↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multimodal large language models (MLLMs) are rapidly advancing, but high-performing models are often closed-source, limiting transparency and hindering research. This paper addresses this issue by improving an existing open-source MLLM called InternVL. Previous versions of InternVL had demonstrated progress, but they still fell short of state-of-the-art commercial models in terms of performance and efficiency. The researchers sought to improve the model to achieve competitive performance, and offer a transparent, accessible alternative.
The authors introduce InternVL 2.5, which builds upon the foundation of InternVL 2.0. Their enhancements include improved training strategies, higher-quality data, and systematic exploration of scaling techniques for both model parameters and inference times. The improved model demonstrates significantly enhanced performance across a broad range of benchmarks. This includes improvements in multidisciplinary reasoning, document understanding, image/video understanding, and more. The work highlights the benefits of improving both training data and inference strategies when building powerful MLLMs, and contributes the InternVL 2.5 model to the open-source community.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal AI because it presents InternVL 2.5, a significant advancement in open-source multimodal large language models. Its systematic exploration of model scaling and performance, along with its open-source nature, provides valuable insights and resources that can accelerate progress in the field and fosters collaboration. This work bridges the gap between closed-source and open-source models, making powerful tools accessible for broader research and innovation.
Visual Insights#

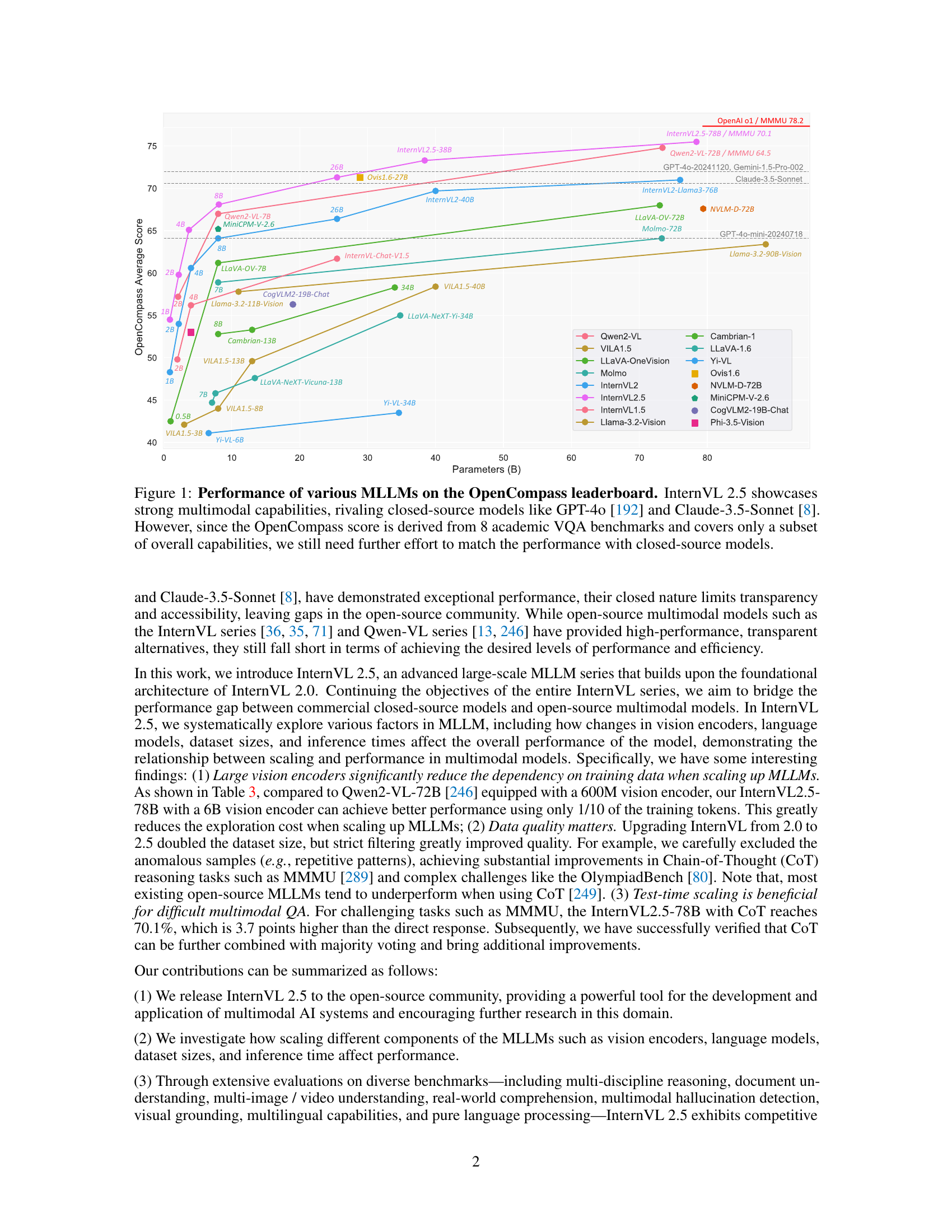
🔼 This figure presents a comparison of the performance of various multimodal large language models (MLLMs) on the OpenCompass leaderboard. InternVL 2.5 is highlighted, demonstrating competitive performance compared to leading closed-source models such as GPT-40 and Claude-3.5-Sonnet. The x-axis represents the number of parameters (in billions) for each MLLM, and the y-axis shows the average score on the OpenCompass benchmark. The figure illustrates that InternVL 2.5 achieves a high score, rivaling closed-source models despite being open-source, though further work is needed to improve performance across all capabilities. It emphasizes that OpenCompass focuses on a limited set of visual question answering (VQA) benchmarks, not the full scope of an MLLM’s abilities.
read the caption
Figure 1: Performance of various MLLMs on the OpenCompass leaderboard. InternVL 2.5 showcases strong multimodal capabilities, rivaling closed-source models like GPT-4o [192] and Claude-3.5-Sonnet [8]. However, since the OpenCompass score is derived from 8 academic VQA benchmarks and covers only a subset of overall capabilities, we still need further effort to match the performance with closed-source models.
| Model Name | Train Res. | Width | Depth | MLP | #Heads | QK-Norm | Norm Type | Loss Type | #Param |
|---|---|---|---|---|---|---|---|---|---|
| InternViT-6B-224px | fixed 224 | 3200 | 48 | 12800 | 25 | ✓ | RMS | CLIP | 5.9B |
| InternViT-6B-448px-V1.0 | fixed 448 | 3200 | 48 | 12800 | 25 | ✓ | RMS | NTP | 5.9B |
| InternViT-6B-448px-V1.2 | fixed 448 | 3200 | 45 | 12800 | 25 | ✓ | RMS | NTP | 5.5B |
| InternViT-6B-448px-V1.5 | dynamic 448 | 3200 | 45 | 12800 | 25 | ✓ | RMS | NTP | 5.5B |
| InternViT-6B-448px-V2.5 | dynamic 448 | 3200 | 45 | 12800 | 25 | ✓ | RMS | NTP | 5.5B |
| InternViT-300M-448px-Distill | fixed 448 | 1024 | 24 | 4096 | 16 | ✗ | LN | Cosine | 0.3B |
| InternViT-300M-448px | dynamic 448 | 1024 | 24 | 4096 | 16 | ✗ | LN | NTP | 0.3B |
| InternViT-300M-448px-V2.5 | dynamic 448 | 1024 | 24 | 4096 | 16 | ✗ | LN | NTP | 0.3B |
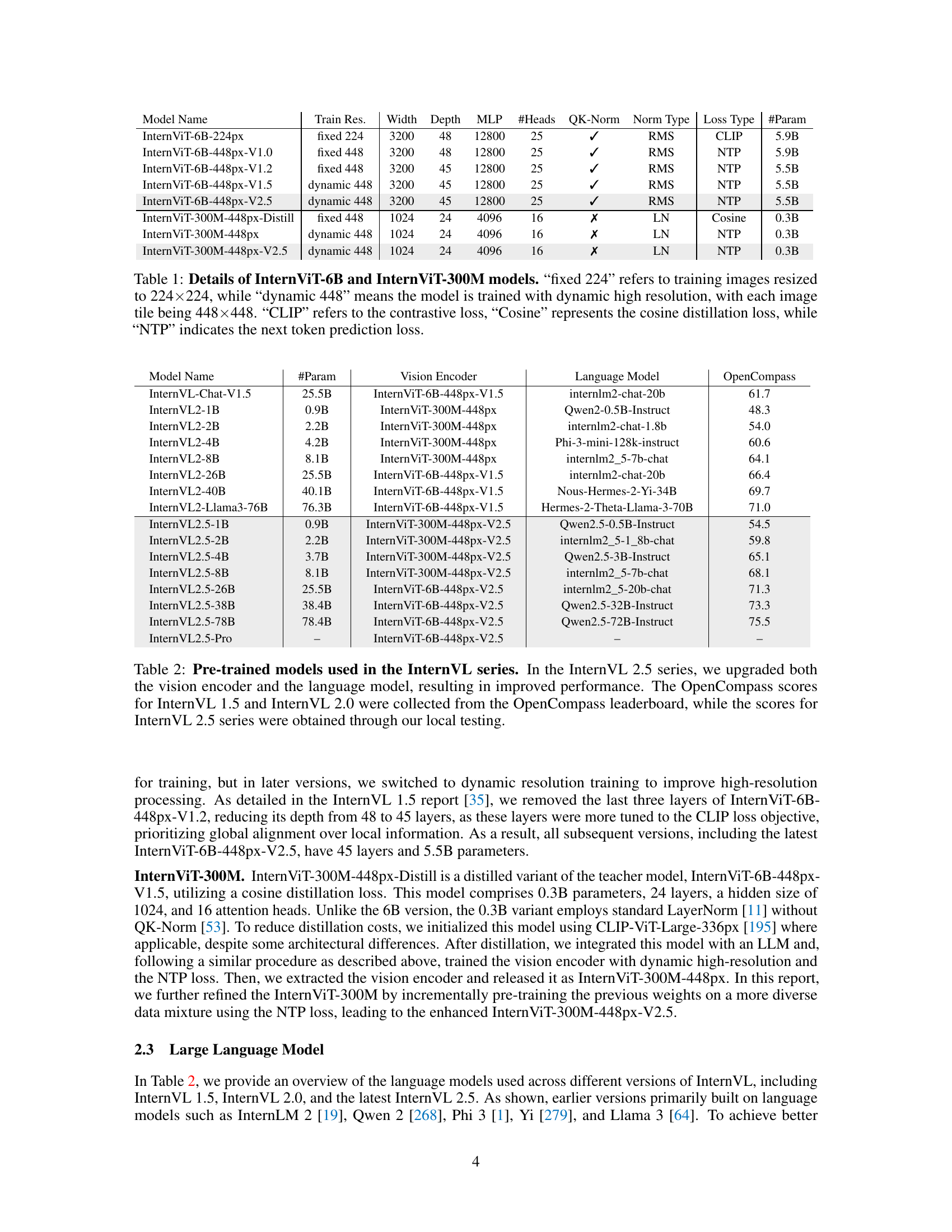
🔼 Table 1 presents a detailed comparison of the InternViT-6B and InternViT-300M models, highlighting key architectural differences and training configurations. The table shows the training resolution (fixed 224x224 or dynamic 448x448), model width, depth, MLP size, number of heads, whether or not they use QK-Norm, the type of normalization used (RMSNorm or LayerNorm), the loss function used (CLIP, Cosine distillation, or Next Token Prediction), and the number of parameters. This information is essential for understanding the design choices and trade-offs involved in training these models and comparing their performance.
read the caption
Table 1: Details of InternViT-6B and InternViT-300M models. “fixed 224” refers to training images resized to 224×\times×224, while “dynamic 448” means the model is trained with dynamic high resolution, with each image tile being 448×\times×448. “CLIP” refers to the contrastive loss, “Cosine” represents the cosine distillation loss, while “NTP” indicates the next token prediction loss.
In-depth insights#
InternVL 2.5 Advances#
InternVL 2.5 represents a substantial advancement in open-source multimodal large language models (MLLMs). Key improvements focus on scaling strategies, encompassing model size, data quality, and test-time configurations. The researchers systematically investigated the impact of each element, demonstrating performance gains across multiple benchmarks. InternVL 2.5 showcases strong multilingual capabilities and surpasses 70% on the challenging MMMU benchmark, rivaling commercial models like GPT-4 and Claude. Significant progress is also observed in visual grounding and video understanding tasks. This release highlights the ongoing effort to bridge the performance gap between open-source and proprietary MLLMs, fostering progress in the field.
Multimodal Scaling Laws#
Multimodal scaling laws explore how improvements in model performance relate to increases in model size, training data, and computational resources. Understanding these laws is crucial for efficiently developing powerful multimodal large language models (MLLMs). Research in this area would investigate the relationships between the scale of different model components (e.g., vision encoder, language model), dataset size and diversity, and the resulting performance across various multimodal benchmarks. A key aspect would be identifying diminishing returns or optimal scaling strategies—are there points where adding more data or increasing model size provides minimal benefit? Another important consideration is the generalizability of observed scaling laws; do they hold consistently across different datasets and tasks, or are there task-specific scaling dynamics? Research into multimodal scaling laws is critical for guiding the efficient allocation of resources in MLLM development, thereby maximizing performance gains while minimizing computational costs.
High-Res Training#
High-resolution training in large vision-language models (LVLMs) presents a unique set of challenges and opportunities. The core idea is to train the model on images at or near their native resolution, rather than downsampling them, which can lead to a loss of fine-grained visual detail. This approach necessitates handling significantly larger input sizes, demanding substantial computational resources. However, the benefits can be substantial. Training at higher resolutions allows the model to learn more precise visual representations, improving its ability to understand subtle visual cues and relationships. This can translate into superior performance on downstream tasks that require a high level of visual understanding, such as object detection, semantic segmentation, and visual question answering. The trade-off is that high-resolution training requires substantial computational resources and may increase the risk of overfitting. Strategies like efficient data processing techniques, and possibly specialized model architectures, are critical for mitigating these issues to enable practical application of high-resolution training in LVLMs.
