↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large multimodal models (LMMs) excel in general tasks but struggle with specialized domains like chart or table understanding due to their training data bias. Directly integrating expert models is also challenging because of representation gaps and imbalanced optimization.
This paper introduces Chimera, a pipeline integrating pre-trained expert models to enhance LMMs for domain-specific tasks. Chimera uses a progressive training strategy and a novel Generalist-Specialist Collaboration Masking (GSCM) mechanism to address optimization issues. The results show Chimera achieves state-of-the-art performance on various challenging benchmarks, demonstrating its effectiveness in improving LMMs’ adaptability to domain-specific tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Chimera, a novel and scalable approach to enhance the performance of large multimodal models (LMMs) on domain-specific tasks. It addresses the limitations of current generalist models by integrating domain-specific expert models, resulting in state-of-the-art performance on various challenging benchmarks. This work opens avenues for improving LMMs’ adaptability and generalizability, which is highly relevant to current AI research trends.
Visual Insights#

🔼 Figure 1 presents a performance comparison of various multi-modal models across several tasks categorized into two groups: multi-modal reasoning and visual structural extraction. For multi-modal reasoning, the models are evaluated on MathVista and MathVerse datasets, which test the ability of models to reason using both visual and textual information. The visual structural extraction tasks evaluate the models’ performance on ChartQA-SE and Table-SE datasets, focusing on their ability to extract structured information from charts and tables, respectively. The figure visually compares the performance scores achieved by different models across these four tasks, providing insights into the strengths and weaknesses of each model in handling different types of multi-modal data.
read the caption
Figure 1: Performance comparison of different models on multi-modal reasoning (MathViata, MathVerse) and visual structural extraction (ChartQA-SE, Table-SE) tasks.
| Stage 1 | General: |
|---|---|
| ShareGPT4v [10], ShareGPT4-o [10] | |
| Table: | TableX [75] |
| Chart: | ChartQA [48], PlotQA [53], ChartX [76], SimChart [74] |
| Math: | MAVIS-Caption [80] |
| Stage 2: | Language: |
| — | — |
| Kaggle-science-exam [36], MathInstruct [78], MathQA [3], SciInstruct [79], Orcamath [54] | |
| General: | ShareGPT4v [10], ShareGPT4-o [10], LLaVAR [82], AI2D (GPT4V) [28], AI2D (InternVL [12]), AI2D (Original) [25], MathVision [70], IconQA [45], MapQA [8], ScienceQA [59], ArxivQA [31], TQA [26], CLEVR-Math [19], Super-CLEVR [34], Cambrian Data Engine [66] |
| Table: | TableX [75], TabMWP [47], MMTab [83] |
| Chart: | PlotQA [53], ChartX [76], SimChart [74], Chart2Text [23], ChartQA [48], LRV Chart [41], ChartGemma [51], DVQA [21], FigureQA [22], VisText [63] |
| Math: | MAVIS-Caption [80], Geo170K [16], GeoMVerse [24], MAVIS Manual Collection [80], MAVIS Data Engine [80], Geometry3K [44], GeoQA+ [9], InterGPS [44] |
🔼 This table details the datasets used to train the Chimera-Reasoner model. The training process is divided into two stages. Stage 1 focuses on Domain-General Knowledge Alignment, where the model learns to align general knowledge with domain-specific knowledge from various datasets. Stage 2, Visual Instruction Tuning, further refines the model using instruction-following datasets from different domains to improve its performance on specialized tasks. Datasets are categorized into general, table, chart, and math domains, with each category including multiple datasets for comprehensive training.
read the caption
Table 1: Dataset used for Chimera-Reasoner. Stage 1 and Stage 2 represent Domain-General Knowledge Alignment and Visual Instruction Tuning separately.
In-depth insights#
Multimodal Reasoning#
Multimodal reasoning, as a research area, investigates how to enable machines to understand and reason using information from multiple modalities, such as text, images, audio, and video. A core challenge lies in effectively integrating and fusing information from these diverse sources, which often have different representations and structures. The paper’s focus on multimodal reasoning is particularly relevant because it directly addresses this critical challenge by introducing Chimera, a model designed to leverage domain-specific knowledge alongside generalist models. This highlights a crucial shift in multimodal reasoning research: moving beyond solely general, web-scale training data to incorporate specialized datasets and models, which improves performance on more challenging, niche tasks. This approach acknowledges that real-world scenarios often require specialized knowledge, and effectively combining these specialized capabilities with generalist models is key to building more robust and capable systems. The success of Chimera in multi-modal reasoning benchmarks underscores the importance of hybrid models that combine domain-specific expertise with the broad capabilities of generalist models, opening new avenues for multimodal reasoning research to focus on the synergistic combination of various models.
GSCM Mechanism#
The Generalist-Specialist Collaboration Masking (GSCM) mechanism is a crucial innovation in the Chimera framework, designed to address the challenge of integrating domain-specific expert models with a generalist Large Multimodal Model (LMM). The core problem is imbalanced optimization, where the well-aligned general visual encoder might overshadow the contributions of experts. GSCM mitigates this by introducing a masking process during training. A portion of the general visual tokens are randomly masked, forcing the LMM to rely more heavily on the information provided by the expert models for specific tasks. This masking strategy helps achieve better feature alignment and knowledge integration between the generalist and specialist components, ultimately improving the overall performance of the multimodal reasoning and visual content extraction tasks. The effectiveness of GSCM is demonstrated through experimental results showing state-of-the-art performance in various domain-specific benchmarks. The flexible and scalable nature of GSCM makes it adaptable to various LMMs and expert model combinations, highlighting its potential for broader applications in multimodal learning.
Progressive Training#
Progressive training, in the context of large multimodal models (LMMs), is a crucial technique for effectively integrating domain-specific expert models into a generalist model. It involves a phased approach where features from expert models are gradually incorporated into the training process. This phased integration helps mitigate the inherent challenges posed by representation gaps and imbalanced optimization between the generalist and specialist models. A key benefit is that it allows for a more stable and efficient learning process, preventing catastrophic forgetting or disruptive interference. The strategy can incorporate various masking mechanisms to strategically balance the learning contributions of general and specific features. The ultimate objective is to enhance the generalist LMM’s performance on domain-specific tasks without significantly compromising its generalization ability across broader domains. This progressive strategy proves particularly effective in multi-modal reasoning and visual content extraction tasks, where specialized domain knowledge is crucial for state-of-the-art performance.
Scalability & Low-cost#
The concept of ‘Scalability & Low-cost’ in the context of large multimodal models (LMMs) is crucial. Scalability refers to the ability of a model to handle increasingly large datasets and complex tasks without significant performance degradation. This is often achieved through architectural innovations like efficient transformers or by leveraging distributed computing resources. Low-cost relates to the computational and financial resources needed for training and deploying the model. This is particularly important for broader adoption and accessibility. A system demonstrating both scalability and low cost would ideally allow for efficient training on massive datasets, yet remain deployable on hardware with limited resources. This balance is vital for both research and real-world applications, enabling the development of more powerful LMMs without prohibitive costs or excessive computational demands. Progressive training strategies, where smaller, specialized models are integrated into a larger generalist model, represent a promising approach to achieve this balance, offering significant improvements in performance while keeping costs down.
Future Research#
Future research directions stemming from this work on improving generalist models with domain-specific experts could focus on several key areas. More sophisticated fusion methods beyond the proposed Generalist-Specialist Collaboration Masking (GSCM) should be explored to better handle representation gaps and imbalanced optimization between generalist and specialist models. Investigating the impact of different expert model architectures and training strategies would be valuable. Exploring alternative routing mechanisms to select experts could enhance efficiency and accuracy. Further analysis is needed to understand how scaling up the number of experts affects performance and computational cost. A broader evaluation across a wider range of domain-specific tasks, beyond chart, table, math, and document understanding, will help establish the robustness and generalizability of the approach. Finally, exploring the potential for applying this framework to other modalities, beyond image and text, could significantly expand its utility and applicability. Investigating theoretical bounds of the model’s performance and developing efficient inference methods are essential steps for practical deployment.
More visual insights#
More on figures

