↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Online toxicity is a major issue, and while AI-generated counterspeech offers a scalable solution, current methods are generic and lack adaptation to the context and users involved. This paper addresses these limitations by exploring multiple strategies for generating counterspeech tailored to both context and individual users. The researchers found that contextualized counterspeech, leveraging information about the community, conversation, and user, significantly outperforms generic counterspeech in terms of adequacy and persuasiveness.
This study employed an LLM (LLaMA2-13B) to generate counterspeech, testing various configurations based on different contextual information and fine-tuning strategies. A novel hybrid evaluation method, combining both quantitative indicators and human evaluations, was utilized to assess the quality of the generated counterspeech. Results showed that while contextualized counterspeech was more effective, there was a surprising lack of correlation between quantitative metrics and human judgements, emphasizing the need for more sophisticated evaluation approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on AI-driven content moderation. It highlights the limitations of current generic counterspeech methods and proposes innovative strategies for generating contextualized and personalized responses, paving the way for more effective and ethical online toxicity mitigation. The novel evaluation methodology combining quantitative and human assessment is also vital for future research in this area.
Visual Insights#

🔼 The figure illustrates the difference between traditional AI-generated counterspeech and the contextualized approach proposed in the paper. Traditional methods only use the toxic message itself to generate a response. In contrast, the authors’ method incorporates additional context, such as information about the online community where the interaction is occurring, the broader conversation thread, and characteristics of the user who posted the toxic message. This additional information aims to create more persuasive and effective counterspeech.
read the caption
Figure 1. Current AI-generated counterspeech only leverages the content of the toxic message. Here, we generate contextualized counterspeech that also leverages information about the community, the conversation, and the moderated user to craft more persuasive responses.
In-depth insights#
Contextualized CS#
The concept of “Contextualized CS” (Counterspeech) introduces a significant advancement in addressing online toxicity. Instead of generic responses, it emphasizes tailoring counterspeech to the specific context of the interaction, considering the community, conversation history, and the user’s behavior. This approach moves beyond a simple reactive mechanism to a more nuanced and persuasive strategy. By leveraging contextual information, contextualized CS aims to increase the likelihood of changing toxic behavior and promoting respectful dialogue. The integration of advanced AI models, such as LLMs, allows for scalable generation of personalized counterspeech. However, challenges remain in evaluating the effectiveness of contextualized CS due to the difficulty of quantifying elements like persuasiveness and the lack of correlation between automated metrics and human judgment. This highlights the crucial need for comprehensive evaluation methodologies that consider both algorithmic indicators and qualitative human assessment, paving the way for robust human-AI collaborative content moderation systems. A key finding is the importance of context, but the precise combination of contextual elements for optimal impact warrants further exploration.
LLM CounterSpeech#
LLM-based counterspeech presents a promising yet complex solution to online toxicity. The core idea is leveraging Large Language Models to automatically generate responses that directly counter hateful or offensive messages, promoting civil discourse. This approach offers scalability and efficiency, surpassing the limitations of manual moderation. However, current methods often fall short, producing generic, ineffective responses. Contextualization is key; understanding the conversation’s nuances, community norms, and the user’s history significantly improves the persuasiveness and relevance of counterspeech. Personalization, tailoring the response to the specific user, adds further effectiveness. Evaluation remains a significant challenge, with current metrics often failing to capture human perception of adequacy, persuasiveness, or artificiality. Future research must focus on developing more nuanced evaluation methods and exploring advanced LLM architectures capable of generating truly contextual and personalized counterspeech to maximize its impact.
Hybrid Evaluation#
A hybrid evaluation approach for contextualized counterspeech, integrating both algorithmic and human assessments, offers a robust and nuanced evaluation compared to solely relying on automated metrics or human judgments. Algorithmic metrics provide quantitative data on aspects like relevance, diversity, and readability, offering an initial screening of generated counterspeech. However, these metrics alone often fail to capture the subtleties of persuasive quality, adequacy, and human perception of the AI-generated text. Human evaluations are essential to assess the persuasiveness, politeness, and overall impact of the response in a real-world context. A hybrid approach allows researchers to identify configurations that excel in both algorithmic and human evaluations, offering a comprehensive understanding of the generated counterspeech’s effectiveness. Combining both methods can reveal discrepancies between human judgment and algorithmic measures, highlighting the limitations of relying solely on automated metrics. This combined evaluation strategy is essential for developing more effective and ethical AI-driven counter-speech systems that can positively impact online discourse.
Adaptation Strategies#
Adaptation strategies in the context of AI-generated counterspeech focus on tailoring responses to specific contexts. Effective adaptation requires considering the community, conversation, and user characteristics. This involves fine-tuning models on diverse datasets representing different community norms and communication styles. Furthermore, incorporating conversational history allows for context-aware responses that directly address the nuances of ongoing interactions. Analyzing user-specific information, like previous comments or writing style, enables personalized responses that are more likely to resonate and be persuasive. However, balancing adaptation and personalization is crucial. Overly tailored responses may lack broader applicability, while generic approaches could miss vital contextual cues. Therefore, the most promising strategies will likely involve carefully balancing both global and local elements to create counterspeech that is both relevant and effective across diverse situations and audiences.
Future Directions#
Future research should explore more sophisticated models and techniques for personalizing and adapting counterspeech, ensuring AI-generated counterspeech is unbiased and fair. Investigating methods to detect biases in generation and assessing long-term effects on diverse user groups are crucial. A combined approach integrating algorithmic and human assessments is essential for evaluating effectiveness. Further research should examine the impact of different LLMs and explore strategies beyond those tested here. The discrepancy between algorithmic and human evaluations necessitates a more nuanced evaluation methodology. Finally, examining the ethical implications of using AI for counterspeech and the potential for unintended consequences is vital for responsible development.
More visual insights#
More on figures

