↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current document parsing methods struggle with diversity and lack comprehensive evaluation, hindering progress. This paper introduces OmniDocBench, a new benchmark to address these issues. OmniDocBench features a meticulously curated dataset spanning diverse document types, comprehensive annotations (19 layout categories and 14 attributes), and a flexible evaluation framework allowing multi-level assessments.
The comprehensive evaluation using OmniDocBench reveals significant limitations of existing methods, particularly in handling diverse document types. This leads to a fairer evaluation and highlights the need for more robust methods to handle document diversity and fair evaluation standards. OmniDocBench sets a new standard for evaluation and provides crucial insights for future advancements in document parsing technologies.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in document AI and related fields. It addresses the critical need for comprehensive benchmarks in document parsing, offering a large-scale, diverse dataset (OmniDocBench) for fair evaluation. This allows for objective comparison of existing and future methods, guiding the development of more robust and generalizable document parsing technologies. The benchmark’s flexibility also allows researchers to evaluate individual modules and end-to-end systems across multiple dimensions, fostering innovation.
Visual Insights#

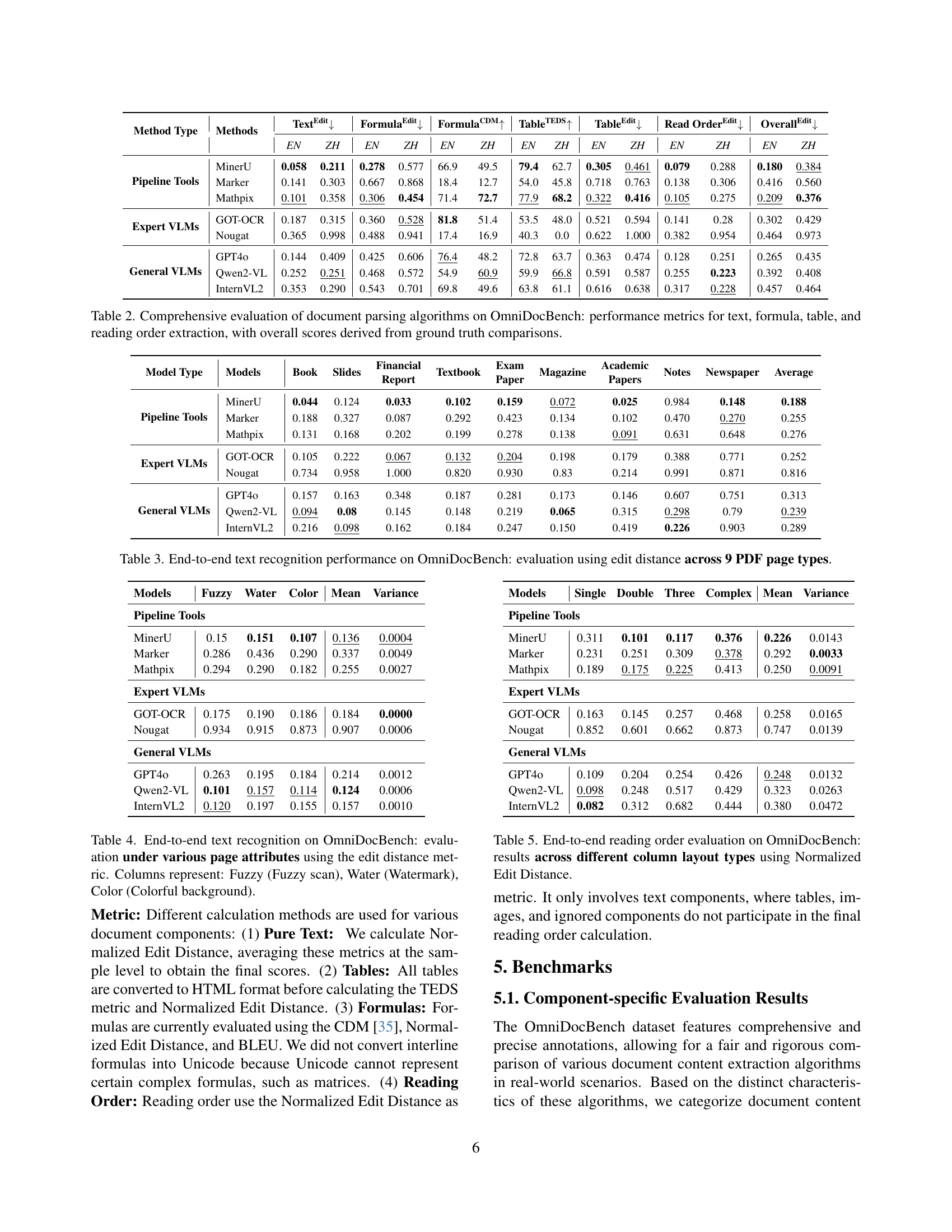
🔼 Figure 1 illustrates the diversity of data within the OmniDocBench dataset. It showcases nine different types of PDF pages included in the benchmark: invoices, academic papers, books, textbooks, magazines, notes, newspapers, financial reports, and slides. The figure highlights that each page type is annotated with both layout annotations (describing the structural elements of the page like text blocks, tables, figures) and recognition annotations (identifying and classifying content within these elements, such as text, formulas, and tables). Beyond the page content, the annotations also capture metadata, including 5 page attributes (like language and whether it has a watermark), 3 text attributes (like text language and color), and 6 table attributes (like frame type and cell merging). This comprehensive annotation provides a multi-level assessment capability across various aspects of document parsing.
read the caption
Figure 1: OmniDocBench Data Diversity. It contains 9 PDF page types, along with Layout Annotations and Recognition Annotations. Furthermore, there are 5 Page Attributes, 3 Text Attributes, and 6 Table Attributes.
| Benchmark | Document Categories | BBox | Text | Table | Order | Formula | OCR | DLA | TR | MFR | OCR | ROD | TR | MFR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Single-Module Eval Benchmark | ||||||||||||||
| Robust Reading [19] | 1 | ✔ | ✔ | |||||||||||
| PubLayNet [43], DocBank [24], DocLayNet [31], M6Doc [7] | 1, 1, 5, 6 | ✔ | ✔ | |||||||||||
| PubTabNet [47],TableX [9], TableBank [23] | 1, 1, 1 | ✔ | ✔ | |||||||||||
| Im2Latex-100K [8],UniMER-Test [34] | 1 | ✔ | ✔ | |||||||||||
| End-to-end Eval Benchmarks | ||||||||||||||
| Nougat [5] | 1 | ✔ | ✔ | ✔ | ✔ | |||||||||
| Fox [27] | 2 | ✔ | ✔ | |||||||||||
| GOT OCR 2.0 [39] | 2 | ✔ | ✔ | ✔ | ||||||||||
| READoc [26] | 2 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||||
| OmniDocBench | 9 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
🔼 This table compares OmniDocBench with other existing document content extraction (DCE) benchmarks. It highlights key differences in the number of document categories, annotation types available (bounding box, text, table, reading order, formula, etc.) and the types of evaluations supported (single-module or end-to-end). Abbreviations used are explained: OCR (Optical Character Recognition), DLA (Document Layout Analysis), MFR (Math Formula Recognition), TR (Table Recognition), and ROD (Reading Order Detection). This allows readers to quickly assess the scope and features of OmniDocBench relative to existing benchmarks.
read the caption
Table 1: A comparison between OmniDocBench and existing DCE benchmarks. OCR: Optical Character Recognition; DLA: Document Layout Analysis; MFR: Math Formula Recognition; TR: Table Recognition; ROD: Reading Order Detection
In-depth insights#
OmniDocBench Data#
The OmniDocBench dataset is a crucial component of the research, offering a multi-source, diverse collection of PDF documents meticulously curated for benchmarking document parsing models. Its strength lies in the comprehensive annotations, including layout, text, formula, table recognition details, and page attributes. This rich annotation allows for multi-level evaluations, assessing individual modules, entire pipelines, or specific document types. The diversity of document types within the dataset is a key feature, moving beyond the limitations of existing benchmarks that often focus heavily on academic papers. By including diverse types such as textbooks, slides, and financial reports, OmniDocBench offers a more realistic evaluation environment, better reflecting real-world scenarios. The careful design and annotation of the dataset ensure fairness and reliability in evaluating various document parsing approaches, facilitating the development of more robust and generalized methods. Therefore, OmniDocBench Data is not merely a dataset; it’s a foundation for fair and comprehensive benchmarking and a key contribution of this work.
