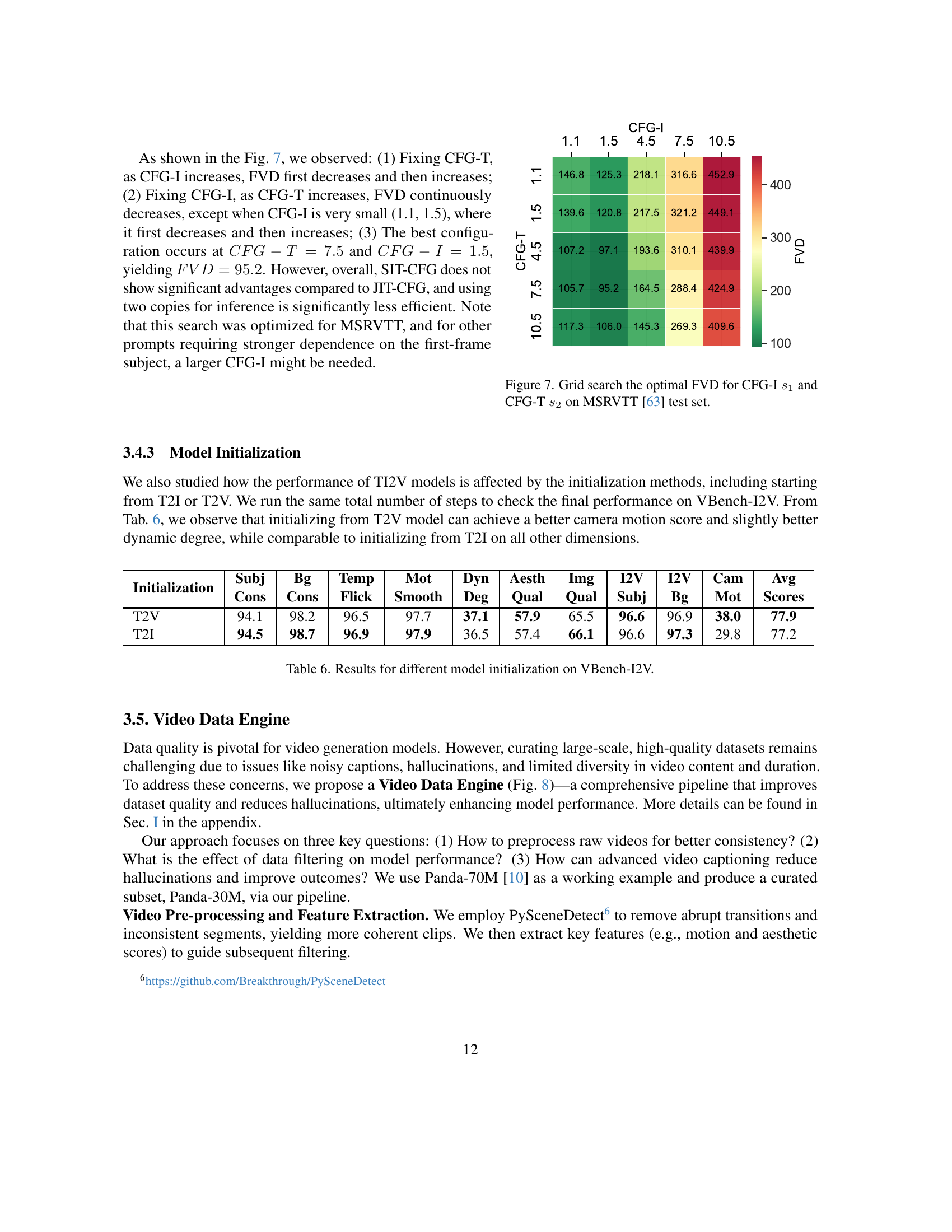
↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video generation models struggle with scalability and seamlessly integrating image conditions into the Diffusion Transformer (DiT) architecture. Existing methods often lack a unified approach for handling both text-to-video (T2V) and text-image-to-video (TI2V) tasks, resulting in suboptimal performance. Additionally, effective large-scale training strategies are also needed to improve model robustness and efficiency.
The paper introduces STIV, a novel framework addressing these issues. STIV integrates image conditions via frame replacement in a DiT architecture and incorporates text conditioning through classifier-free guidance. It demonstrates strong performance across T2V and TI2V tasks, surpassing existing models in benchmarks. The study also provides detailed analysis of model architectures, training recipes, and data curation strategies, thereby offering a simple yet effective recipe for building advanced video generation models.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a scalable and versatile recipe for creating cutting-edge video generation models. It addresses the challenges of integrating image conditions into the DiT architecture, improving training efficiency at scale, and unifying text-to-video and text-image-to-video tasks within a single model. This systematic approach accelerates progress toward more reliable and versatile video generation solutions, opening new avenues for downstream applications like video prediction and interpolation.
Visual Insights#

🔼 This figure displays a performance comparison chart, illustrating the results of several text-to-video (T2V) models on the VBench benchmark [31]. It compares the performance of the authors’ proposed model against state-of-the-art models, both open-source and closed-source. The chart likely uses VBench’s metrics for evaluating video generation quality, which may include measures of semantic accuracy and visual fidelity, allowing for a comparison of both the quality and accuracy of video generation. The visualization helps to understand the relative strengths and weaknesses of different T2V models and shows how the authors’ model performs compared to existing solutions.
read the caption
Figure 1: Performance comparison of our Text-to-Video model against both open-source and closed-source state-of-the-art models on VBench [31].
| Model Size | # of STIV Blocks | Hidden Dim | # of Attn Heads |
|---|---|---|---|
| XL (600M) | 28 | 1,152 | 18 |
| XXL (1.5B) | 38 | 1,536 | 24 |
| M (8.7B) | 46 | 3,072 | 48 |
🔼 This table presents the configurations of different STIV (Scalable Text and Image Conditioned Video Generation) models used in the paper’s experiments. The configurations include model size (in number of parameters), the number of STIV blocks, the hidden dimension size within the blocks, and the number of attention heads. These specifications are crucial for understanding the computational resources and performance characteristics associated with each model variant.
read the caption
Table 1: Model Configurations
In-depth insights#
Scalable Video Gen#
Scalable video generation is a crucial area of research, focusing on creating efficient and effective methods for producing high-quality videos at various resolutions and durations. The core challenges lie in managing computational resources effectively while maintaining or improving video quality. Key aspects include optimizing model architectures (e.g., using efficient attention mechanisms), employing stable training techniques (e.g., addressing vanishing gradients), and leveraging efficient data management strategies. Successful approaches often involve modular designs, allowing for independent scaling of different components, and the use of progressive training techniques to ease the burden on computational resources. Furthermore, research into data augmentation and efficient datasets is essential to reduce training costs while achieving high-quality results. Ultimately, the goal is to develop methods that enable the creation of diverse and high-quality videos across various applications in a cost-effective and resource-efficient manner.
DiT Architecture#
The Diffusion Transformer (DiT) architecture is a crucial element in many state-of-the-art video generation models. Its strength lies in effectively handling the complex spatiotemporal dependencies inherent in video data. Unlike previous methods that struggled with long-range dependencies, DiT leverages the power of transformers, enabling efficient processing of long sequences of frames. The use of self-attention mechanisms within the DiT architecture allows the model to capture intricate relationships between different frames, leading to improved temporal coherence and realism in the generated videos. Furthermore, DiT’s modular design facilitates easy integration with other conditioning modalities, such as text and image. The ability to incorporate these external cues is critical in guiding the generation process and producing more relevant and coherent videos. However, scaling DiT to handle higher resolutions and longer sequences presents computational challenges, requiring careful consideration of model size, training strategies, and stability techniques. Addressing these challenges is crucial for further advancements in video generation and the development of more scalable and efficient DiT-based models.
