↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) are powerful but prone to misuse, generating unsafe or biased content. Existing safety mechanisms often fall short, lacking comprehensive coverage of various risks. This necessitates advanced detection models that ensure safe deployment.
This paper introduces Granite Guardian, a family of open-source risk detection models designed to address these challenges. These models provide a unified approach, covering both traditional safety concerns and novel risks specific to retrieval-augmented generation (RAG). Trained on a diverse dataset combining human-annotated and synthetic data, Granite Guardian achieves state-of-the-art performance on multiple benchmarks, demonstrating its effectiveness and generalizability. By offering these models to the community, the researchers aim to advance the field of responsible AI development.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) safety. It introduces Granite Guardian, a novel, open-source model family that outperforms existing models in risk detection, addressing limitations of traditional methods. This work opens avenues for creating safer LLMs and drives development of more robust risk mitigation strategies. The unified approach, and publicly available benchmarks, offers significant advantages to the community, accelerating progress in responsible AI.
Visual Insights#

🔼 This figure details the guidelines used by annotators to label text samples as either ‘safe’ or ‘unsafe’. It outlines criteria for evaluating both prompts and responses based on categories such as bias, jailbreaking, violence, profanity, sexual content, unethical behavior, AI refusal, and other miscellaneous unsafe content. Specific examples are provided within each category to clarify the guidelines.
read the caption
Figure 1: Annotation guidelines
| Risk | Prompt | Response |
|---|---|---|
harm | ✓ | ✓ |
social-bias | ✓ | ✓ |
profanity | ✓ | ✓ |
sexual content | ✓ | ✓ |
unethical behavior | ✓ | ✓ |
violence | ✓ | ✓ |
jailbreaking | ✓ | |
context relevance (RAG) | ✓ | |
groundedness (RAG) | ✓ | |
answer relevance (RAG) | ✓ |
🔼 This table lists the various risks that the Granite Guardian model is designed to detect. For each risk, it indicates whether the risk is typically found in the prompt (user input) or the response (model output), or both. This helps clarify where in the LLM interaction the model should focus its attention for risk detection.
read the caption
Table 1: Risks detected by Granite Guardian and the corresponding content sections (Prompt or Response) where they may occur.
In-depth insights#
Unified Risk Model#
A unified risk model for large language models (LLMs) is a crucial development for responsible AI. Such a model moves beyond addressing individual risks in isolation (e.g., toxicity, bias, jailbreaking) and instead holistically assesses multiple dimensions simultaneously. This holistic approach is essential because risks often intersect and exacerbate each other. For instance, a seemingly innocuous prompt can be weaponized through jailbreaking techniques to generate toxic or biased outputs. A unified model facilitates the development of more comprehensive and adaptable safety mechanisms. It enables a nuanced risk evaluation capable of detecting subtle and complex interactions between various risks, improving the accuracy and effectiveness of risk mitigation strategies. A key advantage lies in the potential for streamlining existing systems. Instead of deploying multiple independent risk detection modules, a unified model simplifies integration, reducing computational overhead and improving efficiency. The success of a unified model hinges on its ability to incorporate a broad spectrum of risks within a well-defined taxonomy. This taxonomy needs to be both comprehensive and granular, allowing for precise identification and categorization of potential harms. Thorough evaluation and testing against diverse datasets are vital to ensure the model’s generalizability and robustness across different application contexts.
Synthetic Data#
The use of synthetic data in the research paper is a crucial aspect that warrants in-depth analysis. Synthetic data generation plays a vital role in addressing the limitations of real-world datasets, which may be insufficient, costly to obtain, or contain biases. The paper highlights how this approach enhances the model’s ability to detect risks that are typically overlooked in traditional models, such as jailbreaks and RAG-specific issues. The creation of synthetic data involves carefully crafted prompts and well-organized taxonomies to generate diverse samples at scale. This systematic approach ensures the model can handle both benign and harmful prompts effectively. The use of synthetic data also helps to address adversarial attacks, such as jailbreaks, by augmenting the training data with sophisticated prompts designed to bypass standard safeguards. The specific details on the methods and techniques utilized in generating synthetic data, coupled with the extensive evaluations performed to demonstrate the efficacy of the model, showcases the importance of synthetic data in advancing responsible AI development. The quality of the synthetic data and the careful design of the generation process are instrumental in ensuring the model’s robustness and generalizability.
Benchmarking#
A robust benchmarking strategy is crucial for evaluating the effectiveness of large language models (LLMs). The choice of benchmarks should reflect the intended application of the model, encompassing diverse tasks and datasets to provide a holistic assessment. The selection of metrics is equally important. Beyond simple accuracy, metrics that capture various dimensions of performance (precision, recall, F1-score, AUC, AUPRC) are needed to expose strengths and weaknesses across different aspects of the LLM’s capabilities. Furthermore, a comparative analysis against established baselines provides essential context for interpreting the results and understanding the model’s relative performance within the current landscape of LLMs. Finally, transparency and reproducibility are paramount. Openly sharing datasets, model architectures, and evaluation protocols allows the research community to replicate experiments, enhancing trust and enabling further advancements in the field.