🔼 The figure illustrates the architecture of the Chimera framework, a multi-modal pipeline designed to enhance the performance of large multi-modal models (LMMs) on domain-specific tasks. It shows how Chimera integrates domain-specific expert models with a generalist LMM. The framework uses a Generalist-Specialist Collaboration Masking (GSCM) mechanism to align features between the generalist and expert models, ensuring effective integration. During inference, a router module dynamically selects the appropriate expert model based on the input’s visual content, enabling the model to handle various specialized domains (e.g., charts, tables, math) effectively.
read the caption
Figure 2: Overview of our Chimera framework. Chimera uses Generalist-Specialist Collaboration Masking to facilitate the alignment with expert models. During inference, the Router R𝑅Ritalic_R decides expert invocations based on the visual input, resulting in a versatile model that excels across multiple specialized domains and tasks.

🔼 This figure provides a detailed breakdown of the pre-training tasks used for the expert models integrated into the Chimera framework. It visually represents the different types of tasks (categorized as either low-level or high-level) along with examples of each. Low-level tasks focus on precise extraction of specific visual content, such as converting tables to LaTeX or charts to markdown. High-level tasks involve a deeper understanding of the image, including tasks like chart-type and title prediction, or mathematical captioning using contrastive learning.
read the caption
Figure 3: Pre-training tasks of expert models considered by Chimera.

🔼 This table presents a comparison of the performance of different methods on the Table-SE (Table Structural Extraction) task. Three metrics are used for comparison: TEDS (Tree-Edit Distance-based Similarity), TEDS (structure only), and Edit Distance. The TEDS metric measures the similarity between two tree structures, representing the table structures generated by each model and the ground truth. The ‘TEDS (structure only)’ metric focuses solely on the structural aspects of the tables, ignoring the content. The Edit Distance metric provides a simpler comparison of the textual representation of tables. By comparing these metrics across different methods, the table provides a detailed evaluation of the models’ ability to accurately extract and reconstruct the structure and content of tables.
read the caption
Table 7: Comparison of performance on Table-SE across different methods: TEDS, TEDS (structure only), and Edit Distance.

🔼 Table 8 presents a comparative analysis of various models’ performance on the document structure extraction (Doc-SE) task. The metrics used for comparison include Edit Distance (lower scores indicate better performance), Precision, BLEU, and METEOR (higher scores are better). Results are shown for both English and Chinese languages.
read the caption
Table 8: Comparison of performance metrics across different methods on Doc-SE. Metrics include Edit Distance (lower is better), Precision, BLEU, and METEOR (higher is better).

🔼 Figure 4 presents a comparison of the Edit Distance metric across various document categories within the Document Structural Extraction (Doc-SE) task. Lower Edit Distance indicates better performance. The figure visualizes how well the model performs on different document types, allowing for an assessment of its generalization capabilities and potential biases toward specific document structures.
read the caption
Figure 4: Comparison of Edit Distance ↓↓\downarrow↓ across different document categories on Document Structural Extraction (Doc-SE) task.

🔼 This figure showcases examples of the Table-SE task, which involves extracting tabular data from images and converting them into LaTeX format. The figure displays several visual tables alongside their corresponding LaTeX code representations, demonstrating the model’s ability to accurately transform visual tabular data into structured code.
read the caption
Figure 5: Showcase of Table-SE task.