Data Filtering Pipeline#
The heading ‘Data Filtering Pipeline’ suggests a crucial preprocessing step in handling large datasets for training multimodal large language models (MLLMs). The authors likely detail strategies to improve data quality by removing noisy or anomalous samples that might hinder model performance. This involves the identification and subsequent removal of repetitive outputs, a common issue in open-source datasets that can lead to undesired model behavior, such as generating repetitive responses during inference. Furthermore, the pipeline likely emphasizes quality control measures, potentially using techniques like LLM-based quality scoring or heuristic rule-based filtering to identify and filter low-quality samples. The effectiveness of the pipeline in improving model robustness and accuracy is likely demonstrated and discussed in subsequent sections of the paper, highlighting its significance in achieving state-of-the-art results. In short, the data filtering pipeline is a critical component for enhancing the training process of MLLMs by removing unwanted noise and improving the overall quality of the training data, resulting in better model performance.
Future MLLM Research#
Future research in Multimodal Large Language Models (MLLMs) should prioritize improving the efficiency and scalability of training and inference. This includes exploring novel architectures and training strategies that reduce computational costs while maintaining or improving performance. Addressing hallucinations and biases is crucial, requiring the development of more robust evaluation metrics and techniques for detecting and mitigating these issues. Data quality and diversity remain key; future work must focus on building larger, higher-quality, and more diverse datasets, particularly for under-represented modalities and languages. Further research needs to tackle the complexities of multi-modal reasoning and long-form content generation, exploring Chain-of-Thought prompting and advanced reasoning strategies. Finally, exploring the ethical implications of MLLMs and developing responsible development practices is paramount to ensure their beneficial use across various applications.
More visual insights#
More on figures

🔼 InternVL 2.5 uses a ‘ViT-MLP-LLM’ architecture. InternViT (a Vision Transformer) processes images, reducing the initial 1024 visual tokens to 256 using pixel unshuffle. These tokens are then projected via an MLP (Multilayer Perceptron) into an LLM (Large Language Model) for multimodal understanding. Unlike earlier versions, InternVL 2.5 supports multi-image and video inputs.
read the caption
Figure 2: Overall architecture. InternVL 2.5 retains the same model architecture as InternVL 1.5 [35] and InternVL 2.0, i.e. the widely-used “ViT-MLP-LLM” paradigm, which combines a pre-trained InternViT-300M or InternViT-6B with LLMs [19, 229] of various sizes via an MLP projector. Consistent with previous versions, we apply a pixel unshuffle operation to reduce the 1024 visual tokens produced by each 448×\times×448 image tile to 256 tokens. Moreover, compared to InternVL 1.5, InternVL 2.0 and 2.5 introduced additional data types, incorporating multi-image and video data alongside the existing single-image and text-only data.

🔼 Figure 3 illustrates how the InternVL model handles different data types: (a) Single-image inputs are divided into tiles, with the maximum number of tiles used to ensure the highest resolution. (b) Multi-image inputs distribute tiles proportionally among the images in a sample. (c) Video processing simplifies to resizing individual frames to 448x448 pixels.
read the caption
Figure 3: Illustration of the data formats for various data types. (a) For single-image datasets, the maximum number of tiles nmaxsubscript𝑛maxn_{\text{max}}italic_n start_POSTSUBSCRIPT max end_POSTSUBSCRIPT is allocated to a single image, ensuring maximum resolution for the input. (b) For multi-image datasets, the total number of tiles nmaxsubscript𝑛maxn_{\text{max}}italic_n start_POSTSUBSCRIPT max end_POSTSUBSCRIPT is distributed proportionally across all images within the sample. (c) For video datasets, the method simplifies the approach by setting nmax=1subscript𝑛max1n_{\text{max}}=1italic_n start_POSTSUBSCRIPT max end_POSTSUBSCRIPT = 1, resizing individual frames to a fixed resolution of 448×\times×448.

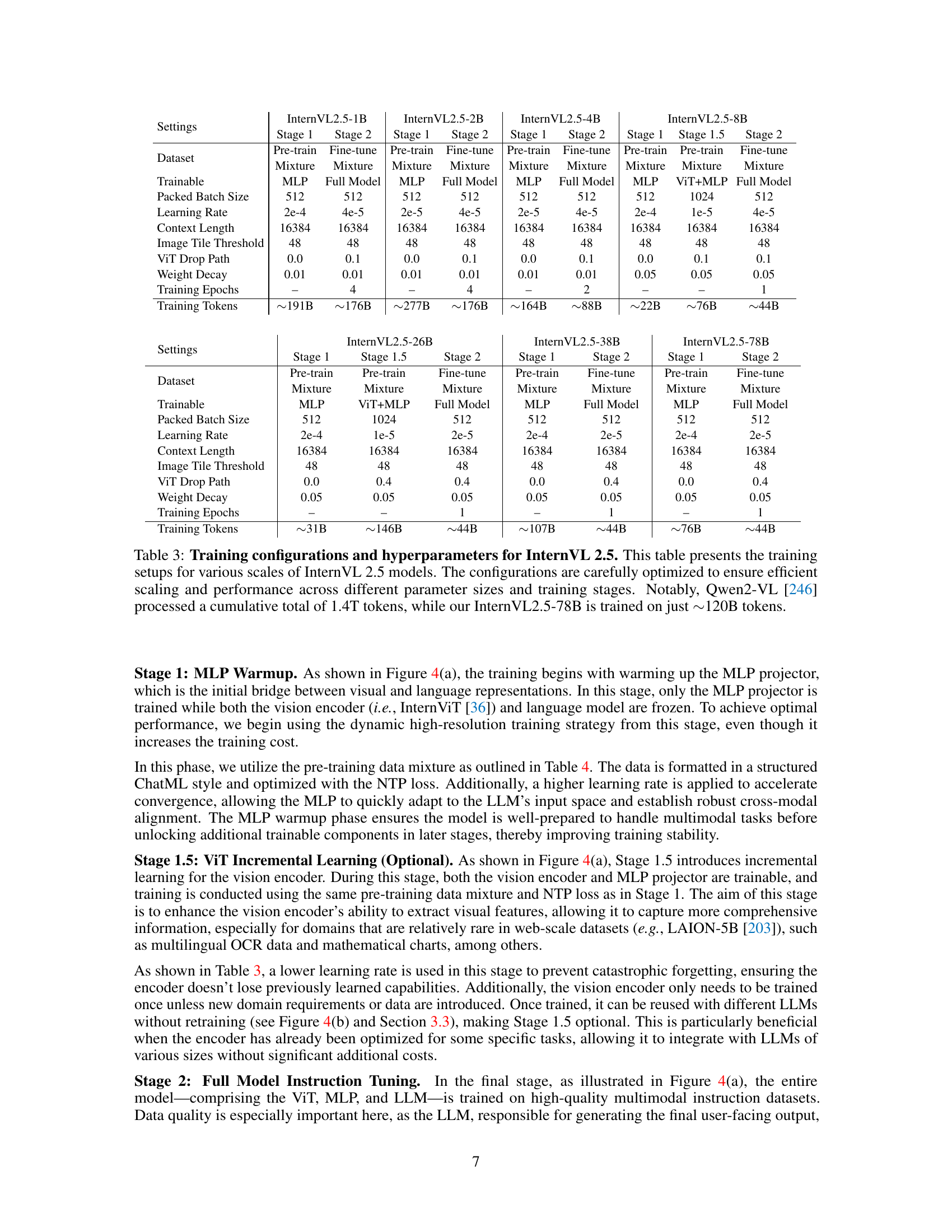
🔼 This figure illustrates the training process of the InternVL 2.5 model, highlighting its two key strategies: single model training and progressive scaling. The single model training pipeline involves three stages: a warmup stage focusing on the MLP projector, an optional incremental learning stage for the vision transformer (ViT), and a final instruction tuning stage for the full model. This multi-stage approach improves vision-language alignment, enhances training stability, and prepares the model for integration with larger language models. The progressive scaling strategy leverages the pre-trained ViT module from earlier stages, allowing for easy integration with larger language models, leading to scalable model alignment and reduced computational costs. This figure helps explain the efficient and scalable training methods used for InternVL 2.5.
read the caption
Figure 4: Illustration of the training pipeline and progressive scaling strategy. (a) Single model training pipeline: The training process is divided into three stages—Stage 1 (MLP warmup), optional Stage 1.5 (ViT incremental learning), and Stage 2 (full model instruction tuning). The multi-stage design progressively enhances vision-language alignment, stabilizes training, and prepares modules for integration with larger LLMs. (b) Progressive scaling strategy: The ViT module trained with a smaller LLM in earlier stages can be easily integrated with larger LLMs, enabling scalable model alignment with affordable resource overhead.

🔼 Figure 5 details the configuration of datasets used to train InternVL 2.0 and 2.5. Data augmentation techniques (like JPEG compression) are selectively applied; they are used for image data but not video or text data. The maximum tile number (nmax) parameter determines the resolution of the input; higher nmax values are used for higher-resolution inputs, such as those found in multi-image datasets. Conversely, lower nmax values are used for video data, which often has many frames to process. The repeat factor (r) controls the sampling frequency of each dataset, balancing dataset representation and ensuring robust and balanced model training.
read the caption
Figure 5: Dataset configuration. In InternVL 2.0 and 2.5, data augmentation is applied selectively, enabled for image datasets and disabled for videos and text. The maximum tile number (nmaxsubscript𝑛n_{\max}italic_n start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT) controls the resolution of inputs, with higher values for multi-image datasets and lower values for videos. The repeat factor (r𝑟ritalic_r) balances dataset sampling by adjusting the frequency of each dataset, ensuring robust and balanced training.

🔼 Figure 6 showcases examples of problematic data points (abnormal samples) frequently found within open-source datasets used to train large language models. These issues affect various data types including single images, multiple images, videos, and text-only datasets. A major problem highlighted is the prevalence of repetitive outputs within the data. The authors argue that these repetitive patterns are highly detrimental to the performance of models, particularly during test-time scaling, often causing them to produce repetitive or cyclical responses, especially in long-form outputs and when using Chain-of-Thought (CoT) reasoning.
read the caption
Figure 6: Visualization of abnormal samples in open-source datasets. Abnormal samples are prevalent across various data types, including single-image, multi-image, video, and pure text datasets, with “repetitive outputs” being a prominent issue. We identify this as one of the most detrimental problems for test-time scaling, often leading models into loops in long-form outputs and CoT reasoning tasks.

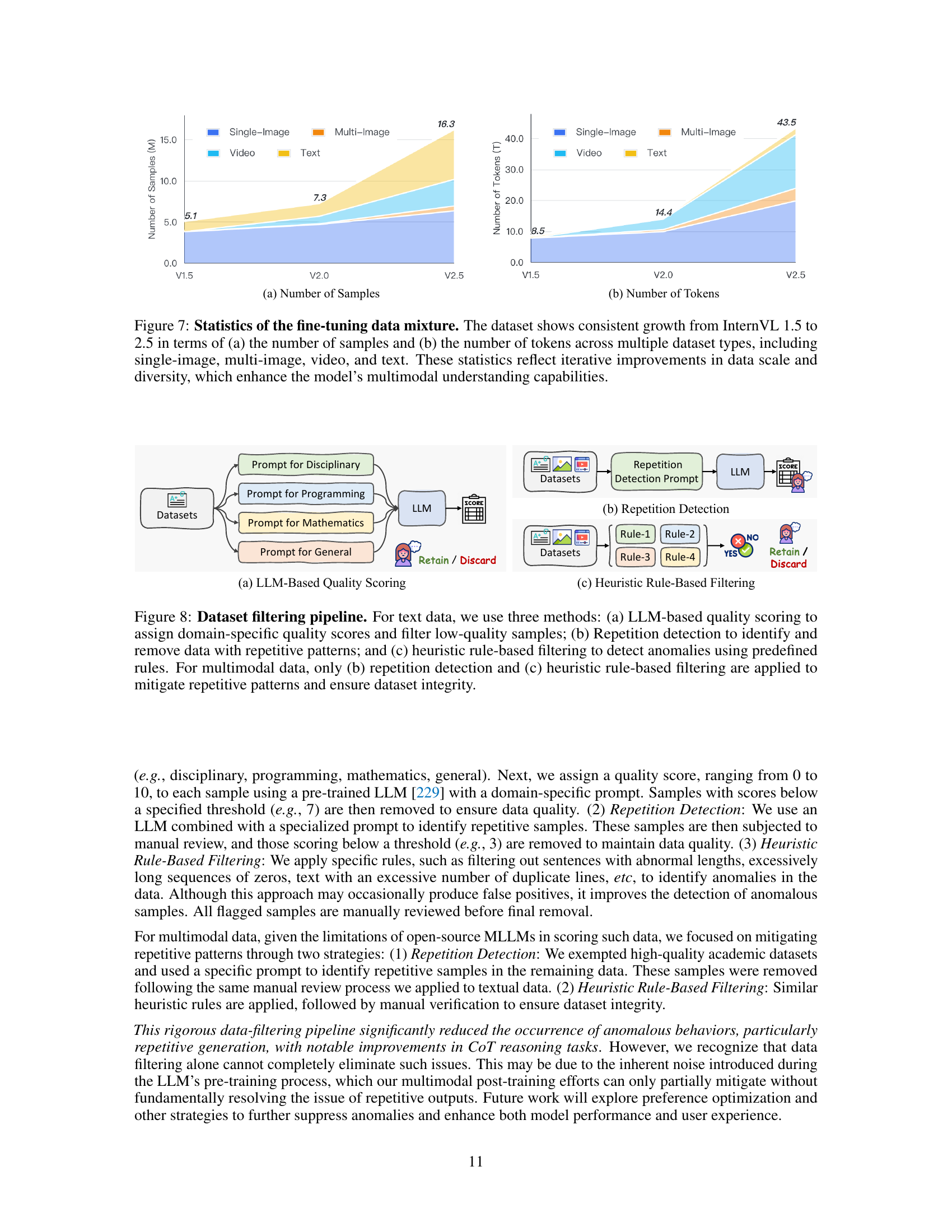
🔼 This figure shows the growth of the dataset used for fine-tuning the InternVL model from version 1.5 to version 2.5. It displays the increase in both the number of samples and the number of tokens across various data types: single images, multiple images, videos, and text. The growth indicates an increase in the scale and diversity of the training data, which ultimately enhances the model’s ability to understand and process multiple data modalities.
read the caption
Figure 7: Statistics of the fine-tuning data mixture. The dataset shows consistent growth from InternVL 1.5 to 2.5 in terms of (a) the number of samples and (b) the number of tokens across multiple dataset types, including single-image, multi-image, video, and text. These statistics reflect iterative improvements in data scale and diversity, which enhance the model’s multimodal understanding capabilities.

