↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) struggle with data inefficiency and a lack of synergy between visual understanding and generation. Existing methods require massive datasets for image-text alignment, hindering efficiency and broader application. Furthermore, they often fail to fully leverage the potential for synergistic enhancement between the two key capabilities.
ILLUME is proposed to address these issues. It employs a novel semantic vision tokenizer and a progressive multi-stage training procedure to significantly reduce the dataset size (15M points). A self-enhancing multimodal alignment scheme is introduced to supervise the model’s self-assessment of consistency between text and self-generated images. Through extensive experiments, ILLUME achieves competitive or superior performance compared to existing unified MLLMs and specialized models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal learning and large language models because it introduces ILLUME, a highly efficient and effective unified multimodal large language model. ILLUME addresses the challenges of data inefficiency and limited synergy between understanding and generation capabilities. The research opens new avenues for developing more efficient and versatile MLLMs, impacting various applications and further prompting research on data-efficient training and self-enhanced learning.
Visual Insights#

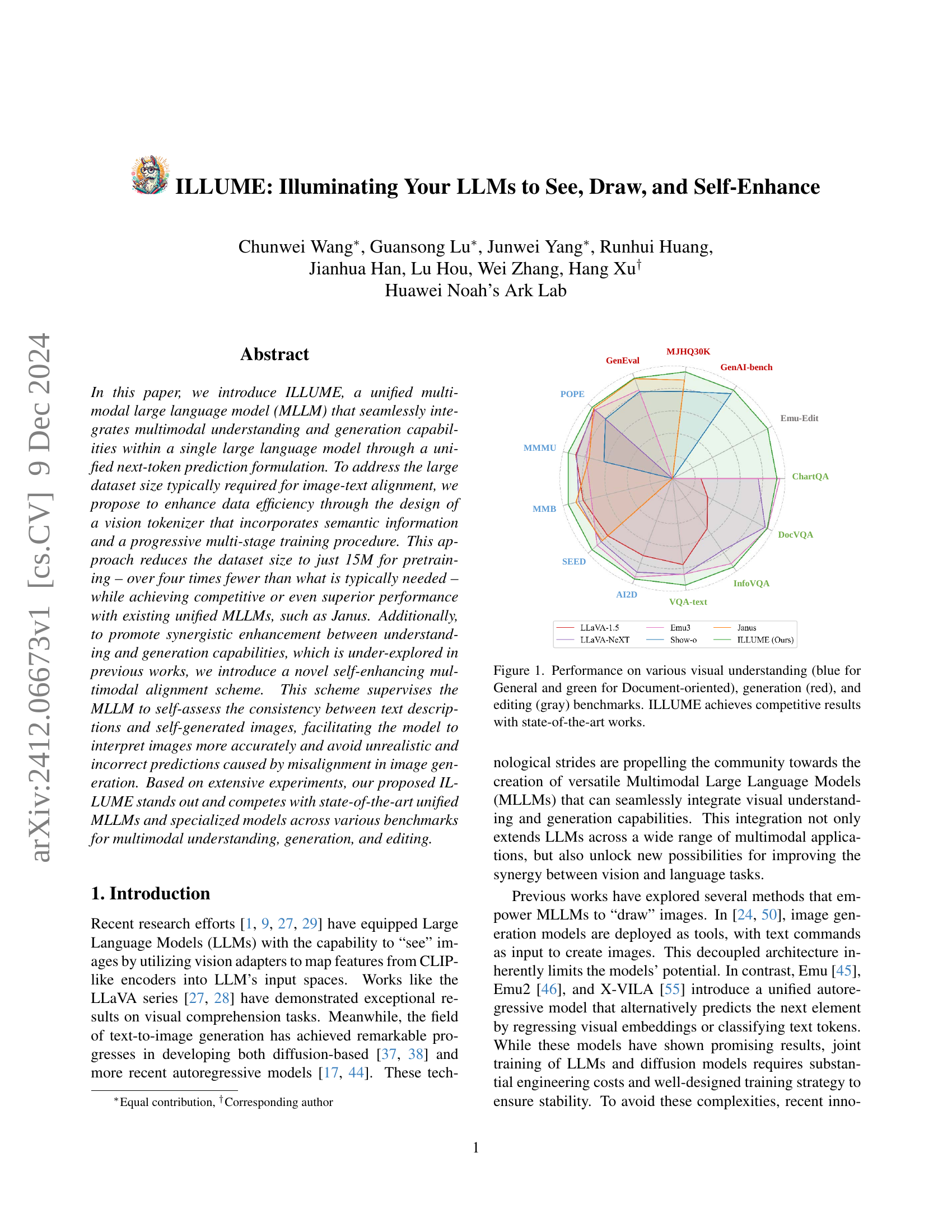
🔼 This figure presents a radar chart comparing the performance of ILLUME against other state-of-the-art models across various benchmark datasets for visual understanding, image generation, and image editing tasks. The blue sections represent the visual understanding benchmarks; specifically, blue denotes general visual understanding tasks, and green indicates document-oriented visual understanding benchmarks. Red sections depict results for image generation tasks, while gray represents image editing tasks. The chart visually demonstrates that ILLUME achieves competitive performance compared to the other models in all three categories.
read the caption
Figure 1: Performance on various visual understanding (blue for General and green for Document-oriented), generation (red), and editing (gray) benchmarks. ILLUME achieves competitive results with state-of-the-art works.
