↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image generation and editing methods often focus on specific tasks, leading to a proliferation of task-specific models and datasets. This specialization hinders the development of more generalizable and efficient solutions. Furthermore, existing methods often lack the ability to seamlessly handle diverse input-output configurations and complex scenarios such as variations in lighting, shadows, or object poses.
UniReal addresses these limitations by proposing a unified framework that treats image-level tasks as discontinuous video generation. By training on large-scale video data, UniReal learns to handle various image generation and editing tasks within a single model, demonstrating versatility in handling complex scenarios and generating highly realistic results. The hierarchical prompting and image embedding schemes effectively manage different types of image tasks and input/output configurations. This approach demonstrates improved efficiency and generalizability compared to task-specific models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UniReal, a novel unified framework for image generation and editing tasks. Its ability to handle diverse tasks with a single model, trained with universal supervision from large-scale videos, is a significant advancement. This opens new avenues for research in generalizable image manipulation and offers a more efficient approach compared to task-specific models.
Visual Insights#

🔼 UniReal, a universal image generation and editing framework, is shown in Figure 1 to be capable of handling a wide variety of tasks with diverse input-output configurations. The model produces highly realistic results and adeptly manages challenging conditions such as shadows, reflections, lighting variations, and alterations in object positioning.
read the caption
Figure 1: Demonstrations of UniReal’s versatile capabilities. As a universal framework, UniReal supports a broad spectrum of image generation and editing tasks within a single model, accommodating diverse input-output configurations and generating highly realistic results, which effectively handle challenging scenarios, e.g., shadows, reflections, lighting effects, object pose changes, etc.
| No. | Dataset | # Samples | Supporting Tasks |
|---|---|---|---|
| 1 | InstructP2P [1] | 300K | Universal Instructive Editing |
| 2 | UltraEdit [72] | 500K | Universal Instructive Editing |
| 3 | VTON-HD [11] | 10K | Virtual Try-on |
| 4 | RefCOCO Series [24, 33] | 150K | Referring Segmentation |
| 5 | T2I Generation (in house) | 300M | Text to Image Generation |
| 6 | Instruct Editing (in house) | 2M | Universal Instructive Editing |
| 7 | Object Insertion (in house) | 100K | Object Insertion with Reference |
| 8 | Video Frame2Frame | 8M | Universal Instructive Editing |
| 9 | Video Multi-object | 5M | Multi-subject Customization |
| 10 | Video Object Insertion | 1M | Object Insertion with Reference |
| 11 | Video ObjectAdd | 1M | Object Insertion with Prompt |
| 12 | Video SEG | 5M | Referring Segmentation |
| 13 | Video Control | 3M | Perception, Controllable Generation |
🔼 This table presents a summary of the datasets used to train the UniReal model. It’s divided into two sections: existing datasets used in prior research and newly created video-based datasets. The table lists each dataset’s name, the number of samples it contains, and the specific image generation or editing tasks it supports. The combination of these datasets provides comprehensive training data for the model, covering a wide range of image manipulation tasks.
read the caption
Table 1: Statistics of datasets used for training. We mix the existing datasets (the first block) with our newly constructed video-based datasets (the second block).
In-depth insights#
UniReal: A Unified Approach#
UniReal proposes a unified framework for addressing diverse image generation and editing tasks. Instead of task-specific models, it leverages a single model trained on a combination of existing datasets and newly constructed video-based data. This approach is inspired by video generation models, treating image-level tasks as discontinuous video sequences. UniReal’s strength lies in its ability to handle various input-output configurations and generate highly realistic results, even in challenging scenarios. By learning real-world dynamics from large-scale videos, the model demonstrates significant capabilities in managing shadows, reflections, and pose variation. A key innovation is the use of hierarchical prompting, enabling fine-grained control over the generation process and promoting task synergy. While the model shows promise for emergent capabilities, further research may be needed to ensure stability when handling a large number of inputs and outputs.
Video-Based Supervision#
The concept of “Video-Based Supervision” offers a compelling approach to training image generation and editing models. Instead of relying on painstakingly labeled image datasets, this method leverages the rich temporal information present in videos. Videos naturally contain a wide range of variations, including changes in lighting, object pose, and scene composition, which directly translate to the diverse transformations needed for image manipulation tasks. This approach is particularly powerful because it avoids the limitations of static image datasets, which often fail to capture the full spectrum of real-world visual dynamics. By treating image-level tasks as discontinuous video generation, the model learns to bridge the gap between different visual states, leading to improved generalization and robustness. The scalability of video data allows for a significant increase in training data compared to traditional approaches, potentially leading to more powerful and versatile models. However, it is crucial to consider how to effectively handle the temporal context in videos and how to design appropriate loss functions that emphasize both consistency and natural variations across frames to ensure effective learning and avoid unwanted artifacts.
Hierarchical Prompting#
The concept of “Hierarchical Prompting” in the context of a universal image generation and editing framework like UniReal is a crucial innovation. It addresses the inherent ambiguity in handling diverse tasks with a single model. By structuring prompts hierarchically, UniReal disentangles complex instructions into manageable components. A base prompt defines the core task, while context prompts specify data source characteristics (e.g., “realistic,” “synthetic”) and image prompts classify input image roles (e.g., “canvas,” “asset,” “control”). This layered approach enhances model understanding, reducing confusion during training and inference. The hierarchical structure also promotes task synergy by enabling the model to leverage common features across different task types, thereby improving efficiency and generalization. This is especially critical when dealing with mixed data sources having varying levels of task-specific annotation and clarity. The use of hierarchical prompting is a smart solution to the challenge of building a truly universal model by simplifying task encoding and fostering a more robust learning process.
UniReal’s Limitations#
UniReal, while a powerful model, faces limitations stemming from its architecture and training data. Stability decreases as the number of input/output images increases, exceeding 3-4 proves computationally expensive and impacts performance. This suggests a scalability bottleneck inherent in the framework, possibly related to the attention mechanisms used to model relationships between multiple images. The reliance on video data, while providing universal supervision, may not fully capture the nuances of all tasks. While effective, video data might lack the fine-grained control and annotation often present in task-specific datasets. This could lead to issues in generating results with precision for certain detailed image editing operations. The need for extensive training data across diverse tasks contributes to the model’s complexity and resource demands. Addressing these limitations requires further exploration of more efficient model architectures and potentially augmented training strategies. For example, investigating alternative attention mechanisms or incorporating more task-specific data alongside the video data could improve both scalability and accuracy. Future work could also focus on refining data collection methods for improved quality and annotation, leading to more robust and versatile performance across a broader spectrum of applications.
Future Research#
Future research directions for UniReal could focus on enhancing its scalability to handle a larger number of input/output images while maintaining efficiency. Improving the model’s ability to understand and respond to more complex and nuanced prompts is crucial. Exploring alternative training strategies, such as incorporating self-supervised learning or reinforcement learning, could lead to better generalization and robustness. Further investigation into the model’s limitations, particularly regarding the handling of highly complex scenes or intricate object interactions, would help to refine its capabilities. Developing more sophisticated methods for handling ambiguity and uncertainty in prompts is essential. Finally, exploring applications beyond image editing and generation, such as video editing or 3D model manipulation, leveraging UniReal’s foundation, would represent a significant advancement.
More visual insights#
More on figures

