systematically investigates the contribution of individual components within a machine learning model. For a temporally controlled multi-event video generation model, this would involve removing or modifying specific elements (e.g., the temporal cross-attention layer, the ReRoPE positional encoding, or the scene cut conditioning) to assess their impact on the model’s performance. Key insights gained from such a study would focus on the effectiveness of each component in achieving the primary goals: precise temporal control, smooth event transitions, and visual quality. For instance, removing the temporal cross-attention layer might show a significant decline in temporal control. Similarly, ablating the ReRoPE might lead to less coherent event transitions. By analyzing changes in metrics like FID, FVD, CLIP-score, and VideoScore across different ablated versions, the researchers can pinpoint the most crucial parts of the architecture and potentially refine future model designs. A well-executed ablation study is not just about identifying essential components; it also provides evidence-based justifications for design choices, showing exactly how much each component contributes to the model’s overall success. Finally, the analysis also may reveal unexpected interactions between model components or point towards promising avenues for further improvement and optimization.
Future Directions#
The research paper on temporally-controlled multi-event video generation opens exciting avenues for future work. Improving the model’s ability to handle complex scenes and intricate interactions between multiple subjects is crucial. Current limitations suggest a need for advancements in representing and reasoning about spatial relationships, possibly through methods like spatial grounding or explicit object tracking. Furthermore, enhancing the controllability over the generated video beyond temporal aspects is essential. This includes exploring techniques for manipulating factors like camera movement, lighting, and background details, all while maintaining event coherence. Expanding the dataset with a wider variety of events, scenarios, and visual styles is also critical to enhance the model’s generalizability and realism. Addressing challenges related to generating longer, more coherent videos with fewer artifacts could involve exploring new model architectures or training strategies. Finally, investigating the ethical considerations of such technology, including potential misuse for generating deepfakes, is imperative. Developing robust detection and mitigation strategies should be a high priority.
More visual insights#
More on figures

🔼 This figure compares the performance of various state-of-the-art video generation models, including open-source options (CogVideoX-5B and Mochi 1) and commercial models (Kling 1.5 and Gen-3 Alpha), against the proposed MinT model. All models are given the same four-event text prompt. The figure demonstrates that while the existing models fail to generate all four events, often omitting some entirely, MinT successfully generates a coherent video depicting all four events seamlessly. Additional comparisons are available in the supplementary material (Sec. C.6) and the project website.
read the caption
Figure 2: Multi-event video generation results from state-of-the-art video generators and MinT. We run two open-source models CogVideoX-5B [100] and Mochi 1 [82], and two commercial models Kling 1.5 [2] and Gen-3 Alpha [1] with a text prompt containing four consecutive events. All of them only generate a subset of events while ignoring the remaining ones. In contrast, MinT generates a natural video with all events smoothly connected. Please refer to Sec. C.6 and our project page for more comparisons.

🔼 Figure 3 illustrates the architecture of the MinT model, a multi-event video generator with temporal control. Panel (a) shows the input: a global caption summarizing the entire video and a sequence of temporal captions. Each temporal caption describes a specific event and its corresponding start and end times, allowing for precise temporal control. Panel (b) depicts the core of the MinT model, which includes a modified video diffusion transformer (DiT). A crucial addition is a new ’temporal cross-attention’ layer in each DiT block. Panel (c) details this layer’s function: it concatenates the text embeddings from all event captions and uses a time-aware positional encoding method (ReRoPE) to map each event to its relevant video frames, enabling temporally aware interactions between the captions and video tokens. The MinT model also incorporates scene cut conditioning to manage shot transitions in the generated video.
read the caption
Figure 3: MinT framework. (a) Our model takes in a global caption describing the overall video, and a list of temporal captions specifying the sequential events. We bind each event to a time range, enabling temporal control of the generated events. (b) To condition the video DiT on temporal captions, we introduce a new temporal cross-attention layer in each DiT block, which (c) concatenates the text embedding of all event prompts and leverages a time-aware positional encoding (Pos.Enc.) method to associate each event to its corresponding frames based on the event timestamps. MinT supports an additional scene cut conditioning, which can control the shot transition of the video.

