↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Mobile video editing using diffusion models offers great potential, but existing methods are computationally expensive, hindering their use on mobile devices. This limitation arises from the complex model architectures, iterative denoising processes, and the computational overhead of classifier-free guidance. The challenge lies in making these methods efficient enough for resource-constrained mobile environments.
This paper introduces MoViE, addressing these challenges by employing several optimizations. The authors optimized the model’s architecture by using a lightweight autoencoder, incorporated a multimodal guidance distillation technique to speed up classifier-free guidance, and introduced a novel adversarial distillation scheme to reduce the number of sampling steps to one. These combined optimizations enable video editing at 12 frames per second on a mobile phone, demonstrating a significant improvement in computational efficiency and on-device feasibility.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates the feasibility of high-quality video editing on mobile devices, a significant advancement in the field of mobile computing and AI. It opens up new avenues for research in efficient diffusion models and on-device AI, with implications for various applications like mobile video creation and editing tools. The work’s focus on computational efficiency makes it highly relevant to the growing demand for resource-constrained AI applications.
Visual Insights#

🔼 Figure 1 demonstrates the speed and efficiency of MoViE, a novel mobile video editing model. It showcases the model’s ability to generate 12 frames per second on a mobile phone, significantly outperforming existing methods in terms of floating-point operations (FLOPs) per frame. This highlights MoViE’s computational efficiency and suitability for on-device video editing.
read the caption
Figure 1: MoViE is a fast video editing model, capable of generating 12121212 frames per second on a mobile phone. It requires significantly fewer floating point operations (FLOPs) to edit a single video frame, making it computationally more efficient than competing methods.
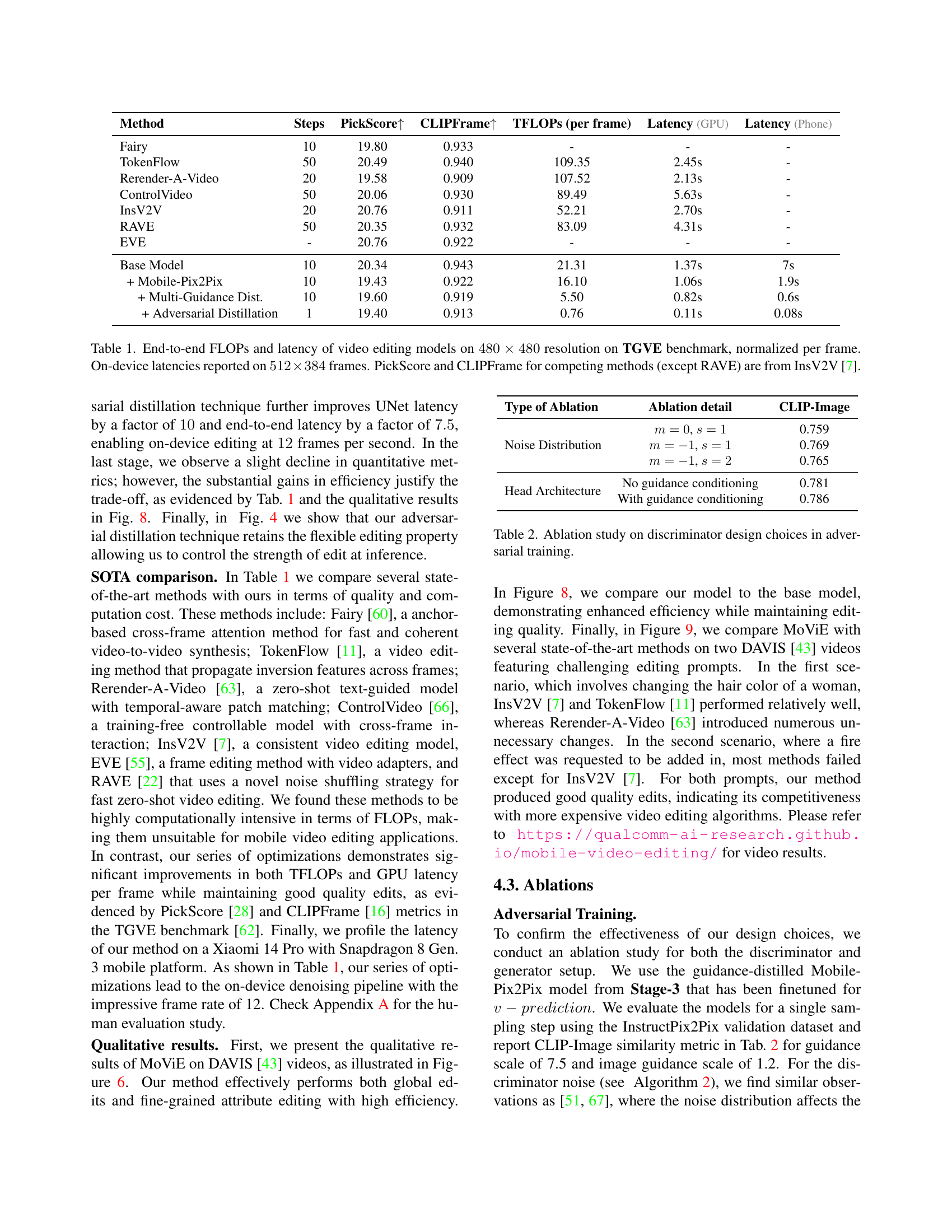
| Method | Steps | PickScore↑ | CLIPFrame↑ | TFLOPs (per frame) | Latency (GPU) | Latency (Phone) |
|---|---|---|---|---|---|---|
| Fairy | 10 | 19.80 | 0.933 | - | - | - |
| TokenFlow | 50 | 20.49 | 0.940 | 109.35 | 2.45s | - |
| Rerender-A-Video | 20 | 19.58 | 0.909 | 107.52 | 2.13s | - |
| ControlVideo | 50 | 20.06 | 0.930 | 89.49 | 5.63s | - |
| InsV2V | 20 | 20.76 | 0.911 | 52.21 | 2.70s | - |
| RAVE | 50 | 20.35 | 0.932 | 83.09 | 4.31s | - |
| EVE | - | 20.76 | 0.922 | - | - | - |
| Base Model | 10 | 20.34 | 0.943 | 21.31 | 1.37s | 7s |
| + Mobile-Pix2Pix | 10 | 19.43 | 0.922 | 16.10 | 1.06s | 1.9s |
| + Multi-Guidance Dist. | 10 | 19.60 | 0.919 | 5.50 | 0.82s | 0.6s |
| + Adversarial Distillation | 1 | 19.40 | 0.913 | 0.76 | 0.11s | 0.08s |
🔼 This table compares the computational efficiency and speed of various video editing models, including the proposed MoViE model, on the TGVE benchmark. It shows the total number of floating point operations (FLOPs) per frame, GPU processing latency, and mobile phone processing latency for each model. The resolution used for FLOP and GPU latency calculations was 480x480 pixels, while mobile phone latency was measured at 512x384 pixels. For comparison, the table also includes the PickScore and CLIPFrame quality metrics reported in the InsV2V paper [7] for several existing models. The number of diffusion steps used by each model is also listed.
