↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-video synthesis methods struggle to precisely control the motion of generated videos, relying heavily on textual descriptions which are often ambiguous. Existing motion transfer methods often utilize UNet architectures and are computationally expensive. There’s a need for a more efficient and effective motion transfer technique tailored for the latest Diffusion Transformer models, which offer improved scalability and realism.
DiTFlow addresses these limitations by leveraging the attention mechanism of Diffusion Transformers to extract motion patterns directly from the video. It employs a training-free, optimization-based approach using Attention Motion Flow (AMF) to guide the video generation process, resulting in realistic motion transfer. DiTFlow outperforms existing methods across various metrics and even enables zero-shot motion transfer via positional embedding optimization, significantly reducing computational costs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces DiTFlow, a novel method for video motion transfer specifically designed for Diffusion Transformers (DiTs). This addresses a significant limitation in current video generation models by enabling more precise control over the motion in generated videos. It opens up new avenues for research in video editing, animation, and special effects, particularly in leveraging the efficiency and scalability of DiTs. The training-free nature of DiTFlow also offers practical advantages for researchers and developers.
Visual Insights#

🔼 This figure illustrates the DiTFlow method, which adapts video motion transfer for Diffusion Transformers (DiTs). The top row shows a reference video whose motion is to be transferred. The bottom row displays newly generated videos based on arbitrary text prompts. DiTFlow uses a training-free approach, extracting motion information from the reference video and applying it to the generation process. A key aspect is optimizing DiT-specific positional embeddings, enabling the generation of new videos without additional training (zero-shot synthesis).
read the caption
Figure 1: Overview of DiTFlow. We propose a motion transfer method tailored for video Diffusion Transformers (DiT). We exploit a training-free strategy to transfer the motion of a reference video (top) to newly synthesized video content with arbitrary prompts (bottom). By optimizing DiT-specific positional embeddings, we can also synthesize new videos in a zero-shot manner.
| Method | CogVideoX-5B | CogVideoX-2B | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Caption | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | Caption | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ |
| Subject | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | Subject | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ |
| Scene | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | Scene | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ |
| All | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | All | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ | IQ ↑ | MF ↑ |
| Backbone | 0.524 | 0.315 | 0.502 | 0.321 | 0.544 | 0.318 | 0.523 | 0.318 | 0.521 | 0.313 | 0.495 | 0.312 | 0.523 | 0.314 | 0.513 | 0.313 |
| Injection [59] | 0.608 | 0.315 | 0.581 | 0.321 | 0.635 | 0.320 | 0.608 | 0.319 | 0.546 | 0.315 | 0.524 | 0.317 | 0.563 | 0.321 | 0.544 | 0.318 |
| SMM [62] | 0.782 | 0.313 | 0.741 | 0.317 | 0.776 | 0.316 | 0.766 | 0.315 | 0.687 | 0.312 | 0.682 | 0.312 | 0.694 | 0.317 | 0.688 | 0.312 |
| MOFT [59] | 0.728 | 0.313 | 0.728 | 0.321 | 0.722 | 0.319 | 0.726 | 0.318 | 0.503 | 0.312 | 0.502 | 0.313 | 0.508 | 0.315 | 0.504 | 0.312 |
| DiTFlow | 0.790 | 0.316 | 0.775 | 0.321 | 0.789 | 0.319 | 0.785 | 0.319 | 0.685 | 0.311 | 0.753 | 0.322 | 0.739 | 0.320 | 0.726 | 0.317 |
🔼 This table presents a quantitative comparison of DiTFlow against four baseline methods for video motion transfer. The evaluation uses three different types of prompts (Caption, Subject, Scene) to assess the model’s performance across diverse scenarios. The metrics used are Motion Fidelity (MF) and Image Quality (IQ). DiTFlow’s performance is shown for two different model sizes (CogVideoX-5B and CogVideoX-2B) to demonstrate the consistency of results across different model scales. Higher scores in MF and IQ indicate better motion transfer and overall video quality, respectively. The best-performing results for each category are highlighted in bold, and the second-best results are underlined. The results strongly suggest that DiTFlow significantly outperforms the baselines in terms of both motion and visual quality across all prompt types and model sizes.
read the caption
Table 1: Metrics evaluation. We compare DiTFlow across 3 different caption setups (Caption, Subject, Scene) and against 4 baselines. We consistently score first or second in all metrics for almost all scenarios, advocating the quality of our motion transfer. Performance is consistent across two backbones with 5B and 2B parameters respectively. Best results are in bold and second best are underlined.