| Method | LLM | Num. of image-text pairs | Num. of interleaved data |
|---|---|---|---|
| Chameleon [47] | 7B from scratch | 1.4B | 400B tokens |
| LWM [30] | LLaMA-2-7B | 1B | - |
| Unified IO 2 [33] | 6.8B from scratch | 970M | 157M |
| SEED-LLaMA [15] | Vicuna-7B | 600M | 150M |
| AnyGPT [59] | LLaMA-2 7B | 300M | 7.3M |
| Janus [51] | DeepSeek-LLM-1.3B | 65M | - |
| ILLUME (Ours) | Vicuna-7B | 15M | - |
🔼 This table compares the amount of image-text data used for pretraining various multimodal large language models (MLLMs) that utilize a next-token prediction approach. It highlights the data efficiency of the proposed ILLUME model. ILLUME requires only 15 million image-text pairs for pretraining, significantly less than other models like Janus (which used 60 million pairs). Despite using a much smaller dataset, ILLUME achieves comparable or better performance.
read the caption
Table 1: Statistics on the data volumes required for image-text alignment in previous next-token prediction-based works. Notably, ILLUME utilizes only 15M image-text pairs, which is 4 times fewer than Janus, yet achieves superior performance.
In-depth insights#
Efficient MLLM Training#
Efficient training of large multimodal language models (MLLMs) is crucial for their widespread adoption. Data efficiency is paramount, as MLLMs typically require massive datasets for training. This paper addresses this by introducing a novel vision tokenizer that incorporates semantic information, drastically reducing the dataset size needed for effective pre-training. Progressive multi-stage training further enhances efficiency by breaking down the training process into manageable stages. Each stage targets specific aspects of MLLM development—initializing visual embeddings, aligning image-text data, and finally conducting supervised fine-tuning. This approach significantly reduces the computational cost and time associated with training MLLMs while achieving state-of-the-art performance. The use of a semantic vision tokenizer and the multi-stage approach showcase a thoughtful strategy to improve efficiency. Furthermore, the self-enhancing multimodal alignment scheme promotes synergy between understanding and generation capabilities, further optimizing the model’s overall performance and potentially reducing overfitting.
Semantic Vision Tokens#
The concept of “Semantic Vision Tokens” represents a significant advancement in multimodal learning. Instead of relying on traditional visual tokenizers that focus solely on low-level image reconstruction, semantic tokenizers aim to capture the high-level semantic meaning of images. This is achieved by quantizing images into discrete tokens within a semantic feature space, moving away from pixel-level representations to a more abstract, concept-based encoding. This approach offers enhanced data efficiency by reducing the need for massive datasets for image-text alignment, leading to models that can learn from comparatively smaller training sets. The resulting tokens are more aligned with the language model’s input, improving communication and synergy between the visual and textual modalities. The ability to generate these tokens efficiently allows for the creation of unified multimodal large language models that can smoothly integrate visual understanding and generation, thereby unlocking exciting possibilities for applications requiring seamless interaction between vision and language.
Self-Enhancement Scheme#
The proposed self-enhancement scheme is a crucial aspect of the ILLUME model, designed to improve the synergy between the model’s visual understanding and generation capabilities. Instead of treating these as separate tasks, the scheme introduces a self-assessment mechanism. The model first generates images based on textual descriptions. Then, it evaluates the consistency between its generated images and the original text descriptions using a detailed assessment process, focusing on key aspects like object presence, color accuracy, spatial relations, and overall consistency. This assessment provides valuable feedback to the model, allowing it to identify and rectify discrepancies between its visual outputs and the expected results. The iterative self-assessment process is a form of self-supervised learning, enabling the model to learn from its mistakes and refine its understanding of visual concepts. This approach significantly boosts the accuracy and reliability of the image generation and visual comprehension tasks, making the overall model more robust and efficient. This process helps ILLUME to improve its ability to produce more accurate and consistent outputs by leveraging its own mistakes as a training signal. The self-enhancement scheme is thus a powerful technique for improving the performance of unified multimodal language models.
Multimodal Benchmarks#
Multimodal benchmarks are crucial for evaluating the capabilities of multimodal large language models (MLLMs). They must assess a range of skills, including image understanding (e.g., visual question answering, object detection), image generation (fidelity, diversity, adherence to prompts), and mixed-modal generation (e.g., image editing, style transfer). A good benchmark suite should include diverse data types (images of varying complexity, different chart types, varying text styles) to avoid bias towards specific datasets and ensure generalizable performance. Metrics need to be carefully chosen, balancing objective (e.g., FID, BLEU scores) and subjective (human evaluation) assessments to fully capture the model’s strengths and weaknesses. Furthermore, benchmarks should be designed to evaluate not only accuracy but also efficiency and robustness, reflecting real-world application requirements. Finally, the creation and maintenance of such benchmarks should be an ongoing collaborative effort, with continuous updates and expansion to reflect the rapidly evolving MLLM field and new tasks.
Future Research#
Future research directions stemming from the ILLUME paper could fruitfully explore several avenues. Improving the efficiency and scalability of the model is crucial, potentially through more advanced quantization techniques or architectural optimizations. The self-enhancing multimodal alignment scheme shows promise, but further investigation into its effectiveness and applicability across diverse tasks is needed. Extending ILLUME’s capabilities to handle additional modalities (3D data, video, audio) would significantly broaden its scope. Developing more robust methods for handling complex or ambiguous instructions would enhance the model’s practical value. Finally, a thorough examination of ILLUME’s biases and limitations, along with methods for mitigating them, will be vital for ensuring responsible and ethical applications. Addressing these areas would contribute to the evolution of robust, efficient, and ethical multimodal large language models.