Modular Pipeline#
Modular pipelines in document parsing represent a traditional approach characterized by a series of independent modules, each tackling a specific subtask. This approach, while offering explainability and flexibility, often suffers from limitations in handling the diversity of real-world documents. Individual module evaluation becomes the norm, potentially neglecting the overall parsing quality and interactions between modules. This can lead to an incomplete assessment, as isolated module accuracy does not guarantee high-quality results when combined. The process can also be computationally expensive and lacks the elegance of end-to-end methods. Despite these drawbacks, modular pipelines remain valuable for their interpretability and capacity to swap individual components for optimized performance on specific document types. Future advancements should focus on creating more robust frameworks that address diversity, better assess overall performance, and enable a more streamlined workflow while retaining the modularity for fine-grained control and optimization.
Multimodal VLMs#
Multimodal Vision-Language Models (VLMs) represent a significant advancement in the field of document understanding. By integrating visual and textual information, VLMs offer a more comprehensive approach to document parsing than traditional, modular methods. Unlike pipeline systems that process different aspects of documents sequentially, VLMs process both image and text data simultaneously, potentially leading to improved accuracy and efficiency. This holistic approach allows for a better understanding of document layout and structure, leading to more accurate content extraction. However, current evaluations of VLMs often lack diversity and comprehensive metrics, hindering a fair comparison and the identification of limitations. A key challenge lies in establishing a standardized benchmark that encompasses a wide range of document types and includes diverse and granular annotation, enabling a more thorough assessment of VLM performance across various aspects of the document parsing task. The development of such benchmarks is crucial for driving progress and fostering innovation in multimodal document understanding.
Evaluation Metrics#
Choosing the right evaluation metrics is crucial for assessing the performance of any document parsing system. A good set of metrics should capture various aspects of the parsing process, including the accuracy of layout detection, text recognition, table extraction, and formula recognition. Commonly used metrics like precision, recall, and F1-score provide a basic assessment of accuracy, but they often fail to capture the nuances of document structure and context. More sophisticated metrics are needed, such as BLEU or ROUGE scores for evaluating the textual content of the extracted information, and metrics that specifically address the structural aspects, like accuracy in capturing tables and formulas. The choice of metrics should always depend on the specific tasks and the nature of the documents being parsed. A comprehensive evaluation requires a combination of both general and task-specific metrics, allowing for a more thorough and nuanced understanding of the model’s strengths and weaknesses. Furthermore, the use of human evaluation to assess the quality of the parsed output remains an essential aspect of building robust and reliable document parsing systems.
Future Directions#
The “Future Directions” section of a research paper on PDF parsing would ideally explore several key areas. Extending OmniDocBench to include even more diverse document types (e.g., handwritten forms, scanned images with significant noise, multilingual documents with complex layouts) is crucial for evaluating robustness and generalization. Improving annotation quality remains paramount; potentially leveraging advanced AI techniques for automated annotation and incorporating uncertainty estimations could be beneficial. Developing more sophisticated evaluation metrics is another critical area, moving beyond simple accuracy scores to capture nuanced aspects like semantic understanding and context awareness. The exploration of novel hybrid approaches that combine the strengths of modular pipelines and end-to-end models could yield significant performance gains. Finally, investigating the ethical implications of automated document parsing, particularly around bias and fairness, is essential for responsible development and deployment of these powerful technologies. A focus on explainable AI (XAI) would also enhance trust and allow for greater debugging and refinement of the models.
More visual insights#
More on figures

🔼 This figure illustrates the process of creating the OmniDocBench dataset. It starts with data acquisition from various web sources and internal data, resulting in 200,000 initial PDF documents. These are then filtered down to 6,000 visually diverse pages through a feature clustering and sampling process. A manual selection step balances the dataset across page types and attributes to a final 981 pages. Annotation then involves stages of automated annotation using state-of-the-art vision models, manual corrections by annotators, and finally, expert quality inspection by PhD-level researchers to ensure accuracy. This multi-stage process generates layout and content annotations, which are then used to build the dataset.
read the caption
Figure 2: Overview of the OmniDocBench dataset construction.

