↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Federated Learning (FL) faces a significant challenge: gradient inversion attacks can reconstruct sensitive training data from shared model updates. Existing solutions, like secure multi-party computation or differential privacy, often lead to significant trade-offs between privacy and model accuracy. This paper introduces HyperFL, a novel FL framework that improves privacy by fundamentally altering how model updates are shared.
HyperFL achieves this by employing hypernetworks to generate model parameters. Instead of sharing the full model parameters, only the hypernetwork parameters (a smaller and less sensitive subset) are shared with the server for aggregation. This technique effectively breaks the direct link between the training data and the shared parameters, making gradient inversion significantly harder. The paper provides both theoretical analysis and empirical evidence demonstrating HyperFL’s effectiveness in protecting privacy and maintaining good model performance, suggesting a substantial advancement in secure FL.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical vulnerability in federated learning—gradient inversion attacks—by introducing a novel framework, HyperFL. HyperFL offers a promising solution to the privacy-utility trade-off inherent in many existing privacy-preserving techniques. Its flexibility and scalability make it highly relevant to current research and open new avenues for developing more secure and efficient federated learning systems. The theoretical analysis and extensive experimental results further solidify its significance.
Visual Insights#

🔼 The figure illustrates two approaches to securing Federated Learning (FL) against gradient inversion attacks. The left panel depicts traditional methods (SMC, HE, DP) which focus on enhancing the security of shared gradients, but often compromise model accuracy. The right panel presents a novel FL framework that decouples shared parameters from local private data, thus mitigating the privacy-utility trade-off.
read the caption
Figure 1: Left. Existing methods mainly explore defenses mechanisms on the shared gradients. Such mechanisms, including SMC, HE, and DP, inherently involve substantial privacy-utility trade-offs. Right. A novel FL framework that “breaks the direct connection” between the shared parameters and the local private data is proposed to achieve a favorable privacy-utility trade-off.
| Method | EMNIST (20 clients) | EMNIST (100 clients) | Fashion-MNIST (20 clients) | Fashion-MNIST (100 clients) | CIFAR-10 (20 clients) | CIFAR-10 (100 clients) | CINIC-10 (20 clients) | CINIC-10 (100 clients) |
|---|---|---|---|---|---|---|---|---|
| Local-only | 73.41 | 75.68 | 85.93 | 87.01 | 65.47 | 66.11 | 63.60 | 64.84 |
| FedAvg | 72.77 | 78.87 | 85.67 | 88.11 | 70.02 | 76.24 | 57.00 | 59.11 |
| pFedHN | 80.86 | 77.37 | 87.64 | 89.80 | 70.18 | 80.07 | 63.88 | 70.36 |
| DP-FedAvg | 35.12 | 45.73 | 59.88 | 68.29 | 29.12 | 32.03 | 27.30 | 29.94 |
| CENTAUR | 68.82 | 67.24 | 83.07 | 79.77 | 50.85 | 51.86 | 48.82 | 51.01 |
| PPSGD | 71.16 | 71.18 | 84.47 | 82.94 | 52.17 | 53.92 | 49.98 | 52.91 |
| HyperFL | 76.29 | 80.22 | 88.28 | 90.41 | 73.03 | 78.73 | 66.74 | 72.21 |
🔼 This table compares the final test accuracy achieved by different federated learning (FL) methods on four image classification datasets (EMNIST, Fashion-MNIST, CIFAR-10, and CINIC-10). The accuracy is presented for two scenarios: one with full participation of 20 clients and another with client sampling (30% participation rate) of 100 clients. This comparison highlights the performance differences between various FL approaches, including FedAvg, a baseline FL algorithm, privacy-preserving techniques like DP-FedAvg, PPSGD, and CENTAUR, and other algorithms like pFedHN and the proposed HyperFL method. It demonstrates how the proposed HyperFL method compares to state-of-the-art methods in terms of model accuracy.
read the caption
Table 1: The comparison of final test accuracy (%) of different methods on various datasets. We apply full participation for FL system with 20 clients, and apply client sampling with rate 0.3 for FL system with 100 clients.