🔼 UniReal processes image generation and editing tasks as a discontinuous video generation process. Input images are first encoded into a latent space using a Variational Autoencoder (VAE). These latent representations, along with noise latents, are then divided into patches and converted into visual tokens. Index embeddings and image prompts (classifying each image as an ‘asset’, ‘canvas’, or ‘control’ image) are added to these visual tokens. Concurrently, context and base prompts (textual instructions) are processed by a T5 text encoder to generate text embeddings. Visual and text embeddings are combined into a single, long 1D tensor, which is fed into a transformer network with full attention. Finally, a VAE decoder reconstructs the denoised latent representations to produce the desired output images.
read the caption
Figure 2: Overall pipeline of UniReal. We formulate image generation and editing tasks as discontinuous frame generation. First, input images are encoded into latent space by VAE encoder. Then, we patchify the image latent and noise latent into visual tokens. Afterward, we add index embeddings and image prompt (asset/canvas/control) to the visual tokens. At the same time, the context prompt and base prompt are processed by the T5 encoder. We concatenate all the latent patches and text embeddings as a long 1D tensor and send them to the transformer. Finally, we decode the denoised results to get the desired output images.

🔼 This figure illustrates the process of creating a dataset for training the UniReal model. It starts with raw video data. Off-the-shelf models automatically extract information like video captions and segment objects from video frames. This information is used to construct various types of training data, including instructive image editing and image customization. The process is shown visually, with two example datasets at the bottom that show how object segmentation from one frame is used to generate a second, modified frame.
read the caption
Figure 3: Data construction pipeline. Starting from raw videos, we use off-the-shelf models to construct data for different kinds of tasks. Two examples of instructive editing and image customization data (we segment objects from one frame to generate another frame) are given at the bottom of the image.