read the caption
Table 1: End-to-end FLOPs and latency of video editing models on 480×480480480480\times 480480 × 480 resolution on TGVE benchmark, normalized per frame. On-device latencies reported on 512×384512384512\times 384512 × 384 frames. PickScore and CLIPFrame for competing methods (except RAVE) are from InsV2V [7].
In-depth insights#
Mobile Diffusion#
The concept of “Mobile Diffusion” in the context of video editing represents a significant advancement. It tackles the challenge of computationally expensive diffusion models by optimizing them for mobile devices. This involves several key strategies: architectual optimizations of the underlying neural network to reduce computational cost; distillation techniques to compress the model’s knowledge into a smaller, faster version; and reducing the number of sampling steps required for generating edited video frames. The resulting model achieves real-time or near real-time video editing capabilities on mobile hardware, which is a major leap toward making sophisticated AI-powered video editing accessible to a broader audience. This advancement is crucial for democratizing access to high-quality video editing, particularly in scenarios with limited computational resources or power constraints. The emphasis on speed and efficiency does not come at the expense of quality; the paper demonstrates high-quality results comparable to those of larger models running on powerful hardware. Furthermore, the successful implementation on mobile phones signifies a potential breakthrough in on-device AI applications and paves the way for more computationally intensive tasks to be performed effectively on resource-constrained devices.
Multimodal Distillation#
Multimodal distillation, in the context of diffusion models for video editing, presents a significant advancement by tackling the computational bottleneck of classifier-free guidance. Instead of multiple forward passes for each diffusion step (one for each modality and one unconditional), multimodal distillation cleverly incorporates guidance scales directly into the model’s architecture. This allows the network to simultaneously consider image and text instructions within a single forward pass, dramatically reducing inference time and computational cost. The core innovation lies in efficiently distilling the knowledge embedded within multiple guidance scales into a single, unified representation, improving both speed and controllability. This technique is crucial for deploying computationally expensive video editing models on resource-constrained mobile devices, enabling real-time or near real-time performance where previously infeasible. The effectiveness of multimodal distillation highlights the potential of knowledge distillation in making sophisticated generative models more accessible and practical across various hardware platforms.
Adversarial Training#