RAG Hallucination#
Retrieval Augmented Generation (RAG) systems, while promising, are susceptible to “hallucinations.” These are instances where the model generates outputs that are factually incorrect or lack grounding in the retrieved context. Hallucinations undermine the reliability and trustworthiness of RAG, posing significant challenges for applications requiring accuracy. The problem stems from the limitations of LLMs in effectively synthesizing information from disparate sources and correctly judging the relevance and consistency of that information. Addressing RAG hallucinations requires a multifaceted approach, including improved retrieval methods to ensure relevant and reliable information is accessed, more sophisticated LLM architectures capable of better contextual understanding, and advanced techniques for detecting and mitigating hallucinatory outputs. Developing robust evaluation metrics specifically tailored to assess hallucination risks in RAG is crucial for advancing the field and fostering responsible development of these systems. Furthermore, investigating the underlying causes of hallucinations is necessary to inform the design of more effective mitigation strategies. This might include exploring better methods for handling conflicting or contradictory information, and exploring techniques that explicitly model the uncertainty associated with retrieved information. Ultimately, mitigating RAG hallucinations is paramount for establishing the trustworthiness and broad applicability of these powerful AI tools.
Deployment#
Deployment of large language models (LLMs) is a critical phase demanding careful consideration of various factors. Robust risk mitigation strategies, such as those presented in the Granite Guardian research, are essential for safe and responsible operation. Transparency in the development and deployment processes is paramount to foster trust and accountability. Comprehensive testing across diverse use cases and scenarios is necessary to identify potential vulnerabilities. Scalability is a major concern, as LLMs are often deployed in high-volume environments. Integration with existing systems and workflows must be seamless and efficient. Furthermore, ongoing monitoring and maintenance are vital to ensure continued safety and effectiveness. Ethical considerations must be integrated into every stage of the deployment lifecycle, addressing issues of bias and potential misuse. Finally, a well-defined feedback loop enables continuous improvement and adaptation based on real-world usage data.
More visual insights#
More on figures

🔼 This figure shows the prompt used to generate benign prompts for the synthetic data used to train the Granite Guardian model. The prompt instructs a language model to create a list of requests that might initially seem harmful but are actually harmless. The goal is to help the language model learn to distinguish between genuinely harmful requests and those that are benign but might appear otherwise. It specifies the number of requests needed, a description of the type of safety, and examples to help guide the generation. The purpose is to provide contrastive examples to those that are harmful, aiding in the training of a more robust and less prone to false-positive model.
read the caption
Figure 2: Prompt for benign prompt generation

🔼 This figure shows the prompt used to generate synthetic data for typically harmful prompts. The prompt instructs an LLM to generate diverse requests that a language model should refuse, even if they might initially seem harmless. The prompt requests that each request be on a new line and prefixed with “Request:”. Specific parameters such as subcategory, fine-grained subcategory and description of the request can be filled to obtain different types of harmful requests. This methodology allows for the generation of a large dataset of harmful prompts that can be used to train a safety model.
read the caption
Figure 3: Prompt for typical harmful prompt generation

🔼 This figure shows a prompt designed to generate adversarial harmful prompts. The prompt instructs an AI to act as a red-teaming assistant, tasked with revising simple harmful prompts into more sophisticated and harder-to-detect adversarial versions. This involves using multiple revision strategies to make the harmful intent more subtle and less likely to be flagged by safety mechanisms. The prompt provides a simple harmful request as input, along with a set of revision strategies, each defined with its description and examples. The AI is expected to produce a revised adversarial prompt that is logically coherent, maintains the same harmful intent, but is harder to detect using common safety measures.
read the caption
Figure 4: Prompt for adversarial harmful prompt generation

🔼 This figure presents an example of a revision strategy used to transform a simple harmful prompt into a more sophisticated adversarial prompt. The goal is to create prompts that can bypass the safety mechanisms of language models and elicit harmful responses. The example shows how a malicious prompt can be broken down into smaller, seemingly innocuous parts (payloads) that would not individually trigger a safety alert but can be reassembled by a language model to produce harmful content. This technique highlights the importance of considering more complex, adversarial prompt construction during safety evaluations of language models. The figure is crucial for illustrating the types of adversarial techniques that language models are vulnerable to, and how these need to be accounted for in safe deployment strategies.
read the caption
Figure 5: Example revision strategy for adversarial prompt transformation

🔼 This figure shows a prompt designed for generating synthetic data to evaluate RAG (Retrieval Augmented Generation) models’ performance on hallucination-related risks. The prompt instructs the model to generate several different types of answers to a given question and short answer, each designed to test a specific aspect of RAG quality. These include correct answers, answers that are irrelevant to the question, incorrect answers taken from the document, and questions that themselves are not relevant to the provided context. This process helps create a comprehensive and diverse dataset for training and evaluating RAG models’ ability to produce accurate and contextually relevant responses.