More visual insights#
More on figures

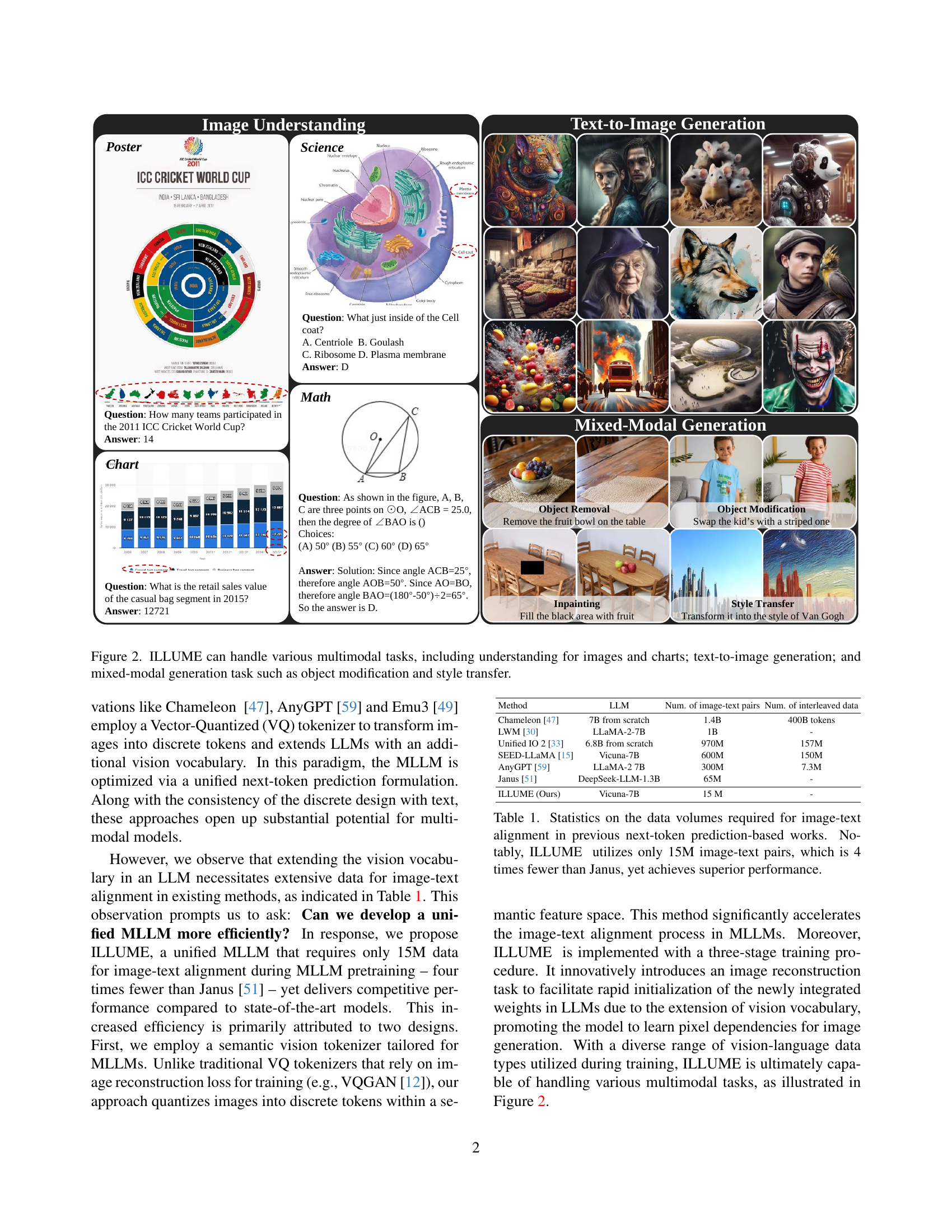
🔼 Figure 2 showcases ILLUME’s capabilities across diverse multimodal tasks. The top row demonstrates image understanding, highlighting ILLUME’s ability to correctly answer questions about diverse image types, including diagrams, charts, and photographs. The middle row exemplifies text-to-image generation; given a textual prompt, ILLUME generates a corresponding image. The bottom row displays mixed-modal generation capabilities, specifically showcasing object removal, modification, inpainting, and style transfer. These examples illustrate ILLUME’s proficiency in understanding and generating various multimodal data.
read the caption
Figure 2: ILLUME can handle various multimodal tasks, including understanding for images and charts; text-to-image generation; and mixed-modal generation task such as object modification and style transfer.

🔼 ILLUME’s architecture is shown in Figure 3, with (a) illustrating how the LLM is enhanced to process image features via a vision adapter and additional vision vocabulary for image generation. Discrete vision tokens are created to represent the images. Part (b) details the vision tokenizer which uses a pre-trained encoder to extract semantic image features. A quantization process, guided by feature reconstruction loss, converts these features into discrete tokens. Finally, a Stable Diffusion model reconstructs the original image from these tokens.
read the caption
Figure 3: Overall architecture of ILLUME. (a) We enhance LLMs with the capability to “see” images by employing a vision adapter that maps features from a vision encoder into LLM’s input spaces. To expand the model’s abilities to generate images, the LLM is extended with an additional vision vocabulary to produce discrete vision tokens. (b) In the vision tokenizer, we utilize a pretrained vision encoder to extract semantic features and supervise quantization process through feature reconstruction loss. The reconstructed features are then processed by a Stable Diffusion model to recover the original images.

🔼 This figure illustrates the three-stage training process for the ILLUME model. Stage 1 focuses on initializing visual embeddings using a smaller dataset, primarily for image-to-text alignment. Stage 2 refines the model’s understanding and generation capabilities through text-to-image alignment using a larger dataset. Stage 3 involves fine-tuning the model on various multimodal tasks for improved accuracy and versatility using a diverse set of training data. The figure also shows the data composition for each stage, highlighting the different data types used (e.g., image-to-text, text-to-image, mixed-modal generation). This visualization helps to understand how the ILLUME model is trained progressively using different data and tasks to achieve efficient visual understanding and generation.
read the caption
Figure 4: Overview of the three-stage training procedure and its corresponding data composition of different stages in MLLM training.