🔼 Figure 4 presents a comparison of UniReal’s performance on instructive image editing against several state-of-the-art methods: OmniGen, UltraEdit, MGIE, InstructPix2Pix, and CosXL. The results showcase UniReal’s superior ability to follow instructions accurately and produce high-quality image edits. Multiple results were generated for each method, with only the best example shown for each.
read the caption
Figure 4: Comparison results for instructive image editing. We compare with the state-of-the-art methods OmniGen [60], UltraEdit [72], MGIE [13], InstructPix2Pix [1], and CosXL [52]. Our UniReal shows significant advantages in the aspects of instruction-following and generation quality. We generate multiple results for each model and pick the best ones for demonstration.

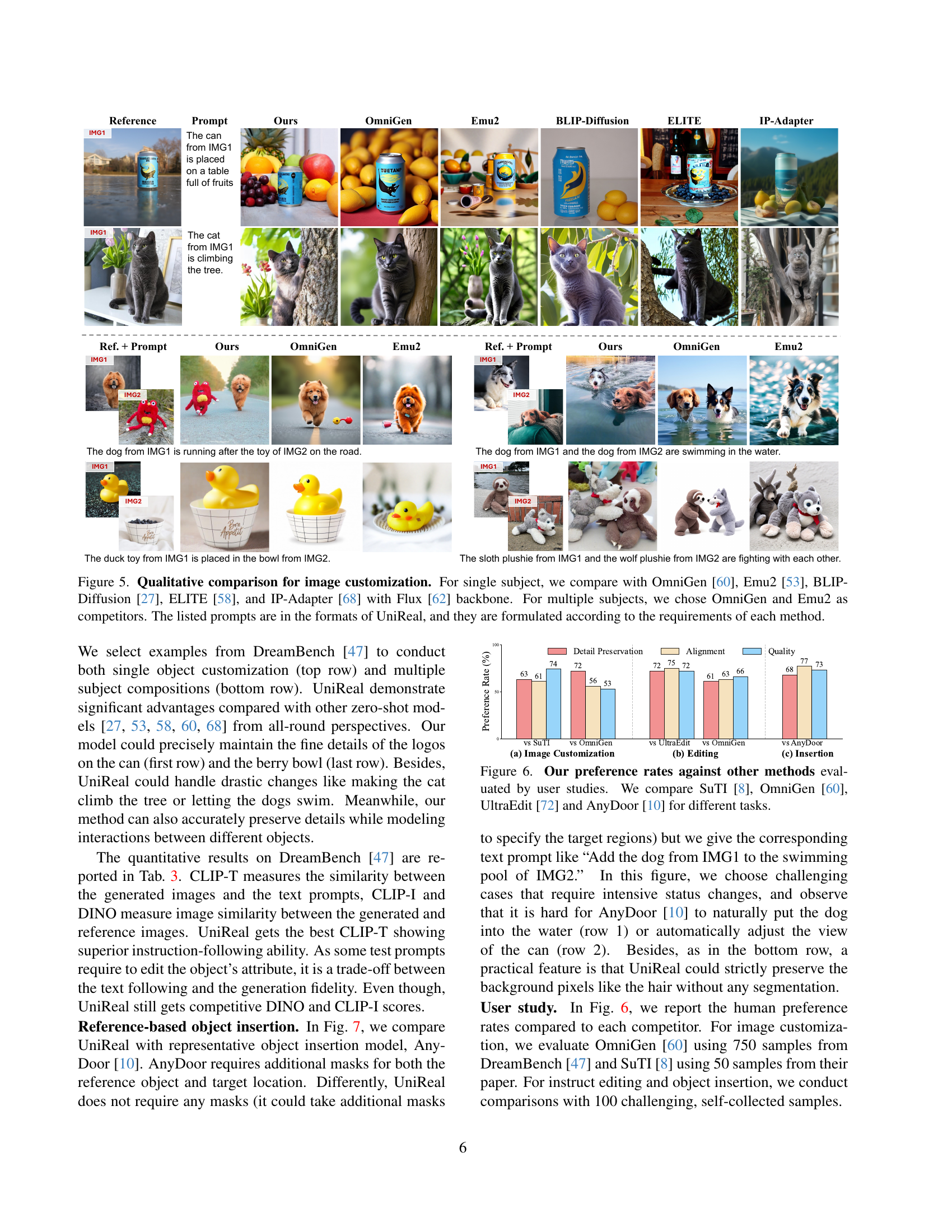
🔼 Figure 5 presents a qualitative comparison of image customization results. The top row demonstrates single-subject customization, where UniReal’s performance is compared against OmniGen, Emu2, BLIP-Diffusion, ELITE, and IP-Adapter (using the Flux backbone). The bottom row shows multi-subject customization, with comparisons made against OmniGen and Emu2. The prompts used in this experiment are formatted according to UniReal’s method and tailored to each model’s specific input requirements to ensure a fair comparison.
read the caption
Figure 5: Qualitative comparison for image customization. For single subject, we compare with OmniGen [60], Emu2 [53], BLIP-Diffusion [27], ELITE [58], and IP-Adapter [68] with Flux [62] backbone. For multiple subjects, we chose OmniGen and Emu2 as competitors. The listed prompts are in the formats of UniReal, and they are formulated according to the requirements of each method.