Image Condition#
The integration of image conditioning into video generation models presents a significant opportunity to enhance realism and control. The core challenge lies in effectively merging image information with textual prompts to create coherent and realistic video sequences. A naive approach might simply concatenate the image embedding with the text features, but this often results in suboptimal results due to the different nature of image and text data and the complexity of the video generation process. Successful methods therefore often employ more sophisticated techniques, such as frame replacement, where the initial frame of the video generation process is replaced by the conditioned image. This anchors the generated video in a specific visual context, guiding the subsequent frames. Another critical aspect is the balance between the influence of the image and the text. If the image dominates too heavily, the text’s creative potential may be diminished. Alternatively, an excessively strong text influence might lead to the generated video deviating significantly from the conditioned image. Consequently, carefully designed architectures and training strategies are needed to harmoniously incorporate both image and text information, achieving a synergistic effect that improves both the semantic and visual quality of the generated video.
Multi-task Training#
Multi-task learning, in the context of video generation, aims to train a single model to perform multiple tasks simultaneously. This approach offers several key advantages. First, it leverages shared representations learned across tasks, potentially leading to improved performance and efficiency compared to training separate models for each task. Second, it reduces the need for large datasets specific to each task; shared data across tasks augments the overall training data. Third, multi-task training can improve model generalization and robustness by allowing the model to learn more generalizable features. However, challenges exist, such as negative transfer (where learning one task hinders the learning of another) and careful hyperparameter tuning to find the optimal balance between tasks. The success of multi-task training hinges on the relatedness of tasks, careful architecture design, and appropriate training strategies. Careful selection of loss functions and strategies to handle different task complexities are crucial for preventing some tasks from dominating the learning process.
Future Directions#
Future research in video generation should prioritize improving the quality and realism of generated videos, addressing current limitations in motion coherence, fine-grained control, and handling of complex scenes. Expanding the range of applications is key; this includes exploring more sophisticated tasks like long-video generation, interactive video creation, and high-fidelity video editing. A key challenge lies in scaling up models efficiently while maintaining computational feasibility and mitigating issues such as training instability or hallucination. This requires further innovation in model architectures and training techniques, potentially focusing on more efficient attention mechanisms or novel loss functions. Addressing biases and ethical concerns is crucial, ensuring fair and representative datasets while mitigating the potential for harmful or misleading content generation. Finally, interdisciplinary collaborations between AI researchers and experts in related fields (e.g., computer graphics, filmmaking) will be critical to push the boundaries of video generation and to fully realize the potential of this powerful technology.
More visual insights#
More on figures

🔼 This figure showcases the video generation capabilities of both the Text-to-Video (T2V) model and the STIV model (which incorporates both text and image conditions). The top two rows present examples generated using only text prompts as input to the T2V model. The bottom two rows demonstrate examples where both text and a first frame image (as an image condition) were given as input to the STIV model. The text prompts and initial image frames are taken directly from existing benchmark datasets (Sora [42] and MovieGenBench [46]) to allow for a direct comparison against these previously published models.
read the caption
Figure 2: Text-to-Video and Text-Image-to-Video generation samples by T2V and STIV models. The text prompts and first frame image conditions are borrowed from Sora’s demos [42] and MovieGenBench [46].
🔼 This figure illustrates the architecture of the STIV block, a key component of the STIV model. The process begins with frame replacement, where the first noisy frame of the video latent is swapped with the corresponding ground truth frame from the image condition. To further enhance the model’s robustness, the image condition is randomly dropped out during training. Text embeddings are incorporated through cross-attention. The architecture then uses QK-norm within the multi-head attention mechanism and sandwich-norm in both attention and feedforward layers. Finally, stateless layernorm is applied after the singleton conditions to enhance training stability. This carefully designed architecture allows STIV to efficiently and effectively handle both text-to-video (T2V) and text-image-to-video (TI2V) tasks.
read the caption
Figure 3: We replace the first frame of the noised video latents with the ground truth latent and randomly drop out the image condition. We use cross attention to incorporate the text embedding, and use QK-norm in multi-head attention, the sandwich-norm in both attention and feedforward, and stateless layernorm after singleton conditions to stabilize the training.

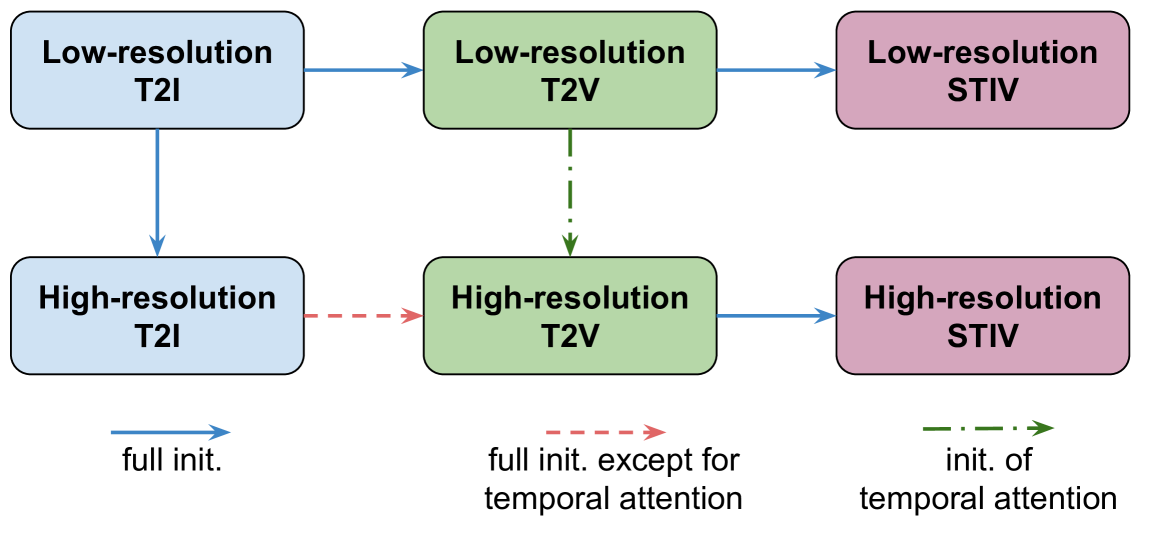
🔼 This figure illustrates the progressive training approach used to develop the STIV model. The process begins by training a text-to-image (T2I) model at a low resolution. This pre-trained T2I model is then used to initialize a text-to-video (T2V) model, also at low resolution. The low-resolution T2V model is subsequently used, along with a newly trained high-resolution T2I model, to initialize a high-resolution T2V model. Finally, this high-resolution T2V model is used to initialize the final STIV model (text-image-to-video) at both low and high resolutions. This progressive training strategy leverages knowledge learned at each stage to improve the efficiency and performance of subsequent models.
read the caption
Figure 4: Progressive training pipeline of the STIV model. The T2I model is first trained to initialize the T2V model, which then initializes the STIV model at both low and high resolutions. Notably, the high-res T2V model is initialized using both the high-res T2I model and the low-res T2V model.

🔼 This figure details an ablation study comparing three model variations. It starts with a base Text-to-Image (T2I) model, then progresses to a temporally-aware Text-to-Video (T2V) model, and culminates in an Image-conditioned Text-to-Video (TI2V) model. Each step builds upon the previous one, adding complexity and capabilities. The purpose is to demonstrate the incremental impact of adding temporal awareness and image conditioning on the performance and functionality of the video generation model.
read the caption
Figure 5: Ablation study of the STIV model, from the base T2I model to the temporally-aware T2V model, and finally to the image-conditioned TI2V model.

🔼 This ablation study investigates the impact of various design choices on the performance of a text-to-video (T2V) model. The baseline model uses a temporal patch size of 2, non-causal temporal attention (meaning the model processes the temporal dimension sequentially, not bidirectionally), a spatial masking ratio of 0.5 (half of the spatial tokens are masked during training), and no temporal masking. The study systematically varies these design choices (temporal patch size, temporal attention causality, spatial masking ratio, and temporal masking) to determine how each impacts model performance. Results are likely presented as metrics reflecting the quality of generated videos.
read the caption
(a) Ablation Study of T2V model design using T2V-XL. The base model uses temporal path size 2, non-causal temporal attention, spatial masking ratio 0.5, and no temporal masking.

🔼 This figure shows a comparison of different initialization methods for training a text-to-video (T2V) model. The model used is a large T2V model (T2V-XL) with a resolution of 512x512. Different initialization strategies are compared based on their performance on the VBench metric, which measures several factors of video generation quality, including semantic alignment and quality scores.
read the caption
(b) Different model initialization for T2V-XL-512.