🔼 This figure illustrates the data filtering pipeline used to improve the quality of the training data. For text data, a three-stage process is used: LLM-based quality scoring to filter out low-quality samples based on domain-specific scores; repetition detection to remove samples with repetitive patterns; and heuristic rule-based filtering to identify and remove anomalous samples using predefined rules. For multimodal data, the LLM-based quality scoring stage is skipped, and only repetition detection and heuristic rule-based filtering are applied to ensure data integrity and remove repetitive patterns.
read the caption
Figure 8: Dataset filtering pipeline. For text data, we use three methods: (a) LLM-based quality scoring to assign domain-specific quality scores and filter low-quality samples; (b) Repetition detection to identify and remove data with repetitive patterns; and (c) heuristic rule-based filtering to detect anomalies using predefined rules. For multimodal data, only (b) repetition detection and (c) heuristic rule-based filtering are applied to mitigate repetitive patterns and ensure dataset integrity.

🔼 This figure showcases the Chain of Thought (CoT) prompts utilized in the InternVL 2.5 model testing. The prompts are designed to guide the model’s reasoning process step-by-step, enhancing its ability to solve complex problems. The figure likely shows examples of both multiple-choice and open-ended question prompts, illustrating how the CoT approach structures the input to elicit a more detailed and logical reasoning process from the model, ultimately improving its performance, particularly on the MMMU benchmark.
read the caption
Figure 9: CoT prompts used in our model testing. By leveraging these prompts for CoT reasoning, we can scale up testing time, significantly enhancing the performance of InternVL 2.5 models on MMMU [289].

🔼 This figure shows the performance of various models on the LongVideoBench benchmark as the number of input video frames increases. It demonstrates how the accuracy of different models, including InternVL 2.5 models and several other state-of-the-art models, changes with varying frame counts (16, 32, 48, 64, and 128 frames). This visualization helps to understand the impact of temporal information on video understanding tasks, particularly for assessing the scalability of models when processing long videos.
read the caption
Figure 10: Performance on LongVideoBench with varying input video frames.
More on tables
🔼 This table presents the pre-trained models used across different InternVL versions (1.5, 2.0, and 2.5). InternVL 2.5 models show improvements in both vision encoders and language models compared to previous versions. The table lists each model’s name, number of parameters (#Param), vision encoder used, language model employed, and the corresponding OpenCompass average score. Scores for InternVL 1.5 and InternVL 2.0 are from the OpenCompass leaderboard, while InternVL 2.5 scores are from local testing.
read the caption
Table 2: Pre-trained models used in the InternVL series. In the InternVL 2.5 series, we upgraded both the vision encoder and the language model, resulting in improved performance. The OpenCompass scores for InternVL 1.5 and InternVL 2.0 were collected from the OpenCompass leaderboard, while the scores for InternVL 2.5 series were obtained through our local testing.
| Settings | InternVL2.5-1B | InternVL2.5-2B | InternVL2.5-4B | InternVL2.5-8B | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Stage 1 | Stage 2 | Stage 1 | Stage 2 | Stage 1 | Stage 2 | Stage 1 | Stage 1.5 | Stage 2 | ||
| — | — | — | — | — | — | — | — | — | — | — |
| Dataset | Pre-train Mixture | Fine-tune Mixture | Pre-train Mixture | Fine-tune Mixture | Pre-train Mixture | Fine-tune Mixture | Pre-train Mixture | Pre-train Mixture | Fine-tune Mixture | |
| — | — | — | — | — | — | — | — | — | — | — |
| Trainable | MLP | Full Model | MLP | Full Model | MLP | Full Model | MLP | ViT+MLP | Full Model | |
| — | — | — | — | — | — | — | — | — | — | — |
| Packed Batch Size | 512 | 512 | 512 | 512 | 512 | 512 | 512 | 1024 | 512 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Learning Rate | 2e-4 | 4e-5 | 2e-5 | 4e-5 | 2e-5 | 4e-5 | 2e-4 | 1e-5 | 4e-5 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Context Length | 16384 | 16384 | 16384 | 16384 | 16384 | 16384 | 16384 | 16384 | 16384 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Image Tile Threshold | 48 | 48 | 48 | 48 | 48 | 48 | 48 | 48 | 48 | |
| — | — | — | — | — | — | — | — | — | — | — |
| ViT Drop Path | 0.0 | 0.1 | 0.0 | 0.1 | 0.0 | 0.1 | 0.0 | 0.1 | 0.1 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Weight Decay | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.05 | 0.05 | 0.05 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Training Epochs | – | 4 | – | 4 | – | 2 | – | – | 1 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Training Tokens | ~191B | ~176B | ~277B | ~176B | ~164B | ~88B | ~22B | ~76B | ~44B |
🔼 Table 3 details the training configurations and hyperparameters used for various InternVL 2.5 model sizes (1B, 2B, 4B, 8B, 26B, 38B, and 78B parameters). It shows the dataset used (a mixture of datasets), the trainable parameters at each stage (MLP warmup, optional ViT incremental learning, and full model instruction tuning), and hyperparameters such as batch size, learning rate, context length, dropout rate, and weight decay. The number of training tokens is also given for each model. Importantly, it highlights the efficiency of InternVL 2.5 training, showcasing that InternVL2.5-78B required only ~120B tokens for training, significantly less than the 1.4 trillion tokens used in Qwen2-VL [246].
read the caption
Table 3: Training configurations and hyperparameters for InternVL 2.5. This table presents the training setups for various scales of InternVL 2.5 models. The configurations are carefully optimized to ensure efficient scaling and performance across different parameter sizes and training stages. Notably, Qwen2-VL [246] processed a cumulative total of 1.4T tokens, while our InternVL2.5-78B is trained on just ∼similar-to\sim∼120B tokens.
| Settings | InternVL2.5-26B | InternVL2.5-26B | InternVL2.5-26B | InternVL2.5-38B | InternVL2.5-38B | InternVL2.5-78B | InternVL2.5-78B |
|---|---|---|---|---|---|---|---|
| Stage 1 | Stage 1.5 | Stage 2 | Stage 1 | Stage 2 | Stage 1 | Stage 2 | |
| — | — | — | — | — | — | — | — |
| Dataset | Pre-train Mixture | Pre-train Mixture | Fine-tune Mixture | Pre-train Mixture | Fine-tune Mixture | Pre-train Mixture | Fine-tune Mixture |
| Trainable | MLP | ViT+MLP | Full Model | MLP | Full Model | MLP | Full Model |
| Packed Batch Size | 512 | 1024 | 512 | 512 | 512 | 512 | 512 |
| Learning Rate | 2e-4 | 1e-5 | 2e-5 | 2e-4 | 2e-5 | 2e-4 | 2e-5 |
| Context Length | 16384 | 16384 | 16384 | 16384 | 16384 | 16384 | 16384 |
| Image Tile Threshold | 48 | 48 | 48 | 48 | 48 | 48 | 48 |
| ViT Drop Path | 0.0 | 0.4 | 0.4 | 0.0 | 0.4 | 0.0 | 0.4 |
| Weight Decay | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 |
| Training Epochs | – | – | 1 | – | 1 | – | 1 |
| Training Tokens | ~31B | ~146B | ~44B | ~107B | ~44B | ~76B | ~44B |
🔼 Table 4 details the composition of the InternVL 2.5 model’s pre-training data. It highlights the exclusive use of conversation-format instruction data and specifies that during this stage, only the Multi-Layer Perceptron (MLP) parameters, or both MLP and Vision Transformer (ViT) parameters, are trainable. This training approach allows for the inclusion of both low- and high-quality data in the pre-training phase.
read the caption
Table 4: Summary of the pre-training data mixture of InternVL 2.5. Notably, we exclusively use conversaiton-format instruction data, and at this stage, only the MLP or both MLP and ViT parameters are trainable, allowing the incorporation of both low- and high-quality data.
| Task | Dataset |
|---|---|
| Type: Single/Multi-Image Datasets | |
| FaceCaption [49], COCO-Caption [214], OpenImages-Caption [116], Objects365-Caption [208], TextCap [211], | |
| Laion-ZH [203], Laion-EN [203], Laion-COCO [204], LLaVAR [305], InternVL-SA-1B-Caption [113], | |
| Captioning | MMInstruct [155], GRIT-Caption [194], ShareGPT4V [29], LVIS-Instruct-4V [244], ShareCaptioner [29], |
| OmniCorpus [133], ShareGPT4o [35] | |
| GQA [98], OKVQA [178], A-OKVQA [205], Visual7W [317], VisText [226], VSR [147], TallyQA [2] | |
| General QA | Objects365-YorN [208], IconQA [167], Stanford40 [273], VisDial [51], VQAv2 [74], Hateful-Memes [111] |
| MAVIS [300], GeomVerse [107], MetaMath-Rendered [281], MapQA [23], GeoQA+ [20], Geometry3K [164], | |
| Mathematics | UniGeo [26], GEOS [206], CLEVR-Math [144] |
| ChartQA [181], PlotQA [187], FigureQA [105], LRV-Instruction [148], ArxivQA [132], MMC-Inst [149], | |
| TabMWP [166], DVQA [104], UniChart [182], SimChart9K [263], Chart2Text [191], FinTabNet [312], | |
| Chart | SciTSR [39], Synthetic Chart2Markdown |
| LaionCOCO-OCR [204], Wukong-OCR [75], ParsynthOCR [89], SynthDoG-EN [112], SynthDoG-ZH [112], | |
| SynthDoG-RU [112], SynthDoG-JP [112], SynthDoG-KO [112], IAM [180], EST-VQA [253], ST-VQA [17], | |
| OCR | NAF [52], InfoVQA [183], HME100K [288], OCRVQA [188], SROIE [97], POIE [115], CTW [287], |
| SynthText [79], ArT [40], LSVT [222], RCTW-17 [209], ReCTs [301], MTWI [82], TextVQA [212], | |
| CASIA [146], TextOCR [213], Chinese-OCR [14], EATEN [78], COCO-Text [238], Synthetic Arxiv OCR, | |
| Synthetic Image2Latex, Synthetic Handwritten OCR, Synthetic Infographic2Markdown | |
| KVQA [207], A-OKVQA [205], ViQuAE [123], iNaturalist2018 [237], MovieNet [95], ART500K [176], | |
| KonIQ-10K [91], IconQA [167], VisualMRC [225], ChemVLM Data [129], ScienceQA [165], AI2D [109], | |
| Knowledge | TQA [110], Wikipedia-QA [81], Synthetic Multidisciplinary Knowledge / QA |
| Objects365 [208], GRIT [278], RefCOCO [280], GPT4Gen-RD-BoxCoT [27], All-Seeing-V1 [251], | |
| Grounding | All-Seeing-V2 [250], V3Det [243], TolokaVQA [236] |
| Document | DocReason25K [93], DocVQA [184], Docmatix [121], Synthetic Arxiv QA |
| ALLaVA [25], SVIT [309], Cambrain-GPT4o [234], TextOCR-GPT4V [102], MMDU [159], | |
| Conversation | Synthetic Real-World Conversations |
| PMC-VQA [303], VQA-RAD [120], ImageCLEF [72], SLAKE [145], Medical-Diff-VQA [94], | |
| Medical | PMC-CaseReport [260], GMAI-VL [134] |
| GUI | Screen2Words [240], WebSight [122] |
| Type: Video Datasets | |
| Captioning | Mementos [254], ShareGPT4Video [30], VideoGPT+ [174], ShareGPT4o-Video [35] |
| General QA | VideoChat2-IT [131], EgoTaskQA [99], NTU RGB+D [152], CLEVRER [276], STAR [259], LSMDC [201] |
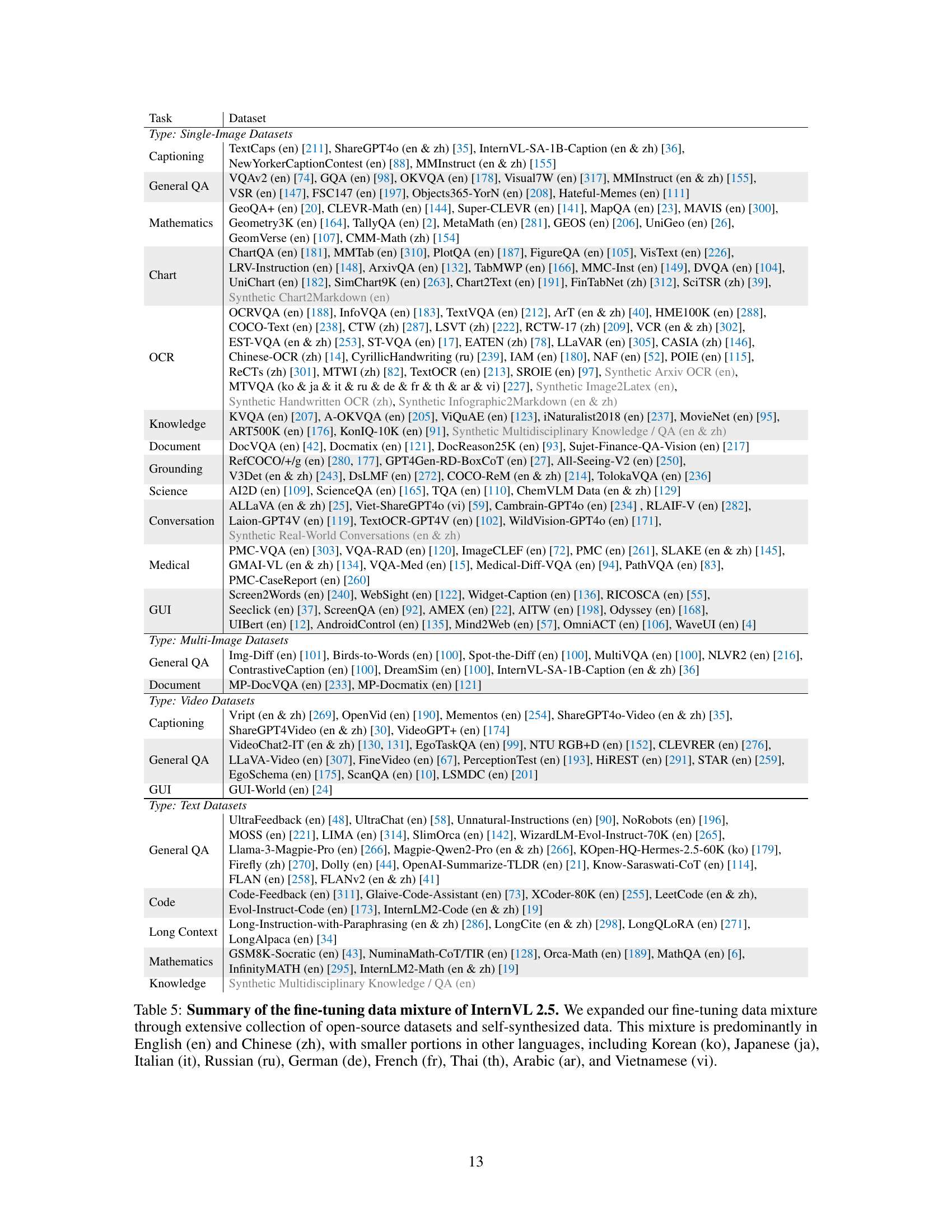
🔼 Table 5 details the composition of the fine-tuning dataset used to train InternVL 2.5. The dataset is a multi-lingual blend, primarily English and Chinese, but also incorporates smaller amounts of data in Korean, Japanese, Italian, Russian, German, French, Thai, Arabic, and Vietnamese. The dataset is a mixture of open-source datasets and data that the authors themselves created.