🔼 This figure illustrates the detailed evaluation pipeline used in the OmniDocBench benchmark. It shows the process flow, starting from model predictions (markdown, LaTeX, HTML, etc.) that are preprocessed and then matched to the ground truth annotations. The pipeline includes stages for extracting special components (tables, formulas, code blocks), extracting pure text, converting inline formula formats, and handling reading order. Finally, the pipeline calculates several metrics to assess the quality of document content extraction.
read the caption
Figure 3: OmniDocBench Evaluation Pipeline.

🔼 Table S4 provides a statistical overview of text attributes within the OmniDocBench dataset. It details the count of each attribute type, offering insights into the diversity of text characteristics in the dataset. Attributes include language (English, Simplified Chinese, and mixed), text background color (white, single-colored, and multi-colored), and text rotation (normal, rotated 90°, 270°, and horizontal). This table is crucial for understanding the complexity and diversity of the OmniDocBench dataset and how these attributes influence the performance of different document parsing algorithms.
read the caption
Table S4: Text Attributes Statistics of OmniDocBench.

🔼 Table S5 presents a statistical overview of the Table Attributes within the OmniDocBench dataset. It details the frequency of different table attributes, such as language (English, Simplified Chinese, or mixed), frame type (full frame, omission line, three lines, or no frame), special situations (merged cells, presence of formulas, colorful background, or rotation), providing insights into the diversity and complexity of tables included in the benchmark dataset.
read the caption
Table S5: Table Attributes Statistics of OmniDocBench.

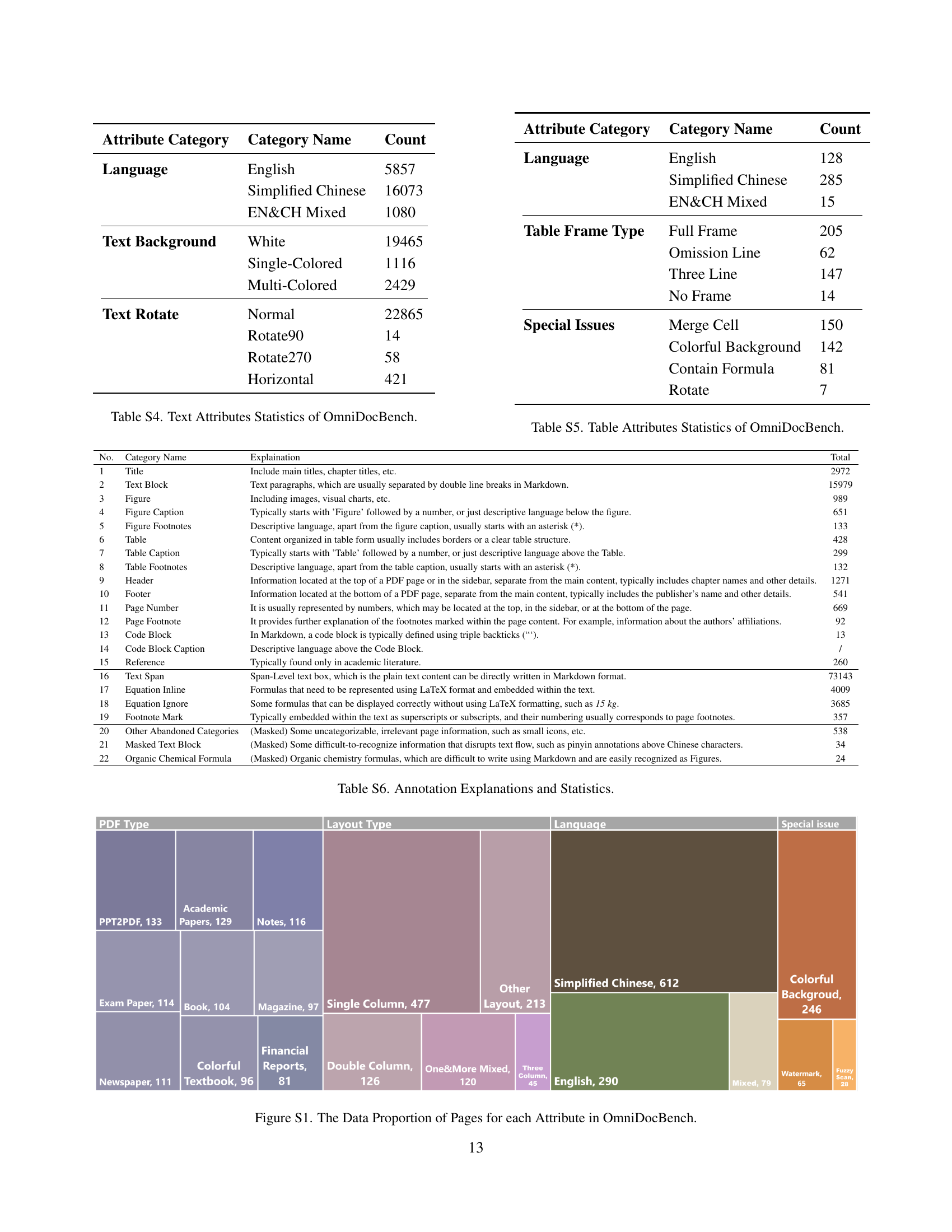
🔼 This figure shows the distribution of various attributes across the OmniDocBench dataset. It visually represents the percentage of pages that possess each attribute, offering insight into the dataset’s diversity and the prevalence of specific characteristics in the collected documents. Attributes may include page type (e.g., academic paper, newspaper), layout type (single column, double column), language (English, Chinese), and special characteristics (e.g., watermark, fuzzy scan, colored background). The visualization allows for a quick understanding of the dataset’s composition and balance across different document attributes.
read the caption
Figure S1: The Data Proportion of Pages for each Attribute in OmniDocBench.

