↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models have achieved impressive results but are resource-intensive. Smaller models offer accessibility but often lag in complex tasks like reasoning. Traditional optimization strategies, like scaling learning rates with batch size, are well-established for large models, but their effectiveness on smaller models isn’t fully understood. This raises the question: how can we optimize training for small models to maximize their performance, especially in areas where they currently struggle?
This paper explored how adjusting the relationship between learning rate and batch size during fine-tuning affects a small language model’s (1.7B parameter) reasoning and pattern recognition abilities. They found that higher learning rate to batch size ratios significantly improved reasoning performance (e.g., math problems, instruction following), while lower ratios were better for pattern recognition tasks. This suggests that tailoring optimization strategies based on the task can unlock the potential of smaller models. The resulting model, SmolTulu, achieves state-of-the-art performance for its size, demonstrating that careful tuning can bring smaller models closer to the capabilities of much larger ones. This finding is significant for researchers working with limited resources.
Key Takeaways#
Why does it matter?#
Smaller language models (SLMs) are gaining traction due to accessibility and lower resource requirements. This research is crucial as it sheds light on how to optimize these SLMs for better performance, particularly in reasoning tasks. By exploring non-traditional optimization strategies, this work opens new avenues for efficient SLM training and deployment, potentially bridging the gap between small and large language models. This has significant implications for democratizing access to powerful language models and furthering research in resource-constrained environments.
Visual Insights#

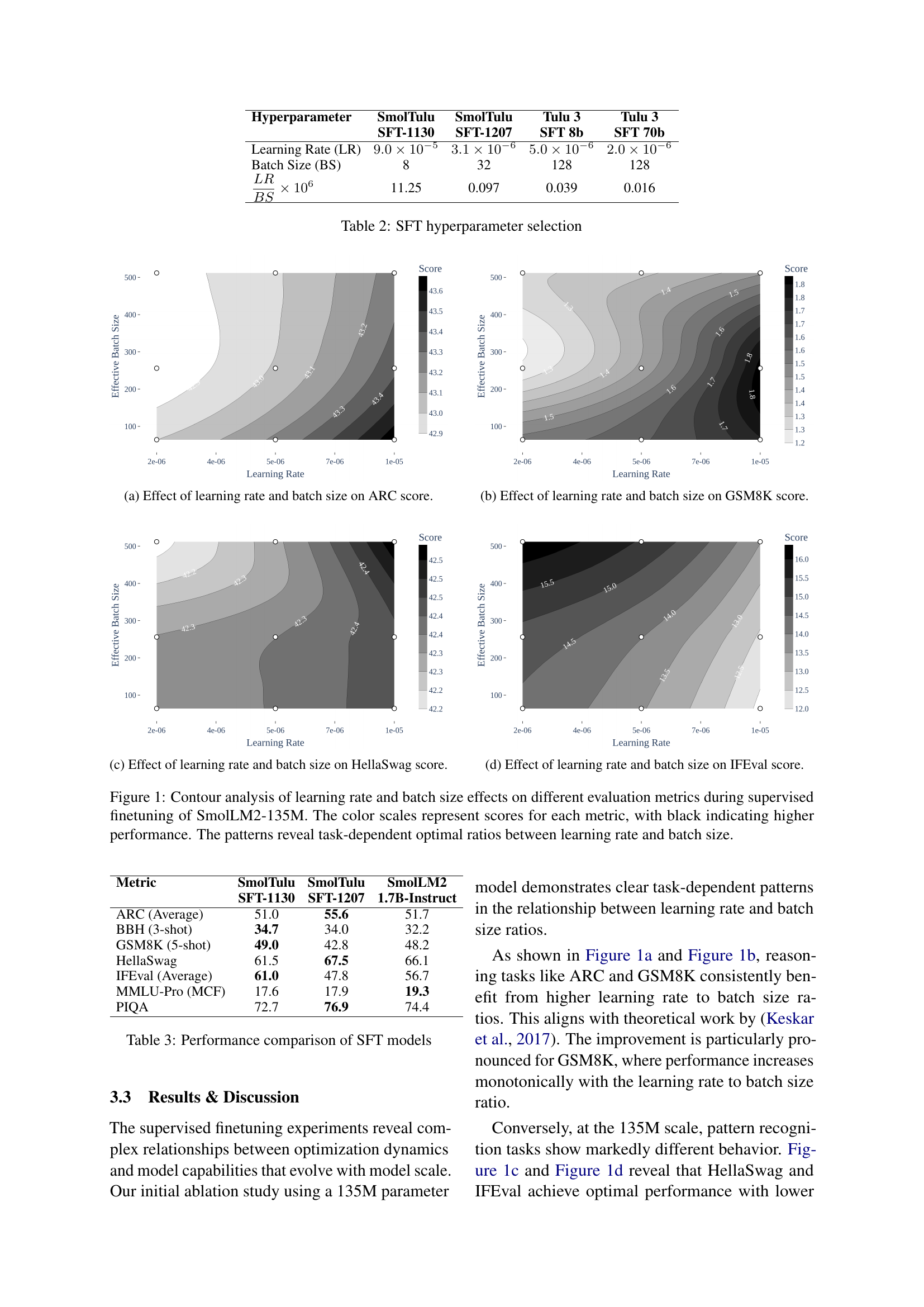
🔼 This contour plot visually represents how different learning rates and batch sizes impact the performance of a 135 million parameter language model on the ARC Challenge, a reasoning task. The x-axis represents the learning rate, and the y-axis represents the effective batch size. The darker areas indicate higher ARC scores, meaning better performance. The contours show how the performance changes with different combinations of learning rate and batch size, revealing the optimal ratio between these hyperparameters for this specific task and model size.
read the caption
(a) Effect of learning rate and batch size on ARC score.
| Benchmark | Contamination |
|---|---|
| cais/mmlu | 1.34% |
| openai/openai_humaneval | 0.00% |