🔼 This figure shows the ablation study on different initialization methods for training T2V-XL models with 40 frames. It compares the performance of various initialization strategies, including training from scratch, initializing from a lower-resolution T2V model (20 frames), initializing from a T2I model, and a combined initialization using both a low-resolution T2V model and a high-resolution T2I model. The results are likely presented in terms of metrics relevant to video generation quality.
read the caption
(c) Different initialization for T2V-XL 40 frames.

🔼 This figure presents ablation studies that analyze the impact of various design choices on the performance of the text-to-video (T2V) model. Specifically, it examines how different configurations affect VBench metrics (Quality, Semantic, and Total). The subplots (a), (b), and (c) showcase results for different aspects: (a) analyzes the effects of model design choices (temporal patch size, attention type, spatial masking); (b) investigates how different initialization methods for the T2V model (training from scratch, initializing from a lower resolution T2V model, initializing from a T2I model, a combination of T2V and T2I initialization) affect VBench metrics; and (c) shows the effects of different model initialization approaches when training with a higher number of frames (40 frames). The results help determine optimal model architecture and training strategies for high-quality video generation.
read the caption
Figure 6: Ablation studies of key designs for T2V.
More on tables
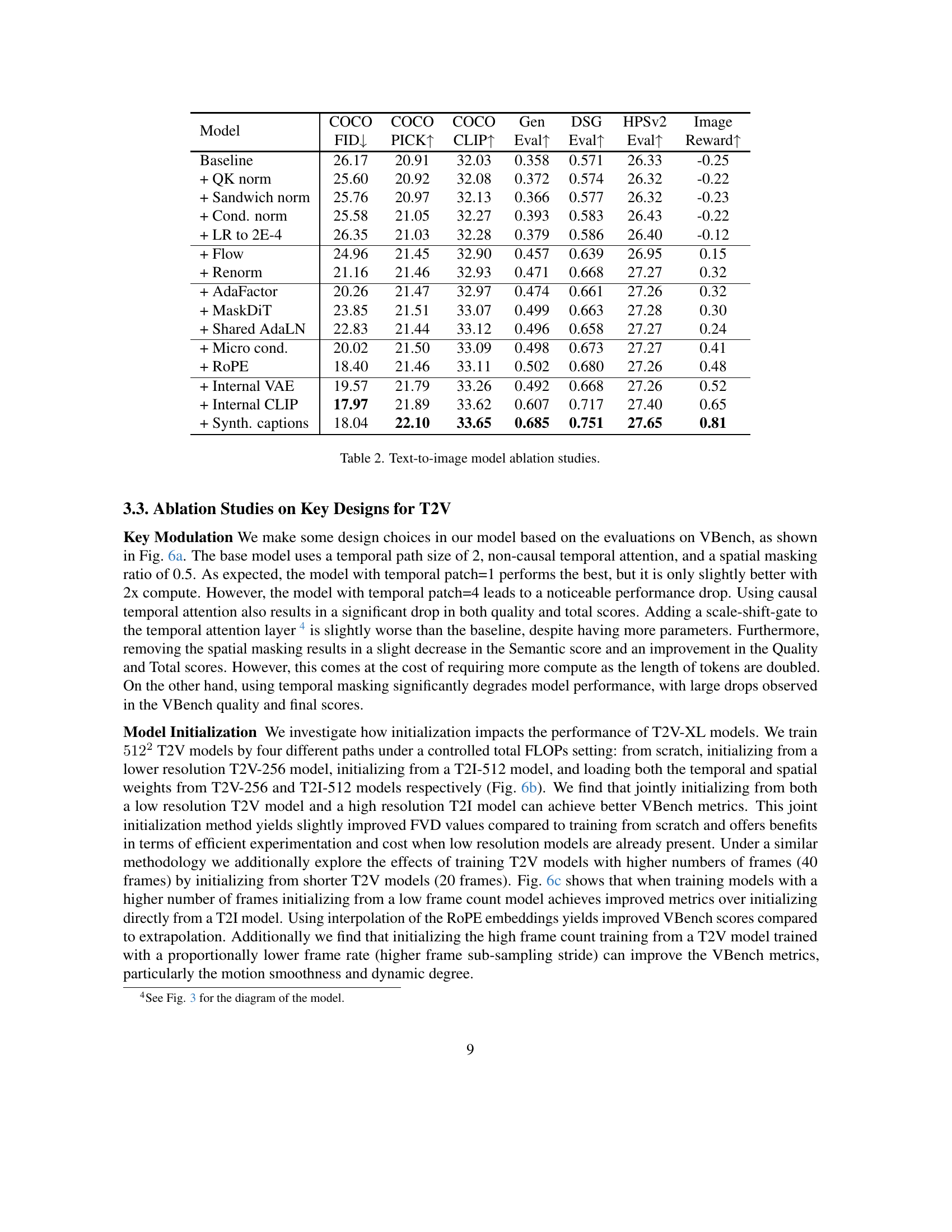
| Model | COCO FID↓ | COCO PICK↑ | COCO CLIP↑ | Gen Eval↑ | DSG Eval↑ | HPSv2 Eval↑ | Image Reward↑ |
|---|---|---|---|---|---|---|---|
| Baseline | 26.17 | 20.91 | 32.03 | 0.358 | 0.571 | 26.33 | -0.25 |
| + QK norm | 25.60 | 20.92 | 32.08 | 0.372 | 0.574 | 26.32 | -0.22 |
| + Sandwich norm | 25.76 | 20.97 | 32.13 | 0.366 | 0.577 | 26.32 | -0.23 |
| + Cond. norm | 25.58 | 21.05 | 32.27 | 0.393 | 0.583 | 26.43 | -0.22 |
| + LR to 2E-4 | 26.35 | 21.03 | 32.28 | 0.379 | 0.586 | 26.40 | -0.12 |
| + Flow | 24.96 | 21.45 | 32.90 | 0.457 | 0.639 | 26.95 | 0.15 |
| + Renorm | 21.16 | 21.46 | 32.93 | 0.471 | 0.668 | 27.27 | 0.32 |
| + AdaFactor | 20.26 | 21.47 | 32.97 | 0.474 | 0.661 | 27.26 | 0.32 |
| + MaskDiT | 23.85 | 21.51 | 33.07 | 0.499 | 0.663 | 27.28 | 0.30 |
| + Shared AdaLN | 22.83 | 21.44 | 33.12 | 0.496 | 0.658 | 27.27 | 0.24 |
| + Micro cond. | 20.02 | 21.50 | 33.09 | 0.498 | 0.673 | 27.27 | 0.41 |
| + RoPE | 18.40 | 21.46 | 33.11 | 0.502 | 0.680 | 27.26 | 0.48 |
| + Internal VAE | 19.57 | 21.79 | 33.26 | 0.492 | 0.668 | 27.26 | 0.52 |
| + Internal CLIP | 17.97 | 21.89 | 33.62 | 0.607 | 0.717 | 27.40 | 0.65 |
| + Synth. captions | 18.04 | 22.10 | 33.65 | 0.685 | 0.751 | 27.65 | 0.81 |
🔼 This table presents the results of an ablation study on the text-to-image model. It shows how different design choices and training techniques affect the model’s performance, as measured by various metrics. Each row represents a different model variation, building upon the previous one with an additional modification. The metrics provide a comprehensive evaluation of the generated images, assessing different aspects like image quality, alignment with the prompt, and efficiency of generation.
read the caption
Table 2: Text-to-image model ablation studies.