🔼 This figure showcases examples of the Table-SE (Table Structural Extraction) task. It presents several visual tables alongside their corresponding LaTeX code, demonstrating the model’s ability to accurately extract and format table content from diverse table layouts.
read the caption
Figure 6: Showcase of Table-SE task.

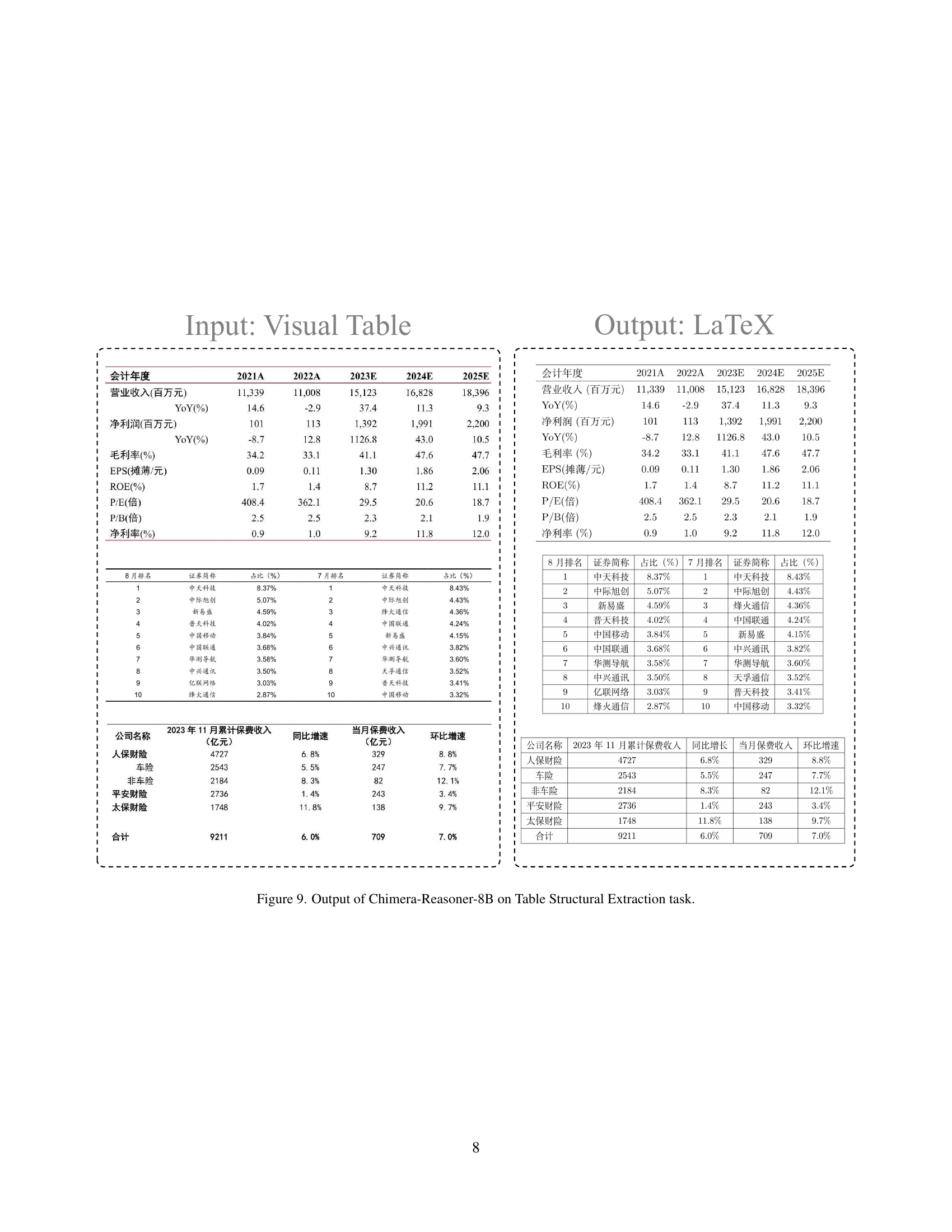
🔼 This figure showcases the output of the Chimera-Reasoner-8B model when performing table structural extraction. It demonstrates the model’s ability to accurately extract and format tabular data from a visual table, converting it into LaTeX code. The visual table shown contains financial data, likely from a balance sheet, showing various financial metrics and amounts for different years.
read the caption
Figure 7: Output of Chimera-Reasoner-8B on Table Structural Extraction task.

🔼 This figure showcases the results of Chimera-Reasoner-8B, a large multi-modal model, performing a table structural extraction task. The image shows a complex table, likely containing numerical and textual data. The output displays the model’s ability to accurately extract the structural information from the table and represent it in LaTeX format, a markup language commonly used for typesetting mathematical and scientific documents. The comparison visually demonstrates the model’s capability to understand the table’s organization and convert it into a structured, machine-readable format.
read the caption
Figure 8: Output of Chimera-Reasoner-8B on Table Structural Extraction task.
🔼 This figure showcases the results of the Chimera-Reasoner-8B model on a table structural extraction task. It displays the input visual table and the corresponding LaTeX code generated by the model. This example demonstrates the model’s ability to accurately extract and format information from complex tables, converting visual data into a structured, machine-readable format. The high level of detail presented allows assessment of the accuracy of the conversion. The model’s success on this task highlights its capability for multi-modal reasoning and data extraction.
read the caption
Figure 9: Output of Chimera-Reasoner-8B on Table Structural Extraction task.