| openai/gsm8k | 0.08% |
| ucinlp/drop | 0.20% |
| lighteval/MATH | 0.06% |
| google/IFEval | 0.00% |
| akariasai/PopQA | 7.21% |
| tatsu-lab/alpaca_eval | 1.37% |
| lukaemon/bbh | 0.02% |
| truthfulqa/truthful_qa | 1.47% |
| allenai/wildguardmix | 0.06% |
| allenai/wildjailbreak | 0.00% |
| TIGER-Lab/MMLU-Pro | 0.93% |
| Idavidrein/gpqa | 0.00% |
| lighteval/agi_eval_en | 0.00% |
| bigcode/bigcodebench | 0.00% |
| deepmind/math_dataset | 0.00% |
🔼 This table presents the contamination levels of various benchmarks used in the Supervised Fine-tuning (SFT) dataset. Contamination refers to the presence of test data in the training set, which can inflate evaluation metrics. Each benchmark is listed with its corresponding percentage of contamination.
read the caption
Table 1: Contamination of benchmarks in the SFT dataset used allenai/tulu-3-sft-mixture
In-depth insights#
SmolTulu#
SmolTulu, an instruction-tuned language model, adapts the Tulu 3 pipeline to a smaller 1.7B parameter model, demonstrating that careful optimization is key for smaller models. The research reveals that the learning rate to batch size ratio significantly impacts performance, especially with limited capacity. Reasoning tasks like ARC and GSM8K favor higher ratios while pattern recognition tasks like HellaSwag and IFEval prefer lower ratios. This suggests that smaller models might need different optimization strategies than larger models due to their limited capacity. SmolTulu achieves state-of-the-art results among sub-2B models on instruction following and mathematical reasoning, showing the potential of adapting large model techniques to smaller, more accessible models. Further research is needed on adaptive optimization and multi-stage training dynamics.
LR/BS Ratios#
The research paper explores the impact of learning rate (LR) to batch size (BS) ratios on model performance, particularly in smaller language models. It emphasizes that this ratio significantly influences training dynamics and achieving optimal performance requires careful consideration of its interplay with model size and task type. Reasoning tasks like ARC and GSM8K benefit from higher LR/BS ratios, while pattern recognition tasks like HellaSwag and IFEval favor lower ratios in smaller models. This suggests a trade-off between different types of learning due to limited capacity. However, larger models exhibit more nuanced behavior, with some benefiting from higher ratios across different tasks. This highlights the complex interplay between model capacity and optimal optimization strategy. Careful tuning of LR/BS ratios can therefore compensate for limited model capacity, particularly in smaller models, and deviates from conventional wisdom derived from large-scale training.