In-depth insights#
DiTFlow: Motion Transfer#
DiTFlow presents a novel approach to video motion transfer, specifically designed for Diffusion Transformers (DiTs). Instead of relying on traditional UNet architectures, DiTFlow leverages the inherent global attention mechanism of DiTs to extract motion patterns directly from the network’s internal representations. This is achieved through the creation of Attention Motion Flow (AMF), a patch-wise motion signal derived from analyzing cross-frame attention maps. The AMF guides the latent denoising process in a training-free, optimization-based manner, enabling realistic motion transfer to newly synthesized video content. A key innovation is the ability to optimize DiT positional embeddings, facilitating zero-shot motion transfer without requiring further optimization for each new video generation. This makes DiTFlow computationally efficient, especially when handling multiple videos. DiTFlow’s training-free nature and its exploitation of DiT’s unique architecture offer a significant advancement in motion transfer, outperforming existing UNet-based methods in both quantitative and qualitative evaluations.
AMF: Attention Flow#
The concept of “AMF: Attention Motion Flow” represents a novel approach to video motion transfer, leveraging the inherent capabilities of Diffusion Transformers (DiTs). Instead of relying on traditional methods, which often struggle with disentangling motion from content, AMF directly extracts motion patterns from the DiT’s cross-frame attention maps. This is a significant departure, as it exploits the global attention mechanism within DiTs to capture intricate relationships between video frames. The training-free nature of AMF is a key strength, making it computationally efficient and adaptable to various DiT architectures. By employing optimization techniques, the AMF guides the latent denoising process, effectively transferring the motion of a reference video to newly synthesized content. The innovative application of AMF to optimize positional embeddings opens the door to zero-shot motion transfer, a significant advancement over previous methods. This represents a potent combination of efficient motion extraction and powerful control over the video generation process, demonstrating a promising direction in realistic and controllable video synthesis.
Zero-shot Transfer#
The concept of ‘zero-shot transfer’ in the context of video motion transfer is highly innovative. It signifies the ability of a model, after training on a dataset of videos and prompts, to transfer motion from a reference video to a newly generated video conditioned on a completely unseen prompt. This is a significant advance over traditional approaches requiring additional training or fine-tuning for each new motion-transfer task. The success hinges on learning generalizable motion representations that can be applied across diverse scenarios. Optimizing positional embeddings within the diffusion transformer model is crucial to achieving this. By altering these embeddings, the model can reorganize its latent representation of the video, effectively transferring motion without retraining, and hence, in a true zero-shot manner. This method demonstrates the power of disentanglement, separating content from motion and thus allowing for flexible and efficient video manipulation.
DiT Optimization#
Optimizing Diffusion Transformers (DiTs) for video motion transfer presents a unique challenge. The paper explores two key optimization strategies: latent optimization and positional embedding optimization. Latent optimization directly adjusts the latent representations of the video at various denoising steps, minimizing the discrepancy between the generated video’s motion and that of a reference video. This approach yields high-quality results, but is computationally expensive. Conversely, positional embedding optimization modifies the positional embeddings within the DiT, enabling zero-shot motion transfer. This method significantly reduces computational cost, but may result in slightly less precise motion control. The choice between these strategies depends on the desired balance between accuracy and efficiency. The AMF loss function plays a crucial role, guiding both optimization strategies by quantifying the difference between the generated and reference Attention Motion Flows. The effectiveness of each method is thoroughly evaluated and compared, offering valuable insights into the tradeoffs involved in optimizing DiTs for video motion transfer.
Future Directions#
Future research could explore improving the robustness of DiTFlow to handle more diverse and complex motions beyond those seen in the training data. This might involve investigating more sophisticated motion representations or incorporating additional cues to guide the generation process. Another key area is reducing the computational cost, particularly for high-resolution videos or longer sequences. Exploring efficient optimization strategies or leveraging architectural innovations in diffusion models are promising avenues. Finally, enhancing the level of control over the generated videos is crucial. This could involve developing methods to seamlessly blend different motion styles, control the intensity of motion transfer, or allow more precise manipulation of specific elements within the video. Investigating the use of different prompt modalities beyond text, such as sketches or other visual cues, could broaden the applications and improve the ease of use.