Adversarial training, in the context of generative models like diffusion models, is a powerful technique used to improve the model’s robustness and quality. It works by pitting a generative model (the student) against a discriminative model (the discriminator). The student attempts to generate outputs that fool the discriminator into believing they are real data, while the discriminator strives to distinguish between real and generated data. This creates a competitive environment, forcing the generator to produce increasingly realistic and high-quality outputs. A key advantage is its ability to enhance generalization; by training the model on adversarial examples – inputs designed to confuse the model – it learns to be more robust to unseen data and less susceptible to noise or perturbations. However, a major challenge is the computational cost. Adversarial training often requires significantly more computational resources than standard training. Moreover, finding the right balance between quality and efficiency is crucial. An overly aggressive adversarial training process can lead to overfitting or decreased image quality. Successfully implementing adversarial training often requires careful tuning of hyperparameters, careful selection of the discriminator architecture, and a well-defined training strategy to maintain both efficiency and performance.
On-Device Efficiency#
On-device efficiency in video editing is a significant challenge due to the high computational demands of diffusion models. The paper tackles this by introducing a series of optimizations to reduce the computational cost and improve the speed of the video editing process. These optimizations include using a lightweight autoencoder, and classifier-free guidance distillation to speed up the process significantly. A key innovation is their novel adversarial distillation scheme to reduce sampling steps from ten to one while preserving quality and controllability. The results demonstrate a remarkable improvement in on-device performance, achieving 12 frames per second on a mobile phone. This is a substantial achievement, moving towards real-time video editing on mobile devices, and highlighting the significant potential for diffusion-based methods in practical, resource-constrained settings.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the autoencoder is crucial; a more lightweight model would further accelerate the process. Investigating alternative diffusion model architectures optimized for mobile devices, potentially exploring less computationally expensive alternatives to UNets, warrants attention. Expanding the range of editing capabilities by incorporating more sophisticated editing functionalities, such as object manipulation or complex temporal effects, while preserving efficiency, is another significant area. Addressing the limitations in handling long videos remains important. The current approach’s linear scaling with video length could be improved for better efficiency. Enhancing the robustness and generalization of the model across diverse video types and quality levels would be valuable, as would exploration of different training strategies to further optimize model performance and speed on mobile platforms. Finally, research focusing on reducing the memory footprint of the entire pipeline would enable editing of higher-resolution and longer videos on resource-constrained devices.
More visual insights#
More on figures