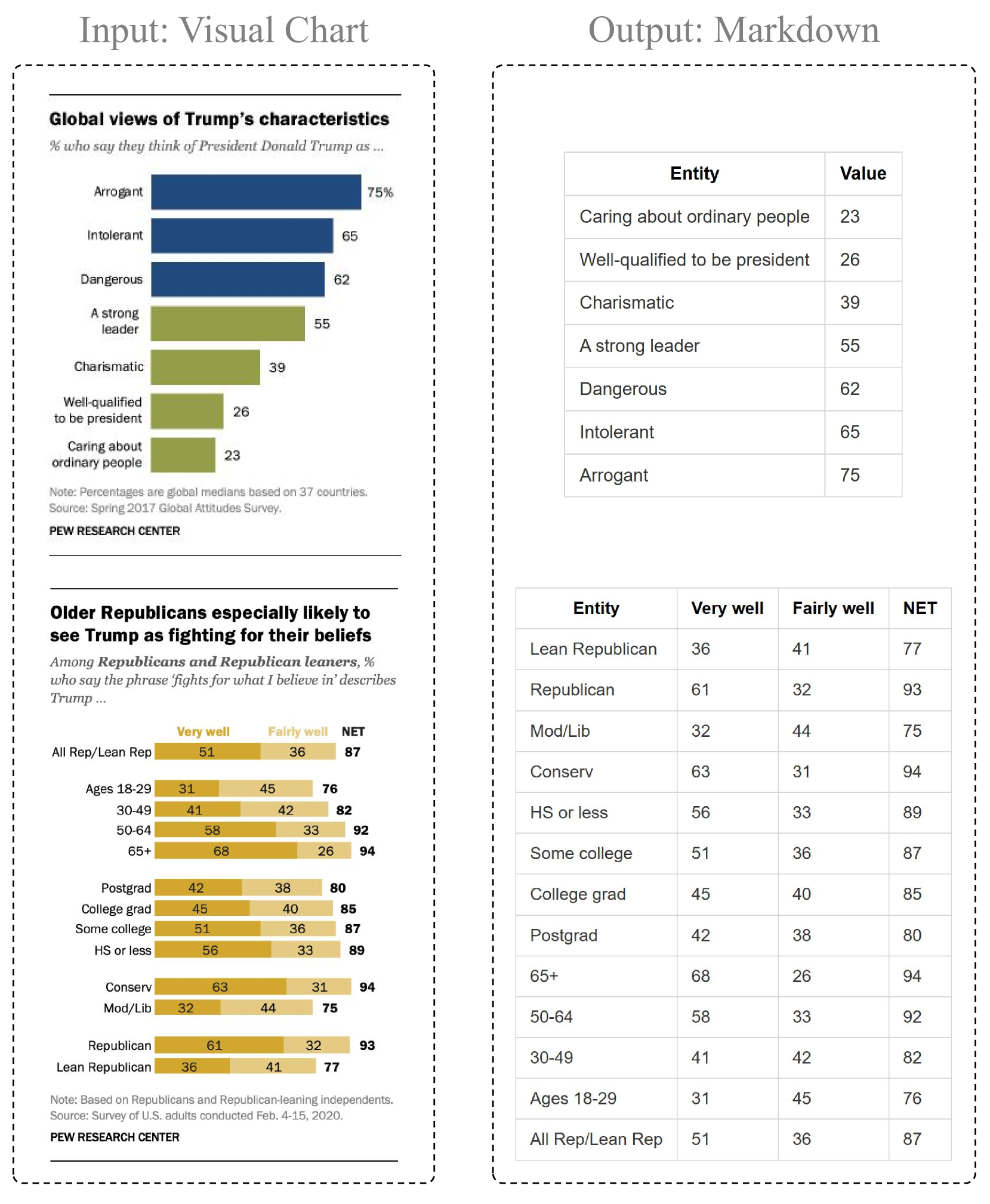
🔼 This figure showcases the results of the Chimera-Reasoner-8B model performing chart structural extraction. It visually demonstrates the model’s ability to accurately identify and extract information from various chart types (pie chart, line graph, bar chart) and output this information in a structured format (markdown). This highlights Chimera’s capability for visual content extraction, a domain where generalist models often struggle.
read the caption
Figure 10: Output of Chimera-Reasoner-8B on Chart Structural Extraction task.

🔼 This figure showcases the results of the Chimera-Reasoner-8B model on a chart structural extraction task. It visually demonstrates the model’s ability to accurately extract and interpret data from various chart types, including bar charts and line charts, converting the visual information into a structured, machine-readable format. The displayed results highlight the model’s performance on multi-modal reasoning and visual content extraction.
read the caption
Figure 11: Output of Chimera-Reasoner-8B on Chart Structural Extraction task.

🔼 This figure showcases the effectiveness of the Chimera-Reasoner-8B model in extracting structured information from various chart types. The input shows several charts, including line charts, bar charts, and pie charts, each containing different types of visual data and labels. The model’s output is a markdown representation that accurately captures the key information present in each chart, including labels, data points, and chart titles. This demonstrates the model’s ability to process and understand complex visual layouts and extract structured information effectively.
read the caption
Figure 12: Output of Chimera-Reasoner-8B on Chart Structural Extraction task.

🔼 This figure showcases the capabilities of the Chimera-Extractor-1B model in extracting structural information from a document page. It visually demonstrates the model’s ability to identify and separate key components of the document, such as text blocks, tables, and other elements, and to represent this structure in a machine-readable format (Markdown). This highlights the model’s ability to perform document understanding tasks beyond simple text extraction.
read the caption
Figure 13: Output of Chimera-Extractor-1B on Document Structural Extraction task.