🔼 This figure illustrates the self-enhancing multimodal alignment scheme, a three-step process designed to improve the model’s ability to generate images that accurately reflect the provided text descriptions. The first step involves the model generating its own image-text pairs from the training data (corpus self-generation). In the second step, the model assesses these generated pairs to identify inconsistencies between the image and text description using criteria such as object presence, color, counting, and spatial relations (assessment generation). Finally, supervised fine-tuning (SFT) leverages the assessment results from step two to train the model, improving its alignment and generating more accurate images that match the descriptions (SFT for multimodal alignment). This iterative process allows the model to learn from its own mistakes and enhance its understanding and consistency in image generation.
read the caption
Figure 5: Procedure of self-enhancing multimodal alignment scheme, which contains three steps: corpus self-generation, assessment generation and SFT for multimodal alignment. This scheme supervises the MLLM to self-assess the consistency between text descriptions and self-generated images, enabling the model to more accurately interpret images and avoid potential mistakes in image generation.

🔼 This figure compares the performance of two different types of vision tokenizers used in training a multimodal large language model (MLLM). The first tokenizer, a reconstruction tokenizer, is trained using image reconstruction loss, focusing on accurately recreating the input images. The second, a semantic tokenizer, is trained with a feature reconstruction loss, prioritizing the preservation of semantic information within the images. The results show that the semantic tokenizer converges much faster during MLLM pretraining, indicating that encoding semantic meaning rather than just pixel-level detail is significantly more efficient for the task.
read the caption
Figure 6: Comparison of different tokenizers for MLLM training. We compare two types of tokenizers: 1) Reconstruction tokenizer: supervised by image reconstruction loss. 2) Semantic tokenizer: supervised by feature reconstruction loss. The results manifest that vision tokenizer with semantics significantly accelerates the convergence of MLLM pretraining.

🔼 This figure shows how different hyperparameter choices in the inference stage affect the quality of generated images. Specifically, it illustrates the impact of varying temperature, top-k sampling, and the classifier-free guidance scale on image generation quality. Different settings are shown to achieve different levels of detail and visual fidelity in the output images.
read the caption
Figure A: Comparison of different hyper-parameters in inference.

🔼 Figure B presents more qualitative results illustrating ILLUME’s performance on various image understanding tasks. Several examples are shown, each demonstrating ILLUME’s ability to understand and extract information from diverse image types, including charts, graphs, diagrams, infographics, and photographs. The areas of the images directly relevant to the question and answer pairs are highlighted with red ellipses, providing clear visual connections between the input image and the extracted information.
read the caption
Figure B: More qualitative results on understanding tasks. Regions that related to the QAs are marked with red ellipses.

🔼 This figure displays several example images generated by ILLUME, showcasing its capabilities in text-to-image generation. Each image is accompanied by a short text description specifying the prompt used to generate the image. The variety of styles, objects, and levels of detail illustrate the model’s versatility and ability to understand and respond to a wide range of creative instructions.
read the caption
Figure C: More qualitative results on text-to-image generation tasks.

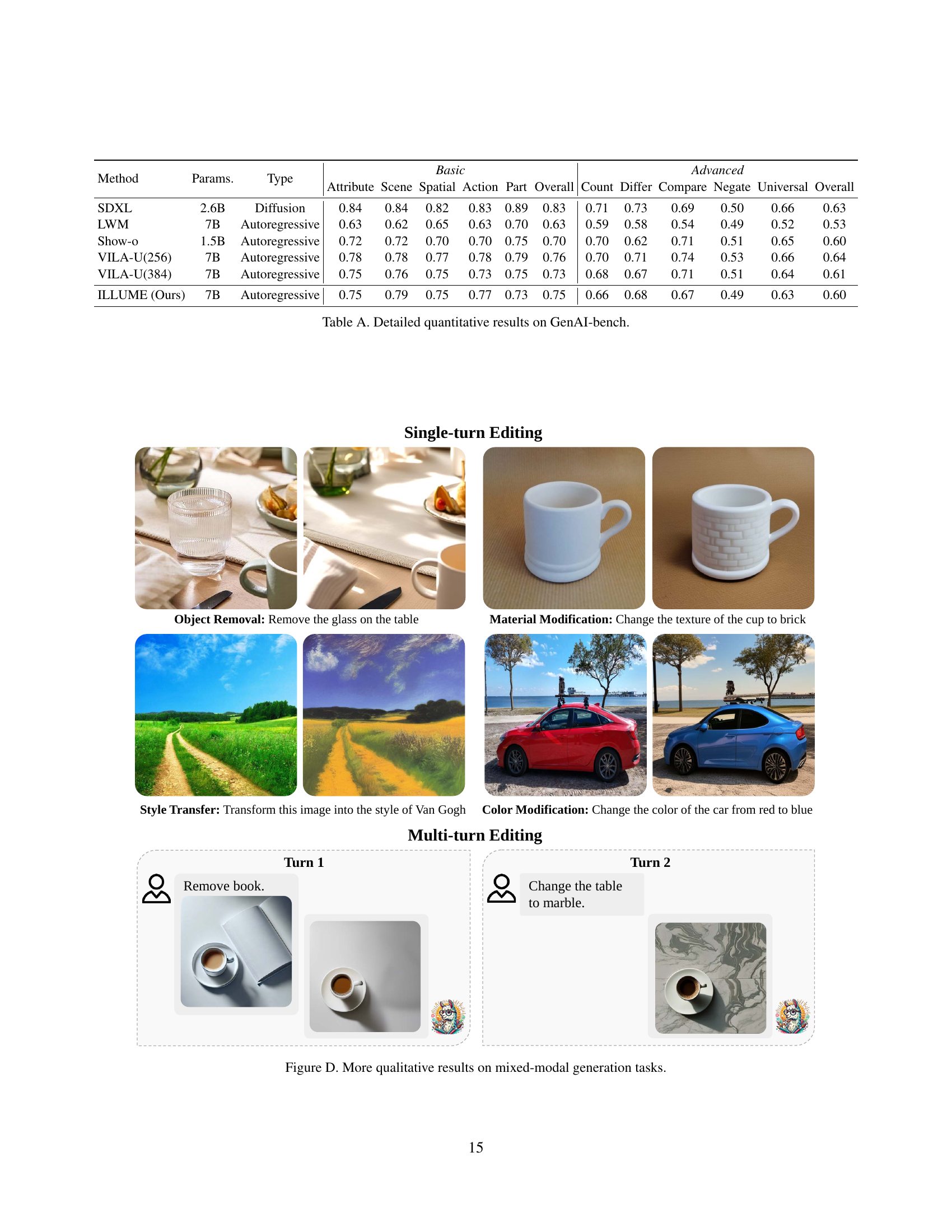
🔼 Figure D presents qualitative results demonstrating ILLUME’s capabilities in mixed-modal generation tasks. It showcases examples of single-turn editing (object removal, material modification, style transfer, color modification) and multi-turn editing tasks. Each example shows an image, the instructions given to the model, and the generated image. This illustrates the model’s ability to follow complex and multi-step instructions involving image manipulation and style changes.