More visual insights#
More on figures

🔼 DiTFlow uses a reference video to guide the generation of new videos. First, it extracts a patch-wise motion signal (Attention Motion Flow or AMF) from the reference video using a pre-trained Diffusion Transformer (DiT). This AMF is then used to condition the latent representation (zt) during the video generation process, ensuring the synthesized video mimics the motion of the reference video. The figure highlights the key steps: extracting the AMF from the reference video, using the DiT to generate a new video latent representation, and guiding that latent representation with the AMF to match the reference motion. Additionally, the experiments explored optimizing positional embeddings within the DiT to enable zero-shot motion transfer, where motion is transferred to new videos without additional optimization.
read the caption
Figure 2: Core idea of DiTFlow. We extract the AMF from a reference video and we use that to guide the latent representation ztsubscript𝑧𝑡z_{t}italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT towards the motion of the reference video. In our experiments, we also tested optimizing positional embeddings for improved zero-shot performance.

🔼 Figure 3 illustrates the process of generating Attention Motion Flow (AMF) from a reference video. It begins by processing cross-frame attention maps obtained from a Diffusion Transformer (DiT) model. The argmax operation identifies the strongest attention relationships between patches in consecutive frames, creating a displacement map that shows how patches move over time. For generating new videos, a soft argmax is used instead of argmax to retain gradient information during optimization, ensuring smoother motion transfer. The reference displacement is then used as guidance to constrain the motion of the synthesized video.
read the caption
Figure 3: Guidance. We compute the reference displacement by processing cross-frame attentions with an argmax operation and rearranging them into displacement maps, identifying patch-aware cross-frame relationships. For video synthesis, we do the same operation with a soft argmax to preserve gradients, and impose reconstruction with the reference displacement.

🔼 Figure 4 demonstrates a comparison of motion transfer results between DiTFlow and several baseline methods. The baselines, relying on UNet architectures, struggle with accurate motion transfer because their spatial averaging or localized deviation analysis fails to capture the complete spatiotemporal context of motion. This leads to errors in associating motion to the correct elements within the video frame. In contrast, DiTFlow leverages the attention mechanism within Diffusion Transformers to comprehensively understand the spatiotemporal dynamics of each patch within the video. This results in more precise motion transfer and accurate spatial positioning and sizing of moving elements within the generated video. The figure provides three examples illustrating this difference: a dog running, a bear running, and a parachutist descending. In each example, DiTFlow achieves significantly better motion transfer accuracy than the baselines.
read the caption
Figure 4: Baseline comparison. Baselines associate motion to wrong elements due to poor layout representation typical of UNet-based approaches that do spatial averaging or only consider deviations at each location. DiTFlow captures the spatio-temporal motion of each patch, resulting in correct spatial positioning and sizing of moving elements, e.g. the dog (left), the bear (middle), the parachute (right).

🔼 Figure 5 showcases the qualitative results of DiTFlow, demonstrating its ability to successfully transfer motion from a reference video to newly synthesized videos under diverse conditions. The top row illustrates how altering the text prompt significantly changes the generated video’s appearance (scene, objects, etc.) while preserving the original motion. This highlights DiTFlow’s capacity for content-agnostic motion transfer. The bottom right image further emphasizes this capability, showcasing accurate motion transfer despite substantial changes in the object’s position and scale in the generated video compared to the reference video.
read the caption
Figure 5: Qualitative results of DiTFlow. We are able to perform motion transfer in various conditions. Note how varying the prompt completely changes the scene’s appearance while maintaining consistent motion. We map motion to correct elements even in cases where the motion changes drastically in positioning and size (bottom right).

🔼 This figure displays the results of a human evaluation comparing DiTFlow’s performance to other baselines in video generation. Participants rated generated videos on two aspects using a Likert scale: motion adherence (how well the generated video’s motion matched the reference video) and prompt adherence (how well the generated video matched the textual prompt). The bar chart visually represents the distribution of responses for each model across the levels of agreement (strongly agree, agree, neutral, disagree, strongly disagree). DiTFlow consistently outperforms the baselines in both motion and prompt adherence, demonstrating superior performance in capturing motion from reference videos and adhering to prompts.
read the caption
Figure 6: Human evaluation. We asked humans to evaluate agreement on the quality of generated samples in terms of motion (left) and prompt (right) adherence. DiTFlow consistently outperforms baselines in both evaluations.