read the caption
Figure 6: Prompt for RAG synthetic data generation
More on tables
| Birth Year | Age | Gender | Education Level | Ethnicity | Region |
|---|---|---|---|---|---|
| - | - | Male | Bachelor | African American | Florida |
| 1989 | 35 | Male | Bachelor | White | Nevada |
| - | - | Female | Associate’s Degree | African American | Pennsylvania |
| 1992 | 32 | Male | Bachelor | African American | Florida |
| 1978 | 46 | Male | Bachelor | White | Colorado |
| 1999 | 25 | Male | High School Diploma | LATAM or Hispanic | Florida |
| - | - | Male | Bachelor | White | Texas |
| 1988 | 36 | Female | Bachelor | White | Florida |
| 1985 | 39 | Female | Bachelor | Native American | Colorado / Utah |
| - | - | Female | Bachelor | White | Arkansas |
| - | - | Female | Master of Science | White | Texas |
| 2000 | 24 | Female | Bachelor | White | Florida |
| 1987 | 37 | Male | Associate’s Degree | White | Florida |
| 1995 | 29 | Female | Master of Epidemiology | African American | Louisiana |
| 1993 | 31 | Female | Master of Public Health | LATAM or Hispanic | Texas |
| 1969 | 55 | Female | Bachelor | LATAM or Hispanic | Florida |
| 1993 | 31 | Female | Bachelor | White | Florida |
| 1985 | 39 | Female | Master of Music | White | California |
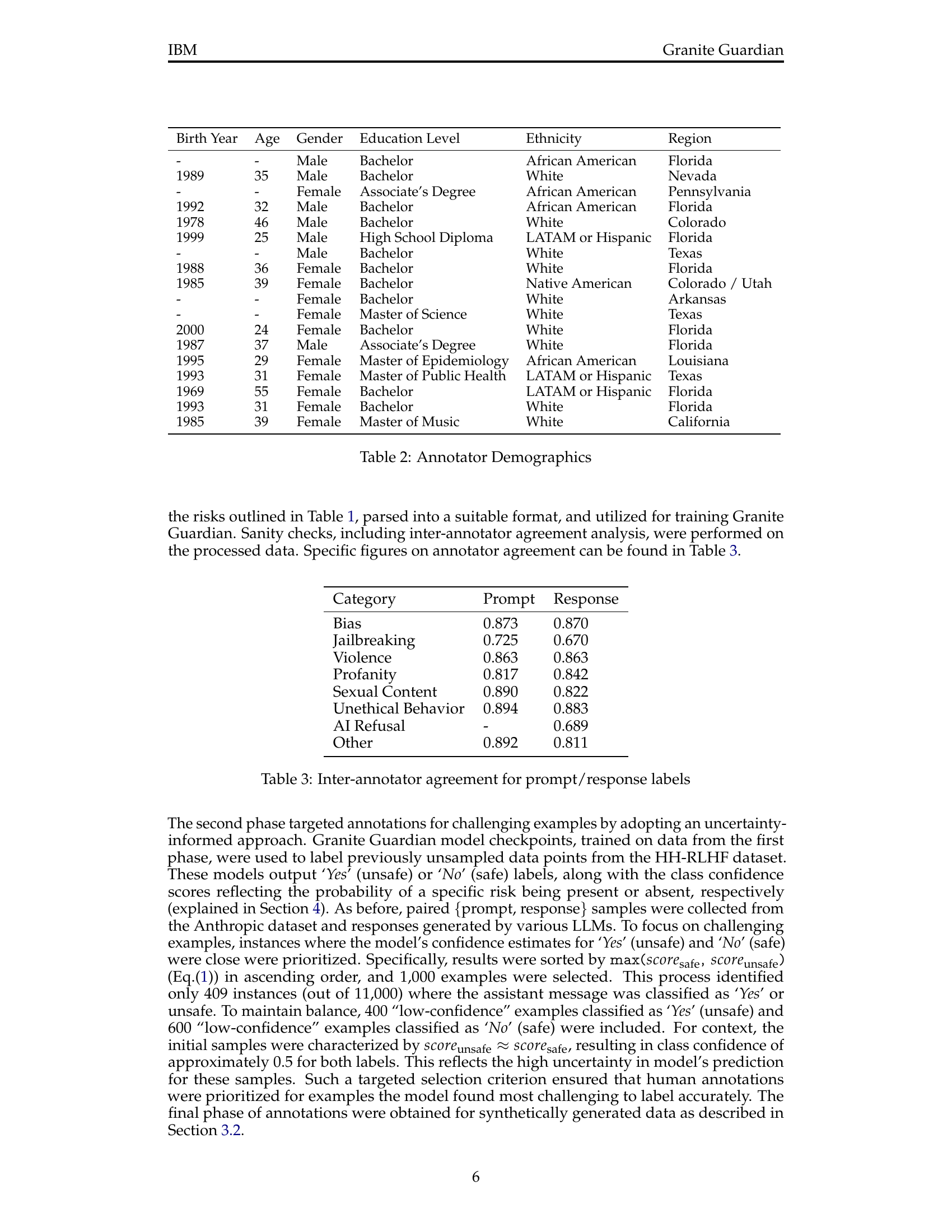
🔼 This table presents the demographic information of the annotators who participated in the data labeling process for the Granite Guardian project. It shows the annotators’ birth year, age, gender, education level, ethnicity, and region. This data provides valuable context on the diversity of the individuals involved in creating the dataset and can help understand any potential biases in the dataset.