read the caption
Figure D: More qualitative results on mixed-modal generation tasks.

🔼 This figure shows an example of assessment data used in the self-enhancing multimodal alignment process. The self-enhancing multimodal alignment scheme consists of three steps: 1. Corpus Self-generation: The model generates images from a subset of text-to-image data. 2. Assessment Generation: Inconsistencies between generated images and text descriptions are identified and analyzed based on criteria such as Object, Counting, Color, and Spatial Relation, and a JSON formatted assessment is generated. 3. Supervised Fine-tuning (SFT): The assessment data is used to refine the model, particularly focusing on correcting misalignments between images and texts. This example highlights how the model assesses the consistency between a text description and its corresponding generated image, identifying discrepancies in color and spatial relation, and then using this feedback for improvement.
read the caption
Figure E: Data example of assessment data for self-enhancing multimodal alignment.
More on tables
| Tasks | GenAI-Bench | GenEval | POPE | MME-P | MMBench | SEED | MMVet |
|---|---|---|---|---|---|---|---|
| Gen. only | 0.63 | 0.58 | - | - | - | - | |
| Und. only | - | - | 84.6 | 1339.0 | 60.9 | 64.0 | 28.0 |
| Gen. and Und. | 0.63 | 0.56 | 86.4 | 1358.6 | 61.6 | 65.0 | 27.4 |
🔼 This table compares the performance of a specialist model (trained for a single task) and a unified model (trained for multiple tasks) on two different tasks: visual understanding and generation. The results indicate that joint training (training the unified model on both tasks) does not significantly hinder the model’s performance in either task compared to a specialist model focused on just one task; however, it does not demonstrate a significant improvement in the unified model’s performance either. This suggests that, in this case, there aren’t strong synergistic benefits between training on visual understanding and generation tasks simultaneously.
read the caption
Table 2: Comparison between the specialist model and unified model. Joint training presents no significant negative impact on the two tasks, but it also does not obviously promote each other.