SFT/DPO/RLVR#
SFT (Supervised Fine-Tuning), DPO (Direct Preference Optimization), and RLVR (Reinforcement Learning with Verifiable Rewards) represent a powerful progression of techniques for aligning language models with human preferences and objectives. SFT establishes a foundational understanding of instructions and desired outputs. DPO refines this by directly optimizing the model to produce outputs preferred by humans, offering increased efficiency compared to traditional reward model approaches. Finally, RLVR introduces the concept of verifiable rewards, leveraging ground truth answers to guide reinforcement learning and enhance performance on tasks with clear correctness criteria. This combination of techniques allows for a robust and efficient training pipeline, enabling language models to achieve better alignment with human intent.
Scaling Laws#
Scaling laws are fundamental to understanding how model performance changes with scale, informing resource allocation and architectural choices. They reveal predictable relationships between model size, data size, and compute budget, enabling more efficient training and deployment. However, scaling laws are not uniform and exhibit task dependence. Smaller models might not follow the same scaling laws as larger models, suggesting different optimization dynamics are at play. Furthermore, scaling laws must consider not just model size but also data quality and diversity, especially for complex reasoning tasks. Focusing solely on size may lead to diminishing returns, as model capacity alone cannot overcome limitations imposed by inadequate or biased data. Finally, exploration of dynamic scaling laws that adapt throughout the training process may offer further improvements compared to statically defined laws.
Small Model Future#
Smaller language models hold immense potential for democratizing AI. Their reduced computational demands make them deployable in resource-constrained environments, widening access to advanced language processing capabilities. While smaller models may not match the raw performance of their larger counterparts, strategic optimization techniques can significantly bridge the capability gap. Efficient fine-tuning methods, innovative training recipes, and careful hyperparameter tuning are crucial for unlocking the full potential of these models, particularly for specialized tasks. This shift towards smaller models emphasizes efficiency and accessibility, empowering a broader range of users and applications while promoting responsible AI development. Further research into optimization dynamics and task-specific training strategies will be instrumental in shaping the future trajectory of smaller, more efficient language models.
More visual insights#
More on figures

🔼 This contour plot visualizes the performance of a 135M parameter language model on the GSM8K benchmark as a function of learning rate and effective batch size during supervised fine-tuning. The x-axis represents the learning rate, and the y-axis represents the effective batch size. The color gradient reflects the model’s performance, with darker shades indicating higher GSM8K scores. The plot reveals that higher learning rate to batch size ratios generally lead to better performance on this mathematical reasoning task.
read the caption
(b) Effect of learning rate and batch size on GSM8K score.

🔼 This contour plot analyzes the effects of learning rate and effective batch size on the HellaSwag score during supervised finetuning of the SmolLM2-135M model. The x-axis represents the learning rate, and the y-axis is the effective batch size. The contour lines and color gradients represent the HellaSwag score, with darker shades indicating higher performance. The plot reveals that HellaSwag, a pattern recognition task, achieves optimal performance with lower learning rate to batch size ratios.
read the caption
(c) Effect of learning rate and batch size on HellaSwag score.

🔼 This contour plot shows the effect of varying learning rate and effective batch size on the IFEval score during supervised finetuning. It visualizes the performance of a 135 million parameter language model (SmollM2-135M) across different learning rate and effective batch size combinations. The x-axis represents the learning rate, and the y-axis represents the effective batch size. The color gradient represents the IFEval score, where darker shades indicate higher scores. The plot reveals an optimal region for learning rate and batch size settings that yield the best performance on the IFEval benchmark.
read the caption
(d) Effect of learning rate and batch size on IFEval score.