🔼 Figure 2 presents a detailed analysis of how different factors influence the performance of the contextualized counterspeech model. For each factor (e.g., fine-tuning with a specific dataset, incorporating conversation history), the figure displays teal and sand dots representing the average performance when the factor is present or absent, respectively. The performance is measured across multiple indicators (relevance, diversity, readability, toxicity, adaptation, personalization), showing the impact of each factor on each metric. Upward arrows indicate higher values are preferable for the given metric, while downward arrows indicate lower values are better.
read the caption
Figure 2. Algorithmic evaluation results for each factor. For each factor (y axis) and indicator (panels), the teal dot shows the mean value of the indicator when the factor is used in the evaluated configurations, while the sand dot indicates the mean value of the indicator when the factor is not used. Arrows specify whether larger ↑↑\uparrow↑ or smaller ↓↓\downarrow↓ scores are better.

🔼 Figure 3 presents the results of a human evaluation comparing different configurations of an AI-generated counterspeech system to a baseline model. The evaluation was performed under non-contextual conditions, meaning participants only saw the toxic message and the generated counterspeech, not additional context. The figure displays effect sizes and confidence intervals for several key aspects of the counterspeech: relevance, adequacy, truthfulness, persuasiveness towards the toxic user, persuasiveness in steering the conversation, and artificiality. Statistical significance (p-values) are indicated by asterisks, with *** denoting p < 0.01.
read the caption
Figure 3. Human evaluation results (non-contextual condition). Effect sizes and confidence intervals of the scores assigned to several configurations compared to the baseline. Statistical significance: ***: p<0.01𝑝0.01p<0.01italic_p < 0.01.

🔼 Figure 4 presents the results of a human evaluation of AI-generated counterspeech, focusing on the impact of providing contextual information. It compares seven different configurations of the AI model, including a baseline (Ba) and variations incorporating adaptation and personalization strategies. The graph displays effect sizes and confidence intervals for six key metrics: relevance, adequacy, truthfulness, persuasiveness (towards the toxic user), persuasiveness (towards the overall conversation), and artificiality. Statistical significance levels (***, **, *) are indicated for comparisons against the baseline, indicating the statistical strength of observed differences. The contextual condition refers to experiments where additional context about the conversation and user was provided to the AI. The figure highlights the relative effectiveness of different model configurations under contextual conditions.
read the caption
Figure 4. Human evaluation results (contextual condition). Effect sizes and confidence intervals of the scores assigned to several configurations compared to the baseline. Statistical significance: ***: p<0.01𝑝0.01p<0.01italic_p < 0.01, **: p<0.05𝑝0.05p<0.05italic_p < 0.05, *: p<0.1𝑝0.1p<0.1italic_p < 0.1.
🔼 Figure 5 presents a comparison of human evaluation results obtained under two conditions: one where participants received contextual information alongside the toxic message and generated counterspeech (contextual condition), and another where they only received the toxic message and counterspeech (non-contextual condition). The figure displays effect sizes and confidence intervals for several key aspects of the counterspeech, including relevance, adequacy, truthfulness, persuasiveness towards the toxic user and the overall conversation, and the perceived artificiality of the generated response. Statistical significance levels are indicated using asterisks: *** for p<0.01, ** for p<0.05, and * for p<0.1, to show the differences between the contextual and non-contextual conditions for each configuration.
read the caption
Figure 5. Differences in human evaluation results between the contextual and non-contextual conditions. Statistical significance: ***: p<0.01𝑝0.01p<0.01italic_p < 0.01, **: p<0.05𝑝0.05p<0.05italic_p < 0.05, *: p<0.1𝑝0.1p<0.1italic_p < 0.1.