| Method | LLM. | POPE | MMBench | SEED | MME-P | MM-Vet | MMMU | AI2D | VQA-text | ChartQA | DocVQA | InfoVQA | OCRBench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| InstructBLIP [10] | Vicuna-7B | - | 36.0 | 53.4 | - | 26.2 | 30.6 | 33.8 | 50.1 | 12.5 | 13.9 | - | 276 |
| Qwen-VL-Chat [1] | Qwen-7B | - | 60.6 | 58.2 | 1487.5 | - | 35.9 | 45.9 | 61.5 | 66.3 | 62.6 | - | 488 |
| LLaVA-1.5 [27] | Vicuna-7B | 85.9 | 64.3 | 58.6 | 1510.7 | 31.1 | 35.4 | 54.8 | 58.2 | 18.2 | 28.1 | 25.8 | 318 |
| ShareGPT4V [7] | Vicuna-7B | - | 68.8 | 69.7 | 1567.4 | 37.6 | 37.2 | 58 | 60.4 | 21.3 | - | - | 371 |
| LLaVA-NeXT [28] | Vicuna-7B | 86.5 | 67.4 | 64.7 | - | 43.9 | 35.1 | 66.6 | 64.9 | 54.8 | 74.4 | 37.1 | 532 |
| Emu3-Chat [49] | 8B from scratch | 85.2 | 58.5 | 68.2 | - | 37.2 | 31.6 | 70.0 | 64.7 | 68.6 | 76.3 | 43.8 | 687 |
| Unified-IO 2 [33] | 6.8B from scratch | 87.7 | - | 61.8 | - | - | - | - | - | - | - | - | - |
| Chameleon [47] | 7B from scratch | - | - | - | - | 8.3 | 22.4 | - | - | - | - | - | - |
| LWM [30] | LLaMA-2-7B | 75.2 | - | - | - | 9.6 | - | - | 18.8 | - | - | - | - |
| Show-o [54] | Phi-1.5B | 73.8 | - | - | 948.4 | - | 25.1 | - | - | - | - | - | - |
| VILA-U (256) [52] | LLaMA-2-7B | 83.9 | - | 56.3 | 1336.2 | 27.7 | - | - | 48.3 | - | - | - | - |
| VILA-U (384) [52] | LLaMA-2-7B | 85.8 | - | 59 | 1401.8 | 33.5 | - | - | 60.8 | - | - | - | - |
| Janus [51] | DeepSeek-LLM-1.3B | 87.0 | 69.4 | 63.7 | 1338.0 | 34.3 | 30.5 | - | - | - | - | - | - |
| ILLUME (Ours) | Vicuna-7B | 88.5 | 75.1 | 72.9 | 1445.3 | 37.0 | 38.2 | 71.4 | 72.1 | 66.7 | 76.0 | 45.5 | 669 |
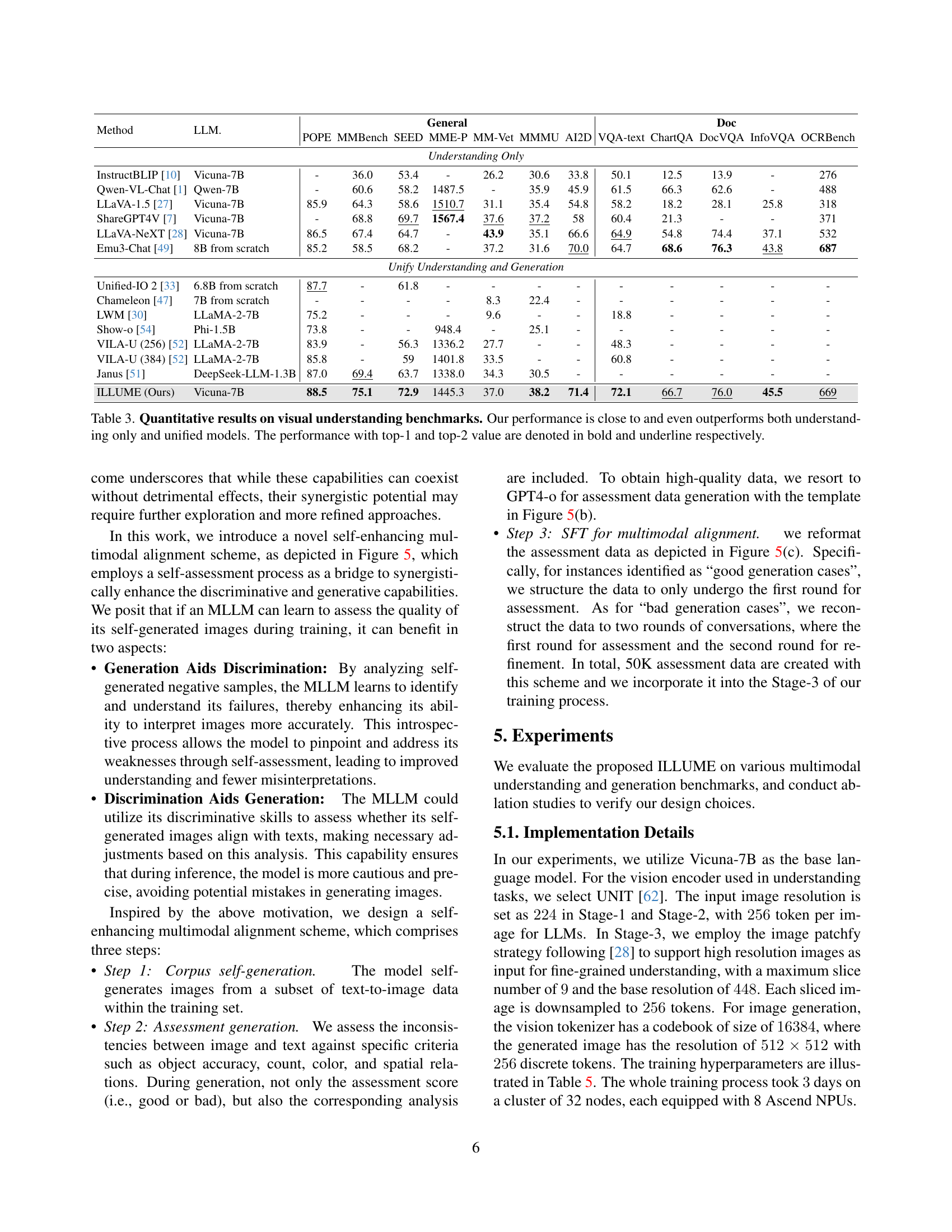
🔼 Table 3 presents a quantitative comparison of ILLUME’s performance on various visual understanding benchmarks against other state-of-the-art models. These benchmarks assess different aspects of visual understanding, categorized into general and document-oriented tasks. The table shows ILLUME achieves competitive results, often surpassing or nearly matching the performance of specialized models designed for understanding only, as well as unified models that combine understanding and generation capabilities. Top-performing scores are highlighted in bold and underlined.
read the caption
Table 3: Quantitative results on visual understanding benchmarks. Our performance is close to and even outperforms both understanding only and unified models. The performance with top-1 and top-2 value are denoted in bold and underline respectively.