More on tables
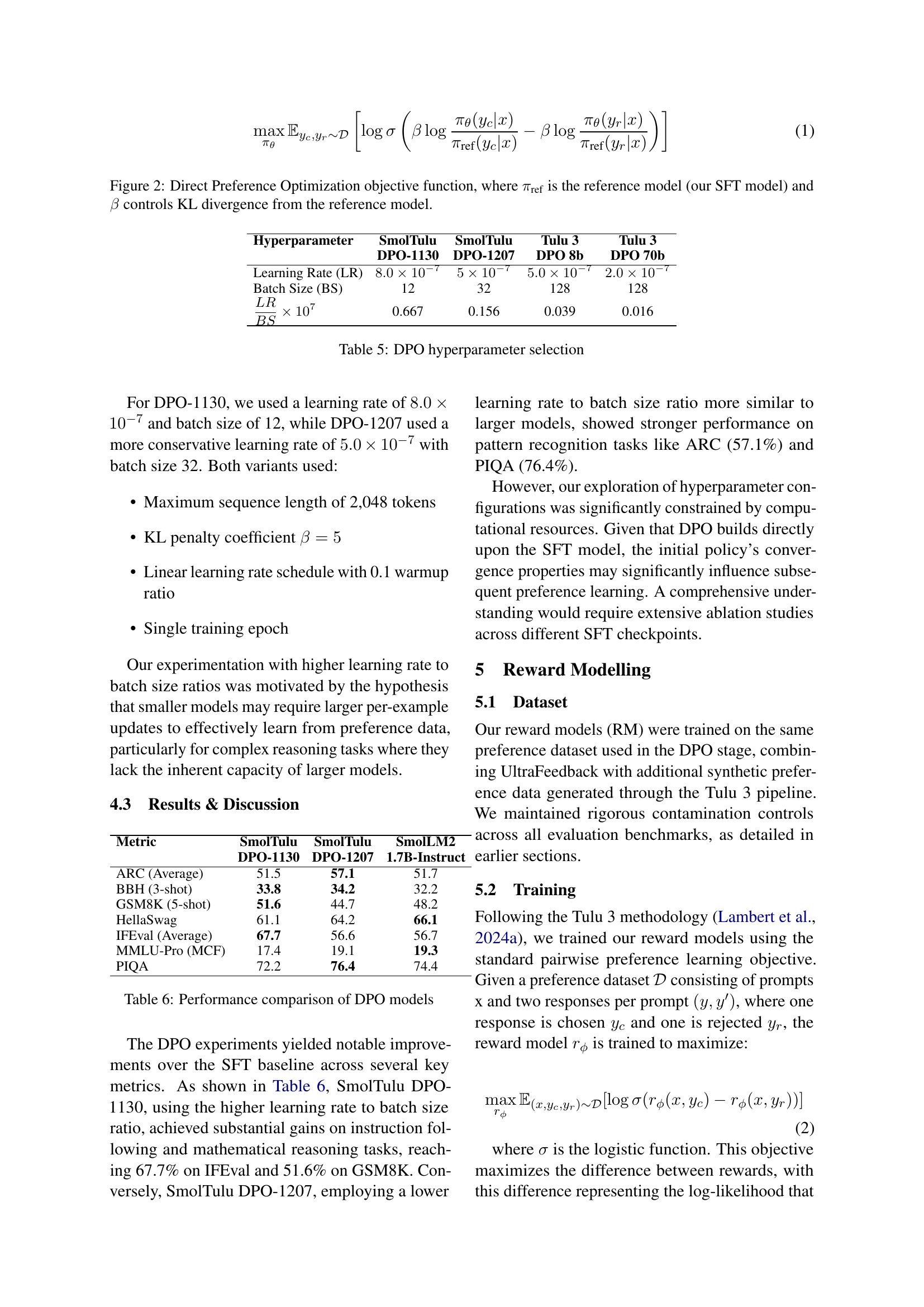
| Hyperparameter | SmolTulu | SmolTulu | Tulu 3 | Tulu 3 |
|---|---|---|---|---|
| SFT-1130 | SFT-1207 | SFT 8b | SFT 70b | |
| Learning Rate (LR) | 9.0 × 10⁻⁵ | 3.1 × 10⁻⁶ | 5.0 × 10⁻⁶ | 2.0 × 10⁻⁶ |
| Batch Size (BS) | 8 | 32 | 128 | 128 |
| LR/BS × 10⁶ | 11.25 | 0.097 | 0.039 | 0.016 |
🔼 This table shows the selected hyperparameters for supervised finetuning (SFT), including learning rate (LR), batch size (BS), and the ratio of LR to BS, for different model sizes during the supervised finetuning stage. Effective Batch Size is calculated to match Tulu-3 and to represent the true batch size used. SmolTulu and Tulu 3 utilize different LR/BS ratios, with SmolTulu employing higher ratios, especially at smaller scales.