read the caption
Table 2: Annotator Demographics
| Category | Prompt | Response |
|---|---|---|
| Bias | 0.873 | 0.870 |
| Jailbreaking | 0.725 | 0.670 |
| Violence | 0.863 | 0.863 |
| Profanity | 0.817 | 0.842 |
| Sexual Content | 0.890 | 0.822 |
| Unethical Behavior | 0.894 | 0.883 |
| AI Refusal | - | 0.689 |
| Other | 0.892 | 0.811 |
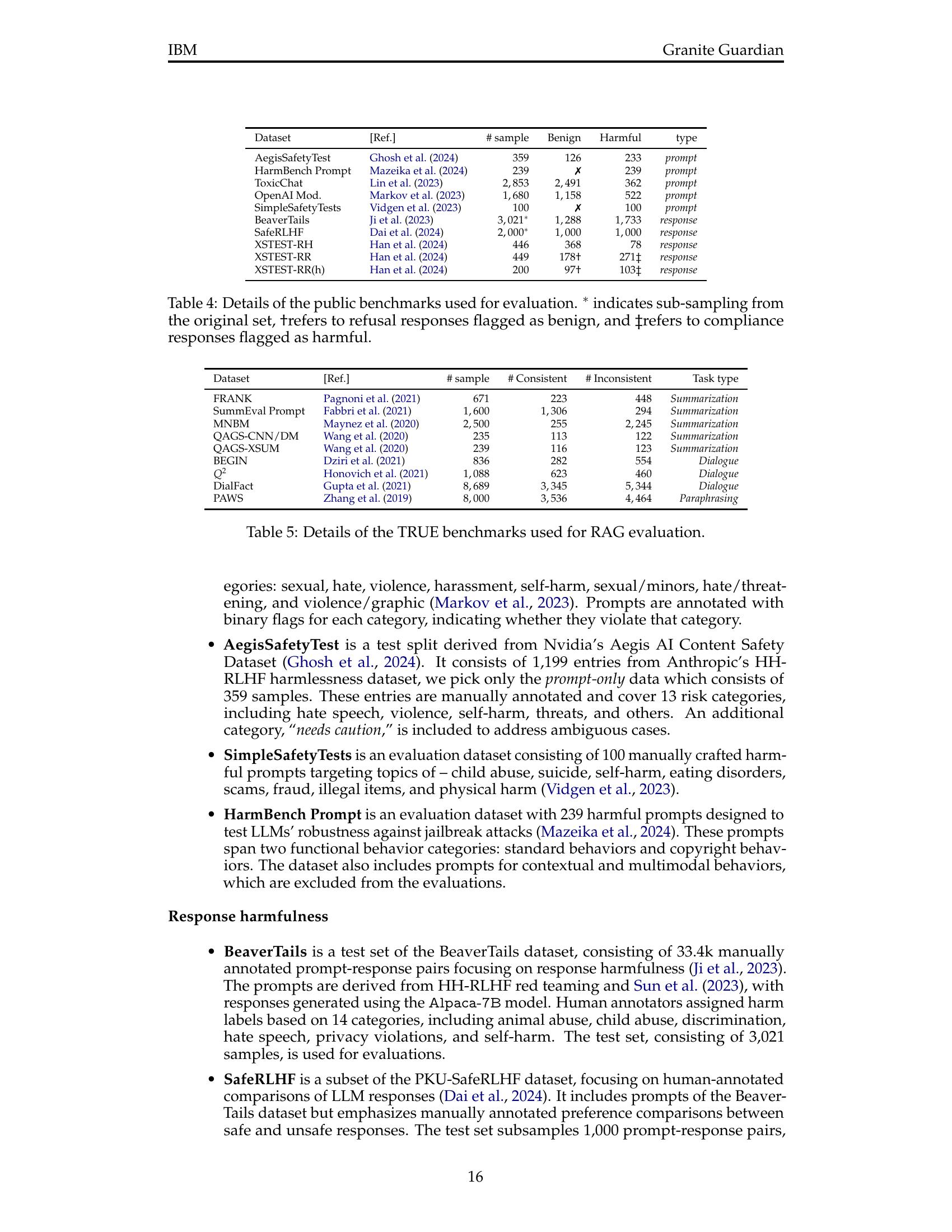
🔼 This table displays the level of agreement between multiple human annotators who independently labeled prompts and responses for various risk categories. It quantifies the inter-annotator reliability for each risk category (Bias, Jailbreaking, Violence, Profanity, Sexual Content, Unethical Behavior, AI Refusal, and Other) by providing the inter-annotator agreement score (presumably Cohen’s Kappa or a similar metric) separately for prompts and responses. Higher scores indicate stronger agreement among annotators, suggesting higher quality and consistency in the labeling process.
read the caption
Table 3: Inter-annotator agreement for prompt/response labels
| Dataset | [Ref.] | # sample | Benign | Harmful | type |
|---|---|---|---|---|---|
| AegisSafetyTest | Ghosh et al. (2024) | 359 | 126 | 233 | prompt |
| HarmBench Prompt | Mazeika et al. (2024) | 239 | ✗ | 239 | prompt |
| ToxicChat | Lin et al. (2023) | 2,853 | 2,491 | 362 | prompt |
| OpenAI Mod. | Markov et al. (2023) | 1,680 | 1,158 | 522 | prompt |
| SimpleSafetyTests | Vidgen et al. (2023) | 100 | ✗ | 100 | prompt |
| BeaverTails | Ji et al. (2023) | 3,021* | 1,288 | 1,733 | response |
| SafeRLHF | Dai et al. (2024) | 2,000* | 1,000 | 1,000 | response |
| XSTEST-RH | Han et al. (2024) | 446 | 368 | 78 | response |
| XSTEST-RR | Han et al. (2024) | 449 | 178† | 271‡ | response |
| XSTEST-RR(h) | Han et al. (2024) | 200 | 97† | 103‡ | response |
🔼 This table presents the details of eight public benchmark datasets used to evaluate the performance of the Granite Guardian model in detecting harmful content in both prompts and responses. It lists each dataset’s name, the source reference, the total number of samples, the number of samples classified as benign, the number of samples classified as harmful, and the type of data (prompt or response). Note that some datasets have undergone sub-sampling (*), refusal responses flagged as benign (†), and compliance responses flagged as harmful(‡). This information is crucial in understanding the evaluation methodology and the nature of the data used to assess the model’s performance.
read the caption
Table 4: Details of the public benchmarks used for evaluation. ∗ indicates sub-sampling from the original set, †refers to refusal responses flagged as benign, and ‡refers to compliance responses flagged as harmful.