🔼 Figure S2 visualizes the comprehensive annotation framework used in OmniDocBench. It showcases the diversity of annotations applied across different page types, including bounding boxes for various content elements (text, tables, figures, etc.), layout attributes (columns, frames, rotations), reading order, and text attributes (language, background color). This visualization demonstrates OmniDocBench’s rich annotation detail, highlighting the complexity and nuance captured for robust evaluation of document parsing models.
read the caption
Figure S2: The Visualization of vary Annotations in OmniDocBench.

🔼 This figure visually showcases the diversity of document types included in the OmniDocBench dataset. It provides example pages from various sources such as academic papers, textbooks, notes, books, and magazines, to illustrate the wide range of document layouts and content included in the benchmark. The goal is to visually demonstrate the breadth and complexity of document types present in OmniDocBench, highlighting the challenge involved in creating a robust, diverse and fair evaluation standard for document content extraction.
read the caption
Figure S3: The Examples of Academic Papers, Books, Textbooks, Notes, and Magazines in OmniDocBench.

🔼 Figure S4 presents a visual representation of the diversity within the OmniDocBench dataset. It showcases examples of four distinct document categories included in the benchmark: financial reports, newspapers, exam papers, and slides. Each category displays several sample pages, highlighting the variety in layout, structure, content type, language, and visual elements found within real-world documents. This diversity is crucial in evaluating the robustness and generalization capabilities of document parsing models.
read the caption
Figure S4: The Examples of Finacial Reports, Newspapers, Example Papers, and Slides in OmniDocBench.

🔼 Figure S5 presents various examples of PDF pages from the OmniDocBench dataset, categorized by their layout structures. Each example visually demonstrates different layout styles including single-column, double-column, three-column, and complex layouts. This showcases the diversity of document layouts encompassed within the OmniDocBench benchmark, highlighting its capacity to evaluate document parsing models’ ability to handle diverse page designs.
read the caption
Figure S5: The Examples of PDF pages with different Layout Types in OmniDocBench.

🔼 Figure S6 presents example PDF pages from OmniDocBench that exhibit various special issues commonly encountered in real-world document processing. These issues include: pages with fuzzy scans (blurry text), watermarks obscuring content, and pages with colorful backgrounds that can interfere with text extraction and layout analysis. These examples showcase the challenges that a robust document parsing model must address to achieve high performance on diverse and imperfect document scans.
read the caption
Figure S6: The Examples of PDF pages under Special Issues in OmniDocBench.

🔼 This figure showcases various table examples from the OmniDocBench dataset, highlighting the diversity in table frames. It visually demonstrates the different types of frames present in the dataset, including tables with full frames, tables with omission lines, tables with three lines, and tables without any frames. This variety is crucial for evaluating table recognition models and ensures they are tested against realistic scenarios.
read the caption
Figure S7: The Examples of Tables with different Frame in OmniDocBench.

🔼 This figure showcases examples of tables within the OmniDocBench dataset that present special characteristics or issues. These special cases highlight the challenges in real-world document parsing, such as tables with merged cells, those containing formulas, tables with colorful backgrounds, or tables that have been rotated.
read the caption
Figure S8: The Examples of Tables under Special Issues in OmniDocBench.

🔼 This figure in the supplementary material showcases a comparison of results from a good-performing model and a poorly performing model when processing academic papers. It visually demonstrates the differences in terms of accuracy and completeness of content extraction. The figure highlights the superior performance of the good model in accurately identifying and extracting textual content, formulas, tables, and other key elements within academic papers, compared to the inferior results of the other model, which may miss or incorrectly extract components.
read the caption
Figure S9: The Good Model Result and Bad Model Result for Academic Papers.

🔼 Figure S10 presents a comparison of the results produced by a high-performing model (good model) and a poorly performing model (bad model) when processing book-type PDF pages. The figure visually showcases how well each model extracts and presents the content, highlighting the differences in accuracy and completeness of text, table, formula, image extraction, and overall layout interpretation.
read the caption
Figure S10: The Good Model Result and Bad Model Result for Books.

🔼 This figure shows a comparison of how well different models perform on exam papers from the OmniDocBench dataset. The ‘good model result’ side displays examples where the model accurately extracts and formats the text and other elements of the exam paper. Conversely, the ‘bad model result’ side presents instances where the model struggles with accurate extraction and formatting, highlighting common issues like incorrect recognition of text blocks, layout misinterpretations, or missing content. This comparison is crucial for understanding the limitations of different models in handling complex document structures and content variations frequently found in exam papers.
read the caption
Figure S11: The Good Model Result and Bad Model Result for Exam Papers.

🔼 Figure S12 presents a comparison of how well different models perform on magazine pages. The ‘good model’ example shows accurate extraction of text, images, and layout elements with minimal errors. In contrast, the ‘bad model’ example highlights common issues in automated magazine parsing such as incomplete text extraction, incorrect layout recognition, and the inability to properly handle complex visual elements. This illustrates the challenges involved in processing visually rich and diverse document layouts and the varying capabilities of different models.
read the caption
Figure S12: The Good Model Result and Bad Model Result for Magazines.

🔼 This figure in the supplementary materials presents a comparison of how well different document parsing models perform on newspaper content. It visually shows examples of successful extractions (good model results) and examples of incorrect or missing information (bad model results) from the same newspaper page. This allows for a direct comparison of the accuracy and completeness of different models in handling this specific type of document.
read the caption
Figure S13: The Good Model Result and Bad Model Result for Newspaper.

🔼 Figure S14 presents a comparison of how well different models (Mineru and InternVL2) perform on handwritten notes. The ‘Good Model Result’ shows accurate transcription of the handwritten text by Mineru. The ‘Bad Model Result’ shows that InternVL2 struggles with accurate transcription and experiences problems, indicated by missing parts of text represented with ‘—Handle Writing Text Missing—’. This highlights the challenge of processing handwritten documents, a common problem in document parsing.
read the caption
Figure S14: The Good Model Result and Bad Model Result for Handwriting Notes.

🔼 This figure in the supplementary materials presents a comparison of the financial report parsing results produced by different models. It showcases examples where models successfully extracted key information (good model results) versus cases where the results contained errors, omissions, or other issues (bad model results). The visualization likely highlights the differences in accuracy and effectiveness between different methods on a specific document type, namely financial reports.
read the caption
Figure S15: The Good Model Result and Bad Model Result for Financial Reports.