In-depth insights#
HyperFL Framework#
The HyperFL framework, a novel federated learning approach, directly addresses the vulnerability of standard federated learning to gradient inversion attacks (GIAs). Instead of directly sharing model parameters, HyperFL employs hypernetworks to generate these parameters locally at each client. Only the hypernetwork’s parameters are uploaded for aggregation, effectively severing the direct link between shared information and sensitive client data, mitigating GIA risks. This dual-pronged approach—combining network decomposition with hypernetwork sharing—offers a favorable privacy-utility trade-off. The framework’s flexibility allows for adaptation to diverse scenarios, ranging from simple tasks using small networks to complex tasks employing large pre-trained models via adapter parameters. Theoretical analysis demonstrates its convergence rate, while experiments confirm comparable performance to FedAvg while achieving robust privacy preservation. The innovation lies in its proactive approach to privacy protection, shifting the focus from reactive defense mechanisms to a fundamental restructuring of the FL process itself. This makes HyperFL a significant advancement in secure and efficient federated learning.
GIA Defense#
Gradient Inversion Attacks (GIAs) pose a significant threat to the privacy of Federated Learning (FL) systems. GIA defense mechanisms are crucial for ensuring the security and trustworthiness of FL. A variety of methods have been explored, including the use of differential privacy to add noise to model updates, and secure multi-party computation to perform computations in a privacy-preserving manner. However, these often lead to significant privacy-utility trade-offs, reducing the effectiveness of the model. A novel approach involves breaking the direct connection between shared parameters and local private data, as seen in the HyperFL framework. This innovative approach uses hypernetworks to generate local model parameters, effectively shielding the underlying data from direct exposure. The success of this method hinges on finding a balance between privacy protection and model utility. The research into GIA defenses is an ongoing process, and further investigation is necessary to explore the full spectrum of effective and efficient techniques.
Privacy Analysis#
A robust privacy analysis section in a federated learning research paper should delve into the defense mechanisms against gradient inversion attacks (GIAs). It must quantify the level of privacy protection offered by the proposed framework, perhaps using metrics like PSNR, SSIM, and LPIPS to measure the reconstruction quality of sensitive data from shared gradients. The analysis should also address the trade-offs between privacy and utility, demonstrating that the proposed method maintains good model accuracy while ensuring a high level of privacy. Theoretical analysis supporting the privacy claims is essential, perhaps demonstrating the framework’s resistance to GIA under certain conditions or assumptions. Furthermore, the analysis should consider different attack models, including those that leverage additional information about the data or the model architecture, to provide a comprehensive evaluation of the framework’s privacy-preserving capabilities. Comparison to existing methods should also be a focal point, highlighting the superior privacy guarantees offered by the proposed system relative to previous work. This should include both empirical and theoretical comparisons, showing the advantages in accuracy and privacy levels.
Convergence Rate#
Analyzing the convergence rate in federated learning (FL) is crucial for evaluating algorithm efficiency and performance. A fast convergence rate indicates that the model parameters quickly reach a stable state, leading to quicker training times and reduced computational costs. The convergence rate is significantly impacted by factors such as data heterogeneity across clients, the choice of optimization algorithm, and the communication frequency between clients and the server. Non-IID data, where clients have dissimilar data distributions, often poses a significant challenge, potentially leading to slower convergence or even failure to converge. Methods like FedAvg, while popular, may struggle with non-IID data. Therefore, analyzing the convergence rate requires understanding the interplay of these factors and potentially developing techniques to mitigate the negative effects of data heterogeneity. Researchers often use theoretical analysis and empirical experiments to study convergence and might adopt measures such as smoothness and strong convexity of the loss function to simplify the analysis. A deep understanding of the convergence rate is essential for designing robust and efficient FL algorithms suitable for real-world scenarios with diverse data distributions.