| Method | Params. | Type | FID | MJHQ30k | GenAI-bench | GenEval | Overall | Single Obj | Two Obj. | Counting | Colors | Position | Color Attri. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Generation Only | ||||||||||||||
| SDv1.5 [40] | 0.9B | Diffusion | - | - | - | 0.43 | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 | ||
| PixArt-α [4] | 0.6B | Diffusion | 6.14 | - | - | 0.48 | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | ||
| SDXL [38] | 2.6B | Diffusion | 9.55 | 0.83 | 0.63 | 0.55 | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | ||
| Emu3-Gen [49] | 8B | Autoregressive | - | - | - | 0.54 | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | ||
| Unify Understanding and Generation | ||||||||||||||
| Chameleon [47] | 7B | Autoregressive | - | - | - | 0.39 | - | - | - | - | - | - | ||
| LWM [30] | 7B | Autoregressive | 17.77 | 0.63 | 0.53 | 0.47 | 0.93 | 0.41 | 0.46 | 0.79 | 0.09 | 0.15 | ||
| Show-o [54] | 1.5B | Autoregressive | 15.18 | 0.70 | 0.60 | 0.53 | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | ||
| VILA-U(256) [52] | 7B | Autoregressive | 12.81 | 0.76 | 0.64 | - | - | - | - | - | - | - | ||
| VILA-U(384) [52] | 7B | Autoregressive | 7.69 | 0.73 | 0.61 | - | - | - | - | - | - | - | ||
| Janus [51] | 1.3B | Autoregressive | 10.10 | - | - | 0.61 | 0.97 | 0.68 | 0.30 | 0.84 | 0.46 | 0.42 | ||
| ILLUME (Ours) | 7B | Autoregressive | 7.76 | 0.75 | 0.60 | 0.61 | 0.99 | 0.86 | 0.45 | 0.71 | 0.39 | 0.28 |
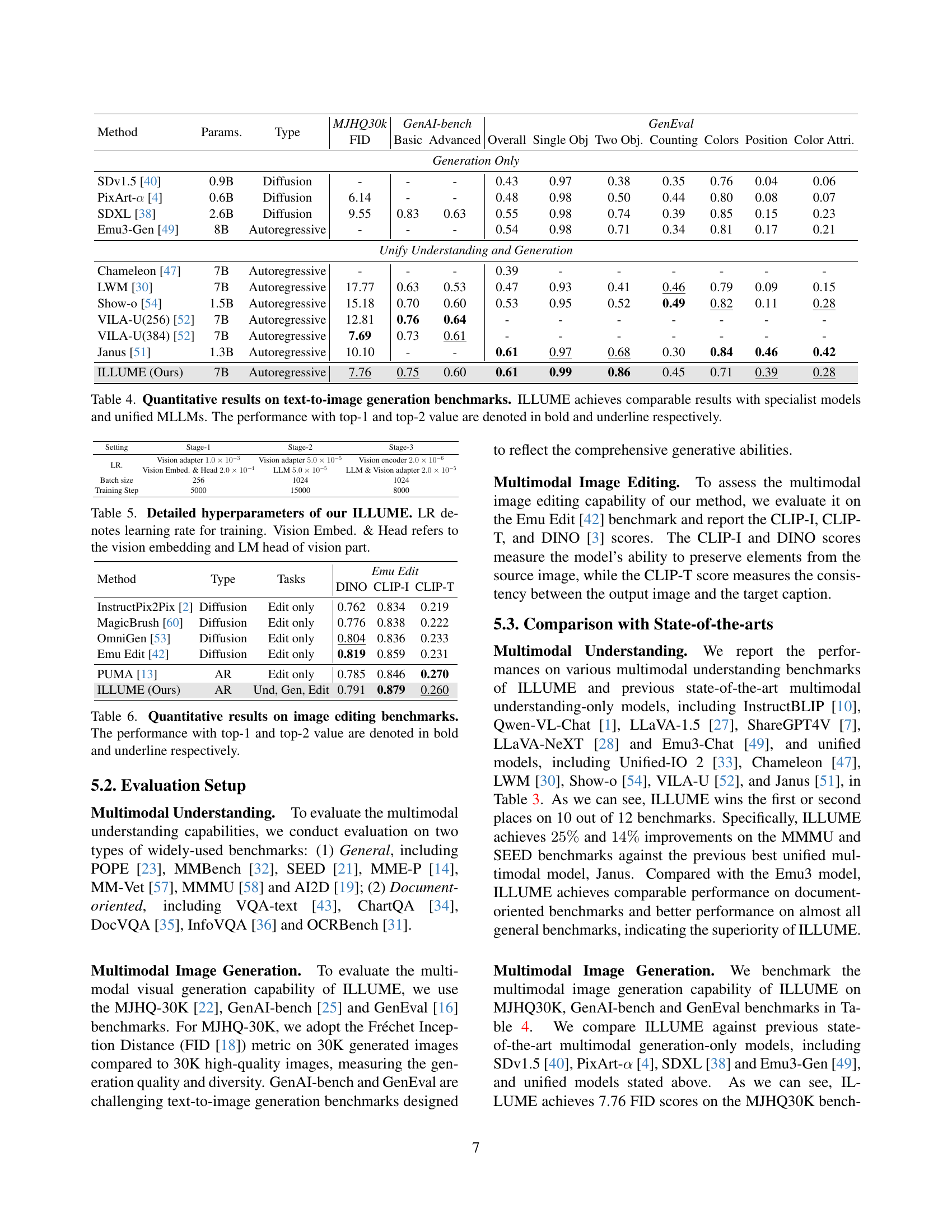
🔼 Table 4 presents a quantitative comparison of various models’ performance on text-to-image generation benchmarks. The metrics used assess different aspects of image quality, including overall quality, object fidelity, color accuracy, and more. The table highlights ILLUME’s performance relative to specialized text-to-image models (designed solely for this task) and unified multimodal large language models (MLLMs) that combine image generation with other capabilities. The top-performing results for each metric are emphasized in bold and underlined, clarifying the best overall performance and second-best results.
read the caption
Table 4: Quantitative results on text-to-image generation benchmarks. ILLUME achieves comparable results with specialist models and unified MLLMs. The performance with top-1 and top-2 value are denoted in bold and underline respectively.