🔼 This figure displays a comparison of how well different models perform on slide-type documents. It shows examples of good and bad model outputs, highlighting the strengths and weaknesses of various algorithms in accurately extracting and representing the visual and textual content of slides. Specific examples may include issues with layout analysis, text recognition, or the handling of diagrams and other non-textual elements frequently found in presentations.
read the caption
Figure S16: The Good Model Result and Bad Model Result for Slides.

🔼 This figure in the supplementary materials visually compares the results of document content extraction from textbook pages using a good-performing model versus a poorly performing model. It highlights the differences in accuracy and completeness of the extracted information, showcasing the challenges associated with parsing complex layouts and formatting commonly found in textbooks. The differences shown help demonstrate the importance of a comprehensive evaluation benchmark such as OmniDocBench.
read the caption
Figure S17: The Good Model Result and Bad Model Result for Textbooks.

🔼 This figure in the supplementary material showcases the results of document parsing on PDF pages with fuzzy scans, comparing the output of well-performing models (good results) against those of poorly-performing models (bad results). It visually demonstrates the challenges posed by low-quality scans in the context of automated document parsing and the varying capabilities of different methods in handling such images.
read the caption
Figure S18: The Good Model Result and Bad Model Result for Fuzzy Scan Pages.

🔼 This figure in the supplementary material section visualizes the performance difference between good and bad models in handling PDF pages containing watermarks. It showcases examples of pages with watermarks and how different models either successfully extract the content or fail due to the presence of the watermarks. This helps demonstrate the robustness and limitations of various models in managing challenging real-world scenarios.
read the caption
Figure S19: The Good Model Result and Bad Model Result for Pages with Watermark.

🔼 This figure in the supplementary material showcases examples from OmniDocBench where pages have colorful backgrounds. It presents a comparison between the results produced by a high-performing model (the ‘Good Model’) and a model that struggles with colorful backgrounds (the ‘Bad Model’). The goal is to highlight how well different models handle challenging scenarios, such as complex visual backgrounds that might interfere with accurate document content extraction.
read the caption
Figure S20: The Good Model Result and Bad Model Result for Colorful Background Pages.

🔼 This figure showcases a comparison of the results from good and bad models when processing single-column PDF pages. It visually demonstrates the differences in accuracy and effectiveness of various models in extracting information and maintaining proper layout from this specific page type. The visual comparison highlights the strengths and weaknesses of each model in handling text and structural elements within single-column layouts.
read the caption
Figure S21: The Good Model Result and Bad Model Result for Single Column Pages.

🔼 This figure showcases a comparison of how well different models handled double-column layouts in PDF documents. It presents examples of a ‘good’ model’s output (correctly parsing the text and layout) alongside examples from a ‘bad’ model (failing to accurately represent the document structure). This visualization helps illustrate the challenges inherent in processing complex document layouts and how different model architectures tackle (or fail to tackle) these challenges.
read the caption
Figure S22: The Good Model Result and Bad Model Result for Double Column Pages.

🔼 This figure showcases the results of document parsing on pages with three columns using two different models. The ‘Good Model Result’ demonstrates high accuracy in content extraction, maintaining proper column separation and order. In contrast, the ‘Bad Model Result’ shows errors in column identification, content merging across columns, and disrupted reading order, highlighting the challenges of three-column layout parsing.
read the caption
Figure S23: The Good Model Result and Bad Model Result for Three Column Pages.

🔼 Figure S24 showcases a comparison of how well different models parse complex page layouts in the OmniDocBench dataset. The figure visualizes the output of a model considered to perform well (‘good model’), juxtaposed with the output of a model that does not perform as well (‘bad model’). This comparison helps illustrate the varying levels of accuracy and effectiveness in handling complex document structures and is part of a larger evaluation within the paper.
read the caption
Figure S24: The Good Model Result and Bad Model Result for Complex Layout Pages.

🔼 This figure in the supplementary material showcases a comparison between the results of good and bad models when processing text written in Chinese. The comparison focuses on how well each model can extract and interpret text, highlighting the differences in accuracy and robustness between effective and less effective approaches in handling the nuances of the Chinese language.
read the caption
Figure S25: The Good Model Result and Bad Model Result for Text Language in Chinese.

🔼 This figure compares the results of two different models (a good model and a bad model) when processing text in English. It visually showcases the differences in accuracy and how effectively each model handles English text within the context of document parsing.
read the caption
Figure S26: The Good Model Result and Bad Model Result for Text Language in English.

🔼 This figure in the supplementary material section visualizes the results of text recognition models’ performance on PDF pages with colorful backgrounds. It directly compares the output of a high-performing model (the ‘Good Model’) against a lower-performing model (the ‘Bad Model’). This allows for a visual inspection of how the models handle text extraction when faced with complex backgrounds. Differences in accuracy and ability to correctly interpret text can be observed.
read the caption
Figure S27: The Good Model Result and Bad Model Result for Text with Colorful Background.

🔼 This figure in the supplementary material section visualizes the poor performance of a model in recognizing text when it is rotated. It shows the ground truth (correct text) alongside the model’s inaccurate transcription of the rotated text. This highlights the model’s limitations in handling text orientation variations, which is a common challenge in document image analysis.
read the caption
Figure S28: The Bad Model Result for Text with Rotation.

🔼 This figure showcases a comparison between the results of a high-performing model (good model) and a lower-performing model (bad model) for tables with three lines in their frames. It highlights the differences in accuracy and effectiveness of different models in parsing tables with specific characteristics, such as line style or quantity.
read the caption
Figure S29: The Good Model Result and Bad Model Result for Three Line Frame Table.