🔼 Figure 2 illustrates the computational efficiency improvement achieved through multimodal guidance distillation. The standard classifier-free guidance pipeline (left) uses two input conditionings (image and text), requiring three inference runs per diffusion step due to separate calculations for text-only, image-only, and combined image and text conditionings. In contrast, the distilled pipeline (right) integrates guidance scales (sI and sT) directly into the UNet, thereby requiring only one inference run per diffusion step.
read the caption
Figure 2: Multimodal Guidance Distillation Overview: Standard classifier-free guidance inference pipeline (left) with two input conditionings (image and text) requires three inference runs per diffusion step. Our distilled pipeline (right) incorporates guidance scales sIsubscript𝑠𝐼s_{I}italic_s start_POSTSUBSCRIPT italic_I end_POSTSUBSCRIPT and sTsubscript𝑠𝑇s_{T}italic_s start_POSTSUBSCRIPT italic_T end_POSTSUBSCRIPT into UNet and only performs one inference run.

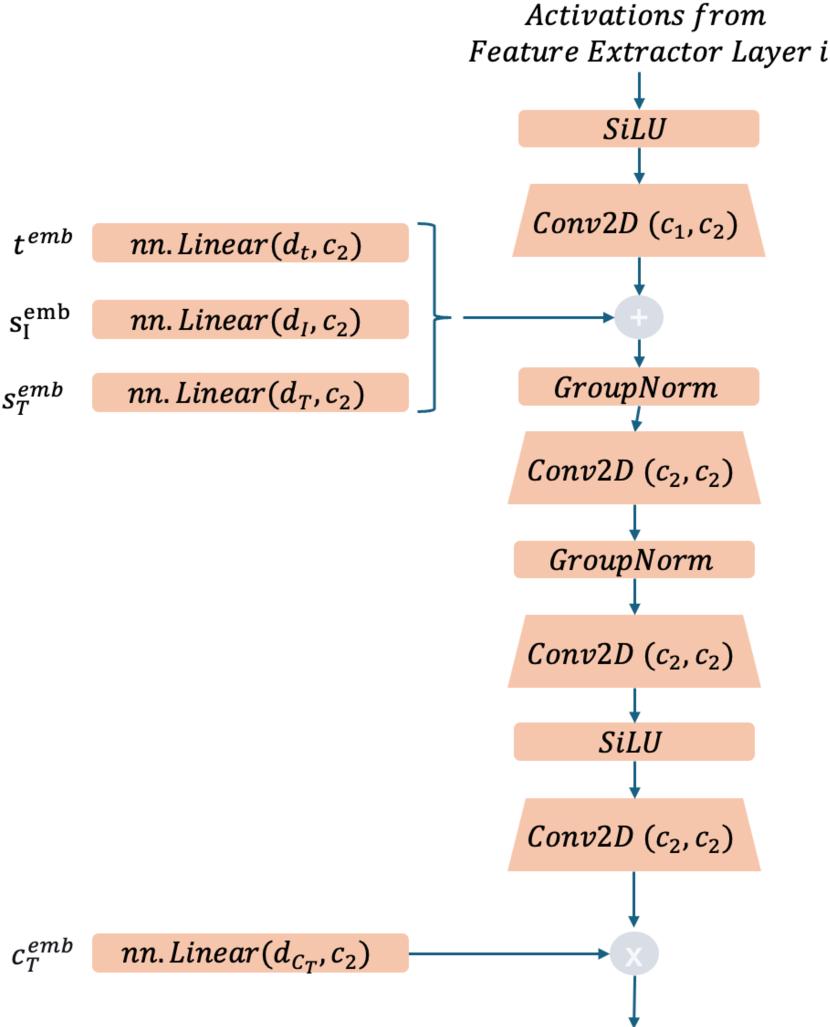
🔼 This figure illustrates the adversarial distillation process used to train a single-step video editing model. A multi-step teacher model is used to generate a sequence of increasingly less noisy video frames (denoising process). At each step, synthetic noisy frames are created and fed to the student model along with guidance signals (controlling image and text edits). The discriminator distinguishes between real (from the teacher) and synthetic (from the student) frames, training the student to generate realistic edits. Importantly, guidance scales (controlling the strength of image and text guidance) are preserved in this process, avoiding loss of control over editing strength that is seen in other adversarial distillation methods.
read the caption
Figure 3: Adversarial Distillation: We distill a multi-step teacher into a single step student using adversarial losses. Unlike existing adversarial distillation approaches [51, 67] that forego guidance flexibility for faster sampling, we preserve guidance strength property during adversarial training by providing the synthetic latent xtsubscript𝑥𝑡x_{t}italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT from teacher’s denoising process and conditioning the student on the corresponding guidance scales.