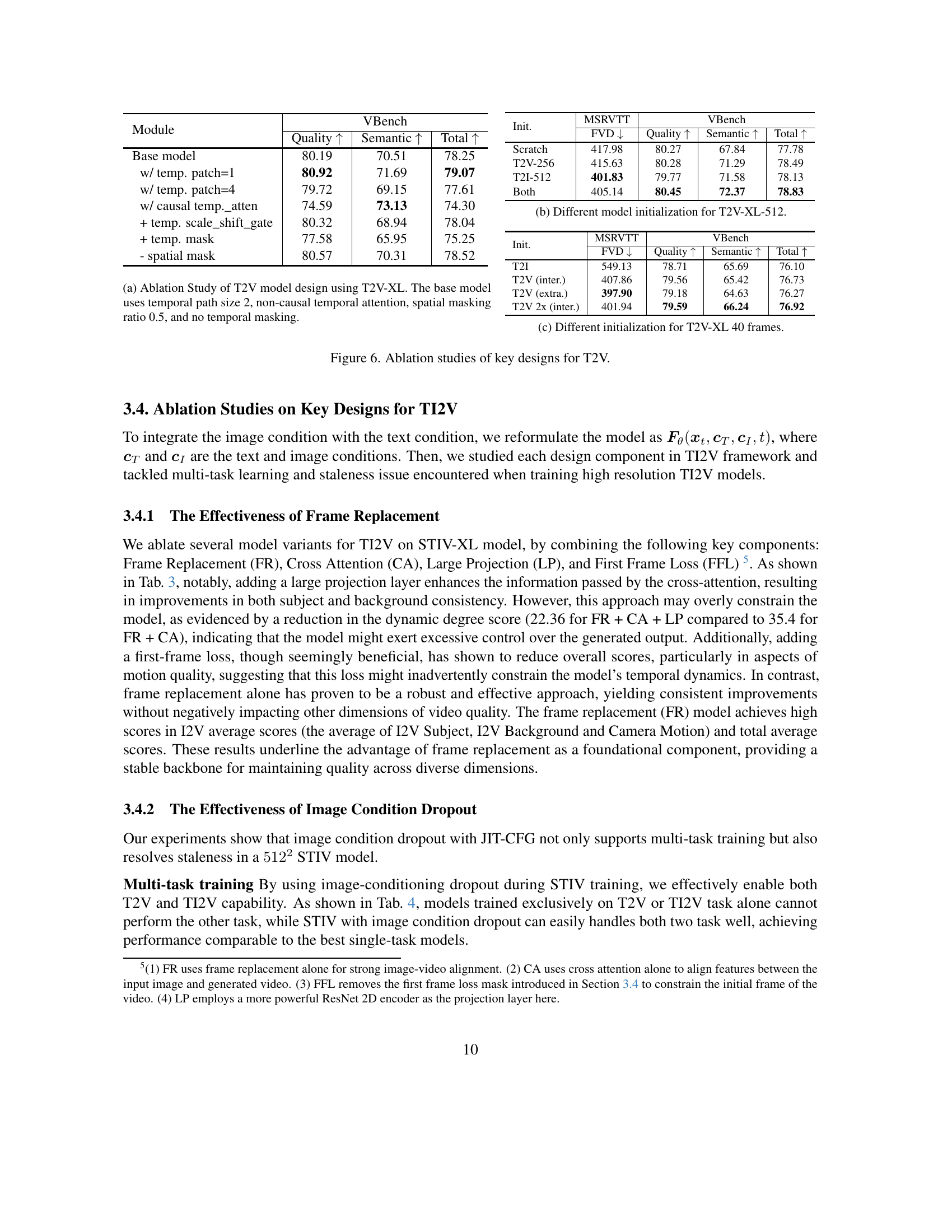
| Module | VBench | ||
|---|---|---|---|
| Base model | 80.19 | 70.51 | 78.25 |
| w/ temp. patch=1 | 80.92 | 71.69 | 79.07 |
| w/ temp. patch=4 | 79.72 | 69.15 | 77.61 |
| w/ causal temp._atten | 74.59 | 73.13 | 74.30 |
| + temp. scale_shift_gate | 80.32 | 68.94 | 78.04 |
| + temp. mask | 77.58 | 65.95 | 75.25 |
| - spatial mask | 80.57 | 70.31 | 78.52 |
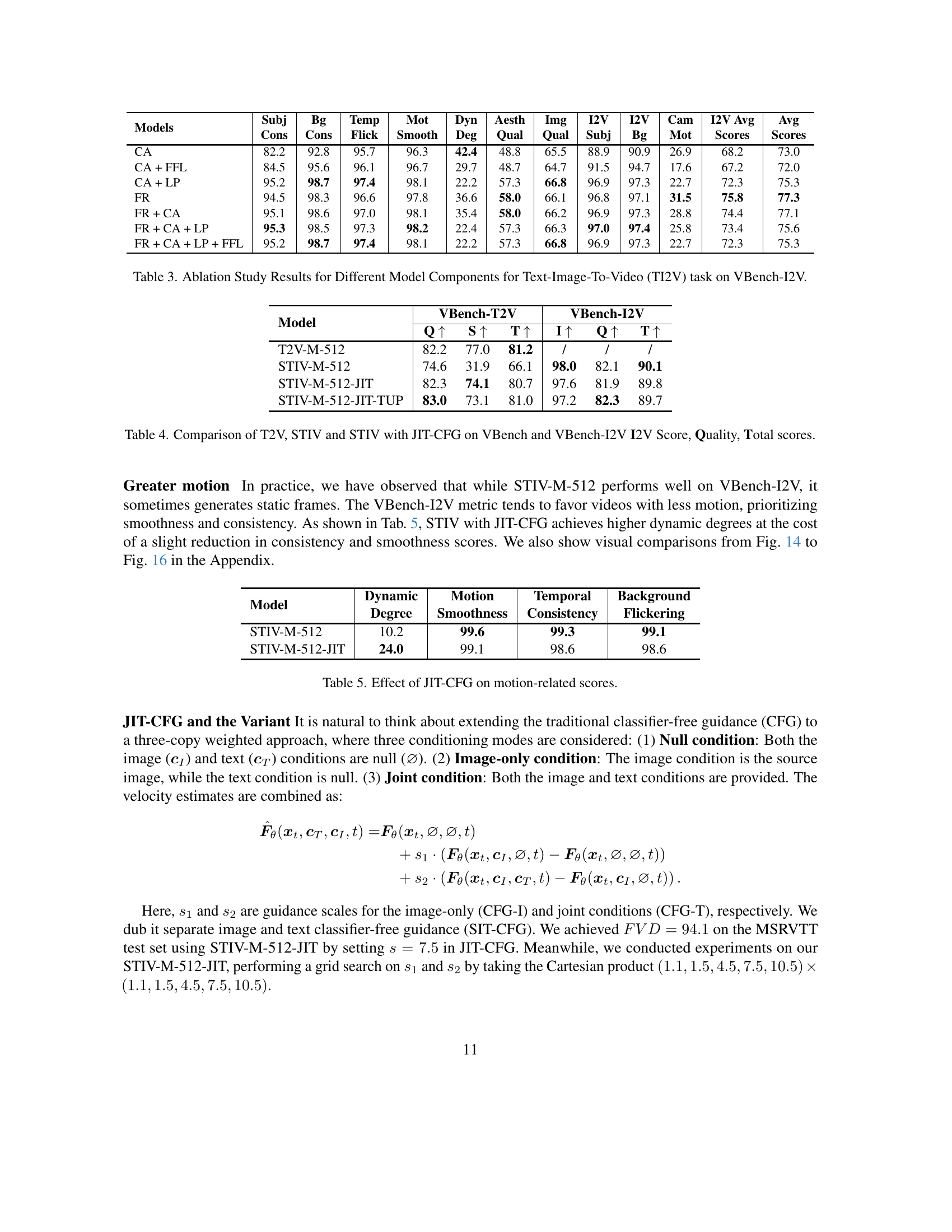
🔼 This table presents the ablation study results for different model components used in the Text-Image-to-Video (TI2V) task, specifically focusing on the VBench-I2V evaluation metric. It showcases the impact of various components on different aspects of video generation quality, such as subject consistency, background consistency, temporal flickering, motion smoothness, dynamic degree, aesthetic quality, image quality, and overall scores. By comparing different model configurations, the table provides insights into which components are most critical for achieving high performance in TI2V video generation.
read the caption
Table 3: Ablation Study Results for Different Model Components for Text-Image-To-Video (TI2V) task on VBench-I2V.