Future Works#
Future research directions stemming from this HyperFL framework could explore several promising avenues. Extending HyperFL to handle more complex data modalities beyond images, such as text or time-series data, would broaden its applicability. Investigating the robustness of HyperFL against more sophisticated adversarial attacks is crucial, and this could involve evaluating its resilience to attacks combining gradient inversion with other techniques like model extraction or membership inference. A theoretical analysis of HyperFL’s privacy guarantees under various attack models and client behaviors would provide deeper insights and strengthen confidence. Furthermore, developing more efficient algorithms for hypernetwork training could improve the framework’s scalability for larger datasets and models. Finally, empirical studies comparing HyperFL’s performance against other privacy-enhancing techniques using heterogeneous real-world datasets would demonstrate its practical advantages and limitations.
More visual insights#
More on figures

🔼 HyperFL framework protects data privacy by breaking the direct link between shared parameters and local data. It splits each client’s network into a feature extractor and a classifier. A hypernetwork generates the feature extractor parameters using a private client embedding vector. Only the hypernetwork parameters are shared during federated learning, keeping other components private to prevent privacy leakage from gradient inversion attacks.
read the caption
Figure 2: The proposed HyperFL framework. HyperFL decouples each client’s network into the former feature extractor f(;θi)f(;\theta_{i})italic_f ( ; italic_θ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) and the latter classifier head g(;ϕi)g(;{\phi_{i}})italic_g ( ; italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ). An auxiliary hypernetwork h(;φi)h(;{\varphi_{i}})italic_h ( ; italic_φ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) is introduced to generate local clients’ feature extractor f(;θi)f(;\theta_{i})italic_f ( ; italic_θ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) using the client’s private embedding vector 𝐯isubscript𝐯𝑖\mathbf{v}_{i}bold_v start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, i.e., θi=h(𝐯i;φi)subscript𝜃𝑖ℎsubscript𝐯𝑖subscript𝜑𝑖{\theta_{i}}=h({{\bf{v}}_{i}};{\varphi_{i}})italic_θ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = italic_h ( bold_v start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ; italic_φ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ). These generated parameters are then used to extract features from the input xisubscript𝑥𝑖{x}_{i}italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, which are subsequently fed into the classifier to obtain the output y^isubscript^𝑦𝑖\hat{y}_{i}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, expressed as y^i=g(f(xi;θi);ϕi)subscript^𝑦𝑖𝑔𝑓subscript𝑥𝑖subscript𝜃𝑖subscriptitalic-ϕ𝑖\hat{y}_{i}=g(f({x}_{i};\theta_{i});\phi_{i})over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = italic_g ( italic_f ( italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ; italic_θ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ; italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ). Throughout the FL training, only the hypernetwork φisubscript𝜑𝑖\varphi_{i}italic_φ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is shared, while all other components are kept private, thus effectively mitigating potential privacy leakage concerns.

🔼 HyperFL-LPM is a variation of the HyperFL framework designed for use with large pre-trained models. Instead of generating the entire feature extractor’s parameters, the hypernetwork generates only the parameters for adapter modules. These adapters modify the pre-trained feature extractor, allowing for personalization without the computational cost of training a large model from scratch. The pre-trained model’s weights remain fixed; only the classifier, hypernetwork, and client embeddings are updated during training. This approach enhances efficiency when working with complex models, and helps to maintain privacy.
read the caption
Figure 3: The proposed HyperFL-LPM framework within each client. In this framework, the weights of the pre-trained model are fixed, while only the classifier, hypernetwork, and client embedding are trainable. Note that θ𝜃\thetaitalic_θ here represents the parameters of the adapters.