🔼 This figure showcases a comparison of how different models perform on tables without frames. It highlights the discrepancies in table recognition accuracy between a well-performing model (good model) and a poorly performing model (bad model). The visual comparison demonstrates the challenges posed by the absence of frames in accurate table extraction.
read the caption
Figure S30: The Good Model Result and Bad Model Result for No Frame Table.
More on tables
🔼 This table presents a comprehensive evaluation of various document parsing algorithms using the OmniDocBench benchmark dataset. It provides performance metrics for four key sub-tasks: text, formula, and table extraction, as well as reading order detection. For each algorithm and each task, the table shows scores in both English and Chinese, allowing for comparison across languages. Finally, it displays an overall score derived by comparing the algorithm’s output to the ground truth.
read the caption
Table 2: Comprehensive evaluation of document parsing algorithms on OmniDocBench: performance metrics for text, formula, table, and reading order extraction, with overall scores derived from ground truth comparisons.
| Model Type | Models | Book | Slides | Financial Report | Textbook | Exam Paper | Magazine | Academic Papers | Notes | Newspaper | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools | MinerU | 0.044 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.148 | 0.188 |
| Marker | 0.188 | 0.327 | 0.087 | 0.292 | 0.423 | 0.134 | 0.102 | 0.470 | 0.270 | 0.255 | |
| Mathpix | 0.131 | 0.168 | 0.202 | 0.199 | 0.278 | 0.138 | 0.091 | 0.631 | 0.648 | 0.276 | |
| Expert VLMs | GOT-OCR | 0.105 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.252 |
| Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.83 | 0.214 | 0.991 | 0.871 | 0.816 | |
| General VLMs | GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.313 |
| Qwen2-VL | 0.094 | 0.08 | 0.145 | 0.148 | 0.219 | 0.065 | 0.315 | 0.298 | 0.79 | 0.239 | |
| InternVL2 | 0.216 | 0.098 | 0.162 | 0.184 | 0.247 | 0.150 | 0.419 | 0.226 | 0.903 | 0.289 |
🔼 This table presents a comprehensive evaluation of end-to-end text recognition performance across nine diverse document types within the OmniDocBench benchmark. It utilizes edit distance as the evaluation metric to measure the accuracy of text extraction methods on various document types, offering insights into the strengths and weaknesses of different models in handling diverse document layouts and content styles.
read the caption
Table 3: End-to-end text recognition performance on OmniDocBench: evaluation using edit distance across 9 PDF page types.
| Models | Fuzzy | Water | Color | Mean | Variance |
|---|---|---|---|---|---|
| Pipeline Tools | |||||
| MinerU | 0.15 | 0.151 | 0.107 | 0.136 | 0.0004 |
| Marker | 0.286 | 0.436 | 0.290 | 0.337 | 0.0049 |
| Mathpix | 0.294 | 0.290 | 0.182 | 0.255 | 0.0027 |
| Expert VLMs | |||||
| GOT-OCR | 0.175 | 0.190 | 0.186 | 0.184 | 0.0000 |
| Nougat | 0.934 | 0.915 | 0.873 | 0.907 | 0.0006 |
| General VLMs | |||||
| GPT4o | 0.263 | 0.195 | 0.184 | 0.214 | 0.0012 |
| Qwen2-VL | 0.101 | 0.157 | 0.114 | 0.124 | 0.0006 |
| InternVL2 | 0.120 | 0.197 | 0.155 | 0.157 | 0.0010 |
🔼 This table presents the end-to-end text recognition performance on the OmniDocBench dataset, broken down by various page attributes. The evaluation metric used is the edit distance. The columns represent different image qualities: Fuzzy (presence of a fuzzy scan), Water (presence of a watermark), and Color (presence of a colorful background). The results show how well different models perform under various image conditions, indicating their robustness and generalizability.
read the caption
Table 4: End-to-end text recognition on OmniDocBench: evaluation under various page attributes using the edit distance metric. Columns represent: Fuzzy (Fuzzy scan), Water (Watermark), Color (Colorful background).
| Models | Single | Double | Three | Complex | Mean | Variance |
|---|---|---|---|---|---|---|
| Pipeline Tools | ||||||
| MinerU | 0.311 | 0.101 | 0.117 | 0.376 | 0.226 | 0.0143 |
| Marker | 0.231 | 0.251 | 0.309 | 0.378 | 0.292 | 0.0033 |
| Mathpix | 0.189 | 0.175 | 0.225 | 0.413 | 0.250 | 0.0091 |
| Expert VLMs | ||||||
| GOT-OCR | 0.163 | 0.145 | 0.257 | 0.468 | 0.258 | 0.0165 |
| Nougat | 0.852 | 0.601 | 0.662 | 0.873 | 0.747 | 0.0139 |
| General VLMs | ||||||
| GPT4o | 0.109 | 0.204 | 0.254 | 0.426 | 0.248 | 0.0132 |
| Qwen2-VL | 0.098 | 0.248 | 0.517 | 0.429 | 0.323 | 0.0263 |
| InternVL2 | 0.082 | 0.312 | 0.682 | 0.444 | 0.380 | 0.0472 |
🔼 This table presents the performance of various document content extraction models in terms of reading order accuracy, specifically focusing on how well the models handle documents with different numbers of columns. The evaluation metric used is the Normalized Edit Distance, which quantifies the difference between the predicted reading order and the ground truth reading order. The results provide insights into the models’ ability to accurately capture the reading sequence in documents of varying complexity.
read the caption
Table 5: End-to-end reading order evaluation on OmniDocBench: results across different column layout types using Normalized Edit Distance.
| Model | Book | Slides | Research | Report | Textbook | Exam | Paper | Academic | Literature | Notes | Newspaper | Average mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DiT-L | 43.44 | 13.72 | 45.85 | 15.45 | 3.40 | 29.23 | 66.13 | 0.21 | 23.65 | 26.90 | ||