read the caption
Table 5: Summary of the fine-tuning data mixture of InternVL 2.5. We expanded our fine-tuning data mixture through extensive collection of open-source datasets and self-synthesized data. This mixture is predominantly in English (en) and Chinese (zh), with smaller portions in other languages, including Korean (ko), Japanese (ja), Italian (it), Russian (ru), German (de), French (fr), Thai (th), Arabic (ar), and Vietnamese (vi).
| Task | Dataset |
|---|---|
| Type: Single-Image Datasets | |
| TextCaps (en) [211], ShareGPT4o (en & zh) [35], InternVL-SA-1B-Caption (en & zh) [36], | |
| Captioning | NewYorkerCaptionContest (en) [88], MMInstruct (en & zh) [155] |
| VQAv2 (en) [74], GQA (en) [98], OKVQA (en) [178], Visual7W (en) [317], MMInstruct (en & zh) [155] | |
| General QA | VSR (en) [147], FSC147 (en) [197], Objects365-YorN (en) [208], Hateful-Memes (en) [111] |
| GeoQA+ (en) [20], CLEVR-Math (en) [144], Super-CLEVR (en) [141], MapQA (en) [23], MAVIS (en) [300], | |
| Geometry3K (en) [164], TallyQA (en) [2], MetaMath (en) [281], GEOS (en) [206], UniGeo (en) [26], | |
| Mathematics | GeomVerse (en) [107], CMM-Math (zh) [154] |
| ChartQA (en) [181], MMTab (en) [310], PlotQA (en) [187], FigureQA (en) [105], VisText (en) [226], | |
| LRV-Instruction (en) [148], ArxivQA (en) [132], TabMWP (en) [166], MMC-Inst (en) [149], DVQA (en) [104], | |
| UniChart (en) [182], SimChart9K (en) [263], Chart2Text (en) [191], FinTabNet (zh) [312], SciTSR (zh) [39], | |
| Chart | Synthetic Chart2Markdown (en) |
| OCRVQA (en) [188], InfoVQA (en) [183], TextVQA (en) [212], ArT (en & zh) [40], HME100K (en) [288], | |
| COCO-Text (en) [238], CTW (zh) [287], LSVT (zh) [222], RCTW-17 (zh) [209], VCR (en & zh) [302], | |
| EST-VQA (en & zh) [253], ST-VQA (en) [17], EATEN (zh) [78], LLaVAR (en) [305], CASIA (zh) [146], | |
| OCR | Chinese-OCR (zh) [14], CyrillicHandwriting (ru) [239], IAM (en) [180], NAF (en) [52], POIE (en) [115], |
| ReCTs (zh) [301], MTWI (zh) [82], TextOCR (en) [213], SROIE (en) [97], Synthetic Arxiv OCR (en), | |
| MTVQA (ko & ja & it & ru & de & fr & th & ar & vi) [227], Synthetic Image2Latex (en), | |
| Synthetic Handwritten OCR (zh), Synthetic Infographic2Markdown (en & zh) | |
| KVQA (en) [207], A-OKVQA (en) [205], ViQuAE (en) [123], iNaturalist2018 (en) [237], MovieNet (en) [95], | |
| Knowledge | ART500K (en) [176], KonIQ-10K (en) [91], Synthetic Multidisciplinary Knowledge / QA (en & zh) |
| Document | DocVQA (en) [42], Docmatix (en) [121], DocReason25K (en) [93], Sujet-Finance-QA-Vision (en) [217] |
| RefCOCO/+/g (en) [280, 177], GPT4Gen-RD-BoxCoT (en) [27], All-Seeing-V2 (en) [250], | |
| Grounding | V3Det (en & zh) [243], DsLMF (en) [272], COCO-ReM (en & zh) [214], TolokaVQA (en) [236] |
| Science | AI2D (en) [109], ScienceQA (en) [165], TQA (en) [110], ChemVLM Data (en & zh) [129] |
| ALLaVA (en & zh) [25], Viet-ShareGPT4o (vi) [59], Cambrain-GPT4o (en) [234], RLAIF-V (en) [282], | |
| Laion-GPT4V (en) [119], TextOCR-GPT4V (en) [102], WildVision-GPT4o (en) [171], | |
| Conversation | Synthetic Real-World Conversations (en & zh) |
| PMC-VQA (en) [303], VQA-RAD (en) [120], ImageCLEF (en) [72], PMC (en) [261], SLAKE (en & zh) [145], | |
| GMAI-VL (en & zh) [134], VQA-Med (en) [15], Medical-Diff-VQA (en) [94], PathVQA (en) [83], | |
| Medical | PMC-CaseReport (en) [260] |
| Screen2Words (en) [240], WebSight (en) [122], Widget-Caption (en) [136], RICOSCA (en) [55], | |
| Seeclick (en) [37], ScreenQA (en) [92], AMEX (en) [22], AITW (en) [198], Odyssey (en) [168], | |
| GUI | UIBert (en) [12], AndroidControl (en) [135], Mind2Web (en) [57], OmniACT (en) [106], WaveUI (en) [4] |
| Type: Multi-Image Datasets | |
| Img-Diff (en) [101], Birds-to-Words (en) [100], Spot-the-Diff (en) [100], MultiVQA (en) [100], NLVR2 (en) [216], | |
| General QA | ContrastiveCaption (en) [100], DreamSim (en) [100], InternVL-SA-1B-Caption (en & zh) [36] |
| Document | MP-DocVQA (en) [233], MP-Docmatix (en) [121] |
| Type: Video Datasets | |
| Vript (en & zh) [269], OpenVid (en) [190], Mementos (en) [254], ShareGPT4o-Video (en & zh) [35], | |
| Captioning | ShareGPT4Video (en & zh) [30], VideoGPT+ (en) [174] |
| VideoChat2-IT (en & zh) [130, 131], EgoTaskQA (en) [99], NTU RGB+D (en) [152], CLEVRER (en) [276], | |
| LLaVA-Video (en) [307], FineVideo (en) [67], PerceptionTest (en) [193], HiREST (en) [291], STAR (en) [259], | |
| General QA | EgoSchema (en) [175], ScanQA (en) [10], LSMDC (en) [201] |
| GUI | GUI-World (en) [24] |
| Type: Text Datasets | |
| UltraFeedback (en) [48], UltraChat (en) [58], Unnatural-Instructions (en) [90], NoRobots (en) [196], | |
| MOSS (en) [221], LIMA (en) [314], SlimOrca (en) [142], WizardLM-Evol-Instruct-70K (en) [265], | |
| Llama-3-Magpie-Pro (en) [266], Magpie-Qwen2-Pro (en & zh) [266], KOpen-HQ-Hermes-2.5-60K (ko) [179], | |
| Firefly (zh) [270], Dolly (en) [44], OpenAI-Summarize-TLDR (en) [21], Know-Saraswati-CoT (en) [114], | |
| General QA | FLAN (en) [258], FLANv2 (en & zh) [41] |
| Code-Feedback (en) [311], Glaive-Code-Assistant (en) [73], XCoder-80K (en) [255], LeetCode (en & zh), | |
| Code | Evol-Instruct-Code (en) [173], InternLM2-Code (en & zh) [19] |
| Long Context | Long-Instruction-with-Paraphrasing (en & zh) [286], LongCite (en & zh) [298], LongQLoRA (en) [271], |
| LongAlpaca (en) [34] | |
| GSM8K-Socratic (en) [43], NuminaMath-CoT/TIR (en) [128], Orca-Math (en) [189], MathQA (en) [6], | |
| Mathematics | InfinityMATH (en) [295], InternLM2-Math (en & zh) [19] |
| Knowledge | Synthetic Multidisciplinary Knowledge / QA (en) |
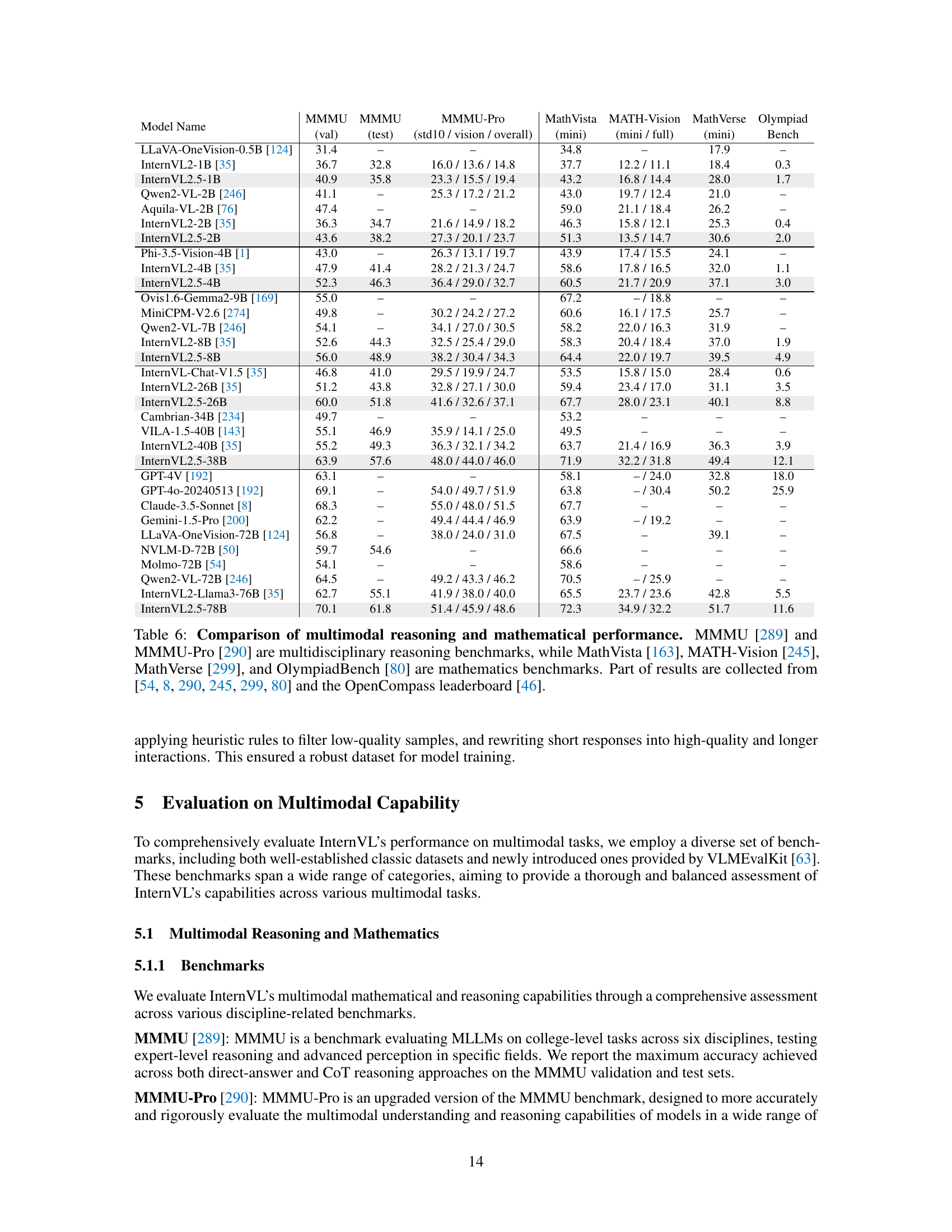
🔼 Table 6 presents a comparative analysis of various Multimodal Large Language Models (MLLMs) across several benchmarks that assess multimodal reasoning and mathematical capabilities. The benchmarks include MMMU and MMMU-Pro, which evaluate multidisciplinary reasoning skills across various academic fields, and MathVista, MATH-Vision, MathVerse, and OlympiadBench, which focus specifically on mathematical problem-solving skills. The table highlights the models’ performance on each benchmark, showing their relative strengths and weaknesses in these critical areas of multimodal intelligence. Some scores are taken from other publications and the OpenCompass leaderboard.