🔼 This figure showcases the performance of the Chimera-Extractor-1B model on a document structural extraction task. The input is a sample document page, and the output shows the structured markdown version extracted by the model. This demonstrates the model’s ability to accurately identify and extract key elements from a document page, separating content into logical units like headings, paragraphs, and references.
read the caption
Figure 14: Output of Chimera-Extractor-1B on Document Structural Extraction task.
More on tables
| Stage | Datasets |
|---|---|
| Stage 1 | ChartQA [48], PlotQA [53], ChartX [76], SimChart [74], TableX [75] |
| Stage 2 | DocGenome [75], DocStruct4M [18], DocVQA [52] |
🔼 This table details the datasets used to train the Chimera-Extractor model. The training process is divided into two stages. Stage 1, Domain-General Knowledge Alignment, focuses on aligning the model’s understanding with general domain knowledge. Stage 2, Visual Instruction Tuning, further refines the model using instruction-following datasets. The table lists the datasets used in each stage, categorized by their contribution to model training.
read the caption
Table 2: Datasets used for Chimera-Extractor. Stage 1 represents Domain-General Knowledge Alignment, and Stage 2 represents Visual Instruction Tuning.
| Model | #Params. | ALL | FQA | GPS | MWP | TQA | VQA | ALG | ARI | GEO | LOG | NUM | SCI | STA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Close Source LMMs | ||||||||||||||
| InternVL2-Pro [12] | - | 66.8 | 70.6 | 65.4 | 76.9 | 71.5 | 48.0 | 66.5 | 62.3 | 63.6 | 27.0 | 40.3 | 65.6 | 81.1 |
| Gemini 1.5 Pro [65] | - | 63.9 | - | - | - | - | - | - | - | - | - | - | - | - |
| GPT-4o | - | 63.8 | - | - | - | - | - | - | - | - | - | - | - | - |
| Grok-1.5V | - | 52.8 | - | - | - | - | - | - | - | - | - | - | - | - |
| Claude 3 Opus [1] | - | 50.5 | - | - | - | - | - | - | - | - | - | - | - | - |
| GPT-4V (Playground) | - | 49.9 | 43.1 | 50.5 | 57.5 | 65.2 | 38.0 | 53.0 | 49.0 | 51.0 | 21.6 | 20.1 | 63.1 | 55.8 |
| Open Source LMMs | ||||||||||||||
| LLaVA-OneVision [28] | 72B | 67.5 | - | - | - | - | - | - | - | - | - | - | - | - |
| Math-LLaVA [62] | 13B | 46.6 | 37.2 | 57.7 | 56.5 | 51.3 | 33.5 | 53.0 | 40.2 | 56.5 | 16.2 | 33.3 | 49.2 | 43.9 |
| Pixtral [2] | 12B | 58.0 | - | - | - | - | - | - | - | - | - | - | - | - |
| SPHINX-MoE [38] | 8×7B | 42.7 | - | - | - | - | - | - | - | - | - | - | - | - |
| InternLM-XComposer2 [15] | 7B | 57.6 | 55.0 | 63.0 | 73.7 | 56.3 | 39.7 | 56.6 | 52.4 | 62.3 | 8.1 | 42.4 | 59.0 | 64.1 |
| LLaVA-OneVision [28] | 7B | 63.2 | - | - | - | - | - | - | - | - | - | - | - | - |
| Math-PUMA-DeepSeek-Math [84] | 7B | 44.7 | 42.8 | 39.9 | 67.7 | 42.4 | 31.3 | 39.2 | 41.9 | 41.4 | 8.1 | 36.8 | 48.4 | 52.5 |
| Qwen2-VL [71] | 2B | 43.0 | - | - | - | - | - | - | - | - | - | - | - | - |
| Qwen2-VL [71] | 7B | 58.2 | - | - | - | - | - | - | - | - | - | - | - | - |
| IntenrVL2 [12] | 2B | 48.3 | 51.3 | 45.7 | 40.9 | 50.6 | 52.5 | 43.4 | 47.3 | 42.3 | 13.5 | 28.5 | 53.3 | 56.8 |
| IntenrVL2 [12] | 4B | 57.0 | 58.0 | 58.2 | 62.4 | 57.0 | 48.6 | 55.9 | 53.8 | 55.2 | 13.5 | 30.6 | 59.0 | 65.1 |
| IntenrVL2 [12] | 8B | 61.6 | 62.5 | 64.4 | 61.3 | 64.6 | 54.7 | 63.0 | 58.9 | 61.9 | 18.9 | 34.0 | 59.0 | 70.1 |
| Chimera-Reasoner | 2B | 53.1 | 52.4 | 56.7 | 62.9 | 51.9 | 40.8 | 52.7 | 47.6 | 56.1 | 10.8 | 34.0 | 52.5 | 61.1 |
| Chimera-Reasoner | 4B | 61.3 | 58.4 | 66.8 | 72.0 | 61.4 | 48.0 | 63.3 | 54.7 | 65.7 | 24.3 | 39.6 | 60.7 | 66.4 |
| Chimera-Reasoner | 8B | 64.9 | 62.8 | 71.6 | 72.6 | 65.2 | 52.0 | 67.6 | 57.8 | 69.5 | 21.6 | 45.8 | 61.5 | 69.4 |
| Human performance | - | 60.3 | 59.7 | 48.4 | 73.0 | 63.2 | 55.9 | 50.9 | 59.2 | 51.4 | 40.7 | 53.8 | 64.9 | 63.9 |
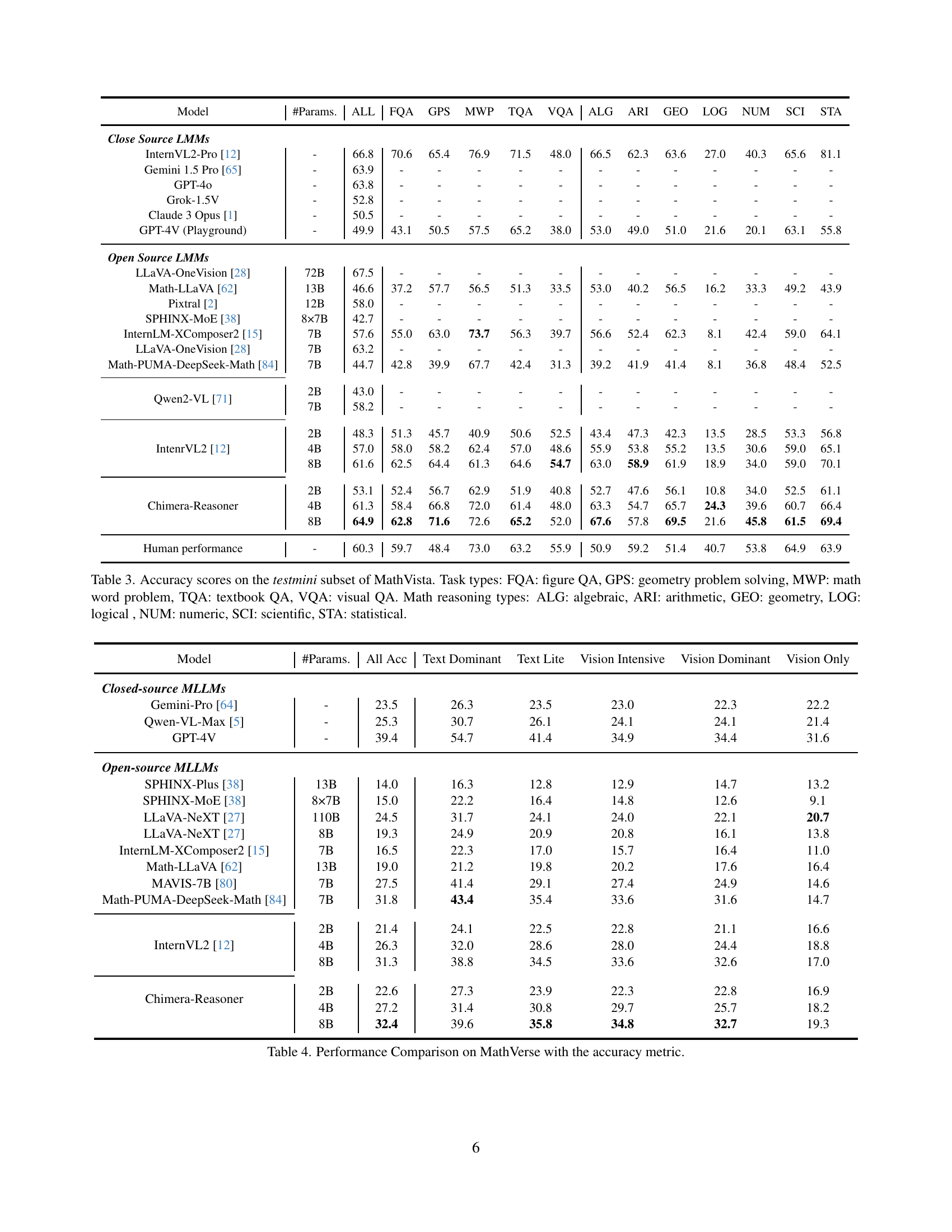