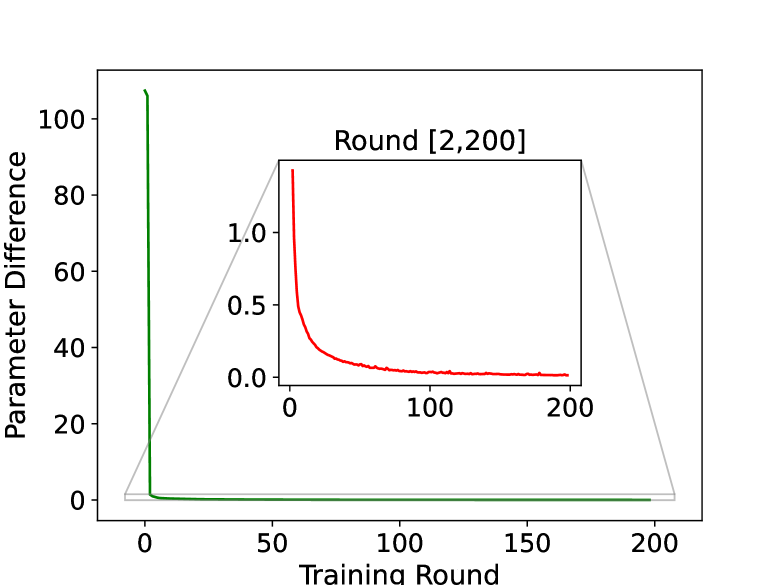
🔼 Figure 4 presents a comparative analysis of the training performance and parameter stability of the proposed HyperFL framework against other established methods. Subfigure (a) illustrates the average training loss curves across multiple training rounds for different algorithms, revealing the convergence speed and overall training efficiency. Subfigure (b) focuses on the parameter changes in the generated feature extractor of a single client between consecutive training rounds. This visualization helps to assess the stability and convergence behavior of the model parameters during the training process. The EMNIST dataset is used with 20 participating clients for this comparison.
read the caption
Figure 4: (a) Average training loss of different methods on the EMNIST dataset with 20 clients. (b) Parameter difference of the generated feature extractor of one client between adjacent training round on the EMNIST dataset with 20 clients.
🔼 This figure visualizes the results of Gradient Inversion Attacks (GIA) on various federated learning (FL) methods. The ‘Ground Truth’ column shows the original images from the EMNIST and CIFAR-10 datasets used for training. Subsequent columns display the reconstructed images obtained by applying the IG (Geiping et al., 2020) attack to different FL approaches, namely FedAvg, pFedHN, pFedHN-PC, DP-FedAvg, CENTAUR, PPSGD, and the proposed HyperFL method. The visual comparison highlights the effectiveness of the HyperFL framework in resisting GIA, as its reconstructed images are significantly less clear and closer to random noise than other methods.
read the caption
Figure 5: Reconstructed images of IG.

🔼 Figure 6 presents the results of applying the ROG (Reconstruction via Optimization of Gradients) attack method on the HyperFL framework. The figure visually compares the original images (ground truth) to the images reconstructed by the ROG attack after the HyperFL model has been trained. This comparison allows for an assessment of the effectiveness of the HyperFL framework in preventing reconstruction attacks. The quality of the reconstructed images is a direct indication of the degree to which the training data’s privacy has been compromised by the attack. Lower quality reconstructions, significantly different from the original images, demonstrate the stronger privacy-preserving capabilities of the HyperFL framework.
read the caption
Figure 6: Reconstructed images of ROG.

🔼 This figure displays the results of a tailored attack method designed to test the privacy-preserving capabilities of the HyperFL framework. The top row shows the original images from the EMNIST and CIFAR-10 datasets used in the experiment. The bottom row presents the reconstructed images produced by the attack method. The comparison allows for a visual assessment of the effectiveness of HyperFL in protecting the privacy of sensitive data by observing how closely the reconstructed images resemble the originals.
read the caption
Figure 7: Reconstructed images of the tailored attack method. The first row contains the original images, while the second row shows the reconstruction results.

🔼 Figure 8 presents a detailed visualization of the learned client embeddings in the EMNIST dataset using 20 clients. Panel (a) shows the distribution of labels across the 20 clients, highlighting the non-IID nature of the data. Each client’s data is not uniformly distributed across the 62 classes in EMNIST. Panel (b) uses t-SNE to reduce the high-dimensional client embedding vectors to two dimensions, allowing for visualization. The clustering of the points indicates meaningful relationships between clients based on their data characteristics. Clients with similar data distributions cluster closely together. This visualization demonstrates the effectiveness of the learned client embeddings in capturing the underlying data heterogeneity and relationships among clients in a federated learning setting.
read the caption
Figure 8: (a) Label distribution of the EMNIST dataset with 20 clients. (b) The t-SNE visualization of the learned client embeddings of the EMNIST dataset with 20 clients.