read the caption
Table 6: Comparison of multimodal reasoning and mathematical performance. MMMU [289] and MMMU-Pro [290] are multidisciplinary reasoning benchmarks, while MathVista [163], MATH-Vision [245], MathVerse [299], and OlympiadBench [80] are mathematics benchmarks. Part of results are collected from [54, 8, 290, 245, 299, 80] and the OpenCompass leaderboard [46].
| Model Name | MMMU (val) | MMMU (test) | MMMU-Pro (std10 / vision / overall) | MathVista (mini) | MATH-Vision (mini / full) | MathVerse (mini) | Olympiad Bench |
|---|---|---|---|---|---|---|---|
| LLaVA-OneVision-0.5B [124] | 31.4 | – | – | 34.8 | – | 17.9 | – |
| InternVL2-1B [35] | 36.7 | 32.8 | 16.0 / 13.6 / 14.8 | 37.7 | 12.2 / 11.1 | 18.4 | 0.3 |
| InternVL2.5-1B | 40.9 | 35.8 | 23.3 / 15.5 / 19.4 | 43.2 | 16.8 / 14.4 | 28.0 | 1.7 |
| Qwen2-VL-2B [246] | 41.1 | – | 25.3 / 17.2 / 21.2 | 43.0 | 19.7 / 12.4 | 21.0 | – |
| Aquila-VL-2B [76] | 47.4 | – | – | 59.0 | 21.1 / 18.4 | 26.2 | – |
| InternVL2-2B [35] | 36.3 | 34.7 | 21.6 / 14.9 / 18.2 | 46.3 | 15.8 / 12.1 | 25.3 | 0.4 |
| InternVL2.5-2B | 43.6 | 38.2 | 27.3 / 20.1 / 23.7 | 51.3 | 13.5 / 14.7 | 30.6 | 2.0 |
| Phi-3.5-Vision-4B [1] | 43.0 | – | 26.3 / 13.1 / 19.7 | 43.9 | 17.4 / 15.5 | 24.1 | – |
| InternVL2-4B [35] | 47.9 | 41.4 | 28.2 / 21.3 / 24.7 | 58.6 | 17.8 / 16.5 | 32.0 | 1.1 |
| InternVL2.5-4B | 52.3 | 46.3 | 36.4 / 29.0 / 32.7 | 60.5 | 21.7 / 20.9 | 37.1 | 3.0 |
| Ovis1.6-Gemma2-9B [169] | 55.0 | – | – | 67.2 | – / 18.8 | – | – |
| MiniCPM-V2.6 [274] | 49.8 | – | 30.2 / 24.2 / 27.2 | 60.6 | 16.1 / 17.5 | 25.7 | – |
| Qwen2-VL-7B [246] | 54.1 | – | 34.1 / 27.0 / 30.5 | 58.2 | 22.0 / 16.3 | 31.9 | – |
| InternVL2-8B [35] | 52.6 | 44.3 | 32.5 / 25.4 / 29.0 | 58.3 | 20.4 / 18.4 | 37.0 | 1.9 |
| InternVL2.5-8B | 56.0 | 48.9 | 38.2 / 30.4 / 34.3 | 64.4 | 22.0 / 19.7 | 39.5 | 4.9 |
| InternVL-Chat-V1.5 [35] | 46.8 | 41.0 | 29.5 / 19.9 / 24.7 | 53.5 | 15.8 / 15.0 | 28.4 | 0.6 |
| InternVL2-26B [35] | 51.2 | 43.8 | 32.8 / 27.1 / 30.0 | 59.4 | 23.4 / 17.0 | 31.1 | 3.5 |
| InternVL2.5-26B | 60.0 | 51.8 | 41.6 / 32.6 / 37.1 | 67.7 | 28.0 / 23.1 | 40.1 | 8.8 |
| Cambrian-34B [234] | 49.7 | – | – | 53.2 | – | – | – |
| VILA-1.5-40B [143] | 55.1 | 46.9 | 35.9 / 14.1 / 25.0 | 49.5 | – | – | – |
| InternVL2-40B [35] | 55.2 | 49.3 | 36.3 / 32.1 / 34.2 | 63.7 | 21.4 / 16.9 | 36.3 | 3.9 |
| InternVL2.5-38B | 63.9 | 57.6 | 48.0 / 44.0 / 46.0 | 71.9 | 32.2 / 31.8 | 49.4 | 12.1 |
| GPT-4V [192] | 63.1 | – | – | 58.1 | – / 24.0 | 32.8 | 18.0 |
| GPT-4o-20240513 [192] | 69.1 | – | 54.0 / 49.7 / 51.9 | 63.8 | – / 30.4 | 50.2 | 25.9 |
| Claude-3.5-Sonnet [8] | 68.3 | – | 55.0 / 48.0 / 51.5 | 67.7 | – | – | – |
| Gemini-1.5-Pro [200] | 62.2 | – | 49.4 / 44.4 / 46.9 | 63.9 | – / 19.2 | – | – |
| LLaVA-OneVision-72B [124] | 56.8 | – | 38.0 / 24.0 / 31.0 | 67.5 | – | 39.1 | – |
| NVLM-D-72B [50] | 59.7 | 54.6 | – | 66.6 | – | – | – |
| Molmo-72B [54] | 54.1 | – | – | 58.6 | – | – | – |
| Qwen2-VL-72B [246] | 64.5 | – | 49.2 / 43.3 / 46.2 | 70.5 | – / 25.9 | – | – |
| InternVL2-Llama3-76B [35] | 62.7 | 55.1 | 41.9 / 38.0 / 40.0 | 65.5 | 23.7 / 23.6 | 42.8 | 5.5 |
| InternVL2.5-78B | 70.1 | 61.8 | 51.4 / 45.9 / 48.6 | 72.3 | 34.9 / 32.2 | 51.7 | 11.6 |
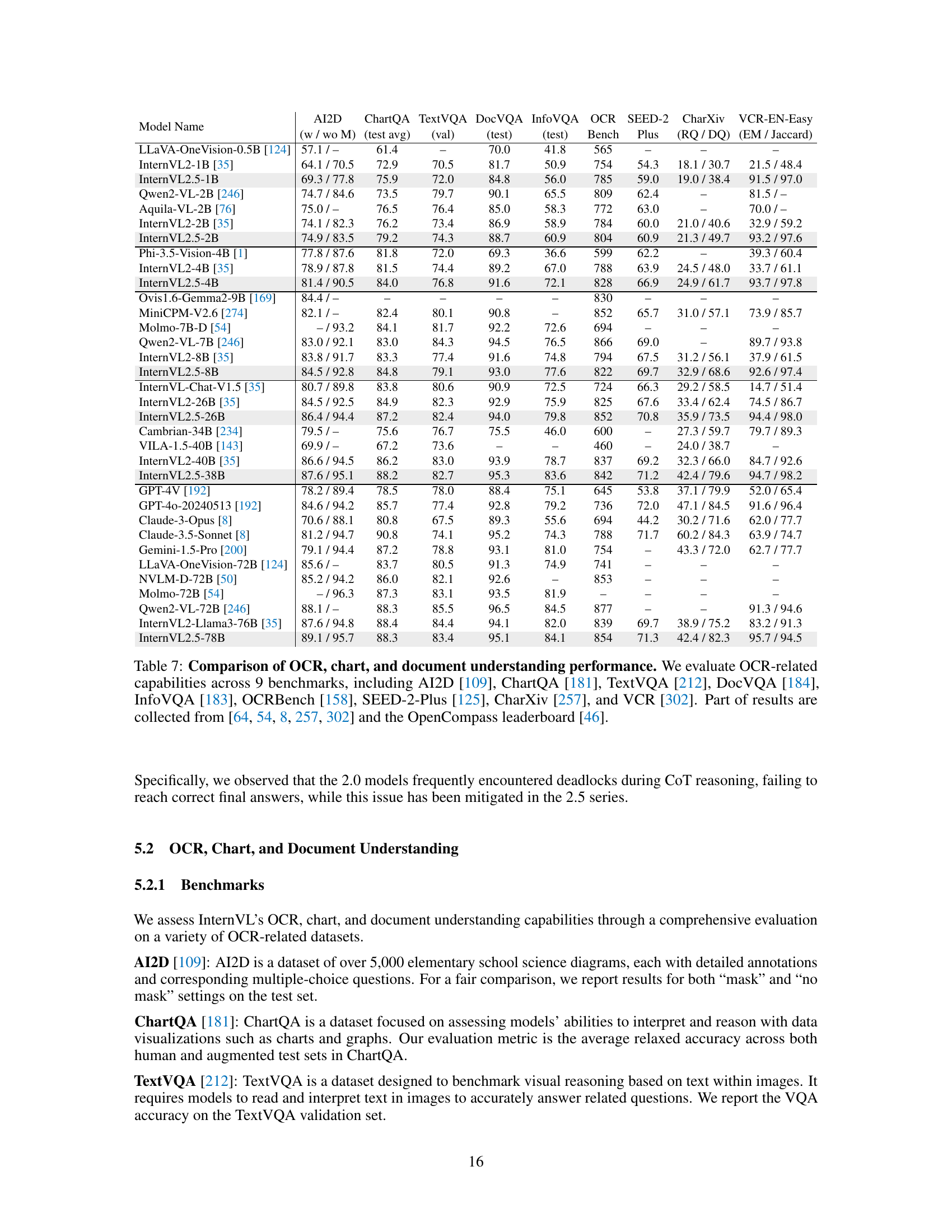
🔼 Table 7 presents a comprehensive evaluation of InternVL 2.5’s performance on various OCR, chart, and document understanding tasks. It compares InternVL 2.5 to several other leading open-source and closed-source models across nine diverse benchmarks. These benchmarks assess different aspects of visual and textual understanding, including text recognition, visual question answering, document question answering, and reasoning with chart data. The results highlight InternVL 2.5’s competitive performance and showcase improvements over previous versions of InternVL.
read the caption
Table 7: Comparison of OCR, chart, and document understanding performance. We evaluate OCR-related capabilities across 9 benchmarks, including AI2D [109], ChartQA [181], TextVQA [212], DocVQA [184], InfoVQA [183], OCRBench [158], SEED-2-Plus [125], CharXiv [257], and VCR [302]. Part of results are collected from [64, 54, 8, 257, 302] and the OpenCompass leaderboard [46].