🔼 Figure 6 presents a detailed comparison of user preference rates for UniReal against several state-of-the-art methods across three distinct image manipulation tasks: image customization, instructive editing, and object insertion. For each task, user preferences were collected and compared against the results produced by SuTI [8], OmniGen [60], UltraEdit [72], and AnyDoor [10]. The bar chart visually represents the percentage of users who preferred UniReal’s output for each task, providing a clear and quantitative assessment of UniReal’s performance relative to existing approaches. This figure offers crucial insights into the effectiveness of UniReal’s methodology and its advantages over alternative techniques in diverse image manipulation scenarios.
read the caption
Figure 6: Our preference rates against other methods evaluated by user studies. We compare SuTI [8], OmniGen [60], UltraEdit [72] and AnyDoor [10] for different tasks.

🔼 Figure 7 showcases the effectiveness of the UniReal model in object insertion tasks. Unlike other methods which often require manual segmentation masks, UniReal automatically integrates the reference object into the target image, seamlessly adjusting its pose and attributes to match the context. The background is consistently maintained, avoiding artifacts and preserving its integrity. This demonstrates UniReal’s capacity to perform complex object insertion without explicit guidance on object placement or segmentation.
read the caption
Figure 7: Comparison results for object insertion. Our method could automatically adjust the status of the reference object according to the environment and strictly preserve the background. Our method does not require any mask as input.

🔼 This figure demonstrates the impact of UniReal’s hierarchical prompting system on image generation and editing. The same input images are used in each row, but different results are obtained by changing the image prompt (row 1) and the context prompt (row 2). This highlights the ability of the system to achieve diverse output by altering prompts, even with the same base input. The results shown in the figure include examples of varied effects achieved, such as addition or removal of objects, alteration of attributes, and changes in scene backgrounds. It shows how careful prompt engineering enables controlling the outcome of the image generation or editing process within UniReal.
read the caption
Figure 8: Effects of hierarchical prompt. The same input could correspond to various types of targets when given different image prompts (row 1) and context prompts (row 2).