| Init. | MSRVTT ↓ | VBench Quality ↑ | VBench Semantic ↑ | VBench Total ↑ |
|---|---|---|---|---|
| Init. | 417.98 | 80.27 | 67.84 | 77.78 |
| Scratch | 415.63 | 80.28 | 71.29 | 78.49 |
| T2V-256 | 401.83 | 79.77 | 71.58 | 78.13 |
| T2I-512 | 405.14 | 80.45 | 72.37 | 78.83 |
| Both |
🔼 This table presents a quantitative comparison of three different video generation models: Text-to-Video (T2V), Text-Image-to-Video (STIV), and STIV enhanced with Joint Image-Text Classifier-Free Guidance (JIT-CFG). The models are evaluated using two distinct benchmarks: VBench and VBench-I2V. For each model and benchmark, the table provides three key metrics: Quality, I2V (Image-to-Video, specific to the VBench-I2V benchmark), and Total score. The Quality score assesses the overall quality of the generated video, while the I2V score specifically evaluates how well the generated video aligns with the provided input image (relevant only for the STIV models using VBench-I2V). The Total score represents a weighted average combining Quality and I2V scores (where applicable). This comparison facilitates the understanding of how the integration of image conditioning and the JIT-CFG technique impact the performance of video generation models across various quality aspects.
read the caption
Table 4: Comparison of T2V, STIV and STIV with JIT-CFG on VBench and VBench-I2V I2V Score, Quality, Total scores.
| Init. | MSRVTT | VBench (Quality ↑) | VBench (Semantic ↑) | VBench (Total ↑) |
|---|---|---|---|---|
| Init. | MSRVTT | FVD ↓ | Quality ↑ | Semantic ↑ |
| T2I | 549.13 | 78.71 | 65.69 | 76.10 |
| T2V (inter.) | 407.86 | 79.56 | 65.42 | 76.73 |
| T2V (extra.) | 397.90 | 79.18 | 64.63 | 76.27 |
| T2V 2x (inter.) | 401.94 | 79.59 | 66.24 | 76.92 |
🔼 This table presents the impact of using Joint Image-Text Classifier-Free Guidance (JIT-CFG) on the motion quality of videos generated by the STIV model. The metrics shown assess various aspects of motion, such as dynamic degree, temporal smoothness, and background consistency. By comparing the scores with and without JIT-CFG, the table demonstrates the method’s effectiveness in improving the realism and coherence of the generated video’s motion.
read the caption
Table 5: Effect of JIT-CFG on motion-related scores.
| Models | SubjCons | BgCons | TempSmooth | MotDeg | DynQual | AesthQual | ImgSubj | I2VSubj | I2VBg | I2VMot | CamScores | I2VAvgScores | AvgScores | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CA | 82.2 | 92.8 | 95.7 | 96.3 | 42.4 | 48.8 | 65.5 | 88.9 | 90.9 | 26.9 | 68.2 | 73.0 | ||
| CA + FFL | 84.5 | 95.6 | 96.1 | 96.7 | 29.7 | 48.7 | 64.7 | 91.5 | 94.7 | 17.6 | 67.2 | 72.0 | ||
| CA + LP | 95.2 | 98.7 | 97.4 | 98.1 | 22.2 | 57.3 | 66.8 | 96.9 | 97.3 | 22.7 | 72.3 | 75.3 | ||
| FR | 94.5 | 98.3 | 96.6 | 97.8 | 36.6 | 58.0 | 66.1 | 96.8 | 97.1 | 31.5 | 75.8 | 77.3 | ||
| FR + CA | 95.1 | 98.6 | 97.0 | 98.1 | 35.4 | 58.0 | 66.2 | 96.9 | 97.3 | 28.8 | 74.4 | 77.1 | ||
| FR + CA + LP | 95.3 | 98.5 | 97.3 | 98.2 | 22.4 | 57.3 | 66.3 | 97.0 | 97.4 | 25.8 | 73.4 | 75.6 | ||
| FR + CA + LP + FFL | 95.2 | 98.7 | 97.4 | 98.1 | 22.2 | 57.3 | 66.8 | 96.9 | 97.3 | 22.7 | 72.3 | 75.3 |
🔼 This table presents the ablation study results of different model initialization methods on the VBench-I2V benchmark. It compares the performance metrics of TI2V models initialized from different starting points: training from scratch, initializing from a pre-trained T2I model, and initializing from a pre-trained T2V model. The metrics evaluated include subjective scores such as Subject Consistency, Background Consistency, Temporal Flickering, Motion Smoothness, Dynamic Degree, Aesthetic Quality, and Image Quality, and objective scores such as overall I2V score, which is computed as the average of I2V Subject, I2V Background, and I2V Camera Motion.
read the caption
Table 6: Results for different model initialization on VBench-I2V.
| Model | VBench-T2V | VBench-I2V |
|---|---|---|
| Q ↑ | S ↑ | T ↑ |
| T2V-M-512 | 82.2 | 77.0 |
| STIV-M-512 | 74.6 | 31.9 |
| STIV-M-512-JIT | 82.3 | 74.1 |
| STIV-M-512-JIT-TUP | 83.0 | 73.1 |
🔼 This table presents a comparison of the performance of a Text-to-Video (T2V) model trained on two different datasets: Panda-30M and Panda-10M. Panda-10M is a curated subset of Panda-30M, focusing on higher-quality videos to enhance model performance. The table shows the results of evaluating the T2V model’s performance on these two datasets using three metrics: FVD (Fréchet Video Distance), measuring the quality of generated videos, and two VBench scores for quality and semantic relevance. By comparing results from Panda-30M and Panda-10M, the table demonstrates the impact of dataset quality on the effectiveness of training a T2V model. The XL T2V model was used in this comparison.
read the caption
Table 7: Compare Panda-30M and Panda-10M (high-quality) using XL T2V model.
| Model | Dynamic Degree | Motion Smoothness | Temporal Consistency | Background Flickering |
|---|---|---|---|---|
| STIV-M-512 | 10.2 | 99.6 | 99.3 | 99.1 |
| STIV-M-512-JIT | 24.0 | 99.1 | 98.6 | 98.6 |
🔼 This table compares the performance of two different captioning methods for training a text-to-video (T2V) model using the XL model variant. The methods are frame-based captioning followed by large language model (LLM) summarization (FCapLLM), and direct video captioning (VCap). The evaluation metrics used include the total number of objects described in the captions, the number of objects identified as hallucinated using the DSG-Video metric, and the FVD (Fréchet Video Distance) and VBench scores reflecting the overall quality of the videos generated using these captions. 100 randomly selected captions were used for the DSG-Video evaluation.
read the caption
Table 8: Compare different captions using XL T2V model. DSG-Video metrics are calculated from 100 random captions.