| Dataset | [Ref.] | # sample | # Consistent | # Inconsistent | Task type |
|---|---|---|---|---|---|
| FRANK | Pagnoni et al. (2021) | 671 | 223 | 448 | Summarization |
| SummEval Prompt | Fabbri et al. (2021) | 1,600 | 1,306 | 294 | Summarization |
| MNBM | Maynez et al. (2020) | 2,500 | 255 | 2,245 | Summarization |
| QAGS-CNN/DM | Wang et al. (2020) | 235 | 113 | 122 | Summarization |
| QAGS-XSUM | Wang et al. (2020) | 239 | 116 | 123 | Summarization |
| BEGIN | Dziri et al. (2021) | 836 | 282 | 554 | Dialogue |
| Q2 | Honovich et al. (2021) | 1,088 | 623 | 460 | Dialogue |
| DialFact | Gupta et al. (2021) | 8,689 | 3,345 | 5,344 | Dialogue |
| PAWS | Zhang et al. (2019) | 8,000 | 3,536 | 4,464 | Paraphrasing |
🔼 This table lists the datasets used to evaluate the performance of RAG (Retrieval Augmented Generation) models on the task of groundedness. It details the name of each dataset, the reference where it is described, the total number of samples, and the breakdown of those samples into consistent and inconsistent examples. Each dataset focuses on different NLP tasks like summarization, dialogue, and paraphrasing, providing a comprehensive evaluation of RAG across various scenarios.
read the caption
Table 5: Details of the TRUE benchmarks used for RAG evaluation.
| model | AUC | AUPRC | F1 | Recall | Precision |
|---|---|---|---|---|---|
| Llama-Guard-7B | 0.824 | 0.803 | 0.659 | 0.533 | 0.861 |
| Llama-Guard-2-8B | 0.841 | 0.822 | 0.723 | 0.627 | 0.852 |
| Llama-Guard-3-1B | 0.796 | 0.775 | 0.656 | 0.575 | 0.765 |
| Llama-Guard-3-8B | 0.826 | 0.819 | 0.710 | 0.607 | 0.857 |
| ShieldGemma-2B | 0.748 | 0.704 | 0.421 | 0.277 | 0.883 |
| ShieldGemma-9B | 0.753 | 0.707 | 0.404 | 0.262 | 0.886 |
| ShieldGemma-27B | 0.772 | 0.718 | 0.438 | 0.295 | 0.849 |
| Granite-Guardian-3.0-2B | 0.782 | 0.746 | 0.674 | 0.747 | 0.614 |
| Granite-Guardian-3.0-8B | 0.871 | 0.846 | 0.758 | 0.735 | 0.781 |
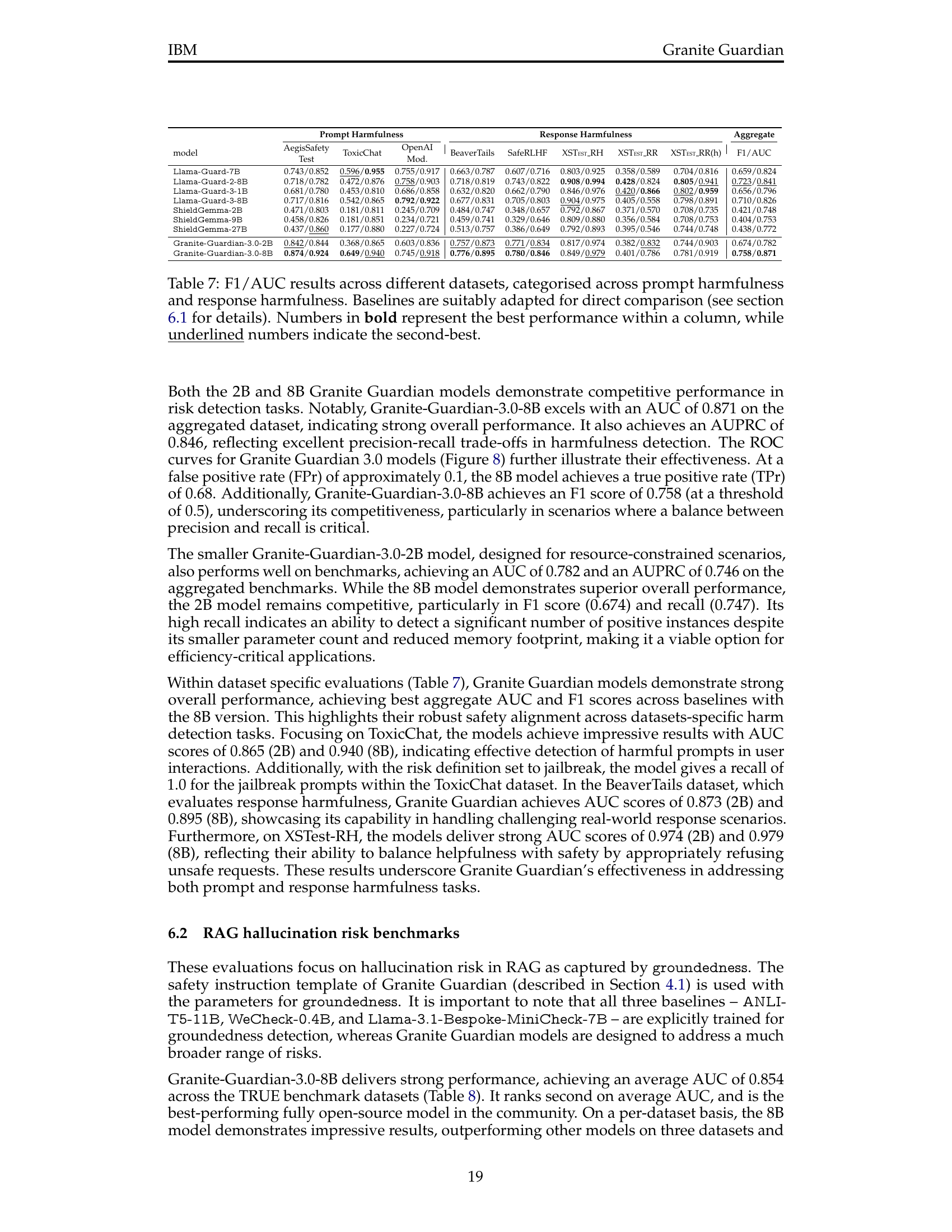
🔼 This table presents a comparison of the performance of Granite Guardian’s harm risk detection model against Llama Guard and ShieldGemma models. The comparison uses aggregated datasets for harmful content detection, focusing on the umbrella harm risk definition. The table shows several evaluation metrics (AUC, AUPRC, F1, Recall, and Precision). The baselines (Llama Guard and ShieldGemma) were adapted to ensure a fair comparison. The best and second-best performances for each metric are highlighted in bold and underlined, respectively. This allows readers to easily identify the relative strengths of each model in detecting harmful content.