🔼 This figure showcases the results of MoViE, a mobile video editing model, demonstrating its ability to control the intensity of edits during inference. Three different text guidance scales (4.0, 8.0, and 12.0) are tested in conjunction with an image guidance scale of 1.75. Higher numbers indicate stronger adherence to the edit instructions. The example uses the prompt ‘In Van Gogh Style’ to transform a portrait image, illustrating how MoViE can apply stylistic edits with varying degrees of intensity based on adjustable parameters.
read the caption
Figure 4: MoViE at text guidance [4.0,8.0,12.0]4.08.012.0[4.0,8.0,12.0][ 4.0 , 8.0 , 12.0 ] and image guidance [1.25,1.75]1.251.75[1.25,1.75][ 1.25 , 1.75 ]. Our adversarial training maintains guidance scales, allowing us to control edit strength during inference. (Prompt: In Van Gogh Style)

🔼 Figure 5 presents a comparison of CLIP image and text similarity metrics across four different models: InstructPix2Pix, Mobile-Pix2Pix (the base model with architectural optimizations), Mobile-Pix2Pix with Multi-modal Guidance (MMG), and MoViE (the final model incorporating all optimizations). The x-axis represents the computational cost (end-to-end TFLOPs per frame), while the y-axis shows the CLIP similarity scores. The plot demonstrates that the proposed optimizations in Mobile-Pix2Pix, MMG, and MoViE significantly reduce computational cost without a substantial decrease in image quality, as indicated by the similarity scores remaining relatively high. MoViE achieves the best balance of high image quality and very low computational cost.
read the caption
Figure 5: CLIP metrics for InstructPix2Pix, Mobile-Pix2pix, Multi-modal Guidance (MMG) Mobile-Pix2pix and MoViE. As shown in the graphs, proposed optimizations improve the efficiency greatly with minimum quality drop.

🔼 Figure 6 showcases the qualitative results obtained using the MoViE model on the DAVIS dataset. The images demonstrate the model’s capability to perform both extensive global edits (e.g., transforming the entire scene) and subtle attribute edits (e.g., altering specific features of an object). A key aspect highlighted is that MoViE achieves these editing results with minimal computational resources, unlike many other comparable video editing models. For a comprehensive visualization of the edits, including video demonstrations, the reader is directed to the Appendix.
read the caption
Figure 6: Qualitative results of MoViE on DAVIS. Our method can handle complex global edits as well as perform more nuanced attribute editing while requiring very few computational resources. Please refer to the Appendix for video results.

🔼 This figure displays the impact of utilizing different autoencoder configurations on the performance of the video editing model. Specifically, it compares the standard Variational Autoencoder (VAE) against the Tiny Autoencoder for Stable Diffusion (TAESD). The results indicate that incorporating TAESD leads to a substantial reduction in FLOPs (floating point operations), representing a significant improvement in computational efficiency, with minimal negative impact on the overall editing performance as measured by CLIP (Contrastive Language–Image Pre-training) metrics.
read the caption
Figure 7: CLIP metrics for different autoencoder configurations. A substational FLOPs reduction can be achieved by incorporating TAESD, with minimal drop in editing performance.

🔼 This figure shows a qualitative comparison between the results of the proposed MoViE model and its base model. The images demonstrate that MoViE achieves comparable or better results in terms of visual quality for both style transfer and attribute editing tasks while significantly improving efficiency. For a detailed video comparison, please refer to the Appendix of the paper.
read the caption
Figure 8: Qualitative comparison of our method to the base model. The efficiency is greatly improved whereas quality is not compromised both for style transfer and attribute edits. Please refer to the Appendix for video results.

🔼 This figure presents a qualitative comparison between MoViE and other state-of-the-art video editing algorithms. Two challenging editing scenarios are used to evaluate the algorithms. The results showcase that MoViE achieves high-quality edits while significantly outperforming other methods in terms of computational efficiency. For detailed video results, the reader is referred to the Appendix.
read the caption
Figure 9: Qualitative comparison of our method MoViE to other SOTA video editing algorithms. We evaluate on two challenging editing scenarios. MoViE produces good quality edits yet far outperforms other competing methods in terms of efficiency. Please refer to the Appendix for video results.
🔼 This figure presents the results of a human evaluation comparing the video editing quality of MoViE against three state-of-the-art methods: TokenFlow, InsV2V, and Rerender-A-Video. The evaluation involved participants comparing video pairs, choosing which video was better or if both were equal. The results visually show the percentage of times MoViE was rated as better, equal or worse than each comparison method. This provides a qualitative measure of MoViE’s performance relative to other advanced video editing techniques.
read the caption
Figure 10: Human Evaluation results comparing MoViE to TokenFlow[11], InsV2V[7], and Rerender-A-Video[63].
Full paper#