| Initialization | Subj | Bg | Temp | Mot | Dyn | Aesth | Img | I2V | I2V | Cam | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| T2V | 94.1 | 98.2 | 96.5 | 97.7 | 37.1 | 57.9 | 65.5 | 96.6 | 96.9 | 38.0 | 77.9 |
| T2I | 94.5 | 98.7 | 96.9 | 97.9 | 36.5 | 57.4 | 66.1 | 96.6 | 97.3 | 29.8 | 77.2 |
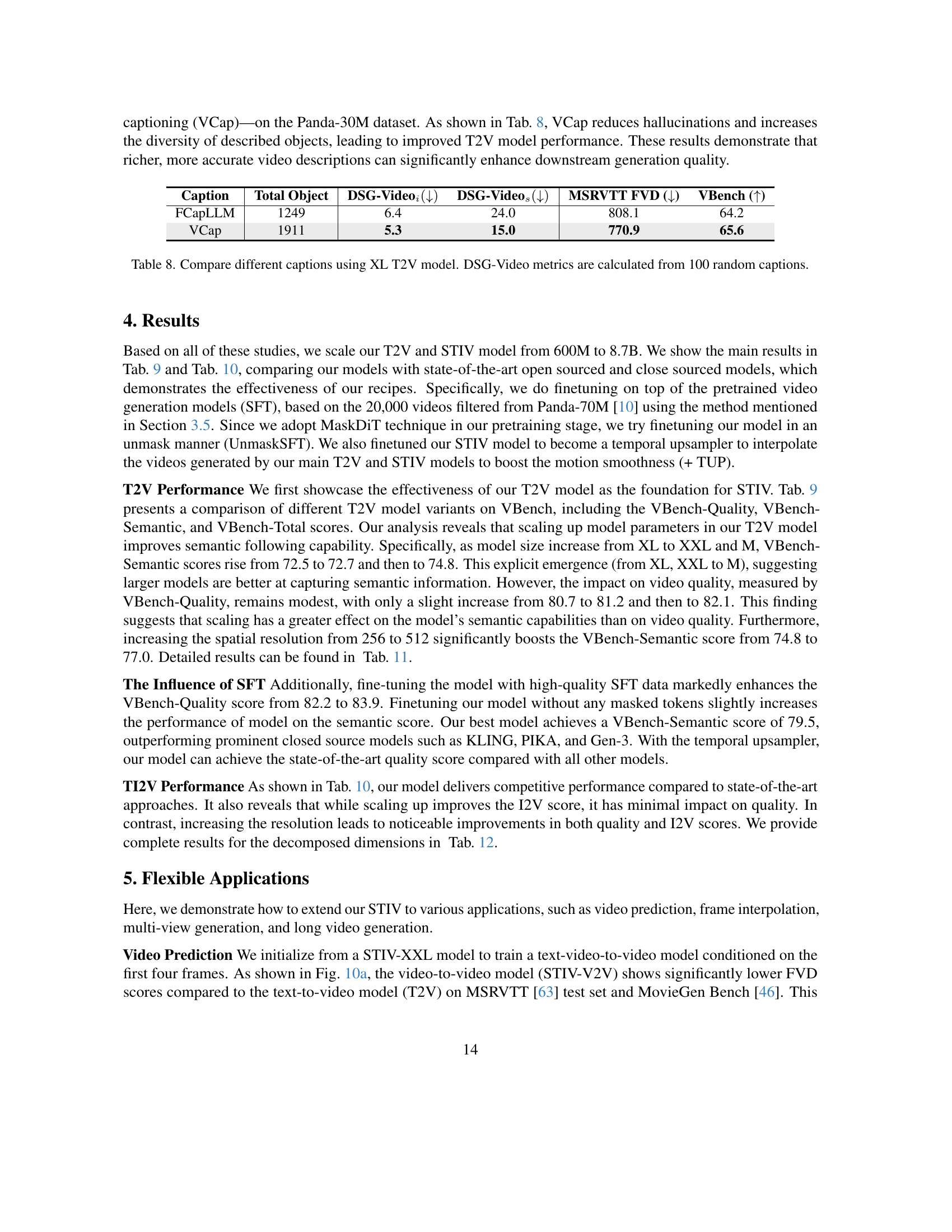
🔼 This table presents a quantitative comparison of the performance of various Text-to-Video (T2V) models on the VBench benchmark. It includes both open-source and closed-source models, allowing for a comprehensive evaluation of the state-of-the-art in T2V. The table specifically compares different variants of the authors’ proposed T2V model (denoted as ‘Ours’) across different scales (XL, XXL, M) and with fine-tuning on high-quality data (SFT) and temporal upsampling (+TUP). This detailed comparison facilitates a thorough analysis of the impact of model scaling, fine-tuning strategies, and architectural choices on the overall quality and semantic alignment of generated videos.
read the caption
Table 9: Performance comparison of T2V variants with open-sourced and close-sourced models on VBench.
| Data | MSRVTT | VBench FVD ↓ | VBench Quality ↑ | VBench Semantic ↑ | VBench Total ↑ |
|---|---|---|---|---|---|
| Panda-30M | 770.9 | 80.4 | 73.6 | 65.6 | |
| Panda-10M | 759.2 | 80.8 | 73.4 | 66.2 |
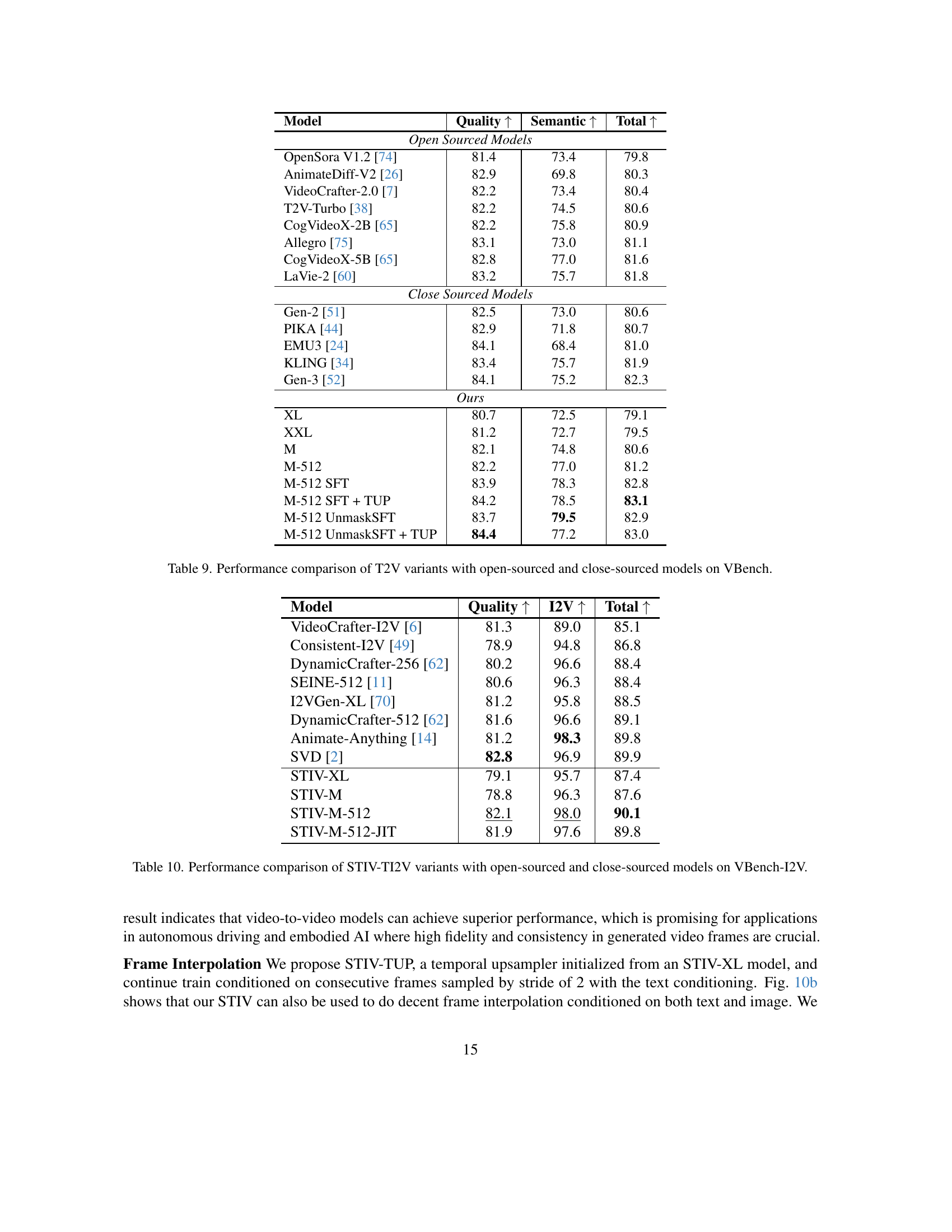
🔼 This table presents a quantitative comparison of the performance of various Text-Image-to-Video (TI2V) models, including the proposed STIV model and its variants, against state-of-the-art open-source and closed-source models. The evaluation is conducted using the VBench-I2V benchmark, a comprehensive evaluation metric specifically designed for TI2V models, focusing on image-video alignment aspects. The table shows the performance scores of different models across multiple metrics within VBench-I2V, facilitating a direct performance comparison and highlighting the effectiveness of the proposed STIV model and its design choices.
read the caption
Table 10: Performance comparison of STIV-TI2V variants with open-sourced and close-sourced models on VBench-I2V.
| Caption | Total Object | DSG-Videoi(↓) | DSG-Videos(↓) | MSRVTT FVD (↓) | VBench (↑) |
|---|---|---|---|---|---|
| FCapLLM | 1249 | 6.4 | 24.0 | 808.1 | 64.2 |
| VCap | 1911 | 5.3 | 15.0 | 770.9 | 65.6 |
🔼 This table presents a detailed quantitative analysis of various text-to-video generation models. It compares performance across multiple metrics, providing a comprehensive evaluation. These metrics cover various aspects of video quality, including temporal consistency (e.g., subject consistency, background consistency, temporal flickering, motion smoothness, dynamic degree), image quality (e.g., aesthetic quality, imaging quality), semantic alignment (e.g., object class, multiple objects, human action), and overall video quality. The models are compared based on their performance scores for each of these individual criteria.