read the caption
Table 6: Results on aggregated datasets for harmful content detection comparing Granite Guardian (using the umbrella harm risk definition) with Llama Guard and ShieldGemma model families. Baselines are suitably adapted for direct comparison (see section 6.1 for details). Numbers in bold represent the best performance within a column, while underlined numbers indicate the second-best.
| model | AegisSafetyTest | ToxicChat | OpenAI Mod. | BeaverTails | SafeRLHF | XSTEST_RH | XSTEST_RR | XSTEST_RR(h) | F1/AUC |
|---|---|---|---|---|---|---|---|---|---|
| Llama-Guard-7B | 0.743/0.852 | 0.596/0.955 | 0.755/0.917 | 0.663/0.787 | 0.607/0.716 | 0.803/0.925 | 0.358/0.589 | 0.704/0.816 | 0.659/0.824 |
| Llama-Guard-2-8B | 0.718/0.782 | 0.472/0.876 | 0.758/0.903 | 0.718/0.819 | 0.743/0.822 | 0.908/0.994 | 0.428/0.824 | 0.805/0.941 | 0.723/0.841 |
| Llama-Guard-3-1B | 0.681/0.780 | 0.453/0.810 | 0.686/0.858 | 0.632/0.820 | 0.662/0.790 | 0.846/0.976 | 0.420/0.866 | 0.802/0.959 | 0.656/0.796 |
| Llama-Guard-3-8B | 0.717/0.816 | 0.542/0.865 | 0.792/0.922 | 0.677/0.831 | 0.705/0.803 | 0.904/0.975 | 0.405/0.558 | 0.798/0.891 | 0.710/0.826 |
| ShieldGemma-2B | 0.471/0.803 | 0.181/0.811 | 0.245/0.709 | 0.484/0.747 | 0.348/0.657 | 0.792/0.867 | 0.371/0.570 | 0.708/0.735 | 0.421/0.748 |
| ShieldGemma-9B | 0.458/0.826 | 0.181/0.851 | 0.234/0.721 | 0.459/0.741 | 0.329/0.646 | 0.809/0.880 | 0.356/0.584 | 0.708/0.753 | 0.404/0.753 |
| ShieldGemma-27B | 0.437/0.860 | 0.177/0.880 | 0.227/0.724 | 0.513/0.757 | 0.386/0.649 | 0.792/0.893 | 0.395/0.546 | 0.744/0.748 | 0.438/0.772 |
| Granite-Guardian-3.0-2B | 0.842/0.844 | 0.368/0.865 | 0.603/0.836 | 0.757/0.873 | 0.771/0.834 | 0.817/0.974 | 0.382/0.832 | 0.744/0.903 | 0.674/0.782 |
| Granite-Guardian-3.0-8B | 0.874/0.924 | 0.649/0.940 | 0.745/0.918 | 0.776/0.895 | 0.780/0.846 | 0.849/0.979 | 0.401/0.786 | 0.781/0.919 | 0.758/0.871 |
🔼 This table presents the performance of various models, including Granite Guardian, in detecting harmful content in both prompts and responses. The models are evaluated across multiple datasets, categorized by whether the harm is present in the prompt or the response. The F1 score and Area Under the ROC Curve (AUC) are reported as key performance metrics. The baselines are modified to facilitate fair comparisons with Granite Guardian. Numbers in bold represent the best performance in each column, and underlined numbers indicate the second-best performance.
read the caption
Table 7: F1/AUC results across different datasets, categorised across prompt harmfulness and response harmfulness. Baselines are suitably adapted for direct comparison (see section 6.1 for details). Numbers in bold represent the best performance within a column, while underlined numbers indicate the second-best.