🔼 Figure 7a presents a quantitative comparison of the zero-shot motion transfer performance between two versions of the proposed DiTFlow method (optimizing latent representations zt and positional embeddings p) and the SMM baseline. The results are based on the ‘All’ prompts category (Caption, Subject, Scene) from Table 1 and showcase the effectiveness of the zero-shot approach for various prompts.
read the caption
(a) Quantitative evaluation. SMM and Ours-ztsubscript𝑧𝑡z_{t}italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT follow Table 1 (All)
More on tables
| Reference | Caption | Subject | Scene | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
 | |  |  |  |  |  | ||||
| Injection |  |  |  |  |  |  | ||||
| SMM [62] |  |  |  |  |  |  | ||||
| MOFT [59] |  |  |  |  |  |  | ||||
| DiTFlow |  |  |  |  |  |  | ||||
| “Dog running between poles in an agility course” | “Bear running in a garden” | “Parachuting over a city, aerial view from above” |
🔼 This table presents ablation study results focusing on the impact of different choices for the guidance block in the DiTFlow model. It shows the Mean Intersection over Union (MIoU) and Mean Average Precision (mAP) metrics for different configurations, such as using different blocks for optimization, varying the number of denoising steps with guidance, and changing the number of optimization steps. The results help to determine the optimal configuration for the DiTFlow model, balancing performance and computational cost.
read the caption
(a) Guidance block
🔼 This table presents ablation study results on the impact of varying the number of denoising steps on the performance of the DiTFlow model. Specifically, it shows how changing the percentage of denoising steps guided by the AMF (Attention Motion Flow) affects the model’s Motion Fidelity (MF) and Image Quality (IQ) scores. The results are presented for different percentages of guided steps (0%, 20%, 40%, 80%, and 100%), allowing for an analysis of the optimal balance between guidance and computational cost.
read the caption
(b) Denoising steps
| Prompts used for the optimization | ||||
|---|---|---|---|---|
| “A blue Sedan car turning into a driveway” | “Zoom into a gorilla wearing a lab coat on a field” | |||
| SMM | ||||
| https://arxiv.org/html/2412.07776/extracted/6056616/figures/camel_easy/smmloss_latentopt_injecthard1.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/camel_easy/smmloss_latentopt_injecthard3.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/lab-coat_hard/smmloss_latentopt_injectmedium1.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/lab-coat_hard/smmloss_latentopt_injectmedium3.png | |
| Ours-$z_t$ | ||||
| https://arxiv.org/html/2412.07776/extracted/6056616/figures/camel_easy/flowloss_latentopt_injecthard1.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/camel_easy/flowloss_latentopt_injecthard3.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/lab-coat_hard/flowloss_latentopt_injectmedium1.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/lab-coat_hard/flowloss_latentopt_injectmedium3.png | |
| Ours-ρ | ||||
| https://arxiv.org/html/2412.07776/extracted/6056616/figures/camel_easy/flowloss_ropeopt_injecthard1.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/camel_easy/flowloss_ropeopt_injecthard3.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/lab-coat_hard/flowloss_ropeopt_injectmedium1.png | https://arxiv.org/html/2412.07776/extracted/6056616/figures/lab-coat_hard/flowloss_ropeopt_injectmedium3.png | |
| “A camel walking in a zoo” | “Zoom into a lion standing on a cliff looking towards us” |
🔼 This table shows the ablation study on the number of optimization steps used in DiTFlow. It displays how the performance metrics (MF and IQ) change as the number of optimization steps increases from 1 to 10, allowing one to see the impact of increased computational cost on the quality of the generated video.
read the caption
(c) Optimization steps
| Block | MF ↑ | IQ ↑ |
|---|---|---|
| 0 | 0.620 | 0.321 |
| 10 | 0.670 | 0.309 |
| 20 | 0.797 | 0.313 |
| 30 | 0.558 | 0.315 |
🔼 This table presents ablation study results for the DiTFlow model, investigating different aspects of its inference pipeline. The first part (2a) analyzes the contribution of different DiT blocks to motion transfer, showing that earlier blocks are more influential. The second and third parts (2b and 2c) examine the impact of increasing computational resources by varying the number of denoising steps and optimization steps, respectively, demonstrating performance improvements with greater computational power.
read the caption
Table 2: Ablation studies. We investigate our inference setups. In 2(a), we highlight that early blocks in DiTs contribute more to motion. In 2(b) and 2(c), we show that DiTFlow performance can be further boosted by increasing computational power.