read the caption
Table 11: Detailed Evaluation Results for Text-To-Video Generation Models.
| Model | Quality ↑ | Semantic ↑ | Total ↑ |
|---|---|---|---|
| Open Sourced Models | |||
| OpenSora V1.2 [74] | 81.4 | 73.4 | 79.8 |
| AnimateDiff-V2 [26] | 82.9 | 69.8 | 80.3 |
| VideoCrafter-2.0 [7] | 82.2 | 73.4 | 80.4 |
| T2V-Turbo [38] | 82.2 | 74.5 | 80.6 |
| CogVideoX-2B [65] | 82.2 | 75.8 | 80.9 |
| Allegro [75] | 83.1 | 73.0 | 81.1 |
| CogVideoX-5B [65] | 82.8 | 77.0 | 81.6 |
| LaVie-2 [60] | 83.2 | 75.7 | 81.8 |
| Close Sourced Models | |||
| Gen-2 [51] | 82.5 | 73.0 | 80.6 |
| PIKA [44] | 82.9 | 71.8 | 80.7 |
| EMU3 [24] | 84.1 | 68.4 | 81.0 |
| KLING [34] | 83.4 | 75.7 | 81.9 |
| Gen-3 [52] | 84.1 | 75.2 | 82.3 |
| Ours | |||
| XL | 80.7 | 72.5 | 79.1 |
| XXL | 81.2 | 72.7 | 79.5 |
| M | 82.1 | 74.8 | 80.6 |
| M-512 | 82.2 | 77.0 | 81.2 |
| M-512 SFT | 83.9 | 78.3 | 82.8 |
| M-512 SFT + TUP | 84.2 | 78.5 | 83.1 |
| M-512 UnmaskSFT | 83.7 | 79.5 | 82.9 |
| M-512 UnmaskSFT + TUP | 84.4 | 77.2 | 83.0 |
🔼 This table presents a detailed breakdown of the performance of various text-to-image-to-video generation models. It assesses performance across several key metrics, offering a granular view of each model’s strengths and weaknesses in generating high-quality videos from both text and image inputs. Metrics include various aspects of video quality (both temporal and image quality), the alignment of generated videos with the input text and image conditions, and an overall consistency score. The table also provides a comparison with various state-of-the-art models, allowing for a direct assessment of the relative performance of the models evaluated in the study. Averages are also computed across different dimensions to provide a holistic evaluation.
read the caption
Table 12: Detailed Evaluation Results for Text-Image-To-Video Generation Models.
| Model | Quality ↑ | I2V ↑ | Total ↑ |
|---|---|---|---|
| VideoCrafter-I2V [6] | 81.3 | 89.0 | 85.1 |
| Consistent-I2V [49] | 78.9 | 94.8 | 86.8 |
| DynamicCrafter-256 [62] | 80.2 | 96.6 | 88.4 |
| SEINE-512 [11] | 80.6 | 96.3 | 88.4 |
| I2VGen-XL [70] | 81.2 | 95.8 | 88.5 |
| DynamicCrafter-512 [62] | 81.6 | 96.6 | 89.1 |
| Animate-Anything [14] | 81.2 | 98.3 | 89.8 |
| SVD [2] | 82.8 | 96.9 | 89.9 |
| STIV-XL | 79.1 | 95.7 | 87.4 |
| STIV-M | 78.8 | 96.3 | 87.6 |
| STIV-M-512 | 82.1 | 98.0 | 90.1 |
| STIV-M-512-JIT | 81.9 | 97.6 | 89.8 |
🔼 This table details the computational cost (measured in FLOPs, or floating-point operations) associated with training high-resolution Text-to-Video (T2V) models using different initialization strategies. It breaks down the FLOPs across four training stages, and the total FLOPs are provided for each approach. The unit of measurement for FLOPs is 1021.
read the caption
Table 13: A breakdown of FLOPs for training high resolution T2V models. Unit 1021superscript102110^{21}10 start_POSTSUPERSCRIPT 21 end_POSTSUPERSCRIPT.
| Model | MSRVTT (FVD ↓) | MovieGen (FVD ↓) |
|---|---|---|
| T2V | 536.2 | 347.2 |
| STIV-V2V | 183.7 | 186.3 |
🔼 This table details the computational cost (floating point operations, or FLOPs) associated with training high-frame-count text-to-video (T2V) models using different initialization methods. It breaks down the FLOPs across four training stages for several approaches. The unit for FLOPs is 1021.
read the caption
Table 14: A breakdown of FLOPs for training high frame count T2V models. Unit: 1021superscript102110^{21}10 start_POSTSUPERSCRIPT 21 end_POSTSUPERSCRIPT.
| Model | use text | MSRVTT FID ↓ | MSRVTT FVD ↓ |
|---|---|---|---|
| STIV-TUP | No | 2.2 | 6.3 |
| STIV-TUP | Yes | 2.0 | 5.9 |
🔼 This table presents a detailed comparison of various model initialization methods for training higher-resolution text-to-video (T2V) models. It shows how different initialization strategies impact various aspects of the generated videos as measured by VBench metrics. The metrics cover video quality (temporal consistency, motion smoothness, etc.), video-text alignment (semantics, styles), and overall quality. By comparing different initialization approaches (from scratch, from a lower-resolution T2V model, from a T2I model, and jointly from both T2I and T2V), the table allows for a thorough assessment of the impact of initialization on the final model’s performance.
read the caption
Table 15: Detailed VBench metrics of different model initialization methods for higher resolution T2V model training.
| Model | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Zero123++ [55] | 21.200 | 0.723 | 0.143 |
| STIV-TI2V-XL | 21.643 | 0.724 | 0.156 |
🔼 This table presents a detailed breakdown of the performance metrics from the VBench benchmark for several variations of a text-to-video (T2V) model. These variations differ in how the model is initialized, specifically focusing on how pre-trained models of different resolutions and frame counts are leveraged to initialize the main higher-frame-count T2V model. The goal is to analyze the effectiveness of different initialization strategies on the final model’s performance in terms of visual quality, semantic alignment, and overall consistency. The metrics evaluated include various aspects of video quality and semantic alignment with the prompt.
read the caption
Table 16: Detailed VBench metrics of different model initialization methods for higher frame count T2V model training.