🔼 This table presents the performance of various large multi-modal models (LMMs) on the testmini subset of the MathVista benchmark. The MathVista benchmark evaluates the ability of LMMs to perform multi-modal reasoning tasks, focusing on mathematical problems. The table shows accuracy scores across different task types within MathVista: Figure QA (FQA), Geometry Problem Solving (GPS), Math Word Problem (MWP), Textbook QA (TQA), and Visual QA (VQA). Furthermore, it breaks down the mathematical reasoning types into six categories: Algebraic (ALG), Arithmetic (ARI), Geometric (GEO), Logical (LOG), Numeric (NUM), Scientific (SCI), and Statistical (STA). This allows for a detailed analysis of model performance across various problem types and reasoning skills.
read the caption
Table 3: Accuracy scores on the testmini subset of MathVista. Task types: FQA: figure QA, GPS: geometry problem solving, MWP: math word problem, TQA: textbook QA, VQA: visual QA. Math reasoning types: ALG: algebraic, ARI: arithmetic, GEO: geometry, LOG: logical , NUM: numeric, SCI: scientific, STA: statistical.
| Model | #Params. | All Acc | Text Dominant | Text Lite | Vision Intensive | Vision Dominant | Vision Only |
|---|---|---|---|---|---|---|---|
| Closed-source MLLMs | |||||||
| Gemini-Pro [64] | - | 23.5 | 26.3 | 23.5 | 23.0 | 22.3 | 22.2 |
| Qwen-VL-Max [5] | - | 25.3 | 30.7 | 26.1 | 24.1 | 24.1 | 21.4 |
| GPT-4V | - | 39.4 | 54.7 | 41.4 | 34.9 | 34.4 | 31.6 |
| Open-source MLLMs | |||||||
| SPHINX-Plus [38] | 13B | 14.0 | 16.3 | 12.8 | 12.9 | 14.7 | 13.2 |
| SPHINX-MoE [38] | 8×7B | 15.0 | 22.2 | 16.4 | 14.8 | 12.6 | 9.1 |
| LLaVA-NeXT [27] | 110B | 24.5 | 31.7 | 24.1 | 24.0 | 22.1 | 20.7 |
| LLaVA-NeXT [27] | 8B | 19.3 | 24.9 | 20.9 | 20.8 | 16.1 | 13.8 |
| InternLM-XComposer2 [15] | 7B | 16.5 | 22.3 | 17.0 | 15.7 | 16.4 | 11.0 |
| Math-LLaVA [62] | 13B | 19.0 | 21.2 | 19.8 | 20.2 | 17.6 | 16.4 |
| MAVIS-7B [80] | 7B | 27.5 | 41.4 | 29.1 | 27.4 | 24.9 | 14.6 |
| Math-PUMA-DeepSeek-Math [84] | 7B | 31.8 | 43.4 | 35.4 | 33.6 | 31.6 | 14.7 |
| InternVL2 [12] | 2B | 21.4 | 24.1 | 22.5 | 22.8 | 21.1 | 16.6 |
| 4B | 26.3 | 32.0 | 28.6 | 28.0 | 24.4 | 18.8 | |
| 8B | 31.3 | 38.8 | 34.5 | 33.6 | 32.6 | 17.0 | |
| Chimera-Reasoner | 2B | 22.6 | 27.3 | 23.9 | 22.3 | 22.8 | 16.9 |
| 4B | 27.2 | 31.4 | 30.8 | 29.7 | 25.7 | 18.2 | |
| 8B | 32.4 | 39.6 | 35.8 | 34.8 | 32.7 | 19.3 |
🔼 This table presents a comparison of different models’ performance on the MathVerse benchmark, specifically focusing on the accuracy metric. It shows how various large multimodal models (LLMs), including both closed-source and open-source options, perform on a range of tasks within the MathVerse dataset. The table allows for a comparison of performance between generalist LMMs and specialized models, and how Chimera-Reasoner compares against other approaches.
read the caption
Table 4: Performance Comparison on MathVerse with the accuracy metric.
| Model | ALL | General | Chart | Table | Math |
|---|---|---|---|---|---|
| InternVL2-2B [12] | 48.3 | 45.3 | 58.9 | 50.0 | 44.2 |
| InternVL2-4B [12] | 57.0 | 50.1 | 66.2 | 65.7 | 58.3 |
| InternVL2-8B [12] | 61.6 | 52.7 | 71.2 | 67.1 | 66.5 |
| Chimera-Reasoner-2B | 53.1 | 46.0 | 60.3 | 62.9 | 56.1 |
| Chimera-Reasoner-4B | 61.3 | 54.0 | 64.8 | 72.9 | 66.9 |
| Chimera-Reasoner-8B | 64.9 | 57.5 | 71.2 | 62.9 | 71.9 |
🔼 This table presents the accuracy results of the Chimera model on the MathVista benchmark’s testmini subset, categorized by visual content domain. The benchmark tests various aspects of multi-modal reasoning. MathVista’s ’testmini’ subset focuses on evaluating the model’s ability to answer questions related to specific visual content. For simplicity, any visual content not belonging to the chart, table, or math domains is grouped under a general category. The table displays the accuracy in percentage for different model sizes and visual content domains.
read the caption
Table 5: Accuracy scores of different visual content domain on the testmini subset of MathVista.Those do not belong to the last three domains are uniformly classified as General for simplicity.