| Model Name | AI2D (w / wo M) | ChartQA (test avg) | TextVQA (val) | DocVQA (test) | InfoVQA (test) | OCR Bench | SEED-2 Plus | CharXiv (RQ / DQ) | VCR-EN-Easy (EM / Jaccard) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA-OneVision-0.5B [124] | 57.1 / – | 61.4 | – | 70.0 | 41.8 | 565 | – | – | – |
| InternVL2-1B [35] | 64.1 / 70.5 | 72.9 | 70.5 | 81.7 | 50.9 | 754 | 54.3 | 18.1 / 30.7 | 21.5 / 48.4 |
| InternVL2.5-1B | 69.3 / 77.8 | 75.9 | 72.0 | 84.8 | 56.0 | 785 | 59.0 | 19.0 / 38.4 | 91.5 / 97.0 |
| Qwen2-VL-2B [246] | 74.7 / 84.6 | 73.5 | 79.7 | 90.1 | 65.5 | 809 | 62.4 | – | 81.5 / – |
| Aquila-VL-2B [76] | 75.0 / – | 76.5 | 76.4 | 85.0 | 58.3 | 772 | 63.0 | – | 70.0 / – |
| InternVL2-2B [35] | 74.1 / 82.3 | 76.2 | 73.4 | 86.9 | 58.9 | 784 | 60.0 | 21.0 / 40.6 | 32.9 / 59.2 |
| InternVL2.5-2B | 74.9 / 83.5 | 79.2 | 74.3 | 88.7 | 60.9 | 804 | 60.9 | 21.3 / 49.7 | 93.2 / 97.6 |
| Phi-3.5-Vision-4B [1] | 77.8 / 87.6 | 81.8 | 72.0 | 69.3 | 36.6 | 599 | 62.2 | – | 39.3 / 60.4 |
| InternVL2-4B [35] | 78.9 / 87.8 | 81.5 | 74.4 | 89.2 | 67.0 | 788 | 63.9 | 24.5 / 48.0 | 33.7 / 61.1 |
| InternVL2.5-4B | 81.4 / 90.5 | 84.0 | 76.8 | 91.6 | 72.1 | 828 | 66.9 | 24.9 / 61.7 | 93.7 / 97.8 |
| Ovis1.6-Gemma2-9B [169] | 84.4 / – | – | – | – | – | 830 | – | – | – |
| MiniCPM-V2.6 [274] | 82.1 / – | 82.4 | 80.1 | 90.8 | – | 852 | 65.7 | 31.0 / 57.1 | 73.9 / 85.7 |
| Molmo-7B-D [54] | – / 93.2 | 84.1 | 81.7 | 92.2 | 72.6 | 694 | – | – | – |
| Qwen2-VL-7B [246] | 83.0 / 92.1 | 83.0 | 84.3 | 94.5 | 76.5 | 866 | 69.0 | – | 89.7 / 93.8 |
| InternVL2-8B [35] | 83.8 / 91.7 | 83.3 | 77.4 | 91.6 | 74.8 | 794 | 67.5 | 31.2 / 56.1 | 37.9 / 61.5 |
| InternVL2.5-8B | 84.5 / 92.8 | 84.8 | 79.1 | 93.0 | 77.6 | 822 | 69.7 | 32.9 / 68.6 | 92.6 / 97.4 |
| InternVL-Chat-V1.5 [35] | 80.7 / 89.8 | 83.8 | 80.6 | 90.9 | 72.5 | 724 | 66.3 | 29.2 / 58.5 | 14.7 / 51.4 |
| InternVL2-26B [35] | 84.5 / 92.5 | 84.9 | 82.3 | 92.9 | 75.9 | 825 | 67.6 | 33.4 / 62.4 | 74.5 / 86.7 |
| InternVL2.5-26B | 86.4 / 94.4 | 87.2 | 82.4 | 94.0 | 79.8 | 852 | 70.8 | 35.9 / 73.5 | 94.4 / 98.0 |
| Cambrian-34B [234] | 79.5 / – | 75.6 | 76.7 | 75.5 | 46.0 | 600 | – | 27.3 / 59.7 | 79.7 / 89.3 |
| VILA-1.5-40B [143] | 69.9 / – | 67.2 | 73.6 | – | – | 460 | – | 24.0 / 38.7 | – |
| InternVL2-40B [35] | 86.6 / 94.5 | 86.2 | 83.0 | 93.9 | 78.7 | 837 | 69.2 | 32.3 / 66.0 | 84.7 / 92.6 |
| InternVL2.5-38B | 87.6 / 95.1 | 88.2 | 82.7 | 95.3 | 83.6 | 842 | 71.2 | 42.4 / 79.6 | 94.7 / 98.2 |
| GPT-4V [192] | 78.2 / 89.4 | 78.5 | 78.0 | 88.4 | 75.1 | 645 | 53.8 | 37.1 / 79.9 | 52.0 / 65.4 |
| GPT-4o-20240513 [192] | 84.6 / 94.2 | 85.7 | 77.4 | 92.8 | 79.2 | 736 | 72.0 | 47.1 / 84.5 | 91.6 / 96.4 |
| Claude-3-Opus [8] | 70.6 / 88.1 | 80.8 | 67.5 | 89.3 | 55.6 | 694 | 44.2 | 30.2 / 71.6 | 62.0 / 77.7 |
| Claude-3.5-Sonnet [8] | 81.2 / 94.7 | 90.8 | 74.1 | 95.2 | 74.3 | 788 | 71.7 | 60.2 / 84.3 | 63.9 / 74.7 |
| Gemini-1.5-Pro [200] | 79.1 / 94.4 | 87.2 | 78.8 | 93.1 | 81.0 | 754 | – | 43.3 / 72.0 | 62.7 / 77.7 |
| LLaVA-OneVision-72B [124] | 85.6 / – | 83.7 | 80.5 | 91.3 | 74.9 | 741 | – | – | – |
| NVLM-D-72B [50] | 85.2 / 94.2 | 86.0 | 82.1 | 92.6 | – | 853 | – | – | – |
| Molmo-72B [54] | – / 96.3 | 87.3 | 83.1 | 93.5 | 81.9 | – | – | – | – |
| Qwen2-VL-72B [246] | 88.1 / – | 88.3 | 85.5 | 96.5 | 84.5 | 877 | – | – | 91.3 / 94.6 |
| InternVL2-Llama3-76B [35] | 87.6 / 94.8 | 88.4 | 84.4 | 94.1 | 82.0 | 839 | 69.7 | 38.9 / 75.2 | 83.2 / 91.3 |
| InternVL2.5-78B | 89.1 / 95.7 | 88.3 | 83.4 | 95.1 | 84.1 | 854 | 71.3 | 42.4 / 82.3 | 95.7 / 94.5 |
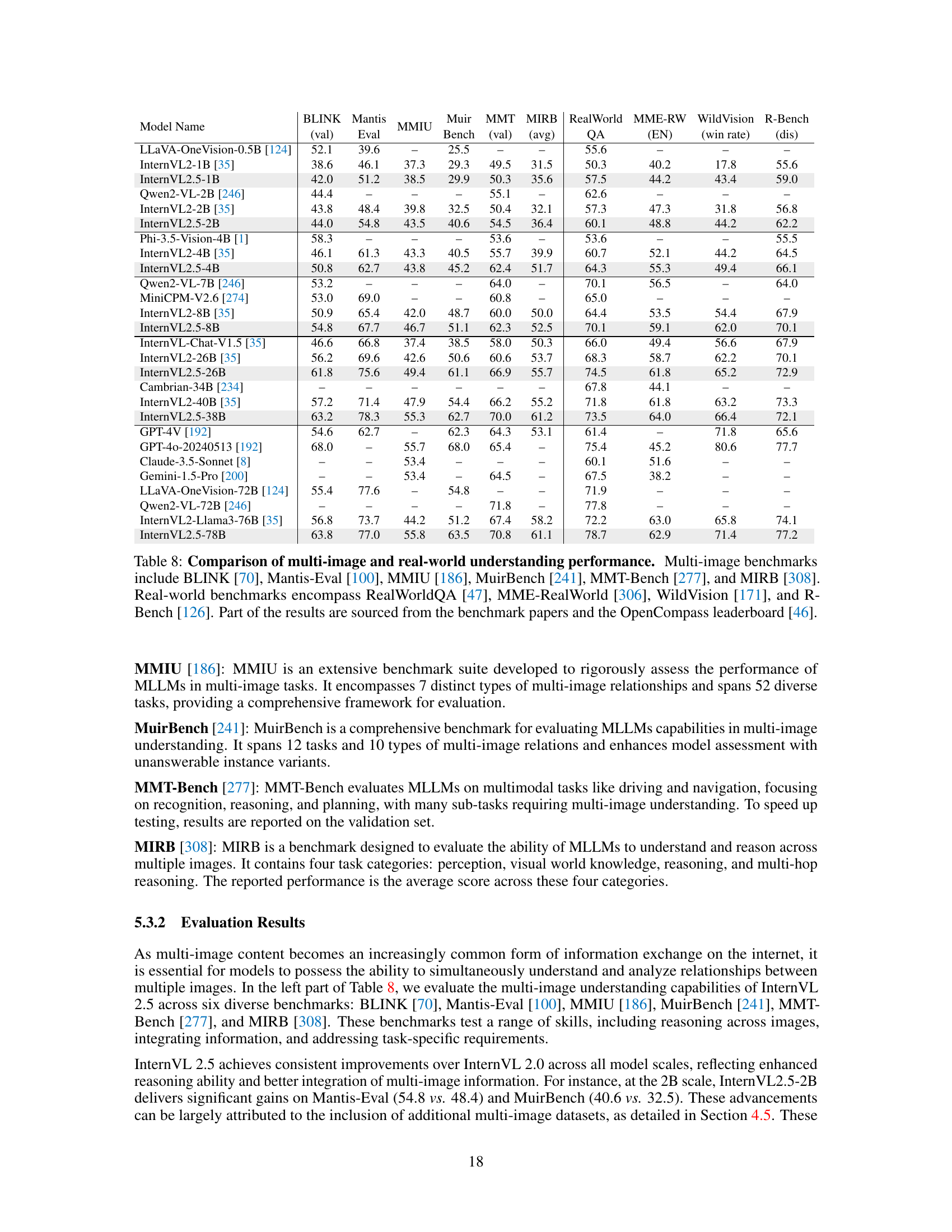
🔼 Table 8 presents a comparative analysis of various multimodal large language models (MLLMs) across a range of benchmarks focusing on multi-image and real-world understanding. The multi-image benchmarks assess the models’ ability to process and reason with multiple images simultaneously. These include BLINK, Mantis-Eval, MMIU, MuirBench, MMT-Bench, and MIRB, each evaluating different aspects of multi-image comprehension. Real-world benchmarks evaluate model performance on more practical, complex scenarios using real-world data; these include RealWorldQA, MME-RealWorld, WildVision, and R-Bench, assessing capabilities like spatial understanding and robustness to real-world image distortions. A subset of the results are drawn from existing literature while others are obtained through local testing.
read the caption
Table 8: Comparison of multi-image and real-world understanding performance. Multi-image benchmarks include BLINK [70], Mantis-Eval [100], MMIU [186], MuirBench [241], MMT-Bench [277], and MIRB [308]. Real-world benchmarks encompass RealWorldQA [47], MME-RealWorld [306], WildVision [171], and R-Bench [126]. Part of the results are sourced from the benchmark papers and the OpenCompass leaderboard [46].
| Model Name | BLINK (val) | Mantis Eval | MMIU | Muir Bench | MMT (val) | MIRB (avg) | RealWorld QA | MME-RW (EN) | WildVision (win rate) | R-Bench (dis) |
|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA-OneVision-0.5B [124] | 52.1 | 39.6 | – | 25.5 | – | – | 55.6 | – | – | – |
| InternVL2-1B [35] | 38.6 | 46.1 | 37.3 | 29.3 | 49.5 | 31.5 | 50.3 | 40.2 | 17.8 | 55.6 |
| InternVL2.5-1B | 42.0 | 51.2 | 38.5 | 29.9 | 50.3 | 35.6 | 57.5 | 44.2 | 43.4 | 59.0 |
| Qwen2-VL-2B [246] | 44.4 | – | – | – | 55.1 | – | 62.6 | – | – | – |
| InternVL2-2B [35] | 43.8 | 48.4 | 39.8 | 32.5 | 50.4 | 32.1 | 57.3 | 47.3 | 31.8 | 56.8 |
| InternVL2.5-2B | 44.0 | 54.8 | 43.5 | 40.6 | 54.5 | 36.4 | 60.1 | 48.8 | 44.2 | 62.2 |
| Phi-3.5-Vision-4B [1] | 58.3 | – | – | – | 53.6 | – | 53.6 | – | – | 55.5 |
| InternVL2-4B [35] | 46.1 | 61.3 | 43.3 | 40.5 | 55.7 | 39.9 | 60.7 | 52.1 | 44.2 | 64.5 |
| InternVL2.5-4B | 50.8 | 62.7 | 43.8 | 45.2 | 62.4 | 51.7 | 64.3 | 55.3 | 49.4 | 66.1 |
| Qwen2-VL-7B [246] | 53.2 | – | – | – | 64.0 | – | 70.1 | 56.5 | – | 64.0 |
| MiniCPM-V2.6 [274] | 53.0 | 69.0 | – | – | 60.8 | – | 65.0 | – | – | – |
| InternVL2-8B [35] | 50.9 | 65.4 | 42.0 | 48.7 | 60.0 | 50.0 | 64.4 | 53.5 | 54.4 | 67.9 |
| InternVL2.5-8B | 54.8 | 67.7 | 46.7 | 51.1 | 62.3 | 52.5 | 70.1 | 59.1 | 62.0 | 70.1 |
| InternVL-Chat-V1.5 [35] | 46.6 | 66.8 | 37.4 | 38.5 | 58.0 | 50.3 | 66.0 | 49.4 | 56.6 | 67.9 |
| InternVL2-26B [35] | 56.2 | 69.6 | 42.6 | 50.6 | 60.6 | 53.7 | 68.3 | 58.7 | 62.2 | 70.1 |
| InternVL2.5-26B | 61.8 | 75.6 | 49.4 | 61.1 | 66.9 | 55.7 | 74.5 | 61.8 | 65.2 | 72.9 |
| Cambrian-34B [234] | – | – | – | – | – | – | 67.8 | 44.1 | – | – |
| InternVL2-40B [35] | 57.2 | 71.4 | 47.9 | 54.4 | 66.2 | 55.2 | 71.8 | 61.8 | 63.2 | 73.3 |
| InternVL2.5-38B | 63.2 | 78.3 | 55.3 | 62.7 | 70.0 | 61.2 | 73.5 | 64.0 | 66.4 | 72.1 |
| GPT-4V [192] | 54.6 | 62.7 | – | 62.3 | 64.3 | 53.1 | 61.4 | – | 71.8 | 65.6 |
| GPT-4o-20240513 [192] | 68.0 | – | 55.7 | 68.0 | 65.4 | – | 75.4 | 45.2 | 80.6 | 77.7 |
| Claude-3.5-Sonnet [8] | – | – | 53.4 | – | – | – | 60.1 | 51.6 | – | – |
| Gemini-1.5-Pro [200] | – | – | 53.4 | – | 64.5 | – | 67.5 | 38.2 | – | – |
| LLaVA-OneVision-72B [124] | 55.4 | 77.6 | – | 54.8 | – | – | 71.9 | – | – | – |
| Qwen2-VL-72B [246] | – | – | – | – | 71.8 | – | 77.8 | – | – | – |
| InternVL2-Llama3-76B [35] | 56.8 | 73.7 | 44.2 | 51.2 | 67.4 | 58.2 | 72.2 | 63.0 | 65.8 | 74.1 |
| InternVL2.5-78B | 63.8 | 77.0 | 55.8 | 63.5 | 70.8 | 61.1 | 78.7 | 62.9 | 71.4 | 77.2 |
🔼 Table 9 presents a comprehensive evaluation of InternVL 2.5’s performance on various multimodal understanding and hallucination benchmarks. The multimodal understanding benchmarks assess the model’s ability across diverse tasks requiring integrated visual and language processing capabilities. These include MME, MMBench, MMVet, and MMStar. The hallucination benchmarks focus on evaluating the model’s tendency to generate inaccurate or nonsensical outputs, and encompass HallusionBench, MMHal, CRPE, and POPE. The results shown are sourced from both the individual benchmark papers and the OpenCompass leaderboard, allowing comparison to other state-of-the-art models.
read the caption
Table 9: Comparison of comprehensive multimodal understanding and hallucination performance. Comprehensive multimodal benchmarks include MME [68], MMBench series [156], MMVet series [283, 284], and MMStar [28]. Hallucination benchmarks encompass HallusionBench [77], MMHal [223], CRPE [250], and POPE [139]. Part of the results are sourced from the benchmark papers and the OpenCompass leaderboard [46].