🔼 This ablation study investigates the impact of different training data on UniReal’s performance. Three models were trained: one using only the Video Frame2Frame dataset (pairs of video frames with captions describing the changes), another using task-specific expert datasets (curated datasets for specific image editing tasks), and a third using a combination of both (the full dataset). The results demonstrate that even a model trained solely on the Video Frame2Frame dataset, a less curated and more general source of data, can successfully perform a variety of image editing tasks including adding or removing objects, changing attributes, or adjusting poses. This finding highlights the effectiveness of the video data as a scalable and universal training approach for generalizable image editing and generation.
read the caption
Figure 9: Ablation study for the training data. We visualize the results for models that are trained on Video Frame2Frame dataset, task-specific expert dataset, and our multi-task full dataset. It is impressive that the model trained only on video data could master many editing tasks (e.g., add, remove, attribute/pose changing), even for tasks with multiple input images.
More on tables
| Method | CLIPdir↑ | CLIPim↑ | CLIPout↑ | L1↓ | DINO↑ | CLIPdir↑ | CLIPim↑ | CLIPout↑ | L1↓ | DINO↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| InstructPix2Pix [1] | 0.078 | 0.834 | 0.219 | 0.121 | 0.762 | 0.115 | 0.837 | 0.245 | 0.093 | 0.767 |
| MagicBrush [69] | 0.090 | 0.838 | 0.222 | 0.100 | 0.776 | 0.123 | 0.883 | 0.261 | 0.058 | 0.871 |
| PnP [55] | 0.028 | 0.521 | 0.089 | 0.304 | 0.153 | 0.025 | 0.568 | 0.101 | 0.289 | 0.220 |
| Null-Text Inv. [35] | 0.101 | 0.761 | 0.236 | 0.075 | 0.678 | 0.121 | 0.752 | 0.263 | 0.077 | 0.664 |
| UltraEdit [72] | 0.107 | 0.793 | 0.283 | 0.071 | 0.844 | - | 0.868 | - | 0.088 | 0.792 |
| EMU Edit [48] | 0.109 | 0.859 | 0.231 | 0.094 | 0.819 | 0.135 | 0.897 | 0.261 | 0.052 | 0.879 |
| ACE [15] | 0.086 | 0.895 | 0.274 | 0.076 | 0.862 | - | - | 0.284 | - | - |
| OmniGen [60] | - | 0.836 | 0.233 | - | 0.804 | - | - | - | - | - |
| PixWizard [29] | 0.104 | 0.845 | 0.248 | 0.069 | 0.798 | 0.124 | 0.884 | 0.265 | 0.063 | 0.876 |
| UniReal (ours) | 0.127 | 0.851 | 0.285 | 0.099 | 0.790 | 0.151 | 0.903 | 0.308 | 0.081 | 0.837 |
🔼 This table presents a quantitative comparison of various models’ performance on two instructive image editing datasets: EMU Edit and MagicBrush. The models are categorized into task-specific models (designed for a single editing task) and concurrent universal models (designed to handle various image editing tasks). The comparison uses metrics such as CLIP direction (CLIP dir), CLIP image (CLIP im), CLIP output (CLIP out), L1 distance (L1), and DINO similarity (DINO) to assess the models’ ability to accurately follow instructions, maintain image consistency, and produce high-quality results. These metrics evaluate alignment with instruction, preservation of source image details, and the quality of the edited output.
read the caption
Table 2: Comparison results for instructive image editing on EMU Edit [48] and MagicBrush [69] test sets. We list the task-specific models in the first block and some concurrent universal models in the second block.
| Model | CLIP-T↑ | CLIP-I↑ | DINO↑ |
|---|---|---|---|
| Oracle (reference images) | - | 88.5 | 77.4 |
| Textual Inversion [35] | 0.255 | 0.780 | 0.569 |
| DreamBooth [47] | 0.305 | 0.803 | 0.668 |
| BLIP-Diffusion [27] | 0.302 | 0.805 | 0.670 |
| ELITE [58] | 0.296 | 0.772 | 0.647 |
| Re-Imagen [7] | 0.270 | 0.740 | 0.600 |
| BootPIG [42] | 0.311 | 0.797 | 0.674 |
| SuTI [8] | 0.304 | 0.819 | 0.741 |
| OmniGen [60] (our test) | 0.320 | 0.810 | 0.693 |
| UniReal (ours) | 0.326 | 0.806 | 0.702 |
🔼 This table presents a quantitative comparison of different methods for image generation customization on the DreamBench benchmark [47]. The evaluation focuses on customized generation, comparing both fine-tuning approaches and zero-shot methods. The ‘Oracle’ row indicates the best possible performance, acting as an upper bound. Results are reported using several metrics, including CLIP-T (measuring text-image agreement), CLIP-I (comparing generated and reference images), and DINO (another image similarity metric). This allows for a comprehensive assessment of the effectiveness of various techniques in achieving high-fidelity image generation that adheres to the specified customizations.
read the caption
Table 3: Quantitative results for customized generation on DreamBench [47]. We report the oracle results in the first row and compare both tuning methods and zero-shot methods.
| Method | MagicBrush Test set | DreamBench | |||||
|---|---|---|---|---|---|---|---|
| CLIPdir↑ | CLIPout↑ | DINO↑ | CLIP-T↑ | CLIP-I↑ | DINO↑ | ||
| w/o Context Prompt | 0.144 | 0.294 | 0.769 | 0.315 | 0.781 | 0.683 | |
| w/o Image Prompt | 0.136 | 0.305 | 0.809 | 0.295 | 0.782 | 0.698 | |
| only Expert Data | 0.139 | 0.310 | 0.788 | 0.309 | 0.790 | 0.708 | |
| UniReal-full | 0.151 | 0.308 | 0.837 | 0.326 | 0.806 | 0.702 |
🔼 Table 4 presents a quantitative analysis of the core components of the UniReal model. It assesses the model’s performance on two distinct benchmark datasets: MagicBrush [69] and DreamBench [47]. The table shows the impact of key components, such as the context prompt and image prompt, on various metrics, providing a detailed comparison of the model’s performance with and without these components. The metrics likely include scores evaluating the quality of image generation and editing based on the datasets’ specific evaluation criteria.
read the caption
Table 4: Quantitative studies for our basic components on MagicBrush [69] test sets, and DreamBench [47].
Full paper#