| $T_{\text{opt}}$ | MF ↑ | IQ ↑ |
|---|---|---|
| 0% | 0.623 | 0.317 |
| 20 % | 0.797 | 0.313 |
| 40 % | 0.813 | 0.314 |
| 80 % | 0.803 | 0.311 |
| 100 % | 0.799 | 0.312 |
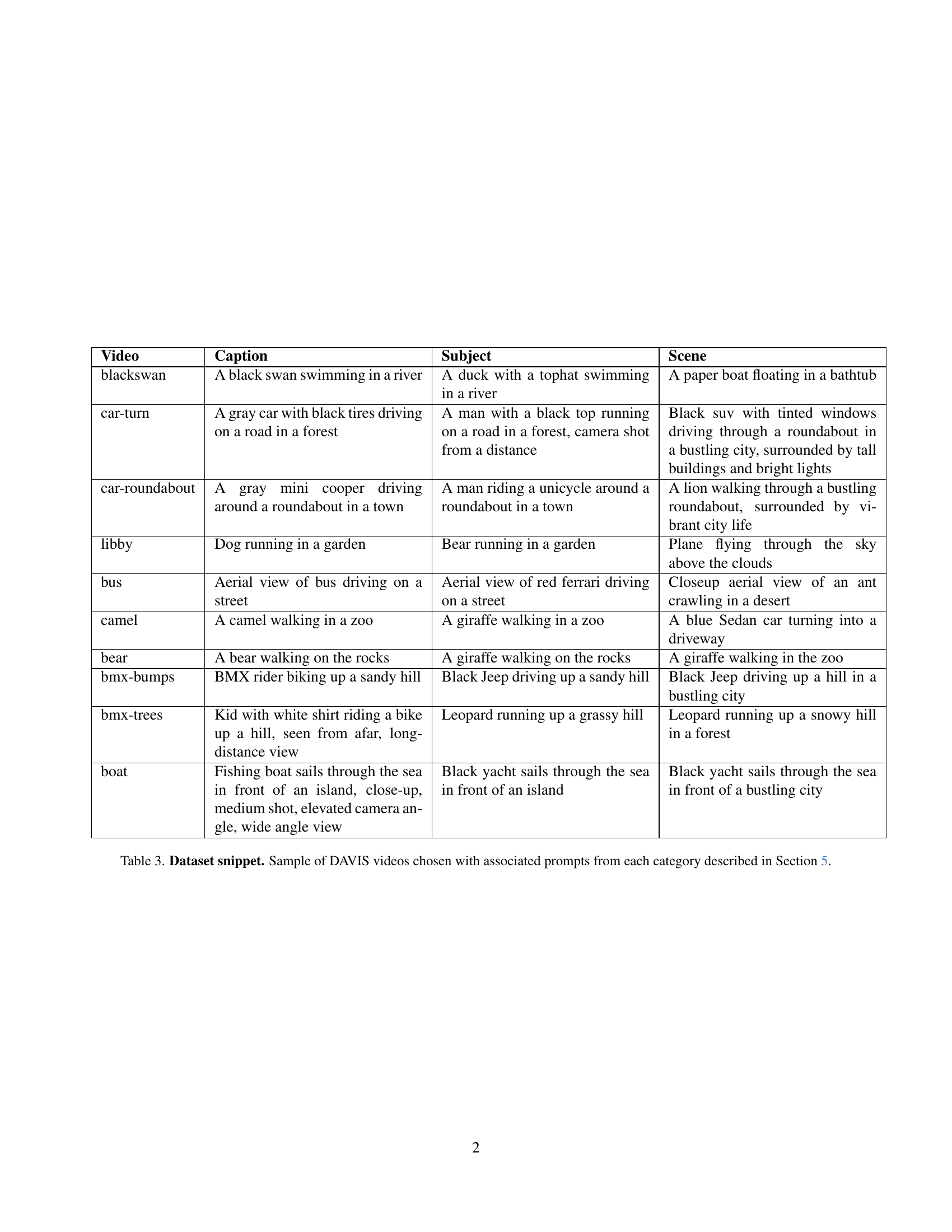
🔼 This table presents a subset of the DAVIS dataset used in the paper’s experiments. For each video, three different prompts are provided, categorized as ‘Caption,’ ‘Subject,’ and ‘Scene.’ The ‘Caption’ prompt is a simple description of the video content. The ‘Subject’ prompt alters the subject of the video while maintaining a similar scene. The ‘Scene’ prompt completely changes the scene and context while keeping the original video’s motion as inspiration. This sampling showcases the variety of videos and prompt types employed in the evaluation to thoroughly assess the motion transfer techniques.
read the caption
Table 3: Dataset snippet. Sample of DAVIS videos chosen with associated prompts from each category described in Section 5.
Full paper#