🔼 This figure compares the attention mechanisms of vanilla Rotary Position Embedding (RoPE) and the proposed Rescaled RoPE. Both methods use positional encoding to guide the attention of video tokens to relevant text embeddings, but they differ in how they handle event durations. Vanilla RoPE uses raw timestamps, which can lead to bias towards incorrect text embeddings, especially near event boundaries. Rescaled RoPE, on the other hand, normalizes all events to a fixed length, ensuring that video tokens within an event attend primarily to the current event’s text embedding. It also ensures equal attention weights to adjacent events at event boundaries, facilitating smooth transitions between events. The visualization uses identical random vectors for video tokens and text embeddings to isolate the effects of positional encoding.
read the caption
Figure 4: Comparison of vanilla RoPE and our Rescaled RoPE. We use the same random vector for video tokens and text embeddings to only visualize the bias introduced by positional encoding. (a) Vanilla RoPE uses raw timestamps as the rotation angle, where frames within one event might be biased to the wrong text. (b) We instead rescale all events to have the same length L𝐿Litalic_L, so that video tokens always attend the most to the current event. In addition, frames at event boundaries attend to adjacent events equally.

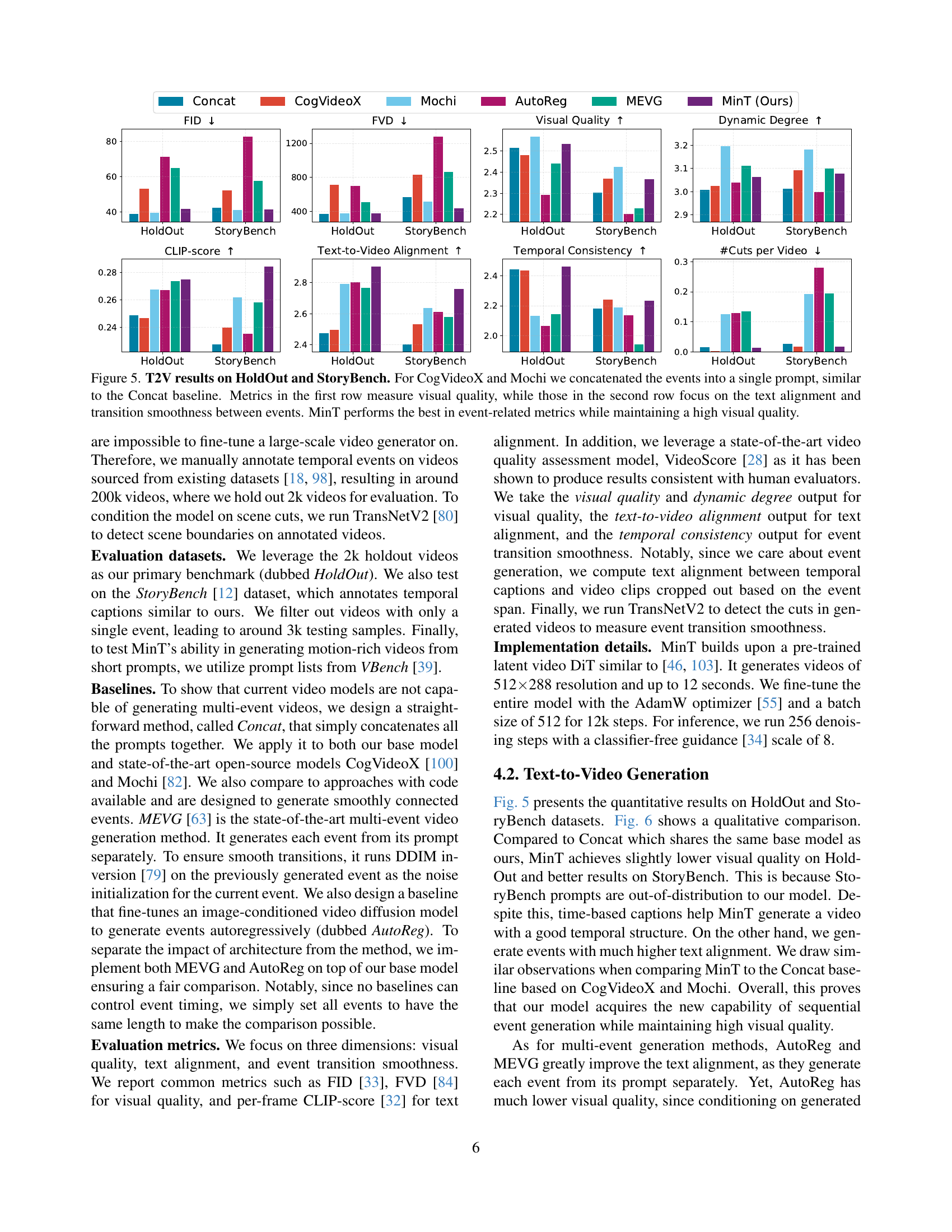
🔼 Figure 5 presents a quantitative comparison of text-to-video (T2V) generation models on two benchmark datasets, HoldOut and StoryBench. The experiment evaluates the ability of different models to generate videos from multiple sequential events described within a single prompt. For the CogVideoX and Mochi models, all events were combined into a single input, mimicking the ‘Concat’ baseline. The figure shows that MinT achieves superior results across various metrics measuring both the visual quality of the generated video (FID, FVD, CLIP score) and the coherence of the generated content compared to the text prompts (text-to-video alignment, temporal consistency, and the number of cuts in the video). In particular, MinT excels in metrics assessing event-related aspects while maintaining high visual quality.
read the caption
Figure 5: T2V results on HoldOut and StoryBench. For CogVideoX and Mochi we concatenated the events into a single prompt, similar to the Concat baseline. Metrics in the first row measure visual quality, while those in the second row focus on the text alignment and transition smoothness between events. MinT performs the best in event-related metrics while maintaining a high visual quality.