read the caption
Table 2: SFT hyperparameter selection
| Metric | SmolTulu SFT-1130 | SmolTulu SFT-1207 | SmolLM2 1.7B-Instruct |
|---|---|---|---|
| ARC (Average) | 51.0 | 55.6 | 51.7 |
| BBH (3-shot) | 34.7 | 34.0 | 32.2 |
| GSM8K (5-shot) | 49.0 | 42.8 | 48.2 |
| HellaSwag | 61.5 | 67.5 | 66.1 |
| IFEval (Average) | 61.0 | 47.8 | 56.7 |
| MMLU-Pro (MCF) | 17.6 | 17.9 | 19.3 |
| PIQA | 72.7 | 76.9 | 74.4 |
🔼 This table presents a comparison of the performance of different Supervised Fine-Tuning (SFT) models, including two versions of SmolTulu (SFT-1130 and SFT-1207), and the SmolLM2 1.7B-Instruct model. The models are evaluated on a variety of benchmarks including ARC, BBH, GSM8K, HellaSwag, IFEval, MMLU-Pro, and PIQA. The table shows the scores achieved by each model on these benchmarks, allowing for a direct comparison of their performance after SFT.
read the caption
Table 3: Performance comparison of SFT models
| Benchmark | Contamination |
|---|---|
| cais/mmlu | 0.69% |
| openai/openai_humaneval | 0.00% |
| openai/gsm8k | 0.00% |
| ucinlp/drop | 0.07% |
| lighteval/MATH | 0.02% |
| google/IFEval | 0.00% |
| akariasai/PopQA | 2.72% |
| tatsu-lab/alpaca_eval | 1.24% |
| lukaemon/bbh | 0.00% |
| truthfulqa/truthful_qa | 0.61% |
| allenai/wildguardmix | 0.06% |
| allenai/wildjailbreak | 0.00% |
| TIGER-Lab/MMLU-Pro | 0.36% |
| Idavidrein/gpqa | 0.00% |
| lighteval/agi_eval_en | 0.00% |
| bigcode/bigcodebench | 0.00% |
| deepmind/math_dataset | 0.00% |
🔼 This table presents the contamination levels of various evaluation benchmarks within the Direct Preference Optimization (DPO) dataset, which is a mixture of preference data derived from various sources. Contamination refers to the presence of training data within the evaluation set, which can inflate performance metrics. Lower contamination percentages indicate a cleaner evaluation set. This analysis is crucial for ensuring a fair and accurate assessment of the model’s performance improvements after undergoing preference optimization. The table lists the benchmark dataset name and its corresponding contamination rate.
read the caption
Table 4: Contamination of benchmarks in the DPO dataset used allenai/llama-3.1-tulu-3-8b-preference-mixture
| DPO 70b | ||||
|---|---|---|---|---|
| Learning Rate (LR) | 8.0e-7 | 5e-7 | 5.0e-7 | 2.0e-7 |
| Batch Size (BS) | 12 | 32 | 128 | 128 |
| LR/BS x 10^7 | 0.667 | 0.156 | 0.039 | 0.016 |
🔼 Hyperparameters used for Direct Preference Optimization (DPO) training across different model sizes, including learning rate, batch size, and the derived ratio between them.
read the caption
Table 5: DPO hyperparameter selection
| Metric | SmolTulu DPO-1130 | SmolTulu DPO-1207 | SmolLM2 1.7B-Instruct |
|---|---|---|---|
| ARC (Average) | 51.5 | 57.1 | 51.7 |
| BBH (3-shot) | 33.8 | 34.2 | 32.2 |
| GSM8K (5-shot) | 51.6 | 44.7 | 48.2 |
| HellaSwag | 61.1 | 64.2 | 66.1 |
| IFEval (Average) | 67.7 | 56.6 | 56.7 |
| MMLU-Pro (MCF) | 17.4 | 19.1 | 19.3 |
| PIQA | 72.2 | 76.4 | 74.4 |
🔼 This table compares the performance of different Direct Preference Optimization (DPO) models, including two SmolTulu variants (DPO-1130 and DPO-1207) and a baseline SmolLM2 1.7B-Instruct model, across a range of evaluation metrics (ARC, BBH, GSM8K, HellaSwag, IFEval, MMLU-Pro, and PIQA). The table presents the scores achieved by each model on these benchmarks, allowing for direct comparison and analysis of the impact of different DPO hyperparameter settings on the performance of smaller vs. larger language models.