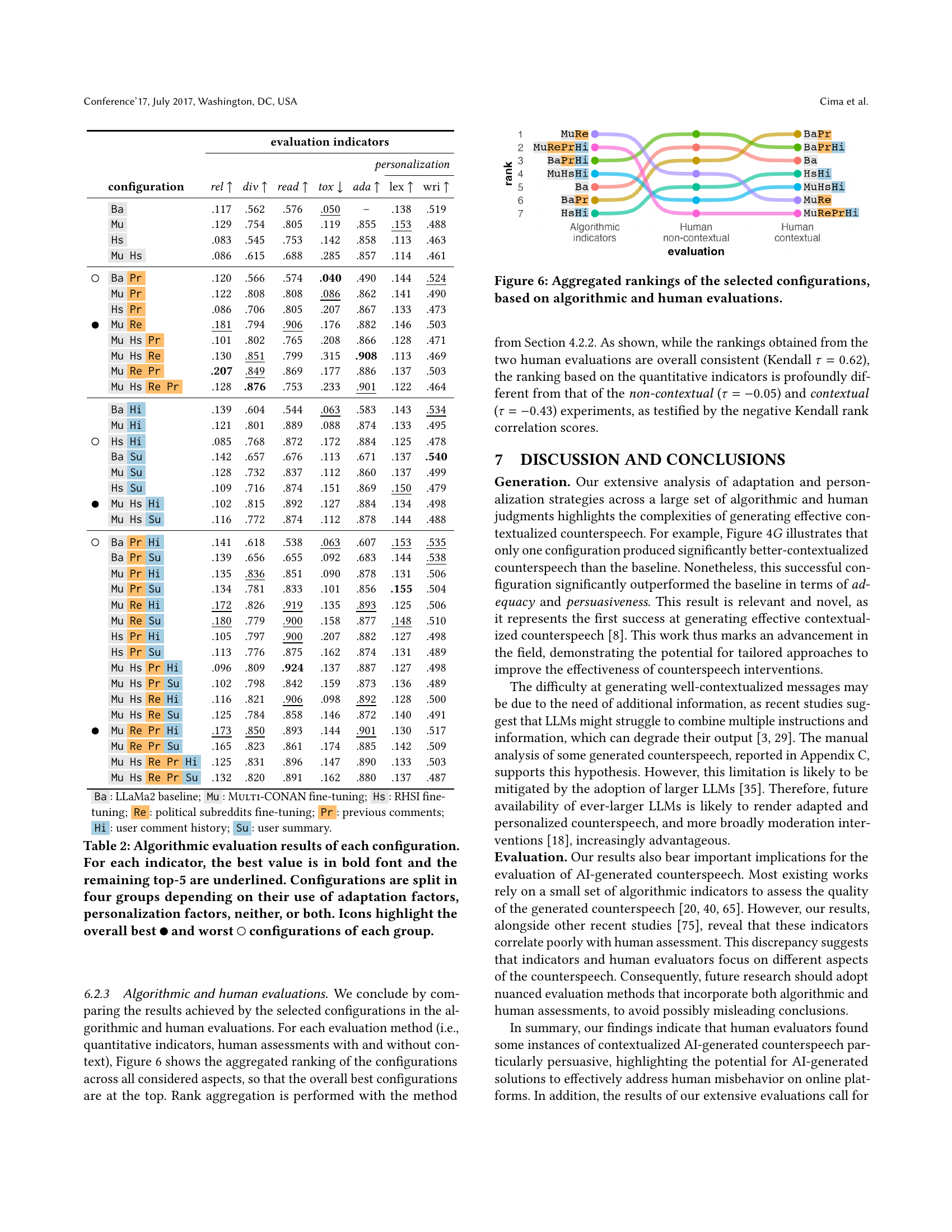
🔼 This figure displays the aggregated rankings of seven configurations of a large language model (LLM) for generating counterspeech. The rankings are based on two types of evaluations: algorithmic (using quantitative indicators such as relevance, diversity, readability, toxicity, adaptation, and personalization) and human (using crowd-sourced ratings on the same aspects, with and without providing the context surrounding the toxic message). The figure visually represents how the configurations performed across various aspects of counterspeech generation in both the algorithmic and human evaluations, allowing for a comparison of the two evaluation methods and highlighting any discrepancies between them. The configurations incorporate various contextual factors such as community style, conversation history, and user-specific information to generate more persuasive and tailored responses.
read the caption
Figure 6. Aggregated rankings of the selected configurations, based on algorithmic and human evaluations.

🔼 Figure 7 presents the results of a human evaluation focusing on participants who use social media very frequently. The evaluation was conducted under non-contextual conditions, meaning participants only saw the toxic messages and the generated counterspeech responses. The figure shows statistical comparisons of seven different configurations of a large language model (LLM) used for generating counterspeech, comparing each configuration to a baseline. Statistical significance is indicated using asterisks: *** represents p<0.01 (highly significant), and ** represents p<0.05 (significant). The figure visualizes the effect sizes and confidence intervals for several metrics, including relevance, adequacy, truthfulness, persuasiveness towards the toxic user and the conversation, and artificiality of the generated counterspeech.
read the caption
Figure 7. Human evaluation results (non-contextual condition) based on answers from those participants who reported using social media “very often”. Statistical significance: ***: p<0.01𝑝0.01p<0.01italic_p < 0.01, **: p<0.05𝑝0.05p<0.05italic_p < 0.05.
Full paper#