| Setting | Stage-1 | Stage-2 | Stage-3 |
|---|---|---|---|
| Vision adapter 1.0×10⁻³ | Vision adapter 5.0×10⁻⁵ | Vision encoder 2.0×10⁻⁶ | |
| LR. | Vision Embed. & Head 2.0×10⁻⁴ | LLM 5.0×10⁻⁵ | LLM & Vision adapter 2.0×10⁻⁵ |
| Batch size | 256 | 1024 | 1024 |
| Training Step | 5000 | 15000 | 8000 |
🔼 Table 5 presents the hyperparameters used during the training of the ILLUME model. It details the learning rates (LR) applied to different components of the model during its three training stages: Visual Embedding Initialization, Unified Image-Text Alignment, and Supervised Fine-tuning. Specifically, it shows separate learning rates for the vision adapter, vision embedding and head, and the main language model (LLM). The batch size and number of training steps are also included for each stage. Understanding these hyperparameters is crucial for replicating the model’s training process and interpreting the impact of the design choices on the overall performance.
read the caption
Table 5: Detailed hyperparameters of our ILLUME. LR denotes learning rate for training. Vision Embed. & Head refers to the vision embedding and LM head of vision part.
| Method | Type | Tasks | DINO | CLIP-I | CLIP-T |
|---|---|---|---|---|---|
| InstructPix2Pix [2] | Diffusion | Edit only | 0.762 | 0.834 | 0.219 |
| MagicBrush [60] | Diffusion | Edit only | 0.776 | 0.838 | 0.222 |
| OmniGen [53] | Diffusion | Edit only | 0.804 | 0.836 | 0.233 |
| Emu Edit [42] | Diffusion | Edit only | 0.819 | 0.859 | 0.231 |
| PUMA [13] | AR | Edit only | 0.785 | 0.846 | 0.270 |
| ILLUME (Ours) | AR | Und, Gen, Edit | 0.791 | 0.879 | 0.260 |
🔼 Table 6 presents a quantitative comparison of different image editing models’ performance on various benchmarks. The models are evaluated based on three metrics: CLIP-I, CLIP-T, and DINO, which assess different aspects of image editing quality, including the preservation of elements from the source image and the consistency between the output image and the target caption. The table highlights the top performing models for each metric, denoted in bold and underlined font, offering insights into the strengths and weaknesses of each approach in image editing tasks.
read the caption
Table 6: Quantitative results on image editing benchmarks. The performance with top-1 and top-2 value are denoted in bold and underline respectively.
| Understanding | POPE | MME-P | MMBench | SEED | GQA | MM-Vet | MMMU |
|---|---|---|---|---|---|---|---|
| baseline | 86.4 | 1358.6 | 61.7 | 65.0 | 60.0 | 27.4 | 31.2 |
| + assessment | 86.1 | 1446.7 | 63.1 | 66.0 | 60.7 | 29.0 | 32.0 |
| Generation | Overall | Single Obj | Two Obj. | Counting | Colors | Position | Color Attri. |
| — | — | — | — | — | — | — | — |
| baseline | 0.56 | 0.98 | 0.8 | 0.35 | 0.69 | 0.34 | 0.22 |
| + assessment | 0.59 | 0.99 | 0.84 | 0.43 | 0.72 | 0.33 | 0.24 |
🔼 This table presents the ablation study results evaluating the effectiveness of the self-enhancing multimodal alignment scheme. It compares the performance on various multimodal understanding and generation benchmarks with and without the proposed scheme, demonstrating its contribution to improved model performance. The results are split to show the impact on both the understanding and generation tasks.
read the caption
Table 7: Ablation of self-enhancing multimodal alignment.
| Method | Params. | Type | Attribute | Scene | Spatial | Action | Part | Overall | Count | Differ | Compare | Negate | Universal | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SDXL | 2.6B | Diffusion | 0.84 | 0.84 | 0.82 | 0.83 | 0.89 | 0.83 | 0.71 | 0.73 | 0.69 | 0.50 | 0.66 | 0.63 |
| LWM | 7B | Autoregressive | 0.63 | 0.62 | 0.65 | 0.63 | 0.70 | 0.63 | 0.59 | 0.58 | 0.54 | 0.49 | 0.52 | 0.53 |
| Show-o | 1.5B | Autoregressive | 0.72 | 0.72 | 0.70 | 0.70 | 0.75 | 0.70 | 0.70 | 0.62 | 0.71 | 0.51 | 0.65 | 0.60 |
| VILA-U(256) | 7B | Autoregressive | 0.78 | 0.78 | 0.77 | 0.78 | 0.79 | 0.76 | 0.70 | 0.71 | 0.74 | 0.53 | 0.66 | 0.64 |
| VILA-U(384) | 7B | Autoregressive | 0.75 | 0.76 | 0.75 | 0.73 | 0.75 | 0.73 | 0.68 | 0.67 | 0.71 | 0.51 | 0.64 | 0.61 |
| ILLUME (Ours) | 7B | Autoregressive | 0.75 | 0.79 | 0.75 | 0.77 | 0.73 | 0.75 | 0.66 | 0.68 | 0.67 | 0.49 | 0.63 | 0.60 |
🔼 Table A presents a detailed breakdown of the quantitative results obtained from evaluating the ILLUME model on the GenAI-bench benchmark. It compares ILLUME’s performance against several other models, including those using diffusion and autoregressive methods. The table assesses various aspects of image generation quality, such as attribute accuracy, scene understanding, spatial relationships, action recognition, and overall image quality. Separate scores are provided for basic and advanced generation tasks, allowing for a nuanced comparison of model capabilities across different levels of complexity.
read the caption
Table A: Detailed quantitative results on GenAI-bench.
Full paper#