read the caption
Table 6: Performance comparison of DPO models
| Hyperparameter | SmolTulu | SmolTulu | Tulu 3 |
|---|---|---|---|
| RM-1130 | RM-1207 | DPO 8b | |
| Learning Rate (LR) | 4.0 × 10⁻⁵ | 7.5 × 10⁻⁷ | 5.0 × 10⁻⁷ |
| Batch Size (BS) | 4 | 8 | 128 |
| LR/BS × 10⁷ | 100 | 0.938 | 0.039 |
🔼 This table details the hyperparameters used for training the reward model, including learning rate and batch size. Two configurations are shown for the SmolTulu models and one for the Tulu 3 8b model, allowing for comparison. The key difference is the learning rate to batch size ratio, which is significantly higher for the smaller SmolTulu models. This highlights the exploration of different optimization strategies tailored to the model scale.
read the caption
Table 7: Reward model hyperparameter selection
| Metric | SmolTulu RM-1130 | SmolTulu RM-1207 | Tulu 3 8b RM |
|---|---|---|---|
| RB Chat | 94.13 | 83.52 | 96.27 |
| RB Chat Hard | 43.64 | 44.74 | 55.92 |
| RB Safety | 75.54 | 64.59 | 84.05 |
| RB Reasoning | 68.01 | 54.71 | 76.50 |
| RB Average | 72.43 | 58.59 | 81.34 |
| UFB | 73.17 | 61.66 | 77.34 |
🔼 This table presents a comparison of the performance of different reward models (RMs). It includes two variants of SmolTulu RMs, and a Tulu 3 RM for comparison. The table uses two key metrics: UltraFeedback (UFB) and RewardBench (RB), RB is further categorized into RB Chat, RB Chat Hard, RB Safety, and RB Reasoning, providing a more comprehensive evaluation across different aspects of reward modeling.
read the caption
Table 8: Performance comparison of reward models, where UFB is the test_prefs split of allenai/ultrafeedback_binarized_cleaned and RB is RewardBench.
| Metric | SmolTulu DPO-1130 | SmolTulu DPO-1207 | SmolTulu SFT-1130 | SmolTulu SFT-1207 | SmolLM2 1.7B-Instruct | Llama-3.2 1B-Instruct | Qwen2.5 1.5B-Instruct |
|---|---|---|---|---|---|---|---|
| ARC (Average) | 51.5 | 57.1 | 51.0 | 55.6 | 51.7 | 41.6 | 46.2 |
| BBH (3-shot) | 33.8 | 34.2 | 34.7 | 34.0 | 32.2 | 27.6 | 35.3 |
| GSM8K (5-shot) | 51.6 | 44.7 | 49.0 | 42.8 | 48.2 | 26.8 | 42.8 |
| HellaSwag | 61.1 | 64.2 | 61.5 | 67.5 | 66.1 | 56.1 | 60.9 |
| IFEval (Average) | 67.7 | 56.6 | 61.0 | 47.8 | 56.7 | 53.5 | 47.4 |
| MMLU-Pro (MCF) | 17.4 | 19.1 | 17.6 | 17.9 | 19.3 | 12.7 | 24.2 |
| PIQA | 72.2 | 76.4 | 72.7 | 76.9 | 74.4 | 72.3 | 73.2 |
🔼 This table presents a comprehensive comparison of the performance of different SmolTulu models against a wider selection of prominent language models, including SmolLM2, Llama 3.2, and Qwen 2.5. The evaluation spans a variety of tasks, such as ARC, BBH, GSM8K, HellaSwag, IFEval, MMLU-Pro, and PIQA, providing a holistic view of the models’ capabilities across different domains.