| LayoutLMv3 | 42.12 | 13.63 | 43.22 | 21.00 | 5.48 | 31.81 | 64.66 | 0.80 | 30.84 | 28.84 | ||
| DOCX-Chain | 30.86 | 11.71 | 39.62 | 19.23 | 10.67 | 23.00 | 41.60 | 1.80 | 16.96 | 21.27 | ||
| DocLayout-YOLO | 43.71 | 48.71 | 72.83 | 42.67 | 35.40 | 51.44 | 66.84 | 9.54 | 57.54 | 48.71 |
🔼 Table 6 presents a detailed breakdown of the performance of component-level layout detection models across various PDF page types within the OmniDocBench benchmark dataset. The mean Average Precision (mAP) metric is used to assess the accuracy of layout detection for each document category. This provides insights into the strengths and weaknesses of different models in handling the diverse layout structures found in real-world documents. The table allows for a granular analysis of performance across different document types, facilitating a more comprehensive understanding of the challenges and opportunities in document layout analysis.
read the caption
Table 6: Component-level layout detection evaluation on OmniDocBench layout subset: mAP results by PDF page type.
| Model Type | Model | Language EN | Language ZH | Language Mixed | Table Frame Type Full | Table Frame Type Omission | Table Frame Type Three | Table Frame Type Zero | Special Situation Merge Cell (+/-) | Special Situation Formula (+/-) | Special Situation Colorful (+/-) | Special Situation Rotate (+/-) | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCR-based Models | PaddleOCR | 76.8 | 71.8 | 80.1 | 67.9 | 74.3 | 81.1 | 74.5 | 70.6/75.2 | 71.3/74.1 | 72.7/74.0 | 23.3/74.6 | 73.6 |
| RapidTable | 80.0 | 83.2 | 91.2 | 83.0 | 79.7 | 83.4 | 78.4 | 77.1/85.4 | 76.7/83.9 | 77.6/84.9 | 25.2/83.7 | 82.5 | |
| Expert VLMs | StructEqTable | 72.0 | 72.6 | 81.7 | 68.8 | 64.3 | 80.7 | 85.0 | 65.1/76.8 | 69.4/73.5 | 66.8/75.7 | 44.1/73.3 | 72.7 |
| GOT-OCR | 72.2 | 75.5 | 85.4 | 73.1 | 72.7 | 78.2 | 75.7 | 65.0/80.2 | 64.3/77.3 | 70.8/76.9 | 8.5/76.3 | 74.9 | |
| General VLMs | Qwen2-VL-7B | 70.2 | 70.7 | 82.4 | 70.2 | 62.8 | 74.5 | 80.3 | 60.8/76.5 | 63.8/72.6 | 71.4/70.8 | 20.0/72.1 | 71.0 |
| InternVL2-8B | 70.9 | 71.5 | 77.4 | 69.5 | 69.2 | 74.8 | 75.8 | 58.7/78.4 | 62.4/73.6 | 68.2/73.1 | 20.4/72.6 | 71.5 |
🔼 This table presents a detailed breakdown of the performance of various models on the table recognition task within the OmniDocBench benchmark dataset. It assesses the accuracy of different models across nine diverse document types. The evaluation considers both standard table scenarios and those with special characteristics (indicated by +/-), such as merged cells, rotated text, and more. This allows for a comprehensive comparison of model performance under various conditions.
read the caption
Table 7: Component-level Table Recognition evaluation on OmniDocBench table subset. (+/-) means with/without special situation.
| Model Type | Model | Language EN | Language ZH | Language Mixed | Text background White | Text background Single | Text background Multi | Text Rotate Normal | Text Rotate Rotate90 | Text Rotate Rotate270 | Text Rotate Horizontal |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Expert Vision Models | PaddleOCR | 0.071 | 0.055 | 0.118 | 0.060 | 0.038 | 0.085 | 0.060 | 0.015 | 0.285 | 0.021 |
| Tesseract OCR | 0.179 | 0.553 | 0.553 | 0.453 | 0.463 | 0.394 | 0.448 | 0.369 | 0.979 | 0.982 | |
| Surya | 0.057 | 0.123 | 0.164 | 0.093 | 0.186 | 0.235 | 0.104 | 0.634 | 0.767 | 0.255 | |
| GOT-OCR | 0.041 | 0.112 | 0.135 | 0.092 | 0.052 | 0.155 | 0.091 | 0.562 | 0.966 | 0.097 | |
| Mathpix | 0.033 | 0.240 | 0.261 | 0.185 | 0.121 | 0.166 | 0.180 | 0.038 | 0.185 | 0.638 | |
| Vision Language Models | Qwen2-VL | 0.072 | 0.274 | 0.286 | 0.234 | 0.155 | 0.148 | 0.223 | 0.273 | 0.721 | 0.067 |
| InternVL2 | 0.074 | 0.155 | 0.242 | 0.113 | 0.352 | 0.269 | 0.132 | 0.610 | 0.907 | 0.595 | |
| GPT4o | 0.020 | 0.224 | 0.125 | 0.167 | 0.140 | 0.220 | 0.168 | 0.115 | 0.718 | 0.132 |
🔼 This table presents a comprehensive evaluation of OCR performance on the OmniDocBench dataset, broken down by various text attributes. It shows the edit distance results for different OCR models, categorized by language (English, Chinese, mixed), text background color (white, single-colored, multi-colored), and text rotation (normal, rotated 90°, rotated 270°, horizontal). This allows for a detailed analysis of OCR accuracy under diverse conditions and provides insights into the strengths and weaknesses of different OCR models.
read the caption
Table 8: Component-level evaluation on OmniDocBench OCR subset: results grouped by text attributes using the edit distance metric.
| Models | CDM | ExpRate@CDM | BLEU | Norm Edit |
|---|---|---|---|---|
| GOT-OCR | 74.1 | 28.0 | 55.07 | 0.290 |
| Mathpix | 86.6 | 2.8 | 66.56 | 0.322 |
| Pix2Tex | 73.9 | 39.5 | 46.00 | 0.337 |
| UniMERNet-B | 85.0 | 60.2 | 60.84 | 0.238 |
| GPT4o | 86.8 | 65.5 | 45.17 | 0.282 |
| InternVL2 | 67.4 | 54.5 | 47.63 | 0.308 |
| Qwen2-VL | 83.8 | 55.4 | 53.71 | 0.285 |
🔼 Table 9 presents a comprehensive evaluation of formula recognition algorithms on the OmniDocBench dataset, specifically focusing on the formula subset. It details the performance of various models in accurately recognizing and extracting formula information from diverse document types within the benchmark.
read the caption