| Task | Metric | Deplot [40] | UniChart [49] | ChartVLM [76] | GPT-4V | Qwen-VL [5] | GOT [73] | InternVL-2 [12] | Chimera-Reasoner |
|---|---|---|---|---|---|---|---|---|---|
| ChartQA-SE | AP@strict | 61.4 | 42.3 | 71.8 | 50.4 | 58.6 | 74.7 | 73.7 | 74.1 |
| AP@slight | 70.9 | 53.1 | 81.4 | 60.6 | 68.5 | 84.5 | 83.9 | 84.4 | |
| AP@high | 72.9 | 56.0 | 84.2 | 64.3 | 72.7 | 86.7 | 87.2 | 87.6 | |
| PlotQA-SE | AP@strict | 3.1 | 10.5 | 3.8 | 7.3 | 0.5 | 13.3 | 5.7 | 5.9 |
| AP@slight | 16.5 | 26.0 | 46.8 | 19.4 | 4.2 | 59.6 | 55.0 | 62.1 | |
| AP@high | 26.5 | 26.9 | 54.0 | 22.3 | 12.0 | 64.0 | 61.8 | 71.0 |
🔼 Table 6 presents a performance comparison of different models on two chart question answering benchmarks: ChartQA-SE and PlotQA-SE. The Average Precision (AP) metric is used to evaluate the performance of each model at three levels of strictness: strict, slight, and high. A higher AP score indicates better performance. The table allows for a comparison of how well each model can answer questions about charts with varying degrees of tolerance for errors in the answers.
read the caption
Table 6: Performance comparison on ChartQA-SE and PlotQA-SE benchmarks. Metrics include Average Precision (AP) at strict, slight, and high levels.
| Method | Edit Distance ↓ | TEDS ↑ | TEDS (structure only) ↑ |
|---|---|---|---|
| InternVL-2 [12] | 0.229 | 0.676 | 0.762 |
| Qwen2-VL [71] | 0.231 | 0.690 | 0.773 |
| StructEqTable [75] | 0.226 | 0.706 | 0.787 |
| GOT [73] | 0.257 | 0.745 | 0.830 |
| Chimera-Reasoner | 0.165 | 0.740 | 0.828 |
🔼 This table presents ablation study results on the MathVista benchmark’s testmini subset. It compares the performance of different model variations: a naive finetuned baseline (InternVL2-4B-NF) and Chimera models trained with various Generalist-Specialist Collaboration Masking (GSCM) ratios (Chimera-4B-R, where R represents the mask ratio). The goal is to analyze how the GSCM ratio affects the model’s performance across different visual content domains within MathVista.
read the caption
Table 9: Ablation results on different visual content domain on the testmini subset of MathVista. InternVL2-4B-NF represents naive finetune of baseline with the same settings, Chimera-4B-R𝑅Ritalic_R means Chimera model trained with mask ratio R𝑅Ritalic_R in GSCM.
| Method | Edit Distance ↓ en | Edit Distance ↓ zh | Precision ↑ en | Precision ↑ zh | BLEU ↑ en | BLEU ↑ zh | METEOR ↑ en | METEOR ↑ zh |
|---|---|---|---|---|---|---|---|---|
| InternVL [12] | 0.504 | 0.604 | 65.4 | 66.0 | 38.4 | 33.1 | 52.6 | 50.6 |
| GOT [73] | 0.355 | 0.510 | 67.9 | 71.2 | 52.5 | 34.3 | 65.3 | 53.9 |
| Chimera-Extractor | 0.304 | 0.461 | 69.6 | 66.1 | 49.8 | 40.5 | 64.8 | 56.9 |
🔼 Table 10 provides a detailed breakdown of the data used in the Document Structural Extraction (Doc-SE) task. It lists various categories of documents included in the dataset, along with the count of documents in each category. The categories are broken down by document type (like PPT2PDF, Academic Literature, etc.) and language (Simplified Chinese and English). The table also presents information on document layout (e.g. number of columns), giving a comprehensive overview of the dataset’s composition.
read the caption
Table 10: Statistical information of Doc-SE task.
| Model | Ratio | ALL | General | Chart | Table | Math |
|---|---|---|---|---|---|---|
| InternVL2-4B [12] | N/A | 57.0 | 50.1 | 66.2 | 65.7 | 58.3 |
| InternVL2-4B-NF [12] | N/A | 58.5 | 51.5 | 67.1 | 74.3 | 58.6 |
| Chimera-4B-0.0 | 0.0 | 59.4 | 50.8 | 66.2 | 67.1 | 65.5 |
| Chimera-4B | 0.3 | 61.3 | 54.0 | 64.8 | 72.9 | 66.9 |
| Chimera-4B-0.5 | 0.5 | 60.4 | 51.3 | 68.5 | 70.0 | 65.8 |
| Chimera-4B-1.0 | 1.0 | 56.2 | 51.5 | 63.5 | 72.9 | 53.6 |
🔼 Table 11 presents a detailed breakdown of the characteristics of the Table-SE (Table Structural Extraction) dataset used in the paper. It shows the distribution of various factors relevant to the types of tables included. These factors include the presence or absence of background elements, equations, specific table layouts, and the languages used in the tables.