🔼 Figure 6 presents a qualitative comparison of text-to-video (T2V) generation methods applied to a multi-event scenario. The results demonstrate that simply concatenating all events into a single prompt (Concat) leads to only the first event being generated. Autoregressive generation (AutoReg), while producing a smoother transition between the first two events, fails to fully generate the third event and suffers from video stagnation. MEVG struggles to maintain consistent subject identity and produces abrupt transitions between events. In contrast, MinT successfully generates all four events in a coherent video with smooth transitions and consistent visual content.
read the caption
Figure 6: Qualitative results of T2V. Concatenating all events into a single prompt (Concat) can only generate the first event. Autoregressive generation (AutoReg) suffers from video stagnation and cannot generate the third event. MEVG struggles to preserve the person’s identity and produces abrupt event transitions. MinT is the only method that generates all events with smooth transitions and consistent content. See Sec. C.1 for more qualitative results and our project page for video results.

🔼 This figure displays the results of a human evaluation comparing the performance of MinT against several text-to-video (T2V) baselines across multiple metrics. The evaluation focused on four key aspects: visual quality, text-to-video alignment, temporal consistency, and the number of cuts in the generated video. The results show that MinT achieves comparable or superior visual quality to the baselines and significantly surpasses them in terms of text alignment, temporal consistency, and the reduction of abrupt transitions (indicated by fewer cuts).
read the caption
Figure 7: Human preference evaluation against T2V baselines. MinT is better or competitive in visual quality, and significantly outperforms baselines in the other three event-related metrics.

🔼 This figure displays a qualitative comparison of video generation results using different prompts. The top row shows videos generated from a short prompt: ‘A cat drinking water.’ The middle row presents videos generated from the same short prompt but enhanced with a global caption and a sequence of detailed temporal captions about the cat’s actions. The bottom row demonstrates results from using only the enhanced prompts without the original short prompt. The comparison highlights the impact of detailed prompt engineering on the quality and specificity of the generated videos, showcasing more detailed and accurate actions in the enhanced prompt scenarios.
read the caption
Figure 8: Qualitative comparison of prompt enhancement results. The original short prompt is “a cat drinking water”.