Table 9: Component-level formula recognition evaluation on OmniDocBench formula subset.
| Model Type | Model | Language EN | Language ZH | Language Mixed | Table Frame Type Full | Table Frame Type Omission | Table Frame Type Three | Table Frame Type Zero | Special Situation Merge Cell (+/-) | Special Situation Formula (+/-) | Special Situation Colorful (+/-) | Special Situation Rotate (+/-) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools | MinerU | 75.7 | 59.9 | 79.6 | 60.0 | 72.8 | 70.1 | 60.4 | 64.1/66.0 | 66.7/65.0 | 59.8/68.1 | 2.9/66.4 |
| Marker | 52.5 | 43.0 | 44.2 | 41.8 | 55.3 | 47.1 | 52.4 | 43.8/47.0 | 42.9/46.6 | 44.3/46.7 | 6.3/46.6 | |
| Mathpix | 76.1 | 64.3 | 71.9 | 68.3 | 79.3 | 67.0 | 25.8 | 71.2/66.4 | 69.8/67.6 | 60.5/71.8 | 20.7/68.8 | |
| Expert Vision Models | GOT-OCR | 51.9 | 47.0 | 49.4 | 46.2 | 49.3 | 51.6 | 47.2 | 46.5/49.7 | 46.4/49.1 | 40.2/52.7 | 0.0/49.4 |
| Nougat | 36.5 | 0.4 | 0.0 | 6.3 | 3.6 | 22.2 | 0.0 | 15.1/9.1 | 21.2/8.9 | 2.8/15.3 | 0.0/11.4 | |
| Vision Language Models | GPT4o | 71.8 | 58.8 | 57.9 | 63.3 | 69.5 | 61.9 | 31.8 | 57.5/65.5 | 61.6/62.9 | 62.0/63.0 | 14.5/63.5 |
| Qwen2-VL | 57.4 | 62.9 | 72.7 | 70.7 | 64.1 | 48.3 | 57.6 | 49.4/68.2 | 48.5/64.7 | 63.5/60.7 | 41.6/61.9 | |
| InterVL2 | 61.5 | 59.3 | 65.9 | 59.7 | 66.5 | 58.7 | 56.2 | 49.6/65.9 | 54.4/61.6 | 59.4/60.6 | 7.3/61.1 |
🔼 This table presents the end-to-end table recognition performance, evaluated using the Tree Edit Distance (TEDS) metric. Results are broken down by various table attributes such as language (English, Chinese, or mixed), table frame type (full frame, omission line, three lines, or no frame), and presence of special features (merged cells, formulas, colorful background, or rotation). This detailed breakdown allows for a nuanced understanding of how different table characteristics affect model performance.
read the caption
Table S1: End-to-End Table TEDS Result grouped by Table Attributes
| Model Type | Model | Language EN | Language ZH | Language Mixed | Text background White | Text background Single | Text background Multi |
|---|---|---|---|---|---|---|---|
| Pipeline Tools | MinerU | 0.123 | 0.206 | 0.742 | 0.163 | 0.147 | 0.513 |
| Marker | 0.267 | 0.389 | 0.499 | 0.339 | 0.389 | 0.497 | |
| Mathpix | 0.173 | 0.774 | 0.538 | 0.675 | 0.554 | 0.570 | |
| Expert Vision Models | GOT-OCR | 0.251 | 0.763 | 0.266 | 0.669 | 0.595 | 0.440 |
| Nougat | 0.587 | 0.991 | 0.983 | 0.874 | 0.935 | 0.972 | |
| Vision Language Models | GPT4o | 0.170 | 0.647 | 0.322 | 0.536 | 0.423 | 0.406 |
| Qwen2-VL | 0.337 | 0.575 | 0.310 | 0.537 | 0.400 | 0.233 | |
| InternVL2 | 0.418 | 0.606 | 0.251 | 0.589 | 0.366 | 0.221 |
🔼 Table S2 presents a detailed breakdown of the end-to-end text recognition performance, evaluated using the Normalized Edit Distance metric. The results are categorized based on three text attributes: language (English, Chinese, or Mixed), text background color (Single or Multi), and text rotation (Normal, Rotate90, Rotate270, or Horizontal). This granular analysis helps to understand how different text characteristics affect the accuracy of the document parsing models.
read the caption
Table S2: End-to-End Text Normalized Edit Distance results grouped by Text Attributes. “Mixed” represents a mixture of Chinese and English, “Single” and “Multi” represent single color and multi color.
| Category | Attribute Name | Count |
|---|---|---|
| PDF Type | Book | 104 |
| PPT2PDF | 133 | |
| Research Report | 81 | |
| Colorful Textbook | 96 | |
| Exam Paper | 114 | |
| Magazine | 97 | |
| Academic Literature | 129 | |
| Notes | 116 | |
| Newspaper | 111 | |
| Layout Type | Single Column | 477 |
| Double Column | 126 | |
| Three Column | 45 | |
| One&More Mixed | 120 | |
| Complex Layout | 213 | |
| Language | English | 290 |
| Simplified Chinese | 612 | |
| Mixed | 79 | |
| Special Issues | Fuzzy Scan | 28 |
| Watermark | 65 | |
| Colorful Background | 246 |
🔼 Table S3 presents a detailed breakdown of the statistics for various page attributes within the OmniDocBench dataset. It shows the count of pages exhibiting specific characteristics like PDF type, layout type, language, and special issues (watermarks, colored backgrounds, fuzzy scans). This provides a comprehensive overview of the dataset’s diversity and the distribution of different page attributes.
read the caption
Table S3: The Page Attributes Statistics of OmniDocBench.
| Attribute Category | Category Name | Count |
|---|---|---|
| Language | English | 5857 |
| Simplified Chinese | 16073 | |
| EN&CH Mixed | 1080 | |
| Text Background | White | 19465 |
| Single-Colored | 1116 | |
| Multi-Colored | 2429 | |
| Text Rotate | Normal | 22865 |
| Rotate90 | 14 | |
| Rotate270 | 58 | |
| Horizontal | 421 |
🔼 Table S6 provides detailed explanations and statistics for each annotation category in the OmniDocBench dataset. It lists the category name, a description of what constitutes that category, and the total count of annotations within that category. The categories include various layout elements (titles, text blocks, figures, tables, etc.) and their associated captions and footnotes, as well as structural elements (headers, footers, page numbers), and special annotations (masked regions of the page due to interference). The table is crucial for understanding the composition and complexity of the OmniDocBench dataset.
read the caption
Table S6: Annotation Explanations and Statistics.
Full paper#