read the caption
Table 11: Statistical information of Table-SE task.
| Document Categories | Count |
|---|---|
| PPT2PDF | 43 |
| Academic Literature | 42 |
| Book | 13 |
| Colorful Textbook | 37 |
| Magazine | 30 |
| Exam Paper | 7 |
| Note | 18 |
| Newspaper | 15 |
| Language | |
| Simplified Chinese | 128 |
| English | 77 |
| Layout | |
| 1 and More Column | 27 |
| Single Column | 91 |
| Other Layout | 43 |
| Double Column | 40 |
| Three Column | 4 |
| # Total | 205 |
🔼 This table presents a comparison of accuracy scores achieved by different models on the ’testmini’ subset of the MathVista benchmark dataset. The models compared include the baseline InternVL2-4B model, a version of InternVL2-4B that only incorporates a chart expert model (InternVL2-4B w/ Chart Expert), and the Chimera-Reasoner-4B model which integrates multiple expert models, specialized in chart, table, and math domains. Accuracy is measured across various visual content domains; those not explicitly belonging to the chart, table, and math categories are grouped under a ‘General’ category for simplicity and clarity in analysis.
read the caption
Table 12: Accuracy scores of different visual content domain on the testmini subset of MathVista. Those do not belong to the last three domains are uniformly classified as General for simplicity. InternVL2-4B w/ Chart Expert represent the case only integrating chart expert model. Chimera-Reasoner-4B integrates more expert models, including specialized models in chart, table, and math domains.
| Feature | Count |
|---|---|
| Background | |
| w/o Background | 80 |
| w/ Background | 20 |
| Equation | |
| w/o Equation | 78 |
| w/ Equation | 22 |
| Language | |
| English | 45 |
| English & Chinese Mixed | 5 |
| Chinese | 50 |
| Table Format | |
| Three-line Table | 47 |
| Full-bordered Table | 39 |
| Partial-bordered Table | 14 |
| w/o Merged Cells | 58 |
| w/ Merged Cells | 42 |
| Layout | |
| Horizontal | 97 |
| Vertical | 3 |
| # Total | 100 |
🔼 Table 13 details the configurations used for training the Chimera-Reasoner models (2B, 4B, and 8B). It shows how the vision parameters, dataset characteristics, and hyperparameters evolved across the two training stages (Domain-General Knowledge Alignment and Visual Instruction Tuning). Values separated by a ‘/’ indicate that the left-hand value applies to the 2B and 4B models, while the right-hand value applies to the 8B model.
read the caption
Table 13: Detailed configuration for each training stage of Chimera-Reasoner-2B, Chimera-Reasoner-4B and Chimera-Reasoner-8B. The table outlines the progression of vision parameters, dataset characteristics and training hyperparameters. For elements containing “/”, the left side represents configurations used by the 2B and 4B model, while the right side represents configurations used by the 8B model.
| Model | ALL | General | Chart | Table | Math |
|---|---|---|---|---|---|
| InternVL2-4B | 57.0 | 50.1 | 66.2 | 65.7 | 58.3 |
| InternVL2-4B w/ Chart Expert | 59.4 | 52.0 | 68.0 | 72.9 | 60.8 |
| Chimera-Reasoner-4B | 61.3 | 54.0 | 64.8 | 72.9 | 66.9 |
🔼 Table 14 details the configuration used for each training phase of the Chimera-Extractor-1B model. It shows how vision parameters, dataset characteristics, and training hyperparameters changed across the two-stage training process: Domain-General Knowledge Alignment and Visual Instruction Tuning. Specifically, it illustrates the changes in resolution, the number of tokens, the use of dynamic high resolution, training samples, GSCM ratio, trainable parameters, batch size, learning rate, learning rate scheduler, maximum length, weight decay, and epochs.
read the caption
Table 14: Detailed configuration for each training stage of Chimera-Extractor-1B. The table outlines the progression of vision parameters, dataset characteristics and training hyperparameters.
Full paper#