| Model | Subject | Back. | Temporal | Motion | Dynamic | Aesthetic | Imaging | Object | Multiple | Human |
|---|---|---|---|---|---|---|---|---|---|---|
| CogVideoX-5B [65] | 96.2 | 96.5 | 98.7 | 96.9 | 80.0 | 62.0 | 62.9 | 85.2 | 62.1 | 99.4 |
| CogVideoX-2B [65] | 96.8 | 96.6 | 98.9 | 97.7 | 59.9 | 60.8 | 61.7 | 83.4 | 62.6 | 98.0 |
| Allegro [75] | 96.3 | 96.7 | 99.0 | 98.8 | 55.0 | 63.7 | 63.6 | 87.5 | 59.9 | 91.4 |
| AnimateDiff-V2 [26] | 95.3 | 97.7 | 98.8 | 97.8 | 40.8 | 67.2 | 70.1 | 90.9 | 36.9 | 92.6 |
| OpenSora V1.2 [74] | 96.8 | 97.6 | 99.5 | 98.5 | 42.4 | 56.9 | 63.3 | 82.2 | 51.8 | 91.2 |
| T2V-Turbo [38] | 96.3 | 97.0 | 97.5 | 97.3 | 49.2 | 63.0 | 72.5 | 94.0 | 54.7 | 95.2 |
| VideoCrafter-2.0 [7] | 96.9 | 98.2 | 98.4 | 97.7 | 42.5 | 63.1 | 67.2 | 92.6 | 40.7 | 95.0 |
| LaVie-2 [60] | 97.9 | 98.5 | 98.8 | 98.4 | 31.1 | 67.6 | 70.4 | 97.5 | 64.9 | 96.4 |
| LaVIE [60] | 91.4 | 97.5 | 98.3 | 96.4 | 49.7 | 54.9 | 61.9 | 91.8 | 33.3 | 96.8 |
| ModelScope [59] | 89.9 | 95.3 | 98.3 | 95.8 | 66.4 | 52.1 | 58.6 | 82.2 | 39.0 | 92.4 |
| VideoCrafter [6] | 86.2 | 92.9 | 97.6 | 91.8 | 89.7 | 44.4 | 57.2 | 87.3 | 25.9 | 93.0 |
| CogVideo [30] | 92.2 | 95.4 | 97.6 | 96.5 | 42.2 | 38.2 | 41.0 | 73.4 | 18.1 | 78.2 |
| PIKA [44] | 96.9 | 97.4 | 99.7 | 99.5 | 47.5 | 62.4 | 61.9 | 88.7 | 43.1 | 86.2 |
| Gen-3 [52] | 97.1 | 96.6 | 98.6 | 99.2 | 60.1 | 63.3 | 66.8 | 87.8 | 53.6 | 96.4 |
| Gen-2 [51] | 97.6 | 97.6 | 99.6 | 99.6 | 18.9 | 67.0 | 67.4 | 90.9 | 55.5 | 89.2 |
| KLING [34] | 98.3 | 97.6 | 99.3 | 99.4 | 46.9 | 61.2 | 65.6 | 87.2 | 68.1 | 93.4 |
| EMU3 [24] | 95.3 | 97.7 | 98.6 | 98.9 | 79.3 | 59.6 | 62.6 | 86.2 | 44.6 | 77.7 |
| XL | 96.0 | 98.5 | 98.4 | 96.5 | 62.5 | 56.3 | 59.3 | 91.5 | 41.3 | 98.0 |
| XXL | 97.5 | 98.9 | 99.1 | 98.2 | 48.6 | 56.2 | 59.7 | 91.1 | 49.1 | 99.0 |
| M-256 | 96.0 | 98.5 | 98.6 | 97.2 | 68.1 | 57.0 | 60.8 | 88.8 | 62.1 | 98.0 |
| M-512 | 95.9 | 96.9 | 98.8 | 98.0 | 59.7 | 60.6 | 62.5 | 85.9 | 72.4 | 96.0 |
| M-512-SFT | 96.7 | 97.4 | 98.7 | 98.3 | 70.8 | 61.7 | 63.9 | 88.1 | 67.7 | 97.0 |
| M-512-SFT+TUP | 94.8 | 95.9 | 98.7 | 99.2 | 70.8 | 63.7 | 65.0 | 88.9 | 70.3 | 95.0 |
| M-512-UnMSFT | 94.3 | 96.9 | 98.8 | 96.7 | 77.8 | 61.4 | 68.6 | 90.0 | 72.3 | 97.0 |
| M-512-UnMSFT+TUP | 95.2 | 95.8 | 98.8 | 99.2 | 70.8 | 63.6 | 65.9 | 90.0 | 69.8 | 94.0 |
| Model | Color | Spatial | Scene | App. | Temp. | Overall | Quality | Semantic | Total | Averaged |
| — | — | — | — | — | — | — | — | — | — | — |
| CogVideoX-5B [65] | 82.8 | 66.4 | 53.2 | 24.9 | 25.4 | 27.6 | 82.8 | 77.0 | 81.6 | 70.0 |
| CogVideoX-2B [65] | 79.4 | 69.9 | 51.1 | 24.8 | 24.4 | 26.7 | 82.2 | 75.8 | 80.9 | 68.3 |
| Allegro [75] | 82.8 | 67.2 | 46.7 | 20.5 | 24.4 | 26.4 | 83.1 | 73.0 | 81.1 | 67.5 |
| AnimateDiff-V2 [26] | 87.5 | 34.6 | 50.2 | 22.4 | 26.0 | 27.0 | 82.9 | 69.8 | 80.3 | 64.7 |
| OpenSora V1.2 [74] | 90.1 | 68.6 | 42.4 | 24.0 | 24.5 | 26.9 | 81.4 | 73.4 | 79.8 | 66.0 |
| T2V-Turbo [38] | 89.9 | 38.7 | 55.6 | 24.4 | 25.5 | 28.2 | 82.6 | 74.8 | 81.0 | 67.4 |
| VideoCrafter-2.0 [7] | 92.9 | 35.9 | 55.3 | 25.1 | 25.8 | 28.2 | 82.2 | 73.4 | 80.4 | 66.0 |
| LaVie-2 [60] | 91.7 | 38.7 | 49.6 | 25.1 | 25.2 | 27.4 | 83.2 | 75.8 | 81.8 | 67.6 |
| LaVIE [60] | 86.4 | 34.1 | 52.7 | 23.6 | 25.9 | 26.4 | 78.8 | 70.3 | 77.1 | 63.8 |
| ModelScope [59] | 81.7 | 33.7 | 39.3 | 23.4 | 25.4 | 25.7 | 78.1 | 66.5 | 75.8 | 62.4 |
| VideoCrafter [6] | 78.8 | 36.7 | 43.4 | 21.6 | 25.4 | 25.2 | 81.6 | 72.2 | 79.7 | 62.3 |
| CogVideo [30] | 79.6 | 18.2 | 28.2 | 22.0 | 7.8 | 7.7 | 72.1 | 46.8 | 67.0 | 52.3 |
| PIKA [44] | 90.6 | 61.0 | 49.8 | 22.3 | 24.2 | 25.9 | 82.9 | 71.8 | 80.7 | 66.1 |
| Gen-3 [52] | 80.9 | 65.1 | 54.6 | 24.3 | 24.7 | 26.7 | 84.1 | 75.2 | 82.3 | 68.5 |
| Gen-2 [51] | 89.5 | 66.9 | 48.9 | 19.3 | 24.1 | 26.2 | 82.5 | 73.0 | 80.6 | 66.1 |
| KLING [34] | 89.9 | 73.0 | 50.9 | 19.6 | 24.2 | 26.4 | 83.4 | 75.7 | 81.9 | 68.8 |
| EMU3 [24] | 88.3 | 68.7 | 37.1 | 20.9 | 23.3 | 24.8 | 84.1 | 68.4 | 81.0 | 66.7 |
| XL | 86.4 | 42.4 | 54.4 | 22.4 | 26.3 | 27.8 | 80.7 | 72.5 | 79.1 | 66.1 |
| XXL | 90.8 | 45.1 | 45.5 | 22.1 | 26.1 | 27.4 | 81.2 | 72.7 | 79.5 | 65.9 |
| M-256 | 83.6 | 44.5 | 54.7 | 22.5 | 26.6 | 28.4 | 82.7 | 74.8 | 80.6 | 67.9 |
| M-512 | 91.2 | 51.0 | 53.6 | 23.9 | 25.8 | 27.8 | 82.2 | 77.0 | 81.2 | 68.8 |
| M-512-SFT | 93.7 | 58.0 | 52.8 | 24.6 | 26.2 | 28.5 | 83.9 | 78.3 | 82.8 | 70.3 |
| M-512-SFT+TUP | 94.7 | 50.6 | 57.3 | 24.5 | 26.7 | 28.6 | 84.2 | 78.5 | 83.1 | 70.3 |
| M-512-UnMSFT | 92.0 | 59.8 | 53.1 | 24.8 | 26.7 | 28.8 | 83.7 | 79.5 | 82.9 | 71.2 |
| M-512-UnMSFT+TUP | 87.7 | 46.9 | 57.1 | 24.5 | 26.6 | 28.5 | 84.4 | 77.2 | 83.0 | 69.7 |
🔼 This table presents a quantitative evaluation of class-to-video generation models on the UCF-101 dataset. It compares several models, including the proposed STIV model, across two key metrics: Inception Score (IS), measuring the quality and diversity of generated videos, and Fréchet Video Distance (FVD), assessing the realism of the generated videos by comparing their distribution to the distribution of real videos. Higher IS values and lower FVD values indicate better performance. The table also includes results for the STIV model with different ablations such as adding spatial or temporal masks, indicating how these changes affect model performance.
read the caption
Table 17: Performance of Class-to-Video Generation on UCF-101.
Full paper#