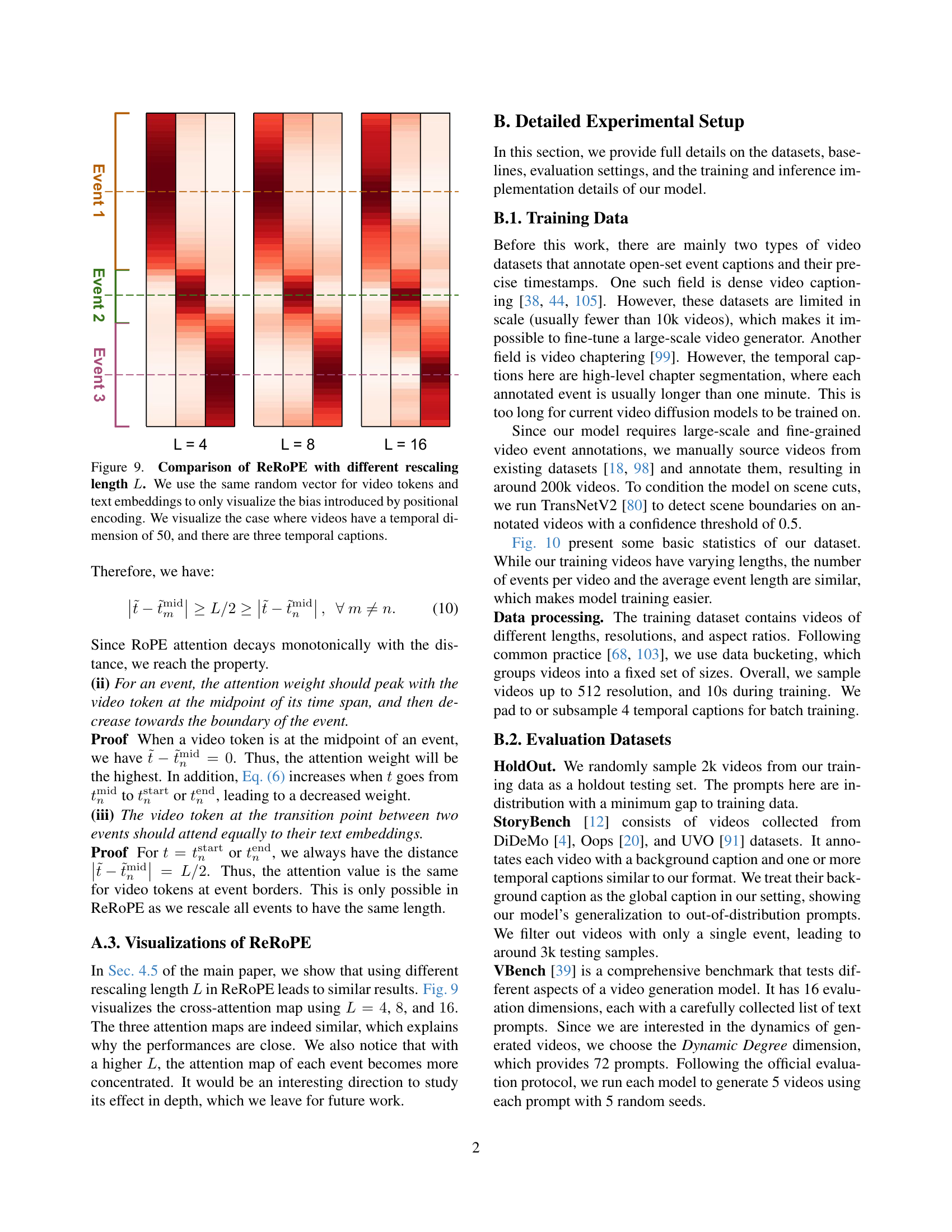
🔼 This figure visualizes how the attention weights change when using different rescaling lengths (L) in the Rescaled Rotary Position Embedding (ReRoPE) method. The experiment uses the same random vectors for video tokens and text embeddings to isolate and highlight the effect of positional encoding. It demonstrates the attention patterns when a video has a temporal dimension of 50 frames and contains three temporal captions. The visualization shows how ReRoPE guides the attention mechanism to focus on the relevant event’s text embedding at each time step while maintaining smooth transitions between adjacent events.
read the caption
Figure 9: Comparison of ReRoPE with different rescaling length L𝐿Litalic_L. We use the same random vector for video tokens and text embeddings to only visualize the bias introduced by positional encoding. We visualize the case where videos have a temporal dimension of 50, and there are three temporal captions.