| Model Name | MME (sum) | MMB (EN / CN) | MMBv1.1 (EN) | MMVet (turbo) | MMVetv2 (0613) | MMStar | HallBench (avg) | MMHal (score) | CRPE (relation) | POPE (avg) |
|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA-OneVision-0.5B [124] | 1438.0 | 61.6 / 55.5 | 59.6 | 32.2 | - | 37.7 | 27.9 | - | - | - |
| InternVL2-1B [35] | 1794.4 | 65.4 / 60.7 | 61.6 | 32.7 | 36.1 | 45.7 | 34.0 | 2.25 | 57.5 | 87.3 |
| InternVL2.5-1B | 1950.5 | 70.7 / 66.3 | 68.4 | 48.8 | 43.2 | 50.1 | 39.0 | 2.49 | 60.9 | 89.9 |
| Qwen2-VL-2B [246] | 1872.0 | 74.9 / 73.5 | 72.2 | 49.5 | - | 48.0 | 41.7 | - | - | - |
| InternVL2-2B [35] | 1876.8 | 73.2 / 70.9 | 70.2 | 39.5 | 39.6 | 50.1 | 37.9 | 2.52 | 66.3 | 88.3 |
| InternVL2.5-2B | 2138.2 | 74.7 / 71.9 | 72.2 | 60.8 | 52.3 | 53.7 | 42.6 | 2.94 | 70.2 | 90.6 |
| Phi-3.5-Vision-4B [1] | - | 76.0 / 66.1 | 72.1 | 43.2 | - | 47.5 | 40.5 | - | - | - |
| InternVL2-4B [35] | 2059.8 | 78.6 / 73.9 | 75.8 | 51.0 | 46.6 | 54.3 | 41.9 | 2.75 | 71.1 | 87.2 |
| InternVL2.5-4B | 2337.5 | 81.1 / 79.3 | 79.3 | 60.6 | 55.4 | 58.3 | 46.3 | 3.31 | 75.5 | 90.9 |
| Qwen2-VL-7B [246] | 2326.8 | 83.0 / 80.5 | 80.7 | 62.0 | - | 60.7 | 50.6 | 3.40 | 74.4 | 88.1 |
| MiniCPM-V2.6 [274] | 2348.4 | 81.5 / 79.3 | 78.0 | 60.0 | - | 57.5 | 48.1 | 3.60 | 75.2 | 87.3 |
| InternVL2-8B [35] | 2210.3 | 81.7 / 81.2 | 79.5 | 54.2 | 52.3 | 62.0 | 45.2 | 3.33 | 75.8 | 86.9 |
| InternVL2.5-8B | 2344.1 | 84.6 / 82.6 | 83.2 | 62.8 | 58.1 | 62.8 | 50.1 | 3.65 | 78.4 | 90.6 |
| InternVL-Chat-V1.5 [35] | 2194.2 | 82.2 / 82.0 | 80.3 | 61.5 | 51.5 | 57.3 | 50.3 | 3.11 | 75.4 | 88.4 |
| InternVL2-26B [35] | 2260.7 | 83.4 / 82.0 | 81.5 | 62.1 | 57.2 | 61.2 | 50.7 | 3.55 | 75.6 | 88.0 |
| InternVL2.5-26B | 2373.3 | 85.4 / 85.5 | 84.2 | 65.0 | 60.8 | 66.5 | 55.0 | 3.70 | 79.1 | 90.6 |
| Cambrian-34B [234] | - | 80.4 / 79.2 | 78.3 | 53.2 | - | 54.2 | 41.6 | - | - | - |
| InternVL2-40B [35] | 2307.5 | 86.8 / 86.5 | 85.1 | 65.5 | 63.8 | 65.4 | 56.9 | 3.75 | 77.6 | 88.4 |
| InternVL2.5-38B | 2455.8 | 86.5 / 86.3 | 85.5 | 68.8 | 62.1 | 67.9 | 56.8 | 3.71 | 78.3 | 90.7 |
| GPT-4V [192] | 1926.6 | 81.0 / 80.2 | 80.0 | 67.5 | 66.3 | 56.0 | 46.5 | - | - | - |
| GPT-4o-20240513 [192] | - | 83.4 / 82.1 | 83.1 | 69.1 | 71.0 | 64.7 | 55.0 | 4.00 | 76.6 | 86.9 |
| Claude-3-Opus [8] | 1586.8 | 63.3 / 59.2 | 60.1 | 51.7 | 55.8 | 45.7 | 37.8 | - | - | - |
| Claude-3.5-Sonnet [8] | - | 82.6 / 83.5 | 80.9 | 70.1 | 71.8 | 65.1 | 55.5 | - | - | - |
| Gemini-1.5-Pro [200] | - | 73.9 / 73.8 | 74.6 | 64.0 | 66.9 | 59.1 | 45.6 | - | - | - |
| LLaVA-OneVision-72B [124] | 2261.0 | 85.8 / 85.3 | 85.0 | 60.6 | - | 65.8 | 49.0 | - | - | - |
| Qwen2-VL-72B [246] | 2482.7 | 86.5 / 86.6 | 85.9 | 74.0 | 66.9 | 68.3 | 58.1 | - | - | - |
| InternVL2-Llama3-76B [35] | 2414.7 | 86.5 / 86.3 | 85.5 | 65.7 | 68.4 | 67.4 | 55.2 | 3.83 | 77.6 | 89.0 |
| InternVL2.5-78B | 2494.5 | 88.3 / 88.5 | 87.4 | 72.3 | 65.5 | 69.5 | 57.4 | 3.89 | 78.8 | 90.8 |
🔼 Table 10 presents a detailed comparison of InternVL 2.5’s visual grounding performance against other state-of-the-art models on three benchmark datasets: RefCOCO, RefCOCO+, and RefCOCOg. These datasets evaluate a model’s ability to locate objects within an image based on textual descriptions, with varying levels of complexity and detail in those descriptions. The table highlights InternVL 2.5’s performance across different model sizes (8B and 78B parameters), showcasing its improvement over previous versions and competitiveness with leading models. The results demonstrate the impact of model scaling and architecture on visual grounding capabilities.
read the caption
Table 10: Comparison of visual grounding performance. We evaluate InternVL’s visual grounding capability on RefCOCO, RefCOCO+, and RefCOCOg datasets [108, 177]. Parts of the results are collected from [246].
| Model Name | RefCOCO val | RefCOCO test-A | RefCOCO test-B | RefCOCO+ val | RefCOCO+ test-A | RefCOCO+ test-B | RefCOCOg val | RefCOCOg test | avg. | |
|---|---|---|---|---|---|---|---|---|---|---|
| Grounding-DINO-L [153] | 90.6 | 93.2 | 88.2 | 82.8 | 89.0 | 75.9 | 86.1 | 87.0 | 86.6 | |
| UNINEXT-H [267] | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 | 88.9 | |
| ONE-PEACE [247] | 92.6 | 94.2 | 89.3 | 88.8 | 92.2 | 83.2 | 89.2 | 89.3 | 89.8 | |
| Shikra-7B [27] | 87.0 | 90.6 | 80.2 | 81.6 | 87.4 | 72.1 | 82.3 | 82.2 | 82.9 | |
| Ferret-v2-13B [297] | 92.6 | 95.0 | 88.9 | 87.4 | 92.1 | 81.4 | 89.4 | 90.0 | 89.6 | |
| CogVLM-Grounding-17B [248] | 92.8 | 94.8 | 89.0 | 88.7 | 92.9 | 83.4 | 89.8 | 90.8 | 90.3 | |
| MM1.5 [296] | – | 92.5 | 86.7 | – | 88.7 | 77.8 | – | 87.1 | – | |
| Qwen2-VL-7B [246] | 91.7 | 93.6 | 87.3 | 85.8 | 90.5 | 79.5 | 87.3 | 87.8 | 87.9 | |
| TextHawk2 [285] | 91.9 | 93.0 | 87.6 | 86.2 | 90.0 | 80.4 | 88.2 | 88.1 | 88.2 | |
| InternVL2-8B [35] | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 | 82.9 | |
| InternVL2.5-8B | 90.3 | 94.5 | 85.9 | 85.2 | 91.5 | 78.8 | 86.7 | 87.6 | 87.6 | |
| Qwen2-VL-72B [246] | 93.2 | 95.3 | 90.7 | 90.1 | 93.8 | 85.6 | 89.9 | 90.4 | 91.1 | |
| InternVL2-Llama3-76B [35] | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 | 90.0 | |
| InternVL2.5-78B | 93.7 | 95.6 | 92.5 | 90.4 | 94.7 | 86.9 | 92.7 | 92.2 | 92.3 |
🔼 Table 11 presents a comprehensive evaluation of the model’s multilingual capabilities across three distinct benchmarks: MMMB, Multilingual MMBench, and MTVQA. Each benchmark assesses performance across six languages: English, Chinese, Portuguese, Arabic, Turkish, and Russian. The table allows for a detailed comparison of the model’s strengths and weaknesses in handling various language-specific aspects within multimodal tasks.
read the caption
Table 11: Comparison of multimodal multilingual performance. We evaluate multilingual capabilities across 3 benchmarks, including MMMB [218], Multilingual MMBench [218] and MTVQA [227]. The languages evaluated are English (en), Chinese (zh), Portuguese (pt), Arabic (ar), Turkish (tr), and Russian (ru).
| Model Name | MMMB en | MMMB zh | MMMB pt | MMMB ar | MMMB tr | MMMB ru | Multilingual MMBench en | Multilingual MMBench zh | Multilingual MMBench pt | Multilingual MMBench ar | Multilingual MMBench tr | Multilingual MMBench ru | MTVQA (avg) | MTVQA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| InternVL2-1B [35] | 73.2 | 67.4 | 55.5 | 53.5 | 43.8 | 55.2 | 67.9 | 61.2 | 50.8 | 43.3 | 31.8 | 52.7 | 12.6 | |
| InternVL2.5-1B | 78.8 | 70.2 | 61.5 | 55.0 | 45.3 | 61.1 | 72.5 | 64.7 | 57.0 | 43.0 | 37.8 | 53.2 | 21.4 | |
| Qwen2-VL-2B [246] | 78.3 | 74.2 | 72.6 | 68.3 | 61.8 | 72.8 | 72.1 | 71.1 | 69.9 | 61.1 | 54.4 | 69.3 | 20.0 | |
| InternVL2-2B [35] | 79.4 | 71.6 | 54.0 | 43.5 | 46.4 | 48.1 | 73.8 | 69.6 | 51.4 | 29.8 | 31.3 | 42.3 | 10.9 | |
| InternVL2.5-2B | 81.4 | 74.4 | 58.2 | 48.3 | 46.4 | 53.2 | 76.5 | 71.6 | 55.9 | 37.3 | 33.9 | 44.8 | 21.8 | |
| InternVL2-4B [35] | 82.0 | 76.1 | 75.6 | 54.3 | 51.2 | 67.4 | 77.3 | 72.4 | 72.6 | 43.6 | 46.5 | 61.2 | 15.3 | |
| InternVL2.5-4B | 83.7 | 81.0 | 79.7 | 76.0 | 70.5 | 79.9 | 82.3 | 81.1 | 78.9 | 73.4 | 68.1 | 76.2 | 28.4 | |
| mPLUG-Owl2 [275] | 67.3 | 61.0 | 59.7 | 45.8 | 45.4 | 62.6 | 66.2 | 59.4 | 58.2 | 37.9 | 47.7 | 60.4 | – | |
| Qwen2-VL-7B [246] | 83.9 | 82.4 | 81.2 | 79.0 | 74.7 | 82.4 | 81.8 | 81.6 | 79.1 | 75.6 | 74.5 | 79.3 | 25.6 | |
| InternVL2-8B [35] | 83.4 | 81.5 | 76.1 | 66.3 | 69.2 | 75.7 | 82.9 | 81.8 | 76.0 | 60.5 | 66.0 | 74.4 | 20.9 | |
| InternVL2.5-8B | 84.3 | 83.1 | 78.6 | 69.3 | 71.5 | 79.5 | 83.8 | 83.2 | 79.4 | 64.3 | 67.8 | 77.3 | 27.6 | |
| InternVL-Chat-V1.5 [35] | 82.6 | 80.8 | 76.3 | 65.2 | 68.6 | 74.0 | 81.1 | 80.2 | 76.9 | 56.2 | 66.7 | 71.0 | 20.5 | |
| InternVL2-26B [35] | 83.8 | 81.7 | 78.0 | 68.8 | 69.3 | 76.3 | 82.7 | 81.8 | 77.8 | 61.9 | 69.6 | 74.4 | 17.7 | |
| InternVL2.5-26B | 86.2 | 83.8 | 81.6 | 73.3 | 73.7 | 82.8 | 86.1 | 85.5 | 80.7 | 67.5 | 75.0 | 79.6 | 28.5 | |
| InternVL2-40B [35] | 85.3 | 84.1 | 81.1 | 70.3 | 74.2 | 81.4 | 86.2 | 85.8 | 82.8 | 64.0 | 74.2 | 81.8 | 20.6 | |
| InternVL2.5-38B | 86.4 | 85.1 | 84.1 | 84.3 | 82.8 | 84.9 | 87.5 | 88.6 | 85.3 | 84.5 | 84.0 | 85.9 | 31.7 | |
| GPT-4V [192] | 75.0 | 74.2 | 71.5 | 73.5 | 69.0 | 73.1 | 77.6 | 74.4 | 72.5 | 72.3 | 70.5 | 74.8 | 22.0 | |
| GPT-4o [192] | – | – | – | – | – | – | – | – | – | – | – | – | 27.8 | |
| Gemini-1.0-Pro [228] | 75.0 | 71.9 | 70.6 | 69.9 | 69.6 | 72.7 | 73.6 | 72.1 | 70.3 | 61.1 | 69.8 | 70.5 | – | |
| Qwen2-VL-72B [246] | 86.8 | 85.3 | 85.2 | 84.8 | 84.2 | 85.3 | 86.9 | 87.2 | 85.8 | 83.5 | 84.4 | 85.3 | 30.9 | |
| InternVL2-Llama3-76B [35] | 85.3 | 85.1 | 82.8 | 82.8 | 83.0 | 83.7 | 87.8 | 87.3 | 85.9 | 83.1 | 85.0 | 85.7 | 22.0 | |
| InternVL2.5-78B | 86.3 | 85.6 | 85.1 | 84.8 | 83.1 | 85.4 | 90.0 | 89.7 | 87.4 | 83.3 | 84.9 | 86.3 | 31.9 |
🔼 Table 12 presents a comprehensive comparison of InternVL’s video understanding capabilities against other state-of-the-art models. It evaluates performance across six different benchmarks, each assessing various aspects of video comprehension. For four benchmarks (Video-MME, MMBench-Video, MLVU, and LongVideoBench), performance is tested using four frame settings (16, 32, 48, and 64), with the maximum result reported. The remaining two benchmarks (MVBench and CG-Bench) use fixed frame settings of 16 and 32 respectively. The table provides a detailed performance analysis across a range of models and benchmarks, allowing for a nuanced understanding of InternVL’s strengths and limitations in video understanding tasks.