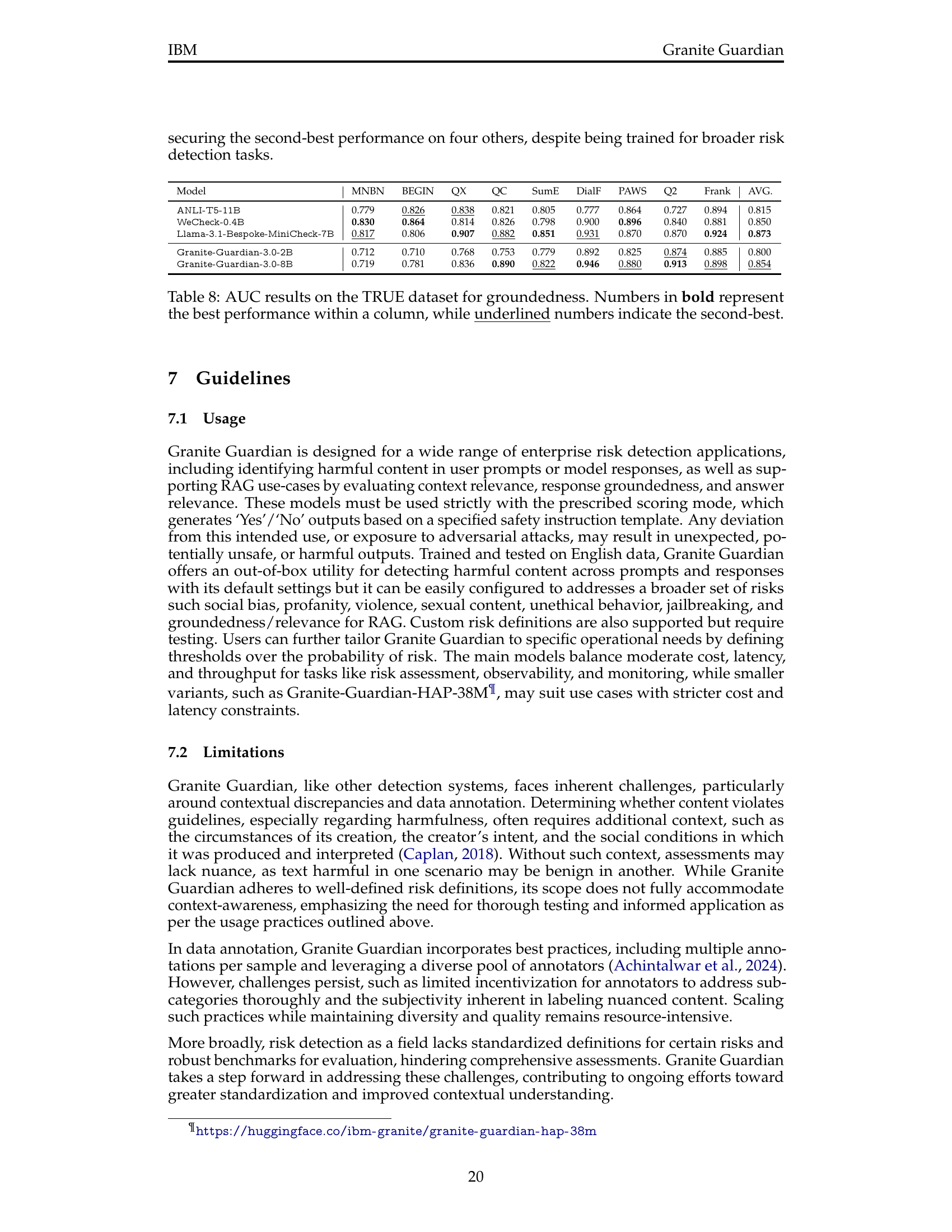
| Model | MNBN | BEGIN | QX | QC | SumE | DialF | PAWS | Q2 | Frank | AVG. |
|---|---|---|---|---|---|---|---|---|---|---|
| ANLI-T5-11B | 0.779 | 0.826 | 0.838 | 0.821 | 0.805 | 0.777 | 0.864 | 0.727 | 0.894 | 0.815 |
| WeCheck-0.4B | 0.830 | 0.864 | 0.814 | 0.826 | 0.798 | 0.900 | 0.896 | 0.840 | 0.881 | 0.850 |
| Llama-3.1-Bespoke-MiniCheck-7B | 0.817 | 0.806 | 0.907 | 0.882 | 0.851 | 0.931 | 0.870 | 0.870 | 0.924 | 0.873 |
| Granite-Guardian-3.0-2B | 0.712 | 0.710 | 0.768 | 0.753 | 0.779 | 0.892 | 0.825 | 0.874 | 0.885 | 0.800 |
| Granite-Guardian-3.0-8B | 0.719 | 0.781 | 0.836 | 0.890 | 0.822 | 0.946 | 0.880 | 0.913 | 0.898 | 0.854 |
🔼 This table presents the Area Under the Curve (AUC) scores for different models on the TRUE benchmark dataset, specifically focusing on the groundedness aspect of RAG (Retrieval Augmented Generation). The TRUE dataset encompasses various natural language processing (NLP) tasks designed to assess the factual consistency of generated text. The models’ AUC scores are compared across multiple sub-datasets within TRUE, allowing for a comprehensive evaluation of their performance in accurately identifying grounded vs. hallucinated statements. The bold numbers in each column highlight the top-performing model for that specific task, while underlined numbers denote the second-best performance. This enables easy comparison of the models’ strengths and weaknesses across a diverse range of NLP tasks.
read the caption
Table 8: AUC results on the TRUE dataset for groundedness. Numbers in bold represent the best performance within a column, while underlined numbers indicate the second-best.