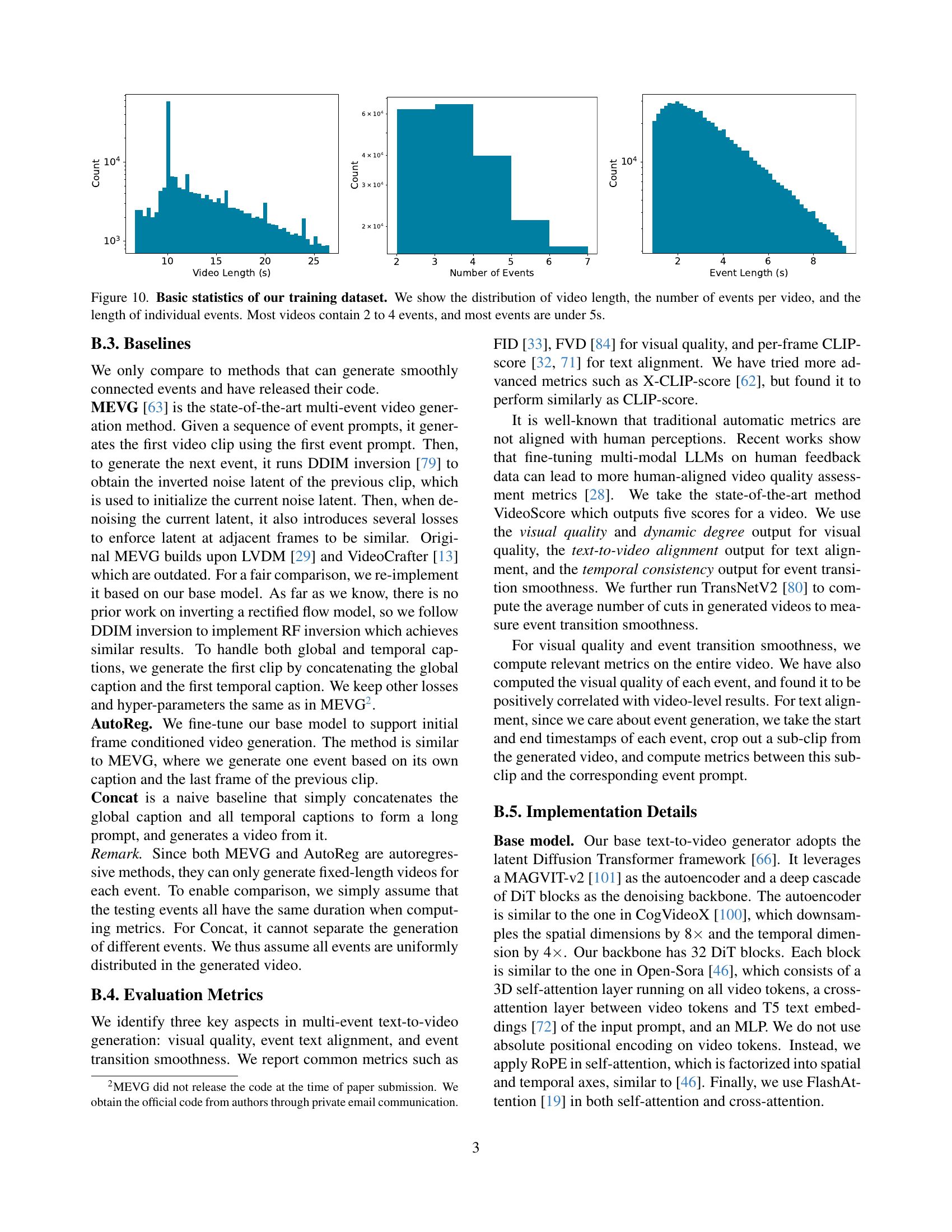
🔼 Figure 10 presents a statistical overview of the training dataset used for the Mind the Time (MinT) model. Three histograms display the distributions of: 1) video length (in seconds), showing the duration of each video; 2) number of events per video, indicating how many distinct events occur in each video; and 3) event length (in seconds), showing the duration of individual events. The histograms reveal that the majority of videos in the training dataset have lengths between 2 to 4 events, with most individual events lasting under 5 seconds.
read the caption
Figure 10: Basic statistics of our training dataset. We show the distribution of video length, the number of events per video, and the length of individual events. Most videos contain 2 to 4 events, and most events are under 5s.

🔼 Figure 11 presents a qualitative comparison of text-to-video (T2V) generation results from four different methods: MinT (the authors’ proposed model), MEVG (a state-of-the-art multi-event video generator), AutoReg (an autoregressive approach), and Concat (a baseline that concatenates all event prompts). The figure shows that MinT successfully generates all four events in a natural, temporally consistent manner. In contrast, the other methods struggle with event generation, resulting in missing events, incorrect temporal order, or visual inconsistencies.
read the caption
Figure 11: Qualitative comparisons of T2V.

🔼 Figure 12 presents additional examples of text-to-video (T2V) generation results produced by the MinT model. The figure showcases the model’s ability to generate coherent videos depicting multiple events within a single continuous scene, with smooth transitions between each event. The prompts used for each video sequence are displayed, highlighting the diversity of scenarios and actions that MinT is capable of handling. Due to space limitations in the paper, the caption directs readers to the project webpage for access to the full collection of results.
read the caption
Figure 12: More T2V results from MinT. Please see our project page for more results.