read the caption
Table 12: Comparison of video understanding performance. We evaluate InternVL’s video understanding capabilities across 6 benchmarks. For Video-MME [69], MMBench-Video [65], MLVU [315], and LongVideoBench [262], we test with four different settings: 16, 32, 48, and 64 frames, and report the maximum results. For MVBench [131], we conduct testing using 16 frames. For CG-Bench [7], we use 32 frames.
| Model Name | Video-MME (wo / w sub) | MVBench | MMBench-Video (val) | MLVU (M-Avg) | LongVideoBench (val total) | CG-Bench v1.1 (long / clue acc.) |
|---|---|---|---|---|---|---|
| InternVL2-1B [35] | 42.9 / 45.4 | 57.5 | 1.14 | 51.6 | 43.3 | - |
| InternVL2.5-1B | 50.3 / 52.3 | 64.3 | 1.36 | 57.3 | 47.9 | - |
| Qwen2-VL-2B [246] | 55.6 / 60.4 | 63.2 | - | - | - | - |
| InternVL2-2B [35] | 46.2 / 49.1 | 60.2 | 1.30 | 54.3 | 46.0 | - |
| InternVL2.5-2B | 51.9 / 54.1 | 68.8 | 1.44 | 61.4 | 52.0 | - |
| InternVL2-4B [35] | 53.9 / 57.0 | 64.0 | 1.45 | 59.9 | 53.0 | - |
| InternVL2.5-4B | 62.3 / 63.6 | 71.6 | 1.73 | 68.3 | 55.2 | - |
| VideoChat2-HD [130] | 45.3 / 55.7 | 62.3 | 1.22 | 47.9 | - | - |
| MiniCPM-V-2.6 [274] | 60.9 / 63.6 | - | 1.70 | - | 54.9 | - |
| LLaVA-OneVision-7B [124] | 58.2 / - | 56.7 | - | - | - | - |
| Qwen2-VL-7B [246] | 63.3 / 69.0 | 67.0 | 1.44 | - | 55.6 | - |
| InternVL2-8B [35] | 56.3 / 59.3 | 65.8 | 1.57 | 64.0 | 54.6 | - |
| InternVL2.5-8B | 64.2 / 66.9 | 72.0 | 1.68 | 68.9 | 60.0 | - |
| InternVL2-26B [35] | 57.0 / 60.2 | 67.5 | 1.67 | 64.2 | 56.1 | - |
| InternVL2.5-26B | 66.9 / 69.2 | 75.2 | 1.86 | 72.3 | 59.9 | - |
| Oryx-1.5-32B [160] | 67.3 / 74.9 | 70.1 | 1.52 | 72.3 | - | - |
| VILA-1.5-40B [143] | 60.1 / 61.1 | - | 1.61 | 56.7 | - | - |
| InternVL2-40B [35] | 66.1 / 68.6 | 72.0 | 1.78 | 71.0 | 60.6 | - |
| InternVL2.5-38B | 70.7 / 73.1 | 74.4 | 1.82 | 75.3 | 63.3 | - |
| GPT-4V/4T [3] | 59.9 / 63.3 | 43.7 | 1.53 | 49.2 | 59.1 | - |
| GPT-4o-20240513 [192] | 71.9 / 77.2 | - | 1.63 | 64.6 | 66.7 | - |
| GPT-4o-20240806 [192] | - | - | 1.87 | - | - | 41.8 / 56.4 |
| Gemini-1.5-Pro [200] | 75.0 / 81.3 | - | 1.30 | - | 64.0 | 40.1 / 56.4 |
| VideoLLaMA2-72B [38] | 61.4 / 63.1 | 62.0 | - | - | - | - |
| LLaVA-OneVision-72B [124] | 66.2 / 69.5 | 59.4 | - | 66.4 | 61.3 | - |
| Qwen2-VL-72B [246] | 71.2 / 77.8 | 73.6 | 1.70 | - | - | 41.3 / 56.2 |
| InternVL2-Llama3-76B [35] | 64.7 / 67.8 | 69.6 | 1.71 | 69.9 | 61.1 | - |
| InternVL2.5-78B | 72.1 / 74.0 | 76.4 | 1.97 | 75.7 | 63.6 | 42.2 / 58.5 |
🔼 This table presents a comprehensive comparison of InternVL 2.5 and its predecessor, InternVL 2.0, along with several other LLMs and MLLMs, across a variety of language-centric benchmarks. The benchmarks cover a wide range of tasks, including commonsense reasoning, mathematical problem solving, coding challenges, and general knowledge tests. The results highlight the improvements in pure language capabilities achieved in InternVL 2.5 by employing a larger, higher-quality dataset during training and enhanced filtering to remove low-quality data. The table offers a detailed performance comparison, enabling a clear understanding of InternVL 2.5’s strengths and weaknesses in various aspects of language understanding.
read the caption
Table 13: Comparison of language capabilities across multiple benchmarks. These results were obtained using the OpenCompass toolkit for testing. Training InternVL 2.0 models led to a decline in pure language capabilities. InternVL 2.5 addresses this by collecting more high-quality open-source data and filtering out low-quality data, achieving better preservation of pure language performance.
| Dataset | Settings | InternLM2-1.8B-Chat | InternVL2-2B | InternLM2.5-1.8B-Chat | InternVL2.5-2B | InternLM2.5-7B-Chat | InternVL2-8B | InternVL2.5-8B | InternLM2-20B-Chat | InternVL2-26B | InternLM2.5-20B-Chat | InternVL2.5-26B |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MMLU | 5-shot | 47.3 | 46.4 | 50.5 | 52.6 | 72.8 | 73.2 | 74.6 | 66.5 | 68.2 | 73.3 | 76.6 |
| CMMLU | 5-shot | 46.1 | 47.1 | 62.7 | 57.0 | 78.2 | 79.2 | 78.7 | 64.7 | 68.1 | 79.4 | 81.9 |
| C-Eval | 5-shot | 48.6 | 48.6 | 60.4 | 56.2 | 77.9 | 80.1 | 79.7 | 61.8 | 67.7 | 80.2 | 83.8 |
| GAOKAO | 0-shot | 33.1 | 32.3 | 54.7 | 52.6 | 78.7 | 75.0 | 77.3 | 63.5 | 62.3 | 81.0 | 86.9 |
| TriviaQA | 0-shot | 37.3 | 31.5 | 32.3 | 31.2 | 64.0 | 62.0 | 63.4 | 61.8 | 61.8 | 67.3 | 69.0 |
| NaturalQuestions | 0-shot | 15.3 | 13.2 | 10.1 | 11.8 | 21.1 | 28.1 | 29.4 | 23.6 | 28.8 | 21.3 | 36.1 |
| C3 | 0-shot | 75.8 | 76.9 | 61.4 | 78.0 | 88.1 | 94.2 | 94.7 | 92.2 | 93.2 | 94.0 | 95.8 |
| RACE-High | 0-shot | 74.0 | 72.6 | 78.5 | 77.4 | 90.5 | 90.8 | 90.8 | 86.2 | 86.5 | 91.3 | 92.2 |
| WinoGrande | 0-shot | 56.5 | 58.7 | 56.9 | 59.1 | 84.9 | 85.9 | 83.5 | 76.4 | 79.9 | 86.4 | 87.9 |
| HellaSwag | 0-shot | 57.9 | 53.7 | 76.2 | 68.2 | 94.8 | 94.9 | 94.1 | 85.3 | 87.5 | 95.9 | 95.8 |
| BBH | 0-shot | 37.9 | 36.3 | 43.4 | 40.9 | 73.1 | 72.7 | 73.4 | 70.1 | 69.8 | 78.4 | 78.9 |
| GSM8K | 4-shot | 42.7 | 40.7 | 53.3 | 55.1 | 85.1 | 75.6 | 77.8 | 80.7 | 80.0 | 88.5 | 82.9 |
| MATH | 4-shot | 11.0 | 7.0 | 39.5 | 33.5 | 60.6 | 39.5 | 49.9 | 34.9 | 35.5 | 54.7 | 53.7 |
| TheoremQA | 0-shot | 13.9 | 12.3 | 11.4 | 12.0 | 23.4 | 15.6 | 23.8 | 22.1 | 15.3 | 23.9 | 15.4 |
| HumanEval | 4-shot | 34.8 | 32.3 | 41.5 | 52.4 | 74.4 | 69.5 | 75.0 | 71.3 | 67.1 | 69.5 | 68.9 |
| MBPP | 3-shot | 40.9 | 33.1 | 42.8 | 50.6 | 63.0 | 58.8 | 68.5 | 70.8 | 66.2 | 70.0 | 72.0 |
| MBPP-CN | 0-shot | 28.2 | 23.4 | 33.8 | 34.2 | 51.6 | 48.2 | 55.2 | 55.8 | 54.2 | 61.0 | 61.6 |
| Average | – | 41.3 | 39.2 | 47.6 | 48.4 | 69.5 | 67.2 | 70.0 | 64.0 | 64.2 | 71.5 | 72.9 |
| Gain | – | – | (-2.1) | – | (+0.8) | – | (-2.3) | (+0.5) | – | (+0.2) | – | (+1.4) |
🔼 Table 14 presents a comprehensive analysis of InternViT’s image classification performance across its various versions (InternViT-6B-224px, InternViT-6B-448px-V1.0, InternViT-6B-448px-V1.2, InternViT-6B-448px-V1.5, InternViT-6B-448px-V2.5). The models were trained using the ImageNet-1K dataset [56] and evaluated not only on the IN-1K validation set but also on several challenging ImageNet variants known for their difficulty: IN-ReaL [16], IN-V2 [199], IN-A [87], IN-R [84], and IN-Sketch [242]. The table reports the average classification accuracy for each InternViT version using two different probing methods: linear probing and attention pooling probing. The difference (Δ) between the accuracies of the attention pooling and linear probing methods highlights the model’s ability to learn increasingly complex, non-linear semantic representations as its architecture evolves.
read the caption
Table 14: Image classification performance across different versions of InternViT. We use IN-1K [56] for training and evaluate on the IN-1K validation set as well as multiple ImageNet variants, including IN-ReaL [16], IN-V2 [199], IN-A [87], IN-R [84], and IN-Sketch [242]. Results are reported for both linear probing and attention pooling probing methods, with average accuracy for each method. ΔΔ\Deltaroman_Δ represents the performance gap between attention pooling probing and linear probing, where a larger ΔΔ\Deltaroman_Δ suggests a shift from learning simple linear features to capturing more complex, nonlinear semantic representations.
| Model Name | res. | IN-1K | IN-ReaL | IN-V2 | IN-A | IN-R | IN-Ske | avg. | IN-1K | IN-ReaL | IN-V2 | IN-A | IN-R | IN-Ske | avg. | Δ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| InternViT-6B-224px | 224 | 88.2 | 90.4 | 79.9 | 77.5 | 89.8 | 69.1 | 82.5 | 89.2 | 91.1 | 82.3 | 84.7 | 93.1 | 72.7 | 85.5 | 3.0 |
| InternViT-6B-224px | 448 | 87.8 | 90.2 | 79.8 | 77.2 | 87.1 | 65.8 | 81.3 | 88.8 | 91.0 | 82.0 | 85.4 | 91.3 | 70.5 | 84.8 | 3.5 |
| InternViT-6B-448px-V1.0 | 448 | 87.0 | 90.0 | 78.8 | 77.2 | 85.5 | 65.1 | 80.6 | 88.7 | 91.0 | 82.0 | 88.7 | 92.8 | 72.0 | 85.9 | 5.3 |
| InternViT-6B-448px-V1.2 | 448 | 87.0 | 89.9 | 78.5 | 77.1 | 83.9 | 59.7 | 79.4 | 88.6 | 91.1 | 82.0 | 88.7 | 92.7 | 71.6 | 85.8 | 6.4 |
| InternViT-6B-448px-V1.5 | 448 | 86.5 | 89.9 | 78.1 | 69.8 | 82.9 | 60.1 | 77.9 | 88.4 | 91.2 | 81.6 | 86.0 | 92.2 | 70.9 | 85.1 | 7.2 |
| InternViT-6B-448px-V2.5 | 448 | 86.6 | 90.1 | 77.8 | 73.7 | 82.7 | 60.0 | 78.5 | 88.3 | 91.2 | 81.3 | 86.9 | 92.4 | 70.8 | 85.2 | 6.7 |
🔼 Table 15 presents a detailed comparison of semantic segmentation performance across various versions of the InternViT model. InternViT models were evaluated using two datasets, ADE20K and COCO-Stuff-164K. Three different training configurations were used: linear probing (only training a linear classifier on top of a frozen InternViT), head tuning (training only the UperNet head while keeping InternViT frozen), and full tuning (training both InternViT and the UperNet head). The table shows the mean Intersection over Union (mIoU) scores for each configuration on both datasets. The Δ₁ column represents the difference in mIoU between the head tuning and linear probing methods, while Δ₂ represents the difference in mIoU between full tuning and linear probing. Larger Δ values suggest the model’s representations are shifting from simple linear features to more complex, non-linear features, indicating increased model sophistication and ability to capture complex semantic information.
read the caption
Table 15: Semantic segmentation performance across different versions of InternViT. The models are evaluated on ADE20K [313] and COCO-Stuff-164K [18] using three configurations: linear probing, head tuning, and full tuning. The table shows the mIoU scores for each configuration and their averages. Δ1subscriptΔ1\Delta_{1}roman_Δ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT represents the gap between head tuning and linear probing, while Δ2subscriptΔ2\Delta_{2}roman_Δ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT shows the gap between full tuning and linear probing. A larger ΔΔ\Deltaroman_Δ value indicates a shift from simple linear features to more complex, nonlinear representations.
Full paper#