| Risk name | Definition |
|---|---|
harm | Content considered universally harmful. This is our general category, which should encompass a variety of risks including those not specifically addressed by the following categories. |
social-bias | Systemic prejudice against groups based on shared identity or characteristics, often stemming from stereotypes or cultural influences. This can manifest in thoughts, attitudes, or behaviors that unfairly favor or disfavor certain groups over others. |
profanity | Use of language considered offensive or socially unacceptable in a given context. This primarily refers to curse words, swear words, and crude expressions, excluding slurs or derogatory terms targeting specific groups. |
sexual content | Material explicitly related to sexual activities, anatomy, or desires. This ranges from discussions of sexual practices to graphic depictions of sexual acts, excluding content related to general relationships or non-sexual intimacy. |
unethical behavior | Actions that violate moral or professional standards, focusing on exploitation for personal gain or disregard for others’ well-being. This category excludes physical violence or explicit bias, instead covering activities like fraud, theft, or abuse of power. |
violence | Promoting or describing physical harm to individuals or groups. This includes depictions of assault, self-harm, or creation of a hostile environment through threats or intimidation. |
jailbreaking | Deliberate circumvention of AI systems’ built-in safeguards or ethical guidelines. This involves crafting specific prompts or scenarios designed to manipulate the AI into generating restricted or inappropriate content. |
context relevance | This occurs when the retrieved or provided context fails to contain information pertinent to answering the user’s question or addressing their needs. Irrelevant context may be on a different topic, from an unrelated domain, or contain information that doesn’t help in formulating an appropriate response to the user. |
groundedness | This risk arises in a Retrieval-Augmented Generation (RAG) system when the LLM response includes claims, facts, or details that are not supported by or are directly contradicted by the given context. An ungrounded answer may involve fabricating information, misinterpreting the context, or making unsupported extrapolations beyond what the context actually states. |
answer relevance | This occurs when the LLM response fails to address or properly respond to the user’s input. This includes providing off-topic information, misinterpreting the query, or omitting crucial details requested by the User. An irrelevant answer may contain factually correct information but still fail to meet the User’s specific needs or answer their intended question. |
🔼 This table provides a comprehensive list of risk categories and their detailed definitions as used in the Granite Guardian model. It covers a wide range of risks, categorized into general harm, social biases, profanity, sexual content, unethical behavior, violence, jailbreaking, and RAG (Retrieval-Augmented Generation)-specific risks such as context relevance, groundedness, and answer relevance. Each risk category includes a clear and concise definition to facilitate a thorough understanding of the model’s capabilities and limitations in risk detection.
read the caption
Table 9: Risk Definitions
| Risk Type | Secondary | Primary |
|---|---|---|
| Harm++ (Prompt) | - | user |
| Harm++ (Response) | user | assistant |
| Jailbreak (Prompt) | - | user |
| RAG - Context Relevance | user | context |
| RAG - Groundedness | context | assistant |
| RAG - Answer Relevance | user | assistant |
🔼 This table details how the safety instruction template is used for different risk categories. The ‘Risk Type’ column lists the various risk types, such as harmful content (Harm++), jailbreaking, and different aspects of Retrieval Augmented Generation (RAG) quality (context relevance, groundedness, and answer relevance). The ‘Secondary’ and ‘Primary’ columns indicate which parts of the prompt and response text (user or assistant) the safety agent focuses on when assessing the risk. This is crucial to understanding how the model processes the information for different kinds of risks and enables flexibility in adapting the model to various safety concerns.
read the caption
Table 10: Designated roles in the safety instruction template for different risk categories. Harm++ refers to all harmful content risks (Section 2.1.1). The “Primary” column indicates the tag that determines the safety agent’s focus, while the “Secondary” column, in conjunction with the “Primary” tag, specifies the content to be included in the safety instruction template, as detailed in Section 4.1.
| model | AUC | TPr | AUC@0.1 | TPr@0.1 | AUC@0.01 | TPr@0.01 | AUC@0.001 | TPr@0.001 |
|---|---|---|---|---|---|---|---|---|
Llama-Guard-7B | 0.824 | 0.533 | 0.454 | 0.617 | 0.148 | 0.224 | 0.037 | 0.068 |
Llama-Guard-2-8B | 0.841 | 0.627 | 0.506 | 0.660 | 0.137 | 0.239 | 0.014 | 0.032 |
Llama-Guard-3-1B | 0.796 | 0.575 | 0.414 | 0.546 | 0.152 | 0.247 | 0.030 | 0.054 |
Llama-Guard-3-8B | 0.826 | 0.607 | 0.521 | 0.648 | 0.174 | 0.320 | 0.016 | 0.033 |
ShieldGemma-2B | 0.748 | 0.277 | 0.308 | 0.400 | 0.112 | 0.179 | 0.021 | 0.035 |
ShieldGemma-9B | 0.753 | 0.262 | 0.307 | 0.403 | 0.129 | 0.193 | 0.020 | 0.052 |
ShieldGemma-27B | 0.772 | 0.295 | 0.305 | 0.399 | 0.133 | 0.191 | 0.016 | 0.049 |
Granite-Guardian-3.0-2B | 0.782 | 0.747 | 0.355 | 0.504 | 0.102 | 0.185 | 0.012 | 0.021 |
Granite-Guardian-3.0-8B | 0.871 | 0.735 | 0.515 | 0.676 | 0.170 | 0.290 | 0.041 | 0.072 |
🔼 This table presents the Area Under the Curve (AUC) and True Positive Rate (TPR) at various False Positive Rate (FPR) thresholds (0.1, 0.01, and 0.001) for several models. The Area Under the Curve (AUC) provides an overall measure of the model’s ability to distinguish between classes. The True Positive Rate (TPR), at a fixed FPR, measures the model’s effectiveness at correctly identifying true positives, while controlling the rate of false positives. This is crucial for applications with stringent requirements for minimizing false positives. The models compared include Granite Guardian (two versions: 2B and 8B), Llama Guard models (multiple versions), and ShieldGemma models (multiple versions). The table highlights the best performing model for each metric at each threshold using bold font and the second-best performing model with underlined font.
read the caption
Table 11: AUC and TPr results on specific FPr thresholds (i.e., with FPr equal to 0.1, 0.01, 0.001). Numbers in bold represent the best performance within a column, while underlined numbers indicate the second-best.
Full paper#