🔼 Figure 13 showcases the effectiveness of the MinT model’s prompt enhancement technique using the VBench dataset. The figure demonstrates how short, simple prompts are significantly improved by expanding them into detailed global and temporal captions. This process, aided by an LLM, allows MinT to generate videos containing multiple events, each with specific timing information. The enhanced prompts produce much more dynamic and interesting videos compared to results from just the original simple prompts. The figure highlights the model’s capability to control the temporal aspects of video generation, which is made possible through the use of temporal captions.
read the caption
Figure 13: Prompt enhancement results on VBench. We can generate more interesting videos from a simple prompt. This highlights the flexible dynamics control ability brought by the temporal captions. Please see our project page for video results.

🔼 This figure demonstrates the impact of scene cut conditioning on video generation. The top row in each example shows videos generated with explicit scene cut timestamps provided to the model. This results in the model creating shot transitions at the specified times while maintaining consistent subjects and backgrounds. The bottom row displays videos generated without scene cut input, effectively disabling the shot transition mechanism. In the second example, this absence of scene cut conditioning leads to a smooth zoom effect instead. The overall experiment highlights the model’s ability to control both the presence and style of shot transitions.
read the caption
Figure 14: Generated videos with and without scene cut input. In each example, the first row is generated by inputting the scene cut at the illustrated timestamps, while the second row is by zeroing out the scene cut input. When using the scene cut, the model is able to generate a shot transition at desired timestamps, while keeping the subject consistent. In the second example, the model generates smooth zoom-in and zoom-out effects when zeroing out scene cuts. Please see our project page for more results.

🔼 This figure demonstrates MinT’s ability to precisely control the timing of events within a generated video. Multiple examples are shown, each with the same events but with the start and end times of each event systematically shifted by a set number of seconds. The results highlight that MinT can maintain consistent subject appearance and background despite changes to event durations, showcasing its fine-grained temporal control.
read the caption
Figure 15: Generated videos with different event time spans. In each example, we offset the start and end timestamps of all events by a specific number of seconds. Results show that MinT enables fine-grained event timing control while keeping the subjects’ appearances to be roughly the same. This capability is very useful for controllable video generation. Please see our project page for more results.

🔼 Figure 16 showcases the ability of the MinT model to generate videos depicting concepts and scenes not explicitly present in its training data. Despite being fine-tuned on primarily human-centric events, MinT retains the capacity of its base model to generate novel content and combinations, including scenarios involving warriors, astronauts, spacecrafts, and even a cat performing yoga. This demonstrates that MinT effectively maintains the capabilities of the underlying pre-trained model while enhancing its capacity to produce temporally-controlled multi-event videos. For more examples and videos, please refer to the project page.
read the caption
Figure 16: Generated videos with out-of-distribution prompts. After fine-tuning, MinT still possesses the base model’s ability to generate novel concepts. Please see our project page for more results.

🔼 This figure compares the performance of MinT against state-of-the-art video generation models (CogVideoX, Mochi, Kling 1.5, and Gen-3 Alpha) on the task of generating videos with multiple events. It demonstrates MinT’s superior ability to generate videos that accurately depict all specified events in the correct order, smoothly transitioning between them, with consistent visual quality, while the other models often fail to generate all events or struggle with smooth transitions and consistent subjects.
read the caption
Figure 17: More comparisons with SOTA video generators. We run SOTA open-source models CogVideoX [100] and Mochi [82], and commercial models Kling 1.5 [2] and Gen-3 Alpha [1] using their online APIs. Please see our project page for video results.