read the caption
Table 9: A comparison against a wider selection of models
| Language | Presence (%) |
|---|---|
| English | 83.13 |
| Hindi | 3.79 |
| Swahili | 2.02 |
| Russian | 2.00 |
| Spanish | 1.15 |
| Arabic | 0.98 |
| Chinese | 0.94 |
| Turkish | 0.87 |
| Urdu | 0.78 |
| Portuguese | 0.77 |
| Vietnamese | 0.64 |
| Japanese | 0.63 |
| French | 0.66 |
| Bulgarian | 0.33 |
| Italian | 0.32 |
| Dutch | 0.31 |
| Polish | 0.25 |
| German | 0.23 |
| Thai | 0.10 |
| Greek | 0.09 |
🔼 This table presents the distribution of different languages within the Supervised Fine-tuning (SFT) dataset used for training the SmolTulu language model. It lists various languages and their corresponding percentage presence in the dataset, providing insights into the linguistic diversity of the training data.
read the caption
Table 10: Language distribution in SFT dataset.
| Language | Presence (%) |
|---|---|
| English | 86.24 |
| Hindi | 2.23 |
| Russian | 2.03 |
| French | 1.42 |
| Spanish | 1.40 |
| Chinese | 1.37 |
| Urdu | 0.68 |
| Swahili | 0.65 |
| German | 0.58 |
| Japanese | 0.57 |
| Portuguese | 0.54 |
| Arabic | 0.51 |
| Turkish | 0.42 |
| Vietnamese | 0.33 |
| Italian | 0.32 |
| Polish | 0.22 |
| Dutch | 0.18 |
| Bulgarian | 0.18 |
| Thai | 0.10 |
| Greek | 0.04 |
🔼 This table presents the language distribution within the dataset used for Direct Preference Optimization (DPO) and Reward Modeling (RM). It lists various languages and their corresponding percentage presence in the dataset.
read the caption
Table 11: Language distribution in DPO / RM dataset.
| Language | Presence (%) |
|---|---|
| English | 94.80 |
| French | 1.29 |
| Spanish | 1.04 |
| Chinese | 0.66 |
| German | 0.55 |
| Russian | 0.48 |
| Japanese | 0.40 |
| Hindi | 0.23 |
| Polish | 0.10 |
| Portuguese | 0.10 |
| Dutch | 0.08 |
| Urdu | 0.07 |
| Bulgarian | 0.07 |
| Italian | 0.05 |
| Turkish | 0.03 |
| Arabic | 0.03 |
| Vietnamese | 0.02 |
| Swahili | 0.00 |
🔼 This table shows the language distribution of the Reinforcement Learning with Verifiable Rewards (RLVR) dataset used for training the model. Most of the dataset consists of English text (94.8%), followed by French (1.29%), and Spanish (1.04%). Other languages are present in smaller amounts.
read the caption
Table 12: Language distribution in RLVR dataset.
| Benchmark | Contamination |
|---|---|
| cais/mmlu | 0.65% |
| openai/openai_humaneval | 0.00% |
| openai/gsm8k | 0.00% |
| ucinlp/drop | 0.00% |
| lighteval/MATH | 0.24% |
| google/IFEval | 0.00% |
| akariasai/PopQA | 0.45% |
| tatsu-lab/alpaca_eval | 0.12% |
| lukaemon/bbh | 0.00% |
| truthfulqa/truthful_qa | 0.12% |
| allenai/wildguardmix | 0.00% |
| allenai/wildjailbreak | 0.00% |
| TIGER-Lab/MMLU-Pro | 0.66% |
| Idavidrein/gpqa | 0.00% |
| lighteval/agi_eval_en | 0.00% |
| bigcode/bigcodebench | 0.00% |
| deepmind/math_dataset | 0.00% |
🔼 This table presents the contamination levels of various evaluation benchmarks within the RLVR dataset, specifically the
allenai/RLVR-GSM-MATH-IF-Mixed-Constraintsversion. Contamination refers to the presence of test data within the training set, which can inflate evaluation metrics and provide an unrealistic assessment of model performance. By quantifying the contamination rate for each benchmark, this table offers insights into the reliability and trustworthiness of the evaluation results obtained using this dataset.read the caption
Table 13: Contamination of benchmarks in the RLVR dataset allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
Full paper#