More on tables
| Arch | Local-only† | Local-only†† | FedAvg† | FedAvg†† | HyperFL-LPM | |
|---|---|---|---|---|---|---|
| EMNIST | ResNet | 72.83 | 80.35 | 68.99 | 75.21 | 80.32 |
| ViT | 76.95 | 80.04 | 70.92 | 76.42 | 79.92 | |
| CIFAR-10 | ResNet | 68.57 | 73.57 | 62.35 | 75.57 | 75.03 |
| ViT | 91.82 | 89.70 | 92.32 | 95.56 | 95.40 |
🔼 This table compares the performance of different federated learning methods on four image classification datasets (EMNIST, Fashion-MNIST, CIFAR-10, and CINIC-10) using 20 clients. The methods compared include a local-only baseline, FedAvg (a standard federated learning algorithm), and HyperFL (the proposed method) with two configurations: one using a fully trainable feature extractor and another using a pre-trained model with only adapter parameters fine-tuned. The table shows the final test accuracy achieved by each method, highlighting HyperFL’s superior performance compared to the baselines and other approaches. The use of † and †† symbols indicates whether the feature extractor was fixed (pre-trained) or fully trainable, respectively, for different model configurations.
read the caption
Table 2: The comparison of final test accuracy (%) of different methods on various datasets with 20 clients. † Fixed feature extractor. †† Adapter fine-tuning.
| Method | EMNIST PSNR | EMNIST SSIM | EMNIST LPIPS | CIFAR-10 PSNR | CIFAR-10 SSIM | CIFAR-10 LPIPS |
|---|---|---|---|---|---|---|
| FedAvg | 32.64 | 0.8925 | 0.0526 | 16.16 | 0.6415 | 0.0536 |
| pFedHN | 31.24 | 0.8701 | 0.0807 | 16.02 | 0.6351 | 0.0504 |
| pFedHN-PC | 28.38 | 0.8713 | 0.0645 | 15.80 | 0.6247 | 0.4407 |
| DP-FedAvg | 7.74 | 0.2978 | 0.7051 | 7.90 | 0.2716 | 0.3204 |
| CENTAUR | 9.52 | 0.2136 | 0.6712 | 9.80 | 0.2723 | 0.2882 |
| PPSGD | 9.73 | 0.1889 | 0.6466 | 9.70 | 0.2788 | 0.2643 |
| HyperFL | 7.85 | 0.3010 | 0.7147 | 8.35 | 0.2732 | 0.3132 |
🔼 This table presents the results of applying the Gradient Inversion (IG) attack to reconstruct the original training data from the gradients shared during federated learning. It compares the performance of several different federated learning methods, including FedAvg, pFedHN, DP-FedAvg, CENTAUR, PPSGD and HyperFL, in terms of their ability to protect against this type of attack. The reconstruction quality is measured using Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Higher PSNR and SSIM values and lower LPIPS indicate that the original image has been reconstructed more accurately, implying weaker privacy protection.
read the caption
Table 3: Reconstruction results of IG.
| FedAvg | DP-FedAvg | PPSGD | CENTAUR | HyperFL | |
|---|---|---|---|---|---|
| # Time (s) | 23 | 194 | 223 | 210 | 37 |
🔼 This table presents the training time for each round of different federated learning methods using the EMNIST dataset with 20 clients. It compares the training efficiency of the proposed HyperFL framework with other differentially private federated learning methods (DP-FedAvg, PPSGD, CENTAUR) and the standard FedAvg method. The time is measured in seconds.
read the caption
Table 4: Training time of per training round on the EMNIST dataset with 20 clients of different methods.
🔼 This table presents the results of the Reconstructed Original Images using the ROG (Reconstructed Original Gradient) attack method. It shows the PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity) scores for the FedAvg and HyperFL models on the EMNIST and CIFAR-10 datasets. These metrics quantify the quality of the reconstructed images and are used to evaluate the privacy-preserving capabilities of the models against ROG attacks. Lower LPIPS and higher PSNR/SSIM indicate better privacy protection.
read the caption
Table 5: Reconstruction results of ROG.
Full paper#

