🔼 Figure 18 presents a qualitative comparison of multi-event video generation results from state-of-the-art models, including open-source options like CogVideoX and Mochi, and commercial models such as Kling 1.5 and Gen-3 Alpha. Each row shows the results for a different set of event prompts. The figure demonstrates that existing methods struggle to generate videos that accurately capture all events in the specified order and with smooth transitions. The full videos are available on the project’s webpage, as noted in the caption.
read the caption
Figure 18: More comparisons with SOTA video generators. We run SOTA open-source models CogVideoX [100] and Mochi [82], and commercial models Kling 1.5 [2] and Gen-3 Alpha [1] using their online APIs. Please see our project page for video results.
More on tables
| Method | Subject (Consist. ↑) | Background (Consist. ↑) | Aesthetic (Quality ↑) | Imaging (Quality ↑) | Motion (Smooth ↑) | Dynamic (Degree ↑) |
|---|---|---|---|---|---|---|
| Short | 0.857 | 0.939 | 0.498 | 0.583 | 0.995 | 0.481 |
| Global | 0.890 | 0.950 | 0.541 | 0.613 | 0.995 | 0.517 |
| Ours | 0.900 | 0.950 | 0.544 | 0.609 | 0.988 | 0.711 |
🔼 Table 2 presents a quantitative evaluation of the model’s performance on the VBench dataset, specifically focusing on videos generated from enhanced prompts. The metrics assess both video quality (using standard measures like subject and background consistency, aesthetic quality, and image quality) and the dynamism of the generated videos (motion smoothness and dynamic degree). The results highlight MinT’s ability to produce videos with a significantly higher dynamic degree than the baselines, while maintaining competitive levels of visual quality and motion smoothness.
read the caption
Table 2: Prompt enhancement results on VBench. Consist. means consistency. The first four metrics measure video quality, while we focus on the motion of generated videos. MinT generates videos with significantly higher dynamics degree and competitive visual quality and motion smoothness.
| Method | VQ ↑ | DD ↑ | CLIP-T ↑ | TA ↑ | TC ↑ | #Cuts ↓ |
|---|---|---|---|---|---|---|
| Full Model | 2.56 | 3.32 | 0.270 | 2.92 | 2.44 | 0.026 |
| Concat time | 2.53 | 3.31 | 0.249 | 2.42 | 2.33 | 0.075 |
| Hard attn mask | 2.45 | 3.34 | 0.260 | 2.68 | 2.30 | 0.069 |
| Vanilla RoPE | 2.54 | 3.32 | 0.262 | 2.79 | 2.42 | 0.030 |
| ReRoPE (L=4) | 2.54 | 3.33 | 0.264 | 2.88 | 2.43 | 0.029 |
| ReRoPE (L=16) | 2.55 | 3.32 | 0.265 | 2.90 | 2.44 | 0.025 |
| No cut condition | 2.54 | 3.33 | 0.268 | 2.89 | 2.34 | 0.084 |
🔼 This table presents an ablation study evaluating the impact of different components in the MinT model on the HoldOut dataset. Specifically, it analyzes the effects of various methods for incorporating event time spans, different values for the rescaling length parameter (L) in the ReRoPE positional encoding, and the inclusion or exclusion of scene cut conditioning. The results are assessed using several metrics derived from the VideoScore model, including visual quality (VQ), dynamic degree (DD), text-to-video alignment (TA), and temporal consistency (TC). The number of scene cuts (#Cuts) per video is also reported to evaluate transition smoothness.
read the caption
Table 3: Ablation results on HoldOut. We study different conditioning mechanisms for event time span, the rescale length L𝐿Litalic_L in ReRoPE, and the use of scene cut conditioning. VQ, DD, TA, and TC stand for visual quality, dynamic degree, text-to-video alignment, and temporal consistency from VideoScore. #Cuts is the average number of scene cuts per video.
| Method | FID ↓ | FVD ↓ | CLIP-score ↑ |
|---|---|---|---|
| Task: T2V (a.k.a. story generation in [12]) | |||
| Phenaki | 273.41 | 998.19 | 0.210 |
| Ours | 40.87 | 484.44 | 0.284 |
| Task: I2V (a.k.a. story continuation in [12]) | |||
| Phenaki | 240.21 | 674.5 | 0.219 |
| Ours | 21.85 | 314.59 | 0.273 |
🔼 This table presents a quantitative comparison of the proposed MinT model against the Phenaki model on the StoryBench benchmark. The comparison uses the zero-shot variant of Phenaki (Phenaki-Gen-ZS) because MinT was not fine-tuned on StoryBench. The results show MinT significantly outperforms Phenaki across all metrics (FID, FVD, CLIP-score) in both text-to-video (T2V) and image-to-video (I2V) generation tasks.
read the caption
Table 4: Comparison with Phenaki on StoryBench. We compare with the zero-shot variant Phenaki-Gen-ZS in their paper [12] since our model is not fine-tuned on StoryBench. We clearly outperform Phenaki across all metrics in both tasks.
Full paper#